

„Darf man Daten von Websites eigentlich scrapen?“ – diese Frage landet fast jede Woche auf meinem Tisch, gestellt von Sales-, Operations- oder Marketing-Teams. Kein Wunder: Web-Scraping ist für Leadgenerierung, Marktanalysen und Wettbewerbsbeobachtung längst unverzichtbar, und alle hätten gern eine klare Antwort. Die ist nur leider selten zu haben. Die Rechtslage gleicht oft einem überfüllten Schreibtisch, auf dem niemand mehr durchblickt: Mal heißt es in den Nachrichten, das Scrapen öffentlicher Daten sei erlaubt, mal wird vor „illegaler Datenerhebung“ gewarnt. Entsprechend unsicher sind viele Unternehmen, wo genau die rote Linie verläuft.
Fakt ist: Über zwei Drittel aller Unternehmen setzen Web-Scraping für Analysen und KI-Projekte ein, und ganze 78 % der E-Commerce-Firmen nutzen es für Preisanalysen. Gleichzeitig hat das Risiko mit bekannten Verfahren wie LinkedIn gegen hiQ Labs zugenommen. Wie nutzt man Webdaten also clever, ohne rechtlich ins Schleudern zu geraten? Wir gehen die wichtigsten rechtlichen Rahmenbedingungen, Compliance-Checks und Best Practices durch, die du kennen solltest. Und ja – ich zeige dir auch, wie Thunderbit rechtssicheres Scrapen denkbar einfach macht.
Rechtlicher Rahmen: Ist das Scrapen von Daten auf Websites legal?
Rechtliche Aspekte von Web-Scraping Erfahre mehr über die rechtlichen Grundlagen des Web-Scrapings und wie du auf der sicheren Seite bleibst. Get Started Free
Kommen wir direkt zur Sache: Ob Web-Scraping legal ist, hängt davon ab, was du scrapen willst, wie du es machst und in welchem Land du dich befindest. Es gibt kein weltweites Gesetz, das Scraping pauschal erlaubt oder verbietet. Stattdessen herrscht ein Flickenteppich an Vorschriften – von Anti-Hacking-Gesetzen über Datenschutz und Urheberrecht bis hin zu den Nutzungsbedingungen der jeweiligen Website (Thunderbit Blog).
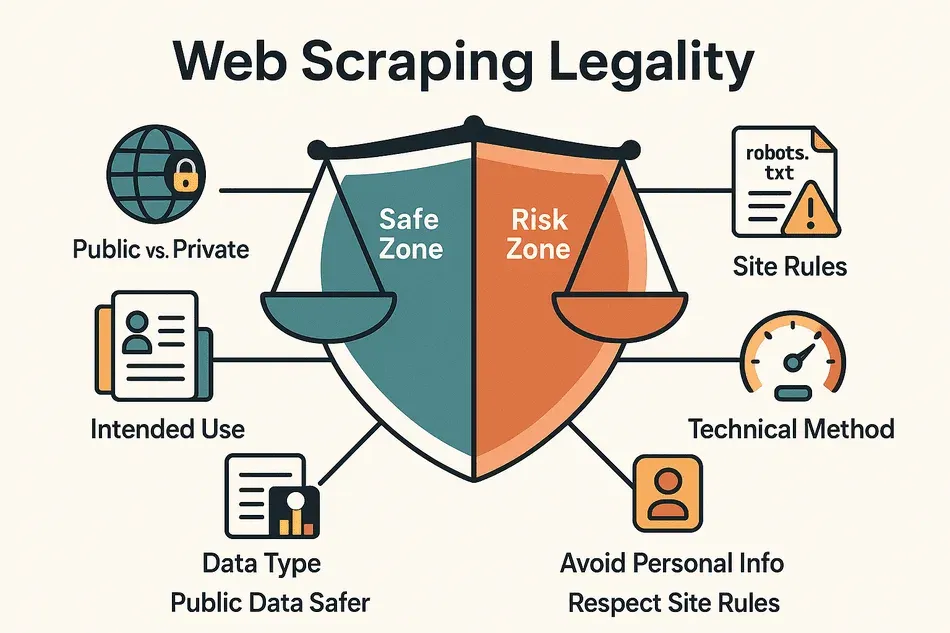
Diese Punkte entscheiden, ob dein Scraping-Projekt rechtlich auf festem Boden steht:
- Öffentliche vs. private Daten: Frei zugängliche Daten (ohne Login oder Bezahlschranke) zu scrapen, ist meist unproblematisch. Wer Inhalte hinter einem Login abruft, landet schnell im Graubereich.
- Art der Daten: Persönliche Daten (Namen, E-Mails, Social-Media-Profile) und urheberrechtlich geschützte Inhalte (Texte, Bilder) sind deutlich riskanter als reine Fakten (Preise, Produktdaten, Unternehmenslisten).
- Verwendungszweck: Die interne Nutzung (z. B. für Analysen) ist rechtlich weniger heikel als das Veröffentlichen oder Verkaufen der Daten.
- Einhaltung der Website-Regeln: Wer gegen Nutzungsbedingungen oder robots.txt verstößt, riskiert Ärger – selbst bei öffentlichen Daten.
- Technische Umsetzung: Wer in menschlichem Tempo scrapt und keine Schutzmechanismen (CAPTCHAs, IP-Sperren) umgeht, ist meist auf der sicheren Seite.
 (https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
Das Fazit: Das Scrapen öffentlicher, nicht-personenbezogener Daten für interne Zwecke ist in vielen Ländern in Ordnung – aber es gibt wichtige Einschränkungen, vor allem bei Datenschutz, Urheberrecht und Scraping-Intensität (Thunderbit Blog).
(https://strapi.thunderbit.com/uploads/webscrapinglegalitysafevsriskzones_6ee3935a34.png)
Das Fazit: Das Scrapen öffentlicher, nicht-personenbezogener Daten für interne Zwecke ist in vielen Ländern in Ordnung – aber es gibt wichtige Einschränkungen, vor allem bei Datenschutz, Urheberrecht und Scraping-Intensität (Thunderbit Blog).
Rechtliche Grundlagen: Die wichtigsten internationalen Regelungen im Überblick
 Hier ein kompakter Überblick über die wichtigsten rechtlichen Rahmenbedingungen weltweit:
Hier ein kompakter Überblick über die wichtigsten rechtlichen Rahmenbedingungen weltweit:
USA: CFAA, Urheberrecht und Verträge
- Computer Fraud and Abuse Act (CFAA): Dieses Anti-Hacking-Gesetz verbietet den unbefugten Zugriff auf Computersysteme. Gerichte haben jedoch klargestellt, dass das Scrapen öffentlicher Websites nicht gegen den CFAA verstößt, weil keine „Autorisierung“ nötig ist (California Lawyers Association).
- Präzedenzfall: Im Fall hiQ Labs gegen LinkedIn entschied das Gericht, dass das Scrapen öffentlicher LinkedIn-Profile nicht gegen den CFAA verstößt. LinkedIn kann aber weiterhin wegen Vertragsbruchs (Verstoß gegen die Nutzungsbedingungen) oder Urheberrechtsverletzung klagen.
- Weitere Risiken: Wer exzessiv scrapt (wie im Fall eBay gegen Bidder’s Edge mit 100.000 Anfragen pro Tag), kann wegen „trespass to chattels“ (Störung fremder Server) belangt werden (Wikipedia).
Europäische Union: DSGVO und Datenbankrechte
- DSGVO: Die Datenschutz-Grundverordnung gilt auch für öffentlich zugängliche personenbezogene Daten. Wer solche Daten scrapt, braucht eine Rechtsgrundlage (z. B. Einwilligung oder berechtigtes Interesse) und muss strenge Datenschutzregeln einhalten.
- Datenbankrichtlinie: Die EU schützt auch ganze Datenbanken. Wer einen „wesentlichen Teil“ einer strukturierten Datenbank scrapt (z. B. alle Immobilienanzeigen), kann gegen Datenbankrechte verstoßen – auch wenn die einzelnen Fakten nicht urheberrechtlich geschützt sind (Thunderbit Blog).
Vereinigtes Königreich: UK-DSGVO und Datenschutzgesetz
- UK-DSGVO: Nach dem Brexit gelten ähnliche Regeln wie in der EU. Öffentlich zugängliche, nicht-personenbezogene Daten zu scrapen ist meist erlaubt, bei personenbezogenen Daten gelten strenge Vorgaben.
- Computer Misuse Act: Ähnlich wie der CFAA kann unbefugter Zugriff strafbar sein.
China: PIPL und Datensicherheitsgesetz
- Personal Information Protection Law (PIPL): Verlangt eine Einwilligung für das Sammeln personenbezogener Daten. Das Scrapen persönlicher Informationen ohne Zustimmung ist verboten.
- Datensicherheitsgesetz: Wird genutzt, um Scraping zu unterbinden, das Dateninhaber schädigt oder unlauteren Wettbewerb fördert.
Weitere Regionen
- Kanada, Australien, APAC: Die meisten Länder haben Anti-Hacking- und Datenschutzgesetze ähnlich wie die EU oder das UK. Prüfe immer die lokalen Vorschriften.
Wichtig: Am sichersten fährst du, wenn du öffentliche, nicht-personenbezogene Daten für interne Zwecke scrapst – und dabei stets die lokalen Gesetze beachtest (Thunderbit Blog).
Compliance-Checkliste: So stellst du sicher, dass dein Scraping legal ist
Bevor du dein Scraping-Projekt startest, arbeite diese Checkliste ab:
- Nutzungsbedingungen lesen: Verbieten die ToS Scraping, dann lieber stoppen oder eine Erlaubnis einholen (Thunderbit Blog).
- Nur öffentliche Daten scrapen: Keine Inhalte hinter Login oder Bezahlschranke ohne ausdrückliche Genehmigung.
- robots.txt prüfen: Unter
site.com/robots.txtsiehst du, ob Bots bestimmte Bereiche meiden sollen. Rechtlich bindend ist das nicht, aber sich daran zu halten ist guter Stil. - Keine personenbezogenen Daten: Namen, E-Mails oder andere persönliche Infos nur mit Rechtsgrundlage und Datenschutzkonzept scrapen.
- Keine kreativen Inhalte kopieren: Bleib bei Fakten und Datenpunkten. Das Veröffentlichen von Artikeln, Bildern oder großen Textmengen kann Urheberrechtsprobleme nach sich ziehen.
- Offizielle APIs nutzen: Wird eine API angeboten, nutze sie – das ist sicherer und stabiler.
- Schonend scrapen: Server nicht überlasten. In menschlichem Tempo scrapen und keine technischen Schutzmaßnahmen umgehen.
- Prozess dokumentieren: Halte fest, was, wann und warum du gescrapt hast. Das hilft bei späteren Rückfragen.
- Bereit sein zu stoppen: Bei einer Abmahnung sofort das Scraping einstellen und prüfen.
Thunderbits Compliance-Strategie: So wird Datenscraping sicher und zuverlässig
Als wir Thunderbit entwickelt haben, stand Compliance ganz oben. So hilft dir Thunderbit, rechtlich auf der sicheren Seite zu bleiben:
- Browserbasiertes Scraping: Thunderbit scrapt nur das, was im Browser sichtbar ist – keine versteckten API-Aufrufe, kein Umgehen von Logins. Was du nicht siehst, kann Thunderbit auch nicht scrapen (Thunderbit Blog).
- Integrierte Warnungen: Versuchst du, eine Website mit strikten Anti-Scraping-Regeln zu scrapen, warnt dich Thunderbit sofort. Fast wie ein Compliance-Experte, der dir über die Schulter schaut.
- KI-Feldvorschläge: Thunderbits KI analysiert die Seite und schlägt nur relevante Felder vor – so vermeidest du, versehentlich sensible Daten zu scrapen (Thunderbit Blog).
- Menschliches Tempo: Ob lokal oder in der Cloud – Thunderbit scrapt in angemessenem Tempo, damit Server nicht überlastet werden.
- Keine Datenspeicherung auf unseren Servern: Deine gescrapten Daten gehören dir – Thunderbit speichert keine Kopien, was den Datenschutz vereinfacht.
- Compliance-freundliche Exporte: Exportiere Daten direkt nach Google Sheets, Excel, Airtable oder Notion – perfekt für die interne Nutzung.
- Unterseiten & Paginierung: Thunderbit navigiert wie ein echter Nutzer durch Seiten und Unterseiten, ohne Schnittstellen zu überlasten.
- Geplantes Scraping mit Augenmaß: Du kannst Scraping-Aufgaben zeitlich steuern, ohne eine Website zu überlasten.
- Mehrsprachige Oberfläche: Thunderbit unterstützt 34 Sprachen, damit Compliance-Hinweise weltweit verständlich sind.
Kurz gesagt: Thunderbit verankert Compliance direkt im Produkt, sodass du auch ohne juristische Vorkenntnisse verantwortungsvoll scrapen kannst (Thunderbit Blog).
Thunderbit für rechtssicheres Web-Scraping testen
Daten scrapen vs. Daten wiederverwenden: Wo verläuft die rechtliche Grenze?
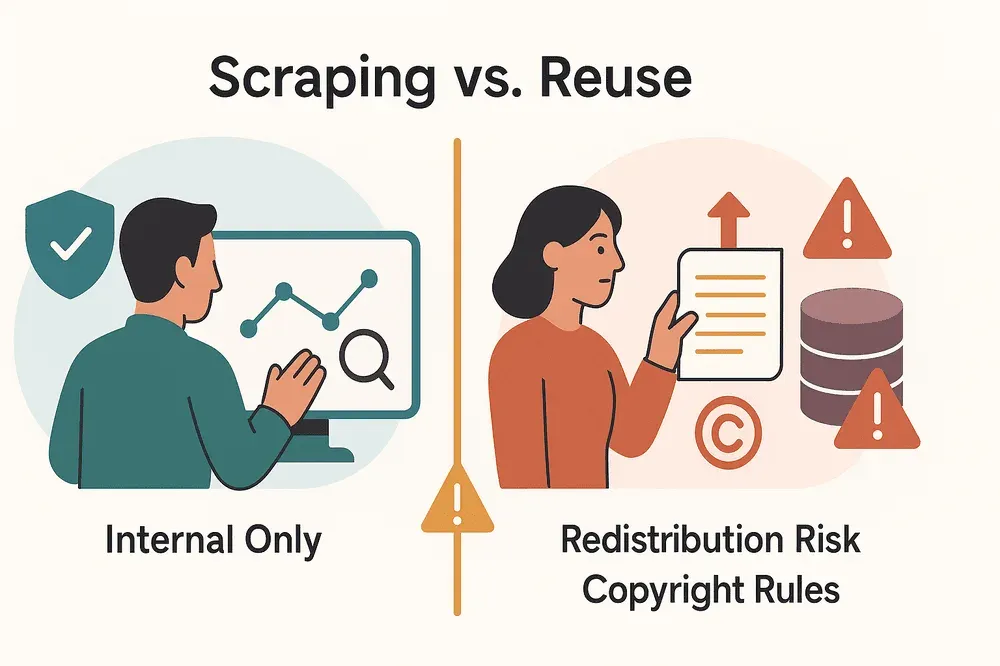 Es macht einen Unterschied, ob du Daten für dich selbst scrapst oder sie weiterverbreitest, verkaufst oder anderweitig nutzt. Hier wird es rechtlich knifflig:
Es macht einen Unterschied, ob du Daten für dich selbst scrapst oder sie weiterverbreitest, verkaufst oder anderweitig nutzt. Hier wird es rechtlich knifflig:
- Interne Nutzung: Öffentliche Daten für interne Analysen zu scrapen (z. B. Leads, Preisbeobachtung) ist meist unproblematisch – solange keine personenbezogenen Daten betroffen sind oder Datenschutzgesetze verletzt werden.
- Weitergabe oder Verkauf: Das Veröffentlichen oder Verkaufen gescrapter Daten (z. B. auf der eigenen Website oder als Produkt) kann Urheberrechte, Datenbankrechte oder Vertragsbedingungen verletzen.
- Urheber- & Datenbankrechte: In den USA sind Fakten nicht urheberrechtlich geschützt, wohl aber kann es die Auswahl oder Anordnung der Daten sein. In der EU/UK kann das Scrapen eines „wesentlichen Teils“ einer Datenbank gegen das Datenbankrecht verstoßen.
- Fair Use: In den USA gibt es das Prinzip „Fair Use“ (z. B. für Kommentare oder Analysen), aber das bloße Kopieren großer Inhalte ist fast nie erlaubt.
- Quellenangabe: Wenn du gescrapte Daten veröffentlichst, solltest du die Quelle angeben – legal wird es dadurch allein aber nicht, wenn andere Rechte verletzt werden.
- Keine Rohdaten verkaufen: Der Verkauf unbearbeiteter, gescrapter Datensätze ist besonders riskant. Nutze die Daten lieber für eigene Analysen und Erkenntnisse.
Tipp: Verwende gescrapte Daten für interne Auswertungen und Entscheidungen. Musst du sie extern teilen, aggregiere oder transformiere sie und prüfe, ob du eine Erlaubnis brauchst (Thunderbit Blog).
Praxisbeispiele: So lassen sich rechtliche Risiken minimieren
Ein Blick auf echte Fälle – denn aus den Fehlern anderer lernt man am meisten:
LinkedIn gegen hiQ Labs
- Was ist passiert: hiQ Labs hat öffentliche LinkedIn-Profile gescrapt, um Analysen zur Mitarbeiterfluktuation zu erstellen. LinkedIn wollte das verhindern, doch das Gericht entschied, dass das Scrapen öffentlicher Daten in den USA zulässig ist.
- Lektion: Das Scrapen öffentlicher Daten ist in den USA rechtlich in Ordnung, aber Nutzungsbedingungen und Datenschutzvorgaben müssen beachtet werden (California Lawyers Association).
eBay gegen Bidder’s Edge
- Was ist passiert: Bidder’s Edge hat eBays Auktionsdaten extrem aggressiv gescrapt (100.000 Anfragen/Tag) und dabei gegen Nutzungsbedingungen und robots.txt verstoßen. Das Gericht untersagte das Scraping wegen „trespass to chattels“.
- Lektion: Auch das Scrapen öffentlicher Daten kann illegal sein, wenn es zu aggressiv erfolgt oder gegen klare Regeln verstößt (Wikipedia).
Facebook (Meta) gegen Power Ventures
- Was ist passiert: Power Ventures hat Facebook-Daten mit Nutzerzustimmung gescrapt. Nachdem Facebook den Zugang sperrte, scrapte Power Ventures weiter. Das Gericht wertete dies als „unbefugten Zugriff“.
- Lektion: Untersagt ein Website-Betreiber das Scraping, muss man aufhören – sonst drohen rechtliche Konsequenzen.
Compliance-Erfolgsgeschichten
Viele Preisvergleichsportale in der EU arbeiten legal, indem sie nur Fakten scrapen, Opt-Outs respektieren und keine kompletten Datenbanken abgreifen. Dass hier kaum geklagt wird, zeigt: Wer öffentliche, nicht-personenbezogene Daten nutzt und die Regeln einhält, ist auf der sicheren Seite.
Wie Thunderbit hilft
Thunderbits Warnungen, Geschwindigkeitsbegrenzungen und der browserbasierte Ansatz hätten viele dieser Fehler verhindert – durch Hinweise auf riskante Seiten und standardmäßig schonendes Scraping.
Compliance-Selbstcheck für Scraping-Projekte im Unternehmen
Hier eine praktische Checkliste für dein nächstes Scraping-Projekt:
- Sind die Daten öffentlich? (Kein Login nötig)
- Was sagen die Nutzungsbedingungen? (Gibt es Anti-Scraping-Klauseln?)
- Hast du robots.txt geprüft? (Ist der Zielbereich gesperrt?)
- Werden personenbezogene Daten gescrapt? (Falls ja: Gibt es ein Datenschutzkonzept?)
- Scrapest du einen großen Teil der Website? (Vermeide das Abgreifen kompletter Datenbanken)
- Wofür werden die Daten genutzt? (Interne Nutzung = sicherer; Veröffentlichung = riskanter)
- Scrapest du schonend? (Menschliches Tempo, keine technischen Sperren umgehen)
- Gibt es eine API? (Nutze sie, falls vorhanden)
- Bist du bereit, bei Aufforderung zu stoppen? (Plan für Abmahnungen vorhanden?)
- Wie speicherst und schützt du die Daten? (Zugriff beschränken, Datenschutz beachten)
- Dokumentierst du den Prozess? (Für die Nachvollziehbarkeit)
Beantwortest du eine Frage mit „Nein“ oder bist dir unsicher, halte das Projekt erst einmal an und schaffe Klarheit (Thunderbit Blog).
Beispiel-Workflow für rechtssicheres Scraping mit Thunderbit
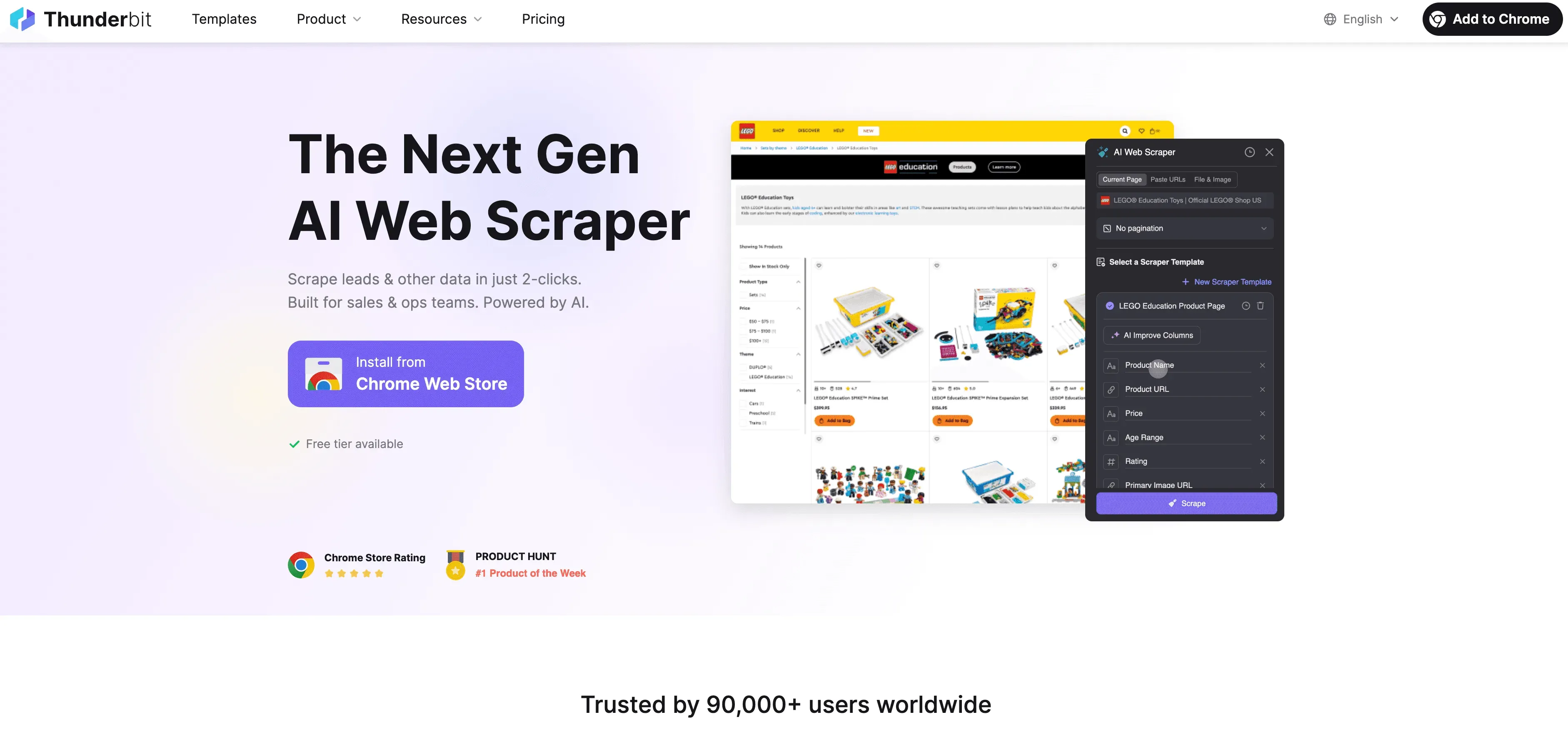 So könnte ein typischer, compliance-freundlicher Workflow mit Thunderbit aussehen:
So könnte ein typischer, compliance-freundlicher Workflow mit Thunderbit aussehen:
- Vorab-Check: robots.txt und Nutzungsbedingungen prüfen. Keine Anti-Scraping-Klauseln? Dann los.
- Thunderbit öffnen: Zielseite im Browser aufrufen und die Thunderbit Chrome Extension starten.
- KI-Feldvorschläge: Thunderbits KI schlägt relevante, nicht-sensible Felder vor. Prüfe, dass keine personenbezogenen Daten enthalten sind – außer du hast eine Rechtsgrundlage.
- Felder anpassen: Spalten und Datentypen nach Bedarf anpassen – nur das sammeln, was wirklich gebraucht wird.
- Scrapen: Auf „Scrape“ klicken. Thunderbit extrahiert die Daten in angemessenem Tempo und respektiert die Seitenstruktur.
- Unterseiten scrapen: Bei Bedarf die Unterseiten-Funktion nutzen, um Daten zu ergänzen – aber nur für öffentliche Infos.
- Exportieren: Daten direkt nach Google Sheets, Excel, Airtable oder Notion exportieren – für interne Analysen.
- Zeitplanung (optional): Scraping-Aufgaben in sinnvollen Abständen planen – nie zu häufig.
- Dokumentieren: Festhalten, was, wann und warum gescrapt wurde.
Thunderbits Oberfläche gibt bei jedem Schritt Hinweise zu Compliance-Fragen – so behältst du jederzeit den Überblick.
Mehr über Thunderbit-Compliance erfahren
Fazit & Empfehlungen: Webdaten sicher und rechtskonform nutzen
Web-Scraping ist ein starkes Werkzeug für Unternehmen – aber kein rechtsfreier Raum. Die Rechtslage ist zwar komplex, die Grundregeln sind jedoch klar:
- Scrape möglichst nur öffentliche, nicht-personenbezogene Daten für interne Zwecke.
- Prüfe immer Nutzungsbedingungen, robots.txt und die geltenden Gesetze, bevor du loslegst.
- Verzichte auf das Scrapen personenbezogener Daten oder kreativer Inhalte, wenn dir Rechtsgrundlage und Datenschutzkonzept fehlen.
- Setze auf compliance-freundliche Tools wie Thunderbit, um Risiken zu minimieren.
- Dokumentiere deinen Prozess und sei bereit, bei Aufforderung zu stoppen.
Wer Compliance zur Routine macht, kann Webdaten nutzen – ohne rechtliche Kopfschmerzen. Und wie einfach rechtssicheres Scraping sein kann, zeigt ein Test mit Thunderbit. Deine Rechtsabteilung (und dein zukünftiges Ich) werden es dir danken.
Mehr zu Web-Scraping, Compliance und Automatisierung findest du im Thunderbit Blog.
AI Web-Scraper für rechtssichere Datenerfassung testen Get Started Free
FAQs
1. Ist das Scrapen von Daten auf jeder Website legal?
Nicht immer. Öffentliche, nicht-personenbezogene Daten für interne Zwecke zu scrapen ist in vielen Ländern erlaubt. Das Scrapen personenbezogener Daten, urheberrechtlich geschützter Inhalte oder von Daten hinter Logins kann dagegen riskant oder sogar illegal sein. Prüfe immer die Nutzungsbedingungen und die lokalen Gesetze, bevor du scrapst (Thunderbit Blog).
2. Was ist der Unterschied zwischen Scraping und Wiederverwendung von Daten?
Scraping meint das Sammeln von Daten; Wiederverwendung heißt, diese Daten zu veröffentlichen, zu verkaufen oder weiterzugeben. Die interne Nutzung ist deutlich sicherer. Das Veröffentlichen oder Verkaufen gescrapter Daten kann Urheberrechte, Datenbankrechte oder Vertragsbedingungen verletzen (Thunderbit Blog).
3. Wie unterstützt Thunderbit bei der Einhaltung von Compliance?
Thunderbit scrapt nur das, was im Browser sichtbar ist, warnt bei riskanten Websites, schlägt relevante (nicht-sensible) Felder vor und steuert die Anfragen so, dass Server nicht überlastet werden. Die Daten werden nicht gespeichert, und die Exportoptionen sind auf die interne Nutzung ausgelegt (Thunderbit Blog).
4. Was tun bei einer Abmahnung?
Sofort das Scraping einstellen und das Projekt überprüfen. Wer nach einer Aufforderung weitermacht, riskiert einen klaren Verstoß gegen Anti-Hacking-Gesetze oder Vertragsbedingungen (Thunderbit Blog).
5. Darf ich personenbezogene Daten scrapen, wenn sie öffentlich sind?
Nicht ohne Rechtsgrundlage. Datenschutzgesetze wie DSGVO und CCPA gelten auch für öffentlich zugängliche personenbezogene Daten. Du brauchst eine Einwilligung oder ein berechtigtes Interesse und musst die Daten verantwortungsvoll behandeln (Thunderbit Blog).
Dieser Leitfaden dient nur zu Informationszwecken und ersetzt keine Rechtsberatung. Bei komplexen oder risikoreichen Projekten solltest du dich an eine qualifizierte Rechtsberatung mit Erfahrung im Datenschutzrecht deines Landes wenden.




