
Jedes Node.js-Fetch-Tutorial bringt dir await fetch(url) bei und tut dann so, als wäre die Sache damit erledigt. In der Produktion verschluckt deine App dann still und leise einen 500-Fehler, eine Anfrage hängt 90 Sekunden lang ohne Timeout, und du verbringst deinen Freitagabend damit, etwas zu debuggen, das eigentlich sofort hätte auffallen müssen.
Ich baue bei schon seit einiger Zeit interne Tools und Datenpipelines, und ich kann dir sagen: Die Lücke zwischen „fetch funktioniert im Tutorial“ und „fetch funktioniert in der Produktion“ ist genau der Ort, an dem der meiste Ärger entsteht. Ein Entwickler auf Reddit hat es perfekt auf den Punkt gebracht: „Wenn du in die Produktion gehst, merkst du, dass du etwas Robusteres brauchst als das native fetch.“
Ein anderer gab zu: „3 Jahre lang als Webentwickler gearbeitet, und heute erst gelernt, dass der catch-Block der fetch API NICHT für HTTP-Fehler ist.“ Dieser Leitfaden behandelt die fünf Dinge, die die meisten Tutorials auslassen — den Fehler-Fallstrick, Timeouts mit AbortController, Retry-Logik, Wiederverwendung von Verbindungen und den Moment, in dem du für strukturierte Datenerfassung über fetch hinausgehen solltest. Wenn dir schon einmal ein fetch-Aufruf in der Produktion stillschweigend fehlgeschlagen ist, ist dieser Artikel für dich.
Was ist die Node.js Fetch API?
Die Node.js Fetch API ist die eingebaute, browserkompatible Möglichkeit, HTTP-Anfragen (GET, POST, PUT, DELETE usw.) aus Node.js heraus zu senden — ohne Axios, node-fetch oder irgendein anderes Paket zu installieren. Wenn du fetch() im Browser schon benutzt hast, kennst du die Syntax bereits. Jetzt läuft dieselbe API auch auf dem Server.
Hier ist die kurze Versionsgeschichte:
| Meilenstein | Node-Version | Was passiert ist |
|---|---|---|
| Experimentelles Fetch-Flag | v17.5.0 / v16.15.0 | fetch hinter --experimental-fetch hinzugefügt |
| Globales Fetch als Standard | v18.0.0 | Experimentelles fetch global verfügbar, betrieben von Undici |
| Stabiles Fetch | v21.0.0 | Nicht mehr experimentell |
| Produktions-Basis 2026 | v22 LTS / v24 LTS | Für die Produktion empfohlen; v20 ist jetzt EOL |
Unter der Haube wird Node-Fetch von Undici angetrieben — einem leistungsstarken HTTP-Client, der speziell für Node.js gebaut wurde. Er setzt nicht auf das ältere eingebaute http-Modul. Der praktische Vorteil: Du bekommst eine moderne, Promise-basierte HTTP-API, die genauso in deinem Browser-Code, deinem Express-Backend, deiner serverlosen Funktion und deinen CLI-Skripten funktioniert.
Warum die Node.js Fetch API für deine Projekte wichtig ist
Vor Node 18 begann jedes neue Projekt mit demselben Ritual: npm install axios oder npm install node-fetch. Im Jahr 2026 brauchst du in einer gepflegten Node-LTS-Version für einfache HTTP-Anfragen keine zusätzliche Abhängigkeit mehr. Das ist ein echter Gewinn für Bundle-Größe, Sicherheit in der Lieferkette und das Onboarding (Front-End- und Back-End-Entwickler verwenden endlich dieselbe API).
Hier spielt natives fetch seine Stärken aus:
| Szenario | Warum natives fetch gut funktioniert | Produktions-Hinweis |
|---|---|---|
| Express/Fastify-Backend, das REST-APIs aufruft | Vertrautes async/await, keine Abhängigkeit | Timeout und response.ok-Prüfung ergänzen |
| Serverless-Funktionen (Lambda, Vercel usw.) | Kleine Cold-Start-Fläche, keine Paketinstallation | Timeout unter der maximalen Laufzeit der Plattform halten |
| CLI-Skripte und Automatisierungen | Einfaches GET/POST ohne Projekt-Setup | Retry/Backoff für instabile APIs hinzufügen |
| Webhook-Zustellung oder -Weiterleitung | Standard-HTTP-Methoden und -Header | Nicht blind nicht-idempotente POSTs erneut versuchen |
| Berichte und Dashboards | Gut für JSON-Abfragen von APIs | Für Schleifen Paging und Connection Pooling verwenden |
| Microservice-Kommunikation | Funktioniert für einfache interne HTTP-Aufrufe | Für Retry, Hooks oder HTTP/2 eher Got oder direkt Undici erwägen |
Für neue Node-22+-Projekte ist natives fetch der vernünftige Standard — außer du weißt, dass du Funktionen brauchst, die es nicht bietet (Interceptor, eingebautes Retry, HTTP/2 usw.). Die npm-Downloadzahlen zeigen einen Markt im Wandel: , aber ein großer Teil davon ist Legacy und transitive Abhängigkeiten. , , und . Der Trend ist klar: natives fetch ist die neue Basis, und Drittanbieter-Clients sind für Spezialfälle da.
Natives Fetch vs. node-fetch vs. Axios vs. Got vs. Ky: Die Entscheidungs-Matrix 2026
Die häufigste Frage, die ich in Entwicklerforen sehe: „Welchen HTTP-Client sollte ich in Node.js verwenden?“ Ein Reddit-Nutzer brachte es so auf den Punkt: „Warum sollte ich eine Bibliothek importieren … wenn die Sprache/das Framework die Funktion schon eingebaut hat?“ Ein fairer Punkt — aber die Antwort hängt davon ab, was du brauchst.
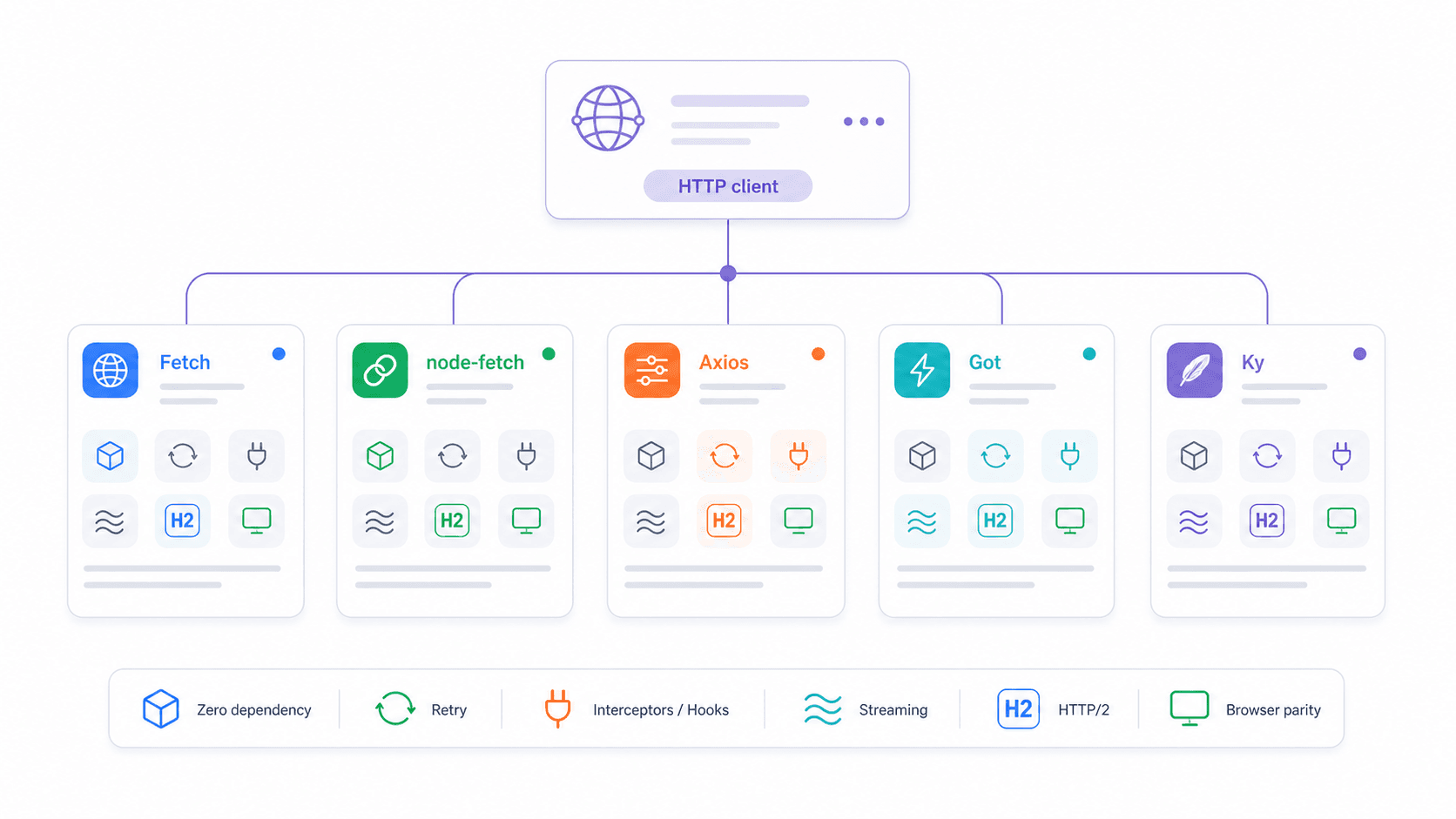
| Funktion | Natives fetch | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Node.js-Version | ≥18 (empfohlen 22/24 LTS) | ≥12.20 | Breite Unterstützung | ≥22 | ≥22 |
| Installation erforderlich | Nein | Ja | Ja | Ja | Ja |
| ESM- und CJS-Unterstützung | Beide (global) | Nur ESM (v3) | Beide | Nur ESM | Nur ESM |
| Automatischer Reject bei 4xx/5xx | Nein | Nein | Ja | Ja | Ja |
| Eingebautes Retry | Nein | Nein | Nein | Ja | Ja |
| Request-Interceptor | Nein | Nein | Ja | Ja (Hooks) | Ja (Hooks) |
| Streaming-Unterstützung | Web ReadableStream | Ja | Eingeschränkt | Starke Node-Streams | Fetch-basiert |
| Bundle-/Installationsumfang | 0 KB | ~107 KB, 3 Abhängigkeiten | ~2,8 MB, 4 Abhängigkeiten | ~355 KB, 12 Abhängigkeiten | ~405 KB, 0 Abhängigkeiten |
| HTTP/2-Unterstützung | Über Undici-Dispatcher | Nein | Nein | Ja | Nein (Fetch-Wrapper) |
Eine kurze Anmerkung zum ESM/CJS-Problem: node-fetch v3 ist nur ESM, was viele Projekte mit require() kaputt gemacht hat. Natives fetch ist global — es funktioniert in CJS- und ESM-Dateien ohne Import-Akrobatik. Wenn du wegen CommonJS an node-fetch v2 festhängst, löst natives fetch dieses Problem komplett.
Und was frühe Stabilitätsbedenken betrifft: Ja, es gab in der ersten fetch-Implementierung von Node 18 echte Fehler. Ein Entwickler auf Reddit erwähnte: „Ich hatte kürzlich einen wilden Bug mit dem nativen Fetch in Node 18, also mussten wir unsere App umstellen.“ Das war 2023. Im Jahr 2026, mit Node 22 und 24 LTS, sind diese Probleme behoben. Natives fetch ist produktionsreif.
Wann du bei nativem Fetch bleiben solltest
Bleib bei nativem fetch, wenn:
- Dein Projekt auf Node 22 LTS oder Node 24 LTS läuft.
- Die Anfragen einfache REST-Aufrufe sind (GET, POST, PUT, DELETE).
- Du bereit bist, einen kleinen Wrapper für
response.ok, JSON-Parsing, Timeouts und Retry hinzuzufügen. - Du keine Abhängigkeiten und weniger Risiken in der Lieferkette willst.
- Dir die Parität zwischen Browser- und Server-API wichtig ist.
- Du in serverlosen oder Edge-Umgebungen arbeitest, in denen eingebaute APIs bevorzugt werden.
Wann Axios, Got oder Ky sinnvoller sind
Axios ist die richtige Wahl, wenn dein Team auf Request-/Response-Interceptor angewiesen ist (z. B. automatisches Erneuern von Auth-Tokens, Mandanten-Header, zentrales Logging), wenn du standardmäßig bei HTTP-Fehlern einen Reject möchtest oder wenn du Rückwärtskompatibilität mit älteren Node-Runtimes brauchst.
Got ist für Node-Services mit hohem Durchsatz gebaut, die eingebaute Retries, Hooks, fortgeschrittene Timeout-Phasen, Streams, Paging-Helfer, Unix-Sockets, Proxy-/Caching-Workflows oder HTTP/2-Unterstützung benötigen. Es ist das Schweizer Taschenmesser für HTTP-Arbeit nur in Node.
Ky ist der Sweet Spot, wenn du die Einfachheit von fetch magst, aber weniger Boilerplate willst — es bringt Retry, Timeout, Hooks und HTTPError in einem winzigen Paket mit null Abhängigkeiten mit.
So sendest du GET-Anfragen mit der Node.js Fetch API
Eine GET-Anfrage mit async/await sieht so aus:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"Und die Variante mit .then(), falls du sie bevorzugst:
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));Beides funktioniert. Aber beides ist noch nicht produktionssicher (dazu gleich mehr).
Response-Reader, die du kennen solltest:
| Methode | Wann verwenden |
|---|---|
response.json() | Der Server liefert JSON |
response.text() | Der Server liefert HTML, Klartext, CSV oder Markdown |
response.arrayBuffer() | Du brauchst Binärdaten (Bilder, Dateien) |
response.body | Du brauchst Streaming-/Chunk-Verarbeitung |
Ein besseres Muster — eines, das tatsächlich auf Fehler prüft:
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);Diese Zeile if (!response.ok) macht den Unterschied zwischen Tutorial und Produktionscode aus. Und genau das ist die größte Falle.
So sendest du POST-Anfragen mit der Node.js Fetch API
POST-Anfragen folgen derselben Struktur — du setzt nur Methode, Header und Body:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Leitfaden für Node-Fetch',
8 body: 'Produktionsreifes Fetch braucht Fehlerbehandlung.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Andere Request-Typen senden (PUT, DELETE, PATCH)
PUT, PATCH und DELETE verwenden dieselbe Struktur mit einem anderen method-Wert:
1// PUT — vollständige Ersetzung
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Ersetzt', body: 'Vollständige Ersetzung', userId: 1 }),
6});
7// PATCH — Teilaktualisierung
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Teilaktualisierung' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});Der Body-Parser-Fallstrick in Express: Wenn du JSON an einen Express-Server sendest und req.body als undefined zurückkommt, ist die Lösung fast immer diese: Verwende express.json() und nicht express.urlencoded(). Der Server braucht express.json()-Middleware vor deiner Route, um Content-Type: application/json-Bodies zu parsen. Das ist eine der häufigsten zu Express, und es erwischt Leute jedes Mal.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← Das brauchst du für JSON-POST-Bodies
4app.post('/api/posts', (req, res) => {
5 res.json({ received: req.body });
6});Der fetch()-Fehler-Fallstrick, der Produktions-Apps kaputtmacht
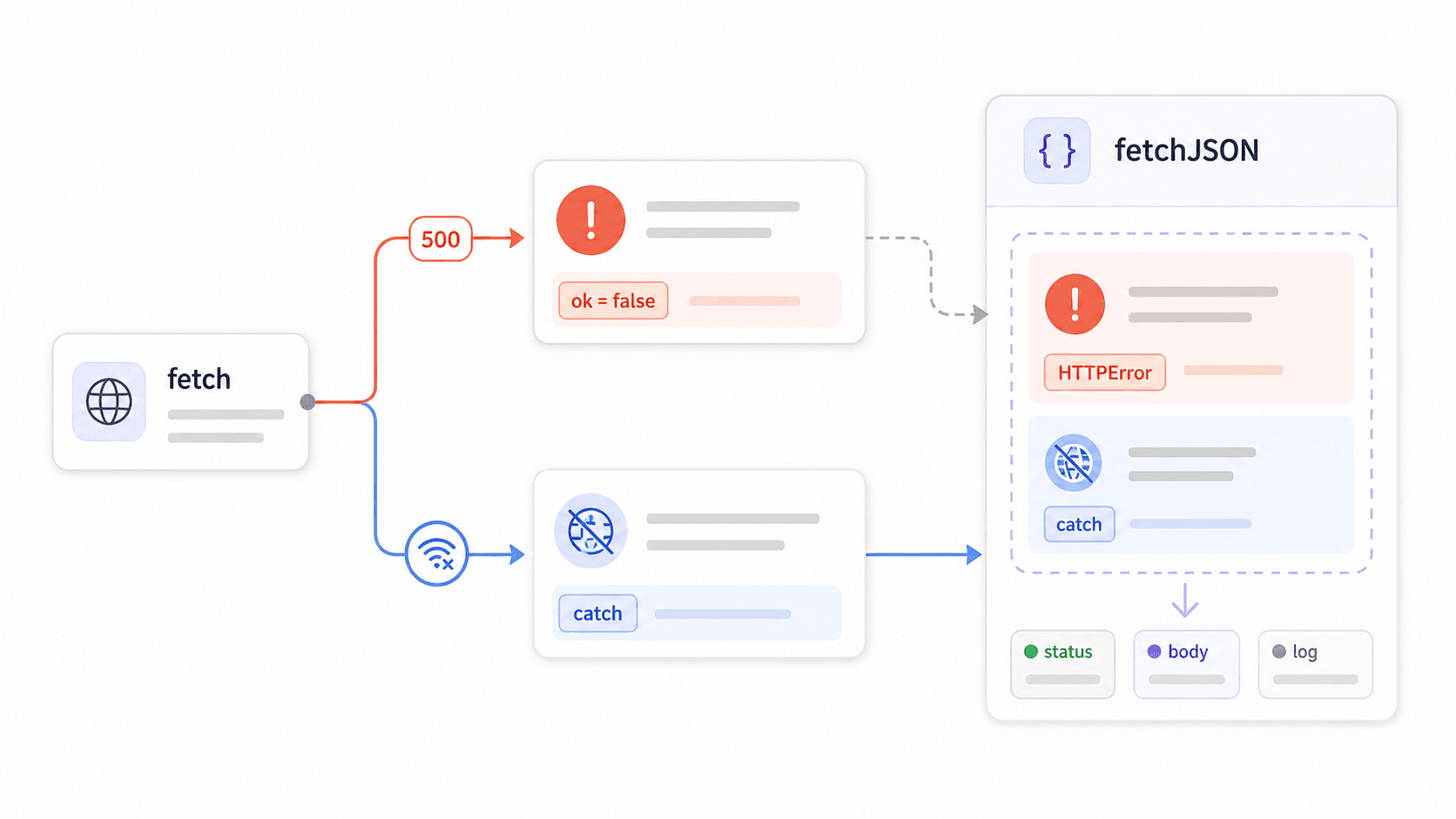
Hier entstehen die meisten Fetch-Bugs in der Produktion.
fetch() lehnt sein Promise bei HTTP-4xx- oder 5xx-Fehlern nicht ab. Es lehnt nur bei Fehlern auf Netzwerkebene ab — DNS-Fehler, keine Internetverbindung, abgebrochene Anfragen. Wenn der Server einen 403 Forbidden oder einen 500 Internal Server Error zurückgibt, betrachtet fetch das als erfolgreiche Antwort. Dein .catch()-Block wird nie ausgeführt. Dein try/catch fängt es nie ab. Dein Code verarbeitet fröhlich alles, was der Server zurückgeschickt hat.
sagt das ganz klar, aber die meisten Tutorials gehen darüber hinweg. Das Ergebnis? Code wie dieser sieht gut aus, verschluckt Fehler aber stillschweigend:
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← Das läuft sogar bei einem 403
4 console.log('Sieht erfolgreich aus:', data);
5} catch (error) {
6 // Nur Fehler auf Netzwerkebene landen hier
7 console.error('Abgefangen:', error);
8}Hier eine kurze Aufschlüsselung, was die einzelnen Muster tatsächlich abfangen:
| Muster | Fängt Netzwerkfehler ab | Fängt 4xx/5xx ab | Parst JSON sicher | Wiederverwendbar |
|---|---|---|---|---|
Rohes .then(res => res.json()) | Ja (über .catch()) | Nein | Keine Content-Type-Prüfung | Nein |
try/catch mit await fetch() | Ja | Nein | Keine Content-Type-Prüfung | Nein |
Manuelles if (!res.ok) pro Aufruf | Ja | Ja | Hängt vom jeweiligen Aufruf ab | Teilweise |
Eigener fetchJSON()-Wrapper | Ja | Ja | Ja | Ja |
Einen wiederverwendbaren fetchJSON()-Wrapper bauen
Schreib einen Wrapper. Importiere ihn überall. Hör auf, if (!response.ok) in jede Datei zu kopieren:
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Wenn der Server jetzt einen 403 zurückgibt:
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`Server gab $\{error.status\} zurück:`, error.body);
6 } else {
7 console.error('Netzwerk- oder anderer Fehler:', error);
8 }
9}Der Fehler enthält den Statuscode, den Response-Body und die URL — also alles, was du für Logging, Alarme oder Meldungen an Nutzer brauchst. Einmal importieren, überall verwenden.
AbortController und Timeouts: Das Produktionsmuster für die Node.js Fetch API
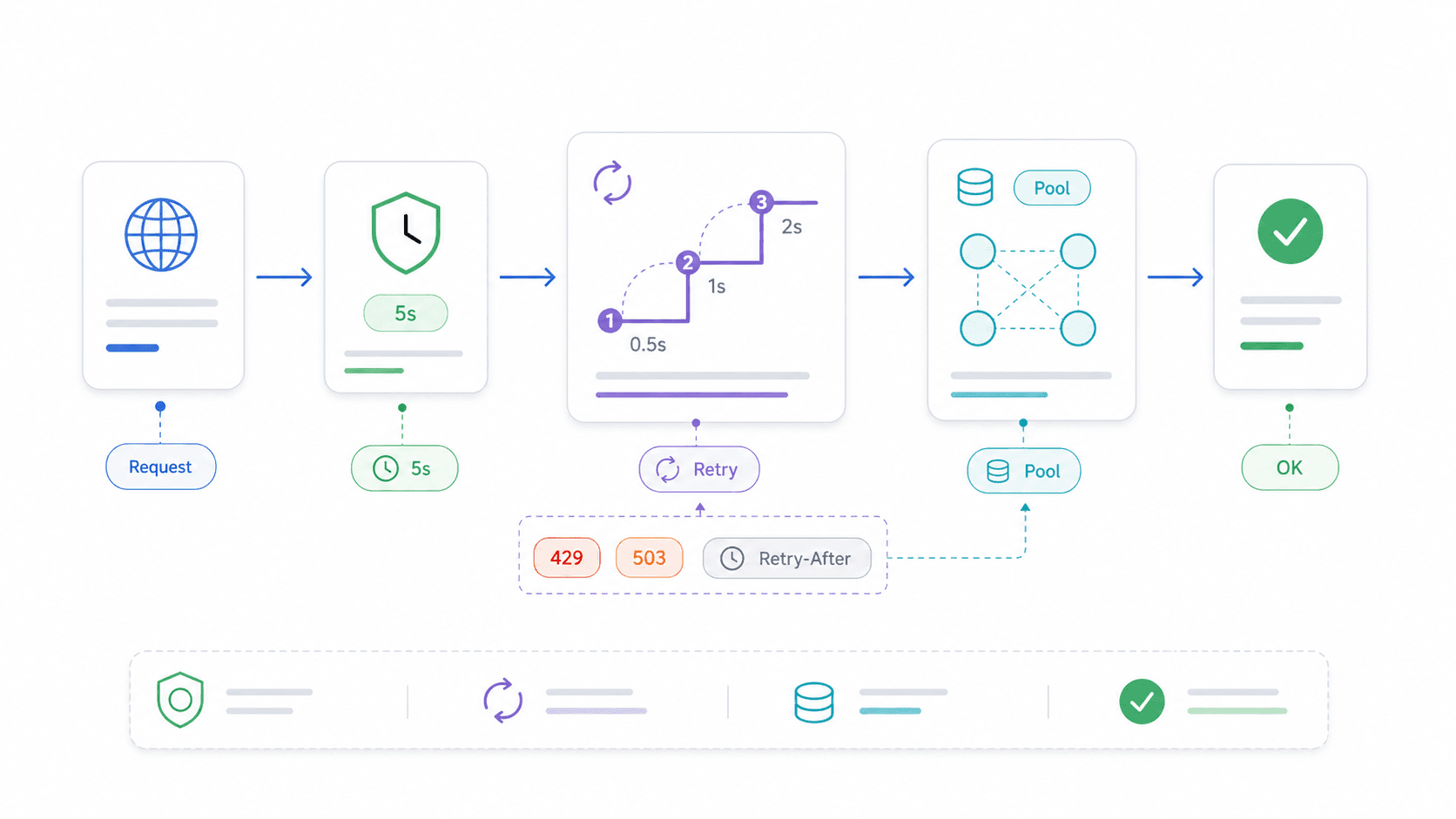
Ohne Timeout hängt ein fetch-Aufruf unbegrenzt, wenn der entfernte Server nicht mehr antwortet. Deine Express-Route blockiert. Deine Lambda-Funktion verbrennt ihr Laufzeitbudget. Dein Skript sitzt einfach ... und wartet.
Ich habe die Top-Suchergebnisse geprüft: Kein einziges Node.js-spezifisches Fetch-Tutorial behandelt Request-Abbruch oder Timeouts. Und doch sind Timeouts einer der Hauptgründe, warum Entwickler bei Axios oder Got bleiben. Ein Reddit-Thread heißt wörtlich „Node fetch does not timeout“.
AbortSignal.timeout() verwenden (Node 18.11+)
Der einfachste Ansatz — eine zusätzliche Option:
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 Sekunden
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('Die Anfrage hat nach 5 Sekunden ein Timeout erreicht.');
11 } else {
12 throw error;
13 }
14}Hinweis: AbortSignal.timeout() löst einen TimeoutError aus, keinen AbortError. Dieses Detail wird sogar von manchen erfahrenen Entwicklern falsch angegeben.
Manuelles Timeout mit AbortController
Für mehr Kontrolle — oder wenn du eine Anfrage nicht nur per Timer, sondern wegen einer Benutzeraktion abbrechen musst:
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('Die Anfrage wurde manuell abgebrochen.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}AbortError vs. TimeoutError behandeln
Diese Unterscheidung ist für Logging und Meldungen an Nutzer wichtig:
| Abbruchpfad | Fehlername im catch-Block |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| DNS-/Netzwerkfehler | Typischerweise TypeError: fetch failed |
Hier ein praktisches Szenario — eine Express-Route, die eine externe API aufruft und innerhalb von 3 Sekunden antworten muss:
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'Upstream-API hat ein Timeout erreicht' });
10 return;
11 }
12 next(error);
13 }
14});Ohne dieses Muster würde eine langsame Upstream-API deine gesamte Route blockieren, bis der Client aufgibt.
Retry-Logik und Connection Reuse: So machst du die Node.js Fetch API produktionsreif
Natives fetch hat kein eingebautes Retry. Ein kurzer Netzwerkaussetzer oder ein vorübergehender 503 bedeutet, dass die Anfrage einfach fehlschlägt. Für die meisten Leseoperationen in der Produktion ist das nicht akzeptabel.
Ein zusammensetzbarer Retry-Wrapper mit exponentiellem Backoff
Das ist bewusst kurz — etwa 10 Zeilen echter Logik:
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250 ms, 500 ms, 1000 ms...
14 }
15}Wann du retryen solltest — und wann nicht
- Retryen: Idempotente GET- und HEAD-Anfragen, vorübergehende Statuscodes (408, 429, 500, 502, 503, 504), kurze Netzwerkaussetzer.
- Nicht retryen: Nicht-idempotente POST-Anfragen, die Datensätze anlegen, Geld abbuchen oder Nebenwirkungen auslösen — außer du verwendest Idempotency Keys.
- Retry-After beachten: Bei 429 (Rate Limit) und 503 (Service nicht verfügbar) solltest du den
Retry-After-Header prüfen, bevor du mit dem Backoff beginnst.
Wenn du deine Retry-Logik nicht selbst bauen willst, ist ein leichtgewichtiges Fetch-Wrapper-Paket, das Retry, Timeout, Hooks und HTTPError direkt mitbringt — ohne Abhängigkeiten.
Connection Reuse mit Undicis Agent und Pool
Für Schleifen mit hohem Durchsatz — Hunderte Seiten scrapen, eine API in einem Batch aufrufen, einen Dienst pollen — spart die Wiederverwendung von TCP-Verbindungen viel Zeit. Jede neue Verbindung bedeutet einen frischen DNS-Lookup, einen TCP-Handshake und bei HTTPS eine TLS-Verhandlung.
Da Node-Fetch von Undici angetrieben wird, kannst du einen benutzerdefinierten Dispatcher übergeben:
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});Für noch mehr Kontrolle bei einem bestimmten Origin:
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// Wenn fertig:
7await pool.close();Die zeigen, dass Connection Reuse und Pooling den Durchsatz massiv verbessern können — undici - dispatch lag in ihrem lokalen Benchmark bei etwa 22.234 req/s gegenüber etwa 5.904 req/s bei undici - fetch. Reale Werte schwanken, aber die Richtung ist klar: Wenn du viele Anfragen an denselben Origin sendest, ist Pooling wichtig.
Noch etwas: Response-Bodies immer konsumieren oder abbrechen. Nicht konsumierte Bodies können in den HTTP-Interna von Node zu Ressourcenlecks führen.
Streaming-Antworten mit der Node.js Fetch API
Große Datei-Downloads, in Chunks gelieferte JSON-Feeds, Server-Sent Events, LLM-Ausgaben — in all diesen Fällen verschwendet es Zeit und Speicher, erst die komplette Antwort abzuwarten. Streaming erlaubt dir, Daten zu verarbeiten, sobald sie eintreffen.
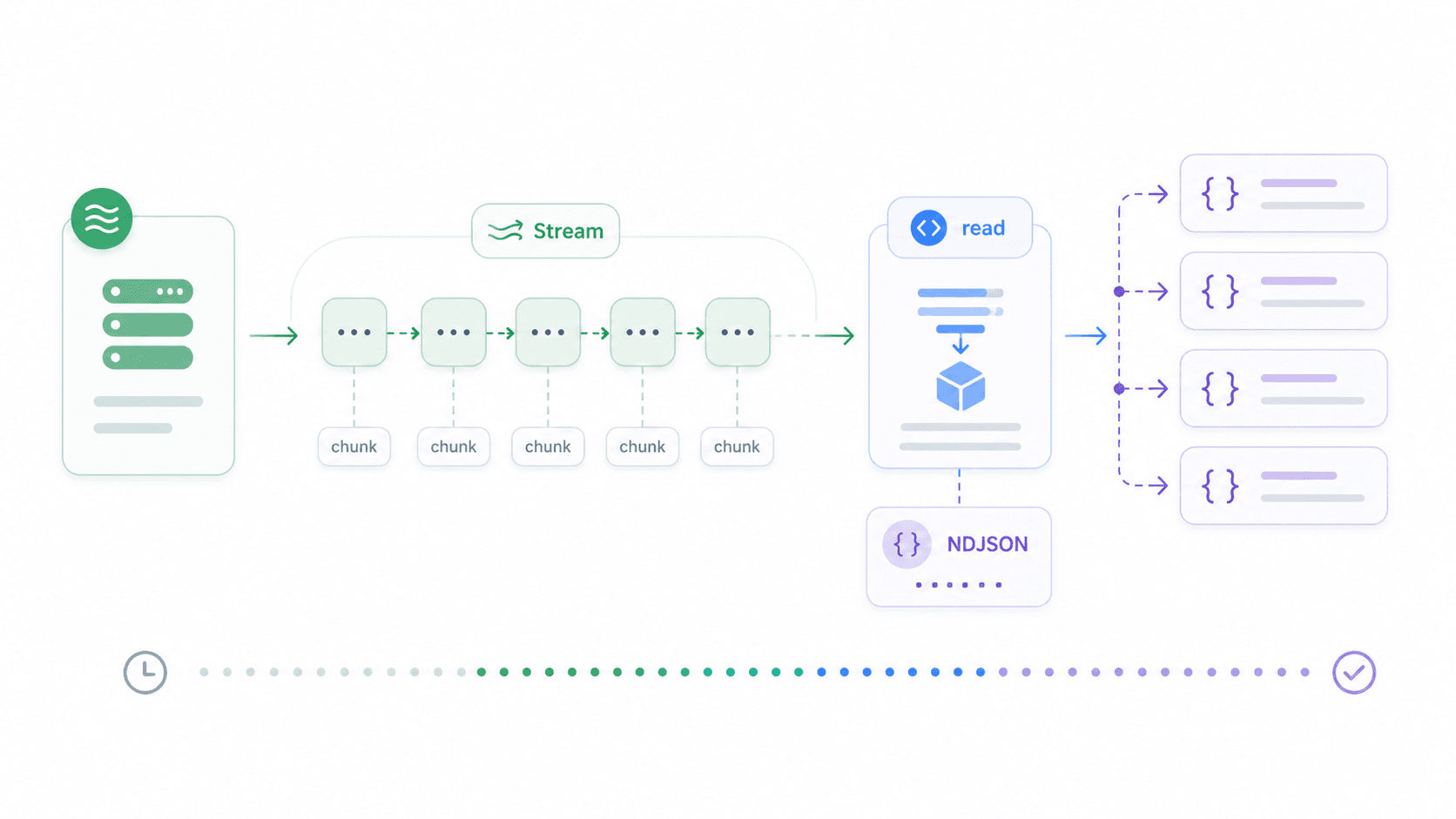
Node 18+ enthält einen browserkompatiblen ReadableStream. So streamst du eine newline-delimited-JSON-Antwort und verarbeitest jede Zeile sofort beim Eintreffen:
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Verarbeitet:', item.id);
17 }
18 }
19}Für einfaches Text-Streaming (z. B. LLM-Ausgabe an stdout weiterleiten):
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}Streaming ist ein Bereich, in dem sowohl natives fetch als auch Got glänzen. Die Streaming-Unterstützung von Axios ist stärker eingeschränkt.
Wenn fetch() an seine Grenzen stößt: Strukturierte Web-Scraping mit APIs
Irgendwann ist fetch nicht mehr der Engpass. Das eigentliche Problem wird dann: „Ich habe HTML — und jetzt?“
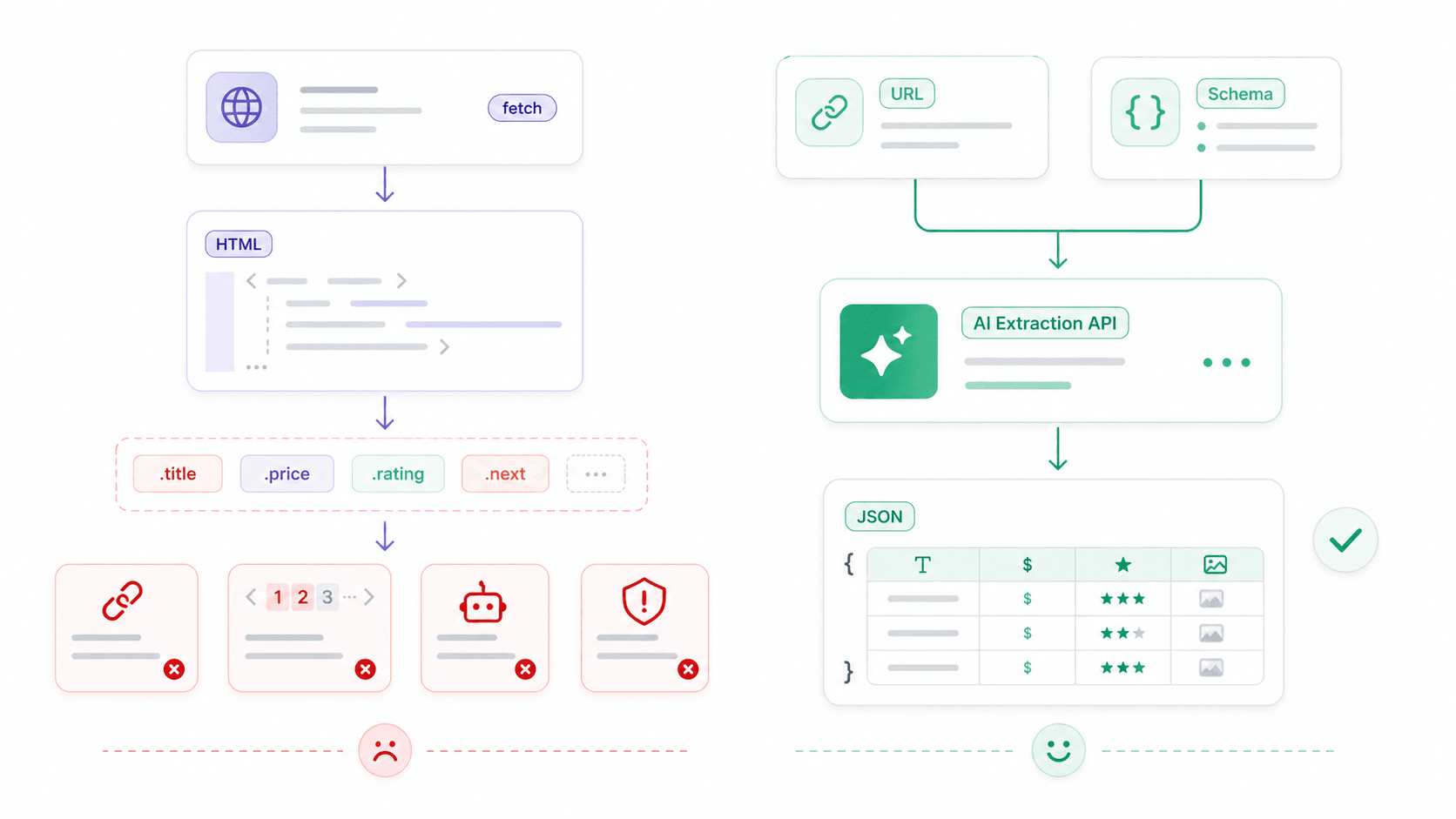
Fetch ist ein HTTP-Client — er holt Bytes, Text, JSON oder HTML. Er kennt weder Produktkarten noch Preise, Bewertungen oder Kontakttabellen. Für strukturiertes Web Scraping sieht der typische rohe Stack so aus:
fetch()zum Herunterladen von HTML- Cheerio (oder ähnliches), um Elemente mit CSS-Selektoren auszuwählen
- Eigene Paginierungslogik
- JavaScript-Rendering, wenn Seiten clientseitig gerendert werden
- Proxy-/Anti-Bot-/CAPTCHA-Behandlung
- Pflege der Selektoren, sobald sich das Layout der Website ändert
Hier ist ein typisches Fetch+Cheerio-Beispiel — etwa 15 Zeilen, um Produkttitel zu scrapen:
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);Das funktioniert für stabile Seiten mit vorhersagbarem HTML. Es wird aber schnell fragil — clientseitig gerenderte Inhalte, wechselnde Klassennamen, Anti-Bot-Maßnahmen und Paginierung erhöhen die Komplexität.
Thunderbits Open API: Von rohem HTML zu strukturierten Daten in einem Aufruf
Hier wird ein anderes Werkzeug nützlich. Bei haben wir eine API-Schicht gebaut, die die schwierigen Teile übernimmt — JavaScript-Rendering, Anti-Bot-Schutz, Layout-Änderungen — damit du dich auf die Daten konzentrieren kannst, die du wirklich willst.
Distill API (POST /distill): Wandelt jede URL in sauberes Markdown um. Nützlich für LLMs, Wissensdatenbanken oder Inhaltsanalysen — kein HTML-Parser nötig.
Extract API (POST /extract): Du definierst ein JSON-Schema für die strukturierten Daten, die du möchtest (Produktname, Preis, Bewertung), und KI extrahiert sie. Keine CSS-Selektoren, kein Bruch bei Layout-Änderungen.
Hier ist dieselbe Produkt-Scraping-Aufgabe mit Thunderbits Extract API — aufgerufen mit nativem fetch:
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Produktname' },
19 price: { type: 'string', description: 'Angezeigter Produktpreis' },
20 rating: { type: 'number', description: 'Durchschnittliche Kundenbewertung' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API: $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);Der Vergleich: etwa 15 Zeilen Fetch+Cheerio (plus fragile Selektoren) versus ein einzelner API-Aufruf, der sauberes JSON zurückgibt. Für Batch-Jobs unterstützt Thunderbit bis zu 50 URLs pro Batch-Extract-Aufruf und bis zu 100 URLs pro Batch-Distill-Aufruf.
Thunderbit ist kein Ersatz für fetch — fetch ist der Transport. Thunderbit ist die Extraktionsschicht, zu der du greifst, wenn rohes HTML-Parsen zum eigentlichen Problem wird. Wenn du dich für die Preise interessierst: Die gibt dir 600 API-Einheiten zum Ausprobieren, und bezahlte Pläne beginnen bei 6 $/Monat. Du kannst dir auch die ansehen, um ohne Code direkt im Browser zu extrahieren.
Mehr zu strukturierten Scraping-Ansätzen findest du in unseren Leitfäden zu den , und , die konkrete Workflows im Detail abdecken.
Schnellreferenz: Node.js Fetch API Spickzettel
Dieser Abschnitt ist zum Bookmarken gedacht. Komm zurück, wenn du ein Muster zum Kopieren und Einfügen brauchst.
| Muster | Snippet |
|---|---|
| Einfaches GET | const res = await fetch(url); const data = await res.json(); |
| Einfaches POST | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| HTTP-Fehlerprüfung | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (einfach) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Manueller Abbruch | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Retry-Statuscodes | 408, 429, 500, 502, 503, 504 erneut versuchen. POST nicht blind retryen. |
| JSON-Wrapper | Verwende fetchJSON(), um ok zu prüfen, den Content-Type zu parsen und HTTPError auszulösen. |
| Connection Pool | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Stream-Chunks | const reader = res.body.getReader(); in einer Schleife await reader.read() |
| Strukturierte Extraktion | Verwende die Thunderbit Extract API, wenn es um Felder von einer Webseite geht und nicht um rohes HTML. |
Fazit und wichtigste Erkenntnisse
Natives fetch in Node.js ist 2026 produktionsreif — kein node-fetch mehr für neue Projekte nötig, keine Standard-Axios-Abhängigkeit erforderlich. Aber reines fetch() allein ist noch keine produktionsreife HTTP-Strategie.
Die fünf Dinge, die die meisten Tutorials auslassen — und die dieser Leitfaden abdeckt:
- Der Fehler-Fallstrick:
fetch()wirft bei 4xx/5xx nicht. Prüfe immerresponse.okoder nutze einen Wrapper wiefetchJSON(). - Timeouts: Verwende
AbortSignal.timeout()für einfache Fälle.AbortSignal.timeout()wirftTimeoutError; ein manuellescontroller.abort()wirftAbortError. - Retry-Logik: Nicht eingebaut. Füge exponentielles Backoff für idempotente Anfragen und vorübergehende Fehler hinzu. Oder nutze Ky für fetch-ähnliches Retry direkt ab Werk.
- Connection Reuse: Für Schleifen mit hohem Durchsatz nutze Undicis
AgentoderPoolüber die Optiondispatcher. - Strukturierte Extraktion: Wenn du Daten aus Webseiten brauchst, nicht nur rohes HTML, erwäge eine Extraktions-API wie Thunderbit statt fragiler CSS-Selektoren.
Die Entscheidungs-Matrix in einem Satz: Verwende natives fetch für die meisten Projekte, Axios für Interceptor, Got für eingebautes Retry und HTTP/2, Ky für fetch mit besseren Standardwerten und Thunderbits API, wenn deine fetch-basierten Scraping-Skripte zu komplex werden, um sie wartbar zu halten.
Probiere die Muster aus diesem Leitfaden aus. Und wenn du sehen willst, wie Thunderbit strukturierte Extraktion handhabt, ist die ein guter Startpunkt — oder schau dir eine Einführung auf dem an.
FAQs
1. Ist fetch in Node.js eingebaut oder muss ich es installieren?
Fetch ist ab Node.js 18 eingebaut — keine Installation nötig. Es wurde in Node 21 stabil und wird in Node 22 LTS und Node 24 LTS vollständig unterstützt. Für ältere Node-Versionen kannst du das npm-Paket node-fetch verwenden, aber neue Projekte sollten auf eine gepflegte LTS-Version abzielen.
2. Wirft fetch bei 404- oder 500-Antworten einen Fehler?
Nein. Fetch lehnt sein Promise nur bei Fehlern auf Netzwerkebene ab (DNS-Fehler, keine Verbindung, abgebrochene Anfragen). HTTP-Antworten wie 404, 403 und 500 werden normal aufgelöst, mit response.ok === false. Du musst response.ok oder response.status explizit prüfen — oder einen Wrapper wie die in diesem Leitfaden gezeigte Funktion fetchJSON() verwenden.
3. Wie füge ich in Node.js ein Timeout zu fetch hinzu?
Der einfachste Ansatz ist AbortSignal.timeout(ms), verfügbar ab Node 18.11+: await fetch(url, { signal: AbortSignal.timeout(5000) }). Das wirft einen TimeoutError, wenn die Anfrage länger als 5 Sekunden dauert. Für mehr Kontrolle erstelle manuell einen AbortController und rufe controller.abort() aus einem setTimeout auf. Fange AbortError für das manuelle Muster und TimeoutError für AbortSignal.timeout() ab.
4. Kann ich fetch für Web Scraping in Node.js verwenden?
Ja, aber fetch gibt nur rohes HTML zurück. Du brauchst einen Parser wie Cheerio, um bestimmte Elemente zu extrahieren, plus eigene Logik für Paginierung, clientseitig gerenderte Seiten und Anti-Bot-Maßnahmen. Für strukturierte Datenerfassung in großem Maßstab — wenn du sauberes JSON mit Produktnamen, Preisen oder Kontaktdaten willst — solltest du in Betracht ziehen, die KI verwendet, um strukturierte Daten ohne CSS-Selektoren oder layoutabhängigen Code zurückzugeben.
5. Sollte ich 2026 von Axios auf natives fetch umsteigen?
Für neue Projekte auf Node 22+ ist natives fetch eine starke Standardwahl. Es kommt ohne Abhängigkeiten aus, basiert auf Promises und nutzt dieselbe API wie das Browser-Fetch. Behalte Axios, wenn du auf Request-/Response-Interceptor, standardmäßige HTTP-Fehler-Rejektion oder Rückwärtskompatibilität mit älteren Node-Versionen angewiesen bist. Beides sind valide Optionen — die Entscheidung hängt davon ab, welche Funktionen dein Projekt tatsächlich nutzt.
Mehr erfahren