
Hinter fast jeder Information, die Sie online abrufen, steckt unsichtbare Vorarbeit. Sie suchen nach einem Rezept, vergleichen den Preis Ihrer Lieblings-Sneaker oder filtern Hotels für den Sommerurlaub — und in den allermeisten Fällen war dort längst ein Web-Crawler, der die passenden Inhalte eingesammelt und geordnet hat, bevor Sie überhaupt die erste Taste gedrückt haben. Wie groß dieser Anteil ist, zeigen aktuelle Zahlen: Etwa die Hälfte des gesamten Internetverkehrs geht mittlerweile auf Bots und Crawler zurück, nicht auf Menschen — Branchenumfragen beziffern den Bot-Anteil auf 49–51 %. Während Sie schlafen, kartieren diese digitalen Späher das Netz und sorgen dafür, dass die Informationen der Welt mit einem Klick erreichbar bleiben.
Bleiben drei Fragen: Was sind Web-Crawler überhaupt? Warum sind sie für Unternehmen, Forschende und alle, die auf aktuelle Daten angewiesen sind, so wichtig? Und wie haben Tools wie Thunderbit das Crawling aus der Welt der Programmierer und Tech-Konzerne geholt und für alle nutzbar gemacht? Ich entwickle seit Jahren Automatisierungs- und KI-Tools und habe miterlebt, wie aus mysteriösen „Spidern“ ganz normale Business-Werkzeuge geworden sind. In diesem Artikel klären wir, was Crawler sind, wie sie arbeiten und warum sie 2026 das Rückgrat eines intelligenteren Datenzugriffs bilden.
Web-Crawler sind die Datenspäher des Internets
Daten von jeder Website mit KI extrahieren Get Started Free
Fangen wir bei der Definition an. Web-Crawler — auch Spider oder Bots genannt — sind automatisierte Programme, die das Internet systematisch abklappern, von Seite zu Seite springen und dabei Informationen einsammeln. Stellen Sie sich die fleißigsten Rechercheassistenten der Welt vor: Sie schlafen nie, beschweren sich nie und schaffen an einem einzigen Tag Millionen von Seiten.
Ein Crawler beginnt mit einer Liste von Webadressen (sogenannten „Seeds“), ruft jede davon auf und folgt anschließend den Links, die er dort findet, um weitere Seiten zu entdecken. Auf seinem Weg durch das Web kopiert er Inhalte, indiziert Daten und zeichnet eine Karte der ständig wechselnden Online-Landschaft (Cloudflare). Genau so weiß Google, was im Netz existiert, und genau so halten Preisvergleichsseiten oder Marktforschungs-Tools ihre Daten aktuell.
Kurz gesagt: Web-Crawler sind die Späher, die das Internet durchsuchbar, vergleichbar und nutzbar machen.
Die vielen Gesichter von Web-Crawlern: Typen und Kernfunktionen
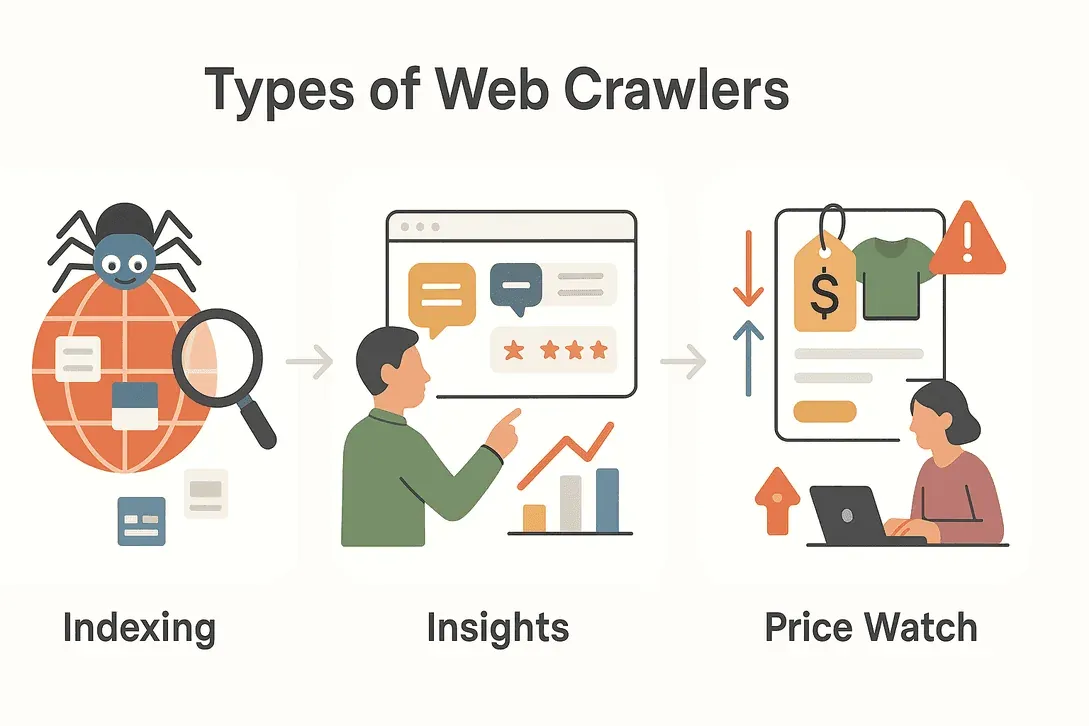 Crawler ist nicht gleich Crawler. Je nach Aufgabe haben sich verschiedene Varianten herausgebildet, jede mit ihrem eigenen Schwerpunkt. Die wichtigsten, denen Sie begegnen werden, im Überblick:
Crawler ist nicht gleich Crawler. Je nach Aufgabe haben sich verschiedene Varianten herausgebildet, jede mit ihrem eigenen Schwerpunkt. Die wichtigsten, denen Sie begegnen werden, im Überblick:
| Typ | Kernfunktion | Typischer Anwendungsfall |
|---|---|---|
| Suchmaschinen-Crawler | Indizieren das Web für Suchergebnisse | Googlebot, Bingbot indizieren neue Websites |
| Data-Mining-Crawler | Sammeln große Datensätze für Analysen | Marktforschung, akademische Studien |
| Preisüberwachungs-Crawler | Verfolgen Produktpreise und Verfügbarkeit | E-Commerce-Preisvergleich, dynamische Preisgestaltung |
| Content-Aggregation-Crawler | Sammeln Artikel, Nachrichten oder Beiträge zur Aggregation | Nachrichtenportale, Content-Kuration |
| Lead-Generation-Crawler | Extrahieren Kontaktinformationen und Geschäftsdaten | Sales Prospecting, B2B-Verzeichnisse |
Drei davon schauen wir uns etwas genauer an:
Suchmaschinen-Crawler
Jede Frage, die Sie bei Google eingeben, baut auf der Arbeit von Suchmaschinen-Crawlern auf. Diese Bots durchstreifen das Web rund um die Uhr, finden neue Seiten, aktualisieren bestehende und indizieren Inhalte, damit sie in den Suchergebnissen auftauchen. Ohne Crawler wären Suchmaschinen blind — sie wüssten nicht, was neu ist, was sich geändert hat oder was überhaupt existiert (TechTarget).
Crawler für Data Mining und Marktforschung
Unternehmen und Forschende setzen Crawler ein, um große Datenmengen für Analysen zusammenzutragen. Wie oft taucht die Marke eines Wettbewerbers online auf? Wie ist die Stimmung rund um einen neuen Produktstart? Data-Mining-Crawler durchsuchen Foren, Bewertungen, soziale Medien und vieles mehr und verwandeln das chaotische Web in strukturierte Erkenntnisse (DataHut).
Preisüberwachungs- und Produkt-Tracking-Crawler
Im E-Commerce ändern sich Preise und Produktdetails im Minutentakt. Preisüberwachungs-Crawler behalten die Konkurrenz im Blick und melden Preissenkungen, Lageränderungen oder neue Produkte. Das ist die Grundlage für dynamische Preisstrategien — und dafür, dass Unternehmen wettbewerbsfähig bleiben (AIMultiple).
Warum Web-Crawler für den modernen Datenzugriff unverzichtbar sind
Das Internet ist schlicht zu groß, um es von Hand im Blick zu behalten. Inzwischen existieren mehr als 1,4 Milliarden Websites, Tendenz steigend, und täglich kommen rund eine Million dazu. Web-Crawler leisten dabei Folgendes:
- Daten in großem Maßstab erfassen: Millionen von Seiten in Stunden statt in Monaten besuchen.
- Immer aktuell bleiben: Kontinuierlich nach Änderungen, neuen Inhalten oder Breaking News suchen.
- Dynamische Echtzeitinformationen nutzen: Auf Marktbewegungen, Preisänderungen oder Trendthemen reagieren, sobald sie entstehen.
- Datengestützte Entscheidungen ermöglichen: Alles antreiben — von Suchmaschinen über Marktforschung bis hin zu Risikomanagement und Finanzmodellierung (DEV Community).
In einer Welt, in der Daten das Rückgrat digitaler Geschäftsstrategien sind, sind Web-Crawler die Motoren, die diesen Datenfluss am Laufen halten.
Häufige Anwendungsfälle für Web-Crawler in verschiedenen Branchen
Crawler sind längst nicht mehr nur Sache von Tech-Giganten oder Suchmaschinen. So nutzen verschiedene Branchen sie:
| Branche | Anwendungsfall | Vorteil |
|---|---|---|
| Vertrieb | Lead-Generierung | Zielgerichtete Prospect-Listen aus Verzeichnissen aufbauen |
| E-Commerce | Preisüberwachung | Preise, Lagerbestand und Produktänderungen der Konkurrenz verfolgen |
| Marketing | Content-Aggregation | Nachrichten, Artikel und Social-Media-Erwähnungen kuratieren |
| Immobilien | Aggregation von Immobilienanzeigen | Anzeigen aus mehreren Quellen zusammenführen |
| Reisen | Flug- und Hotelvergleich | Preise, Verfügbarkeit und Bedingungen überwachen |
| Finanzen | Risikobewertung | Nachrichten, Meldungen und Sentiment für Investitionen verfolgen |
Praxisbeispiel:
Eine Immobilienagentur lässt Crawler Objektdetails, Fotos und Ausstattungsmerkmale von mehreren Immobilienportalen einsammeln und stellt ihren Kunden so eine einheitliche, aktuelle Marktübersicht bereit (DataHut).
Ein E-Commerce-Team überwacht mit Crawlern SKUs und Preise der Konkurrenz und justiert die eigene Strategie in Echtzeit nach (AIMultiple).
Wie Web-Crawler funktionieren: Ein Schritt-für-Schritt-Überblick
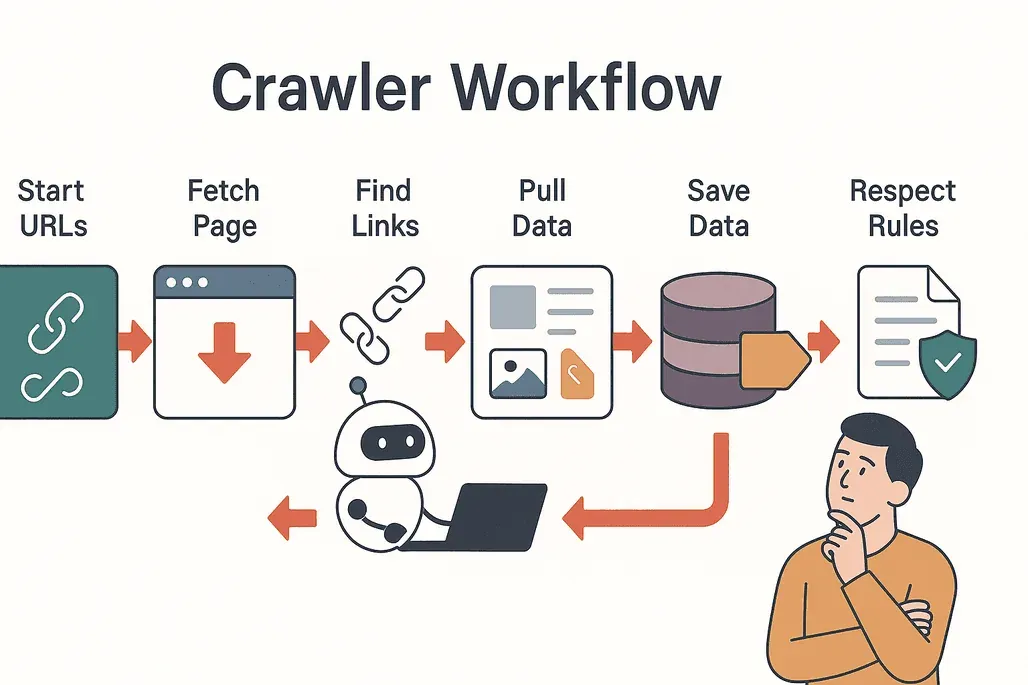 Werfen wir einen Blick unter die Haube. So läuft ein typischer Crawl ab:
Werfen wir einen Blick unter die Haube. So läuft ein typischer Crawl ab:
- Mit Seeds starten: Der Crawler beginnt mit einer Liste von Start-URLs.
- Besuchen und abrufen: Er ruft jede Seite auf und lädt den Inhalt herunter.
- Links extrahieren: Der Crawler findet alle Links auf der Seite.
- Links folgen: Neue, noch nicht besuchte Links wandern in seine Warteschlange.
- Daten extrahieren: Relevante Informationen (Text, Bilder, Preise usw.) werden kopiert und strukturiert.
- Ergebnisse speichern: Die Daten landen in einer Datenbank oder werden für Analysen exportiert.
- Regeln beachten: Der Crawler liest die
robots.txt-Datei jeder Website, prüft, was erlaubt ist, und meidet gesperrte Bereiche (Cloudflare).
Best Practices:
- Rücksichtsvoll crawlen (Server nicht überlasten).
- Datenschutz und rechtliche Grenzen respektieren.
- Doppelte Inhalte und unnötige Anfragen vermeiden.
Herausforderungen und Überlegungen beim Einsatz von Web-Crawlern
Reibungslos läuft Crawling nicht immer. Diese Hürden tauchen am häufigsten auf:
- Serverlast: Zu viele Anfragen können eine Website verlangsamen oder lahmlegen.
- Doppelte Inhalte: Crawler besuchen mitunter dieselben Seiten erneut oder verfangen sich in Schleifen.
- Datenschutz und Legalität: Nicht alle Daten dürfen frei verwendet werden — prüfen Sie immer Nutzungsbedingungen und Datenschutzgesetze.
- Technische Barrieren: Manche Websites blockieren Crawler mit CAPTCHAs, dynamischen Inhalten oder Anti-Bot-Maßnahmen (DEV Community).
Tipps für den Erfolg:
- Verwenden Sie moderate Crawl-Raten.
- Beobachten Sie Änderungen in der Website-Struktur.
- Bleiben Sie bei Datenschutzvorschriften auf dem neuesten Stand.
Thunderbit: Web-Crawler für alle zugänglich machen
Jetzt wird es interessant. Früher hieß ein eigener Web-Crawler: Code schreiben, Einstellungen konfigurieren und stundenlang Fehler suchen. Mit Thunderbit drehen wir diesen Ablauf um.
Thunderbit ist eine KI-gestützte Web-Scraper-Erweiterung für Chrome, gemacht für Business-Nutzer — ganz ohne Programmierung. Das zeichnet sie aus:
- Anweisungen in natürlicher Sprache: Sie beschreiben einfach, welche Daten Sie brauchen („Hole alle Produktnamen und Preise von dieser Seite“), und die KI von Thunderbit übernimmt den Rest.
- KI-gestützte Feldvorschläge: Ein Klick auf „AI Suggest Fields“ genügt, dann liest Thunderbit die Seite aus und empfiehlt die besten Spalten zum Extrahieren.
- Subpage-Scraping: Mehr Details gewünscht? Thunderbit ruft jede Unterseite auf (etwa Produktdetails oder LinkedIn-Profile) und reichert Ihren Datensatz automatisch an.
- Sofortige Vorlagen: Für beliebte Websites (Amazon, Zillow, Shopify usw.) gibt es vorgefertigte Vorlagen, die die Daten mit einem Klick erfassen.
- Einfache Exporte: Schicken Sie Ihre Daten direkt nach Excel, Google Sheets, Airtable oder Notion — ohne Zwischenschritte.
- Kostenloser Datenexport: Laden Sie Ihre Ergebnisse kostenlos als CSV oder JSON herunter.
Thunderbit genießt das Vertrauen von über 100.000 Nutzern weltweit — von Vertriebsteams über E-Commerce-Verantwortliche bis hin zu Immobilienprofis.
Thunderbit KI-Web-Scraper kostenlos testen
Thunderbit vs. traditionelle Web-Crawler
Wie schlägt sich Thunderbit gegen den klassischen Ansatz? Der direkte Vergleich:
| Funktion | Thunderbit | Traditionelle Crawler |
|---|---|---|
| Einrichtungszeit | 2 Klicks (KI übernimmt die Einrichtung) | Stunden/Tage (manuelle Konfiguration, Coding) |
| Erforderliche technische Kenntnisse | Keine (Anweisungen in einfachem Deutsch) | Hoch (Coding, Selektoren, Scripting) |
| Flexibilität | Funktioniert auf jeder Website, passt sich Änderungen an | Bricht bei Layout-Änderungen zusammen |
| Subpage-Scraping | Integriert, keine zusätzliche Einrichtung | Manuelles Scripting erforderlich |
| Exportoptionen | Excel, Sheets, Airtable, Notion, CSV, JSON | Meist nur CSV/JSON |
| Wartung | KI passt sich automatisch an | Häufige manuelle Korrekturen |
Mit Thunderbit brauchen Sie weder Entwicklerkenntnisse noch stundenlanges Feintuning. Zeigen, klicken, und die KI übernimmt die Schwerarbeit (Thunderbit Blog).
Mit Thunderbit in Web-Crawler einsteigen
Lust, es selbst zu testen? So legen Sie mit Thunderbit in wenigen Minuten los:
- Installieren Sie die Thunderbit Chrome-Erweiterung.
- Öffnen Sie die Website, die Sie crawlen möchten.
- Klicken Sie auf das Thunderbit-Symbol und dann auf „AI Suggest Fields“. Die KI empfiehlt Spalten auf Basis des Seiteninhalts.
- Passen Sie bei Bedarf Felder an und klicken Sie dann auf „Scrape“. Thunderbit extrahiert die Daten — auf Wunsch auch von Unterseiten.
- Exportieren Sie Ihre Ergebnisse nach Excel, Google Sheets, Airtable, Notion oder laden Sie sie als CSV/JSON herunter.
Was ist Data Scraping und wie macht man es 2025 Get Started Free
Das war’s — keine Skripte, kein Coding, kein Frust. Ob Sie Preise verfolgen, eine Lead-Liste aufbauen oder Nachrichten aggregieren: Thunderbit erledigt die meisten alltäglichen Crawling-Aufgaben so, dass auch Nicht-Entwickler sie an einem einzigen Nachmittag schaffen.
Fazit: Web-Crawler sind der Schlüssel zu intelligenterem Datenzugriff
Web-Crawler sind die unsichtbaren Motoren unserer digitalen Welt und machen Informationen für alle zugänglich, durchsuchbar und nutzbar. Ob Suchmaschine, Vertriebsteam, E-Commerce oder Immobilien — Crawler sind für jeden unverzichtbar geworden, der verlässliche, aktuelle Daten braucht.
Und dank KI-gestützter Tools wie Thunderbit müssen Sie kein Programmierer sein, um ihre Leistung zu nutzen. Mit wenigen Klicks verwandelt jeder das Web in eine strukturierte, nutzbare Ressource — und schafft damit die Grundlage für klügere Entscheidungen und neue Chancen.
Neugierig, was Web-Crawler für Ihr Unternehmen leisten können? Laden Sie Thunderbit herunter und heben Sie noch heute die verborgenen Daten des Webs. Weitere Tipps und tiefere Einblicke finden Sie im Thunderbit-Blog.
KI-Web-Scraper testen Get Started Free
FAQs
1. Was genau ist ein Web-Crawler?
Ein Web-Crawler ist ein automatisiertes Programm (manchmal auch Spider oder Bot genannt), das das Internet systematisch durchsucht, Webseiten besucht, Links folgt und Informationen für die Indizierung oder Analyse sammelt.
2. Worin unterscheiden sich Web-Crawler von Web-Scrapern?
Web-Crawler sind darauf ausgelegt, große Teile des Webs zu entdecken und zu kartieren, wobei sie oft Links von Seite zu Seite folgen. Web-Scraper hingegen konzentrieren sich darauf, bestimmte Daten aus gezielten Seiten zu extrahieren. Viele moderne Tools (wie Thunderbit) kombinieren beide Funktionen.
3. Warum sind Web-Crawler für Unternehmen wichtig?
Web-Crawler ermöglichen Unternehmen den Zugriff auf aktuelle Informationen in großem Maßstab — sei es zur Überwachung von Konkurrenzpreisen, zur Aggregation von Inhalten oder zum Aufbau von Lead-Listen. Sie unterstützen Entscheidungen in Echtzeit und helfen Unternehmen, wettbewerbsfähig zu bleiben.
4. Ist die Nutzung von Web-Crawlern legal?
Web-Crawling ist in der Regel legal, wenn es verantwortungsvoll und im Einklang mit den Nutzungsbedingungen und Datenschutzrichtlinien einer Website erfolgt. Prüfen Sie immer die robots.txt-Datei einer Website und beachten Sie die Datenschutzvorschriften.
5. Wie macht Thunderbit Web-Crawling einfacher?
Thunderbit nutzt KI, um Einrichtung, Feldauswahl und Datenextraktion zu automatisieren. Mit Anweisungen in natürlicher Sprache und sofort einsatzbereiten Vorlagen kann jeder Websites crawlen und Daten extrahieren — ganz ohne Coding oder technische Kenntnisse. Die Daten lassen sich direkt nach Excel, Google Sheets, Airtable oder Notion exportieren und sofort verwenden.
Mehr erfahren




