Das Tempo der digitalen Nachrichten von heute ist schlicht atemberaubend. Jede Minute erscheinen, werden aktualisiert oder still und leise überarbeitet Tausende von Schlagzeilen – in Mainstream-Medien, Nischenblogs und Social-Media-Feeds.
Zur Einordnung: verarbeitet jeden Tag über 4 Millionen Nachrichtenartikel, während das Nachrichten in über 100 Sprachen erfasst und seinen globalen Feed alle 15 Minuten aktualisiert.
Für alle in Medien, Forschung oder Business Intelligence fühlt sich der Versuch, diesen Datenstrom manuell im Griff zu behalten, an, als würde man ein sinkendes Schiff mit einem Kaffeebecher ausschöpfen.
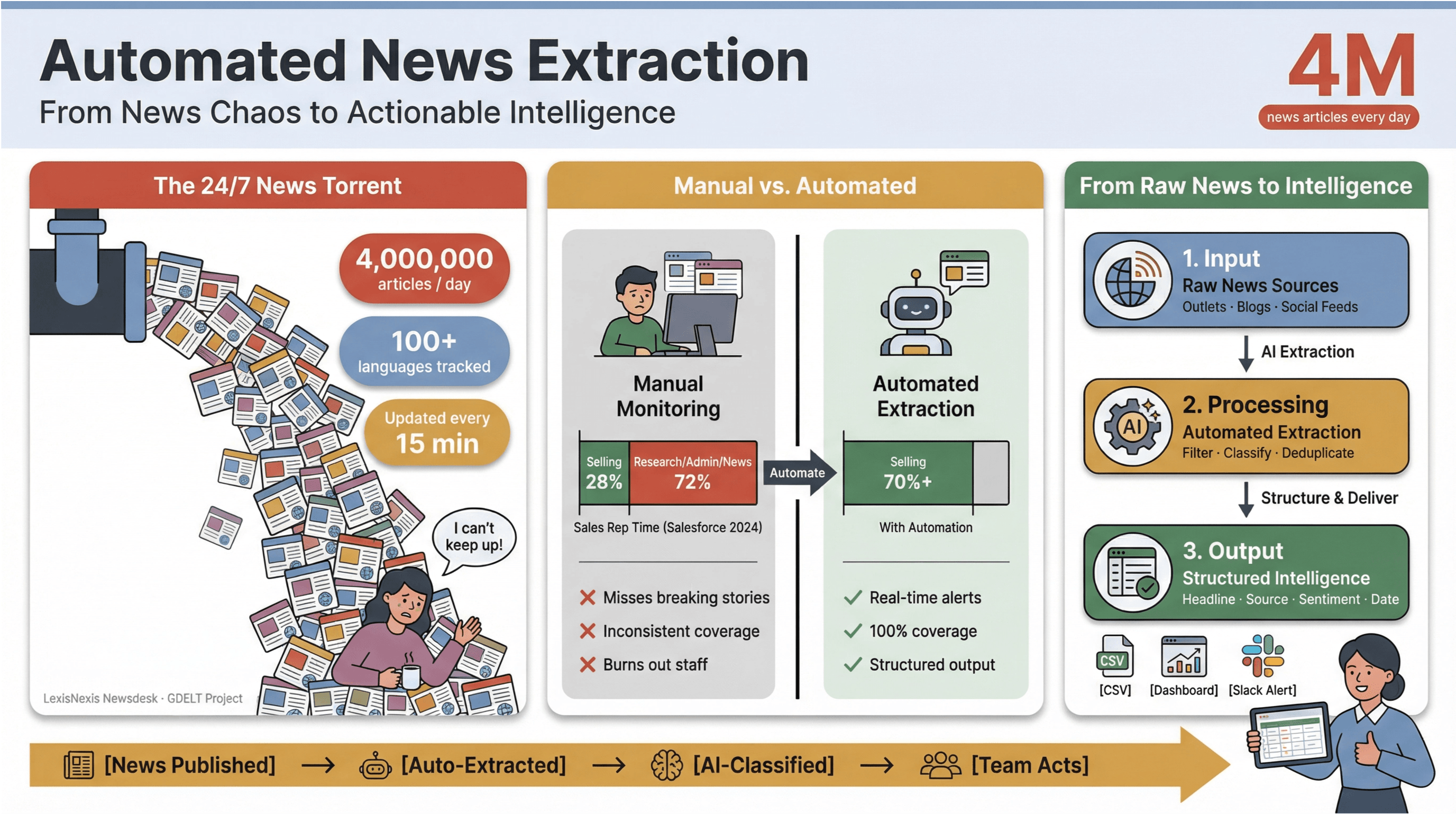
Ich habe aus erster Hand erlebt, wie manuelle Nachrichtenüberwachung Zeit frisst und Ressourcen bindet. Vertriebsteams verbringen weniger als ein Drittel ihrer Woche tatsächlich mit Verkaufen – – der Rest geht für Recherche, Administration und ja, auch für das endlose Jonglieren mit News-Tabs drauf.
Genau deshalb ist automatisierte News-Extraktion für moderne Teams zum Geheimwerkzeug geworden: Nur so lässt sich das Chaos des 24/7-Newszyklus in strukturierte, handlungsrelevante Erkenntnisse verwandeln – ohne das Team auszubrennen oder die wichtigsten Geschichten zu verpassen.
Schauen wir uns an, was automatisierte News-Extraktion wirklich bedeutet, warum sie für alle, die auf Echtzeit-Nachrichtendaten angewiesen sind, unverzichtbar ist, und wie sich mit den besten Tools ein robuster, rechtssicherer Workflow aufbauen lässt – inklusive der Frage, wie den gesamten Prozess verblüffend einfach macht, sogar für Nicht-Techniker wie meine Mutter.
Automatisierte News-Extraktion: Warum sie für moderne Redaktionen unverzichtbar ist
Automatisierte News-Extraktion ist genau das, wonach es klingt: Mithilfe von Software werden Nachrichteninhalte automatisch gesammelt und in strukturierte, durchsuchbare Daten verwandelt – also in Zeilen und Spalten statt in unübersichtlichen Webseiten oder PDFs. In der Praxis heißt das: Sie können Hunderte oder Tausende von Quellen überwachen, wichtige Felder wie Überschrift, Zeitstempel, Autor und Fließtext extrahieren und diese Daten in Dashboards, Alarme oder nachgelagerte Analysen einspeisen – ganz ohne je Ctrl+C/Ctrl+V zu benutzen.
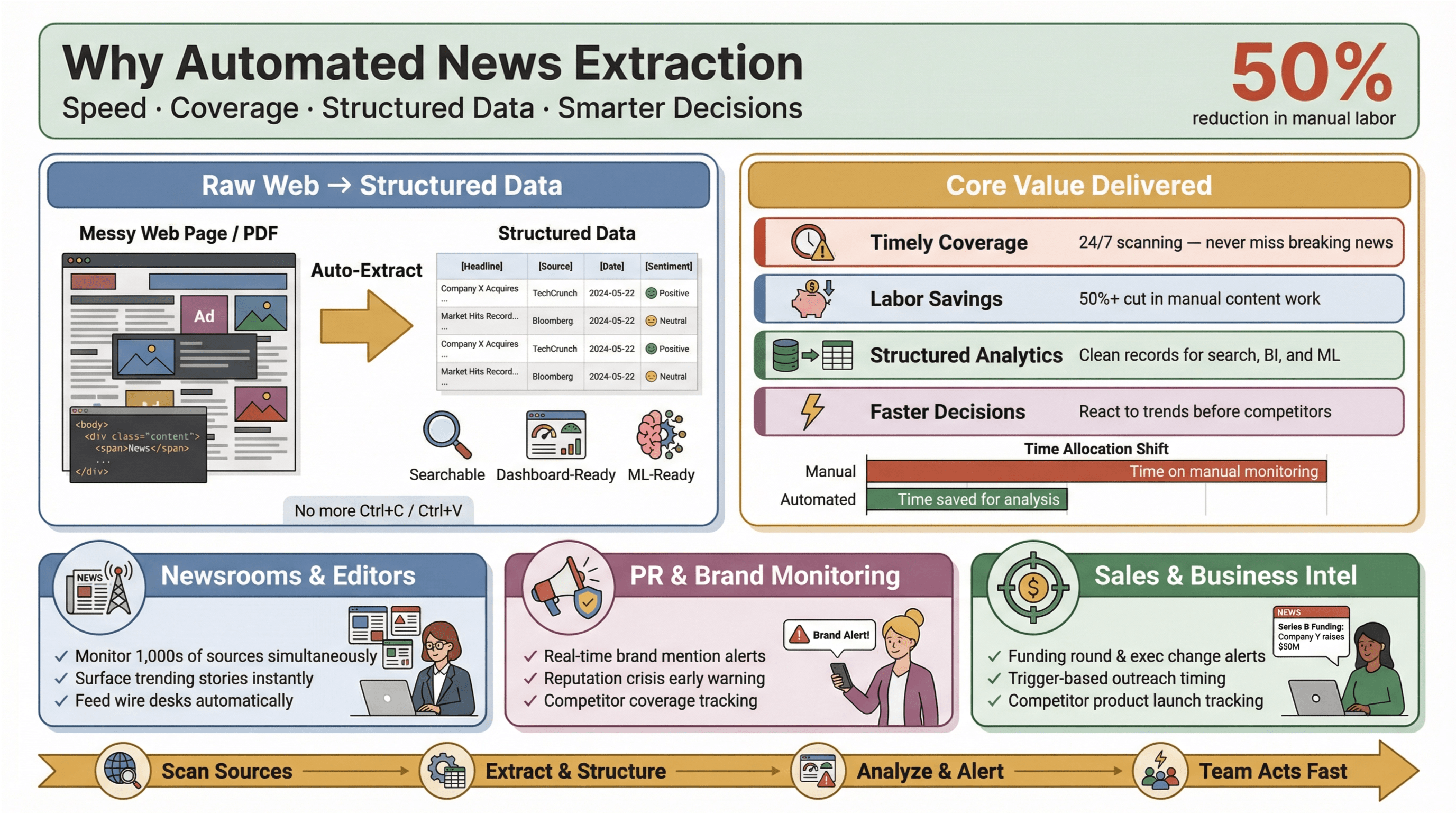 Warum ist das wichtig? Weil in der heutigen Nachrichtenlandschaft Geschwindigkeit alles ist. Ob Sie Redakteur:in in einer Newsroom-Umgebung sind, im PR-Management Markenmentions beobachten oder als Business Analyst Wettbewerbsbewegungen verfolgen: Wer zuerst Bescheid weiß, sichert sich oft den entscheidenden Vorteil. Automatisierte Extraktionstools ermöglichen es selbst kleinen Teams, über sich hinauszuwachsen – indem sie Echtzeit-Nachrichtendaten aus dem Web sammeln, manuelle Arbeit reduzieren und die wichtigsten Stories sichtbar machen.
Warum ist das wichtig? Weil in der heutigen Nachrichtenlandschaft Geschwindigkeit alles ist. Ob Sie Redakteur:in in einer Newsroom-Umgebung sind, im PR-Management Markenmentions beobachten oder als Business Analyst Wettbewerbsbewegungen verfolgen: Wer zuerst Bescheid weiß, sichert sich oft den entscheidenden Vorteil. Automatisierte Extraktionstools ermöglichen es selbst kleinen Teams, über sich hinauszuwachsen – indem sie Echtzeit-Nachrichtendaten aus dem Web sammeln, manuelle Arbeit reduzieren und die wichtigsten Stories sichtbar machen.
Und der Effekt ist real: Studien zeigen, dass Automatisierung den manuellen Aufwand für Content-Updates um mindestens 50 % senken kann – und so Zeit für echte Analyse und Entscheidungen freisetzt.
Der zentrale Nutzen automatisierter News-Extraktion in der Nachrichtenbranche
Wird’s praktisch: Was liefert automatisierte News-Extraktion Redaktionen und Business-Teams konkret?
- Aktuelle, umfassende Abdeckung: Keine verpassten Eilmeldungen mehr, nur weil jemand vergessen hat, einen Feed zu prüfen. Automatisierte Tools scannen Quellen rund um die Uhr und stellen sicher, dass Ihnen nichts entgeht.
- Arbeits- und Kosteneinsparungen: Kleine und mittlere Teams können so viele Quellen überwachen wie die Großen – ohne eine Heerschar von Praktikant:innen einzustellen.
- Strukturierte Daten für Analysen: Statt unstrukturierte Artikel durchzusehen, erhalten Sie saubere, strukturierte Datensätze, die direkt für Suche, Dashboards und Machine Learning bereit sind.
- Schnellere, bessere Entscheidungen: Echtzeit-Nachrichtendaten bedeuten, dass Sie auf Marktbewegungen, PR-Krisen oder neue Trends reagieren können, bevor es die Konkurrenz tut.
Ein Beispiel aus PR und Kommunikation: Plattformen wie und positionieren Echtzeit-Medienmonitoring als unverzichtbar, um Reputation zu schützen und auf kritische Berichterstattung schnell zu reagieren. Im Vertrieb werden Echtzeit-News-Alerts zu „Context Cards“ für das Prospecting – etwa bei Finanzierungsrunden, Führungswechseln oder Produktlaunches, die genau im richtigen Moment eine Kontaktaufnahme auslösen.
Die richtigen News-Scraping-Tools für unterschiedliche Szenarien auswählen
Nicht alle News-Scraping-Tools sind gleich. Die richtige Wahl hängt von Ihren Zielen, Ihrem technischen Komfort und den Nachrichtenarten ab, die für Sie relevant sind. Diese Struktur hilft bei der Auswahl:
Bedienbarkeit und Zugänglichkeit bewerten
Für die meisten Business-Anwender und Journalist:innen ist einfach zu bedienen nicht verhandelbar. Sie wollen ein Tool, das sofort funktioniert – ohne Programmierung oder komplizierte Einrichtung. No-Code- und Low-Code-Plattformen wie , und lassen sich visuell bedienen: zeigen, klicken, extrahieren.
Thunderbit sticht besonders durch seinen Zwei-Schritte-Prozess hervor: Beschreiben, was Sie möchten, die KI passende Felder vorschlagen lassen und auf „Scrape“ klicken. Selbst technisch nicht versierte Nutzer können so in Minuten statt in Stunden eine News-Datenpipeline einrichten.
Sicherheit und Datenschutz berücksichtigen
Mit großen Daten kommt große Verantwortung. News-Scraping-Tools greifen oft auf sensible Inhalte zu, deshalb sollten Sicherheit und Compliance ganz oben auf der Prioritätenliste stehen. Achten Sie auf:
- Datenverschlüsselung (bei Übertragung und Speicherung)
- Klare Datenschutzrichtlinien (Thunderbit erklärt beispielsweise, keine Nutzerdaten zu verkaufen und nur auf Inhalte zuzugreifen, die Sie auswählen)
- Feingranulare Berechtigungen (besonders bei Browser-Erweiterungen – prüfen Sie immer, worauf das Tool zugreifen kann)
- Einhaltung lokaler Gesetze (DSGVO, CCPA und für Nutzer in der EU die )
Für zusätzliche Sicherheit wählen Sie seriöse Anbieter, prüfen Sie Erweiterungsberechtigungen und beschränken Sie den Zugriff auf das notwendige Minimum.
Tools an Nachrichtentypen und Branchenanforderungen anpassen
Manche Tools sind in bestimmten Nachrichtenbereichen besonders stark:
- Finanzen: APIs wie und bieten Clustering, Sentiment-Analyse und Ereigniserkennung für Finanznachrichten.
- Tech & Startups: Individuelles Scraping mit Thunderbit oder Octoparse eignet sich für Nischenblogs, Pressemitteilungen oder Veranstaltungslisten.
- Politik & Regulierung: Lizenzierte Datenbanken wie und bieten Zugriff auf Premiumquellen und Archive.
Wenn Sie ein Gemisch aus Mainstream-, Nischen- und internationalen Quellen überwachen müssen – auch solche ohne APIs – sind flexible, KI-gestützte Scraper wie Thunderbit die beste Wahl.
Thunderbits besondere Vorteile für die Extraktion von Echtzeit-Nachrichtendaten
Jetzt schauen wir uns an, was Thunderbit zu einer herausragenden Wahl für automatisierte News-Extraktion macht – besonders dann, wenn Sie Echtzeit-Nachrichtendaten ohne technischen Stress möchten.
Thunderbit ist eine KI-gestützte Web-Scraper-Chrome-Erweiterung, entwickelt für Business-Anwender, Journalist:innen und Analyst:innen, die aktuelle, strukturierte Nachrichteninhalte von jeder Website benötigen. Deshalb ist sie für mich zum Standard geworden:
- KI-Feldvorschläge: Thunderbit liest die News-Seite und schlägt automatisch die besten Spalten vor – Überschrift, Zeitstempel, Autor, Zusammenfassung und mehr. Kein Herumfummeln mit Selektoren oder Vorlagen nötig.
- Unterseiten-Scraping: Sie brauchen den vollständigen Artikel und nicht nur die Überschrift? Thunderbit kann jeden News-Link aufrufen, den Volltext, Entitäten und Tags extrahieren und alles in einer einzigen strukturierten Tabelle zusammenführen.
- Massenexport & sofortige Aktualisierung: Exportieren Sie Ihre Nachrichtendaten mit einem Klick direkt nach Excel, Google Sheets, Airtable oder Notion. Kein Copy-Paste-Marathon und kein CSV-Chaos mehr.
- Geplantes Scraping: Richten Sie wiederkehrende Jobs ein – stündlich, täglich oder in benutzerdefinierten Intervallen –, damit Ihre News-Pipeline immer frisch bleibt. Ideal für Eilmeldungen, Marktmonitoring oder laufende Recherchen.
- Anpassungsfähigkeit: Thunderbits KI passt sich Layout-Änderungen und Long-Tail-News-Seiten an, sodass Sie weniger Zeit mit kaputten Scrapern und mehr Zeit mit Datenanalyse verbringen.
Mit über und einer Bewertung von 4,8 Sternen vertrauen Teams weltweit darauf – vom PR-Monitoring bis zur Wettbewerbsanalyse.
KI-gestützte Felderkennung und Unterseiten-Scraping
Eine der stärksten Funktionen von Thunderbit ist die KI-gestützte Felderkennung. Ein Klick auf „KI-Felder vorschlagen“ genügt, und das Tool scannt die News-Seite – und erkennt wichtige Felder wie Titel, Datum, Autor und Zusammenfassung. Sie können eigene Felder anpassen oder hinzufügen (etwa: „Kennzeichne diesen Artikel als ‚Earnings‘, wenn er Quartalsergebnisse erwähnt“), und Thunderbits KI erledigt den Rest.
Unterseiten-Scraping ist für Nachrichten ein echter Gamechanger: Scrapen Sie die Startseite oder eine Rubrikenliste für Überschriften, und lassen Sie Thunderbit dann jede Artikel-URL besuchen, um die komplette Story, Entitäten und sogar Bilder zu extrahieren. So erhalten Sie vollständige, angereicherte Nachrichten-Datensätze – bereit für Suche, Dashboards oder nachgelagerte KI-Analysen.
Massenexport und sofortige Aktualisierungen
Thunderbit macht den Export von Nachrichtendaten mühelos. Mit einem Klick senden Sie Ihren strukturierten News-Feed an Google Sheets, Airtable oder Notion oder laden ihn als CSV/Excel herunter. Für Teams, die mit Tabellen oder BI-Tools arbeiten, spart das enorm viel Zeit.
Und weil Thunderbit geplantes Scraping unterstützt, können Sie es stündlich, täglich oder nach einem eigenen Zeitplan ausführen lassen – so bleiben Ihre Nachrichtendaten immer aktuell. Kein Warten mehr darauf, dass Google Alerts Meldungen erst Tage später indexiert.
Operative Herausforderungen bei Echtzeit-Nachrichtendaten lösen
Auch mit den besten Tools bringt Echtzeit-News-Extraktion ihre eigenen Herausforderungen mit. So gehen Sie mit den häufigsten um:
Latenz und Aktualität managen
- Scrapes an der Nachrichtenfrequenz ausrichten: Für Eilmeldungen sollten Scraper alle 15–30 Minuten laufen (analog zum ). Bei langsameren Themen reichen oft tägliche oder stündliche Läufe.
- Verzögerung zwischen Veröffentlichung und Abruf messen: Verfolgen Sie die Zeitspanne zwischen dem Veröffentlichungszeitpunkt eines Artikels und dem Moment, in dem Ihr System ihn erfasst. Wenn die Verzögerung wächst, prüfen Sie Blockaden oder Verlangsamungen.
- Für „stille Änderungen“ erneut scrapen: Nachrichtenartikel werden häufig nach der Veröffentlichung aktualisiert. Planen Sie einen zweiten Scrape 24 Stunden später ein, um Korrekturen oder unauffällige Änderungen zu erfassen ().
API-Limits und Quellenvielfalt bewältigen
- API-Quoten respektieren: Wenn Sie News-APIs verwenden, achten Sie auf Rate Limits – verteilen Sie Anfragen über die Zeit und cachen Sie Ergebnisse, wo möglich ().
- Duplikate entfernen und kanonisieren: Nachrichten erscheinen oft unter mehreren URLs oder werden aktualisiert. Erfassen Sie kanonische URLs und verwenden Sie Hashes (z. B. Titel + Datum), um Duplikate zu vermeiden ().
- Dynamische Inhalte handhaben: Bei Seiten mit Infinite Scroll oder Lazy Loading sollten Sie Tools nutzen, die dynamisches Rendering unterstützen, und Layout-Änderungen überwachen ().
Smarte Analyse von Nachrichtendaten: Die Rolle von KI und Machine Learning
Nachrichten zu extrahieren ist nur der erste Schritt. Der eigentliche Wert entsteht, wenn Sie diese Daten analysieren und darauf reagieren – und genau hier spielen KI und Machine Learning ihre Stärken aus.
- Entitätsextraktion: Nutzen Sie NLP, um Personen, Organisationen und Orte aus jedem Artikel herauszuziehen ().
- Themenklassifizierung: Artikel automatisch nach Thema, Stimmung oder Dringlichkeit taggen – für intelligentere Dashboards und Alarme ().
- Ereignis-Clustering: Gruppieren Sie doppelte oder zusammenhängende Meldungen über verschiedene Medien hinweg, damit Sie das große Ganze sehen – nicht nur eine Flut fast identischer Schlagzeilen.
- Personalisierung und Targeting: Nutzen Sie Echtzeit-Nachrichtendaten, um Zielgruppen zu segmentieren, Anzeigen besser auszusteuern oder Inhalte zu empfehlen – und so Engagement und ROI zu steigern.
PR-Teams verwenden beispielsweise Echtzeit-News-Analysen, um entstehende Krisen zu erkennen, bevor sie viral gehen, während Vertriebsteams ihre Prospect-Listen mit „Trigger Events“ wie Finanzierungsrunden oder Neueinstellungen auf Führungsebene anreichern.
Checkliste: Best Practices für automatisierte News-Extraktion
Hier ist eine kompakte Checkliste, damit Ihre News-Extraktions-Pipeline reibungslos läuft:
| Best Practice | Warum es wichtig ist | Umsetzung |
|---|---|---|
| Häufige Scrapes planen | Datenverzögerung minimieren, Eilmeldungen erfassen | Aktualisierungsfrequenz an das Nachrichten-Tempo anpassen (z. B. alle 15 Min. bei schnellen Themen) |
| KI-gestützte Extraktion nutzen | Passt sich Layout-Änderungen an, reduziert Einrichtungszeit | Tools wie Thunderbit, Diffbot, Zyte API |
| Duplikate entfernen und kanonisieren | Duplikat-Alerts vermeiden, saubere Daten sicherstellen | Kanonische URLs erfassen, Hashes für Deduplikation verwenden |
| Extraktionsqualität überwachen | Fehlende Felder, Drift oder Ausfälle erkennen | Anteil vollständiger Datensätze, Verzögerung und Fehlerraten tracken |
| Rechtliche und Compliance-Grenzen beachten | Rechtsrisiken vermeiden, Vertrauen erhalten | Offizielle APIs/Feeds bevorzugen, Nutzungsbedingungen prüfen, personenbezogene Daten minimieren |
| In strukturierte Formate exportieren | Nachgelagerte Analysen ermöglichen | CSV, Excel, Sheets, Notion, Airtable |
| Nachträgliche Re-Scrapes für Änderungen planen | Veröffentlichte Änderungen erfassen | Artikel nach 24 Std./1 Wo. erneut aufrufen (GDELT-Modell) |
| Ihre Pipeline absichern | Sensible Daten schützen | Verschlüsselung, Zugriffskontrollen, seriöse Tools |
Eine robuste automatisierte News-Extraktions-Workflows aufbauen
Bereit, Ihre eigene Blackbox für Nachrichtendaten zu bauen? So sieht ein Schritt-für-Schritt-Workflow aus:
- Quellen identifizieren: Listen Sie die News-Seiten, Blogs oder APIs auf, die Sie überwachen möchten.
- Extraktion einrichten: Verwenden Sie Thunderbit oder Ihr bevorzugtes Tool, um Felder zu definieren (KI-Feldvorschläge machen das besonders einfach).
- Scrapes planen: Legen Sie die Frequenz nach Nachrichten-Tempo fest – stündlich für Eilmeldungen, täglich für langsamere Themen.
- Unterseiten anreichern: Scrapen Sie zu jeder Schlagzeile den vollständigen Artikel für Fließtext, Entitäten und Tags.
- Duplikate entfernen und normalisieren: Kanonische URLs erfassen, Datensätze hashen und Felder standardisieren.
- Exportieren und integrieren: Strukturierte Daten für Analysen an Excel, Google Sheets, Airtable oder Notion senden.
- Überwachen und anpassen: Extraktionsqualität tracken, auf Layout-Änderungen achten und bei Bedarf nachjustieren.
- Konform bleiben: Nutzungsbedingungen prüfen, robots.txt respektieren und personenbezogene Daten minimieren.
Für einen visuellen Ablauf stellen Sie sich einfach vor:
Quellen → Extraktion (KI-Felder) → Unterseiten-Anreicherung → Deduplikation → Export → Analyse/Alarme → Monitoring
Fazit und wichtigste Erkenntnisse
Automatisierte News-Extraktion ist längst kein „Nice-to-have“ mehr – sondern Pflicht für alle, die in einer Welt auf dem Laufenden bleiben müssen, in der Nachrichten im Minutentakt entstehen und sich verändern. Wenn Sie Best Practices befolgen und die richtigen Tools einsetzen, verwandeln Sie den digitalen Nachrichten-Feuerhahn in einen konstanten Strom handlungsrelevanter, strukturierter Informationen.
Wichtigste Erkenntnisse:
- Der Umfang und das Tempo von Online-News erfordern Automatisierung – manuelles Monitoring kommt einfach nicht mit.
- Automatisierte News-Extraktion spart Zeit, senkt Kosten und ermöglicht kleinen Teams eine Reichweite, die sonst nur deutlich größeren Organisationen vorbehalten wäre.
- Die Wahl des richtigen Tools bedeutet, Benutzerfreundlichkeit, Sicherheit und Anpassungsfähigkeit auszubalancieren – Thunderbit überzeugt durch KI-gestützte Einfachheit und Echtzeit-Exportoptionen.
- Bauen Sie Ihren Workflow rund um Aktualität, Deduplikation, Compliance und Qualitätskontrolle auf, um zuverlässige, nutzbare Nachrichtendaten sicherzustellen.
- KI und Machine Learning erschließen noch mehr Wert – mit smarterem Targeting, mehr Personalisierung und besseren Entscheidungen.
Wenn Sie immer noch Schlagzeilen per Copy-Paste übernehmen oder darauf warten, dass Google Alerts hinterherkommt, ist es Zeit für das nächste Level. und sehen Sie selbst, wie einfach automatisierte News-Extraktion sein kann. Weitere Tipps, Workflows und Deep Dives finden Sie im .
FAQs
1. Was ist automatisierte News-Extraktion und wie funktioniert sie?
Automatisierte News-Extraktion ist der Prozess, bei dem Software eingesetzt wird, um Nachrichtenartikel zu sammeln und sie in strukturierte Daten wie Tabellen oder JSON für Analysen, Suche oder Benachrichtigungen zu verwandeln. Tools wie Thunderbit nutzen KI, um wichtige Felder wie Überschrift, Zeitstempel, Autor und Fließtext zu erkennen und automatisch aus Webseiten oder APIs zu extrahieren.
2. Warum sind Echtzeit-Nachrichtendaten für Unternehmen so wichtig?
Echtzeit-Nachrichtendaten ermöglichen es Unternehmen, schnell auf Marktbewegungen, PR-Krisen oder Wettbewerberaktionen zu reagieren. Ob im Vertrieb, in der PR oder in der Forschung: Aktuelle Nachrichten helfen dabei, schneller und klüger zu entscheiden und einen Schritt voraus zu bleiben.
3. Wie macht Thunderbit das News-Scraping für nicht-technische Nutzer einfacher?
Thunderbit bietet einen einfachen Zweischritt-Prozess: Beschreiben Sie, welche Daten Sie brauchen, und lassen Sie sich von der KI passende Felder vorschlagen. Mit Funktionen wie Unterseiten-Scraping und sofortigem Export nach Excel oder Google Sheets können selbst nicht-technische Nutzer in Minuten robuste News-Datenpipelines aufbauen.
4. Welche rechtlichen und Compliance-Aspekte gelten beim News-Scraping?
Prüfen Sie immer die Nutzungsbedingungen der Zielseiten, bevorzugen Sie offizielle APIs oder Feeds, wenn verfügbar, und respektieren Sie robots.txt-Vorgaben. Scrapen Sie keine Login-geschützten oder bezahlpflichtigen Inhalte ohne Erlaubnis und minimieren Sie die Erhebung personenbezogener Daten, um Datenschutzgesetze einzuhalten.
5. Wie stelle ich sicher, dass mein News-Extraktions-Workflow langfristig zuverlässig bleibt?
Planen Sie regelmäßige Scrapes, überwachen Sie die Extraktionsqualität und nutzen Sie Tools, die sich an Layout-Änderungen anpassen (wie Thunderbits KI-gestützte Extraktion). Entfernen Sie Duplikate, messen Sie die Verzögerung zwischen Veröffentlichung und Extraktion und richten Sie Alarme für Ausfälle oder fehlende Felder ein, damit Ihre Pipeline gesund und aktuell bleibt.
Mehr erfahren