Das Web ist hungriger nach Daten als je zuvor, und 2025 ist die erste Wahl fuer Teams, die smarter scrapen wollen -- nicht haerter. Ob du im Vertrieb, E-Commerce oder einfach ein Daten-Nerd wie ich bist: Du hast bestimmt bemerkt, dass Scraping nicht mehr nur darum geht, "die Daten abzugreifen". Es geht um Geschwindigkeit, Skalierbarkeit -- und darum, dass deine IP nicht auf der digitalen Sperrliste landet. Bei einem prognostizierten Wachstum des Web-Scraping-Marktes von 7,48 Mrd. USD im Jahr 2025 auf fast 38,4 Mrd. USD bis 2034 () waren die Einsaetze (und der Wettbewerb) noch nie hoeher.
Aber hier kommt der Haken: Das moderne Web ist eine Festung aus dynamischen Inhalten, Anti-Bot-Fallen und sich staendig aendernden Layouts. Ich habe mehr Scraper scheitern sehen, als mir lieb ist -- meistens, weil Best Practices ignoriert oder die Cleverness moderner Anti-Scraping-Abwehr unterschaetzt wurde. Also: Lass uns die wirklich praxisrelevanten Best Practices fuer effizientes Web Scraping mit Node.js anschauen -- mit ein paar Geschichten, einer Prise Humor und jeder Menge umsetzbarer Tipps.
Warum Node.js fuer effizientes Web Scraping?
Wer schon mal versucht hat, Hunderte (oder Tausende) Seiten gleichzeitig zu scrapen, weiss: Geschwindigkeit und Parallelitaet sind alles. Genau hier glaenzt Node.js. Das asynchrone, nicht-blockierende I/O-Modell ist wie geschaffen fuer die Verarbeitung massiver, gleichzeitiger Netzwerkanfragen -- stell dir Node.js als den ultimativen Multitasker des Webs vor (). Waehrend andere Sprachen bei jeder einzelnen Anfrage warten, dreht Node.js einfach seinen Event Loop weiter -- wie ein koffeinierter Jongleur.
Ich habe erlebt, dass Node.js Python und Java in Szenarien uebertrifft, in denen Echtzeit-Updates und grossskalierte Datenextraktion gefragt sind -- besonders bei JavaScript-lastigen Zielseiten. Tatsaechlich nutzen Node.js fuer Backend- und Automatisierungsaufgaben, was es zur beliebtesten Web-Technologie der Welt macht.
Node.js im Vergleich zu anderen Web-Scraping-Frameworks
Jetzt wird's ein bisschen technisch. So schneidet Node.js im Vergleich zur Konkurrenz ab:
| Framework | Staerken | Schwaechen | Beste Einsatzgebiete |
|---|---|---|---|
| Node.js | Asynchron, hervorragend fuer Parallelitaet, riesiges npm-Oekosystem, natives JS fuer dynamische Seiten | Kann speicherhungrig sein, Callback Hell (ohne async/await) | Echtzeit-Scraping, JS-lastige Seiten, skalierbare Microservices |
| Python | Zahlreiche Scraping-Bibliotheken (BeautifulSoup, Scrapy), einfache Syntax | Langsamer bei massiver Parallelitaet, Probleme mit JS-gerenderten Seiten | Statisches HTML, Forschung, Prototyping |
| Java | Starke Typisierung, robust fuer Enterprise | Umstaendlich, weniger flexibel fuer schnelle Skripte | Grossskaliertes Enterprise-Scraping |
| Go | Schnell, effiziente Parallelitaet | Kleineres Oekosystem, steilere Lernkurve | Hochleistungs-Scraping mit niedriger Latenz |
Fuer die meisten Business-Anwender trifft Node.js den Sweet Spot: schnell, flexibel und perfekt abgestimmt auf das moderne, JavaScript-getriebene Web ().
Eine robuste Node.js Web-Scraping-Umgebung einrichten
Ein guter Scraper beginnt mit einem soliden Fundament. So sieht mein bevorzugtes Setup aus:
- Projektstruktur: Halte alles modular. Verwende Ordner wie
/src,/libsund/config. Speichere sensible Infos (API-Keys, Proxies) in Umgebungsvariablen mitdotenv(). - HTTP-Client: Verwende , oder fuer Anfragen.
- HTML-Parsing: fuer statisches HTML, oder Playwright fuer dynamische Inhalte.
- Hilfsbibliotheken: fuer Datenverarbeitung und oder fuer Datenvalidierung.
- Tests & Linting: Mocha fuer Tests, ESLint fuer Code-Qualitaet ().
Wichtige Node.js Web-Scraping-Bibliotheken
- axios/got/node-fetch: Fuer HTTP-Anfragen. Axios ist mein persoenlicher Favorit wegen seiner Promise-basierten API und der eingebauten JSON-Verarbeitung.
- Cheerio: Schneller, jQuery-aehnlicher HTML-Parser. Ideal fuer statische Seiten -- parst in ca. 0,5 Sekunden ().
- Puppeteer/Playwright: Headless-Browser-Automatisierung fuer dynamische, JS-lastige Seiten. Langsamer (~4 Sek. pro Seite), aber unverzichtbar fuer Seiten, die Inhalte erst nach dem Laden nachliefern ().
- dotenv: Fuer die Verwaltung von Umgebungsvariablen.
- csv-writer/jsonfile: Fuer den Datenexport.
Haeufige Fallstricke beim Node.js Web Scraping vermeiden
Ich habe laengst aufgehoert zu zaehlen, wie oft ich Scraper gesehen habe, die blockiert wurden, abgestuerzt sind oder einfach einen Haufen unbrauchbarer Daten ausgespuckt haben. Darauf solltest du achten:
- robots.txt und Nutzungsbedingungen ignorieren: Pruefe immer vorher. Verstoesse koennen zu IP-Sperren fuehren -- oder schlimmer noch, zu rechtlichen Problemen ().
- Server ueberlasten: Bombardiere keine Anfragen. Drossle deinen Scraper mit zufaelligen Verzoegerungen (1--3 Sekunden), nutze Parallelitaets-Kontrollen und verhalte dich nicht wie ein hyperaktiver Bot ().
- Fehlerbehandlung vergessen: Umschliesse Anfragen immer mit try/catch, behandle HTTP-Fehler und protokolliere Fehlschlaege. Versuche transiente Fehler mit exponentiellem Backoff erneut ().
- Request-Header vergessen: Verwende realistische User-Agent-Strings und rotiere sie. Fuege Accept-Language, Referer und andere Header hinzu, um echte Browser zu imitieren ().
Anti-Scraping-Mechanismen umgehen
Moderne Websites sind bis an die Zaehne mit Anti-Bot-Technologie bewaffnet. So umgehe ich die digitalen Stolperfallen:
- Rotierende Proxies/IPs: Nutze einen Proxy-Pool und rotiere IPs, um Sperren zu vermeiden ().
- Header randomisieren: Rotiere User-Agent, Accept-Language und andere Header bei jeder Anfrage.
- Headless-Browser tarnen: Nutze Plugins wie
puppeteer-extra-plugin-stealth, um Automatisierungs-Fingerabdruecke zu maskieren. - Menschliches Verhalten simulieren: Fuege zufaellige Verzoegerungen, Mausbewegungen, Scrollen und sogar Tippfehler hinzu ().
Menschliches Verhalten in Node.js-Scrapern simulieren
Hier wird's richtig spannend (und ein bisschen verrueckt). Statt sofort zu klicken und zu scrollen, skripte deinen Scraper so:
- Warte zufaellige Intervalle zwischen Aktionen (
await page.waitForTimeout(randomDelay)) - Bewege die Maus in kleinen, ungleichmaessigen Schritten (
page.mouse.move(x, y)) - Tippe mit zufaelligen Verzoegerungen und gelegentlichen Tippfehlern (
page.type(selector, text, {delay: random(100,200)})) - Scrolle ungleichmaessig, nicht einfach bis zum Ende
Diese Tricks koennen deine Erfolgsrate auf geschuetzten Seiten drastisch erhoehen ().
Komplexe Datenextraktion einfach gemacht mit Thunderbit
Jetzt zum Elefanten im Raum: Scraping ist komplex. Aber das muss nicht so sein. Deshalb haben wir entwickelt.
Thunderbit ist eine KI-gesteuerte Web-Scraper Chrome Extension, mit der du Daten von jeder Website in einfachem Deutsch (oder jeder anderen Sprache) extrahieren kannst. Klicke einfach auf "AI Suggest Fields", lass die KI die Seite analysieren und druecke "Scrape". Es ist wie ein Junior-Entwickler, der nie schlaeft und nie nach einer Gehaltserhoehung fragt.
Noch besser: Thunderbit bietet eine API, sodass du es direkt in deine Node.js-Workflows einbinden kannst. Statt Tausende Zeilen Scraping-Code zu schreiben, laesst du Thunderbit die schwere Arbeit erledigen -- dynamische Inhalte, Unterseiten, Paginierung und alles andere. Du holst dir einfach die strukturierten Daten (CSV, JSON oder direkt in Google Sheets, Airtable, Notion) und machst mit deinem Tag weiter ().
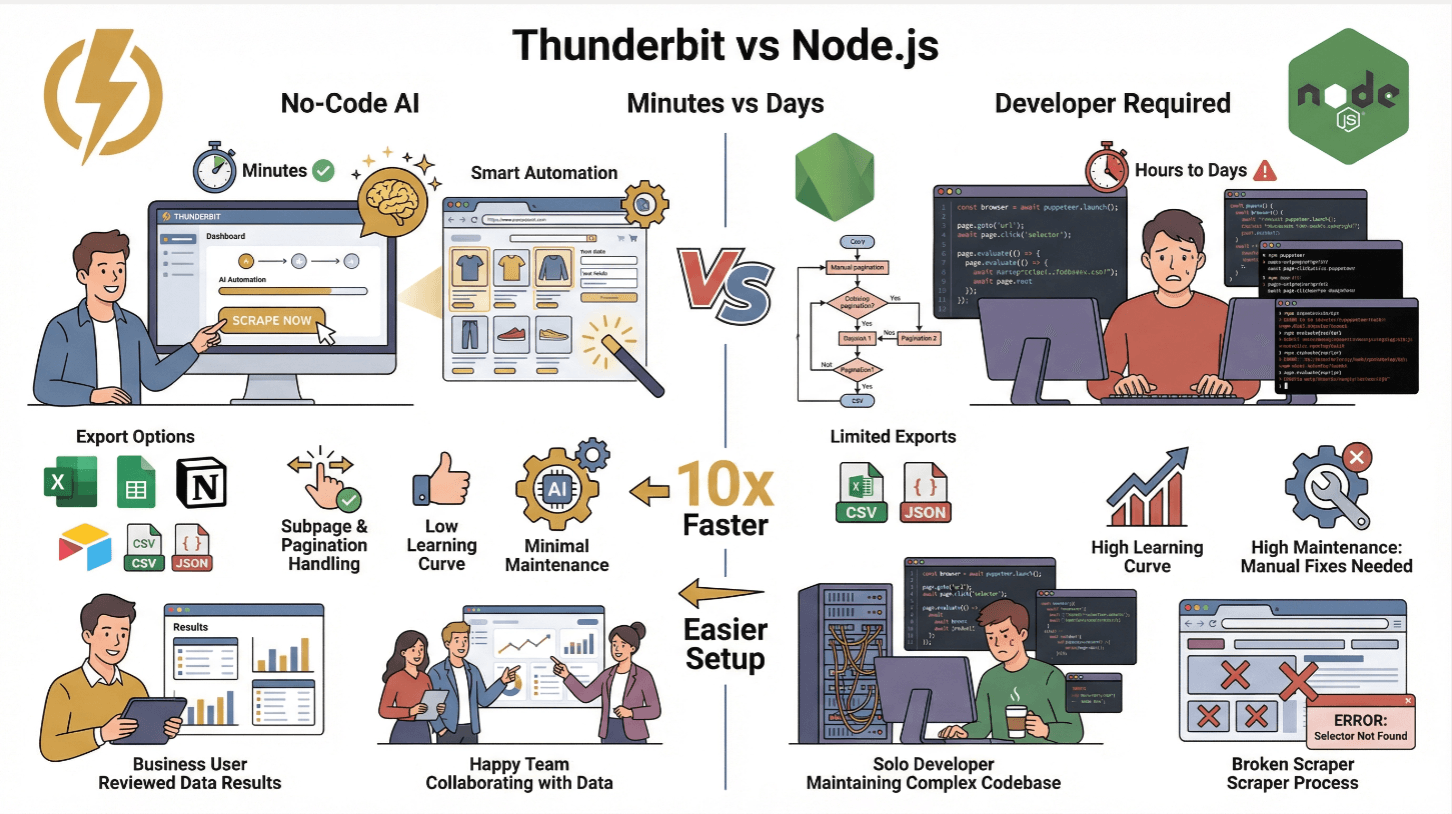
Thunderbit vs. Traditionelles Node.js-Scraping
| Funktion | Thunderbit | Traditioneller Node.js-Scraper |
|---|---|---|
| Einrichtungszeit | Minuten (kein Code) | Stunden bis Tage (Programmierung, Tests) |
| Dynamische Inhalte | Ja (KI + Browser) | Ja (mit Puppeteer/Playwright) |
| Unterseiten & Paginierung | 1 Klick | Manuelle Programmierung erforderlich |
| Datenexport | Excel, Sheets, Notion, Airtable, CSV, JSON | CSV/JSON (eigener Code) |
| Lernkurve | Niedrig (Business-Anwender) | Hoch (Entwickler) |
| Wartungsaufwand | Minimal (KI passt sich an) | Hoch (manuelle Korrekturen bei Website-Aenderungen) |
Thunderbit ist perfekt fuer nicht-technische Teams oder fuer alle, die sich die muehsame Arbeit sparen und direkt auf Erkenntnisse konzentrieren wollen. Fuer fortgeschrittene Nutzer bietet Thunderbit eine API zur skalierbaren Automatisierung ().
Cheerio und Puppeteer fuer dynamische Inhalte kombinieren
Das ist meine liebste Node.js-Scraping-Power-Kombi. So funktioniert's:
- Puppeteer verwenden, um die Seite zu laden und JavaScript auszufuehren (warte auf
networkidle, um sicherzustellen, dass alle Inhalte geladen sind). - HTML abrufen mit
await page.content(). - Mit Cheerio parsen: Fuettere das HTML an Cheerio fuer ultraschnelles, jQuery-aehnliches Parsing und Datenextraktion.
Dieser hybride Ansatz gibt dir das Beste aus beiden Welten: Puppeteers Power fuer dynamische Inhalte, Cheerios Geschwindigkeit beim Parsen ().
Performance-Tipp: Selektiere nur die Elemente, die du brauchst. Cheerio laedt das gesamte DOM in den Speicher, also vermeide breite Selektoren und cache Ergebnisse, wenn du dieselben Seiten wiederholt scrapst ().
HTML-Parsing und Datenextraktion optimieren
- Spezifische Selektoren verwenden: Vermeide
$('body *')-- ziele nur auf das, was du brauchst. - Grosse Seiten streamen: Bei riesigem HTML ziehe Streaming oder Aufteilung in Betracht.
- Gerendertes HTML cachen: Wenn du URLs erneut besuchst, cache das HTML, um redundante Anfragen zu vermeiden.
- Daten validieren und bereinigen: Nutze Validator-Bibliotheken, um sicherzustellen, dass du keine Muell-Daten in deine Datenbank schreibst ().
Skalierbares Deployment von Node.js Web Scrapern in der Cloud
Scraping im grossen Massstab? Zeit fuer Cloud-native.
- Scraper dockerisieren: Schreibe ein
Dockerfile, kopiere deinen Code, installiere Abhaengigkeiten und setze den Entrypoint. - In der Cloud deployen: Nutze AWS EC2, Google Cloud Compute oder Azure VMs fuer einfache Jobs. Fuer echte Skalierung nutze Kubernetes oder verwaltete Dienste wie AWS ECS/EKS, Google Cloud Run oder Azure Kubernetes Service ().
- Mit Kubernetes orchestrieren: Fuehre mehrere Pods aus, skaliere automatisch nach Bedarf und nutze Load Balancer, um URLs zu verteilen.
- Jobs planen: Nutze Cloud-Scheduler (CloudWatch Events, Cloud Scheduler) oder Cron-Jobs, um Scrapes in regelmaessigen Intervallen auszuloesen.
In einem Praxisbeispiel hat die Skalierung von 5 auf 10 Kubernetes-Pods ein 400-Seiten-Scraping von Minuten auf unter eine Minute reduziert ().
Monitoring und Auto-Scaling deiner Scraping-Infrastruktur
- Logging: Streame Logs an CloudWatch, Stackdriver oder Datadog. Richte Alerts fuer Fehler oder Verlangsamungen ein.
- Health Checks: Nutze Prometheus und Grafana fuer Metriken wie gescrapte Seiten pro Minute, Fehlerraten und Pod-Gesundheit.
- Auto-Scaling: Richte Kubernetes HPA (Horizontal Pod Autoscaler) ein, um Pods basierend auf CPU oder Anfragen zu skalieren.
Implementiere immer Retries mit exponentiellem Backoff, um Netzwerkprobleme oder temporaere Sperren abzufangen.
Best Practices fuer Datenspeicherung und Nachbearbeitung
Sobald du die Daten gescrapt hast, musst du sie speichern und bereinigen:
- Kleine Jobs: Exportiere in CSV, JSON oder pushe an Google Sheets, Airtable oder Notion (Thunderbit macht das direkt out of the box).
- Grosse Jobs: Nutze SQL (MySQL/PostgreSQL) fuer strukturierte Daten oder NoSQL (MongoDB, DynamoDB) fuer semistrukturierte oder sich entwickelnde Schemata ().
- Cloud-Speicher: S3 oder Google Cloud Storage fuer Rohdateien und Backups.
- Datenbereinigung: Validiere Felder, normalisiere Formate (Daten, Zahlen) und dedupliziere Eintraege. Nutze Schema-Validatoren, um die Datenqualitaet sicherzustellen ().
Bewahre sowohl die Roh- als auch die bereinigten Daten auf -- man weiss nie, wann man sie erneut verarbeiten oder debuggen muss.
Fazit: Die wichtigsten Erkenntnisse fuer effizientes Node.js Web Scraping
Fassen wir die wichtigsten Punkte zusammen:
- Nutze die asynchrone Power von Node.js fuer massives, paralleles Scraping -- besonders bei JS-lastigen Seiten.
- Kombiniere die richtigen Tools: Verwende axios/got fuer Anfragen, Cheerio fuer statisches HTML, Puppeteer fuer dynamische Inhalte -- und mische sie fuer Geschwindigkeit und Flexibilitaet.
- Anti-Bot-Fallen vermeiden: Rotiere Proxies und Header, simuliere menschliches Verhalten und respektiere robots.txt.
- Vereinfache mit Thunderbit: Fuer Business-Anwender oder schnelles Prototyping ermoeglicht die Extraktion komplexer Daten mit KI und die Integration in deinen Node.js-Stack via API.
- Skaliert deployen: Dockerisieren, mit Kubernetes orchestrieren und alles fuer Zuverlaessigkeit monitoren.
- Daten speichern und bereinigen: Waehle den richtigen Speicher fuer deine Beduerfnisse und validiere immer vor der Nutzung.
Das Web wird nicht einfacher, aber mit diesen Best Practices bleiben deine Node.js-Scraper schnell, zuverlaessig und dem Anti-Bot-Wettruesten immer einen Schritt voraus. Und wenn du mal wieder um 2 Uhr nachts Selektoren debuggst: Denk dran, Thunderbits KI ist immer wach.
Willst du weiterlernen? Schau im vorbei fuer tiefergehende Artikel oder teste die , um zu sehen, wie einfach Scraping sein kann.
FAQ
1. Warum ist Node.js 2025 besonders gut fuer Web Scraping geeignet?
Das asynchrone, ereignisgesteuerte Modell von Node.js ermoeglicht es, Tausende gleichzeitige Anfragen zu verarbeiten -- ideal fuer das Scraping grosser Datenmengen oder Echtzeit-Updates. Das riesige npm-Oekosystem und die native JavaScript-Unterstuetzung sind perfekt fuer moderne, JS-lastige Websites ().
2. Wie kann ich beim Scraping mit Node.js Blockierungen vermeiden?
Nutze rotierende Proxies, randomisiere Request-Header, drossle deine Anfragen mit zufaelligen Verzoegerungen und simuliere menschliches Verhalten (Mausbewegungen, Scrollen, Tippen) mit Tools wie Puppeteer. Respektiere immer robots.txt und die Nutzungsbedingungen der Seite ().
3. Wann sollte ich Cheerio vs. Puppeteer in meinem Node.js-Scraper verwenden?
Verwende Cheerio fuer schnelles Parsing von statischem HTML (wenn die Daten im rohen HTML stehen). Verwende Puppeteer fuer Seiten, die Inhalte dynamisch mit JavaScript laden. Fuer beste Ergebnisse: Puppeteer zum Rendern der Seite, dann Cheerio zum Parsen des HTML ().
4. Wie vereinfacht Thunderbit das Node.js Web Scraping?
Thunderbit ermoeglicht die Extraktion strukturierter Daten von jeder Website mithilfe von KI und natuerlichsprachlichen Prompts -- ganz ohne Programmierung. Es verarbeitet dynamische Inhalte, Unterseiten und Paginierung und bietet eine API fuer die Node.js-Integration. Daten koennen direkt nach Excel, Google Sheets, Airtable oder Notion exportiert werden ().
5. Wie skaliert und ueberwacht man Node.js-Scraper am besten in der Cloud?
Dockerisiere deinen Scraper, deploye ihn auf Kubernetes oder verwalteten Cloud-Diensten und nutze Auto-Scaling fuer Lastspitzen. Ueberwache Logs und Metriken mit Tools wie CloudWatch oder Prometheus und richte Alerts fuer Fehler oder Verlangsamungen ein ().
Bereit, dein Web Scraping auf das naechste Level zu bringen? Probiere Thunderbit aus -- und moegen deine Scraper schnell, unauffaellig und immer einen Schritt voraus sein.
Mehr erfahren