

Web-Scraping war lange eine Nischenfähigkeit. Heute ist es für Teams im Vertrieb, in den Operations oder in der Marktforschung praktisch zur Grundausstattung geworden. Kein Wunder, denn die Datenmengen im Netz explodieren förmlich: Zwischen 2019 und 2023 stieg die globale Datenerzeugung um fast 193 %, und inzwischen bezeichnen 81 % der Unternehmen Daten als das „Herz“ ihrer Entscheidungsfindung. Der Haken dabei: 95 % der Organisationen tun sich schwer mit unstrukturierten Daten – also etwa mit chaotischem HTML. Ich habe genug Teams gesehen, die in endlosen Copy-and-Paste-Runden versuchen, Website-Informationen in Tabellen zu pressen. Schön anzusehen ist das nicht.
Daten von jeder Website mit KI extrahieren Get Started Free
An dieser Stelle kommt BeautifulSoup in Python ins Spiel. In diesem praxisnahen Tutorial zeige ich Ihnen, wie Sie BeautifulSoup fürs Web-Scraping einsetzen – inklusive eines konkreten Python-Beautiful-Soup-Beispiels, das Sie an Ihre eigenen geschäftlichen Anforderungen anpassen können. Und weil ich lieber clever als mühsam arbeite, zeige ich Ihnen außerdem, wie Sie BeautifulSoup mit Thunderbit, unserem KI-gestützten Web-Scraper, kombinieren, um Ihren Workflow zu beschleunigen und sauberere, besser strukturierte Daten zu erhalten – ganz gleich, wie gut Sie programmieren können.
Was ist BeautifulSoup, und warum sollte man es fürs Web-Scraping nutzen?
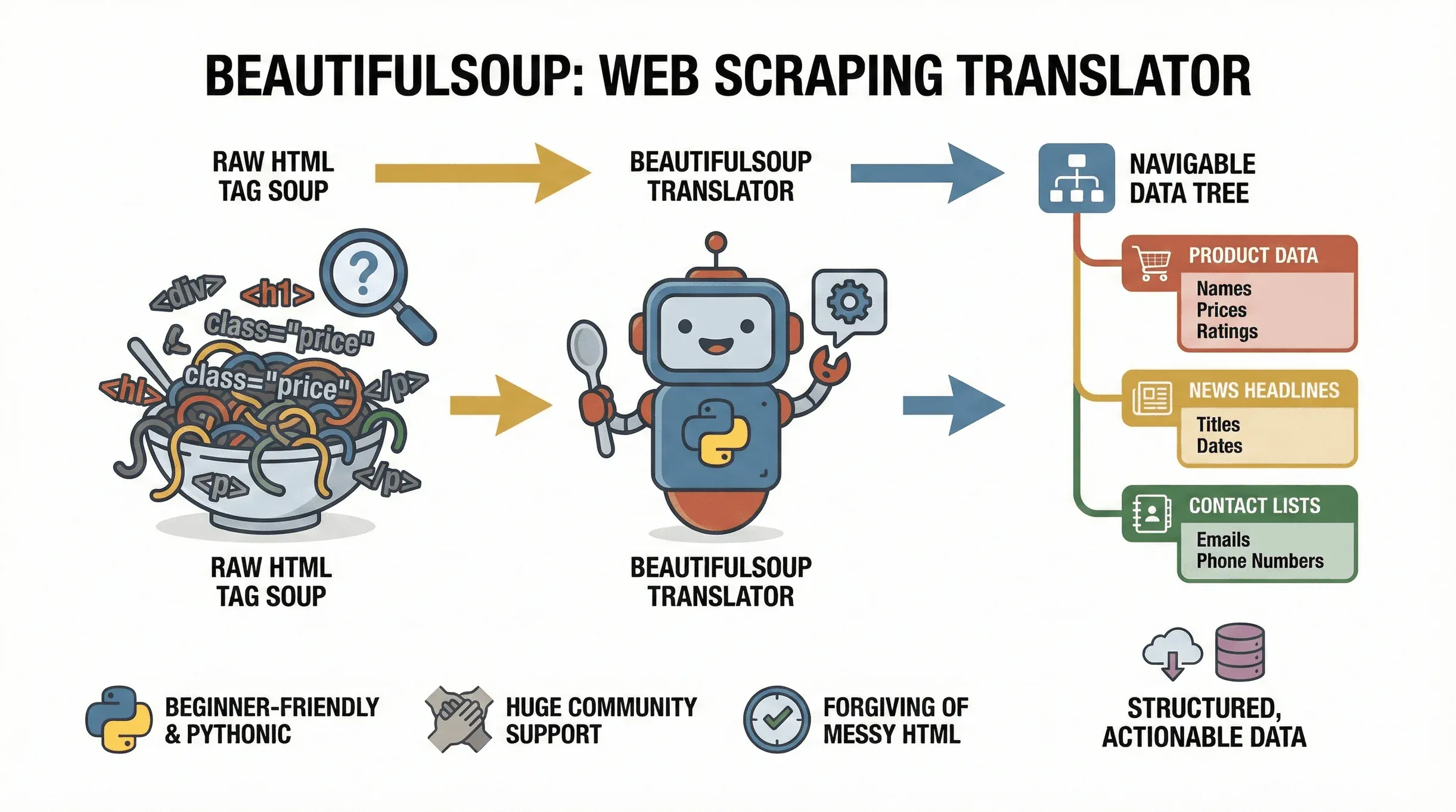 Zunächst die Grundlagen. BeautifulSoup ist eine Python-Bibliothek, die das Parsen von HTML- und XML-Dokumenten erleichtert. Sie funktioniert wie ein Übersetzer: Aus dem „Tag-Wirrwarr“ einer Webseite macht sie einen navigierbaren Baum, in dem Sie die gewünschten Daten leicht finden, extrahieren und bearbeiten können. Das Projekt wird weiterhin aktiv gepflegt —
Zunächst die Grundlagen. BeautifulSoup ist eine Python-Bibliothek, die das Parsen von HTML- und XML-Dokumenten erleichtert. Sie funktioniert wie ein Übersetzer: Aus dem „Tag-Wirrwarr“ einer Webseite macht sie einen navigierbaren Baum, in dem Sie die gewünschten Daten leicht finden, extrahieren und bearbeiten können. Das Projekt wird weiterhin aktiv gepflegt — beautifulsoup4 4.14.3 wurde Ende 2025 auf PyPI veröffentlicht — alles, was Sie hier lernen, ist also auf dem aktuellen Stand. Ob Sie Produktpreise aus einem E-Commerce-Shop ziehen, Nachrichtenüberschriften sammeln oder Branchenverzeichnisse nach Leads durchforsten: BeautifulSoup ist das Mittel der Wahl, um Webseiten in strukturierte, verwertbare Daten zu überführen.
Woher kommt die Beliebtheit? Zum einen ist die Bibliothek extrem einsteigerfreundlich. BeautifulSoup verzeiht fehlerhaftes oder unsauberes HTML, und davon gibt es im Web reichlich. Dank der Python-Syntax kommen Sie in wenigen Codezeilen vom Nullpunkt zum fertigen Scraper. Hinzu kommt die enorme Verbreitung: Millionen Downloads und eine riesige Community sorgen dafür, dass Hilfe meist nur eine Google-Suche entfernt ist, wenn Sie einmal nicht weiterkommen.
Typische Anwendungsfälle für BeautifulSoup sind:
- Produktnamen, Preise und Bewertungen von E-Commerce-Seiten extrahieren
- Nachrichtenüberschriften, Autoren und Veröffentlichungsdaten von Nachrichtenseiten ziehen
- Tabellen oder Verzeichnisse parsen (z. B. Unternehmens- oder Kontaktlisten)
- E-Mails oder Telefonnummern von Verzeichnisseiten sammeln
- Aktualisierungen überwachen (Preisänderungen, neue Stellenanzeigen usw.)
Wenn Ihre Daten in statischem HTML liegen, ist BeautifulSoup Ihr bester Freund fürs Web-Scraping.
Die besonderen Vorteile von BeautifulSoup fürs Web-Scraping
Es gibt zahlreiche Python-Bibliotheken fürs Web-Scraping – warum also BeautifulSoup? Im Vergleich überzeugt es mit diesen Punkten:
- Einfachheit: BeautifulSoup ist leichtgewichtig und schnell gelernt. Sie müssen kein ganzes Framework aufsetzen und keinen Berg an Boilerplate-Code schreiben. Ideal für schnelle, einmalige Scraping-Aufgaben oder für Einsteiger.
- Fehlertoleranz: Es kommt auch mit kaputtem oder fehlerhaftem HTML zurecht, was häufiger vorkommt, als man denkt.
- Flexibilität: Sie sind nicht in eine starre Crawling-Architektur gezwungen. Einfach HTML einspeisen und das Gewünschte extrahieren.
- Integration: BeautifulSoup arbeitet hervorragend mit anderen Python-Bibliotheken wie
requests(zum Abrufen von Webseiten),csv(zum Speichern von Daten) undpandas(für die Datenanalyse) zusammen.
Wie schneidet es im Vergleich zu anderen Tools ab?
| Tool | Am besten geeignet für | Vorteile | Nachteile |
|---|---|---|---|
| BeautifulSoup | Parsing von statischem HTML, Anfänger | Einfach, schneller Start, fehlertolerant, flexibel | Nicht für Seiten mit viel JavaScript geeignet |
| Scrapy | Groß angelegte, asynchrone Jobs | Leistungsstark, skalierbar, integriertes Crawling | Höhere Lernkurve, mehr Setup |
| Selenium | JavaScript-/dynamische Inhalte | Kann mit JS interagieren, Formulare ausfüllen, Buttons klicken | Langsamer, schwerer, ressourcenintensiver |
Wer gerade erst anfängt oder statische Seiten schnell parsen muss, hat in BeautifulSoup das Allzweckwerkzeug des Web-Scrapings vor sich (medium.com). Bei komplexeren oder dynamischen Seiten kombinieren Sie es eventuell mit Selenium oder Scrapy – aber um die Grundlagen zu lernen, führt an BeautifulSoup kaum ein Weg vorbei.
Ihre Python-Umgebung für BeautifulSoup einrichten
So richten Sie Ihre Umgebung ein:
-
Python installieren: Laden Sie die neueste Version von python.org herunter.
-
Eine virtuelle Umgebung einrichten (optional, aber empfohlen):
python -m venv venv source venv/bin/activate # Unter Windows: venv\Scripts\activate -
BeautifulSoup und Abhängigkeiten installieren:
pip install beautifulsoup4 requests lxml html5libbeautifulsoup4: Die Hauptbibliothekrequests: Zum Abrufen von Webseitenlxmloderhtml5lib: Schnellere/zuverlässigere HTML-Parser
-
Tipps zur Fehlersuche:
- Wenn die Fehlermeldung „pip not found“ erscheint, versuchen Sie
pip3oderpy -m pip. - Unter Mac/Linux benötigen Sie möglicherweise
sudofür Berechtigungen. - Unter Windows sollte Python zu Ihrem PATH hinzugefügt sein.
- Wenn die Fehlermeldung „pip not found“ erscheint, versuchen Sie
Um Ihre Einrichtung zu überprüfen, führen Sie diesen kurzen Test aus:
from bs4 import BeautifulSoup
import requests
html = requests.get("http://example.com").text
soup = BeautifulSoup(html, "html.parser")
print(soup.title)
Wenn Sie <title>Example Domain</title> sehen, kann es losgehen (Thunderbit Blog).
Ein Schritt-für-Schritt-Python-Beautiful-Soup-Beispiel
Nun ein echtes Python-Beautiful-Soup-Beispiel. Angenommen, Sie möchten die neuesten Nachrichtenüberschriften von einer öffentlichen Nachrichtenseite extrahieren. So gehen Sie vor:
1. Die Webseite abrufen
import requests
from bs4 import BeautifulSoup
url = "https://www.bbc.com/news"
response = requests.get(url)
html = response.text
2. Das HTML parsen
soup = BeautifulSoup(html, "html.parser")
3. Die HTML-Struktur untersuchen
Öffnen Sie die Entwickler-Tools Ihres Browsers (Rechtsklick → Untersuchen) und suchen Sie nach den Tags, die die Überschriften enthalten. Auf vielen Nachrichtenseiten stehen Überschriften in <h3>-Tags mit bestimmten Klassen.
Zum Beispiel könnte man Folgendes sehen:
<h3 class="gs-c-promo-heading__title">Headline Title</h3>
4. Die Daten extrahieren
headlines = soup.find_all("h3", class_="gs-c-promo-heading__title")
for h in headlines:
print(h.get_text(strip=True))
Das gibt alle Nachrichtenüberschriften auf der Seite aus.
5. Die Daten als CSV speichern
Speichern wir die Überschriften für spätere Analysen:
import csv
with open("headlines.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow(["headline"])
for h in headlines:
writer.writerow([h.get_text(strip=True)])
Jetzt haben Sie eine CSV-Datei, die für Excel oder Google Sheets bereit ist.
HTML-Struktur für effektive Datenextraktion verstehen
Bevor Sie irgendeinen Code schreiben, sollten Sie immer das HTML der Seite untersuchen. So geht’s:
- Entwickler-Tools öffnen: Rechtsklick auf die Seite und „Untersuchen“ auswählen.
- Die Daten finden: Fahren Sie über Elemente, um zu sehen, welche Tags die gewünschten Informationen enthalten (z. B. Überschriften, Preise, Autoren).
- Tags und Klassen notieren: Achten Sie auf eindeutige Kennungen wie
class="product-title"oderid="main-content". - Selektoren testen: Verwenden Sie BeautifulSoups Methoden
.find(),.find_all()oder.select(), um diese Elemente gezielt anzusprechen.
Profi-Tipp: Nutzen Sie soup.prettify(), um eine lesbare Version des HTMLs in Ihrer Python-Konsole auszugeben.
Daten mit BeautifulSoup extrahieren und strukturieren
Angenommen, Sie möchten sowohl Titel als auch Autoren von einer Blogseite extrahieren:
articles = soup.find_all("article")
data = []
for article in articles:
title = article.find("h2").get_text(strip=True)
author = article.find("span", class_="author").get_text(strip=True)
data.append({"title": title, "author": author})
Jetzt haben Sie eine Liste von Dictionaries – perfekt für den Export nach CSV oder für weitere Analysen.
Sie können Links, Bilder oder beliebige Attribute so extrahieren:
for link in soup.find_all("a"):
print(link.get("href"))
Oder Bilder:
for img in soup.find_all("img"):
print(img.get("src"))
Extrahierte Daten speichern: Von Python zu Excel oder CSV
Sobald Ihre Daten strukturiert sind, ist der Export ganz einfach. So geht’s mit dem csv-Modul:
import csv
with open("articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Oder, wenn Sie lieber pandas verwenden:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv("articles.csv", index=False)
df.to_excel("articles.xlsx", index=False)
Verwenden Sie immer UTF-8-Kodierung, um Probleme mit Sonderzeichen zu vermeiden, besonders bei internationalen Daten.
Fallstudie: Nachrichten-Websitedaten mit BeautifulSoup scrapen
Hier ein praktisches Python-Beautiful-Soup-Beispiel: das Scrapen von Artikeltiteln, Autoren und Veröffentlichungsdaten von einer Nachrichtenseite.
Angenommen, Sie möchten CNN nach Artikeldaten scrapen:
import requests
from bs4 import BeautifulSoup
import csv
url = "https://edition.cnn.com/world"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
articles = soup.find_all("article")
data = []
for article in articles:
title_tag = article.find("h3")
date_tag = article.find("span", class_="date")
author_tag = article.find("span", class_="author")
title = title_tag.get_text(strip=True) if title_tag else ""
date = date_tag.get_text(strip=True) if date_tag else ""
author = author_tag.get_text(strip=True) if author_tag else ""
data.append({"title": title, "date": date, "author": author})
with open("cnn_articles.csv", "w", newline='', encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["title", "date", "author"])
writer.writeheader()
for row in data:
writer.writerow(row)
Dieses Skript ruft die neuesten Artikel ab, extrahiert Titel, Datum und Autor und speichert alles als CSV — vorausgesetzt, das aktuelle Markup von CNN verwendet noch die oben genannten Tags. Große Nachrichtenseiten ändern Klassennamen und DOM-Struktur häufig, daher sollten Sie die Seite vor dem Einsatz in der Produktion erneut prüfen. Die Struktur (<article>-Container und anschließend find auf untergeordneten Tags) ist das robuste Muster; die konkreten Klassennamen wie "date" und "author" sind Platzhalter, die Sie anpassen sollten, je nachdem, was die Live-Seite aktuell ausliefert.
Ihren Workflow verbessern: BeautifulSoup mit Thunderbit kombinieren
Wie lässt sich Ihr Scraping-Workflow noch reibungsloser gestalten? Thunderbit ist eine KI-gestützte Web-Scraper-Chrome-Erweiterung, die das Rätselraten bei der Datenerfassung beendet. Mit Thunderbit können Sie:
- „KI-Felder vorschlagen“ verwenden: Thunderbit liest die Seite und schlägt automatisch vor, welche Datenfelder extrahiert werden sollen. Kein Suchen mehr im HTML, kein Herumprobieren mit Selektoren.
- Unterseiten scrapen: Thunderbit kann Links zu Unterseiten verfolgen (z. B. einzelne Produkt- oder Artikelseiten) und Ihren Datensatz mit zusätzlichen Details anreichern.
- Sofort exportieren: Senden Sie Ihre Daten mit einem Klick direkt an Excel, Google Sheets, Airtable oder Notion.
- Paginierung verarbeiten: Thunderbit kann Daten über mehrere Seiten hinweg scrapen, einschließlich unendlichem Scrollen.
- Scrapes planen: Richten Sie wiederkehrende Jobs ein, damit Ihre Daten aktuell bleiben.
Hier ist ein Hybrid-Workflow, den ich sehr schätze:
- Mit Thunderbit starten: Öffnen Sie Ihre Zielseite, klicken Sie auf das Thunderbit-Symbol und lassen Sie „KI-Felder vorschlagen“ die passenden Spalten erkennen (z. B. Titel, Autor, Datum).
- Die Daten exportieren: Laden Sie die Ergebnisse als CSV herunter oder senden Sie sie an Google Sheets.
- BeautifulSoup für die individuelle Nachbearbeitung nutzen: Wenn Sie tiefere Analysen brauchen (z. B. Textbereinigung, Deduplizierung oder das Zusammenführen mit anderen Quellen), laden Sie die exportierte CSV in Python und verwenden Sie BeautifulSoup oder pandas für die Weiterverarbeitung.
Diese Kombination gibt Ihnen das Beste aus beiden Welten: Thundebits Geschwindigkeit und KI-gestützte Felderkennung plus BeautifulSoups Flexibilität für individuelle Logik.
Den KI-Web-Scraper von Thunderbit kostenlos testen
Geschwindigkeit und Datenqualität: Warum Thunderbit und BeautifulSoup zusammen nutzen?
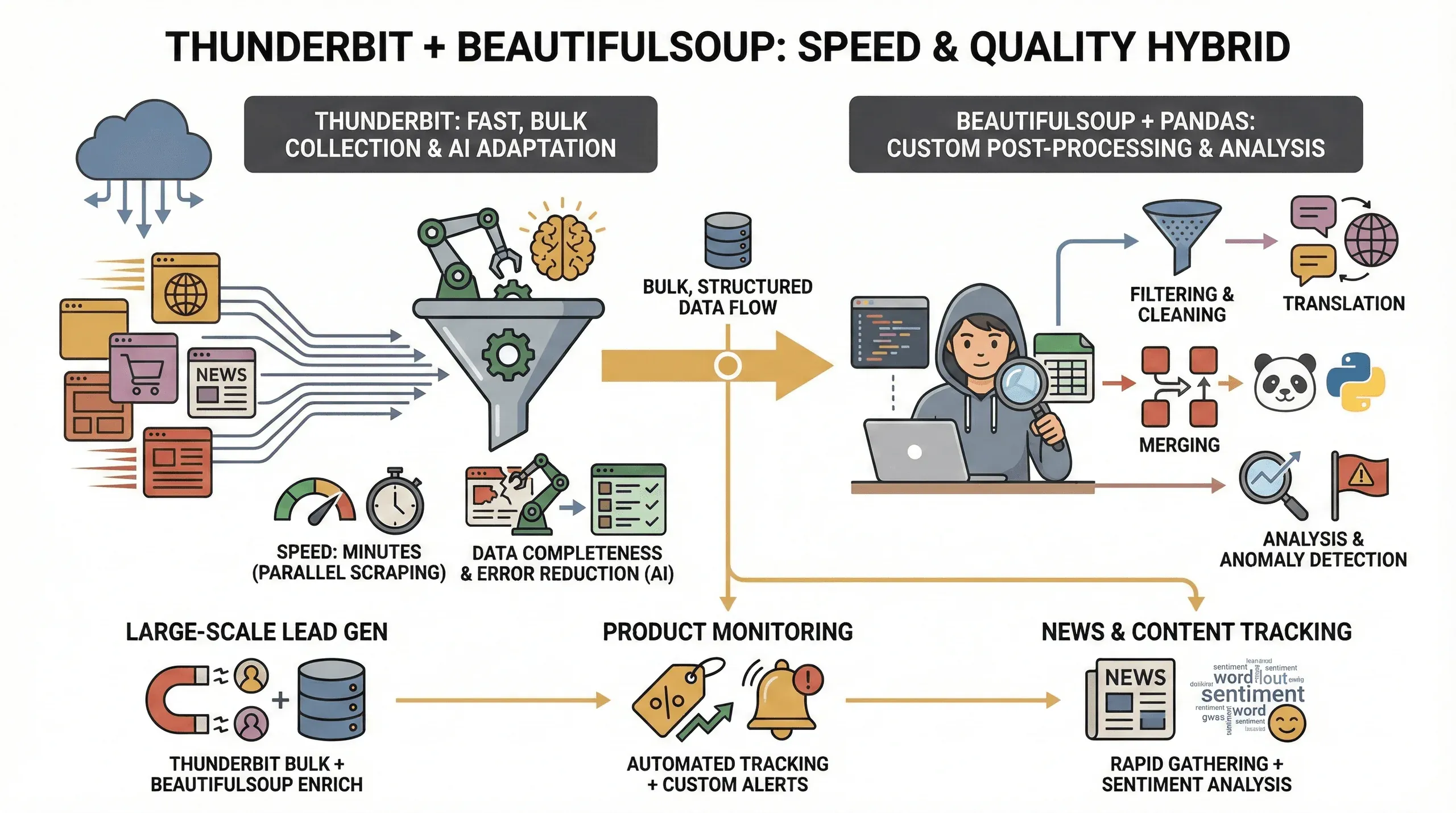 Warum überhaupt beide Tools verwenden? Das habe ich festgestellt:
Warum überhaupt beide Tools verwenden? Das habe ich festgestellt:
- Geschwindigkeit: Thunderbit kann Dutzende Seiten parallel scrapen (im Cloud-Modus bis zu 50 gleichzeitig), sodass Sie Ihre Daten in Minuten statt Stunden erhalten.
- Vollständigkeit der Daten: Die KI von Thunderbit passt sich an Layoutänderungen an und kann selbst von schwierigen Seiten strukturierte Daten extrahieren, wodurch das Risiko fehlender Felder sinkt.
- Weniger Fehler: Keine kaputten Skripte mehr, nur weil sich ein Klassenname ändert – Thundebits KI bewertet die Seite bei jedem Durchlauf neu.
- Individuelle Nachbearbeitung: Für fortgeschrittene Anforderungen (z. B. Filtern, Übersetzen oder Zusammenführen von Datensätzen) geben Ihnen BeautifulSoup und pandas volle Kontrolle.
Dieser hybride Ansatz ist besonders wertvoll für:
- Lead-Generierung im großen Stil: Verwenden Sie Thunderbit, um die Rohdaten zu holen, und BeautifulSoup, um sie zu bereinigen und anzureichern.
- Produkt-Monitoring: Thunderbit übernimmt das repetitive Scraping, während BeautifulSoup Ihnen hilft, Trends zu analysieren oder Ausreißer zu markieren.
- News- und Content-Tracking: Sammeln Sie Artikel schnell mit Thunderbit und nutzen Sie anschließend Python für Sentiment-Analyse oder Keyword-Extraktion.
Häufige Probleme beim Web-Scraping mit BeautifulSoup beheben
Thunderbit Chrome-Erweiterung testen Jede Website mit KI in 2 Klicks scrapen. Get Started Free
Web-Scraping läuft nicht immer reibungslos – hier sind einige typische Stolpersteine und wie man sie behebt:
- Dynamische Inhalte: Wenn eine Seite Daten mit JavaScript lädt (Infinite Scroll, AJAX), sieht BeautifulSoup das allein nicht. Verwenden Sie dafür Selenium oder den Browser-Modus von Thunderbit.
- Anti-Bot-Maßnahmen: Manche Seiten blockieren automatisierte Anfragen. Versuchen Sie einen benutzerdefinierten User-Agent-Header, fügen Sie Pausen zwischen Anfragen ein oder nutzen Sie Thundebits Cloud-Scraping, um einfache Sperren zu umgehen.
- Änderungen an der HTML-Struktur: Wenn Ihr Skript plötzlich nicht mehr funktioniert, hat sich wahrscheinlich das HTML der Seite geändert. Untersuchen Sie die Seite erneut und aktualisieren Sie Ihre Selektoren. Thundebits KI kann hier helfen, indem sie sich spontan anpasst.
- Fehlende Daten: Prüfen Sie immer, ob Elemente existieren, bevor Sie
.get_text()aufrufen. Verwenden Sie bei Attributen.get()statt[], um KeyErrors zu vermeiden. - Kodierungsprobleme: Speichern Sie Dateien mit UTF-8-Kodierung, damit Sonderzeichen korrekt verarbeitet werden.
Und ganz wichtig: Beachten Sie immer robots.txt und die Nutzungsbedingungen der Website. Scrapen Sie verantwortungsvoll und belasten Sie fremde Server nicht unnötig.
Fazit und wichtigste Erkenntnisse
Web-Scraping mit BeautifulSoup gehört zu den praktischsten Fähigkeiten, die Sie sich heute aneignen können, wenn Entscheidungen zunehmend datengetrieben fallen. Das haben wir in diesem BeautifulSoup-Web-Scraping-Tutorial behandelt:
- BeautifulSoup ist der ideale Einstieg, um statisches HTML zu parsen und strukturierte Daten mit Python zu extrahieren.
- Das Einrichten ist unkompliziert – Python, pip und ein paar Bibliotheken genügen.
- HTML zu prüfen ist entscheidend, um die richtigen Daten zu treffen.
- Der Export nach CSV/Excel macht Ihre Daten sofort für die Geschäftsanalyse nutzbar.
- Die Kombination mit Thunderbit bringt Ihnen KI-gestützte Felderkennung, schnelleres Scraping und einfachere Exporte – perfekt für Business-Anwender und Nicht-Programmierer.
- Hybride Workflows (Thunderbit für die Massenextraktion, BeautifulSoup für individuelle Verarbeitung) liefern die beste Mischung aus Geschwindigkeit, Datenqualität und Flexibilität.
Wenn Sie Ihr Web-Scraping aufs nächste Level bringen möchten, probieren Sie beide Tools aus: Experimentieren Sie mit einem einfachen BeautifulSoup-Skript und sehen Sie dann, wie viel schneller Sie mit Thundebits KI-Web-Scraper werden. Weitere praxisnahe Anleitungen finden Sie im Thunderbit Blog.
Mit beiden Tools stehen Ihnen saubere, strukturierte und einsatzbereite Daten zur Verfügung.
Thunderbit KI-Web-Scraper testen Get Started Free
FAQs
1. Was ist BeautifulSoup und wofür wird es verwendet?
BeautifulSoup ist eine Python-Bibliothek zum Parsen von HTML- und XML-Dokumenten. Sie hilft Ihnen, Daten von Webseiten zu extrahieren und in strukturierte Formate wie Listen oder Tabellen zu überführen – ideal für Web-Scraping-Projekte.
2. Wie schlägt sich BeautifulSoup im Vergleich zu Selenium und Scrapy?
BeautifulSoup ist leichtgewichtig und einfach zu nutzen für statische HTML-Seiten. Selenium eignet sich besser zum Scrapen dynamischer, stark JavaScript-lastiger Seiten, während Scrapy ein voll ausgestattetes Framework für groß angelegtes, asynchrones Scraping ist. BeautifulSoup ist die beste Wahl für Einsteiger und schnelle Aufgaben.
3. Kann ich BeautifulSoup und Thunderbit zusammen verwenden?
Absolut. Thunderbit kann Datenfelder auf Webseiten mithilfe von KI schnell erkennen und extrahieren, und Sie können BeautifulSoup für individuelle Nachbearbeitung oder eine tiefere Analyse der exportierten Daten verwenden.
4. Was sind häufige Herausforderungen beim Web-Scraping mit BeautifulSoup?
Typische Probleme sind der Umgang mit dynamischen Inhalten, Anti-Bot-Maßnahmen und Änderungen an der HTML-Struktur. Thundebits KI-Funktionen oder der Browser-Modus können helfen, viele dieser Herausforderungen zu meistern.
5. Wie exportiere ich mit BeautifulSoup extrahierte Daten nach Excel oder CSV?
Sie können das eingebaute csv-Modul von Python oder die Bibliothek pandas verwenden, um Ihre extrahierten Daten in CSV- oder Excel-Dateien zu schreiben. Verwenden Sie immer UTF-8-Kodierung, um Sonderzeichen korrekt zu behandeln und die Kompatibilität mit Tabellenkalkulations-Tools sicherzustellen.
Lust, es selbst auszuprobieren? Laden Sie Thundebits Chrome-Erweiterung herunter und scrapen Sie noch heute clever statt mühsam. Weitere Tutorials und Tipps finden Sie im Thunderbit Blog.
Mehr erfahren




