
Das Internet ist heute eine echte Goldmine für Daten – so sehr, dass sie mittlerweile das Fundament vieler Unternehmen bilden. Egal ob Vertrieb, E-Commerce, Immobilien oder Wettbewerbsanalyse: Wer die richtigen Infos schnell parat hat, verschafft sich einen klaren Vorsprung. Aber mal ehrlich: Niemand hat Lust, stundenlang Daten von Webseiten per Hand in Excel zu kopieren. Genau hier kommt der Web-Scraper ins Spiel – und das Ganze ist viel unkomplizierter, als du vielleicht denkst.
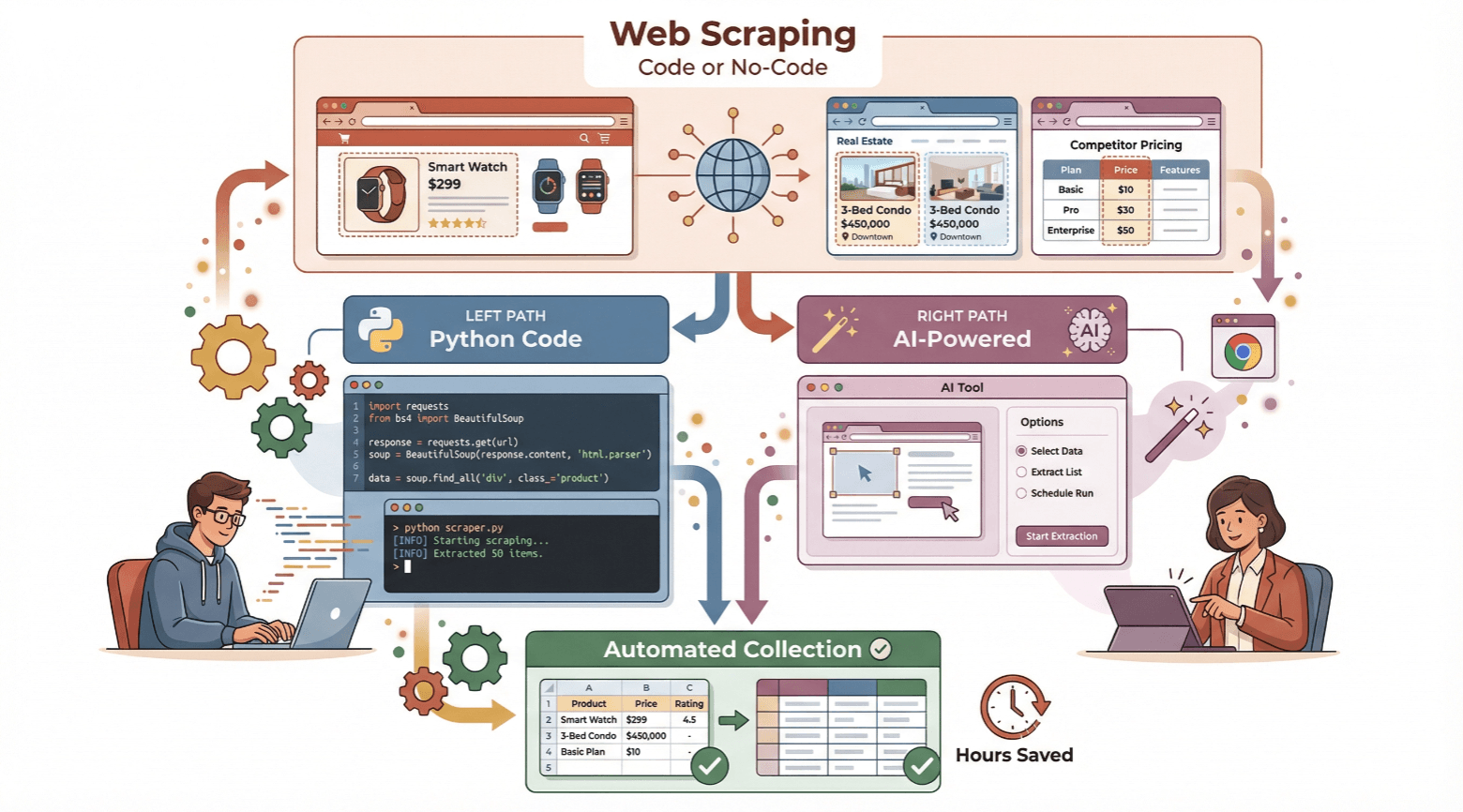
In diesem Guide zeige ich dir, wie du ganz easy einen Web-Scraper erstellst – egal, ob du als Anfänger mit Python loslegen willst oder lieber komplett ohne Code mit einem KI-Tool wie arbeitest. Ich erkläre dir die Basics, führe dich Schritt für Schritt durch beide Methoden und helfe dir, die beste Lösung für dich zu finden. Bereit, Zeit zu sparen und die Vorteile automatisierter Datenerfassung zu nutzen? Dann lass uns direkt starten.
Was ist ein Web-Scraper? Die Basics auf den Punkt gebracht
Ein Web-Scraper ist ein Tool – also eine Software oder ein Service –, das automatisch Infos von Webseiten einsammelt. Stell dir vor, du brauchst eine Liste aller Cafés in deiner Stadt, inklusive Adresse und Telefonnummer. Du könntest dich jetzt durch jede Seite klicken und alles per Hand kopieren (hallo Copy-Paste-Marathon) – oder du lässt einen Web-Scraper die Arbeit für dich machen.
Ein Web-Scraper ist wie dein digitaler Helfer: Er liest Webseiten aus, findet gezielt die Daten, die du brauchst (z. B. Preise, Produktnamen oder Kontaktdaten) und speichert sie ordentlich in einer Tabelle oder Datenbank. Statt ständig zwischen Browser und Excel zu springen, übernimmt der Scraper das Sammeln, Auslesen und Speichern – und das in einem Bruchteil der Zeit.
So läuft das Ganze im Hintergrund ab:
- Anfrage: Der Scraper schickt eine Anfrage an die Webseite und lädt den HTML-Code runter.
- Auslesen: Er analysiert das HTML und sucht gezielt nach den Infos, die du brauchst (z. B. Preis in einem
<span>-Tag). - Extrahieren: Die Daten werden rausgezogen und in einem strukturierten Format gespeichert (CSV, Excel, Google Sheets usw.).
Manuelles Kopieren ist wie ein Loch mit dem Löffel graben. Web Scraping ist der Bagger auf der Baustelle.
Warum ein Web-Scraper für Unternehmen heute ein Muss ist
Web Scraping ist längst nicht mehr nur was für Techies oder Daten-Nerds – es ist für alle, die auf aktuelle und verlässliche Infos angewiesen sind, ein echter Gamechanger. Fast setzen mittlerweile auf datenbasierte Entscheidungen, und der Markt für Web Scraping wird sich bis 2030 voraussichtlich verdoppeln.
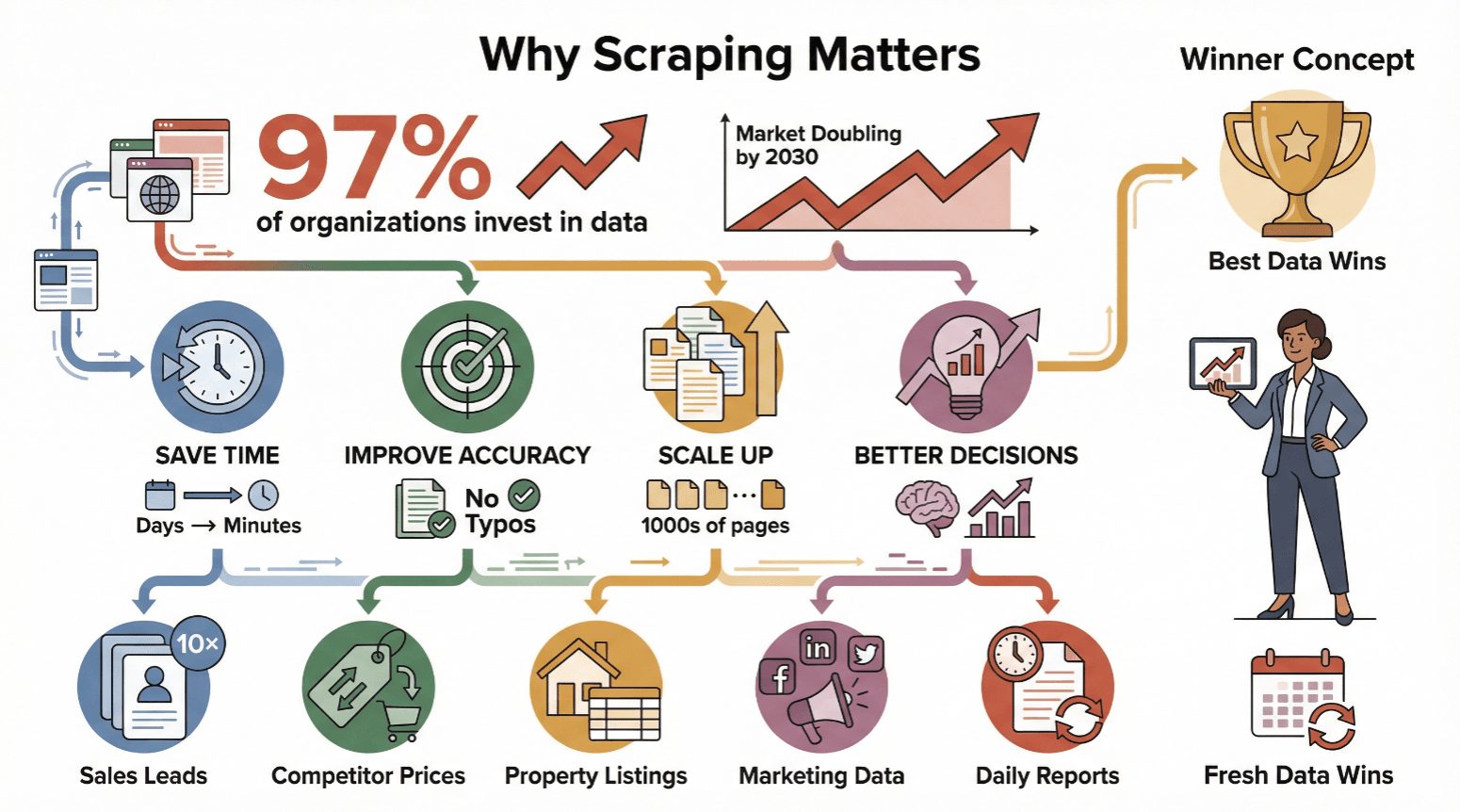
Warum setzen Unternehmen jeder Größe auf Web Scraping?
- Zeitersparnis: Automatisiertes Scraping erledigt in Minuten, wofür manuell Tage draufgehen würden.
- Mehr Genauigkeit: Software macht keine Tippfehler und wird nicht müde.
- Skalierbarkeit: Statt nur ein paar Seiten kannst du tausende Webseiten auf einmal auslesen.
- Bessere Entscheidungen: Aktuelle Daten führen zu klügeren Strategien – egal ob bei Preisen, Lead-Generierung oder Trendanalysen.
Hier ein paar typische Anwendungsbeispiele:
| Anwendungsfall | Wer profitiert | Typisches Ergebnis |
|---|---|---|
| Leads aus Branchenverzeichnissen extrahieren | Vertriebsteams | 10× mehr Leads, deutlich weniger Zeitaufwand für Recherche |
| Konkurrenzpreise im E-Commerce überwachen | E-Commerce-Manager | Preisoptimierung in Echtzeit, bessere Margen |
| Immobilienangebote aggregieren | Immobilienmakler | Schnellere Deals, stets aktuelle Marktdaten |
| Marketingdaten aus Web/Social Media sammeln | Marketingteams | Zielgenauere Kampagnen, bessere Erfolgskontrolle |
| Tägliche Web-Reports automatisieren | Operations, Analysten | Geringere Personalkosten, weniger Fehler, pünktliche und konsistente Berichte |
Kurz gesagt: Wer die besten und aktuellsten Daten hat, ist klar im Vorteil.
Einsteiger-Guide: Einen einfachen Web-Scraper mit Python bauen
Du willst wissen, wie Web Scraping technisch funktioniert? Python ist dafür super geeignet – auch für Anfänger. Mit ein paar Schritten kannst du dir einen einfachen Scraper selbst bauen. So geht’s:
Die Umgebung vorbereiten
Zuerst brauchst du Python auf deinem Rechner. Lade die aktuelle Version von runter und folge den Installationsanweisungen für dein Betriebssystem (Windows oder Mac). Wichtig: Aktiviere „Add Python to PATH“ während der Installation.
Öffne dann das Terminal oder die Eingabeaufforderung und installiere die nötigen Bibliotheken:
1pip install requests
2pip install bs4
3pip install pandasrequestslädt Webseiten runter.bs4(Beautiful Soup) hilft beim Auslesen von HTML.pandasist praktisch, um Daten als CSV oder Excel zu speichern.
Webseitenstruktur checken
Bevor du loslegst, musst du wissen, wo die gewünschten Daten im HTML stehen. Öffne die Zielseite in Chrome, mach einen Rechtsklick auf das gewünschte Element (z. B. Jobtitel) und wähle „Untersuchen“. Das passende HTML-Element wird markiert – vielleicht ein <a>-Tag mit der Klasse jobtitle. Notiere dir diese Tags und Klassen, sie sind wichtig für deinen Scraper.
Den Scraper schreiben und ausführen
Angenommen, du möchtest Jobtitel und Firmennamen von einer Jobbörse extrahieren. Hier ein einfaches Beispiel:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4URL = "https://example.com/jobs" # Ziel-URL anpassen
5response = requests.get(URL)
6soup = BeautifulSoup(response.text, 'html.parser')
7# Alle Jobtitel und Firmennamen finden (Selektoren ggf. anpassen)
8titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
9companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
10# Als CSV speichern
11df = pd.DataFrame({'Job Title': titles, 'Company': companies})
12df.to_csv('jobs.csv', index=False)
13print("Scraping abgeschlossen! Daten gespeichert in jobs.csv")- Passe die URL und Klassennamen an deine Zielseite an.
- Führe das Skript im Terminal aus:
python yourscript.py - Öffne
jobs.csv, um die Ergebnisse zu sehen.
Tipp: Für komplexere Seiten (z. B. mit mehreren Seiten oder dynamischen Inhalten) brauchst du eventuell Schleifen oder Tools wie Selenium. Für viele statische Seiten reicht dieses Vorgehen aber völlig aus.
No-Code-Lösung: Web-Scraper mit Thunderbit erstellen
Du willst gar nicht programmieren? Dann ist genau das Richtige – ein KI-basierter Web-Scraper, der komplett ohne Code auskommt. Mit Thunderbit kommst du in wenigen Klicks von „Ich brauche diese Daten“ zu „Hier ist meine Tabelle“.
So funktioniert’s:
Schritt 1: Thunderbit Chrome-Erweiterung installieren
Geh zur und füge die Erweiterung deinem Browser hinzu. Registriere dich kostenlos (im Gratis-Tarif kannst du einige Seiten testen).
Schritt 2: Zielwebseite öffnen
Ruf die Seite auf, von der du Daten extrahieren möchtest. Logge dich ggf. ein und scrolle, damit alle Inhalte geladen werden.
Schritt 3: Datenbedarf beschreiben
Klick auf das Thunderbit-Icon, um die Seitenleiste zu öffnen. Du kannst entweder:
- „KI Felder vorschlagen“ anklicken und Thunderbits KI analysiert die Seite und schlägt passende Spalten vor (z. B. „Produktname“, „Preis“, „Bild“).
- Oder du gibst eine einfache Beschreibung ein (z. B. „Alle Buchtitel und Autoren von dieser Seite extrahieren“).
Thunderbits KI erkennt automatisch Felder und Datentypen. Du kannst Felder umbenennen, hinzufügen oder entfernen.
Schritt 4: Ersten Scrape starten
Sind die Felder festgelegt, klick einfach auf „Scrapen“. Thunderbit extrahiert die Daten, erkennt bei Bedarf auch mehrere Seiten und zeigt alles übersichtlich in einer Tabelle an. Willst du Details von Unterseiten (z. B. einzelne Produktseiten), klick auf „Unterseiten scrapen“ – Thunderbit besucht dann alle Links und sammelt weitere Infos.
Schritt 5: Ergebnisse prüfen und exportieren
Check deine Daten in der Thunderbit-Tabelle. Bist du zufrieden, klick auf „Exportieren“ und wähle das gewünschte Format: Excel, CSV, Google Sheets, Airtable, Notion oder JSON. Exporte sind kostenlos und unbegrenzt.
Das war’s. Kein Code, keine Vorlagen, kein Stress.
Vergleich: Klassische vs. No-Code Web-Scraper
Wie schlagen sich die beiden Ansätze im Vergleich?
| Lösung | Einrichtungszeit | Erforderliche Kenntnisse | Wartungsaufwand | Flexibilität | Exportmöglichkeiten |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Stunden/Tage | Programmieren, HTML | Hoch (anfällig) | Sehr hoch | CSV, Excel, JSON (per Code) |
| Ältere No-Code-Tools | 30–60 Minuten | Etwas Technikverständnis | Mittel (manuell) | Gut für statische Seiten | CSV, Excel |
| Thunderbit (KI No-Code) | Minuten | Keine (einfache Sprache) | Gering (KI passt an) | Hoch (dynamische Seiten) | Excel, CSV, Sheets, Notion... |
Mit Thunderbits KI-basiertem Ansatz sparst du dir aufwendige Einrichtung und ständiges Nachbessern – und kannst dich voll auf die Nutzung deiner Daten konzentrieren.
Typische Probleme klassischer Web-Scraper und wie Thunderbit sie löst
Klassische Scraper haben oft mit diesen Stolpersteinen zu kämpfen:
- Webseiten-Änderungen: Ändert sich das Layout, funktioniert der Code oft nicht mehr. Thunderbits KI passt sich automatisch an die meisten Änderungen an – ohne Nachbessern.
- Bot-Schutz: Viele Seiten blockieren automatisierte Skripte. Thunderbit läuft direkt im Browser (mit deinem Login/Session) oder in der Cloud für mehr Geschwindigkeit.
- Dynamische Inhalte: Seiten mit Endlos-Scroll oder „Mehr laden“-Buttons bringen viele Scraper ins Schwitzen. Thunderbits KI erkennt und verarbeitet solche Elemente automatisch.
- Login-geschützte Daten: Mit Thunderbits Browser-Modus kannst du alles scrapen, was du in Chrome siehst.
Kurz gesagt: Thunderbit ist darauf ausgelegt, die Herausforderungen moderner Webseiten zu meistern – damit du dich nicht mit technischen Hürden rumschlagen musst.
Effizienter arbeiten: Thunderbits smarte Web-Scraping-Features
Thunderbit liefert nicht nur Daten – sondern macht sie auch direkt nutzbar. Hier ein paar Highlights:
Automatische Seitenerkennung und Unterseiten-Scraping
Du willst hunderte Produkte über mehrere Seiten hinweg extrahieren? Thunderbit erkennt Paginierung (z. B. „Weiter“-Buttons, Endlos-Scroll) und sammelt alles auf einmal. Für Details von Unterseiten einfach „Unterseiten scrapen“ anklicken – Thunderbit besucht alle Links und holt zusätzliche Felder (z. B. Verkäuferinfos oder Produktspezifikationen).
KI-Feldvorschläge und clevere Datenstrukturierung
Thunderbits KI versteht den Kontext: Sie benennt Spalten, weist Datentypen zu (Text, Zahl, Bild, E-Mail) und kann sogar individuelle Anweisungen umsetzen (z. B. „nur Preise über 100 €“ oder „Beschreibungen ins Deutsche übersetzen“). Du kannst Prompts hinzufügen, um Daten zu kategorisieren, zusammenzufassen oder umzuwandeln.
Vorlagen und Sofort-Scraping
Für beliebte Seiten (Amazon, Zillow, Google Maps, Instagram) gibt es fertige Vorlagen – einfach auswählen, alle Felder sind schon vorkonfiguriert. Kein Setup nötig.
Zeitplanung und Automatisierung
Du brauchst täglich aktuelle Daten? Lege einen Zeitplan fest („jeden Montag um 9 Uhr“) und Thunderbit aktualisiert automatisch dein Google Sheet oder deine Datenbank – ganz ohne dein Zutun.
Cloud- oder lokales Scraping
Du hast die Wahl: Scraping direkt im Browser (ideal für eingeloggte oder interaktive Seiten) oder in der Cloud (schneller für öffentliche Daten – bis zu 50 Seiten gleichzeitig).
Mit diesen Features ist Thunderbit die Top-Wahl für Unternehmen, die Wert auf zuverlässiges, skalierbares und einfaches Web Scraping legen.
Schritt-für-Schritt: Web-Scraper mit Thunderbit erstellen
Hier die Schnellstart-Checkliste:
- Thunderbit installieren: und registrieren.
- Zielwebseite öffnen: Ggf. einloggen, Inhalte laden lassen.
- Thunderbit-Seitenleiste öffnen: Auf das Erweiterungs-Icon klicken.
- Daten beschreiben: „KI Felder vorschlagen“ anklicken oder eigenen Prompt eingeben.
- Felder prüfen: Spalten umbenennen, hinzufügen oder entfernen.
- „Scrapen“ klicken: Thunderbit erledigt den Rest.
- (Optional) Unterseiten scrapen: Für mehr Details „Unterseiten scrapen“ wählen.
- Ergebnisse prüfen: Tabelle auf Vollständigkeit kontrollieren.
- Daten exportieren: Excel, CSV, Google Sheets, Notion, Airtable oder JSON wählen.
- Speichern/Vorlage/Planen: Setup für später speichern oder regelmäßige Scrapes einrichten.
Tipps zur Fehlerbehebung:
- Fehlen Daten, formuliere deinen Prompt um oder nutze individuelle Anweisungen.
- Für dynamische Inhalte Browser-Modus nutzen.
- Bei Limit im Gratis-Tarif ggf. aufstocken.
Fazit & wichtigste Erkenntnisse
Einen Web-Scraper zu erstellen ist heute keine Sache mehr nur für Programmierer. Ob du selbst mit Python loslegst oder lieber die KI für dich arbeiten lässt – die Möglichkeiten sind so einfach wie nie.
Das solltest du dir merken:
- Web Scraping spart Zeit, erhöht die Genauigkeit und ermöglicht datenbasierte Entscheidungen.
- Python eignet sich zum Lernen und für individuelle Projekte, erfordert aber Programmierkenntnisse und Wartung.
- Thunderbit bietet eine schnelle No-Code-Lösung – einfach beschreiben, was du brauchst, und auf „Scrapen“ klicken.
- Funktionen wie automatische Paginierung, Unterseiten-Scraping und KI-Feldvorschläge machen Thunderbit zum Power-Tool für Unternehmen.
- Du kannst Thunderbit kostenlos testen und in wenigen Minuten Ergebnisse sehen.
Bereit, Schluss mit Copy-Paste zu machen und auf Automatisierung umzusteigen? und erleben, wie einfach Web Scraping sein kann. Noch mehr Tipps und Anleitungen findest du im .
Häufige Fragen (FAQ)
1. Muss ich programmieren können, um einen Web-Scraper zu erstellen?
Nein! Mit Code (z. B. Python + Beautiful Soup) hast du zwar volle Kontrolle, aber No-Code-Tools wie Thunderbit ermöglichen jedem, leistungsstarke Web-Scraper mit einfachen Anweisungen und wenigen Klicks zu erstellen.
2. Welche Daten kann ich mit Thunderbit extrahieren?
Thunderbit kann Texte, Zahlen, Bilder, E-Mails, Telefonnummern und mehr von fast jeder Webseite auslesen – auch von Listen mit mehreren Seiten und Unterseiten. Für viele bekannte Seiten gibt es zudem Vorlagen.
3. Wie geht Thunderbit mit Webseiten um, die ihr Layout ändern?
Thunderbits KI passt sich automatisch an die meisten Layout-Änderungen an. Im Gegensatz zu klassischen Scraper-Lösungen, die bei Updates oft nicht mehr funktionieren, bleibt Thunderbit dank semantischer Analyse einsatzbereit.
4. Ist Web Scraping legal und sicher?
Web Scraping ist legal, solange du öffentlich zugängliche Daten sammelst und die Nutzungsbedingungen der Seite beachtest. Thunderbit unterstützt einen verantwortungsvollen Umgang und bietet Funktionen, um die Einhaltung zu erleichtern.
5. Kann ich wiederkehrende Scrapes planen oder Exporte automatisieren?
Ja! Mit Thunderbit kannst du Scrapes beliebig planen (täglich, wöchentlich usw.) und Ergebnisse direkt nach Google Sheets, Notion, Airtable, Excel oder als CSV exportieren – ganz ohne manuelle Arbeit.
Bereit, deine Datensammlung zu automatisieren? und erleben, wie einfach Web Scraping für alle sein kann.
Mehr erfahren