

Neulich erreichte uns über den Support eine Frage, bei der ich mein Kaffeetrinken kurz unterbrach: „Wenn ich öffentliche Produktpreise von Coupang scrape, drohen mir dann in Korea rechtliche Konsequenzen?“ Eine saubere Ein-Satz-Antwort hatte ich nicht parat – und die meisten Rechtsratgeber im Netz, die ich daraufhin durchsah, auch nicht.
Die Frage blieb mir hängen, denn genau sie tippen Woche für Woche Tausende E-Commerce-Betreiber, Vertriebsteams und SaaS-Gründer still bei Google ein. Der weltweite Markt für Web-Scraping-Services lag 2024 bei rund 1,03 Milliarden US-Dollar und wächst schnell. So viele Unternehmen wie nie sammeln Webdaten, und immer mehr fragen sich, wo in Korea die rechtlichen Grenzen verlaufen. Ein pauschales Scraping-Verbot kennt Korea nicht.
Je nachdem, was Sie scrapen, wie Sie es scrapen und warum, können aber vier große Gesetze ins Spiel kommen. Der meistzitierte Grundsatzfall ist das Yanolja-Urteil des koreanischen Obersten Gerichtshofs (2021Do1533, entschieden am 12. Mai 2022): Es sprach das Scraping-Tool eines Konkurrenten strafrechtlich frei, belastete dieselbe Firma anschließend aber in einem separaten Zivilverfahren mit Schadenersatz von rund 1 Milliarde KRW. Genau dieses doppelte Ergebnis ist das Wichtigste, was Nicht-Juristen am koreanischen Scraping-Recht verstehen müssen, und es bildet das Rückgrat dieses Leitfadens. Kein Jurastudium nötig – nur ein praxistaugliches Risikorahmenwerk, das Sie wirklich anwenden können.
Schwierigkeitsgrad: Anfänger (keine rechtlichen oder technischen Vorkenntnisse nötig)
Zeitaufwand: ca. 15 Minuten Lesezeit; als fortlaufende Referenz geeignet
Was Sie brauchen: Ein grundlegendes Verständnis davon, was Web-Scraping macht (falls Sie eine Auffrischung brauchen, lesen Sie unseren Beitrag zu Was ist Web-Scraping)
Ist Web-Scraping in Korea legal? Die kurze Antwort
Web-Scraping selbst ist in Korea nicht illegal. Es ist eine neutrale Technologie, ähnlich wie ein Webbrowser oder eine Tabellenformel. Koreanische Gerichte haben sich konsequent nicht auf das Tool konzentriert, sondern auf das Verhalten rund um seine Nutzung.
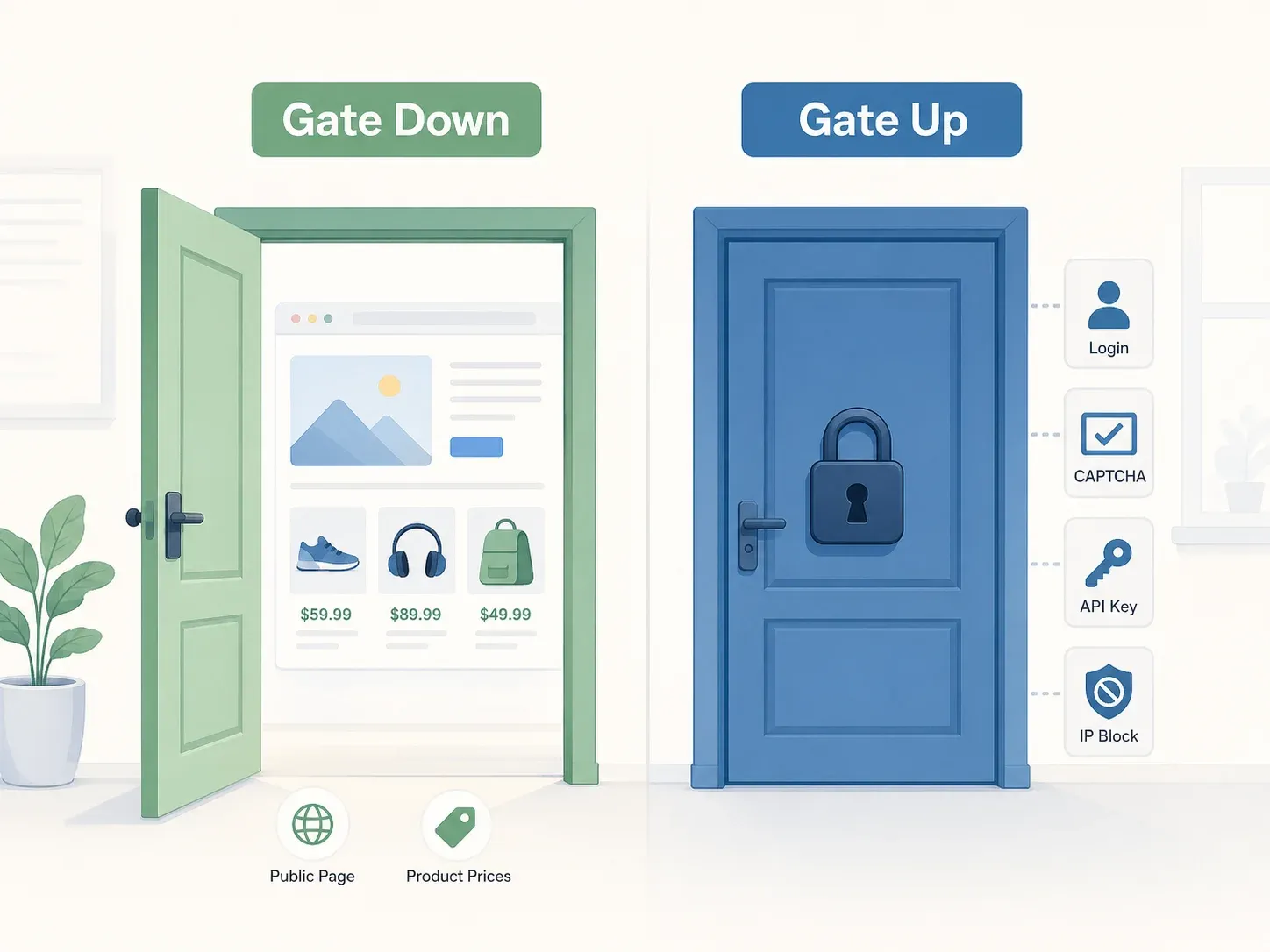
Das beste mentale Modell liefert die Supreme-Court-Entscheidung zu Yanolja: das „Tor oben vs. Tor unten“-Prinzip. Hat eine Website keine objektiven Zugangsbeschränkungen – keine Login-Schranke, kein CAPTCHA, keine API-Key-Pflicht, kein IP-Block – dann ist das Tor „unten“, und der Zugriff auf öffentlich verfügbare Daten ist nach Koreas Information and Communications Network Act (ICNA) in der Regel keine Straftat. Das Gericht prüfte ausdrücklich, ob „Schutzmaßnahmen, Nutzungsbedingungen und andere objektiv erkennbare Umstände“ den Zugang beschränkten, und stellte fest, dass der API-Server von Yanolja über die öffentliche App frei erreichbar war.
Doch „nicht strafbar“ heißt nicht „kein Risiko“.
Die zivilrechtliche Haftung ist eine völlig eigene Frage. Sie können einer Strafverfolgung entgehen und trotzdem mit einem Schadenersatzurteil in Milliardenhöhe konfrontiert werden. Der Yanolja-Fall hat das schmerzhaft deutlich gemacht.
Für Web-Scraping können vier koreanische Gesetze relevant sein:
- ICNA (Information and Communications Network Act) – die Regel gegen „unerlaubtes Betreten“
- Copyright Act – Rechte des Datenbankherstellers
- PIPA (Personal Information Protection Act) – Regeln zur Erhebung personenbezogener Daten
- UCPA (Unfair Competition Prevention Act) – die umfassende Regel gegen unfaire Mitnahmeeffekte
Der Rest dieses Leitfadens ordnet diese Gesetze realen Szenarien zu, damit Sie einschätzen können, wo Ihr Scraping-Projekt tatsächlich steht.
Das Grün-Gelb-Rot-Risikomodell für Web-Scraping in Korea
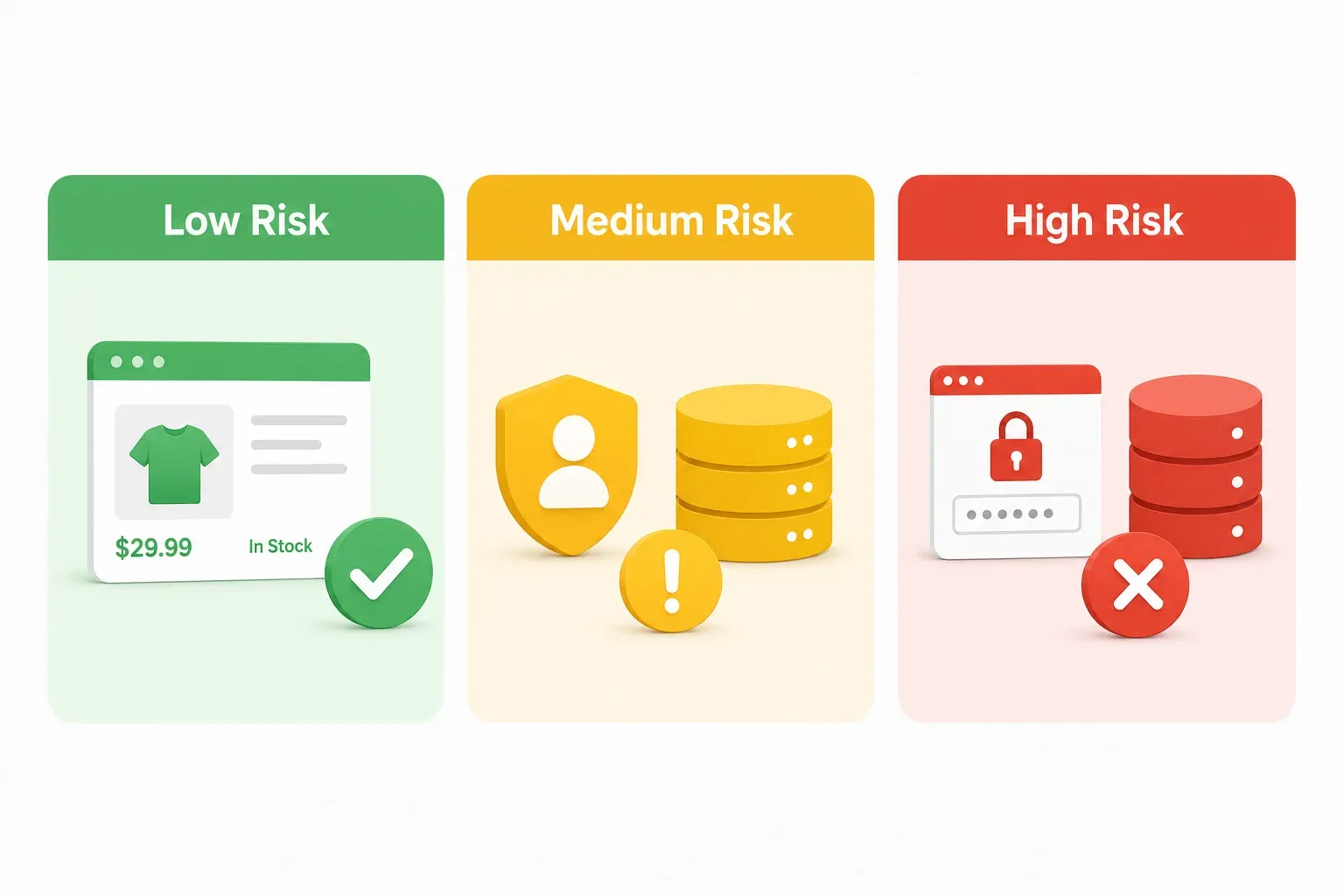
Jeder Rechtsartikel zum koreanischen Scraping-Recht, der mir untergekommen ist, liest sich, als wäre er für Anwälte geschrieben. Wer aber E-Commerce-Operations-Manager oder SaaS-Gründer ist, braucht keine 40-seitige Gesetzesanalyse – sondern einen schnellen Weg, das Risiko einzuschätzen, bevor das Projekt startet. Stellen Sie sich eine Ampel vor. Grün heißt loslegen (mit normaler Vorsicht). Gelb heißt: langsamer machen und den Überblick behalten. Rot heißt: anhalten und einen Anwalt einschalten.
Grüne Zone: Niedrigrisiko-Szenarien beim Scraping
| Szenario | Risikostufe | Wichtige(s) Gesetz(e) | Warum |
|---|---|---|---|
| Öffentliche Produktlisten scrapen (kein Login, kein CAPTCHA) | 🟢 Niedrig | ICNA, Copyright Act | Yanolja-Urteil: keine Zugangsbeschränkung = kein ICNA-Verstoß; faktische Daten (Preise, Verfügbarkeit) sind kein kreativer Ausdruck |
| Öffentliche Preise nur für interne Analysen scrapen | 🟢 Niedrig | UCPA, Copyright Act | Faktische Daten, begrenzter Umfang, keine wettbewerbliche Weiterverbreitung |
| Nicht-personenbezogene, nicht urheberrechtlich geschützte Fakten von öffentlichen Seiten sammeln | 🟢 Niedrig | ICNA, Copyright Act | Keine Zugangssperre umgangen; einzelne Fakten sind nicht geschützt |
Die strafrechtliche Yanolja-Entscheidung ist der Anker dieser Zone. Der Oberste Gerichtshof sah keinen ICNA-Eingriff, weil der API-Server frei erreichbar war. Normale Nutzer konnten über die App mit oder ohne Mitgliedschaft darauf zugreifen, und es gab keine separaten Schutzmaßnahmen, die den API-Zugang blockierten.
Für Thunderbit Nutzer ist das der ideale Bereich. Wenn Sie öffentliche E-Commerce- oder Immobilienseiten im Cloud-Scraping-Modus scrapen – also Produktnamen, Preise, Verfügbarkeit oder Metadaten von Inseraten erfassen und personenbezogene Felder ausschließen – bewegen Sie sich typischerweise in der grünen Zone. (Wobei „typischerweise“ nicht „immer“ bedeutet; die Nuancen erkläre ich weiter unten.)
Thunderbit zum Scrapen öffentlicher Daten testen
Gelbe Zone: Mittleres Risiko beim Scraping
| Szenario | Risikostufe | Wichtige(s) Gesetz(e) | Warum |
|---|---|---|---|
| Personenbezogene Daten scrapen (Namen, E-Mails, Telefonnummern), auch von öffentlichen Seiten | 🟡 Mittel | PIPA, ICNA | PIPA gilt unabhängig von öffentlicher Sichtbarkeit; Änderungen von 2023 verschärften die Einwilligungsregeln |
| Große Datenmengen scrapen, die einen „wesentlichen Teil“ einer Wettbewerber-Datenbank darstellen könnten | 🟡 Mittel | Copyright Act, UCPA | Quantitativer + qualitativer Test nach koreanischem Recht |
| robots.txt-Signale ignorieren | 🟡 Mittel | Indiz für bösen Glauben | Nicht per se strafbar, kann aber vor Gericht gegen Sie verwendet werden |
| Öffentliche Daten scrapen und sie direkt im Wettbewerb mit der Quelle nutzen | 🟡 Mittel | UCPA | Free-Riding auf der Investition einer anderen Plattform |
Personenbezogene Daten sind der größte Auslöser in der gelben Zone.
Selbst wenn eine Telefonnummer oder E-Mail-Adresse auf einer öffentlichen Webseite sichtbar ist, gilt PIPA trotzdem. Die PIPA-Reform von 2023 erweiterte die Rechte der betroffenen Personen und verschärfte die Einwilligungsanforderungen. Und 2024 veröffentlichte die koreanische Datenschutzkommission PIPC eine Leitlinie speziell zu öffentlich zugänglichen personenbezogenen Informationen im Kontext von KI und Datenerhebung – mit der klaren Aussage, dass öffentliche Zugänglichkeit allein keine pauschale Erlaubnis darstellt.
Auch das Volumen spielt eine Rolle. Der Oberste Gerichtshof sagte in Yanolja, dass sowohl quantitative als auch qualitative Faktoren bestimmen, ob ein „wesentlicher Teil“ einer Datenbank kopiert wurde. Vergleichen Sie den kopierten Teil mit der Gesamtdatenbank und fragen Sie, ob er die wesentliche Investition des Herstellers widerspiegelt.
Rote Zone: Hochrisikoszenarien beim Scraping
| Szenario | Risikostufe | Wichtige(s) Gesetz(e) | Warum |
|---|---|---|---|
| Hinter einer Login-Schranke scrapen oder Zugriffskontrollen umgehen | 🔴 Hoch | ICNA Art. 48 | „Tor oben“ = unbefugter Zugriff; hohes Strafverfolgungsrisiko |
| CAPTCHAs, IP-Sperren oder Bot-Erkennungssysteme umgehen | 🔴 Hoch | ICNA Art. 48(4) | Die Änderung von 2024 richtet sich ausdrücklich gegen Umgehungs-Tools/-Geräte |
| Die vollständige Datenbank eines Wettbewerbers kopieren und weiterverkaufen | 🔴 Hoch | Copyright Act (DB-Rechte), UCPA | Wesentliche Vervielfältigung + kommerzielles Free-Riding |
| Personenbezogene Informationen ohne Rechtsgrundlage für Marketing/Outreach sammeln | 🔴 Hoch | PIPA | Bis zu 5 Jahre / 50 Mio. KRW Geldstrafe; Verwaltungssanktionen bis zu 3 % des Umsatzes |
Eine 2024 hinzugefügte Vorschrift im ICNA, Artikel 48(4), verbietet nun ausdrücklich das Installieren, Übertragen oder Verbreiten von Programmen oder technischen Geräten, die „normale Schutz- oder Authentifizierungsverfahren“ ohne legitimen Grund umgehen.
Unabhängig davon hat ein Urteil des Obersten Gerichtshofs vom November 2024 (2021Do5555) bekräftigt, dass eine unbefugte Netzwerkeindringung auch ohne physische Beschädigung von Schutzmaßnahmen vorliegen kann. Es reicht aus, die Zugangsbeschränkungen mit fremden Kennungen oder fehlerhaften Befehlen zu umgehen.
Die vier koreanischen Gesetze, die für Web-Scraping gelten
| Gesetz | Was es schützt | Wann es für Scraper relevant wird |
|---|---|---|
| ICNA Artikel 48 | Netzstabilität, Zugriffsberechtigung | Umgehen von Login, CAPTCHA, Authentifizierung, IP-Blockierungen, API-Key-Limits |
| Copyright Act (Art. 93) | Kreative Werke + Rechte des Datenbankherstellers | Vervielfältigung von Ausdrucksinhalten, Bildern oder aller/wesentlicher Teile einer Datenbank |
| PIPA | Personenbezogene Daten, Rechte der betroffenen Person | Erheben von Namen, Telefonnummern, E-Mails, IDs – auch von öffentlichen Seiten |
| UCPA (Art. 2(1)(k) und (m)) | Fairer Wettbewerb, wirtschaftlich wertvolle Daten | Ausnutzung der Dateninvestition einer anderen Plattform für das eigene konkurrierende Geschäft |
ICNA Artikel 48: Die Regel gegen „unerlaubtes Betreten“
ICNA Artikel 48(1) besagt, dass niemand in ein Informations- und Kommunikationsnetz „ohne legitime Zugriffsberechtigung oder über die erlaubte Zugriffsberechtigung hinaus“ eindringen darf. Auf Scraping übertragen heißt das: Wenn die Website Zugangsbeschränkungen hat, die Sie umgehen, verstoßen Sie gegen das Gesetz. Gibt es keine Beschränkungen (öffentliche Seite, kein Login), sind Sie wahrscheinlich auf der sicheren Seite.
Die Strafe für einen Verstoß liegt nach ICNA Artikel 71 bei bis zu fünf Jahren Freiheitsstrafe oder einer Geldstrafe von bis zu 50 Millionen KRW.
Eine wichtige Nuance: Der koreanische Oberste Gerichtshof behandelt Nutzungsbedingungen konsequent anders als Zugangsbeschränkungen. Die App-Nutzungsbedingungen von Yanolja beschränkten die kommerzielle Weiterverwendung und verboten automatisierte Programme, die den Server belasteten, doch das Gericht stellte fest, dass diese Klauseln den Zugang zum API-Server selbst nicht objektiv einschränkten.
Copyright Act: Rechte des Datenbankherstellers
Das koreanische Urheberrechtsgesetz schützt Datenbankhersteller getrennt vom Urheberrecht an einzelnen Inhalten. Nach Artikel 93 ist es unzulässig, „alle oder einen wesentlichen Teil“ einer Datenbank zu vervielfältigen – selbst wenn einzelne Datenpunkte öffentliche Tatsachen sind.
Der Maßstab ist sowohl quantitativ (wie viel haben Sie im Verhältnis zum Ganzen kopiert?) als auch qualitativ (spiegelt der kopierte Teil die wesentliche Investition des Herstellers in Aufbau, Prüfung oder Pflege der Datenbank wider?). Wiederholtes oder systematisches Kopieren kleinerer Teile kann ebenfalls genügen, wenn es faktisch dasselbe Ergebnis erzielt wie die Kopie eines wesentlichen Teils.
Die Strafe für eine Verletzung der Datenbankherstellerrechte beträgt nach Artikel 136(2)(3) bis zu drei Jahre oder 30 Millionen KRW. Gesetzlicher Schadenersatz nach Artikel 125-2 erlaubt bis zu 10 Millionen KRW pro Werk bzw. 50 Millionen KRW pro Werk bei vorsätzlicher gewinnorientierter Verletzung.
PIPA: Personal Information Protection Act
PIPA regelt die Erhebung personenbezogener Daten – Namen, Kontaktdaten, IDs – auch dann, wenn sie öffentlich sichtbar sind. Die Reform von 2023 war bedeutend: Sie erweiterte die Rechte der betroffenen Personen, verschärfte die Einwilligungsanforderungen, führte Regeln für automatisierte Entscheidungen ein und setzte Verwaltungssanktionen von bis zu 3 % des Gesamtumsatzes für bestimmte Verstöße fest.
Die öffentliche-Daten-KI-Leitlinie 2024 der PIPC nennt Daten, die durch „Web Crawling und Scraping“ gewonnen wurden, ausdrücklich im Zusammenhang mit öffentlich verfügbaren personenbezogenen Informationen. Die Leitlinie stellt klar, dass berechtigte Interessen in manchen Kontexten als Grundlage dienen können, Organisationen aber eine Abwägung, Schutzmaßnahmen, Rechtewahrung und Governance benötigen.
Und der Trend wird strenger. Im März 2026 berichtete die koreanische Presse über eine PIPA-Änderung, wonach die Höchststrafen für schwere, wiederholte Datenleckverstöße später im Jahr 2026 auf bis zu 10 % des Umsatzes steigen sollen.
UCPA: Die umfassende Regel gegen unlauteren Wettbewerb
Das UCPA ist das Gesetz, das GC Company im Yanolja-Zivilverfahren zum Verhängnis wurde. Das aktuelle Gesetz enthält zwei relevante Vorschriften:
- Artikel 2(1)(k): erfasst unlautere Nutzungen elektronisch angesammelter und verwalteter technischer oder geschäftlicher Daten, die nicht geheim sind
- Artikel 2(1)(m): die weiter gefasste Auffangnorm für die Nutzung der durch erhebliche Investitionen oder Anstrengungen erzielten Ergebnisse einer anderen Person für das eigene Geschäft ohne Erlaubnis, entgegen den fairen Handelspraktiken
Das UCPA ist für diese Vorschriften nur zivilrechtlich relevant – keine Strafbarkeit – kann aber nach Artikel 4 zu Unterlassungsansprüchen, nach Artikel 5 zu Schadenersatz und selbst zu dreifachem Schadenersatz in bestimmten vorsätzlichen Fällen nach Artikel 14-2 führen. Im Yanolja-Zivilverfahren wurden auf dieser Grundlage rund 1 Milliarde KRW zugesprochen.
Der Yanolja-Fall: Warum man strafrechtlich gewinnen, aber zivilrechtlich verlieren kann
Das ist der Fall, den jeder Geschäftsnutzer in Korea verstehen muss. Ich erzähle ihn als eine einzige Geschichte, weil er sich genau so abgespielt hat und weil das geteilte Ergebnis der Kernpunkt ist.
Was geschah: GC Company scrapte Yanoljas Reisedaten
GC Company betrieb eine konkurrierende Online-Reiseplattform. Das Unternehmen baute einen selbst entwickelten Crawler, der auf den API-Server der Baro-Reservation-App von Yanolja zugriff, die API-URLs und Request-Befehle erlernte und an den Server sendete. Der Scraper erfasste Unterkunftsinformationen: Partnernamen, Adressen, Preise, Verfügbarkeiten und Bilder. GC Company nutzte diese Daten intern für Marketing und Wettbewerbspositionierung.
Yanolja erhob sowohl Strafanzeige als auch Zivilklage.
Strafurteil: Freispruch in allen Punkten (Oberster Gerichtshof 2021Do1533)
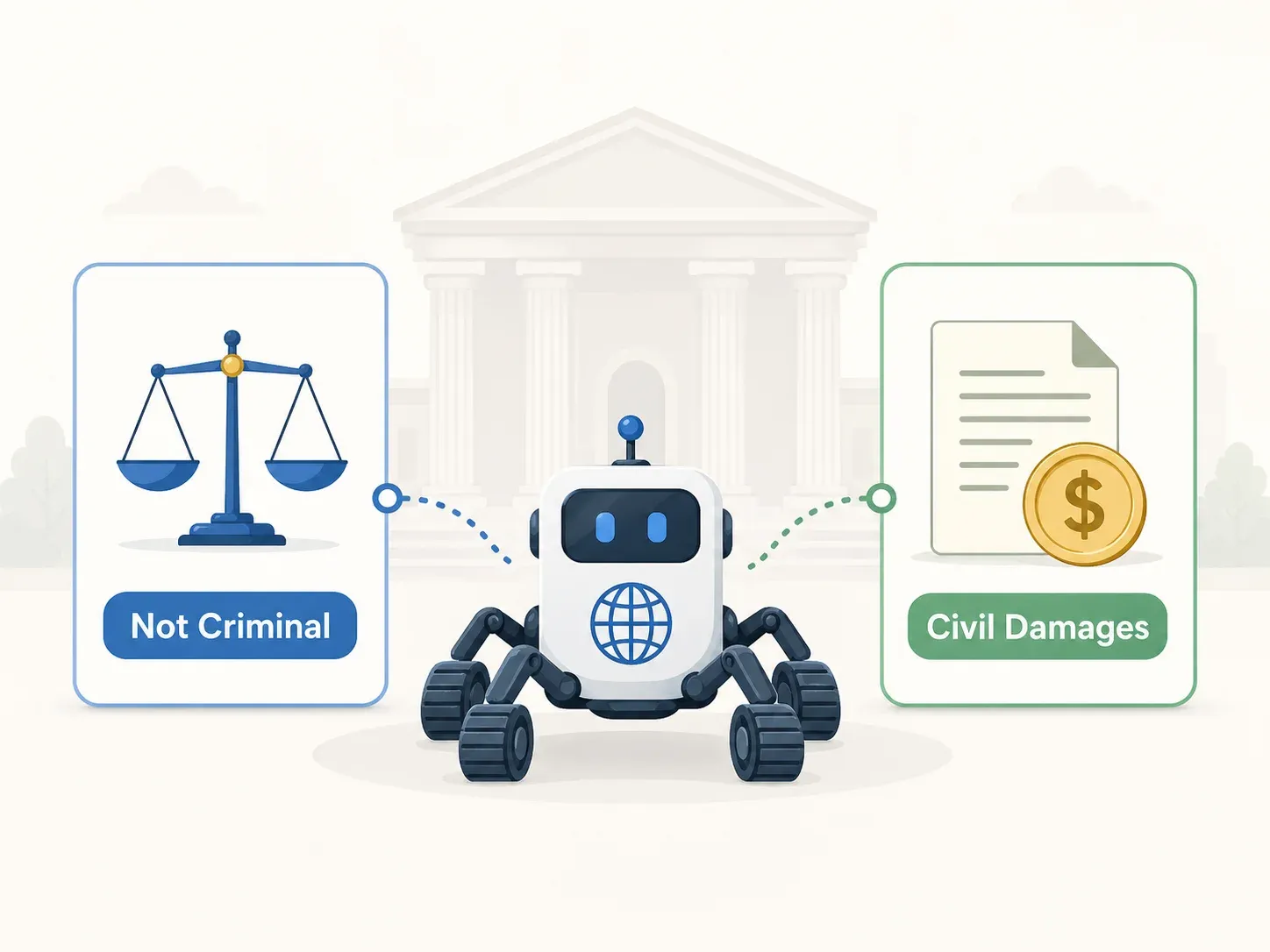
Der Oberste Gerichtshof bestätigte am 12. Mai 2022 den Freispruch der Berufungsinstanz in allen drei Anklagepunkten:
- ICNA Artikel 48 (Eindringen): Es gab keine Zugangsbeschränkungen. Der API-Server war über Browser und mobile App öffentlich erreichbar. Es gab keine technische Blockade. Die Nutzungsbedingungen beschränkten die Nutzung, nicht den Zugang.
- Copyright Act (Rechte des Datenbankherstellers): Die Beklagten vervielfältigten nicht „alle oder einen wesentlichen Teil“ der Datenbank. Die kopierten Daten waren bereits öffentlich bekannt, und die Beweise zeigten nicht, dass der kopierte Teil Yanoljas wesentliche Investition widerspiegelte.
- Criminal Act Artikel 314 (Geschäftsstörung): Es wurde keine tatsächliche Beeinträchtigung des Betriebs des API-Servers von Yanolja nachgewiesen. Keine Datenveränderung. Kein Vorsatz für Geschäftsstörung.
Die zitierfähige Regel lautet: Zugangsbeschränkungen müssen anhand von „Schutzmaßnahmen, Nutzungsbedingungen und anderen objektiv erkennbaren Umständen“ beurteilt werden. Wenn das Tor unten ist, ist das Durchgehen kein Hausfriedensbruch.
Zivilurteil: 1 Milliarde KRW Schadenersatz nach UCPA
Und hier kippt die Geschichte. Das Seoul Central District Court und anschließend das Seoul High Court (Fall 2021Na2034740, entschieden am 25. August 2022) kamen zu dem Ergebnis, dass GC Company gegen die Auffangnorm des UCPA verstoßen hatte. Das Gericht sprach rund 1 Milliarde KRW (~800.000 USD) als Schadenersatz zu und ordnete die Einstellung weiterer Datenkopien an.
Die Begründung: Yanoljas Unterkunftsdatenbank hatte wirtschaftlichen Wert und spiegelte eine erhebliche Investition wider: Sammeln, Prüfen und Aktualisieren von Unterkunftsdaten. GC Company nutzte diese Investition kostenlos mit. Das Zivilurteil wurde auf Ebene des Seoul High Court rechtskräftig.
Praktische Lehre: Strafrechtlicher Freispruch bedeutet nicht zivilrechtliche Sicherheit
Das ist die kontraintuitivste Lehre aus dem koreanischen Scraping-Recht. Strafrechtlich zulässiger Zugriff immunisiert nicht gegen wirtschaftlich unfaire Nutzung. „Kann ich strafrechtlich verfolgt werden?“ und „Kann ich verklagt werden?“ sind unterschiedliche Fragen mit möglicherweise gegensätzlichen Antworten.
Für Geschäftsnutzer gilt: Selbst wenn Ihre Scraping-Methode strafrechtlich klar in der grünen Zone liegt, entscheidet Ihre Nutzung der Daten, vor allem wenn Sie direkt mit der Quelle konkurrieren, über Ihr zivilrechtliches Risiko.
Korea vs. USA vs. EU: Wie sich die Web-Scraping-Gesetze vergleichen
Mir ist kein anderer Leitfaden begegnet, der das in einer einzigen Tabelle zusammenfasst – erstaunlich, wenn man bedenkt, wie viele Unternehmen grenzüberschreitend scrapen.
| Dimension | Südkorea | USA | EU / EWR |
|---|---|---|---|
| Zentrales Gesetz | ICNA Art. 48, Copyright Act | CFAA (18 U.S.C. §1030), einzelstaatliche Gesetze | DSGVO, Datenbankrichtlinie (96/9/EG) |
| Leitfall | Yanolja v. GC Company (Oberster Gerichtshof 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (EuGH C-30/14, 2015) |
| Scraping öffentlicher Daten | Legal, wenn keine objektiven Zugangshürden bestehen („Tor unten“) | Legal nach der hiQ-Logik (öffentliche Daten); Van Buren verengte den CFAA | Hängt von Datenbankrechten, Vertrag, Urheberrecht, DSGVO und nationalem Recht ab |
| Regeln für personenbezogene Daten | PIPA (2023 geändert) – Einwilligung oder Rechtsgrundlage | Sektoral: CCPA (Kalifornien), staatliche Datenschutzgesetze | DSGVO – strenge Einwilligung / berechtigtes Interesse; Höchststrafe 20 Mio. € oder 4 % des weltweiten Umsatzes |
| Verstoß gegen ToS = Straftat? | Nein (Gerichte sehen ToS ≠ ICNA-Verstoß) | Nein (Van Buren 2021: ToS ≠ CFAA) | Im Allgemeinen nein, aber Vertragsverletzung möglich (Ryanair) |
| Datenbankschutz | Copyright Act: Rechte des Datenbankherstellers | Kein allgemeines Bundesrecht zum Datenbankschutz | Sui-generis-Datenbankrecht |
| Maximale Strafe | Bis zu 5 Jahre / 50 Mio. KRW (ICNA) | Bis zu 10 Jahre / 250.000 USD (CFAA) | Je nach Mitgliedstaat unterschiedlich |
Wichtige Unterschiede für Ihr Unternehmen
- Korea hat keine breite Ausnahme für Text-and-Data-Mining (TDM) wie die DSM-Richtlinie der EU. Wenn Sie KI-Modelle mit gescrapten koreanischen Daten trainieren, gibt es keine gesetzliche Freistellung.
- Die UCPA-Auffangnorm in Korea ist breiter und unvorhersehbarer als das US-Recht zum unlauteren Wettbewerb. Das zivilrechtliche Ergebnis in Yanolja wäre unter US-Recht deutlich schwerer zu erreichen.
- Alle drei Rechtsräume sind sich einig: Ein Verstoß gegen Nutzungsbedingungen allein ist keine Straftat.
- Koreas Datenbankschutz ist gesetzlich verankert (ähnlich wie in der EU), während die USA kein allgemeines Bundesrecht zum Datenbankschutz kennen. Das gibt koreanischen Plattformbetreibern mehr zivilrechtliche Instrumente.
- Wer grenzüberschreitend scrapt, muss das strengste anwendbare Recht beachten. Ein Scraping-Projekt, das koreanische, US- und EU-Daten berührt, muss alle drei Regime einhalten.
Branchenspezifische Szenarien: Ist Web-Scraping in Korea für Ihre Branche legal?
Das Risikoprofil unterscheidet sich je nach Branche dramatisch, und keiner der Leitfäden, die ich gefunden habe, ordnet das koreanische Scraping-Recht konkreten Vertikalen zu. Also habe ich es selbst zusammengetragen.
E-Commerce: Preisüberwachung und Produktdaten
Öffentliche Produktpreise von Coupang, Gmarket oder 11Street zu scrapen ist das klarste Beispiel für die grüne Zone – bleiben Sie bei faktischen Feldern (Preis, Verfügbarkeit, Produktname), vermeiden Sie Bereiche nur mit Login, umgehen Sie keine technischen Sperren und nutzen Sie die Daten intern für Benchmarks.
Das Risiko steigt, wenn Sie Produktbeschreibungen scrapen (kreativer Inhalt → Urheberrecht), Verkäufer-Kontaktinformationen (PIPA), Bilder (Urheberrecht) oder einen gesamten Katalog (Rechte des Datenbankherstellers + UCPA).
Einen führenden koreanischen E-Commerce-Scraping-Fall, der mit Yanolja vergleichbar wäre, habe ich nicht gefunden. Die weiter entwickelte Rechtsprechung gibt es im Reise- und Recruiting-Bereich – aber keine Klagen bedeutet nicht kein Risiko.
Thundersbits geplanter Scraper und der Cloud-Scraping-Modus sind genau für dieses Muster gemacht: wiederkehrende Preis- und Bestandsprüfungen auf öffentlichen Seiten, wobei Sie mit AI Suggest Fields die gewünschten Spalten auswählen und personenbezogene Felder ausschließen können.
Immobilien: Objektanzeigen
Der Immobilienbereich ist naturgemäß ein gelber Bereich. Inserate auf Plattformen wie Zigbang oder Naver Real Estate mischen faktische Daten (Preis, Fläche, Stadtteil) mit Maklernamen, Bürotelefonnummern, Mobilnummern, Fotos und kuratierten Plattformdatenbanken.
Das Scrapen öffentlicher Objektdetails kann weniger riskant sein. Das Sammeln von Makler-Kontaktspalten löst jedoch sofort PIPA aus, und das Scrapen aller Inserate einer Region sieht schnell wie eine wesentliche Datenbankkopie aus.
Minderung: personenbezogene Spalten ausschließen, geografischen Umfang reduzieren, einen legitimen Geschäftszweck dokumentieren, Rate Limits beachten und keine konkurrierende Inserate-Plattform nachbilden. Thunderbits KI kann so konfiguriert werden, dass nur die benötigten Objektfelder extrahiert werden (Preis, Quadratmeter, Lage), während persönliche Kontaktdaten übersprungen werden.
Recruiting: Stellenanzeigen
Recruiting ist die Hochrisikobranche, ohne Wenn und Aber. Korea hat einen direkten Präzedenzfall: JobKorea gegen Saramin. Saramin scrapte die Stellenanzeigen-Datenbank von JobKorea und haftete wegen Verletzung von Datenbankrechten und unlauterem Wettbewerb. Recruiting-Daten verbinden oft Plattforminvestitionen (kuratierte, verifizierte Inserate), großvolumige Datenbankkopien sowie persönliche oder Recruiter-Kontaktinformationen.
Meine Empfehlung: Vermeiden Sie es im Allgemeinen, eine konkurrierende Jobplattform zu scrapen, um eine eigene Jobdatenbank aufzubauen oder zu erweitern. Wenn der Anwendungsfall eng begrenzt ist, holen Sie vor der Erhebung eine rechtliche Prüfung ein, minimieren Sie das Volumen, entfernen Sie persönliche Kontakte und verteilen Sie die Ergebnisse nicht weiter.
Vollständige Straf-/Sanktionsübersicht: Was Sie riskieren, wenn Web-Scraping in Korea schiefläuft
| Koreanisches Gesetz | Verstoßart | Maximale strafrechtliche Sanktion | Maximale zivil-/verwaltungsrechtliche Sanktion | Wichtige Änderung 2023–2026 |
|---|---|---|---|---|
| ICNA Art. 48 | Unbefugter Zugriff / Störung | 5 Jahre / 50 Mio. KRW Geldstrafe | Schadenersatz + Unterlassung | 2024: Art. 48(4) hinzugefügt, gegen Umgehungs-Tools gerichtet |
| Copyright Act (DB-Rechte, Art. 93) | Wesentliche Vervielfältigung einer DB | 3 Jahre / 30 Mio. KRW Geldstrafe | Gesetzlicher Schadenersatz bis zu 50 Mio. KRW/Werk (vorsätzlich gewinnorientiert) | — |
| PIPA | Unrechtmäßige Erhebung personenbezogener Daten | 5 Jahre / 50 Mio. KRW Geldstrafe | Verwaltungsstrafe bis zu 3 % des Gesamtumsatzes; Sammelklagen möglich | Reform 2023; 2024 Leitlinie zu öffentlichen Daten/KI; 2026 Trend zu 10 % bei wiederholten Lecks |
| UCPA Art. 2(1)(k)/(m) | Unlautere Datenerlangung / -nutzung | Nur zivilrechtlich (keine Strafbarkeit für die Auffangnorm) | Schadenersatz + Unterlassung; dreifacher Schadenersatz für bestimmte vorsätzliche Fälle | 2022 Data Framework Act stärkte die Vorschriften |
| Criminal Code Art. 314 | Geschäftsstörung mit technischen Mitteln | 5 Jahre / 15 Mio. KRW Geldstrafe | — | Yanolja: keine tatsächliche Störung nachgewiesen |
Der entscheidende Punkt: Straf- und Zivilverfahren laufen unabhängig voneinander. Sie können gleichzeitig mit beiden konfrontiert werden – und eines gewinnen, während Sie das andere verlieren.
Ihre 10-Punkte-Compliance-Checkliste für Web-Scraping in Korea
Hier sind zehn Ja/Nein-Fragen, die Sie vor jedem Scraping-Projekt durchgehen sollten. Drucken Sie das aus, setzen Sie ein Lesezeichen oder kleben Sie es an den Monitor – was auch immer hilft.
- Benötigt die Zielseite kein Login für die Daten, die Sie wollen? Wenn Login, Token oder Konto nötig sind, steigt das Risiko deutlich in Richtung ICNA Artikel 48.
- Gibt es keine technischen Zugangsbeschränkungen? CAPTCHAs, IP-Sperren, API-Keys, Rate Limits und Bot-Schutz sind starke rote Signale.
- Haben Sie die robots.txt der Seite geprüft? Rechtlich in der koreanischen Rechtsprechung nicht allein bindend, aber ein nützlicher Hinweis auf die Erwartungen der Website und Ihren guten Glauben.
- Erheben Sie personenbezogene Daten? Wenn Namen, Telefonnummern, E-Mails, IDs oder individuelle Kontaktdaten im Umfang enthalten sind, ist eine PIPA-Prüfung erforderlich.
- Kopieren Sie einen „wesentlichen Teil“ der Datenbank der Seite? Stellen Sie sowohl quantitative als auch qualitative Fragen – wie viel, und spiegelt der kopierte Teil die Investition der Quelle wider?
- Haben Sie Ihren Zweck definiert? Interne Analysen sind weniger riskant als Weiterverbreitung oder der Aufbau einer konkurrierenden Datenbank. (Yanolja zeigt jedoch, dass interne wettbewerbliche Nutzung keinen vollständigen Schutz bietet.)
- Haben Sie Ihren legitimen Geschäftszweck schriftlich dokumentiert? Dokumentation hilft bei der PIPA-Abwägung des berechtigten Interesses und als Nachweis des guten Glaubens.
- Haben Sie personenbezogene Felder vor dem Speichern/Verwenden entfernt oder anonymisiert? Das Ausschließen von Kontaktdaten verschiebt Immobilien-, Recruiting- und Verzeichnis-Scraping oft aus dem gefährlichsten PIPA-Muster heraus.
- Verwenden Sie angemessene Anfrageintervalle? Vermeiden Sie Serverüberlastung – Risiken aus Criminal Act Artikel 314 und ICNA Artikel 48(3) steigen, wenn Scraping den Dienstbetrieb beeinträchtigt.
- Haben Sie für große, kommerzielle oder grenzüberschreitende Projekte koreanischen Rechtsrat eingeholt? Koreanisches Recht plus DSGVO/US-Datenschutz- oder Computerzugangsgesetze können alle anwendbar sein.
⚠️ Haftungsausschluss: Diese Checkliste dient der Orientierung, nicht der Rechtsberatung. Wenden Sie sich für konkrete Fälle immer an lokale koreanische Rechtsberatung.
Wie Thunderbit Ihnen hilft, koreanische Websites verantwortungsvoll zu scrapen
Volle Offenheit: Ich arbeite im Marketing-Team von Thunderbit. Aber ich halte die Passung von Produkt und Rechtslage hier wirklich für sinnvoll – nicht nur für einen Verkaufspitch.
Thunderbit ist für genau die Green-Zone-Anwendungsfälle dieses Artikels gebaut: das Scrapen öffentlich verfügbarer Daten ohne Login. So ordnen sich die einzelnen Funktionen in das Compliance-Rahmenwerk ein:
- Cloud-Scraping-Modus für öffentliche Seiten – kein Login nötig, keine lokale Sitzung erforderlich, bleibt innerhalb der öffentlich zugänglichen Grenzen. Das passt zum Yanolja-Prinzip des „Tors unten“.
- AI Suggest Fields erlaubt es Ihnen, genau die Datenspalten zu definieren, die extrahiert werden sollen. Sie brauchen Produktpreise und Verfügbarkeit, aber keine Verkäufer-Telefonnummern? Dann schließen Sie die personenbezogenen Spalten einfach aus. Das ist der einfachste Weg, PIPA-Auslöser zu vermeiden.
- Geplanter Scraper für wiederkehrende Preis-, Bestands- oder Anzeigenprüfungen in angemessenen Abständen – kein Grund, einen Server mit ständigen Anfragen zu belasten.
- Kostenloser Datenexport nach Excel, Google Sheets, Airtable und Notion für interne Analyse-Workflows.
- Subpage-Scraping zur Anreicherung öffentlicher Listendaten (z. B. durch Klick in einzelne Produktseiten für Spezifikationen), ohne Login- oder gesperrte Bereiche zu öffnen.
- KI-Layout-Anpassung – der Scraper liest die Seitenstruktur jedes Mal neu ein und passt sich Layoutänderungen an, ohne fragile Hardcoded-Selektoren.
Thunderbit unterstützt mehrsprachige Nutzung in Dutzenden von Sprachen, was für Teams mit koreanischsprachigen Websites wichtig ist. Sie können es kostenlos über die Thunderbit Chrome-Erweiterung testen.
Kein Tool beseitigt rechtliche Risiken. Aber eine verantwortungsvolle Konfiguration – öffentliche Seiten, faktische Daten, ausgeschlossene personenbezogene Felder, angemessene Intervalle – hält Sie innerhalb des in diesem Artikel beschriebenen Compliance-Rahmens.
Die wichtigsten Erkenntnisse zur Legalität von Web-Scraping in Korea
Fünf Dinge, die Sie sich merken sollten:
- Die Web-Scraping-Technologie selbst ist in Korea legal. Der Oberste Gerichtshof hat das im Yanolja-Urteil bestätigt.
- Das Risiko hängt von der Zugriffsart (Tor oben vs. Tor unten), der Datenart (personenbezogen vs. faktisch) und der Nutzung (intern vs. wettbewerbliche Weiterverbreitung) ab.
- Strafrechtlicher Freispruch ≠ zivilrechtliche Sicherheit. Der Yanolja-Fall zeigt, dass Sie einer Strafverfolgung entgehen und trotzdem Schadenersatz in Milliardenhöhe riskieren können.
- Wenn Sie öffentliche, nicht-personenbezogene, faktische Daten ohne Zugangshürden für interne Zwecke scrapen, bewegen Sie sich im Allgemeinen im sicheren Bereich. Aber „im Allgemeinen“ hat Gewicht – Umfang, Volumen und Zweck zählen alle.
- Konsultieren Sie bei groß angelegten oder kommerziellen Projekten immer lokale koreanische Rechtsberatung. Dieser Artikel dient der Orientierung, nicht der Rechtsberatung.
Wenn Sie koreanische Websites verantwortungsvoll scrapen möchten, können Sie mit Thunderbits kostenlosem Tarif den Workflow in kleinem Maßstab testen. Mehr dazu, wie KI-gestütztes Scraping in der Praxis funktioniert, finden Sie in unseren Leitfäden zu AI Web Scraping und Web-Scraping ohne Programmierung. Und wenn Sie das Tool in Aktion sehen möchten, finden Sie auf unserem YouTube-Kanal Anleitungen zu typischen Anwendungsfällen.
FAQs
1. Ist das Scrapen öffentlich verfügbarer Daten in Korea legal?
Im Allgemeinen ja, was den Strafbereich betrifft – laut dem Yanolja-Urteil des Obersten Gerichtshofs verstößt der Zugriff auf Daten von einer Seite ohne objektive Zugangsbeschränkungen nicht gegen ICNA. Zivilrechtliche Haftung nach UCPA oder Copyright Act kann dennoch bestehen, abhängig von Umfang, Investition der Quelle und Ihrer kommerziellen Nutzung der Daten.
2. Kann ich in Korea wegen Web-Scraping verklagt werden, auch wenn es nicht strafbar ist?
Ja. Straf- und Zivilverfahren sind unabhängig. GC Company wurde in allen strafrechtlichen Anklagepunkten freigesprochen, musste aber im Rahmen der UCPA-Auffangnorm rund 1 Milliarde KRW Zivil-Schadenersatz zahlen. Ein strafrechtlicher Freispruch schützt nicht vor zivilrechtlichen Ansprüchen.
3. Macht ein Verstoß gegen die Nutzungsbedingungen einer Website Web-Scraping in Korea illegal?
Koreanische Gerichte haben konsequent entschieden, dass Verstöße gegen Nutzungsbedingungen allein keine Straftaten nach ICNA darstellen – das Gericht unterschied zwischen der Beschränkung der Nutzung (ToS) und der Beschränkung des Zugangs (technische Barrieren). Allerdings können ToS-Verstöße dennoch eine zivilrechtliche Vertragsverletzung stützen oder als Indiz für bösen Glauben in einer Unlauterkeitsprüfung dienen.
4. Wie unterscheidet sich Koreas Web-Scraping-Recht von dem der USA?
Beide Rechtsräume schützen das Scraping öffentlicher Daten (Yanolja in Korea, hiQ gegen LinkedIn in den USA), und beide halten fest, dass ein bloßer ToS-Verstoß keine Straftat ist (Van Buren in den USA). Der entscheidende Unterschied: Korea hat einen stärkeren gesetzlichen Datenbankschutz und eine breitere Auffangnorm gegen unlauteren Wettbewerb als die USA, die kein allgemeines Bundesrecht zum Datenbankschutz haben. Koreanische Plattformbetreiber haben mehr zivilrechtliche Mittel gegen Scraper.
5. Was passiert, wenn ich personenbezogene Daten von koreanischen Websites scrappe?
PIPA gilt unabhängig davon, ob die Informationen öffentlich sichtbar sind. Personenbezogene Informationen wie Namen, Telefonnummern oder E-Mails ohne Einwilligung oder eine andere Rechtsgrundlage zu erheben, ist ein Verstoß. Die PIPA-Änderung von 2023 hat diesen Schutz gestärkt, und die PIPC-Leitlinie von 2024 zu öffentlich zugänglichen personenbezogenen Informationen befasst sich ausdrücklich mit Web Crawling und Scraping. Die Sanktionen können bis zu 5 Jahre Freiheitsstrafe, 50 Millionen KRW Geldstrafe und Verwaltungssanktionen von bis zu 3 % des Gesamtumsatzes betragen.
Thunderbit für verantwortungsbewusstes Web-Scraping testen Get Started Free
Mehr erfahren




