Die meisten Online-Artikel mit dem Titel „octoparse review“ sind, freundlich gesagt, nicht gerade vertrauenswürdig. Mehrere Nutzer auf Reddit und Trustpilot berichten, dass Octoparse sie aktiv um bezahlte 5-Sterne-Bewertungen gebeten habe — und wenn man das einmal weiß, wirken viele Lobeshymnen plötzlich in einem ganz anderen Licht. Ich arbeite bei Thunderbit, also habe ich natürlich ein eigenes Interesse an dem Thema. Gleichzeitig beschäftige ich mich beruflich sehr intensiv mit Recherche, Tests und dem Vergleich von Web-Scraping-Tools — nicht nur mit unserem eigenen, sondern mit dem gesamten Markt. Für diesen Test habe ich Bewertungen von G2, Capterra und Trustpilot zusammengetragen, echte Nutzerbeschwerden aus Reddit und Foren abgeglichen und Octoparse selbst unabhängig getestet. Das Ziel: dir eine ehrliche, konkrete Einschätzung zu geben, wo Octoparse überzeugt, wo es scheitert, was es tatsächlich kostet und wann du mit einer anderen Lösung besser fährst. Ganz egal, ob du im Vertrieb, E-Commerce oder Marketing arbeitest oder einfach nur Daten aus dem Web ziehen willst, ohne Python zu schreiben — das ist genau der Test, den ich mir selbst gewünscht hätte, als ich mit der Recherche angefangen habe.
Was ist Octoparse? Ein kurzer Überblick für Business-Anwender
Octoparse ist ein Desktop-basiertes No-Code-Tool für Web Scraping. Du installierst es unter Windows oder macOS, öffnest darin eine Website und legst mit einem visuellen Klick-und-Zieh-Workflow fest, welche Daten extrahiert werden sollen. Programmieren musst du dafür nicht — zumindest ist das die Zusage.
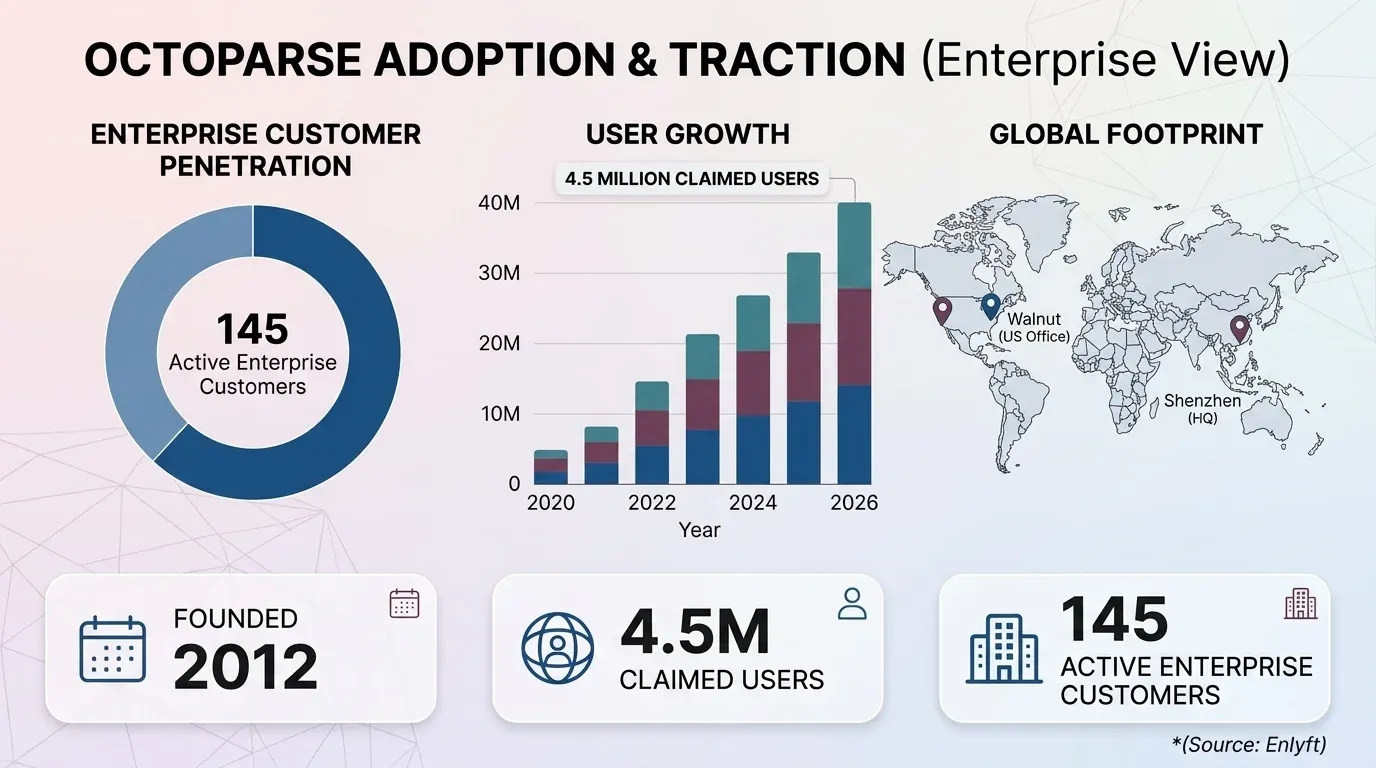
Technisch erstellt Octoparse anhand deiner Klicks XPath-Selektoren und führt diese entweder lokal auf deinem Rechner oder in der Cloud auf den Servern von Octoparse aus. Exportiert werden Daten nach Excel, CSV, JSON und in Datenbanken wie MySQL, SQL Server und PostgreSQL; in kostenpflichtigen Tarifen außerdem nach Google Sheets, Dropbox und S3. Das Unternehmen Octopus Data Inc. wurde und hat seinen Sitz in Shenzhen, China, mit einem US-Büro in Walnut, Kalifornien. Octoparse gibt weltweit an, während unabhängige Tracker wie Enlyft die Zahl aktiver Unternehmenskunden eher bei rund 145 sehen.
Die Zielgruppe: Marktforscher, E-Commerce-Teams, Lead-Gen-Profis und alle, die strukturierte Webdaten ohne Code brauchen. Die aktuelle Version ist 8.9.0 (März 2026).
Das ist die Kurzfassung. Die eigentliche Frage ist: Hält das Tool, was es verspricht?
Kann man Octoparse-Bewertungen trauen? Das Problem mit incentivierten Reviews
Bevor ich zu Funktionen und Schwachstellen komme, solltest du etwas über die Bewertungslandschaft von Octoparse wissen: Sie ist nicht gerade sauber.
Ein Trustpilot-Rezensent schilderte, dass er direkt von Octoparse angesprochen wurde:
„Wären Sie an diesem Angebot interessiert? [zusätzliche 15 Tage auf Ihrem Basic-Tarif für eine 5-Sterne-Trustpilot-Bewertung]. Ich fand es ziemlich beleidigend, dass sie versuchen, ihren Trustpilot-Score so zu manipulieren. Ein seriöses Unternehmen mit einem guten Produkt müsste so etwas nicht tun.“
Das verstößt gegen die eigenen Regeln von Trustpilot. Auf Capterra sind viele Bewertungen offen als „Incentivized review“ gekennzeichnet — der Anbieter hat den Nutzer also eingeladen, im Gegenzug für eine kleine Gegenleistung eine Bewertung abzugeben. Das ist laut Capterra zwar erlaubt, treibt die Bewertung aber erwartbar nach oben. Mir fiel auf, dass auf Seite 2 der Capterra-Bewertungen angezeigt wurden — also eine 92%-Fünf-Sterne-Quote —, dazu Rezensionen, die innerhalb weniger Tage veröffentlicht wurden und sprachlich sehr kurz und schematisch wirken.
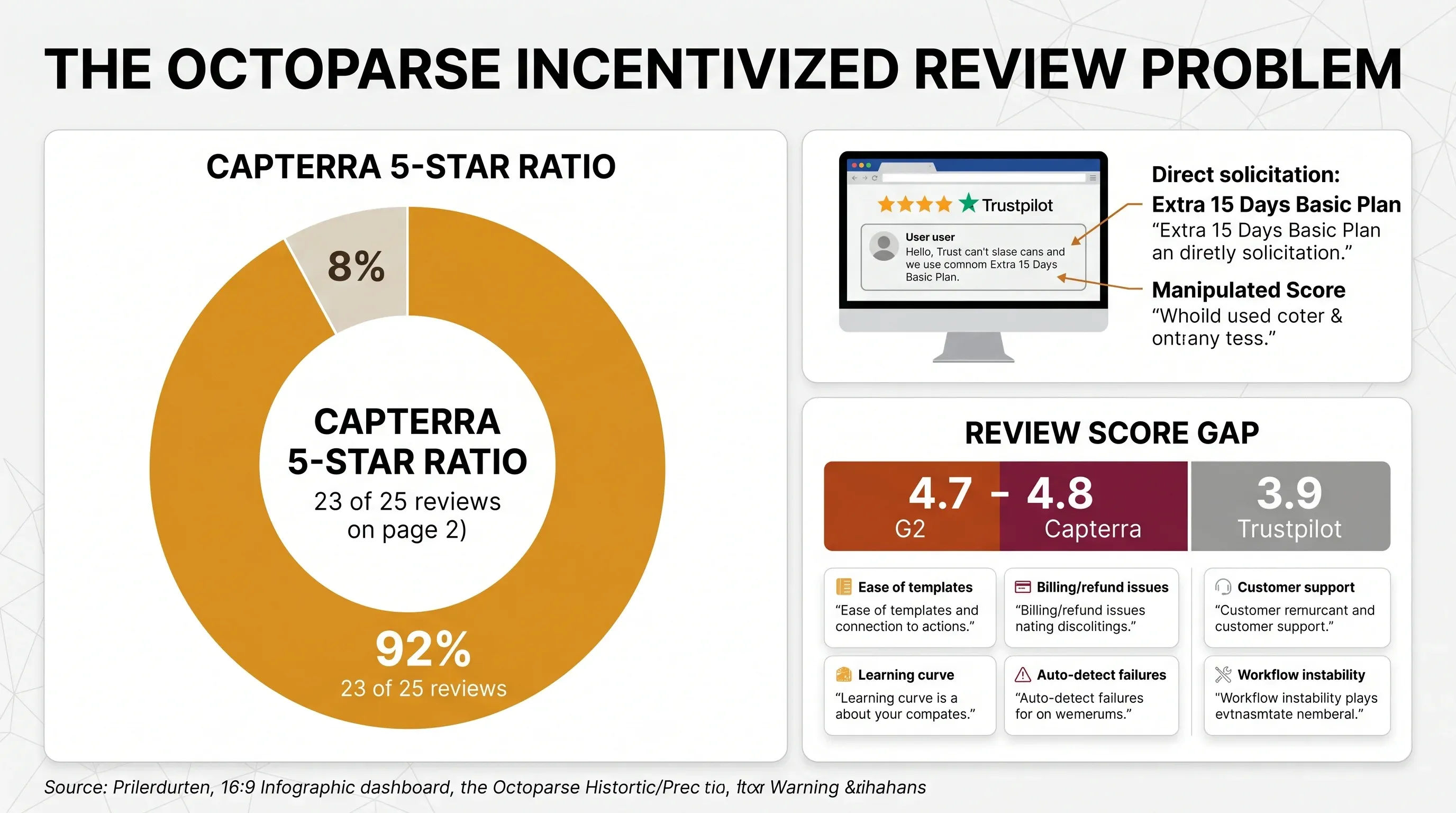
Das Ergebnis: Zwischen den kuratierten Plattformen und der Plattform, auf der incentivierte Bewertungen markiert werden, klafft fast ein ganzer Notenpunkt.
| Bewertungsplattform | Score | Anzahl Bewertungen | Hauptsächliches Lob | Hauptkritik |
|---|---|---|---|---|
| G2 | 4,7–4,8/5 | 40–52 | Einfache Vorlagen | Instabile Workflows |
| Capterra | 4,7/5 | 106 | Cloud-Extraktion | Probleme mit Abrechnung/Erstattung |
| Trustpilot | 3,9/5 | ~91 | Kundenservice | Fehler bei Auto-Detect, Streit um Rückerstattungen |
| TrustRadius | 7,0/10 | 13 | Funktionsumfang | Einarbeitungsaufwand |
Beispiel für eine positive Bewertung (G2):
„Vorher habe ich Web Scraping ehrlich gesagt vermieden, weil ich keine Lösung finden konnte, für die man keine technischen Skills oder Programmierkenntnisse braucht. Aber mit Octoparse wirkte es machbar.“
Beispiel für eine negative Bewertung (Trustpilot):
„Verdient null Sterne. Probieren Sie mal, dieses kostenlose Konto zu kündigen. Viel Glück. Die angegebenen Anweisungen sind falsch — die Funktion zum Kündigen existiert nicht.“
Ich behaupte nicht, dass jede positive Bewertung gefälscht ist. Aber wenn du Octoparse-Bewertungen anderswo liest, solltest du prüfen, ob sie incentiviert waren — und die ungefilterten Trustpilot-Werte stärker gewichten.
Octoparse-Test: Was wirklich gut funktioniert (die guten Seiten)
Fairness halber: Octoparse ist kein Scam, sondern ein echtes Produkt mit echten Stärken. Das kann es gut.
Visueller Workflow-Builder
Das Herzstück von Octoparse ist die Klick-Oberfläche. Du lädst eine URL im integrierten Browser, klickst auf die gewünschten Daten und Octoparse erzeugt automatisch XPath-Selektoren. Der Workflow-Editor zeigt einen Ablauf als Flussdiagramm: Seite öffnen → Schleife → Extrahieren → Paginieren. Für Menschen, die noch nie eine Zeile Code geschrieben haben, ist das ein echter Fortschritt gegenüber Python-Skripten.
Nach meiner Erfahrung lassen sich einfache Scrapes auf einer einzelnen Seite, etwa Tabellen mit Produktnamen und Preisen, in unter 10 Minuten einrichten. Die integrierte Browseransicht macht die Auswahl von Elementen angenehm intuitiv — anklicken, markieren lassen, bestätigen.
Vorgefertigte Aufgabenvorlagen
Octoparse bietet eine Bibliothek mit für bekannte Websites: Amazon, eBay, Google Maps, LinkedIn, Twitter/X, Indeed, Zillow, Yelp und viele mehr. Die Vorlagen sind bereits vorkonfiguriert — man muss also keine Selektoren manuell anlegen. Für wiederkehrende Standardaufgaben auf bekannten Seiten spart das tatsächlich Zeit.
Einige Vorlagen sind mit kostenpflichtigen Tarifen nutzbar; Premium-Vorlagen werden nach Ergebnissen abgerechnet, mit .
Cloud-Extraktion und Zeitplanung
Mit den kostenpflichtigen Tarifen kannst du Aufgaben auf den Cloud-Servern von Octoparse ausführen und deinen eigenen Rechner schonen. Zeitpläne lassen sich stündlich, täglich, wöchentlich oder individuell einrichten. Für Teams, die regelmäßig unbeaufsichtigte Scrapes brauchen — etwa zur täglichen Preisüberwachung — ist das ein echter Vorteil. Die Cloud-Kapazität reicht von 3–6 Knoten (Standard) über 20 (Professional) bis zu 40+ (Enterprise).
Exportmöglichkeiten
Octoparse unterstützt Export nach Excel, CSV, JSON, HTML, XML sowie direkte Datenbankanbindungen (MySQL, SQL Server, PostgreSQL, Oracle). Google Sheets, Google Drive, Dropbox und S3 gibt es ab Professional. Der API-Zugriff beginnt ab Standard. Für die meisten Business-Workflows reicht das aus.
Octoparse-Test: Wo das Tool tatsächlich an seine Grenzen stößt (die schlechten Seiten)
Jetzt kommen die Punkte, die dir keine incentivierte Bewertung sagen wird. Ich habe die konkreten, reproduzierbaren Fehlerbilder gesammelt, die reale Nutzer erleben — keine vagen „Nachteile“, sondern belegbare Situationen aus Foren und Nutzerberichten.
Cloudflare- und Anti-Bot-Sperren
Das ist mit Abstand die häufigste schwerwiegende Beschwerde. auf Reddit, Capterra und Trustpilot beschreiben, dass Octoparse an Cloudflare und anderen Anti-Bot-Schutzmechanismen scheitert.
Das typische Szenario: Du richtest einen Workflow für eine Cloudflare-geschützte Website ein. Du klickst auf „Run“. Ergebnis: leere Daten oder eine Fehlerseite. Octoparse hat ab Version 8.7.2 eine Option „Bypass Cloudflare with credit“ eingeführt, aber die kostet — und fehlgeschlagene Versuche verbrauchen trotzdem Credits.
„Sie konnten mein geschäftliches Problem nicht lösen. Ich wollte eine bestimmte Website parsen/scrapen, und der Octoparse-Dienst kam nicht an der Cloudflare-Anti-Bot-Technologie vorbei.“ — Jason K., CTO, Computer Software,
Unabhängige Tests sehen Erfolgsraten von unter 60 % auf modernen Plattformen wie LinkedIn. Für Google Maps Scraping sind Residential Proxies nötig, weil Google Rechenzentrums-IPs aggressiv blockiert.
Zum Vergleich: Thunderbit geht hier anders vor. Im Cloud-Scraping-Modus nutzen wir integrierte IP-Rotation, und der Browser-Scraping-Modus läuft direkt in deiner eigenen Chrome-Sitzung (die Website sieht also dein echtes Login und deine Cookies, nicht einen Bot aus dem Rechenzentrum).
Auto-Detect übersieht relevante Daten
Die Auto-Detect-Funktion von Octoparse soll eine Seite scannen und die passenden Datenfelder automatisch erkennen. In der Praxis zeigte unabhängiges Testen nur auf 43 % der Websites konsistente Ergebnisse, bei JavaScript-lastigen oder dynamischen Inhalten lag die Trefferquote bei lediglich 45 %. Etwa 15 % der extrahierten Daten mussten manuell bereinigt werden.
Das typische Szenario: Du verwendest Auto-Detect auf einer Produktliste. Das Tool erkennt den Produktnamen, übersieht aber den Preis — oder es zieht irrelevante Inhalte aus der Seitenleiste statt aus dem Hauptbereich. Am Ende musst du XPath-Selektoren doch wieder manuell anpassen, was das ganze „No-Code“-Versprechen ad absurdum führt.
Schleifen und Pagination brechen ohne klare Fehlermeldung ab
Octoparse hat allein zu Pagination- und Scroll-Problemen. Einer davon trägt sogar den Titel „Pagination Loop issue — The extraction stops after 3 pages.“
Das typische Szenario: Du scrapest einen Shopify-Store mit Infinite Scroll. Der Workflow bleibt nach drei Seiten hängen, weil der Scroll-Trigger nicht richtig ausgelöst wird. Es erscheint keine eindeutige Fehlermeldung — die Aufgabe liefert einfach keine Daten mehr. Nutzer müssen die Logik dann manuell debuggen, den Scroll-Timing-Wert anpassen, den XPath für die „Next“-Schaltfläche ändern oder zwischen Variable List und Fixed List wechseln.
„Der automatisch generierte Pagination-XPath funktioniert möglicherweise nicht immer zuverlässig.“ — Octoparse Help Center
Workflows brechen bei Layout-Änderungen der Website
Da Octoparse mit festen XPath-/CSS-Selektoren arbeitet, kann schon eine kleine Änderung im Frontend der Zielseite den kompletten Workflow zerstören — oft still und ohne Warnung, sodass einfach nur leere Datensätze entstehen.
„Octoparse nutzt größtenteils child/child/child-XPath-Pfade. Mir erscheint das weniger robust als Positionen mit spezifischen Attributen.“ — F.S., CEO, Retail,
„Jedes Mal, wenn Wettbewerber ihre Websites aktualisiert haben, sind unsere Workflows kaputtgegangen.“ — E-Commerce-Betreiber,
Unabhängige Tests zeigen, dass 73 % der Scraper-Fehler darauf zurückgehen, dass Selektoren nach Website-Updates nicht mehr funktionieren. Branchenzahlen belegen ebenfalls: Klassische Scraping-Tools müssen ständig gewartet werden, weil Skripte schon nach wenigen Wochen durch Änderungen auf den Seiten brechen.
Hier haben KI-gestützte Tools wie Thunderbit einen strukturellen Vorteil: Unsere KI liest die Seite bei jedem Lauf neu ein, sodass keine fragilen Selektoren repariert werden müssen, wenn sich das Layout ändert.
Die Lernkurve ist steiler als versprochen
Trotz des Marketings als „No-Code“-Lösung braucht Octoparse etwa 15–20 Stunden bis zur grundlegenden Sicherheit und 40–60 Stunden, um komplexere Workflows zu erstellen. Für mehrstufige Workflows (Listen-Seite → Detailseite, Logins, AJAX-Inhalte) musst du bei Problemen mit Auto-Detect weiterhin HTML-Struktur, XPath und Regex verstehen.
„Trotz der sehr intuitiven Oberfläche braucht man mehrere Stunden Trial and Error, bevor man das Tool wirklich beherrscht.“ — Juan Carlos R., Director of Master's Degree Programs,
| Fehlermodus | Schweregrad | Foren-Erwähnungen | Wichtigste Kennzahl |
|---|---|---|---|
| Lernkurve / Komplexität | MITTEL | ~20–25 | 15–20 Std. bis zur Grundsicherheit |
| Anti-Bot-/Cloudflare-Blockade | HOCH | ~15–20 | <60 % Erfolgsquote auf modernen Plattformen |
| Pagination / Infinite Scroll | MITTEL-HOCH | ~12–18 | 7+ eigene Hilfsartikel |
| Auto-Detect-Fehler | MITTEL-HOCH | ~10–15 | 43 % konsistente Erfolgsrate |
| Fehler bei Cloud-Extraktion | MITTEL-HOCH | ~10–15 | 5+ Hilfsartikel zu diesem Thema |
| Abrechnungs-/Kündigungsprobleme | MITTEL | ~10–12 | Trustpilot 3,9 vs. G2/Capterra 4,7 Abstand |
| Workflow-/XPath-Ausfälle | MITTEL | ~8–12 | 73 % der Fehler durch defekte Selektoren |
Die wahren Kosten von Octoparse: Versteckte Ausgaben jenseits der Preisseite
Die meisten Reviews zeigen einfach nur einen Screenshot der Preisseite. Die tatsächlichen Kosten von Octoparse liegen deutlich höher — und sind schwerer vorherzusagen.
Basispreise der Tarife
Auf der eigenen Website nennt Octoparse auf verschiedenen Seiten unterschiedliche Preise (das Help Center sagt das eine, die Preisseite das andere). Die am häufigsten zitierten Werte sind:
| Tarif | Monatlich | Jährlich (pro Monat) | Aufgaben | Cloud-Knoten | Export-Limit |
|---|---|---|---|---|---|
| Free | 0 $ | 0 $ | 10 | Keine | 50.000 Zeilen/Monat, 10.000/Export |
| Standard | 119 $ | ca. 100 $ | 100 | 3–6 | Unbegrenzt |
| Professional | 199 $ | ca. 151 $ | 250 | 20 | Unbegrenzt |
| Enterprise | Individuell (600–1.000 $+) | Individuell | 750+ | 40+ | Unbegrenzt |
Der kostenlose Tarif ist nur lokal nutzbar, ohne Cloud, ohne Zeitplanung und ohne Vorlagen. Für echten geschäftlichen Einsatz solltest du mindestens mit 119 US-Dollar pro Monat rechnen.
Versteckte Zusatzkosten
Hier kommt der eigentliche Preisschock.
| Zusatzleistung | Kosten | Wichtige Hinweise | |---|---|---|---| | Residential Proxies | 3 $ pro GB | Für Seiten mit Anti-Bot-Schutz erforderlich | | CAPTCHA-Lösung (Cloudflare) | 1,50 $ pro 1.000 | Fehlversuche verbrauchen trotzdem Credits | | CAPTCHA-Lösung (andere) | 0,80 $ pro 1.000 | Fehlversuche verbrauchen trotzdem Credits | | Vorlagen mit Pay-per-Result | 0,001–3 $ pro 1.000 Ergebnisse | Premium-Vorlagen nicht im Basistarif enthalten | | Individuelle Crawler-Einrichtung | ab 399 $ (einmalig) | Das Octoparse-Team baut deinen Scraper | | Data Service | ab 599 $ (einmalig) | Vollservice für die Datenlieferung |
Der Punkt mit den CAPTCHA-Credits ist besonders wichtig: In der eigenen Dokumentation bestätigt Octoparse ausdrücklich, dass Wenn es drei Anläufe braucht, um ein CAPTCHA zu lösen, zahlst du für alle drei.
Unabhängige Analysen schätzen, dass Zusatzkosten die Basisrechnung um 40–60 % erhöhen. Eine realistische Monatsrechnung für ein Team mit ernsthaftem Scraping liegt selbst im Standard-Tarif eher bei 200 bis 400 US-Dollar.
Credit-Verbrauch und doppelte Daten
Octoparse und erklärt es auch im eigenen Help Center. Wenn du dieselbe Aufgabe mehrfach ausführst, sammeln sich Duplikate an, weil Octoparse die Ergebnisse aller Läufe gemeinsam speichert, ohne automatisch zu deduplizieren. Credits und Bandbreite werden selbst dann verbraucht, wenn die Seiten keine verwertbaren Daten liefern.
Streitfälle um Rückerstattung und Kündigung
Das ist der Punkt, der den Abstand zwischen Trustpilot und Capterra erklärt. beschreiben, dass nach einer Kündigung trotzdem abgebucht wurde oder Erstattungsanträge abgelehnt wurden.
„Mir wurden 119 $ berechnet, obwohl ich es nur einmal ausprobiert habe und es nicht funktioniert hat, und das Unternehmen hat sich geweigert, zu erstatten.“ — Trustpilot-Rezensent
„Achtung: Eine Kündigung über die Website bedeutet nicht immer, dass wirklich gekündigt wurde. Am Ende wird trotzdem abgebucht und dann will man den ersten Monat nicht zurückerstatten!“ — Trustpilot-Rezensent
Auch das 5-Tage-Rückerstattungsfenster wurde unabhängig kritisiert: „Ein 5-Tage-Testfenster für ein Scraping-Tool, das erst noch konfiguriert werden muss … ist keine Rückerstattungsregel. Es ist eine Formalität.“
Vergleich der Gesamtkosten
Hier ist die Tabelle, die du in keinem anderen Octoparse-Test findest:
| Kostenfaktor | Octoparse Standard | Octoparse Professional | Thunderbit Free | Thunderbit Pro |
|---|---|---|---|---|
| Monatlicher Grundpreis | 119 $ | 199 $ | 0 $ | 9 $/Monat (jährlich) / 15 $/Monat |
| Integrierte Proxy-/IP-Rotation | ❌ (Zusatz, 3 $/GB) | ❌ (Zusatz, 3 $/GB) | ✅ (Cloud-Scraping) | ✅ |
| CAPTCHA-Behandlung | ❌ (Zusatz, 0,80–1,50 $/1K) | ❌ (Zusatz) | ✅ (integriert) | ✅ |
| Datenexport (Excel, Sheets usw.) | Inklusive | Inklusive | ✅ Kostenlos | ✅ Kostenlos |
| Rückerstattungsregel | ⚠️ 5-Tage-Fenster, umstritten | ⚠️ 5-Tage-Fenster, umstritten | — | — |
Octoparse im Vergleich zu Alternativen: Ein ehrlicher Vergleich Seite an Seite
Jeder Konkurrenz-„Octoparse Review“ vergleicht das Tool genau mit einer Alternative — meist mit dem eigenen Produkt. Hier ist der mehrdimensionale Vergleich, der dir wirklich bei der Entscheidung hilft.
| Kriterium | Octoparse | ParseHub | Apify | Bright Data | Thunderbit |
|---|---|---|---|---|---|
| Einrichtungsaufwand | Mittel (visueller Workflow-Builder) | Mittel (visuell) | Hoch (Actors/Code) | Hoch (entwicklerorientiert) | Niedrig (2-Klick-KI) |
| KI-gestützte Extraktion | ❌ Regelbasiert | ❌ Regelbasiert | Teilweise (Actors) | ❌ | ✅ KI schlägt Felder vor |
| Reagiert auf Layout-Änderungen | ❌ Manuelles Neuaufsetzen | ❌ Manuelles Neuaufsetzen | Unterschiedlich | ❌ | ✅ KI liest die Seite neu ein |
| Cloud-Scraping-Geschwindigkeit | Mittel | Langsam | Schnell | Schnell | Schnell (50 Seiten parallel) |
| Anti-Bot/Cloudflare | ⚠️ Proxy-Zusatz | ⚠️ Eingeschränkt | ✅ Proxy integriert | ✅ Fortgeschritten | ✅ Cloud- und Browser-Modus |
| Nutzen des Gratis-Tarifs | Begrenzt (10 Aufgaben, nur lokal) | 14-Tage-Testversion | 5 $ kostenlos/Monat | Kein Gratis-Tarif | 6 Seiten gratis |
| Am besten für | Wiederkehrende Scrapes im mittleren Umfang | Einfache Einmal-Scrapes | Entwickler / Automatisierung | Enterprise-Datenpipelines | Business-Anwender / schnelle Extraktion |
Octoparse vs. ParseHub
Beide sind visuelle No-Code-Scraper mit ähnlicher Oberfläche. ParseHub läuft auf einer vollständigen Chromium-Engine, wodurch JavaScript-gerenderte Inhalte (React, Angular, Vue) zuverlässiger verarbeitet werden. Außerdem ist bei kostenpflichtigen Tarifen IP-Rotation enthalten — kein Zusatzposten mit 3 $/GB.
Der Haken: ParseHub ist beim Einstieg etwa 2,5-mal teurer (189 $/Monat statt ca. 119 $), bietet keine vorgefertigten Vorlagen (gegenüber Octoparse mit über 469) und hat eine sehr kleine Bewertungsbasis (16 Capterra-Bewertungen gegenüber 106). Ein Nutzer schrieb, dass es „den ganzen CPU- und RAM-Speicher frisst (16 GB)“.
Beide Tools verwenden keine KI für die Extraktion — beide sind regelbasiert und brechen, wenn sich Layouts ändern.
Octoparse vs. Apify
Apify ist grundsätzlich ein anderes Produkt. Es richtet sich an Entwickler, basiert auf „Actors“ (vorgefertigte oder eigene Code-Module) und bietet über 6.000 Actors im Marktplatz. Es ist vollständig cloudbasiert — keine Desktop-App nötig — und unterstützt eigenen Code in JavaScript und Python.
Apify übertrifft Octoparse in jeder Capterra-Kategorie (Ease of Use: 4,7 vs. 4,4; Functionality: 4,7 vs. 4,5; Value for Money: 4,6 vs. 4,4) bei vierfacher Bewertungsmenge (427 vs. 106). Der Gratis-Tarif enthält 5 US-Dollar Plattform-Guthaben pro Monat mit vollem Cloud-Zugriff — deutlich nützlicher als Octoparse im lokalen Free-Tarif.
Der Haken: Apify ist nichts für nicht-technische Nutzer. Wenn du keinen Code lesen kannst oder kein Entwickler in deinem Team sitzt, ist es wahrscheinlich nicht die richtige Wahl.
Octoparse vs. Bright Data
Bright Data ist Dateninfrastruktur auf Enterprise-Niveau: über 150 Millionen Residential IPs in 195 Ländern, SOC2-/ISO-27001-Zertifizierungen und mehr als 120 gepflegte Scraper-APIs. Auf G2 erreichte das Unternehmen in der Kategorie Data Collection die perfekte 10,0/10.
Es spielt aber auch preislich in einer anderen Liga. Der sinnvolle Einstieg liegt bei 499 US-Dollar pro Monat (Growth-Tarif) und ist damit 3–5-mal teurer als Octoparse. Für die meisten kleinen Teams ist das schlicht überdimensioniert.
Octoparse vs. Thunderbit
Thunderbit ist das Produkt, das wir bei gebaut haben, um genau die Probleme zu lösen, die ich oben beschrieben habe. Es ist eine KI-gestützte . Du klickst auf „AI Suggest Fields“, die KI liest die Seite aus und schlägt die Spaltenstruktur vor, dann klickst du auf „Scrape“. Zwei Klicks. Fertig.
Die wichtigsten Unterschiede:
- Keine Workflows, die gebaut oder gepflegt werden müssen. Die KI liest die Seite bei jedem Lauf neu ein — keine fragilen Selektoren, die bei Website-Updates brechen.
- Pagination und Unterseiten werden automatisch verarbeitet. Klick-Paginierung und Infinite Scroll funktionieren ohne manuelle Schleifenlogik. Mit dem Ein-Klick-Subpage-Scraping werden Detailseiten direkt in deine Tabelle übernommen.
- Cloud- und Browser-Scraping. Im Cloud-Modus werden öffentliche Seiten parallel verarbeitet, bis zu 50 Seiten gleichzeitig. Der Browser-Modus läuft in deiner Chrome-Sitzung für Seiten mit Login — separate Proxies musst du nicht kaufen.
- Kostenloser Export. Excel, Google Sheets, Airtable, Notion — .
Thunderbit ist für nicht-technische Business-Anwender gemacht, die schnell Daten brauchen, ohne eine Scraping-Infrastruktur zu warten.
Entscheidungsrahmen: Wann Octoparse sinnvoll ist — und wann nicht
In Foren wird nicht nur gefragt: „Ist Octoparse gut?“ — sondern: „Ist Octoparse für MEINE Situation richtig?“ Hier ist die praxisnahe Einordnung, die in vielen Tests fehlt.
Nutze Octoparse, wenn ...
- du geplante Cloud-Extraktionen auf gut strukturierten, stabilen Websites brauchst
- du bereit bist, 15–20+ Stunden in den visuellen Workflow-Builder zu investieren
- du nur einige wenige bekannte Seiten scrapst, für die es Vorlagen gibt (Amazon, Google Maps)
- du die Zusatzkosten realistisch einkalkulierst (bei ernsthaftem Einsatz effektiv ca. 200–400 $/Monat)
Nutze stattdessen Thunderbit, wenn ...
- du ein nicht-technischer Business-Anwender bist (Vertrieb, E-Commerce, Marketing)
- du KI-gestützte Extraktion willst, ohne Workflows zu bauen oder zu pflegen
- du unterschiedliche oder Nischen-Websites scrapst, bei denen sich Layouts von Seite zu Seite unterscheiden
- du Unterseiten mit einem Klick anreichern willst
- du kostenlos nach Excel, Google Sheets, Airtable oder Notion exportieren möchtest
- du Seiten mit Login scrapen musst (Thunderbit Browser-Scraping nutzt deine eigene Sitzung)
Nutze Apify oder Bright Data, wenn ...
- du Entwickler bist oder Entwicklerressourcen im Team hast
- du Enterprise-fähige Proxy-Infrastruktur brauchst
- du mit codebasierter Automatisierung oder Actors arbeiten kannst
- Anti-Bot-Umgehung im großen Maßstab entscheidend ist
Baue dir einen eigenen Scraper, wenn ...
- du Python kannst und volle Kontrolle brauchst
- Leistung wichtig ist (eigene Skripte laufen meist 3–5-mal schneller als No-Code-Tools)
- du regelmäßig nur eine Datenquelle ausliest und maximale Anpassbarkeit willst
Ein Forennutzer brachte es auf den Punkt: „Ich habe mir einfach beigebracht, meinen eigenen Webscraper zu bauen, und meiner ist viel besser.“
Beauftrage einen Freelancer, wenn ...
- du ein einmaliges Projekt mit komplexen Anti-Bot-Anforderungen hast (typisch 500–5.000 $, auf Upwork)
- du keine Zeit hast, ein Tool zu lernen, und schnell Ergebnisse brauchst
Wie Thunderbit Octoparses größte Schwachstellen löst
Das ist kein allgemeiner Werbetext. Jeder Punkt unten entspricht direkt einer oben beschriebenen Schwachstelle.
KI-gestützte Extraktion: Keine Workflows zum Bauen oder Pflegen
Klicke auf „AI Suggest Fields“ und die KI liest die Seite und schlägt Spalten sowie Datentypen vor. Ein Klick auf „Scrape“ — fertig in zwei Klicks. Keine XPath-Selektoren, kein Workflow-Debugging, keine Wartung bei Layout-Änderungen. Wenn du sehen willst, wie das in der Praxis funktioniert, schau dir unseren an.
Automatische Anpassung an Layouts
Thunderbits KI liest die Seite bei jedem Scrape frisch ein. Es gibt keine fragilen Selektoren, die bei Frontend-Updates kaputtgehen. Das ist besonders nützlich für Nischenseiten und Long-Tail-Websites mit ungewöhnlichen Layouts — genau die Fälle, in denen Octoparse mit seinem XPath-Ansatz am häufigsten scheitert.
Integrierte Pagination- und Unterseiten-Extraktion
Thunderbit verarbeitet sowohl Klick-Paginierung als auch Infinite Scroll, ohne dass du Schleifen manuell konfigurieren musst. Mit dem Ein-Klick-Subpage-Scraping besucht die KI jede Detailseite und reichert deine Tabelle automatisch an — ganz ohne Workflow-Logik. Mehr dazu im Vergleich unserer .
Cloud- und Browser-Scraping-Optionen
Beim Cloud-Scraping für öffentliche Seiten werden bis zu 50 Seiten parallel verarbeitet, was Geschwindigkeit bringt. Beim Browser-Scraping für Login-Seiten läuft alles in deiner eigenen Chrome-Sitzung — die Website sieht also deine echten Cookies und deine Session, nicht einen Bot aus dem Rechenzentrum. Separate Proxies brauchst du nicht.
Kostenloser Export in deine Tools
Export nach Excel, Google Sheets, Airtable oder Notion — komplett kostenlos. Alternativ kannst du als CSV oder JSON herunterladen. Kein Paywall-Blocker beim Herausziehen deiner Daten. Du kannst Daten auch oder — mit nur wenigen Klicks.
Fazit: Lohnt sich Octoparse?
Octoparse ist ein brauchbares Tool — aber nur für einen bestimmten Nutzertyp. Wenn du geplante Cloud-Extraktionen auf stabilen, gut strukturierten Websites brauchst und bereit bist, Zeit in den Workflow-Builder zu investieren und deine Scrapes bei Website-Änderungen zu pflegen, kann es funktionieren. Die Vorlagenbibliothek ist für populäre Seiten ein echter Pluspunkt.
Doch die versteckten Kosten sind real. Proxy-Zusätze, CAPTCHA-Credits (auch bei Fehlversuchen), Credit-Verbrauch durch Duplikate und ein 5-Tage-Erstattungsfenster, das kaum als echte Regelung durchgeht — das summiert sich schnell. Die auf Trustpilot dokumentierten Abrechnungsstreitigkeiten sind für Geschäftskunden ein ernstes Warnsignal. Und das Problem mit incentivierten Reviews bedeutet, dass man den Bewertungen auf vielen Plattformen nicht einfach blind glauben sollte.
Für nicht-technische Business-Anwender — Vertriebsteams, die Leads ziehen, E-Commerce-Teams, die Preise beobachten, Marketing-Teams, die Wettbewerbsdaten sammeln — sind Lernkurve und Wartungsaufwand von Octoparse schwer zu rechtfertigen. 15–20 Stunden bis zur Grundsicherheit, defekte Workflows nach Website-Updates, stille Fehler bei Pagination: Das ist Zeit, die du produktiver für dein eigentliches Geschäft einsetzen könntest.
Deshalb haben wir Thunderbit so gebaut, wie es ist: KI-gestützt, Extraktion in 2 Klicks, keine Workflows, die gewartet werden müssen, kostenloser Export.
Es ist nicht für jedes Szenario das richtige Tool. Wenn du als Entwickler eine produktive Datenpipeline baust, schau dir Apify oder einen eigenen Scraper an. Aber für Business-Anwender, die einfach nur zuverlässig und schnell Daten von einer Webseite brauchen — ohne Lernkurve — ist das die Lösung, die ich stattdessen nehmen würde.
Teste die kostenlos oder wirf einen Blick auf die , um die Tarife zu vergleichen. Und wenn du sehen willst, wie es in der Praxis aussieht, findest du auf dem Anleitungen für typische Anwendungsfälle.
FAQs
Ist Octoparse kostenlos?
Ja, Octoparse hat einen Gratis-Tarif — aber der ist begrenzt auf 10 Aufgaben, 2 gleichzeitige lokale Läufe, keine Cloud-Extraktion, keine Zeitplanung und keine Vorlagen. Der Export ist auf 10.000 Zeilen pro Export und 50.000 Datensätze pro Monat begrenzt. Für echte geschäftliche Nutzung brauchst du einen bezahlten Tarif ab 119 US-Dollar pro Monat.
Ist Octoparse sicher und legal zu verwenden?
Das Scraping öffentlich zugänglicher Daten ist grundsätzlich legal, aber du solltest immer die Nutzungsbedingungen und die robots.txt der Zielseite prüfen. Octoparse selbst ist ein legitimes Softwareprodukt. Für viele Nutzer ist eher die Abrechnungs-Transparenz das Problem — mehrere Rezensenten berichten, dass Kündigungen und Rückerstattungen schwierig seien. Bevor du abonnierst, solltest du das 5-Tage-Erstattungsfenster und die etwa 4 % Verarbeitungsgebühr auf genehmigte Rückerstattungen verstehen.
Funktioniert Octoparse auf dem Mac?
Ja, Octoparse bietet inzwischen eine macOS-Version an, die sowohl Intel als auch Apple Silicon unterstützt. Einige unabhängige Quellen deuten jedoch darauf hin, dass die Mac-Version weniger Funktionen haben könnte als die Windows-Version — historisch war der visuelle Builder nur unter Windows verfügbar, während Mac-Nutzer auf das Cloud-Dashboard beschränkt waren. Prüfe den aktuellen Funktionsumfang vor der Entscheidung.
Was ist die beste Alternative zu Octoparse?
Das hängt von deinem Bedarf ab. Für nicht-technische Business-Anwender, die schnelle KI-gestützte Extraktion wollen: . Für Entwickler, die eine codebasierte Plattform mit großem Actor-Marktplatz suchen: Apify. Für Enterprise-Teams mit Bedarf an fortgeschrittener Proxy-Infrastruktur: Bright Data. Für maximale Kontrolle mit Python-Kenntnissen: einen eigenen Scraper mit Scrapy oder Playwright bauen. Für ein einmaliges Projekt: einen Freelancer auf Upwork beauftragen.
Warum unterscheiden sich Octoparse-Bewertungen je nach Plattform so stark?
Der Abstand zwischen den G2-/Capterra-Werten von Octoparse (ca. 4,7) und Trustpilot (ca. 3,9) hängt größtenteils mit incentivierten Bewertungen zusammen. Es ist dokumentiert, dass Octoparse bezahlte 5-Sterne-Bewertungen auf Trustpilot angefragt hat, und viele Capterra-Bewertungen sind als incentiviert gekennzeichnet. Die ungefilterten Trustpilot-Werte — insbesondere die konkreten Beschwerden zu Abrechnung und Rückerstattung — sind ein verlässlicheres Signal für die tatsächliche Nutzererfahrung.
Mehr erfahren