

Ein nüchterner Blick auf den Web-Traffic des Jahres 2025 zeigt: Fast die Hälfte davon stammt gar nicht von Menschen. Bots und Crawler machen mittlerweile über 50 % der gesamten Internetaktivität aus (Thales Group), und nur ein Bruchteil davon sind die „guten" Bots, die du auf deiner Seite haben willst: Suchmaschinen, Social-Media-Vorschau-Bots und Analysehelfer. Der Rest? Sagen wir es so – die sind nicht immer mit guten Absichten unterwegs. In den Jahren, in denen ich bei Thunderbit Automatisierungs- und KI-Tools entwickle, habe ich aus nächster Nähe gesehen, wie der richtige – oder eben falsche – Crawler deine SEO nach oben treibt oder ruiniert, deine Analysedaten verzerrt, deine Bandbreite auffrisst oder gleich einen handfesten Sicherheitsvorfall auslöst.
Wer ein Unternehmen führt, eine Website betreibt oder schlicht seine digitale Infrastruktur im Griff behalten will, sollte wissen, wer da an die Server-Tür klopft – und das gilt heute mehr denn je. Genau deshalb dieser Leitfaden für 2025: zu den wichtigsten Crawlern – was sie tun, wie du sie erkennst und wie du deine Seite für die guten Bots offenhältst, während du die schlechten draußen lässt.
Was macht einen Crawler „bekannt"? User-Agent, IPs und Verifizierung
Starten wir bei den Grundlagen: Was genau ist ein „bekannter" Crawler? Vereinfacht gesagt ein Bot, der sich mit einer konsistenten User-Agent-Zeichenfolge ausweist (etwa Googlebot/2.1 oder bingbot/2.0) und idealerweise aus veröffentlichten IP-Bereichen oder ASN-Blöcken crawlt, die du überprüfen kannst (Googlebot-Verifizierung). Die großen Anbieter – Google, Microsoft, Baidu, Yandex, DuckDuckGo – veröffentlichen Dokumentationen zu ihren Bots und stellen oft Tools oder JSON-Dateien mit ihren offiziellen IPs bereit (Googlebot-IP-Liste, Bingbot-IP-Liste, DuckDuckBot-IPs).
Der Haken dabei: Sich allein auf den User-Agent zu verlassen, ist riskant. Spoofing ist gang und gäbe – bösartige Bots geben sich gern als Googlebot oder Bingbot aus, um an deinen Schutzmechanismen vorbeizukommen (SecurityWeek). Der Goldstandard heißt deshalb doppelte Verifizierung: Prüfe sowohl den User-Agent als auch die IP-Adresse (oder das ASN), etwa per Reverse-DNS-Lookup oder anhand veröffentlichter Listen. Mit einem Tool wie Thunderbit lässt sich dieser Vorgang automatisieren – Logs extrahieren, User-Agents abgleichen und IPs gegenprüfen, um eine vertrauenswürdige Echtzeitliste der Crawler auf deiner Website aufzubauen.
Wie du diese Crawler-Liste nutzen solltest
Was fängst du nun konkret mit einer Liste bekannter Crawler an? So würde ich vorgehen:
- Allowlisting: Sorge dafür, dass die Bots, die du willst (Suchmaschinen, Social-Media-Vorschau-Bots), niemals versehentlich von Firewall, CDN oder WAF blockiert werden. Nutze ihre offiziellen IPs und User-Agents für ein präzises Allowlisting.
- Filterung in der Analyse: Filtere Bot-Traffic aus deinen Analytics, damit deine Zahlen echte menschliche Besucher abbilden – und nicht bloß Googlebot und AhrefsBot, die ihre Runden auf deiner Website drehen (SecurityWeek).
- Bot-Management: Lege Crawl-Delay- oder Drosselungsregeln für aggressive SEO-Tools fest und blockiere oder prüfe unbekannte bzw. bösartige Bots.
- Automatisierte Log-Analyse: Nutze KI-Tools wie Thunderbit, um Crawler-Aktivitäten in deinen Logs zu extrahieren, zu klassifizieren und zu kennzeichnen – so erkennst du Trends, entlarvst Betrüger und hältst deine Richtlinien auf dem aktuellen Stand.
Eine Crawler-Liste aktuell zu halten ist nichts, was man einmal einrichtet und dann vergisst. Neue Bots tauchen auf, alte ändern ihr Verhalten, und Angreifer werden Jahr für Jahr raffinierter. Wer die Updates automatisiert – etwa, indem er offizielle Dokumentationen oder GitHub-Repos mit Thunderbit ausliest –, spart sich Stunden und eine Menge Ärger.
1. Thunderbit: KI-gestützte Crawler-Erkennung und Datenverwaltung
KI-gestütztes Crawler-Management mit Thunderbit Get Started Free
Thunderbit ist nicht bloß ein KI-Web-Scraper – es ist ein Datenassistent für Teams, die Crawler-Traffic verstehen und steuern wollen. Das zeichnet Thunderbit aus:
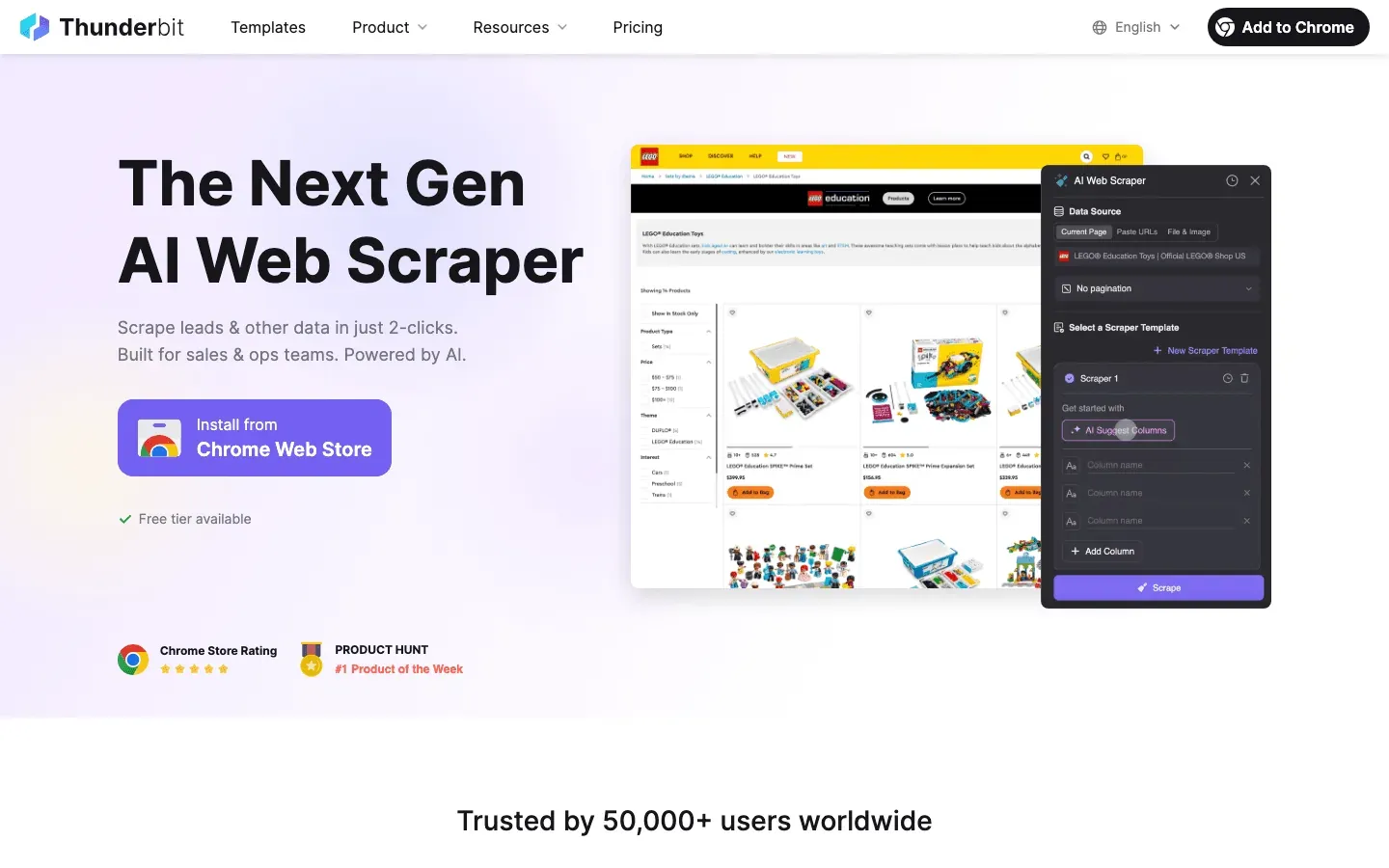
- Semantische Vorverarbeitung: Bevor Daten extrahiert werden, wandelt Thunderbit Webseiten und Logs in Markdown-ähnliche, strukturierte Inhalte um. Diese Vorverarbeitung auf „semantischer Ebene" sorgt dafür, dass die KI Kontext, Felder und Logik des Inhalts tatsächlich erfasst. Ein großer Vorteil bei komplexen, dynamischen oder JavaScript-lastigen Seiten (etwa Facebook Marketplace oder langen Kommentar-Threads), an denen klassische DOM-basierte Scraper schnell scheitern.
- Doppelte Verifizierung: Thunderbit sammelt offizielle Crawler-IP-Dokumente und ASN-Listen im Handumdrehen und gleicht sie mit deinen Server-Logs ab. Das Ergebnis? Eine „vertrauenswürdige Crawler-Allowlist", auf die du dich wirklich verlassen kannst – ohne manuelles Gegenprüfen.
- Automatisierte Log-Extraktion: Übergib Thunderbit deine Roh-Logs, und es verwandelt sie in strukturierte Tabellen (Excel, Sheets, Airtable), inklusive Kennzeichnung von Besuchern mit hoher Frequenz, verdächtigen Pfaden und bekannten Bots. Von dort speist du die Ergebnisse in deine WAF oder dein CDN ein, um automatisches Blockieren, Drosseln oder CAPTCHA-Prüfungen anzustoßen.
- Compliance und Audit: Die semantische Extraktion von Thunderbit liefert eine saubere Prüfkette – wer worauf zugegriffen hat, wann und wie damit umgegangen wurde. Eine enorme Erleichterung für DSGVO, CCPA und weitere Compliance-Anforderungen.
Ich habe Teams gesehen, die mit Thunderbit ihren Aufwand fürs Crawler-Management um 80 % gesenkt haben – und endlich klar erkennen, welche Bots helfen, welche schaden und welche bloß so tun als ob.
Thunderbit für das Crawler-Management ausprobieren
2. Googlebot: Der Standard der Suchmaschinen
Googlebot ist der Goldstandard unter den Web-Crawlern. Er indexiert deine Website für die Google-Suche – sperrst du ihn aus, kannst du auch gleich ein „Geschlossen"-Schild an dein digitales Schaufenster hängen.
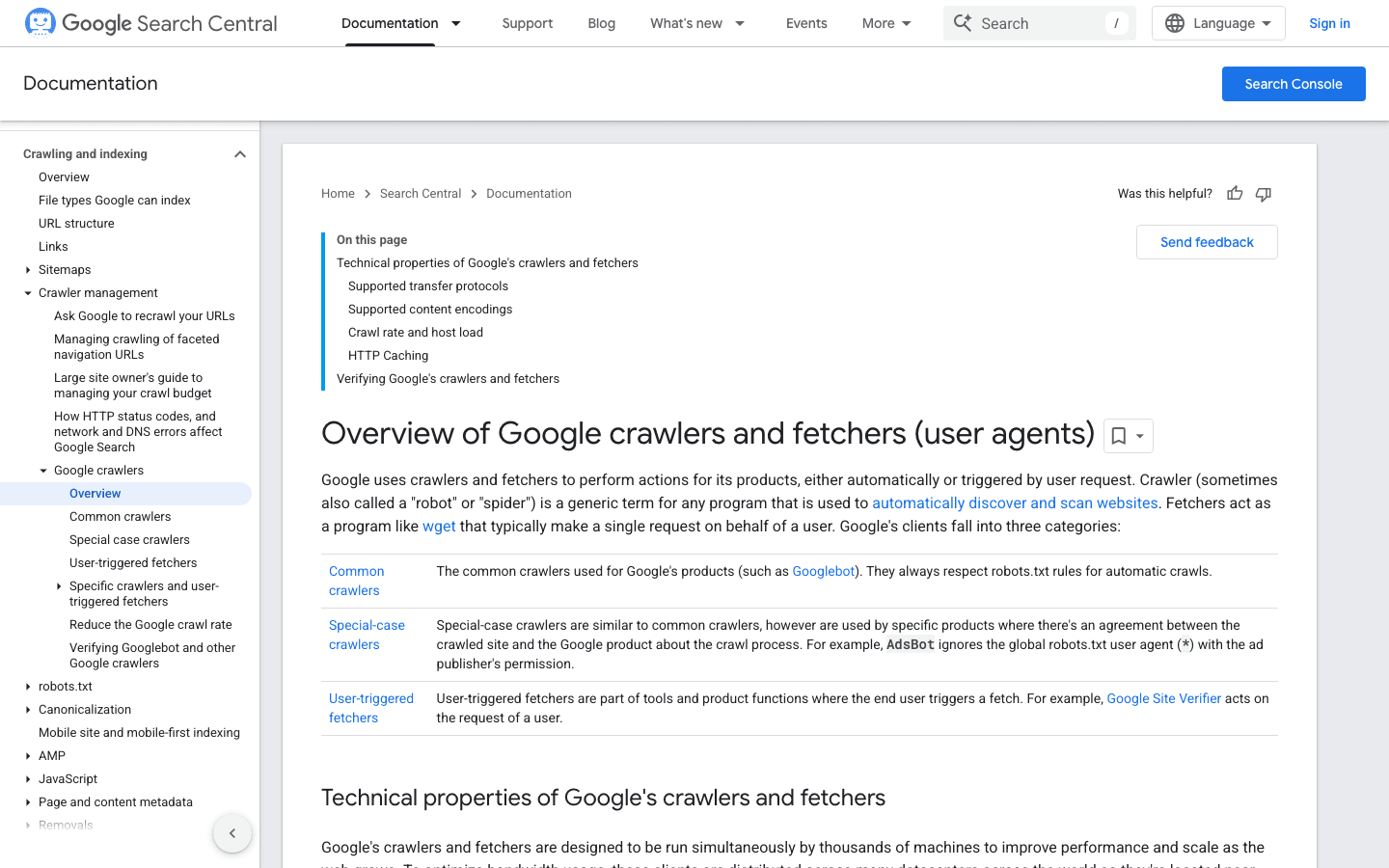
- User-Agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - Verifizierung: Nutze Googles Reverse-DNS-Methode oder die offizielle IP-Liste.
- Management-Tipps: Googlebot immer erlauben. Verwende robots.txt, um sein Crawling zu lenken – nicht, um es zu blockieren – und passe die Crawl-Rate bei Bedarf in der Google Search Console an.
3. Bingbot: Microsofts Web-Explorer
Bingbot liefert die Suchergebnisse für Bing und Yahoo. Für die meisten Websites ist er der zweitwichtigste Crawler.
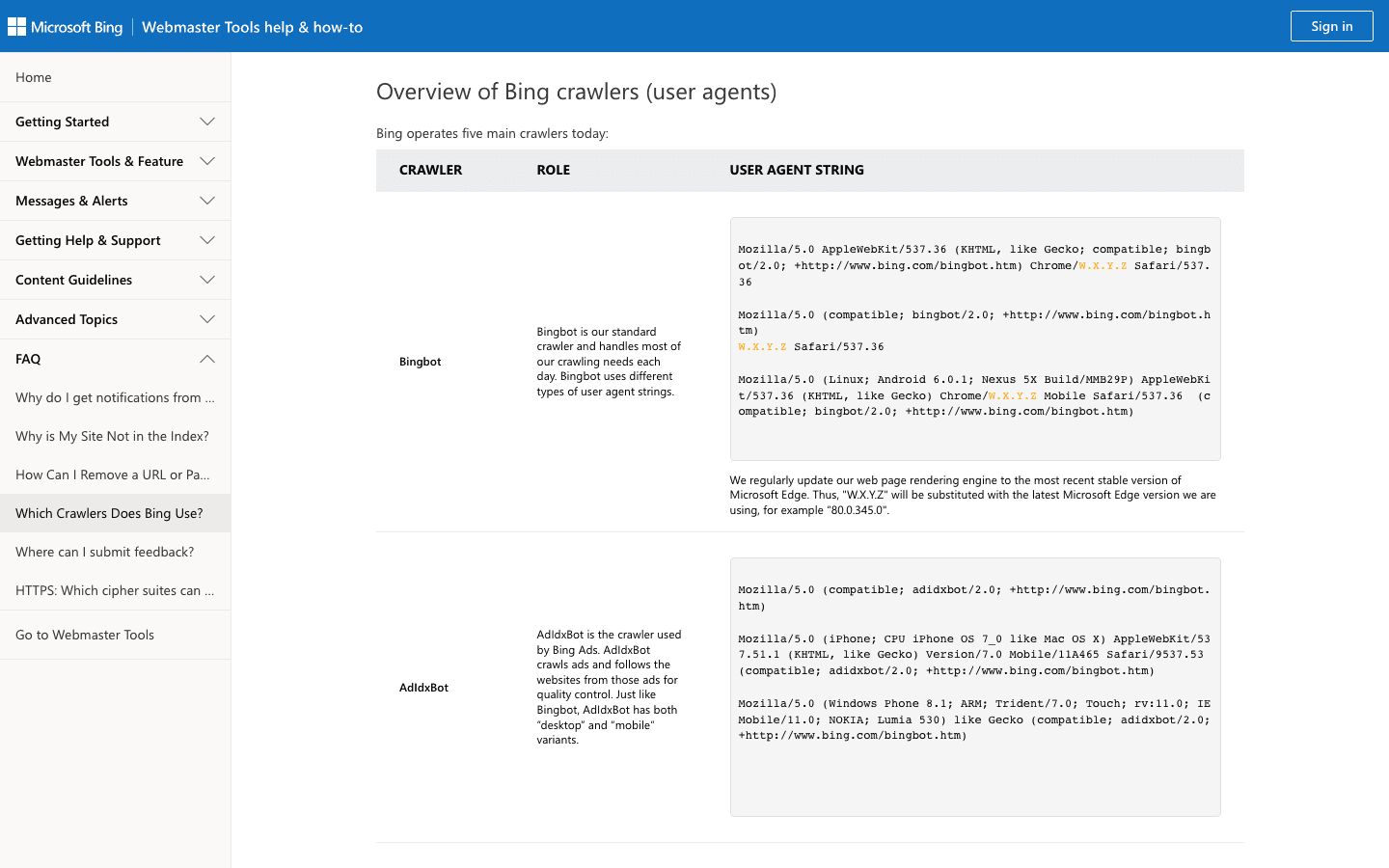
- User-Agent:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - Verifizierung: Nutze Microsofts Prüftool und die offizielle IP-Liste.
- Management-Tipps: Bingbot erlauben, Crawl-Rate in den Bing Webmaster Tools verwalten und robots.txt zur Feinabstimmung nutzen.
4. Baiduspider: Chinas führender Such-Crawler
Baiduspider ist das Tor zum chinesischen Suchverkehr.
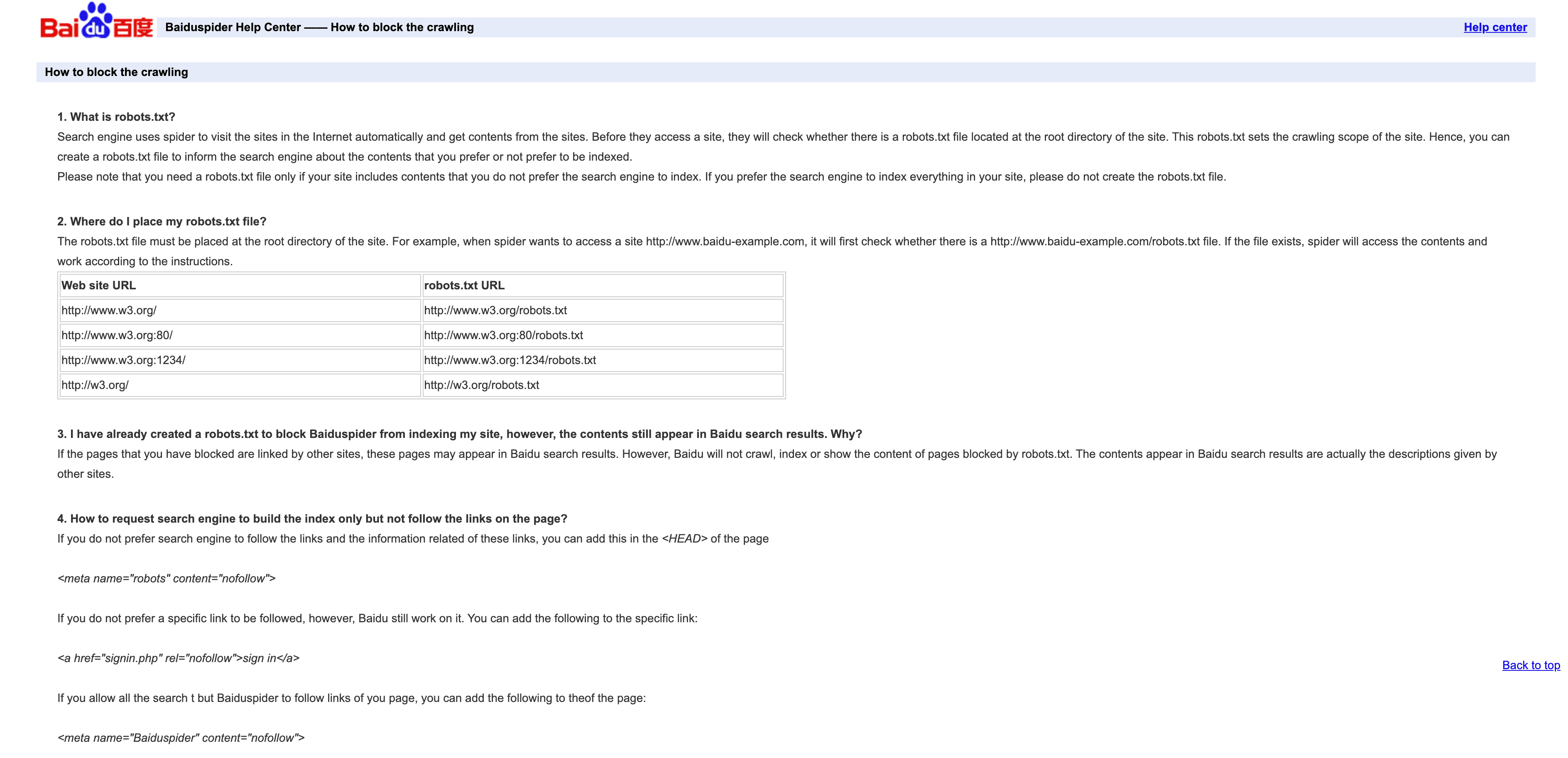
- User-Agent:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html) - Verifizierung: Keine offizielle IP-Liste; prüfe per Reverse DNS auf
.baidu.com, beachte aber die Grenzen dieser Methode. - Management-Tipps: Erlauben, wenn dir chinesischer Traffic wichtig ist. Nutze robots.txt für Regeln, wobei Baiduspider sie gelegentlich ignoriert. Brauchst du kein chinesisches SEO, lohnt sich Drosseln oder Blockieren, um Bandbreite zu sparen.
5. YandexBot: Der Such-Crawler für Russland
YandexBot ist für den russischen Markt und die GUS-Staaten unverzichtbar.
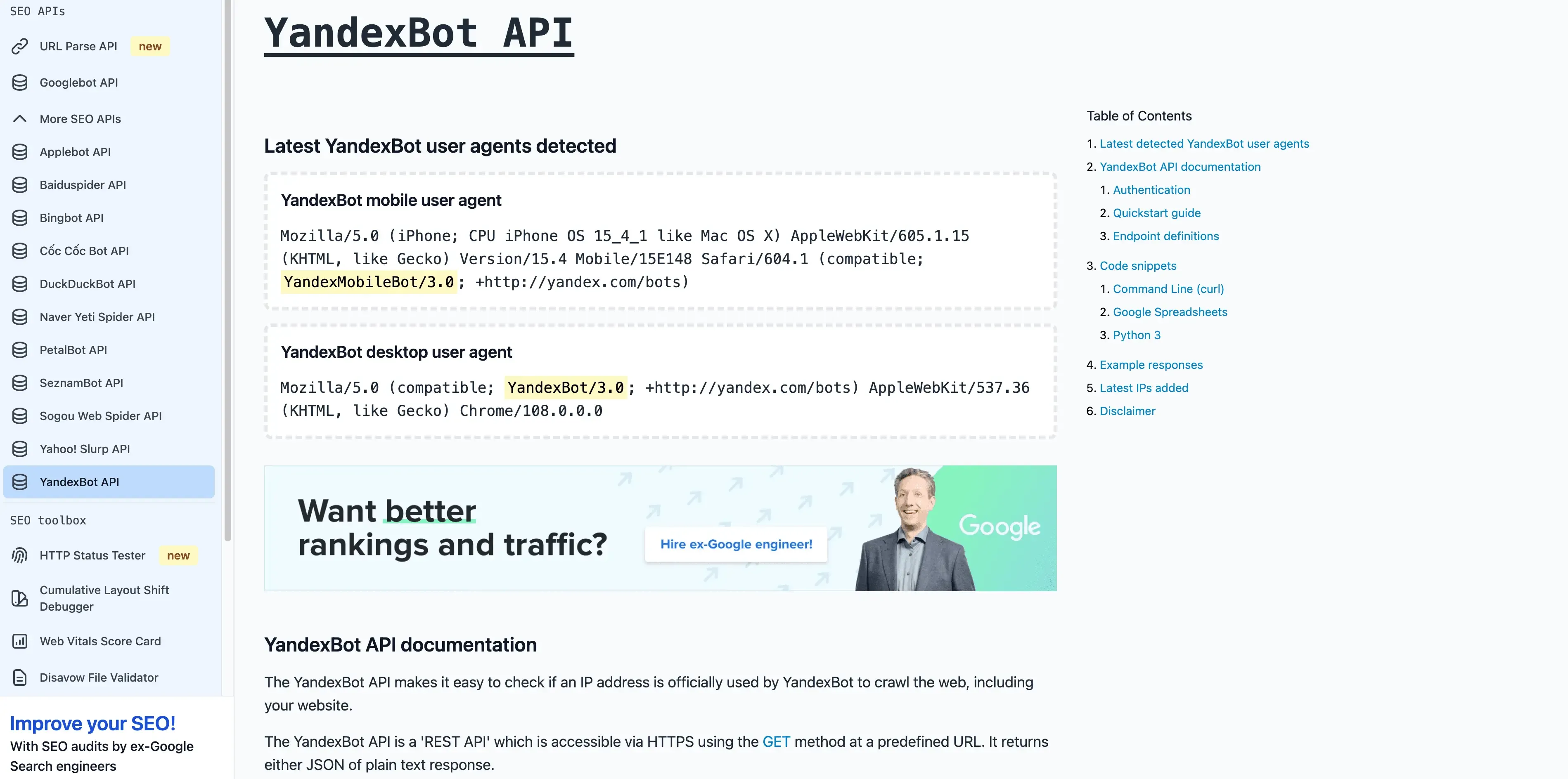
- User-Agent:
Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) - Verifizierung: Reverse DNS sollte auf
.yandex.ru,.yandex.netoder.yandex.comenden. - Management-Tipps: Erlauben, wenn du russischsprachige Nutzer ansprichst. Nutze Yandex Webmaster zur Crawl-Steuerung.
6. DuckDuckBot: Datenschutzorientierter Such-Crawler
DuckDuckBot treibt die datenschutzorientierte Suche von DuckDuckGo an.
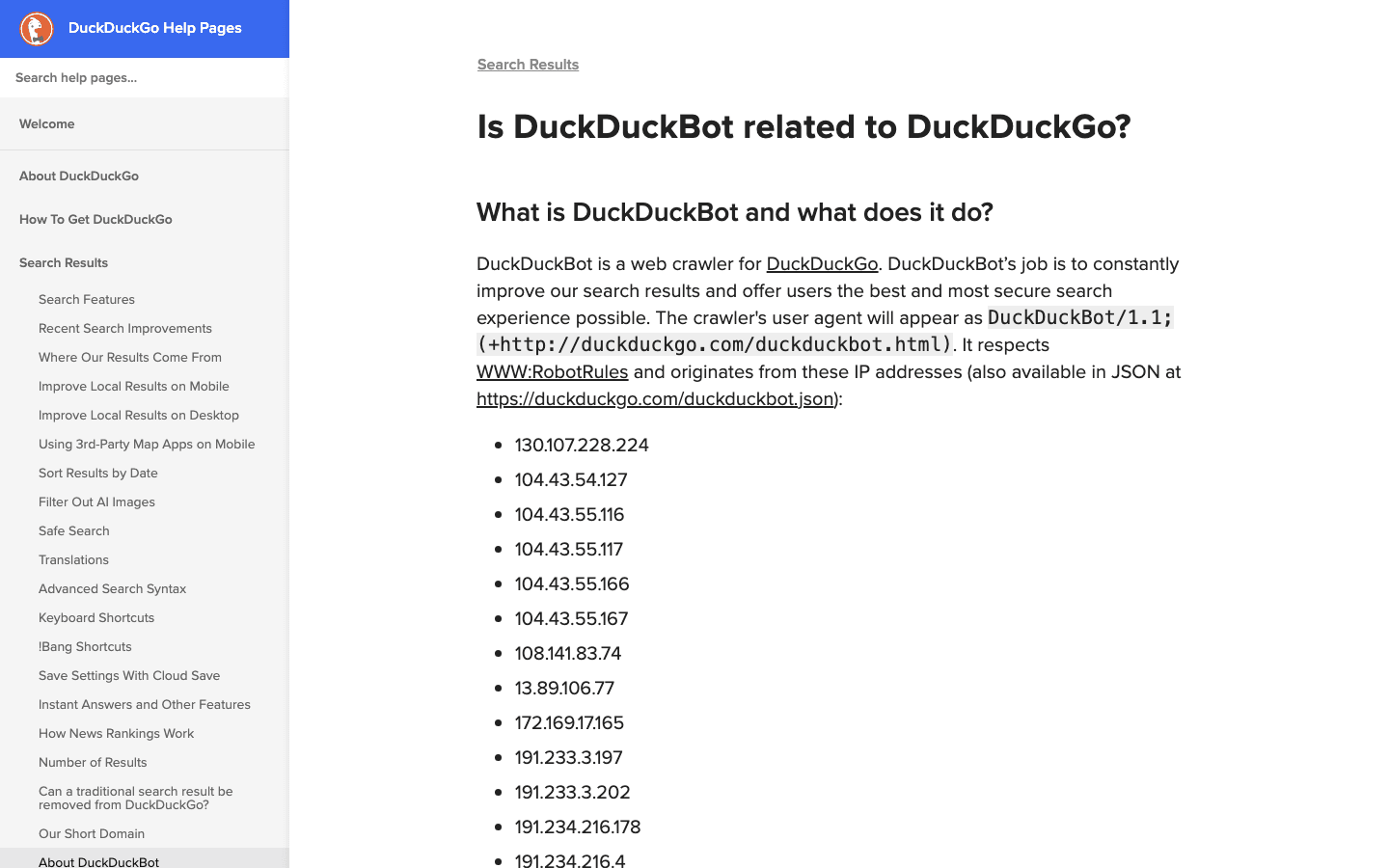
- User-Agent:
DuckDuckBot/1.1; (+http://duckduckgo.com/duckduckbot.html) - Verifizierung: Offizielle IP-Liste (JSON).
- Management-Tipps: Erlauben, sofern du kein Problem mit datenschutzbewussten Nutzern hast. Geringe Crawl-Last, leicht zu verwalten.
7. AhrefsBot: SEO- und Backlink-Analyse
AhrefsBot ist ein wichtiger Crawler für SEO-Tools – hervorragend für Backlink-Analysen, mitunter aber bandbreitenintensiv.
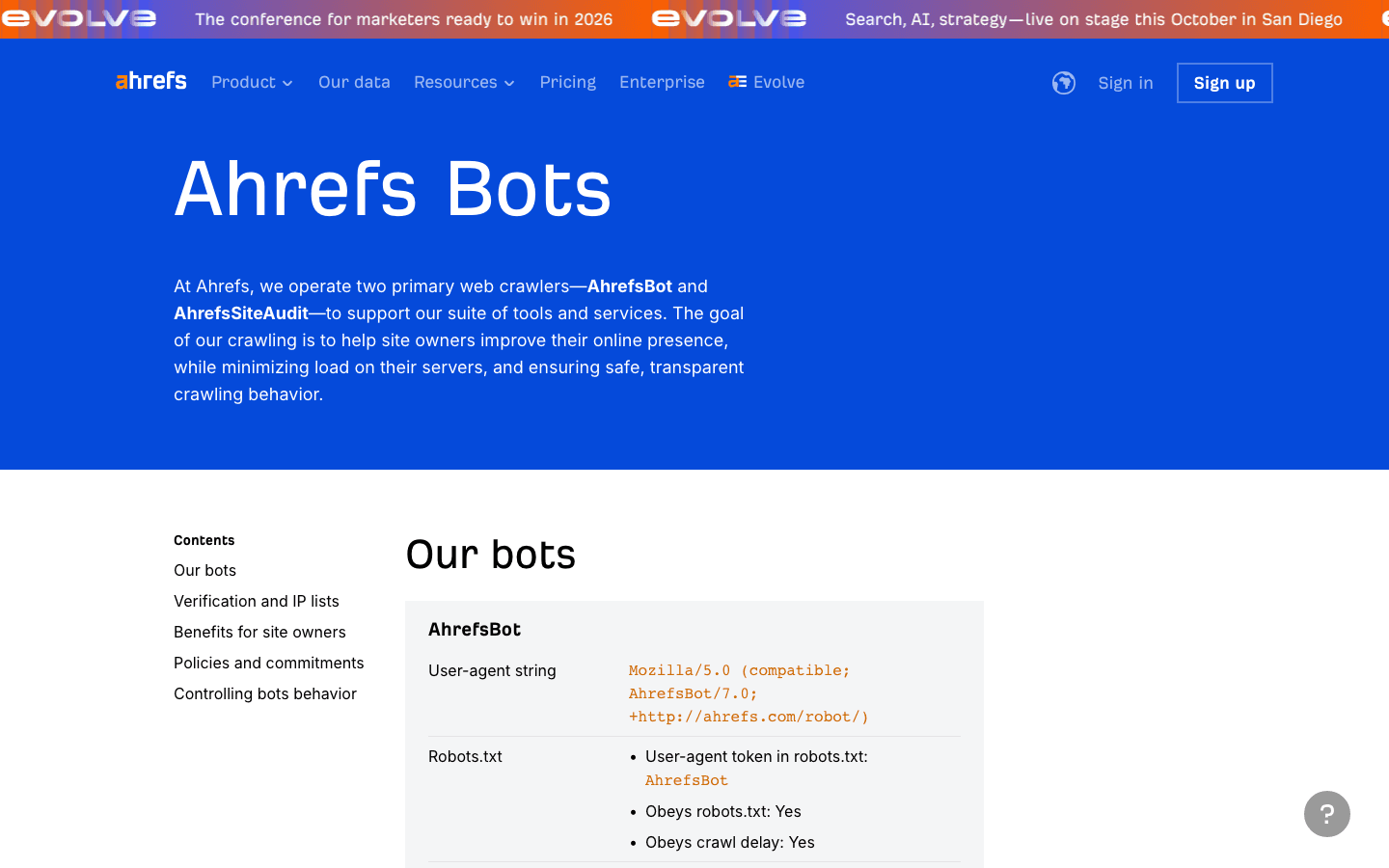
- User-Agent:
Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) - Verifizierung: Keine öffentliche IP-Liste; über User-Agent und Reverse DNS prüfen.
- Management-Tipps: Erlauben, wenn du Ahrefs nutzt. Verwende robots.txt für Crawl-Delay oder Blockierung. Du kannst dich per E-Mail abmelden.
8. SemrushBot: Einblicke in die Konkurrenz-SEO
SemrushBot ist ein weiterer großer SEO-Crawler.
- User-Agent:
Mozilla/5.0 (compatible; SemrushBot/1.0; +http://www.semrush.com/bot.html)(plus Varianten wieSemrushBot-BA,SemrushBot-SIusw.) - Verifizierung: Über den User-Agent; keine öffentliche IP-Liste.
- Management-Tipps: Erlauben, wenn du Semrush nutzt, ansonsten mit robots.txt oder Serverregeln drosseln oder blockieren.
9. FacebookExternalHit: Bot für Social-Media-Vorschauen
FacebookExternalHit holt Open-Graph-Daten für Link-Vorschauen auf Facebook und Instagram.
- User-Agent:
facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) - Verifizierung: Über den User-Agent; die IPs gehören zum ASN von Facebook.
- Management-Tipps: Erlauben, um ansprechende Social Previews zu ermöglichen. Blockierst du ihn, gibt es auf Facebook/Instagram keine Thumbnails oder Zusammenfassungen.
10. Twitterbot: Link-Preview-Crawler für X (Twitter)
Twitterbot holt Twitter-Card-Daten für X (Twitter).
- User-Agent:
Twitterbot/1.0 - Verifizierung: Über den User-Agent; Twitter-ASN (AS13414).
- Management-Tipps: Für Twitter-Vorschauen erlauben. Verwende Twitter-Card-Meta-Tags für beste Ergebnisse.
Vergleichstabelle: Crawler auf einen Blick
| Crawler | Zweck | User-Agent-Beispiel | Verifizierungsmethode | Geschäftliche Auswirkung | Management-Tipps |
|---|---|---|---|---|---|
| Thunderbit | KI-Analyse von Logs/Crawlern | N/A (Tool, kein Bot) | N/A | Datenverwaltung, Bot-Klassifizierung | Für Log-Extraktion, Aufbau von Allowlists nutzen |
| Googlebot | Google-Suche indexieren | Googlebot/2.1 | DNS- & IP-Liste | Kritisch für SEO | Immer erlauben, über die Search Console verwalten |
| Bingbot | Bing-/Yahoo-Suche | bingbot/2.0 | DNS- & IP-Liste | Wichtig für Bing-/Yahoo-SEO | Erlauben, über Bing Webmaster Tools verwalten |
| Baiduspider | Baidu-Suche (China) | Baiduspider/2.0 | Reverse DNS, UA-Zeichenfolge | Entscheidend für China-SEO | Erlauben, wenn du China ansprichst, Bandbreite überwachen |
| YandexBot | Yandex-Suche (Russland) | YandexBot/3.0 | Reverse DNS auf .yandex.ru | Entscheidend für Russland/Osteuropa | Erlauben, wenn du RU/GUS ansprichst, Yandex-Tools nutzen |
| DuckDuckBot | DuckDuckGo-Suche | DuckDuckBot/1.1 | Offizielle IP-Liste | Datenschutzorientierte Zielgruppe | Erlauben, geringe Auswirkung |
| AhrefsBot | SEO-/Backlink-Analyse | AhrefsBot/7.0 | UA-Zeichenfolge, Reverse DNS | SEO-Tool, kann bandbreitenintensiv sein | Erlauben/drosseln/blockieren via robots.txt |
| SemrushBot | SEO-/Konkurrenzanalyse | SemrushBot/1.0 (plus Varianten) | UA-Zeichenfolge | SEO-Tool, kann aggressiv sein | Erlauben/drosseln/blockieren via robots.txt |
| FacebookExternalHit | Social-Link-Vorschauen | facebookexternalhit/1.1 | UA-Zeichenfolge, Facebook-ASN | Social-Media-Engagement | Für Vorschauen erlauben, OG-Tags nutzen |
| Twitterbot | Twitter-Link-Vorschauen | Twitterbot/1.0 | UA-Zeichenfolge, Twitter-ASN | Twitter-Engagement | Für Vorschauen erlauben, Twitter-Card-Tags nutzen |
Deine Crawler-Liste verwalten: Best Practices für 2025
Mehr über List Crawling mit KI erfahren Get Started Free
- Regelmäßig aktualisieren: Die Crawler-Landschaft verändert sich rasant. Plane vierteljährliche Überprüfungen ein und nutze Tools wie Thunderbit, um offizielle Listen zu scrapen und zu vergleichen (Human Security).
- Verifizieren, nicht vertrauen: Prüfe immer sowohl User-Agent als auch IP/ASN. Lass keine Betrüger durchrutschen, die deine Analysedaten verfälschen oder deine Daten scrapen (FriendlyCaptcha).
- Gute Bots auf die Allowlist setzen: Sorge dafür, dass Such- und Social-Crawler nie durch Anti-Bot-Regeln oder Firewalls blockiert werden.
- Aggressive Bots drosseln oder blockieren: Nutze robots.txt, Crawl-Delay oder Serverregeln für SEO-Tools, die zu viel Last erzeugen.
- Log-Analyse automatisieren: Setze KI-gestützte Tools wie Thunderbit ein, um Crawler-Aktivitäten zu extrahieren, zu klassifizieren und zu kennzeichnen – das spart Zeit und deckt Trends auf, die dir sonst entgehen.
- SEO, Analytics und Sicherheit in Balance halten: Blockiere nicht die Bots, die dein Geschäft voranbringen, lass die schlechten aber auch nicht ungehindert gewähren.
Thunderbit-Chrome-Erweiterung herunterladen
Fazit: Deine Crawler-Liste aktuell und handlungsfähig halten
Im Jahr 2025 ist die Verwaltung deiner Crawler-Liste längst keine reine IT-Aufgabe mehr – sie ist geschäftskritisch und berührt SEO, Analytics, Sicherheit und Compliance. Da Bots inzwischen die Mehrheit des Web-Traffics stellen, musst du wissen, wer deine Website besucht, warum und was du tun solltest. Halte deine Liste aktuell, automatisiere, wo es geht, und nutze Tools wie Thunderbit, um einen Schritt voraus zu bleiben. Das Web wird nur noch voller – und eine kluge, umsetzbare Crawler-Strategie ist deine beste Verteidigung und dein stärkster Hebel in einer von Bots geprägten Welt.
FAQs
1. Warum ist es wichtig, eine aktuelle Crawler-Liste zu pflegen?
Weil Bots inzwischen über die Hälfte des Web-Traffics ausmachen und nur ein kleiner Teil davon nützlich ist. Eine aktuelle Liste stellt sicher, dass du die guten Bots für SEO und Social Previews zulässt und die schlechten blockierst oder drosselst – zum Schutz deiner Analytics, deiner Bandbreite und deiner Datensicherheit.
2. Woran erkenne ich, ob ein Crawler echt oder gefälscht ist?
Vertrau nicht allein dem User-Agent – verifiziere immer die IP-Adresse oder das ASN über offizielle Listen oder Reverse-DNS-Lookups. Tools wie Thunderbit automatisieren diesen Vorgang, indem sie Logs mit veröffentlichten Bot-IPs und User-Agents abgleichen.
3. Was sollte ich tun, wenn ein unbekannter Bot meine Website crawlt?
Schau dir User-Agent und IP genauer an. Steht er nicht auf deiner Allowlist und passt zu keinem bekannten Bot, solltest du ihn drosseln, prüfen oder blockieren. Nutze KI-Tools, um neue Crawler zu klassifizieren und zu beobachten, sobald sie auftauchen.
4. Wie hilft Thunderbit beim Crawler-Management?
Thunderbit nutzt KI, um Crawler-Aktivitäten aus Logs zu extrahieren, zu strukturieren und zu klassifizieren. So baust du mühelos Allowlists auf, entlarvst Betrüger und automatisierst Richtlinien. Die semantische Vorverarbeitung erweist sich gerade bei komplexen oder dynamischen Websites als besonders robust.
5. Was ist das Risiko, einen großen Crawler wie Googlebot oder Bingbot zu blockieren?
Blockierst du Suchmaschinen-Crawler, kann deine Website aus den Suchergebnissen verschwinden und dein organischer Traffic einbrechen. Prüfe daher immer doppelt Firewall, robots.txt und Anti-Bot-Regeln, damit du nicht versehentlich die wichtigsten Bots aussperrst.
Mehr erfahren:
- Wie du mit KI jede Website scrapen kannst
- Python-Leitfaden für Web-Scraping: Lernen anhand echter Beispiele
- Die ultimative Liste der Web-Crawler und guten Bots für 2025: Erkennung, Beispiele und Best Practices
- Die beliebtesten Web-Crawler-Bots
Thunderbit für KI-gestütztes Crawler-Management ausprobieren Get Started Free




