

Neulich kam ein Kollege aus unserem Vertrieb mit einer Frage zu mir, die ich ständig höre: „Dürfen wir Leads aus diesem öffentlichen Unternehmensverzeichnis scrapen, oder werden wir verklagt?“ Er hatte im offenen Web eine echte Fundgrube an Interessentendaten gefunden – kein Login, keine Paywall –, aber eine kurze Google-Suche hatte ihn überzeugt, er könnte am Ende in Handschellen landen.
Diese Verunsicherung ist weit verbreitet. Automatisierter Traffic macht inzwischen schätzungsweise 51 % des gesamten Web-Traffics aus, und der Markt für Web-Scraping-Software soll von rund 1,08 Milliarden US-Dollar im Jahr 2025 auf 3,59 Milliarden US-Dollar bis 2031 wachsen – und trotzdem ist der Großteil der online kursierenden Rechtsratgeber entweder veraltet, zu stark vereinfacht oder schlicht falsch. Der Fall hiQ gegen LinkedIn aus dem Jahr 2022? Fast jeder Artikel behandelt ihn so, als wäre er ein Supreme-Court-Urteil, das „jedes Scraping sei legal“. (Spoiler: Ist es nicht, und war es auch nie.)
Gleichzeitig schreiben große neue Fälle aus den Jahren 2024 und 2025 – mit X (ehemals Twitter), Meta, Reddit, Google und KI-Unternehmen – die Regeln gerade aktiv um, und fast niemand berichtet darüber. Dieser Leitfaden erklärt, was das US-Recht 2026 tatsächlich über Web-Scraping sagt, trennt Mythen von Realität und gibt Ihnen einen praxistauglichen Rahmen an die Hand, um einzuschätzen, was Sie dürfen und was nicht.

Was ist Web-Scraping (und warum ist es für Unternehmen wichtig)?
Web-Scraping bedeutet, mit automatisierter Software Informationen von Websites zu sammeln und in strukturierte Daten zu überführen – also etwa in Tabellen, Datenbanken oder CRM-Datensätze.
Genauer gesagt besucht ein Scraper Webseiten, liest das zugrunde liegende HTML und zieht gezielt bestimmte Datenpunkte heraus – Preise, Namen, Adressen, Produktspezifikationen, was auch immer Sie brauchen – und ordnet sie sauber in Zeilen und Spalten. Das ist das digitale Äquivalent dazu, jemanden zu beauftragen, Informationen von einer Website in Excel zu übertragen, nur dass ein Bot das in Sekunden statt in Stunden erledigt.
Web-Scraping ist KEIN Hacking. Es greift auf dieselben Informationen zu, die jeder Besucher im Browser sehen könnte.
Und es ist auch kein Nischen-Trick für Entwickler. Suchmaschinen, Preisvergleichsportale, Immobilienplattformen, Dashboards für Marktforschung und KI-gestützte Tools verlassen sich alle auf Web Crawling und Scraping, um zu funktionieren. Wenn Sie jemals Google genutzt, einen Flugaggregator geprüft oder Zillow durchsucht haben, haben Sie bereits von Scraping profitiert.
Die geschäftlichen Anwendungsfälle, die mir am häufigsten begegnen:
- Lead-Generierung: Firmennamen, Websites, Jobtitel oder öffentliche Kontaktdaten aus Unternehmensverzeichnissen extrahieren.
- Preisüberwachung bei Wettbewerbern: E-Commerce-Teams verfolgen Preise, Verfügbarkeit und Versandinformationen rivalisierender SKUs.
- Immobilien-Intelligence: Öffentliche Immobilienangebote, Preise und Markttrends bündeln.
- Produktrecherche: Produktspezifikationen, Bewertungen, Verfügbarkeit und Kategoriedaten von Handelsseiten ziehen.
- Markt-Intelligence: Stellenausschreibungen, Filialeröffnungen, Nachrichtensignale oder öffentliche Finanzdaten verfolgen.
Die Technik selbst ist neutral. Die rechtliche Bewertung hängt davon ab, wie Sie auf die Daten zugreifen und was Sie danach damit tun.
Ist Web-Scraping in den USA legal? Die kurze Antwort
Es gibt kein US-Bundesgesetz, das Web-Scraping pauschal verbietet. Das Scrapen öffentlich zugänglicher Daten ist grundsätzlich erlaubt.
Aber – und das ist ein großes Aber – die Legalität hängt von mehreren Faktoren ab: der Art der Daten, der Zugriffsweise, davon, ob Sie Nutzungsbedingungen zugestimmt haben, ob die Daten personenbezogene Informationen enthalten und was Sie damit vorhaben.
Die größte Ursache für Verwirrung in Foren, Reddit-Threads und sogar Legal-Blogs? Viele setzen „illegal“ mit „gegen die Nutzungsbedingungen einer Website verstoßen“ gleich. Das sind sehr unterschiedliche Dinge. Gegen die Regeln einer Website zu verstoßen, kann dazu führen, dass Ihre IP blockiert oder Ihr Konto gesperrt wird. Ein Verstoß gegen ein Bundesgesetz kann eine Klage oder in seltenen Fällen sogar eine strafrechtliche Verfolgung nach sich ziehen. Die meisten Konsequenzen beim Scraping liegen eindeutig im Zivilrecht.
Der Rest dieses Artikels beleuchtet die wichtigsten Gesetze, die wegweisenden Gerichtsentscheidungen (einschließlich solcher aus 2024 und 2025, über die fast niemand berichtet) und ein praxisnahes Entscheidungsmodell, das Sie tatsächlich verwenden können.
Die drei Arten von „illegal“: strafrechtlich, zivilrechtlich und ToS-Verstöße
Zeit, mit dem größten Missverständnis zum Web-Scraping-Recht aufzuräumen. Wenn jemand fragt: „Ist Web-Scraping illegal?“, werden meist drei völlig unterschiedliche Risikokategorien in einen Topf geworfen. Sie zu trennen, verändert die ganze Diskussion.

| Art der Haftung | Was sie auslöst | Mögliche Folge | Schweregrad |
|---|---|---|---|
| Strafrechtlich (CFAA) | Zugriff auf Daten hinter Authentifizierungsbarrieren ohne Erlaubnis, Betrug, Missbrauch von Zugangsdaten | Bundesstrafverfolgung, Geldstrafen, Freiheitsstrafe | 🔴 Schwerwiegend — aber bei normalem Business-Scraping äußerst selten |
| Zivilklage | Urheberrechtsverletzung, Eingriff in bewegliche Sachen, Vertragsbruch, Missbrauch von Geschäftsgeheimnissen, Datenschutzverstöße | Schadensersatz, Unterlassungsverfügung, Löschung von Daten | 🟡 Bedeutend |
| ToS-Verstoß | Verstoß gegen Browsewrap- oder Clickwrap-Nutzungsbedingungen | Kontosperrung, IP-Blocking, Abmahnung, mögliche Zivilklage | 🟢 Gering bis mittel |
Die Strafverfolgungspolitik des US-Justizministeriums zur CFAA von 2022 stellt ausdrücklich klar, dass gewöhnliche Verstöße gegen Nutzungsbedingungen – etwa das Erstellen eines Fake-Kontos oder das Verstoßen gegen Website-Regeln – allein nicht ausreichen, um eine bundesstrafrechtliche Anklage zu tragen. Das ist ein großer Unterschied.
Die praktische Quintessenz: Wenn Ihr Vertriebsteam öffentliche Unternehmenslisten scrapt oder Ihr E-Commerce-Team die Preise von Wettbewerbern überwacht, bewegen Sie sich mit sehr hoher Wahrscheinlichkeit im Bereich des zivilrechtlichen Risikomanagements und nicht im strafrechtlichen Risiko. Das heißt nicht, dass Sie die Regeln ignorieren dürfen – aber es sollte Ihr Angstlevel einordnen.
Die wichtigsten US-Gesetze, die auf Web-Scraping Anwendung finden
In den USA überschneiden sich vier rechtliche Säulen mit Web-Scraping, und jede davon betrifft einen anderen Teil des Puzzles.
Der Computer Fraud and Abuse Act (CFAA)
Der CFAA (18 U.S.C. § 1030) wurde ursprünglich zur Verfolgung von Computer-Hacking formuliert. Im Laufe der Jahre wurde er zum Standardgesetz für Scraping-Klagen, meist mit der Begründung, ein Scraper habe auf eine Website „ohne Erlaubnis“ zugegriffen.
Dann kam Van Buren gegen die Vereinigten Staaten. Der Supreme Court entschied, dass eine Person den Zugriff im Sinne des CFAA nur dann „überschreitet“, wenn sie Bereiche eines Computers – Dateien, Ordner, Datenbanken – aufruft, die ihr nicht zugänglich sind. Das bloße missbräuchliche Verwenden von Informationen, die man ansonsten sehen darf, zählt nicht.
Auswirkungen fürs Scraping:
- Geringeres CFAA-Risiko: Öffentliche Webseiten, die jedem ohne Login zugänglich sind. Kein Gate, kein Problem mit „unbefugtem Zugriff“.
- Höheres CFAA-Risiko: Daten hinter Logins, Paywalls, Zugriffstokens, Session-Manipulation oder widerrufenem Zugang.
Der Fall hiQ gegen LinkedIn (den wir unten detailliert analysieren) hat dies für öffentliche Daten noch einmal bestätigt. Aber die CFAA ist nur ein Teil des Puzzles.
Urheberrecht und der DMCA
Das US-Urheberrecht schützt originäre kreative Ausdrucksformen – Artikel, Fotos, Videos, kreative Produktbeschreibungen – aber keine bloßen Fakten. Der Feist-Fall des Supreme Court ist hier wegweisend: Fakten wie Namen, Adressen und Telefonnummern sind nicht urheberrechtlich schützbar, ganz egal, wie viel Aufwand in ihre Zusammenstellung geflossen ist.
Risikostufen für gescrapte Daten:
| Was Sie scrapen | Urheberrechtsrisiko | Warum |
|---|---|---|
| Preise, Produktnamen, Adressen, Daten, Spezifikationen | Geringer | Das sind Fakten |
| Vollständige Artikel, Fotos, Videos, kreative Rezensionen | Höher | Das sind Ausdrucksformen |
| Kuratierte Datenbanken, Rankings, redaktionelle Taxonomien | Mittel bis hoch | Auswahl und Anordnung können geschützt sein |
| Paywall- oder DRM-geschützte Inhalte | Hoch | Urheberrecht plus Zugriffsschutz-Probleme |
Die Anti-Umgehungsregel des DMCA (17 U.S.C. § 1201) fügt eine weitere Ebene hinzu: Das Umgehen technischer Schutzmaßnahmen (Paywalls, DRM, bestimmte Anti-Bot-Systeme), um auf urheberrechtlich geschützte Inhalte zuzugreifen, kann Haftung auslösen, selbst wenn Sie den Inhalt nie selbst kopieren. Das wird in den Verfahren 2025–2026 aggressiv getestet, darunter Google gegen SerpApi, wo Google DMCA-Verstöße wegen der Umgehung seines SearchGuard-Anti-Bot-Systems geltend macht.
Auch Fair Use spielt eine Rolle – transformative Nutzung (Daten analysieren, aggregieren oder darauf aufbauen, statt sie nur erneut zu veröffentlichen) ist im Allgemeinen sicherer als das Kopieren und erneute Veröffentlichen fremder Inhalte.
Vertragsrecht: Nutzungsbedingungen (Browsewrap vs. Clickwrap)
Viele Websites enthalten in ihren Nutzungsbedingungen Anti-Scraping-Klauseln – aber die Durchsetzbarkeit hängt vollständig davon ab, wie Sie auf diese Bedingungen gestoßen sind.
| Vertragsart | Durchsetzbarkeit | Was das für Scraper bedeutet |
|---|---|---|
| Clickwrap (Sie klicken auf „Ich stimme zu“) | Stark | Gerichte setzen diese regelmäßig durch. Anti-Scraping-Klauseln können zivilrechtliche Ansprüche stützen. |
| Sign-in-Wrap (Hinweis in der Nähe des Logins) | Vom Einzelfall abhängig | Hängt davon ab, wie auffällig der Hinweis war. |
| Browsewrap (über den Footer verlinkt) | Schwächer | Gerichte sind skeptisch, wenn Nutzer keinen echten Hinweis hatten. |
| Konto-/API-Bedingungen | Stärker | Scraping im eingeloggten Zustand oder API-Missbrauch ist deutlich riskanter. |
In Meta gegen Bright Data (2024) stellte das Gericht fest, dass Metas Bedingungen das öffentliche Scraping im ausgeloggten Zustand nicht so abdeckten, wie Meta es behauptet hatte – Bright Data sei nicht nachweislich mit eingeloggten Konten für das streitige öffentliche Scraping vorgegangen. Das ist ein bedeutsamer Unterschied.
Praktischer Rat: Wenn Sie sich nie eingeloggt, nie auf „Ich stimme zu“ geklickt haben und nur öffentliche Seiten scrapen, sind Browsewrap-Einschränkungen für eine Website schwerer gegen Sie durchsetzbar. Prüfen Sie die ToS aber trotzdem immer vor dem Scraping, insbesondere wenn Sie ein Konto erstellt haben.
US-Bundesstaatliche Datenschutzgesetze (CCPA und darüber hinaus)
Wenn die von Ihnen gescrapten Daten personenbezogene Informationen enthalten – Namen, E-Mails, Telefonnummern, Standortdaten – können staatliche Datenschutzgesetze greifen. Und der Flickenteppich wächst rasant. Die IAPP zählte bis Mitte 2025 19 verabschiedete umfassende Datenschutzgesetze auf Bundesstaatsebene, und MultiState berichtete über 20 Bundesstaaten mit 2026 in Kraft befindlichen umfassenden Datenschutzgesetzen.
Die meisten dieser Gesetze enthalten Ausnahmen für „öffentlich verfügbare“ personenbezogene Informationen, aber die Definitionen unterscheiden sich. Und die weitere Verwendung – Verkaufen, Teilen oder Profiling mit diesen Daten – kann dennoch Pflichten auslösen, selbst wenn die ursprüngliche Erhebung ausgenommen war.
| Landesgesetz | Inkrafttreten | Erfasst gescrapte personenbezogene Daten? | Opt-out-Anforderung | Strafrahmen |
|---|---|---|---|---|
| CCPA/CPRA (Kalifornien) | 2020/2023 | Ja | Opt-out für Verkauf/Weitergabe; GPC anerkannt | $2.663–$7.988/Verstoß (2025 angepasst) |
| CPA (Colorado) | 2023 | Ja | Universelles Opt-out/GPC ab Juli 2024 | Zivilstrafen nach dem Deceptive-Trade-Practices-Rahmen |
| CTDPA (Connecticut) | 2023 | Ja | OOPS/GPC ab Jan. 2025 | Bis zu $5.000 bei vorsätzlichem Verstoß |
| VCDPA (Virginia) | 2023 | Ja | Opt-out-Recht | Bis zu $7.500 pro Verstoß |
| TDPSA (Texas) | 2024 | Ja | Universelles Opt-out ab Jan. 2025 | Bis zu $7.500 pro Verstoß |
| + 8 weitere bis 2026 verabschiedet | Variiert | Variiert | Variiert | Variiert |
Weitere Bundesstaaten mit verabschiedeten Gesetzen sind Utah, Oregon, Montana, Delaware, Iowa, Nebraska, New Hampshire, New Jersey, Tennessee, Minnesota, Maryland, Indiana, Kentucky und Rhode Island. Alabama hat ein Gesetz verabschiedet, das am 1. Mai 2027 in Kraft tritt.
Für Business-Anwender, die Produktpreise, Unternehmensverzeichnisse oder Marktdaten scrapen – also nicht-personenbezogene, faktische Informationen – ist das Datenschutzrisiko deutlich geringer. Tools wie Thunderbit konzentrieren sich auf strukturierte Extraktion aus öffentlichen Seiten (Produktdaten, Branchenverzeichnisse, Immobilienangebote), was genau zur risikoärmsten Scraping-Kategorie passt.
Wegweisende Web-Scraping-Fälle: Eine Zeitleiste von 2000 bis 2026
Hier liegt aus meiner Sicht die Schwäche der meisten Leitfäden zu diesem Thema. Fast jeder Artikel bleibt bei hiQ gegen LinkedIn (2022) stehen und ignoriert die Urteile, die das Scraping-Recht gerade tatsächlich prägen. Hier ist die vollständige Zeitleiste:
| Fall | Jahr | Kernaussage | Bedeutung für Scraper |
|---|---|---|---|
| eBay gegen Bidder's Edge | 2000 | Vorläufige Verfügung wegen Eingriffs in bewegliche Sachen; die Belastung der Server durch den Crawler war relevant | ⚠️ Scraping mit hohem Volumen, das Server belastet, kann zivilrechtliche Haftung auslösen |
| Facebook gegen Power Ventures | 2016 | CFAA-Haftung nach Unterlassungsaufforderung und fortgesetztem Zugriff unter Nutzung von Facebook-Systemen | ⚠️ C&D plus authentifizierter/gated Zugriff ist sehr riskant |
| Van Buren gegen die USA | 2021 | „Überschreitet autorisierten Zugriff“ im CFAA setzt voraus, dass gesperrte Computerbereiche aufgerufen werden | ✅ Hat den CFAA-Anwendungsbereich deutlich eingeengt |
| hiQ gegen LinkedIn | 2022 | Zugriff auf öffentliche Daten verstößt nicht gegen die CFAA (vorläufige Verfügung, später beigelegt) | ✅ Öffentliche Daten ≠ „unbefugter Zugriff“ – aber kein Endurteil |
| Meta gegen Bright Data | 2024 | Bright Data gewann im verkürzten Verfahren gegen Metas Vertragsargument beim öffentlichen Scraping im ausgeloggten Zustand | ✅ Nutzungsbedingungen binden ausgeloggtes Scraping unter Umständen nicht ohne Zustimmung |
| X Corp. gegen Bright Data | 2024 | Im Mai wurden viele Ansprüche abgewiesen; ein November-Beschluss wies Ansprüche auf Basis von Scraping/Verkauf zurück | ✅ Ansprüche wegen Kopierens öffentlicher Daten wurden geschwächt |
| Compulife gegen Newman/Rutstein | 2024–2025 | Haftung wegen Geschäftsgeheimnissen bei massenhafter Extraktion von Versicherungsangeboten; Cert denied im Feb. 2025 | ⚠️ Öffentlich sichtbare Daten können dennoch eine geschützte Datenbank sein |
| Reddit gegen Perplexity/SerpApi/Oxylabs/AWMProxy | 2025–2026 | Behauptet ein Scraping in industriellem Maßstab über Google-Ergebnisse hinweg | ⚠️ Fälle aus der KI-Ära zielen auf Datenlieferketten |
| Google gegen SerpApi | 2025–2026 | DMCA-§1201-Ansprüche wegen angeblicher Umgehung von Anti-Bot-Systemen | ⚠️ Testet, ob Anti-Bot-Systeme als DMCA-Zugangskontrollen gelten |
Die Tendenz ist klar: Gerichte schützen den Zugriff auf öffentliche Daten unter der CFAA zunehmend, aber Urheberrecht, Vertragsrecht, Datenschutz, Geschäftsgeheimnisse und Infrastrukturansprüche bleiben vollständig eigenständige Risiken. Und die KI-Trainingswelle schafft völlig neue Rechtsfragen.
Die Sache richtigstellen: Was hiQ gegen LinkedIn tatsächlich entschieden hat
Das ist der am meisten missverstandene Fall im gesamten Web-Scraping-Recht. Ich habe ihn in Blogbeiträgen, Reddit-Threads und sogar juristischen Zusammenfassungen als Beweis dafür gesehen, dass „öffentliches Web-Scraping legal“ sei. So einfach ist es nicht.
Was tatsächlich passiert ist:
Was hiQ entschieden hat: Der Ninth Circuit bestätigte eine vorläufige Verfügung – also eine temporäre Anordnung –, die LinkedIn daran hinderte, das Scraping öffentlicher LinkedIn-Profile durch hiQ zu blockieren. Das Gericht sagte, der Zugriff auf öffentlich verfügbare Daten habe wahrscheinlich nicht gegen die CFAA verstoßen. Schlüsselwort: wahrscheinlich. Quelle: hiQ Labs gegen LinkedIn, Ninth Circuit.
Was hiQ NICHT festgestellt hat:
- Ein pauschales Recht, jede öffentliche Website zu scrapen
- Ein Endurteil in der Sache – der Supreme Court hob auf und verwies nach Van Buren zurück, der Ninth Circuit bestätigte erneut, und dann wurde der Fall Ende 2022 beigelegt, ohne endgültige Gerichtsentscheidung
- Die berichtete Einigung umfasste 500.000 US-Dollar, eine Unterlassungsverfügung und Verpflichtungen zur Vernichtung von Daten/Software
Warum das für Sie wichtig ist: hiQ ist ermutigend für Scraper öffentlicher Daten. Es signalisiert, dass Gerichte skeptisch gegenüber Plattformen sind, die sich private Monopole über Informationen schaffen, die ihnen nicht gehören. Aber es ist keine rechtliche Garantie. Andere Ansprüche – Urheberrecht, Vertragsrecht, Datenschutz, Geschäftsgeheimnisse – wurden nie entschieden. Nach Van Buren ist die CFAA-Lage klarer, aber sich ausschließlich auf hiQ als rechtlichen Schutzschild zu verlassen, wäre ein Fehler.
Das richtig einzuordnen, unterscheidet fundiertes Risikomanagement von Wunschdenken.
Darf ich das legal scrapen? Ein praktischer Entscheidungsbaum
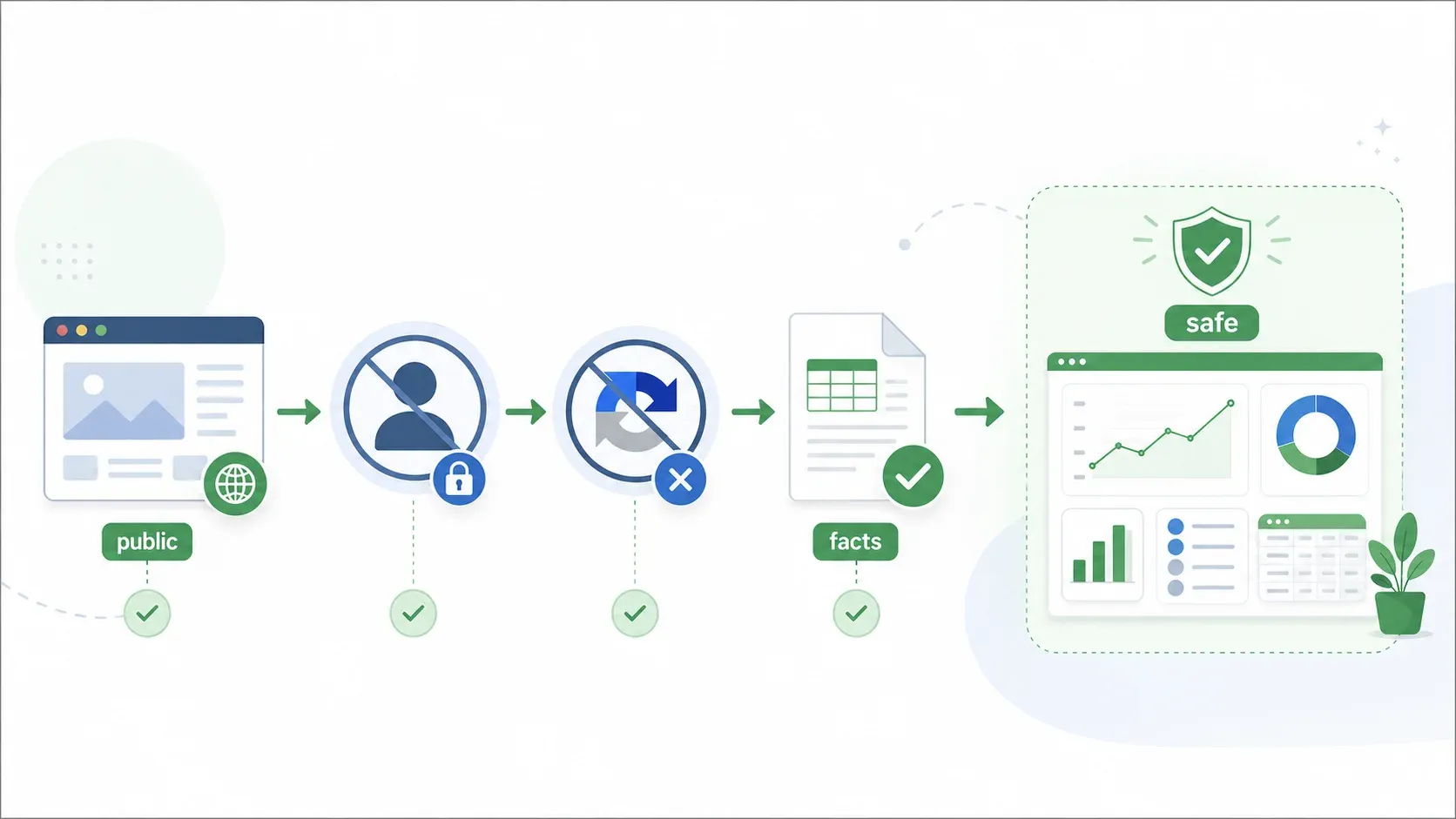
Die Legalität von Scraping fühlt sich wie eine „Grauzone“ an – das höre ich ständig. Statt noch mehr Rechtstheorie hier also ein Entscheidungsrahmen, den Sie wirklich nutzen können. Fünf Fragen für jedes Scraping-Projekt:
1. Sind die Daten öffentlich zugänglich (kein Login erforderlich)?
- Wenn NEIN → Höheres CFAA-Risiko. Holen Sie vor dem Fortfahren eine Erlaubnis ein oder lassen Sie das rechtlich prüfen.
- Wenn JA → Weiter zu Frage 2.
2. Umgehen Sie technische Barrieren (CAPTCHA, IP-Sperren, Rate Limits, Paywalls)?
- Wenn JA → Mögliche DMCA- und CFAA-Probleme. Stoppen oder an die Rechtsabteilung eskalieren.
- Wenn NEIN → Weiter zu Frage 3.
3. Haben Sie einer Clickwrap-ToS zugestimmt, die Scraping verbietet?
- Wenn JA → Zivilrechtliches Vertragsrisiko. Prüfen Sie, ob die Daten aus einer anderen Quelle verfügbar sind, oder holen Sie eine Erlaubnis ein.
- Wenn NEIN → Weiter zu Frage 4.
4. Enthalten die Daten personenbezogene Informationen (PII)?
- Wenn JA → Prüfen Sie CCPA und die anwendbaren Datenschutzgesetze der Bundesstaaten. Stellen Sie sicher, dass Ihr Verwendungszweck rechtskonform ist und Sie Opt-out-Rechte respektieren.
- Wenn NEIN → Weiter zu Frage 5.
5. Was werden Sie mit den Daten tun?
- Kommerzielle Neuveröffentlichung urheberrechtlich geschützter Inhalte (vollständige Artikel, Fotos, Videos) → Urheberrechtsrisiko.
- Transformative Analyse, interne Recherche oder faktische Datennutzung (Preise, Spezifikationen, Angebote) → In der Regel geringeres Risiko.
Wenn Sie im Bereich „öffentliche Seiten, keine Umgehung, kein Clickwrap, keine personenbezogenen Daten, faktische Daten für interne Analyse“ landen, bewegen Sie sich in der risikoärmsten Kategorie. Genau für diesen Workflow wurde Thunderbit entwickelt – strukturierte, faktische Daten von öffentlichen Webseiten wie Produktangeboten, Unternehmensverzeichnissen und Immobiliendaten zu extrahieren und anschließend für Ihre eigene Analyse nach Excel, Google Sheets, Airtable oder Notion zu exportieren.
Speichern Sie sich diesen Entscheidungsbaum. Er ersetzt keinen Anwalt, erspart Ihnen aber viel unnötige Panik.
KI-Training und Web-Scraping: Die neue rechtliche Front

KI hat dem Scraping-Recht eine völlig neue Komplexitätsebene hinzugefügt. Daten zu scrapen, um Large Language Models, Bildgeneratoren und andere KI-Systeme zu trainieren, ist inzwischen ein zentrales juristisches Schlachtfeld – und die Gerichte haben die Kernfragen noch nicht geklärt.
Der aktuelle Stand:
| Fall | Status (2026) | Kernfrage |
|---|---|---|
| NYT gegen OpenAI/Microsoft | Laufend. Zentrale Urheberrechtsansprüche durften im April 2025 fortgeführt werden; Beweisstreitigkeiten umfassen mehr als 20 Mio. ChatGPT-Logs. | Ist das Training mit gescrapten Nachrichtenartikeln Fair Use oder Urheberrechtsverletzung? |
| Bartz gegen Anthropic | Richter Alsup entschied, dass bestimmte Trainingsnutzungen Fair Use seien, aber der Erwerb aus Raubkopien nicht. Berichteter Vergleich: rund 1,5 Mrd. US-Dollar. | Training kann transformativ sein, aber das Kopieren raubkopierter Quellen ist ein separates Problem. |
| Thomson Reuters gegen Ross | Ein Gericht in Delaware verwarf Fair Use für die Verwendung von Westlaw-Headnotes zum Aufbau eines konkurrierenden juristischen Rechercheprodukts. | Direkt ersetzende Produkte haben ein höheres Urheberrechtsrisiko. |
| Getty gegen Stability AI | Der britische Fall fiel 2025 weitgehend zugunsten von Stability aus; US-Verfahren noch anhängig. | Das Recht zum Training von Bildern ist weiterhin ungeklärt. |
Der AI-Bericht des US Copyright Office von 2025 bringt nützliche Nuancen ein: Das Training auf großen, vielfältigen Datensätzen kann oft transformativ sein, aber das Kopieren aus Raubquellen und Nutzungen, die direkt mit den Märkten der Rechteinhaber konkurrieren, sind deutlich schwächere Fair-Use-Argumente.
Für die meisten Business-Nutzer, die diesen Artikel lesen, ist der Unterschied klar: Daten für die eigene Analyse oder den Geschäftsbetrieb zu scrapen (Lead-Gen, Preisüberwachung, Marktforschung) ist rechtlich ein ganz anderes Risiko als Daten zum Training und zur Kommerzialisierung eines KI-Modells zu scrapen. Ersteres birgt ein geringeres Urheberrechtsrisiko. Letzteres ist der Bereich, in dem die großen Klagen laufen.
Wie man Daten verantwortungsvoll scrapt (Best Practices für Business-Teams)
Genug Rechtstheorie. So scrapen Sie Daten tatsächlich, ohne Ihrem Team juristische Kopfschmerzen zu bereiten.
Bei öffentlich verfügbaren Daten bleiben
Konzentrieren Sie sich auf Daten, die jeder ohne Login sehen kann – Produktlisten, Unternehmensverzeichnisse, öffentliche Register, Preis-Seiten. Sobald Sie hinter einem Login sind, bewegen Sie sich in einem risikoreicheren Bereich.
Technische Barrieren nicht umgehen
Wenn eine Website CAPTCHAs, IP-Sperren, Rate Limits oder Paywalls einsetzt, sind das Signale. Deren Umgehung kann DMCA-, CFAA- oder Vertragsansprüche auslösen. Wenn die Daten wichtig genug sind, suchen Sie stattdessen nach einer offiziellen API oder einer Datenpartnerschaft.
Die Nutzungsbedingungen prüfen
Vor allem, wenn Sie ein Konto erstellt oder auf „Ich stimme zu“ geklickt haben. Lesen Sie die ToS auf Anti-Scraping-Klauseln. Wenn die Bedingungen Scraping verbieten und Sie ihnen zugestimmt haben, prüfen Sie, ob die Daten aus einer anderen Quelle verfügbar sind.
Sammlung personenbezogener Daten minimieren
Wenn Sie PII erfassen (Namen, E-Mails, Telefonnummern), stellen Sie sicher, dass Ihr Einsatz unter den geltenden Datenschutzgesetzen der Bundesstaaten zulässig ist. Faktische Geschäftsdaten – Firmennamen, Produktpreise, Angebotsdetails – zu scrapen ist deutlich weniger riskant als das Scrapen von Verbraucherprofilen.
Robots.txt und Rate Limits respektieren
Robots.txt (RFC 9309) ist für sich genommen nicht rechtlich bindend, aber sein Respekt zeigt guten Willen. Und überlasten Sie die Server einer Website nicht – drosseln Sie Ihre Requests, verwenden Sie vernünftige Intervalle und verursachen Sie keinen Infrastrukturschaden.
Daten für Analyse nutzen, nicht für Neuveröffentlichung
Transformative Nutzung – Analyse, Aggregation, interne Recherche, Competitive Intelligence – ist weit sicherer als das Kopieren und erneute Veröffentlichen fremder Artikel, Bilder oder Rezensionen. Wenn Sie Dashboards oder Tabellen für Ihr Team erstellen, sind Sie in einer besseren Position, als wenn Sie gescrapte Inhalte auf Ihrer eigenen Website neu veröffentlichen.
Tools wählen, die für rechtskonformes Scraping gemacht sind
An dieser Stelle erwähne ich, was wir bei Thunderbit gebaut haben. Unsere KI-Web-Scraper-Chrome-Erweiterung ist für Business-Nutzer gedacht, die strukturierte Daten von öffentlichen Webseiten extrahieren möchten – Produktlisten, Unternehmensverzeichnisse, Immobiliendaten, Lead-Informationen – ohne Code schreiben oder technische Barrieren umgehen zu müssen. Die KI liest die Seite, schlägt Felder vor und ermöglicht den Export nach Excel, Google Sheets, Airtable oder Notion. Sie ist für den risikoärmsten Zweig des obigen Entscheidungsbaums gebaut: öffentliche Seiten, faktische Daten, kein Login-Bypass.
Trotzdem macht kein Tool Sie immun gegen rechtliche Risiken. Die Verantwortung dafür, was Sie scrapen und wie Sie es verwenden, liegt immer bei Ihnen.
Protokolle führen und bei Abmahnungen stoppen
Dokumentieren Sie Ihre Scraping-Aktivitäten und den geschäftlichen Zweck. Wenn Sie eine Abmahnung oder Unterlassungsaufforderung erhalten, stoppen Sie und konsultieren Sie eine Rechtsberatung. Nach einer formellen Aufforderung weiter zu scrapen erhöht Ihr Risikoprofil deutlich, insbesondere wenn gated Systeme beteiligt sind.
Zentrale Erkenntnisse zur Legalität von Web-Scraping in den USA
Die Kurzfassung:
- Kein US-Bundesgesetz verbietet Web-Scraping pauschal. Das Scrapen öffentlich verfügbarer faktischer Daten ist grundsätzlich erlaubt.
- Die Legalität hängt davon ab, was Sie scrapen, wie Sie darauf zugreifen und was Sie damit tun. Öffentliche Seiten + faktische Daten + interne Analyse = geringstes Risiko.
- Der Anwendungsbereich der CFAA ist nach Van Buren und hiQ enger geworden, aber Urheberrechts-, Vertrags-, Datenschutz- und Geschäftsgeheimnisansprüche bleiben eigenständige Risiken.
- Strafrechtliche Haftung ist bei typischem Business-Scraping selten. Die meisten Risiken sind zivilrechtlich – also Klagen, nicht Handschellen.
- hiQ gegen LinkedIn ist keine pauschale Freikarte. Es war eine vorläufige Verfügung, die später beigelegt wurde. Ermutigend, aber keine Garantie.
- Landesweite Datenschutzgesetze sind relevant, wenn PII im Spiel ist, aber nicht-personenbezogene Daten (Preise, Angebote, Spezifikationen) bergen das geringste Risiko.
- KI-Trainingsanwendungen sind eine neue und noch ungeklärte Rechtsfront. Business-Scraping für die eigene Analyse ist ein anderes Risikoprofil als Scraping zum Aufbau kommerzieller KI-Modelle.
- Best Practices einzuhalten – öffentliche Daten, ToS respektieren, PII vermeiden, Barrieren nicht umgehen, Daten verantwortungsvoll nutzen – hält Ihr Team im sicheren Bereich.
Ein notwendiger Hinweis: Dieser Artikel dient nur der Information und stellt keine Rechtsberatung dar. Wenn Sie eine groß angelegte Scraping-Operation planen oder mit sensiblen Daten arbeiten, wenden Sie sich an einen qualifizierten Anwalt. Aber für den Vertriebsleiter, der nur Leads aus einem öffentlichen Verzeichnis ziehen möchte, oder das E-Commerce-Team, das die Preise von Wettbewerbern überwacht? Das Gesetz ist eher auf Ihrer Seite, als Sie wahrscheinlich denken.
Wenn Sie sehen möchten, wie Thunderbit diese Art der Extraktion öffentlicher Daten einfach macht – kein Code, kein Umgehen von Schutzmaßnahmen, nur strukturierte Daten direkt in Ihren Workflow – schauen Sie sich unseren Schnellstart-Leitfaden an oder holen Sie sich die Chrome-Erweiterung und testen Sie es selbst.
FAQs
1. Ist Web-Scraping 2026 in den USA legal?
Ja, Web-Scraping ist in den USA grundsätzlich legal, wenn Sie öffentlich verfügbare Daten scrapen. Es gibt kein Bundesgesetz, das es verbietet. Allerdings können Ihre Vorgehensweise, die Art der gesammelten Daten und die Nutzung rechtliche Risiken nach der CFAA, dem Urheberrecht, dem Vertragsrecht oder den Datenschutzgesetzen der Bundesstaaten auslösen. Der sicherste Ansatz ist, bei öffentlichen Seiten zu bleiben, technische Barrieren nicht zu umgehen, die Erhebung personenbezogener Daten zu minimieren und die Daten für Analysen statt für eine direkte Neuveröffentlichung zu verwenden.
2. Kann ich wegen Web-Scrapings ins Gefängnis kommen?
Strafrechtliche Verfolgung wegen Web-Scrapings ist extrem selten und würde in der Regel voraussetzen, dass Daten hinter Authentifizierungsbarrieren ohne Erlaubnis abgerufen werden (ein CFAA-Verstoß) oder dass Betrug im Spiel ist. Die CFAA-Anklagepolitik des DOJ aus dem Jahr 2022 stellt klar, dass gewöhnliche Verstöße gegen Nutzungsbedingungen nicht für Strafanzeigen ausreichen. Die meisten Web-Scraping-Streitigkeiten sind zivilrechtlicher Natur – also Klagen, keine Strafsachen.
3. Macht ein Verstoß gegen die Nutzungsbedingungen einer Website Scraping automatisch illegal?
Nicht automatisch. Ein Verstoß gegen die ToS einer Website ist eine Vertragsfrage, kein Straftatbestand. Wenn Sie Clickwrap-Bedingungen zugestimmt haben, die Scraping verbieten, könnte die Website eine zivilrechtliche Vertragsverletzungsklage anstrengen. Browsewrap-Bedingungen (über den Footer verlinkt) sind jedoch deutlich schwerer durchzusetzen, vor allem, wenn Sie sich nie eingeloggt oder nie auf „Ich stimme zu“ geklickt haben. Gerichte waren in mehreren Scraping-Fällen skeptisch gegenüber passiver Browsewrap-Durchsetzung.
4. Ist es in den USA legal, personenbezogene Daten (E-Mails, Telefonnummern) zu scrapen?
Das kommt darauf an. Viele Datenschutzgesetze der US-Bundesstaaten – darunter CCPA, VCDPA, CPA und andere – enthalten Ausnahmen für öffentlich verfügbare personenbezogene Informationen, aber Definitionen und Pflichten für die Weiterverwendung unterscheiden sich. Nicht-personenbezogene Daten zu scrapen (Produktpreise, Unternehmensverzeichnisse, öffentliche Register) ist deutlich weniger riskant als das Scrapen einzelner Verbraucherprofile. Wenn Sie PII in großem Umfang erfassen, prüfen Sie die einschlägigen Landesgesetze und stellen Sie sicher, dass Ihr Zweck zulässig ist.
5. Hat hiQ gegen LinkedIn jedes Web-Scraping legal gemacht?
Nein. Das hiQ-Urteil war eine vorläufige Verfügung – eine temporäre Anordnung auf Basis einer Erfolgsaussicht – und keine endgültige Entscheidung in der Sache. Der Ninth Circuit sagte, der Zugriff auf öffentliche Daten habe wahrscheinlich nicht gegen die CFAA verstoßen, aber der Fall wurde 2022 ohne endgültiges Gerichtsurteil beigelegt. Es erteilt keine pauschale Erlaubnis, jede Website zu scrapen, und behandelt auch nicht Urheberrecht, Vertragsrecht, Datenschutz oder Geschäftsgeheimnisse. Für Scraper öffentlicher Daten ist es ermutigend, aber keine rechtliche Garantie.
Mehr erfahren




