
Eine Crawl-gestützte Studie darüber, wie Websites mit hohem Traffic maschinenlesbare Hinweise für große Sprachmodelle veröffentlichen, wie erste Implementierungen aussehen und warum sich Verbreitung nicht nur an HTTP-200-Antworten messen lässt.
- Datensatz:
data/llms_probe_results_top_10000.csv - Heruntergeladenes Tranco-Listing: 6. Mai 2026
- Umfang:
/llms.txtund/llms-full.txtauf Root-Ebene
Zentrale Kennzahlen
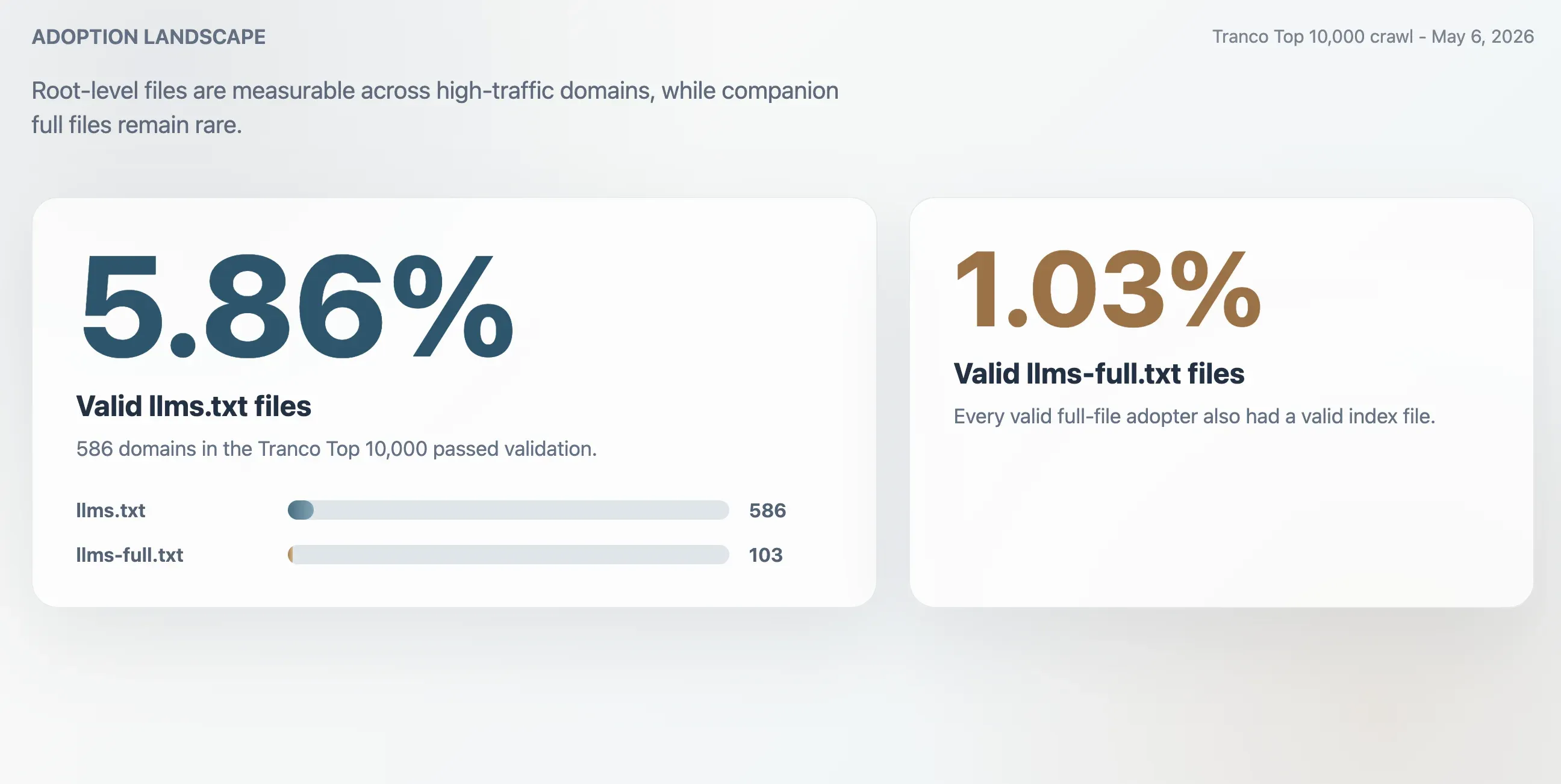
- 5,86 %: Validierte Verbreitung von
llms.txtim Tranco Top 10.000, entsprechend 586 Domains. - 1,03 %: Validierte Verbreitung von
llms-full.txt, entsprechend 103 Domains. Jede gültige Vollversion hatte auch eine gültige Indexdatei. - 63,51 %: Anteil der HTTP-200-Antworten für
/llms.txt, die die Validierung nicht bestanden. - 2,74x: Grober Überschätzungsfaktor, wenn man die Verbreitung nur anhand roher HTTP-200-Antworten misst.
Kurzfassung
llms.txt ist noch immer eine frühe Web-Konvention, aber längst kein Randexperiment mehr. In einem Crawl vom 6. Mai 2026 über die Tranco Top 10.000 Domains fand diese Studie 586 gültige llms.txt-Dateien, was einer beobachteten Verbreitung von 5,86 % entspricht. Die begleitende Datei llms-full.txt war deutlich seltener: 103 Domains hatten eine gültige Vollversion, also 1,03 %.
Die wichtigste methodische Erkenntnis: Statuscodes sind ein schlechter Proxy für Adoption. Der Crawler beobachtete 1.606 HTTP-200-Antworten für /llms.txt, aber nur 586 bestanden die Validierung. Die übrigen 1.020 waren meist Weiterleitungen auf falsche Ziele, generische HTML-Seiten, leere Inhalte oder andere ungültige Antworten. Ein naiver Crawler, der jede 200-Antwort als Adoption zählt, würde die gültige Verbreitung um etwa das 2,74-Fache überschätzen.
Unter den gültigen Anwendern ist die Implementierungsqualität höher, als es eine reine Platzhalter-Erzählung vermuten lässt. Die mediane gültige Datei war etwa 7,1 KB groß, 61,77 % der gültigen Dateien waren größer als 5 KB, 70,82 % enthielten sechs oder mehr Markdown-Abschnitte und 77,47 % enthielten 11 oder mehr Markdown-Links. Zu den frühen Anwendern gehören Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog und Cloudinary.
llms.txtversteht sich am besten als erklärendes und navigationsorientiertes Signal für KI-Systeme, nicht als Ersatz fürrobots.txt. Entscheidend ist nicht nur, dass die Datei existiert, sondern ob sie Maschinen hilft, autoritative, kompakte und aktuelle Informationen zu finden.
Kontext: Das Web ergänzt Signale für KI
Websites nutzen seit Langem robots.txt, um Crawler-Präferenzen auszudrücken, sitemap.xml, um die Auffindbarkeit von URLs zu verbessern, und strukturierte Daten, damit Such- und Plattformsysteme Seiten besser interpretieren können. Generative KI bringt ein anderes Problem mit sich. Inhalte können für Training, Retrieval, Zusammenfassungen, agentisches Browsing, Code-Hilfe, Kundensupport und Antwortgenerierung verwendet werden. Daraus ergeben sich zwei gleichzeitige Anforderungen: Publisher wollen mehr Kontrolle über die automatisierte Nutzung, gleichzeitig sollen KI-Systeme aber die richtige kanonische Information finden, wenn sie mit ihren Seiten interagieren.
Der , 2024 von Jeremy Howard vorgestellt, beschreibt die Datei als Markdown-Dokument im Website-Root, das zur Inferenzzeit LLM-freundliche Informationen bereitstellt. Der Vorschlag argumentiert, dass HTML-Seiten oft Navigation, Werbung, Skripte und andere Störfaktoren enthalten, die ihre Verarbeitung für Sprachmodelle erschweren. Eine kompakte Markdown-Datei kann Modelle zu den wichtigsten Seiten, Dokus, APIs, Beispielen, Richtlinien und Produktinformationen leiten.
Externe Web-Recherche liefert den breiteren Hintergrund. Die beschreibt einen schnellen Anstieg von KI-bezogenen Einschränkungen in robots.txt und Nutzungsbedingungen und argumentiert, dass bestehende Web-Consent-Mechanismen nicht für die großskalige Wiederverwendung von KI-Daten entworfen wurden. hat zudem Muster von KI-Crawlern und robots.txt auf Top-10.000-Domain-Ebene sichtbar gemacht. In diesem Umfeld steht llms.txt auf der konstruktiven Seite des KI-Signalings: nicht „dies hier nicht crawlen“, sondern „wenn du diese Website verstehen willst, fang hier an“.
Externe Evidenz und die Debatte über die Verbreitung
Die öffentliche Debatte um llms.txt teilt sich in zwei Positionen. Die optimistische These lautet, dass die Datei KI-Systemen einen saubereren, effizienteren Weg zu autoritativen Inhalten bietet. Die skeptische These besagt, dass kein großer LLM-Anbieter öffentlich zugesagt hat, llms.txt als Ranking-, Crawling- oder Zitationssignal zu verwenden, und Publisher daher allein von der Datei keine Traffic-Zuwächse erwarten sollten. Die drei für dieses Update ausgewerteten externen Quellen stützen eine nuanciertere Schlussfolgerung: llms.txt ist nützliche Infrastruktur, aber die Evidenz für direkten Traffic-Effekt bleibt begrenzt und kontextabhängig.
Externe Benchmarks zur Verbreitung entwickeln sich schnell
meldete für den 22. Juni 2025 eine Verbreitungsrate von 0,3 % über die Top 1.000 Websites, also 3 von 1.000 Seiten. Beschrieben wird ein monatlicher automatisierter Scan von domain.com/llms.txt, inklusive Validierung, die Weiterleitungen und HTML-Antworten ausschließt. Diese Methodik ist in ihrer Stoßrichtung ähnlich wie der konservative Validierungsansatz dieser Studie.
Der Unterschied in den Ergebnissen ist groß: Diese Studie fand am 6. Mai 2026 75 gültige llms.txt-Dateien in den Tranco Top 1.000, also 7,50 %. Die beiden Zahlen sollten nicht als strikte Zeitreihe gelesen werden, da sich Ranking-Quelle, Implementierungsdetails, Validierungslogik und Crawl-Zeitpunkt unterscheiden können. Dennoch legt der Kontrast nahe, dass sich die Adoption zwischen Mitte 2025 und Mai 2026 spürbar verändert hat, insbesondere bei entwickler-, SaaS-, Cloud-, Sicherheits- und dokumentationslastigen Websites.
| Quelle | Snapshot | Stichprobe | Berichtete gültige Verbreitung | Einordnung |
|---|---|---|---|---|
| Rankability | 22. Juni 2025 | Top 1.000 Websites | 0,3 % | Früher öffentlicher Benchmark mit minimaler Adoption Mitte 2025. |
| Diese Studie | 6. Mai 2026 | Tranco Top 1.000 | 7,50 % | Späterer Crawl mit sichtbarer Adoption bei Websites mit hohem Traffic. |
| Diese Studie | 6. Mai 2026 | Tranco Top 10.000 | 5,86 % | Breitere Stichprobe, die zeigt, dass Adoption messbar, aber nicht Mainstream ist. |
Traffic-Experimente bleiben gemischt
veröffentlichte im Januar 2026 eine Analyse von 10 Websites, die 90 Tage vor und 90 Tage nach der Implementierung verfolgt wurden. Der Artikel berichtete, dass zwei Sites einen Anstieg des KI-Traffics um 12,5 % und 25 % verzeichneten, acht keinen messbaren Fortschritt zeigten und eine um 19,7 % zurückging. Die zentrale Interpretation war kausale Vorsicht: Die beiden scheinbaren Erfolgsgeschichten starteten zugleich neue Templates, bauten Resource Centers neu auf, ergänzten auslesbare Vergleichstabellen, erhielten Presseberichterstattung, behoben technische Probleme oder veröffentlichten neue FAQ-Inhalte. In dieser Lesart dokumentierte llms.txt stärkere Inhalte und technische Arbeit; sie schien das Wachstum nicht allein verursacht zu haben.
Das persönliche Blog-Experiment von kam auf Basis einer kleineren Beobachtung auf Site-Ebene zu einem positiveren Schluss. Es verglich zwei Viermonatszeiträume in Yandex.Metrica nach dem Hinzufügen von llms.txt und llms-full.txt. LLM-Referral-Sitzungen stiegen von 75 auf 92, also um 23 %, während die Zahl der Nutzer von 51 auf 64 zunahm. Perplexity-Sitzungen stiegen von 29 auf 55, während ChatGPT-Sitzungen von 31 auf 26 fielen. Im selben Beitrag wird auch erwähnt, dass der gesamte Referral-Traffic schneller wuchs, von 160 auf 290 Sitzungen, sodass der LLM-Anteil von 47 % auf 32 % sank.
| Evidenztyp | Beobachtetes Ergebnis | Wichtigste Einschränkung | Bedeutung für diesen Bericht |
|---|---|---|---|
| Search-Engine-Land-Studie mit 10 Websites vor/nachher | Zwei Sites stiegen, acht blieben unverändert, eine sank. | Positive Fälle hatten gleichzeitig Content-, PR- und technische Änderungen. | Spricht dafür, llms.txt als Infrastruktur zu sehen, nicht als eigenständigen Wachstumstreiber. |
| Vorher/nachher-Beobachtung im persönlichen Blog von Alimbekov | LLM-Referral-Sitzungen stiegen im Nachher-Zeitraum um 23 %. | Keine Kontrollgruppe; der gesamte Referral-Traffic stieg um 81 %, und der LLM-Anteil sank. | Weist auf mögliches Potenzial für technische Blogs hin, besonders über Perplexity, ohne die Kausalität isolieren zu können. |
| Diese Crawl-basierte Adoptionsstudie | 586 gültige Dateien und viele strukturierte Implementierungen. | Misst Präsenz und Struktur, nicht den downstream Traffic-Effekt. | Zeigt Adoption und Reife der Implementierung, aber nicht allein den ROI. |
Was die Debatte klärt
Die externe Evidenz schärft die Interpretation dieses Datensatzes. Eine gut strukturierte llms.txt-Datei kann die Parsing-Reibung für Maschinen reduzieren, besonders bei Entwicklerdokumentation, API-Referenzen und Wissensdatenbank-Inhalten. Doch die stärksten Traffic-Fälle scheinen weiterhin von Inhalten abzuhängen, die nützlich, auslesbar, autoritativ und außerhalb der Datei auffindbar sind. Deshalb lautet die praktische Frage nicht isoliert „Ist llms.txt wichtig?“. Sie lautet vielmehr, ob die Datei Teil eines umfassenderen, KI-lesbaren Content-Systems ist.
Aktualisierte Einordnung:
llms.txtsollte als kostengünstige Infrastruktur für KI-Zielsysteme implementiert werden. Sie sollte nicht als Ersatz für bessere Dokumentation, strukturierte Inhalte, technische Zugänglichkeit, Zitate, Links oder Markenautorität positioniert werden.
Methodik
Diese Studie nutzte die Tranco Top 10.000 Domains als Stichprobe. Tranco ist ein forschungsorientiertes Ranking der Top-Sites, das stabiler und manipulationsresistenter sein soll als viele traditionelle Ranglisten. Die Tranco-Quelldatei wurde am 6. Mai 2026 heruntergeladen; der Last-Modified-Zeitstempel der Quelle lag bei 5. Mai 2026, 22:17:59 GMT.
Der Crawler prüfte für jede Domain zwei Root-Pfade:
https://example.com/llms.txt, bei Bedarf mit HTTP-Fallback.https://example.com/llms-full.txt, bei Bedarf mit HTTP-Fallback.
Für jeden Probeaufruf erfasste der Crawler Statuscode, finale URL, Abrufmethode, Antwortbytes, Content-Type, Fehlermeldung, Laufzeit und Validierungsergebnis. Erfolgreiche Antwortinhalte wurden unter raw_llms_txt/ für die Sichtung und Sekundäranalyse gespeichert.
Validierungsregeln
Eine Antwort wurde nur dann als gültige Datei gezählt, wenn sie einen erfolgreichen Body zurückgab und nicht wie ein generischer Web-Fallback wirkte. Der finale URL-Pfad musste /llms.txt oder /llms-full.txt bleiben. Leere Bodies wurden verworfen. Offensichtliche HTML-Dokumente und App Shells wurden verworfen. Der Content-Type diente als unterstützender Hinweis und nicht als alleinige Regel, da eine kleine Zahl gültiger textähnlicher Dateien mit ungewöhnlichen Content-Types ausgeliefert wurde.
Verbreitungslandschaft
Der Crawl fand 586 gültige llms.txt-Dateien im Tranco Top 10.000. Daraus ergibt sich eine gültige Verbreitungsrate von 5,86 %. Die kleinere Begleitdatei llms-full.txt war auf 103 Domains vorhanden und gültig, also auf 1,03 % der Stichprobe.
| Metrik | Anzahl | Anteil am Top 10.000 |
|---|---|---|
| Gecrawlte Domains | 10.000 | 100,00 % |
| Gültige llms.txt-Dateien | 586 | 5,86 % |
| Gültige llms-full.txt-Dateien | 103 | 1,03 % |
| HTTP-200-Antworten für /llms.txt | 1.606 | 16,06 % |
| Als ungültig verworfene HTTP-200-Antworten | 1.020 | 10,20 % |
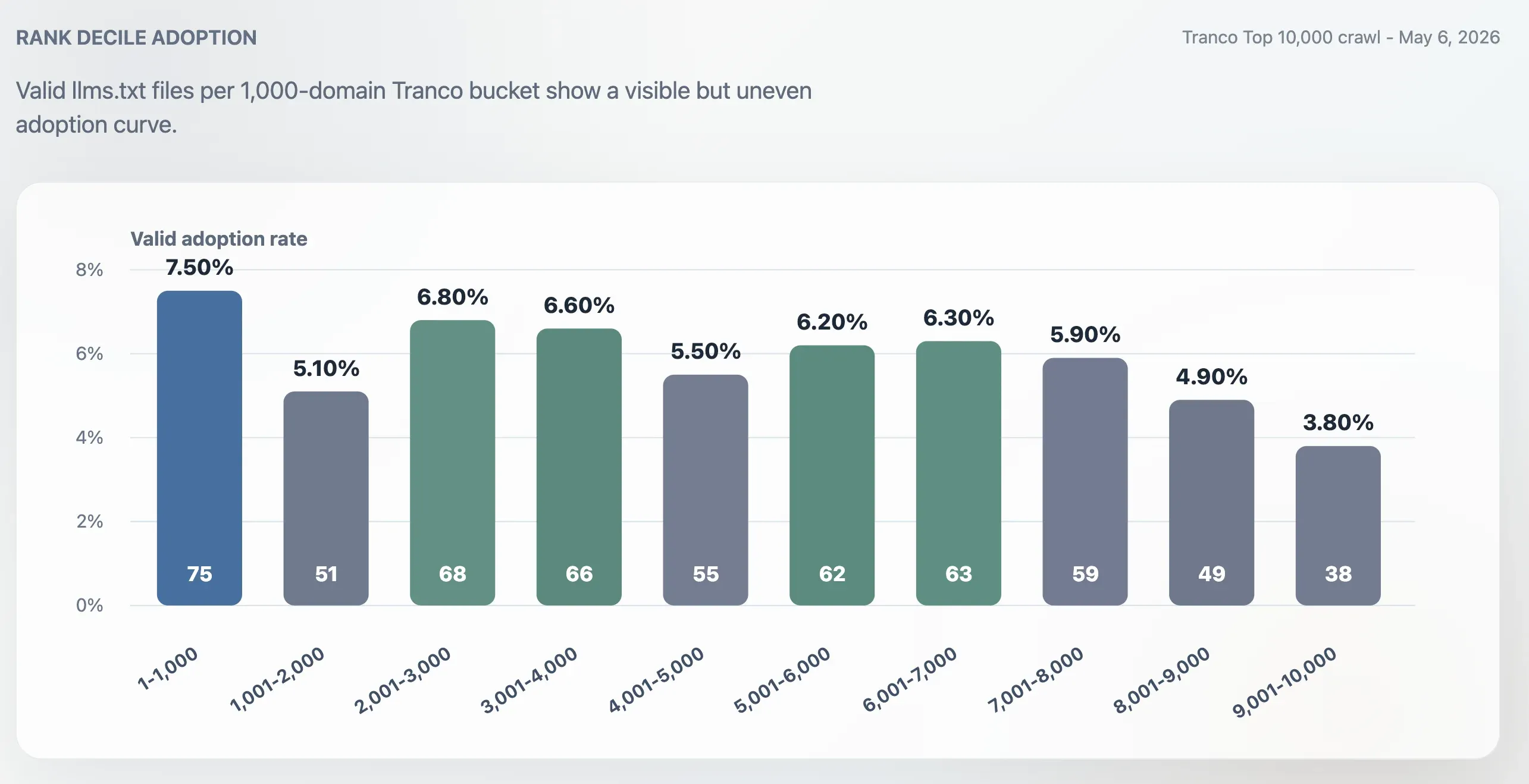
Adoption ist nicht rein toplastig
Die Adoption war in den Top 1.000 höher als im gesamten Top 10.000, beschränkte sich aber nicht auf die allergrößten Websites. Die Adoptionsrate in den Top 1.000 lag bei 7,50 %. Das letzte 1.000er-Bucket, also Rang 9.001–10.000, fiel auf 3,80 %. Die Mitte des Rankings blieb aktiv: Die Buckets 2.001–3.000, 3.001–4.000, 5.001–6.000 und 6.001–7.000 lagen alle um etwa 6 %.
Frühe Anwender
Der höchstplatzierte gültige Anwender war Cloudflare auf Tranco-Rang 4. Weitere hochrangige Anwender waren Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink und OneSignal.
Diese Anwender sind nicht zufällig. Sie haben meist große Dokumentationsflächen, Produktlinien, die erklärt werden müssen, APIs oder Entwickler-Ökosysteme, Support-Inhalte, Preisübersichten, Sicherheits- und Datenschutzmaterial sowie genug Markenautorität, um darauf zu achten, wie KI-Systeme ihre Sites interpretieren.
| Rang | Domain | Dateigröße | Beobachtetes Muster |
|---|---|---|---|
| 4 | cloudflare.com | 4.225 B | Kompakter Index für Produkte, Entwickler, Unternehmen und Preise. |
| 26 | azure.com | 47.037 B | Entwicklertools, KI, Compute, Storage, Sicherheit, Monitoring und optionale Ressourcen. |
| 28 | github.com | 27.108 B | Programmatischer Zugriff, Copilot, MCP, REST API, Actions, Repositories und CLI-Links. |
| 248 | stripe.com | 64.229 B | Zahlungen, Connect, Checkout, Billing, Tax, Atlas, Radar und Entwicklerdokumentation. |
| 265 | salesforce.com | 1,02 MB | Riesiger Produkt- und Agentforce-Link-Katalog ohne Markdown-Abschnittsüberschriften. |
Kategorien der Top-1.000-Anwender
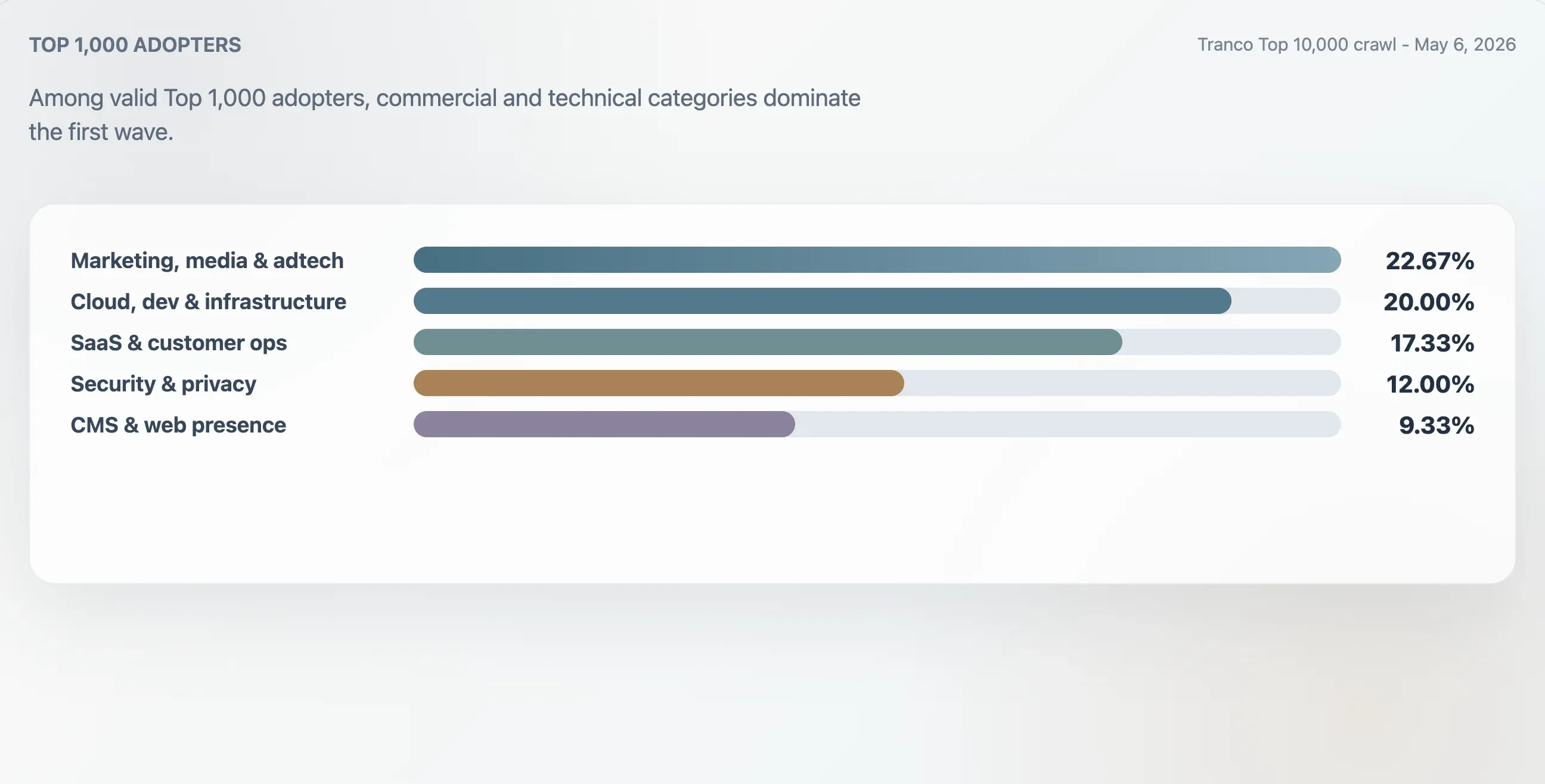
Diese Studie klassifizierte die 75 gültigen Anwender in den Tranco Top 1.000 anhand von Domain-Kontext, ersten Überschriften, Rohdateistruktur und Inhalts-Keywords. Die größte Gruppe war Marketing, Medien und Adtech mit 22,67 %. Cloud-, Entwickler- und Infrastruktur-Seiten machten 20,00 % aus. SaaS-, Produktivitäts- und Customer-Operations-Seiten machten 17,33 % aus. Sicherheits-, Identitäts- und Privacy-Seiten machten 12,00 % aus.
| Kategorie | Domains | Anteil der Top-1.000-Anwender | Median des Qualitäts-Score | Median der Links |
|---|---|---|---|---|
| Marketing, Medien & Adtech | 17 | 22,67 % | 94 | 25 |
| Cloud, Dev & Infrastruktur | 15 | 20,00 % | 94 | 62 |
| SaaS, Produktivität & Customer Ops | 13 | 17,33 % | 94 | 46 |
| Sicherheit, Identität & Datenschutz | 9 | 12,00 % | 98 | 78 |
| CMS, Hosting & Web-Präsenz | 7 | 9,33 % | 100 | 24 |
TLD-Muster
Top-Level-Domains sind keine Branchenlabels, aber sie liefern nützliche Richtungsindikatoren. Unter den TLDs mit mindestens 50 Domains in der Stichprobe hatte .io mit 14,44 % die höchste gültige Verbreitungsrate. .com folgte mit 8,19 %. Die geringere Adoption bei .gov, .edu und .net deutet darauf hin, dass die frühe Anwenderbasis stärker kommerziell und technisch als institutionell geprägt ist.
Implementierungsqualität
Gültige Adoption bedeutet nicht automatisch einheitliche Implementierungsqualität. Einige Dateien sind kompakte, gut strukturierte Indizes. Einige bestehen überwiegend aus Fließtext. Einige sind reine Link-Kataloge. Einige sind nahezu leere Platzhalter. Einige sind mehrmegabytegroße Inhalts-Dumps, die vielleicht vollständig sind, aber teuer zu laden und zu parsen.
Unter den gültigen llms.txt-Dateien waren 362 größer als 5 KB, also 61,77 % der gültigen Anwender. Die mediane Dateigröße lag bei etwa 7,1 KB. Die P90-Dateigröße betrug 156 KB, P95 356 KB, P99 2,54 MB und die größte beobachtete Datei 7,97 MB.
Häufige Inhaltssignale
Ein Keyword-Scan der gültigen Dateien zeigte, dass viele Websites nicht bloß eine Erklärung veröffentlichen, sondern Modelle auf operativ nützliche Inhalte verweisen. Support- oder Hilfebegriffe tauchten in 70,31 % der gültigen Dateien auf. Blog-, Guide- oder Tutorial-Begriffe in 67,92 %. Sicherheits-, Datenschutz-, Compliance- oder Terms-Begriffe in 61,43 %. Pricing erschien in 53,92 %, Documentation in 52,22 %, API-Begriffe in 33,96 % und Changelog- oder Release-Signale in 27,30 %.
Qualitätsbewertung und Archetypen
Um von bloßer Präsenz zu Reife zu gelangen, entwickelte diese Studie einen leichten Implementierungs-Score. Der Score berücksichtigt Content-Type, Dateigröße, Markdown-Struktur, Linkanzahl, Themenabdeckung und Warnsignale wie fehlende Überschriften, keine Markdown-Links, ungewöhnliche Content-Types, winzige Dateien, sehr große Dateien und Link-Dump-Verhalten. Das ist kein formaler Standard, sondern ein Forschungsmodell zum Vergleich beobachteter Implementierungen.
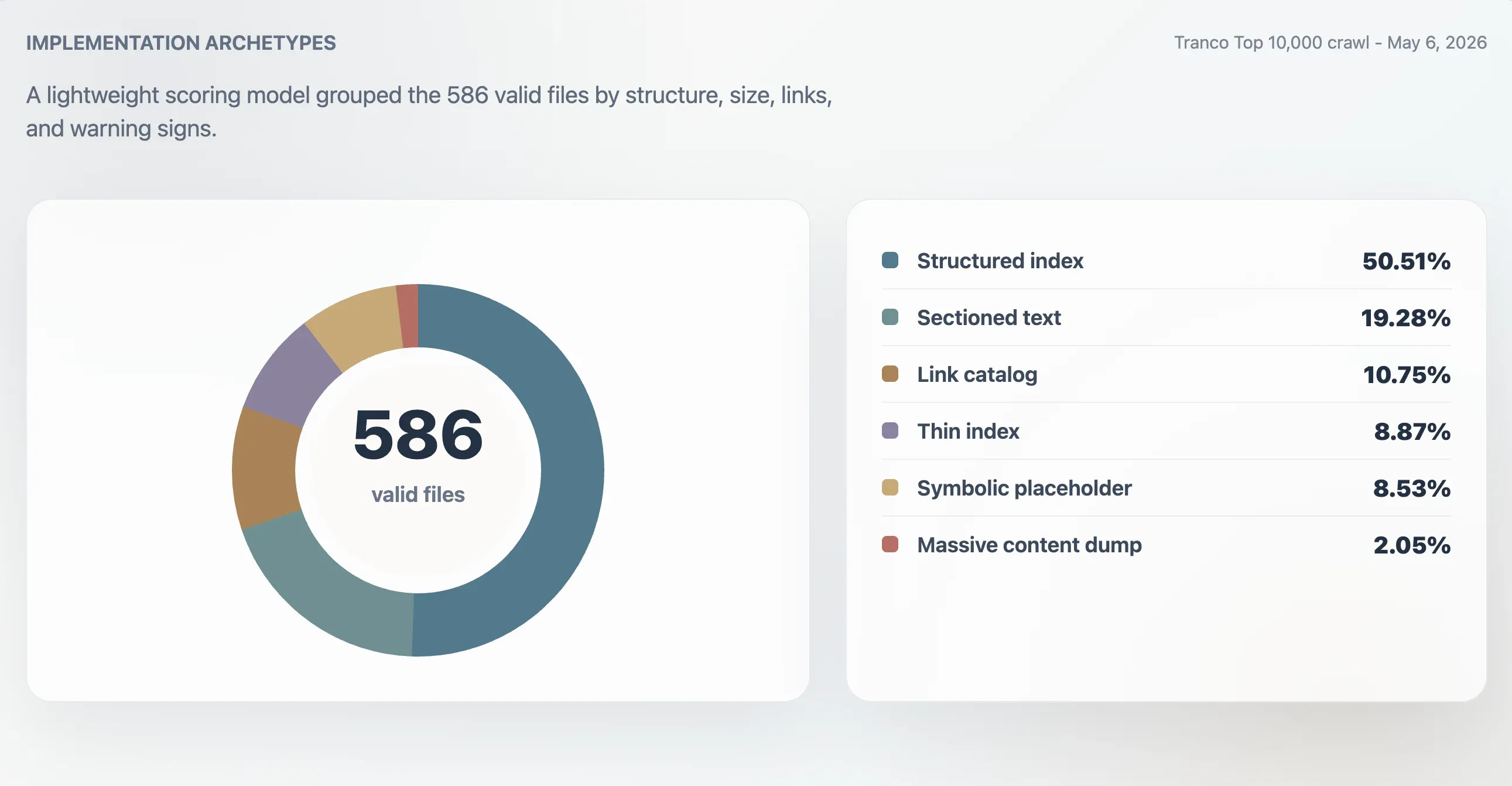
Mit diesem Modell wurden 416 gültige Dateien als starke strukturierte Indizes klassifiziert, 107 als nutzbare Indizes, 24 als dünn oder unregelmäßig und 39 als symbolisch oder von geringem Nutzen. Eine separate Archetypenanalyse ergab 296 strukturierte Indizes, 113 Dateien mit Abschnittstext, 63 Link-Kataloge, 52 dünne Indizes, 50 symbolische oder Platzhalter-Dateien und 12 massive Inhalts-Dumps.
| Archetyp | Domains | Anteil gültiger Dateien | Median-Score | Mediane Dateigröße | Mediane Links |
|---|---|---|---|---|---|
| Strukturierter Index | 296 | 50,51 % | 98 | 11.241 B | 61,5 |
| Abschnittstext | 113 | 19,28 % | 78 | 4.718 B | 0 |
| Link-Katalog | 63 | 10,75 % | 86 | 4.160 B | 23 |
| Dünner Index | 52 | 8,87 % | 66 | 2.814 B | 0 |
| Symbolisch oder Platzhalter | 50 | 8,53 % | 27 | 15 B | 0 |
| Massiver Inhalts-Dump | 12 | 2,05 % | 74 | 2,84 MB | 7.259,5 |
Top-Anwender haben dichtere Implementierungen
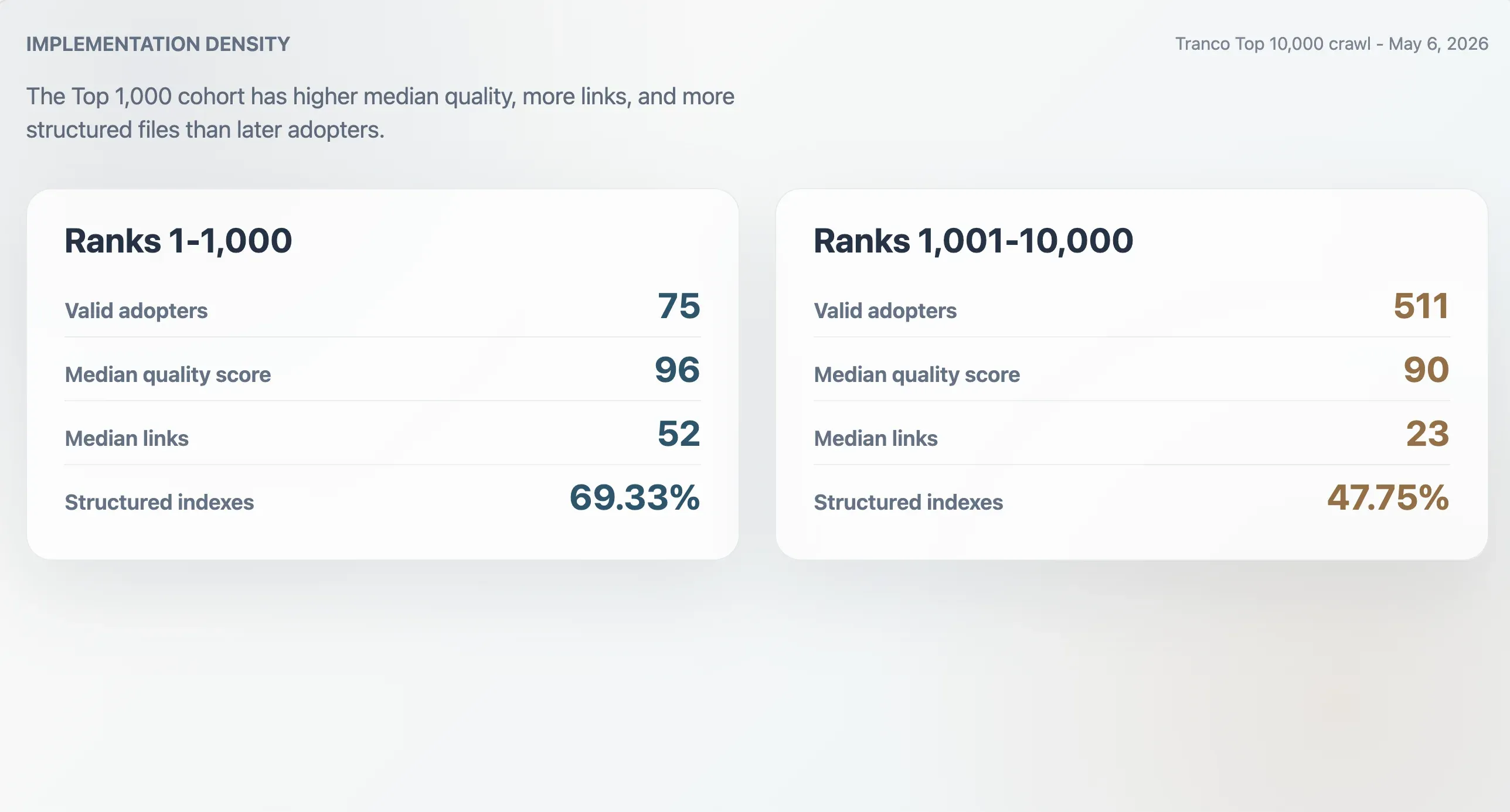
Die 75 gültigen Anwender in den Tranco Top 1.000 hatten einen medianen Qualitäts-Score von 96, eine mediane Dateigröße von 9.068 Byte, eine mediane Markdown-Linkanzahl von 52 und eine mediane Abschnittszahl von 11. Die 511 Anwender mit Rang 1.001–10.000 wiesen niedrigere Mediane auf: Score 90, Dateigröße 6.506 Byte, 23 Markdown-Links und 9 Abschnitte. Top-1.000-Anwender waren außerdem häufiger strukturierte Indizes: 69,33 % gegenüber 47,75 % in der späteren Kohorte.
Das Problem der Falschpositiven

Das größte Messrisiko sind Falschpositive. Von den 1.606 Domains, die für /llms.txt HTTP 200 zurückgaben, fielen 1.020 bei der Validierung durch. Der häufigste ungültige Grund war eine Weiterleitung auf ein falsches Ziel, mit 618 Fällen. Weitere 367 Antworten waren generische HTML-Dokumente. 29 lieferten einen leeren Body, und 6 waren sonstige oder nicht kategorisierte ungültige Antworten.
Das ist wichtig, weil viele große Websites unbekannte Pfade auf Login-Seiten, Startseiten, App Shells, regionale Seiten, Consent-Flächen oder Marketing-Fallbacks umleiten. Solche Antworten wirken für einen Statuscode-Crawler unauffällig, enthalten aber kein gültiges llms.txt-Signal.
llms-full.txt: seltener und ungleichmäßiger
Die begleitende Datei llms-full.txt war deutlich seltener als llms.txt. Der Crawl fand 103 gültige Vollversionen, also 17,58 % der gültigen llms.txt-Anwender und 1,03 % der gesamten Top-10.000-Stichprobe.
Vollversion-Implementierungen waren uneinheitlich. Unter den 103 Dual-File-Anwendern hatten 57 eine llms-full.txt, die größer war als die Indexdatei, aber 46 hatten entweder eine Vollversion, die nicht größer als die Indexdatei war, oder eine Vollversion unter 100 Byte. Das mediane Größenverhältnis Vollversion zu Index betrug 1,43, doch es gab deutlich höhere Extremfälle. Die Vollversion von Supabase war etwa 7.139-mal so groß wie die Indexdatei. Made-in-China.com hatte eine 89,89-MB-Vollversion.
| Domain | llms.txt | llms-full.txt | Verhältnis |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7.139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Empfehlung:
llms-full.txtnur veröffentlichen, wenn die Website bereits über eine stabile Dokumentations-Pipeline, Versionierung diszipliniert handhabt und einen klaren Grund hat, große Inhaltsmengen in einer einzigen maschinenlesbaren Datei bereitzustellen.
llms.txt, robots.txt und sitemap.xml
llms.txt sollte nicht als neues robots.txt verstanden werden. Beide sind maschinenlesbare Dateien auf Root-Ebene, aber sie kommunizieren unterschiedliche Dinge. robots.txt ist ein Signal für Crawler-Präferenzen und Zugriffskontrolle. sitemap.xml ist ein Signal für die URL-Auffindbarkeit. llms.txt ist ein erklärendes und navigationsorientiertes Signal.
| Signal | Hauptrolle | Typischer Leser | Interpretation in dieser Studie |
|---|---|---|---|
robots.txt | Crawler-Präferenzen und Pfadbeschränkungen festlegen. | Such-Crawler, KI-Crawler, Archiv-Crawler, generische Bots. | Governance- und Zugriffssignal. |
sitemap.xml | Auffindbare URLs für Indexierungssysteme auflisten. | Suchmaschinen und Indexierungs-Pipelines. | Discovery-Signal. |
llms.txt | Kompakten Site-Kontext, wichtige Links, Dokus, APIs, Beispiele und Policy-Referenzen bereitstellen. | LLM-Anwendungen, KI-Agenten, Entwicklertools, Retrieval-Systeme. | Erklärungs- und Navigationssignal. |
Empfehlungen
Für Websites, die llms.txt erwägen, deuten die stärksten Implementierungen in diesem Datensatz und die externen Traffic-Evidenzen auf ein pragmatisches Muster hin:
- Veröffentlichen Sie
/llms.txtim Root und halten Sie sie ohne Login, JavaScript-Ausführung, Consent-Wände oder Weiterleitungen von anderen Pfaden zugänglich. - Liefern Sie sie möglichst als
text/plainodertext/markdownaus. - Beginnen Sie mit einer kurzen Beschreibung der Website und gruppieren Sie Links anschließend nach Produkt, Dokumentation, API, Preisen, Changelog, Beispielen, Support, Richtlinien und Unternehmensressourcen.
- Bevorzugen Sie kanonische Links statt erschöpfender URL-Listen.
- Vermeiden Sie leere symbolische Dateien; sie sind bestenfalls ein schwaches Signal.
- Vermeiden Sie massive, undifferenzierte Dumps, außer es gibt einen starken Anwendungsfall für maschinelle Verarbeitung und eine verlässliche Generierungspipeline.
- Validieren Sie nach der Veröffentlichung finale URL, Response-Body, Content-Type, Markdown-Struktur, Linkanzahl und Dateigröße.
Teams sollten die Erwartungen ebenfalls sorgfältig setzen. Die verfügbaren öffentlichen Experimente beweisen nicht, dass llms.txt den KI-Referral-Traffic unabhängig steigert. Wenn ein Team die Business-Wirkung testen will, sollte es LLM-Referrals, zitierte Seiten, Bot-Requests, Index-Frische und Inhaltsänderungen gemeinsam verfolgen. Ein nützliches Experiment wäre der Vergleich gematchter Seitengruppen, möglichst mit konstant gehaltenen Content-Updates und einer Trennung plattformspezifischer Traffic-Quellen wie Perplexity, ChatGPT, Gemini, Claude und Bing/Copilot.
Einschränkungen
Dies ist ein Crawl-basiertes Snapshot, keine dauerhafte Wahrheit. Websites können llms.txt-Dateien jederzeit hinzufügen, entfernen oder ändern. Einige Domains blockieren automatisierte Anfragen oder verhalten sich je nach Geografie, TLS-Konfiguration, Weiterleitungslogik, User-Agent oder Bot-Mitigation unterschiedlich. Die Studie testete nur Root-Level-Dateien und suchte weder Subdomains noch nicht standardisierte Pfade.
Der Qualitäts-Score und die Archetypen sind Forschungswerkzeuge, keine offiziellen Compliance-Labels. Die Themenanalyse ist keyword-basiert und sollte als Richtungsindikator gelesen werden. Die Studie beweist nicht, dass irgendeine bestimmte KI-Plattform llms.txt derzeit in der Produktion liest, respektiert oder verwendet.
Auch die hier ausgewerteten externen Traffic-Evidenzen haben Einschränkungen. Die Analyse von Search Engine Land ist eher als vorsichtige Multisite-Beobachtung denn als randomisiertes Experiment zu verstehen. Das Ergebnis von Alimbekov ist als transparentes Fallbeispiel auf Site-Ebene hilfreich, hat aber keine Kontrollgruppe und umfasst einen Zeitraum, in dem der gesamte Referral-Traffic deutlich stieg. Diese Quellen helfen, die Debatte einzuordnen, machen aus diesem Crawl aber keine kausale Traffic-Studie.
Dateien und Reproduzierbarkeit
| Datei | Zweck |
|---|---|
crawl_llms_txt.py | Crawler für /llms.txt und /llms-full.txt. |
analyze_llms_txt.py | Primäre Adoptionsanalyse und Diagrammerstellung. |
deep_analyze_llms_txt.py | Sekundäranalyse für Rangdezile, TLDs, Themen-Signale, Qualitäts-Score, Archetypen und Dual-File-Verhalten. |
deep_dive_early_quality.py | Klassifizierung früher Anwender und Deep Dive zur Implementierungsqualität. |
data/llms_probe_results_top_10000.csv | Hauptdatensatz der Crawl-Ergebnisse. |
data/deep_analysis_top_10000.json | Zusammenfassung der Sekundäranalyse. |
data/deep_early_quality_analysis.json | Kategorien früher Anwender, Vergleich der Qualitätskohorten, Archetyp-Details und Fallstudien. |
Quellen
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, Januar 2026.
- , Rankability, Juni 2025.
- , Renat Alimbekov.
Korrekturen zur Methodik, Hinweise zu Datensatzproblemen und Folgeanalysen sind willkommen unter support@thunderbit.com. Dieser Bericht wird unabhängig von jeder kommerziellen Position veröffentlicht, die Thunderbit innehat. Die Daten in diesem Bericht stehen für sich. — Das Thunderbit-Forschungsteam, Mai 2026.