

Das Web ist 2026 ein ziemlich rauer Ort – mittlerweile geht die Hälfte des gesamten Internetverkehrs auf das Konto von Bots, und Open-Source-Web-Crawler sind die stillen Arbeitstiere im Hintergrund. Sie halten alles am Laufen, von der Preisüberwachung bis zum KI-Training. Ich bin seit Jahren in SaaS und Automatisierung unterwegs, und eine Erkenntnis hat sich dabei besonders eingeprägt: Der richtige selbst gehostete Crawler erspart einem Team Monate voller Ärger – und so manche durchgemachte Debugging-Nacht. Egal, ob Sie nur eine Handvoll Produktseiten scrapen oder Millionen von URLs für die Forschung crawlen: Die Open-Source-Alternativen zu Firecrawl auf dieser Liste decken jeden Bedarf ab – ganz gleich, wie groß das Vorhaben ist, wie Ihr Tech-Stack aussieht oder wie viel Komplexität Sie sich zumuten wollen.
Eine Einschränkung gibt es allerdings: Die eine Lösung, die zu allen passt, existiert nicht. Manche Teams setzen auf die rohe Power von Scrapy oder die Archivierungsstärke von Heritrix, anderen wird die Pflege von Open-Source-Bibliotheken schlicht zu teuer. Deshalb stellen wir hier die 9 besten Open-Source-Alternativen zu Firecrawl für 2026 vor, zeigen, wo jede Lösung ihre Stärken hat, und helfen Ihnen, das passende Tool für Ihre Anforderungen zu finden – ohne das übliche Ausprobieren auf gut Glück.
So wählen Sie die beste Open-Source-Alternative zu Firecrawl für Ihr Unternehmen
Bevor Sie sich in die Liste stürzen, ein kurzes Wort zur Strategie. Die Landschaft des Open-Source-Web-Crawlings ist so vielfältig wie nie, und Ihre Entscheidung sollte von ein paar zentralen Faktoren abhängen:
- Einfachheit der Nutzung: Soll es eine Point-and-Click-Oberfläche sein, oder schreiben Sie lieber Python, Go oder JavaScript?
- Skalierbarkeit: Geht es nur um eine einzelne Website, oder müssen Sie Millionen von Seiten über Hunderte von Domains crawlen?
- Inhaltstyp: Ist Ihre Zielseite statisches HTML, oder lebt sie von schwerem JavaScript und dynamischem Nachladen?
- Integrationsanforderungen: Was wollen Sie mit den Daten machen – nach Excel exportieren, in eine Datenbank schieben oder in eine Analytics-Pipeline einspeisen?
- Wartung: Haben Sie die Kapazität, eigenen Code zu pflegen, oder soll sich das Tool selbst an Website-Änderungen anpassen?
Hier ein kurzer Spickzettel für die Entscheidung:
| Szenario | Bestes Tool / beste Tools |
|---|---|
| No-Code, Offline-Browsing | HTTrack |
| Groß angelegtes Crawling über mehrere Domains | Scrapy, Apache Nutch, StormCrawler |
| Dynamische / JS-lastige Websites | Puppeteer |
| Formularautomatisierung / Login erforderlich | MechanicalSoup |
| Statische Website herunterladen / archivieren | Wget, HTTrack, Heritrix |
| Go-Entwickler, hohe Performance | Colly |
Und jetzt zu den 9 besten Open-Source-Alternativen zu Firecrawl für 2026.
1. Scrapy: Am besten für groß angelegtes Crawling mit Python

Scrapy ist der Schwergewichts-Champion unter den Open-Source-Web-Crawlern. Das in Python geschriebene Framework ist die erste Adresse für Entwickler, die in großem Maßstab crawlen müssen – also Millionen von Seiten, häufige Aktualisierungen und verzwickte Website-Logik.
Warum Scrapy?
- Enorme Skalierung: Scrapy stemmt Tausende von Anfragen pro Sekunde und ist bei Unternehmen im Einsatz, die monatlich Milliarden von Seiten scrapen (Zyte).
- Erweiterbar & modular: Schreiben Sie eigene Spiders, binden Sie Middleware für Proxys ein, handhaben Sie Logins und geben Sie die Daten als JSON, CSV oder in Datenbanken aus.
- Aktive Community: unzählige Plugins, ausführliche Dokumentation und schnelle Antworten auf Stack Overflow.
- Praxisbewährt: weltweit im produktiven Einsatz bei E-Commerce-, News- und Forschungsteams.
Einschränkungen: Für Nicht-Entwickler ist die Lernkurve steil, und Ihre Spiders wollen gepflegt werden, sobald sich Websites ändern. Wer aber volle Kontrolle und Skalierbarkeit sucht, kommt an Scrapy kaum vorbei.
2. Apache Nutch: Am besten für Enterprise-Suchmaschinen
Apache Nutch ist gewissermaßen der Urvater der Open-Source-Crawler und wurde für Crawling auf Enterprise-Niveau und im Internet-Maßstab gebaut. Wenn Sie davon träumen, Ihre eigene Suchmaschine aufzubauen oder Millionen von Domains zu crawlen, ist Nutch Ihr Verbündeter.
Warum Apache Nutch?
- Hadoop-gestützte Skalierung: Auf Hadoop aufgesetzt, crawlt Nutch Milliarden von Seiten über Server-Cluster hinweg (Common Crawl setzt es genau dafür ein, um das öffentliche Web zu crawlen).
- Batch-Crawling: Geben Sie eine Liste von Seed-URLs vor und lassen Sie den Job durchlaufen – ideal für geplante Durchläufe im großen Stil.
- Integration: arbeitet mit Solr, Elasticsearch und Big-Data-Pipelines zusammen.
Einschränkungen: Die Einrichtung ist aufwendig (Hadoop-Cluster und Java-Konfigurationsdateien inklusive), und der Fokus liegt eher auf reinem Crawling als auf der Extraktion strukturierter Daten. Für kleine Projekte überdimensioniert, für Web-Scale-Crawling kaum zu schlagen.
3. Heritrix: Am besten für Web-Archivierung und Compliance

Heritrix ist der hauseigene Crawler des Internet Archive und eigens für Web-Archivierung und digitale Langzeitbewahrung entwickelt.
Warum Heritrix?
- Archivierungsreife Vollständigkeit: erfasst jede Seite, jedes Asset und jeden Link – ideal für rechtliche Compliance oder historische Snapshots.
- WARC-Ausgabe: speichert alles in standardisierten Web-ARChive-Dateien, bereit zur Wiedergabe oder Analyse.
- Webbasierte Verwaltung: Crawls über eine Browser-Oberfläche konfigurieren und überwachen.
Einschränkungen: schwergewichtig (braucht reichlich Speicher und RAM), führt kein JavaScript aus und liefert rohe Archive statt strukturierter Datentabellen. Wie geschaffen für Bibliotheken, Archive oder regulierte Branchen.
4. Colly: Am besten für leistungsstarke Go-Entwickler
Colly ist der Liebling der Go-Community – ein schneller, schlanker und stark parallelisierter Web-Scraper.
Warum Colly?
- Extrem schnell: Dank der Nebenläufigkeit von Go scrapt Colly Tausende von Seiten bei minimalem CPU- und RAM-Verbrauch (Oxylabs).
- Schlichte API: Definieren Sie Callbacks für HTML-Elemente; Cookies und robots.txt handhabt Colly automatisch.
- Ideal für statische Websites: perfekt für servergerenderte Seiten, APIs oder wenn Sie Scraping direkt in ein Go-Backend einbauen wollen.
Einschränkungen: kein eingebautes JavaScript-Rendering (für dynamische Seiten brauchen Sie etwas wie Chromedp dazu), und Go-Kenntnisse sind Voraussetzung.
5. MechanicalSoup: Am besten für einfache Formularautomatisierung

MechanicalSoup ist eine Python-Bibliothek, die die Lücke zwischen schlichten HTTP-Requests und vollwertiger Browserautomatisierung schließt.
Warum MechanicalSoup?
- Formularautomatisierung: einloggen, Formulare ausfüllen und Sitzungen aufrechterhalten – ideal, um hinter einer Authentifizierung zu scrapen.
- Leichtgewichtig: nutzt intern Requests und BeautifulSoup, ist also schnell und in Minuten eingerichtet.
- Perfekt für interaktive Websites: Wenn Sie Suchformulare absenden oder nach dem Login scrapen müssen, ist MechanicalSoup eine gute Wahl (Apify Blog).
Einschränkungen: keine JavaScript-Ausführung, damit für JS-lastige Websites ungeeignet. Am besten aufgehoben bei statischen oder servergerenderten Seiten mit einfachen Interaktionen.
6. Puppeteer: Am besten für dynamische und JavaScript-lastige Websites
Puppeteer ist das Allzweckwerkzeug zum Scrapen moderner, JavaScript-lastiger Websites. Die Node.js-Bibliothek gibt Ihnen die volle Kontrolle über einen Headless-Chrome-Browser.
Warum Puppeteer?
- Beherrscht dynamische Inhalte: Scrapen Sie SPAs, Infinite Scroll und Seiten, die ihre Daten per AJAX nachladen (Browserless Guide).
- Nutzer-Simulation: Buttons anklicken, Formulare ausfüllen, Screenshots erstellen und mit den passenden Plugins sogar CAPTCHAs lösen.
- Leistungsstarke Automatisierung: ideal für Tests, Monitoring und das Scrapen von allem, was ein echter Nutzer zu sehen bekommt.
Einschränkungen: ressourcenhungrig (es laufen vollständige Chrome-Instanzen), langsamer als reine HTTP-Scraper, und die Skalierung verlangt robuste Hardware oder Cloud-Orchestrierung.
7. Wget: Am besten für schnelle Downloads per Kommandozeile

Wget ist das klassische Kommandozeilen-Tool, um statische Websites und Dateien herunterzuladen.
Warum Wget?
- Einfachheit: ganze Websites oder Verzeichnisse mit einem einzigen Befehl herunterladen – ohne eine Zeile Code.
- Geschwindigkeit: in C geschrieben und damit schnell und sparsam.
- Ideal für statische Inhalte: perfekt für Dokumentationsseiten, Blogs oder Massendownloads von Dateien (HuggingFace Guide).
Einschränkungen: keine JavaScript-Ausführung, keine Formularverarbeitung; außerdem landen rohe Seiten statt strukturierter Daten bei Ihnen. Man kann es sich als digitalen Staubsauger für statische Websites vorstellen.
8. HTTrack: Am besten für Offline-Browsing (No-Code)
HTTrack ist sozusagen der freundliche Cousin von Wget und bringt eine grafische Oberfläche zum Spiegeln von Websites mit.
Warum HTTrack?
- GUI-Einfachheit: Ein Schritt-für-Schritt-Assistent macht das Tool auch für nicht technische Nutzer zugänglich.
- Offline-Browsing: passt Links so an, dass Sie gespiegelte Websites lokal durchstöbern können.
- Ideal zum Archivieren: perfekt für Forschende, Marketer oder alle, die einen Website-Snapshot ganz ohne Code wollen (Reddit DataHoarder).
Einschränkungen: keine Unterstützung für dynamische Inhalte, bei großen Websites mitunter träge und nicht für die Extraktion strukturierter Daten gedacht.
9. StormCrawler: Am besten für verteiltes Crawling in Echtzeit

StormCrawler ist der moderne, verteilte Crawler für Teams, die Webdaten in Echtzeit und in großem Maßstab fortlaufend verarbeiten müssen.
Warum StormCrawler?
- Crawling in Echtzeit: Auf Apache Storm aufgesetzt, verarbeitet es Daten als Streams – ideal für News-Monitoring oder Suchmaschinen (Wikipedia).
- Modular & skalierbar: Ergänzen Sie Parsing-, Indexierungs- und eigene Verarbeitungs-Bolts ganz nach Bedarf.
- Im Einsatz bei Common Crawl: treibt den News-Datensatz eines der größten offenen Webarchive an.
Einschränkungen: setzt Java-Entwicklung und einen Storm-Cluster voraus und passt deshalb am besten zu Teams mit Erfahrung in verteilten Systemen. Für kleine Projekte überdimensioniert.
Open-Source-Alternativen zu Firecrawl im Vergleich: Welche kostenlose Alternative passt zu Ihren Anforderungen?
Hier der direkte Vergleich aller 9 Tools:
| Tool | Bester Anwendungsfall | Wichtigste Vorteile | Nachteile | Sprache / Einrichtung |
|---|---|---|---|---|
| Scrapy | Groß angelegtes, häufiges Crawling | Leistungsstark, skalierbar, große Community | Steile Lernkurve, Python erforderlich | Python-Framework |
| Apache Nutch | Enterprise-, Web-Scale-Crawling | Hadoop-gestützt, im großen Maßstab bewährt | Komplexe Einrichtung, batch-orientiert | Java/Hadoop |
| Heritrix | Archivierungs- und Compliance-Crawling | Vollständige Website-Erfassung, WARC-Ausgabe | Schwergewichtig, kein JS, rohe Archive | Java-App, Web-UI |
| Colly | Go-Entwickler, High-Performance-Scraping | Schnell, einfache API, parallelisierbar | Kein JS, Go erforderlich | Go-Bibliothek |
| MechanicalSoup | Formularautomatisierung, Login-Scraping | Leichtgewichtig, Sitzungsverwaltung | Kein JS, begrenzte Skalierung | Python-Bibliothek |
| Puppeteer | Dynamische / JS-lastige Websites | Volle Browserkontrolle, Automatisierung | Ressourcenintensiv, Node.js erforderlich | Node.js-Bibliothek |
| Wget | Statischer Website-Download, Offline-Zugriff | Einfach, schnell, CLI | Kein JS, rohe Seiten | Kommandozeilen-Tool |
| HTTrack | Nicht-technische Nutzer, Website-Archivierung | GUI, einfaches Offline-Browsing | Kein JS, langsam bei großen Websites | Desktop-App (GUI) |
| StormCrawler | Verteiltes Crawling in Echtzeit | Skalierbar, modular, in Echtzeit | Java-/Storm-Expertise nötig | Java-/Storm-Cluster |
Sollten Sie Ihren eigenen Crawler bauen oder eine bestehende Open-Source-Alternative zu Firecrawl nutzen?
Ehrlich gesagt: Einen eigenen Crawler zu bauen klingt erst einmal reizvoll – bis Sie knietief in Wartung, Proxys und Anti-Bot-Problemen stecken. Die Open-Source-Tools von oben bündeln dagegen jahrelange Erfahrung und das Wissen ganzer Communitys. Branchenberichte sind sich einig: Auf bestehende Lösungen zu setzen ist der schnellste und verlässlichste Weg zu Ergebnissen und erspart Ihnen, das Rad neu zu erfinden (IveerData).
- Setzen Sie auf Open Source, wenn: Ihre Anforderungen zu dem passen, was es schon gibt, Sie Entwicklungszeit sparen wollen und Ihnen Community-Support wichtig ist.
- Bauen Sie selbst, wenn: Sie wirklich einzigartige Anforderungen haben, über tiefes internes Know-how verfügen und Scraping zum Kern Ihres Geschäfts gehört.
Wirklich „kostenlos“ ist Open Source allerdings nicht, sobald man Engineering-Zeit, Serverwartung und die laufenden Updates zur Umgehung von Anti-Scraping-Maßnahmen einrechnet. Wer die Vorzüge eines leistungsstarken Crawlers ohne Code haben möchte, hat noch eine weitere Option.
Bonus: Wenn Open Source zu komplex ist, probieren Sie Thunderbit
Die genannten Tools sind für Entwickler eine feine Sache, stoßen aber alle an ähnliche Grenzen: Sie verlangen Programmierkenntnisse, tun sich mit dynamischen KI-basierten Anti-Bots schwer und müssen ständig nachgepflegt werden.
Thunderbit ist meine erste Empfehlung für alle, die genau diese Grenzen hinter sich lassen wollen. Es verbindet leistungsstarkes Scraping mit einfacher Bedienung.
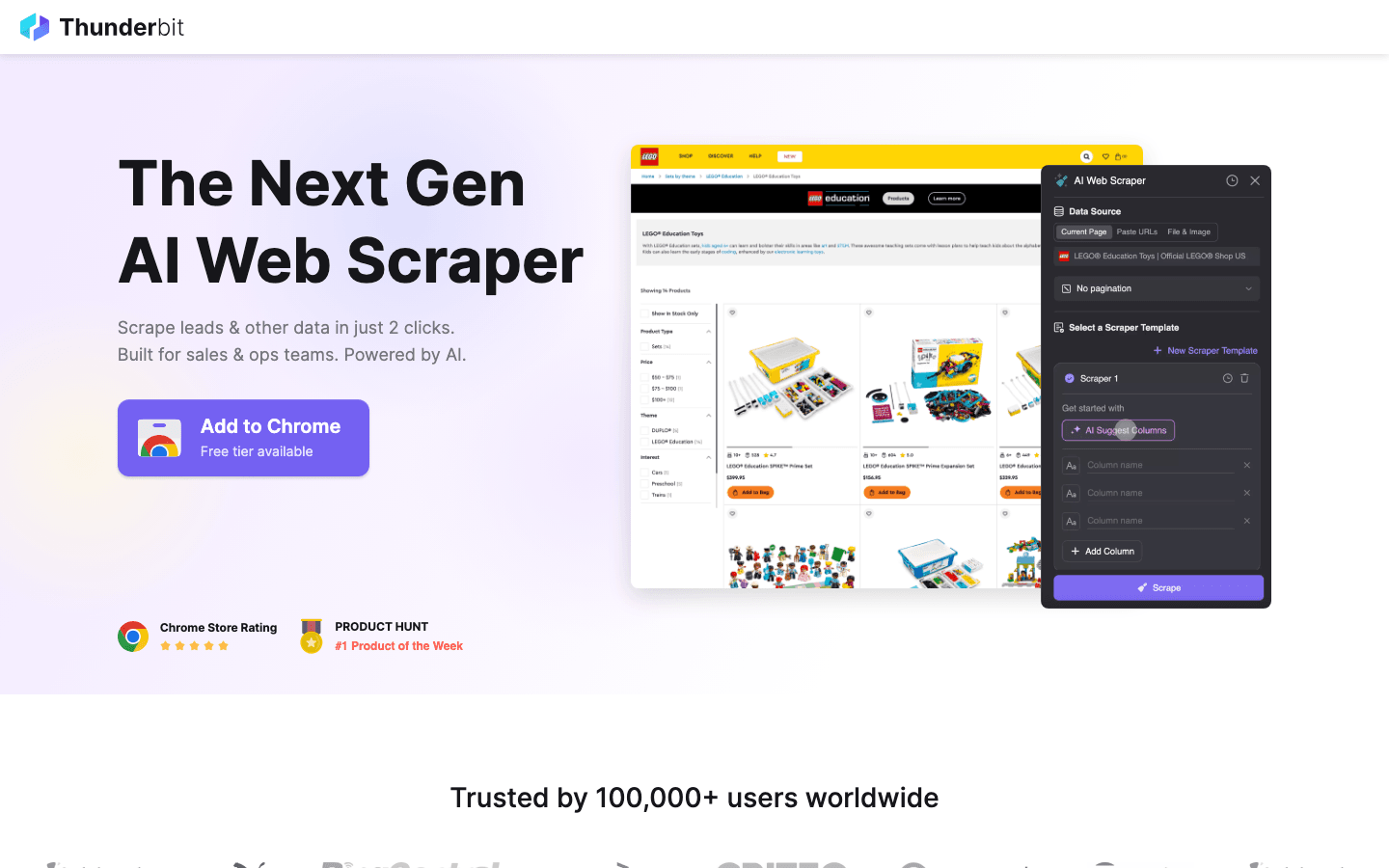
Warum Thunderbit statt Open Source in Betracht ziehen?
- Kein Code erforderlich: Anders als Scrapy oder Puppeteer ist Thunderbit eine KI-gestützte Chrome-Erweiterung. Ein Klick auf „AI Suggest Fields“, und der Scraper baut sich für Sie zusammen.
- Meistert die kniffligen Fälle: Dynamische Inhalte, unendliches Scrollen und Pagination übernimmt die KI automatisch – das spart Ihnen Stunden eigener Script-Arbeit.
- Sofortiger Export: in zwei Klicks von der Website nach Excel, Google Sheets oder Notion.
- Keine Wartung: Ändert eine Website ihr Layout, müssen Sie keinen Code anfassen – Thunderbits KI stellt sich für Sie darauf ein.
Wenn Sie im Vertrieb, Marketing oder in der Recherche arbeiten und Daten sofort brauchen, ohne erst Python oder Go zu lernen, ist Thunderbit die perfekte Ergänzung zu den Open-Source-Tools auf dieser Liste.
Sie wollen es in Aktion sehen? Laden Sie die Chrome-Erweiterung herunter und probieren Sie es selbst aus.
Thunderbit AI Web Scraper ausprobieren
Fazit: Der richtige selbst gehostete Web-Crawler für 2026
Mehr Web-Scraping-Anleitungen lesen Get Started Free
Die Welt der Open-Source-Alternativen zu Firecrawl ist so reichhaltig wie nie. Ob Sie die rohe Skalierung von Scrapy oder Nutch oder die Archivierungstreue von Heritrix brauchen – für jedes Unternehmensszenario gibt es das passende Werkzeug. Worauf es ankommt: das Tool dem Bedarf anpassen. Überfrachten Sie die Architektur nicht, wenn Sie nur schnell Daten brauchen, und sparen Sie nicht an der falschen Stelle, wenn Sie im Internet-Maßstab crawlen.
Und vergessen Sie nicht: Wird der Open-Source-Weg zu technisch oder zu zeitraubend, springen KI-Tools wie Thunderbit in die Bresche.
Bereit für den Start? Bringen Sie Scrapy für Ihr nächstes großes Datenprojekt an den Start oder probieren Sie Thunderbit für einfaches, KI-gestütztes Scraping. Wer mehr Tipps rund ums Web Scraping sucht, findet im Thunderbit-Blog Deep Dives und Tutorials.
Thunderbit für KI-gestütztes Web Scraping ausprobieren
FAQs
1. Was ist der Hauptvorteil von Open-Source-Alternativen zu Firecrawl?
Open-Source-Alternativen punkten mit Flexibilität, Kostenvorteilen und der Möglichkeit, den Crawler selbst zu hosten und individuell anzupassen. Sie umgehen den Vendor Lock-in und profitieren von aktiver Community-Unterstützung und regelmäßigen Updates.
2. Welches Tool eignet sich für nicht technische Nutzer mit schnellem Ergebnisbedarf am besten?
HTTrack ist eine solide Open-Source-Wahl fürs Offline-Browsing. Geht es um die Extraktion strukturierter Daten (etwa als Excel-Tabelle), empfehlen wir allerdings das Bonus-Tool Thunderbit wegen seiner KI-Funktionen.
3. Wie gehe ich mit dynamischen, JavaScript-lastigen Websites um?
Puppeteer ist hier die beste Wahl – es steuert einen echten Browser und scrapt deshalb alles, was ein Nutzer zu sehen bekommt, einschließlich SPAs und per AJAX geladener Inhalte.
4. Wann sollte ich einen Schwergewichts-Crawler wie Apache Nutch oder StormCrawler einsetzen?
Wenn Sie Millionen von Seiten über viele Domains crawlen müssen oder verteiltes Crawling in Echtzeit brauchen – etwa für Suchmaschinen oder News-Monitoring – sind diese Tools auf Skalierung und Zuverlässigkeit ausgelegt.
5. Ist es besser, einen eigenen Crawler zu bauen oder eine bestehende Open-Source-Lösung zu nutzen?
Für die meisten Teams ist es schneller, günstiger und zuverlässiger, ein bestehendes Open-Source-Tool zu nutzen und anzupassen. Bauen Sie nur dann selbst, wenn Sie hochspezialisierte Anforderungen haben und die Mittel, das Ganze langfristig zu pflegen.
Viel Erfolg beim Crawlen – und mögen Ihre Daten stets frisch, strukturiert und einsatzbereit sein.
Thunderbit AI Web Scraper kostenlos ausprobieren Get Started Free
Mehr erfahren




