

Das Web steckt voller Daten, und der Hunger danach wächst rasant — auch wenn man schnell merkt, dass schon eine einzige Marktgröße je nach Analyst um Größenordnungen schwankt, je nachdem, ob man Software, Services, Proxies oder alles zusammen rechnet. Ehrlich betrachtet hat sich Web Scraping in der unscheinbaren, aber unverzichtbaren Ecke des Data Stacks dauerhaft eingerichtet.
Ob du Business Analyst, Marketer oder einfach neugieriger Einsteiger bist: Daten von einer Website abzurufen wird zügig zur Schlüsselkompetenz. Und wenn es dir geht wie mir, willst du die endlose Copy-Paste-Routine am liebsten überspringen und gleich zum Spannenden vorstoßen — zu verwertbaren Insights, sauberen Tabellen und vielleicht ein bisschen Automatisierungs-Magie.
Genau hier kommt Python ins Spiel. Es ist das Allzweckwerkzeug der Datenwelt — einsteigerfreundlich genug für Anfänger und zugleich mächtig genug für alles: vom Scrapen einer einzelnen Seite bis zum Crawlen von Tausenden. In diesem praxisnahen Tutorial zeige ich dir die Grundlagen des Web Scrapings mit Python, wie du mit dynamischen Websites umgehst, und ich stelle dir Thunderbit vor — unseren KI-gestützten No-Code-Web-Scraper, der das Extrahieren von Daten so einfach macht, wie beim Lieferdienst zu bestellen. Egal, ob du den Code lernen oder einfach abkürzen willst — hier bist du richtig.
Was ist Web Scraping und warum Python nutzen, um Daten von einer Website abzurufen?
Daten von jeder Website mit KI scrapen Get Started Free
Web Scraping ist der automatisierte Vorgang, Informationen von Websites zu extrahieren und in ein strukturiertes Format zu bringen — etwa Tabellen, CSVs oder Datenbanken — für Analysen oder geschäftliche Zwecke (PromptCloud). Statt Daten von Hand zu kopieren und einzufügen, macht ein Scraper genau das nach, was ein Mensch tun würde — nur in Lichtgeschwindigkeit und im großen Maßstab.
Warum das so wertvoll ist? Weil in der Geschäftswelt von heute datengetriebene Entscheidungen den Ton angeben. Je größer das Unternehmen, desto mehr Entscheidungen stützen sich auf echte Zahlen statt aufs Bauchgefühl — und viele dieser Zahlen beginnen ihr Leben auf der Website von jemand anderem.
Stell dir vor, du überwachst täglich die Preise der Konkurrenz, führst Immobilienangebote zusammen oder baust dir eine eigene Lead-Liste — ganz ohne ins Schwitzen zu geraten.
Warum also Python? Die Gründe, warum es beim Web Scraping erste Wahl ist:
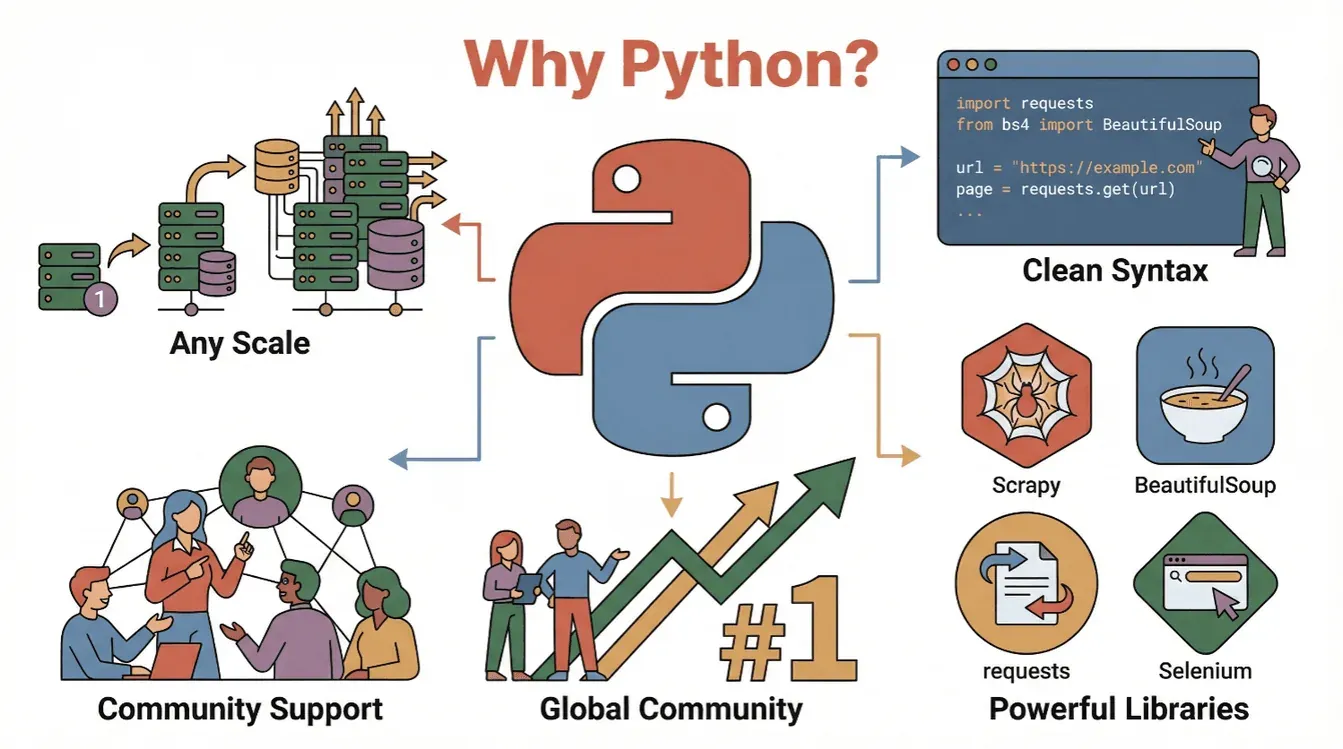
- Lesbarkeit und Einfachheit: Pythons Syntax ist klar und einsteigerfreundlich, sodass sich Scraping-Skripte mühelos schreiben und nachvollziehen lassen (PromptCloud).
- Riesiges Ökosystem: Bibliotheken wie
requests,BeautifulSoup,ScrapyundSeleniummachen Scraping, Parsing und das Automatisieren von Browser-Aktionen zum Kinderspiel. - Starke Community: Da Python verlässlich als weltweit beliebteste Programmiersprache rangiert, findest du unzählige Tutorials, Foren und Codebeispiele.
- Skalierbarkeit: Python deckt alles ab — vom schnellen Einmal-Skript bis zum Crawling-System im großen Stil.
Kurz gesagt: Python ist dein Eintrittsticket in die Welt der Webdaten, ganz gleich, ob du blutiger Anfänger oder erfahrener Analyst bist.
Einstieg: Grundlagen des Python-Web-Scraping-Tutorials
Bevor wir in den Code springen, werfen wir einen Blick auf den grundlegenden Ablauf, um mit Python Daten von einer Website abzurufen:
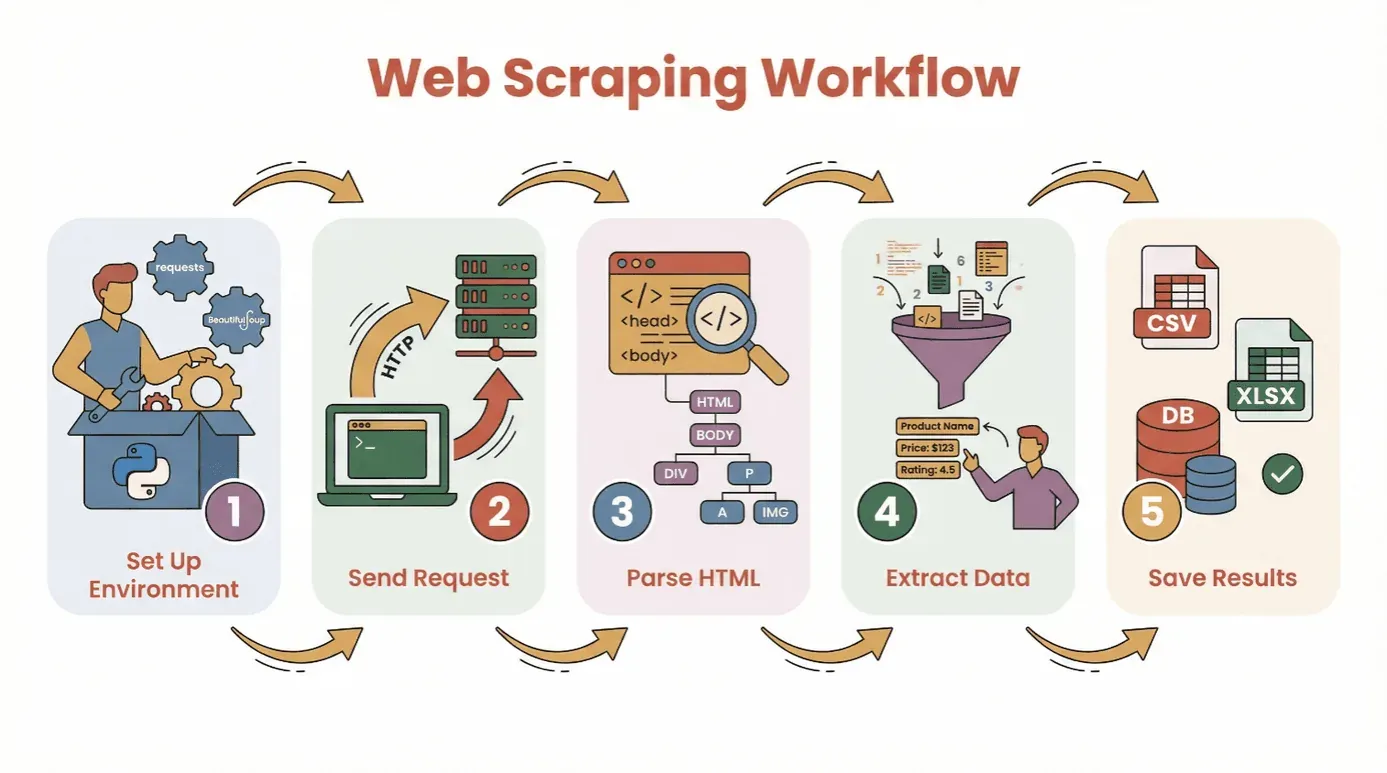
- Umgebung einrichten: Python und die nötigen Bibliotheken installieren (
requests,BeautifulSoupusw.). - Anfrage senden: Mit Python den HTML-Inhalt deiner Zielseite abrufen.
- HTML parsen: Mit einem Parser durch die Struktur der Seite navigieren.
- Daten extrahieren: Die gewünschten Informationen finden und herausziehen.
- Ergebnisse speichern: Die Daten als CSV, Excel-Datei oder in einer Datenbank für die Analyse ablegen.
Du musst kein Coding-Genie sein, um loszulegen. Wer Python installieren und ein Skript starten kann, hat schon die halbe Strecke geschafft. Kompletten Einsteigern empfehle ich eine virtuelle Umgebung oder ein Jupyter Notebook, aber ein ganz normaler Texteditor tut es auch.
Wichtige Bibliotheken:
requests— zum Abrufen von WebseitenBeautifulSoup— zum Parsen von HTMLpandas— zum Speichern und Bereinigen von Daten (optional, aber sehr zu empfehlen)
Die richtige Python-Web-Scraping-Bibliothek wählen: BeautifulSoup, Scrapy oder Selenium?
Nicht jedes Python-Scraping-Tool taugt für alles. Hier ein kompakter Überblick über die drei beliebtesten Optionen:
| Tool | Am besten geeignet für | Stärken | Nachteile |
|---|---|---|---|
| BeautifulSoup | Einfache, statische Seiten; Einsteiger | Einfach zu nutzen, minimaler Einrichtungsaufwand, gute Dokumentation | Nicht ideal für große Crawls oder dynamische Inhalte |
| Scrapy | Crawling im großen Maßstab, mehrere Seiten | Schnell, asynchron, integrierte Pipelines, behandelt Crawling und Speicherung | Steilere Lernkurve, für kleine Aufgaben überdimensioniert, führt kein JavaScript aus |
| Selenium | Dynamische/JavaScript-lastige Seiten, Automatisierung | Kann JS rendern, Nutzeraktionen simulieren, unterstützt Logins und Klicks | Langsamer, ressourcenintensiv, komplexere Einrichtung |
BeautifulSoup: Die erste Wahl für einfaches HTML-Parsen
BeautifulSoup ist wie gemacht für Einsteiger und kleinere Projekte. Damit parst du HTML und holst Elemente mit wenigen Codezeilen heraus. Ist deine Zielseite überwiegend statisch (also ohne aufwendiges JavaScript-Loading), reicht BeautifulSoup zusammen mit requests völlig aus.
Beispiel:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
print(titles)
Wann verwenden: Einmalige Scrapes, einfache Blogs, Produktseiten oder Verzeichnisse.
Scrapy: Für Crawling im großen Stil oder mit Struktur
Scrapy ist ein vollständiges Framework, um ganze Websites zu crawlen oder Tausende von Seiten abzuarbeiten. Es arbeitet asynchron (also schnell), unterstützt Pipelines zum Bereinigen und Speichern von Daten und folgt Links automatisch.
Beispiel:
import scrapy
class ProductSpider(scrapy.Spider):
name = "products"
start_urls = ["https://example.com/products"]
def parse(self, response):
for item in response.css('div.product'):
yield {
'name': item.css('h2::text').get(),
'price': item.css('span.price::text').get()
}
Wann verwenden: Große Projekte, geplante Crawls oder wenn du Tempo und Struktur brauchst.
Selenium: Dynamische und JavaScript-lastige Websites behandeln
Selenium steuert einen echten Browser (etwa Chrome oder Firefox) und kommt daher mit Seiten zurecht, die Daten per JavaScript laden, einen Login verlangen oder Klicks erfordern.
Beispiel:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com/login")
driver.find_element(By.NAME, "username").send_keys("myuser")
driver.find_element(By.NAME, "password").send_keys("mypassword")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
dashboard = driver.find_element(By.ID, "dashboard").text
print(dashboard)
driver.quit()
Wann verwenden: Social Media, Börsenseiten, Infinite Scroll oder alles, was leer wirkt, wenn du in den Quelltext schaust.
Schritt für Schritt: Wie man mit Python Daten von einer Website abruft (Anfängertutorial)
Gehen wir ein echtes Beispiel mit requests und BeautifulSoup durch. Wir scrapen eine einfache Buchlisten-Seite nach Titeln, Autoren und Preisen.
Schritt 1: Deine Python-Umgebung einrichten
Installiere zuerst die nötigen Bibliotheken:
pip install requests beautifulsoup4 pandas
Dann importierst du sie in dein Skript:
import requests
from bs4 import BeautifulSoup
import pandas as pd
Schritt 2: Eine Anfrage an die Website senden
Rufe den HTML-Inhalt ab:
url = "http://books.toscrape.com/catalogue/page-1.html"
response = requests.get(url)
if response.status_code == 200:
html = response.text
else:
print(f"Seite konnte nicht abgerufen werden: {response.status_code}")
Schritt 3: HTML-Inhalt parsen
Erstelle ein BeautifulSoup-Objekt:
soup = BeautifulSoup(html, 'html.parser')
Finde alle Buch-Container:
books = soup.find_all('article', class_='product_pod')
print(f"{len(books)} Bücher auf dieser Seite gefunden.")
Schritt 4: Die benötigten Daten extrahieren
Geh jedes Buch durch und hol die Details:
data = []
for book in books:
title = book.h3.a['title']
price = book.find('p', class_='price_color').text
data.append({"Titel": title, "Preis": price})
Schritt 5: Daten für die Analyse speichern
In ein DataFrame umwandeln und speichern:
df = pd.DataFrame(data)
df.to_csv('books.csv', index=False)
Fertig — jetzt hast du eine saubere CSV-Datei, bereit für die Analyse!
Tipps zur Fehlerbehebung:
- Bekommst du leere Ergebnisse, prüfe, ob die Daten per JavaScript geladen werden (siehe nächster Abschnitt).
- Sieh dir die HTML-Struktur immer mit den DevTools deines Browsers an.
- Fehlende Daten fängst du mit
get_text(strip=True)und bedingten Prüfungen ab.
Dynamische Inhalte meistern: Daten von JavaScript-gerenderten Websites abrufen
Moderne Websites lieben JavaScript. Manchmal stehen die gewünschten Daten gar nicht im initialen HTML — sie werden erst nach dem Seitenaufbau eingefügt. Liefert dein Scraper keine Ergebnisse, hast du es womöglich mit dynamischen Inhalten zu tun.
So gehst du damit um:
- Selenium: Simuliert einen echten Browser, wartet, bis die Inhalte geladen sind, und kann Buttons klicken oder scrollen.
- Playwright/Puppeteer: Fortgeschrittener, aber nach demselben Prinzip (Headless-Browser).
Mini-Anleitung für Selenium:
- Selenium und einen Browser-Treiber installieren (z. B. ChromeDriver).
- Explizite Wartezeiten setzen, damit die Inhalte laden können.
- Das gerenderte HTML extrahieren und bei Bedarf mit BeautifulSoup parsen.
Beispiel:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://example.com/dynamic")
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# Daten wie zuvor extrahieren
driver.quit()
Wann brauchst du Selenium?
- Wenn
requests.get()HTML ohne Daten zurückgibt, du die Daten aber im Browser siehst. - Wenn die Seite Infinite Scroll, Pop-ups oder einen Login verlangt.
Web Scraping mit KI vereinfachen: Thunderbit nutzen, um Daten von einer Website abzurufen
Thunderbit KI-Web-Scraper ausprobieren Daten von jeder Website in 2 Klicks abrufen — ganz ohne Code. Get Started Free
Seien wir ehrlich — manchmal willst du einfach nur die Daten, nicht den Code. Genau hier setzt Thunderbit an. Thunderbit ist eine KI-gestützte Chrome-Erweiterung, mit der du mit wenigen Klicks Daten von jeder Website abrufst — ganz ohne Python.
So funktioniert Thunderbit:
- Installiere die Thunderbit Chrome-Erweiterung.
- Öffne deine Zielwebsite.
- Klicke auf das Thunderbit-Symbol und dann auf „KI-Felder vorschlagen“. Thunderbits KI scannt die Seite und empfiehlt, welche Daten sich extrahieren lassen (z. B. Produktnamen, Preise, E-Mails).
- Passe die Felder bei Bedarf an und klicke dann auf „Scrapen“.
- Exportiere deine Daten direkt nach Excel, Google Sheets, Notion oder Airtable.
Warum Thunderbit überzeugt:
- Keine Programmierung nötig. Sogar meine Mutter kommt damit klar (auch wenn sie mich bei WLAN-Problemen immer noch um Hilfe bittet).
- Support für Unterseiten und Pagination. Du musst Produktdetails von mehreren Seiten scrapen? Thunderbit klickt sich durch und führt die Daten für dich zusammen.
- Anweisungen in natürlicher Sprache. Sag einfach, was du willst („alle Produkttitel und Preise extrahieren“), und die KI erledigt den Rest.
- Sofortvorlagen für beliebte Websites. Amazon, Zillow, LinkedIn und mehr — ein Klick, fertig.
- Kostenloser Datenexport. Als CSV oder Excel herunterladen oder direkt in deine Lieblings-Tools übertragen.
Thunderbit vertrauen über 100.000 Nutzer weltweit. Es gibt eine kostenlose Stufe, die du ohne Bezahlung testen kannst — die aktuellen Limits stehen auf der Preisseite, da sich die Kontingente schon ein paar Mal geändert haben. Für Business-Anwender spart das ordentlich Zeit; für Python-Leute ist es eine praktische Möglichkeit, den Aufwand grob abzuschätzen, bevor sie entscheiden, ob sich ein eigener Scraper überhaupt lohnt.
Thunderbit kostenlos ausprobieren – kein Code nötig
Nach dem Scraping: Daten mit Pandas und NumPy bereinigen und analysieren
Die Daten abzurufen, ist nur der erste Schritt. Rohe Webdaten sind oft unordentlich — Duplikate, fehlende Werte, schräge Formate. Genau hier spielen Pythons Bibliotheken pandas und NumPy ihre Stärken aus.
Häufige Bereinigungsaufgaben:
- Duplikate entfernen:
df.drop_duplicates(inplace=True) - Fehlende Werte behandeln:
df.fillna('Unknown')oderdf.dropna() - Datentypen konvertieren:
df['Price'] = df['Price'].str.replace('$','').astype(float) - Datumswerte parsen:
df['Date'] = pd.to_datetime(df['Date']) - Ausreißer herausfiltern:
df = df[df['Price'] > 0]
Einfache Analyse:
- Zusammenfassende Statistik:
df.describe() - Nach Kategorie gruppieren:
df.groupby('Category')['Price'].mean() - Schnelle Diagramme:
df['Price'].hist()oderdf.groupby('Category')['Price'].mean().plot(kind='bar')
Für anspruchsvollere Berechnungen oder schnelle Array-Operationen ist NumPy ideal. Bei den meisten Business-Anwendern deckt pandas allein aber rund 95 % des Bedarfs ab.
Ressourcen: Bist du neu bei pandas, schau dir den Leitfaden 10 Minutes to pandas an.
Best Practices und Tipps für erfolgreiches Python-Web-Scraping
Web Scraping ist mächtig, bringt aber auch Verantwortung mit sich. Hier meine Checkliste, um wie ein Profi zu scrapen — ohne geblockt oder verklagt zu werden:
- robots.txt und Nutzungsbedingungen beachten. Prüfe immer, ob die Website Scraping erlaubt (PromptCloud).
- Server nicht überlasten. Bau Pausen zwischen den Anfragen ein (
time.sleep(2)) und scrape mit menschlichem Tempo. - Realistische Header verwenden. Setz einen User-Agent-String, der einen Browser nachahmt.
- Fehler sauber abfangen. Nutze try/except-Blöcke und wiederhole fehlgeschlagene Anfragen.
- Bei Bedarf Proxies rotieren. Beim Scraping im großen Maßstab solltest du Proxy-Pools erwägen, um IP-Sperren zu umgehen.
- Ethik und Recht beachten. Scrape keine personenbezogenen Daten oder Inhalte hinter Logins ohne Erlaubnis.
- Den Prozess dokumentieren. Halte fest, was du gescrapt hast, von wo und wann.
- Offizielle APIs nutzen, wenn vorhanden. Manchmal gibt es eine bessere Lösung als HTML-Scraping.
Mehr Tipps findest du im Ultimate Web Scraping Guide.
Fazit und wichtigste Erkenntnisse
Web Scraping mit Python ist eine Superkraft für alle, die das Chaos des Webs in strukturierte, verwertbare Daten verwandeln wollen. Ob mit Code (requests, BeautifulSoup, Scrapy oder Selenium) oder mit einem No-Code-Tool wie Thunderbit — du hast die Werkzeuge in der Hand, um Daten von einer Website abzurufen und neue Erkenntnisse freizusetzen.
Merke dir:
- Fang klein an — scrape erst eine einzelne Seite, bevor du dich an große Projekte wagst.
- Wähle das passende Tool für deinen Bedarf (BeautifulSoup für die Basics, Scrapy für die Skalierung, Selenium für dynamische Seiten, Thunderbit für No-Code).
- Bereinige und analysiere deine Daten mit pandas und NumPy.
- Scrape immer verantwortungsvoll und ethisch.
Lust, es selbst auszuprobieren? Starte mit einem kleinen Projekt — vielleicht die heutigen Schlagzeilen oder eine Produktliste scrapen — und sieh, wie schnell du von der rohen Webseite zur sauberen Tabelle kommst. Und wenn du dir den Code sparen willst, lade Thunderbit herunter und überlass der KI die Schwerarbeit.
Mehr Tutorials, Tipps und Web-Scraping-Wissen findest du im Thunderbit Blog.
Mehr Web-Scraping-Tutorials lesen
FAQs
1. Was ist Web Scraping und warum ist Python dafür so beliebt?
Web Scraping ist die automatisierte Extraktion von Daten aus Websites. Python ist dafür so beliebt wegen seiner gut lesbaren Syntax, leistungsstarker Bibliotheken wie BeautifulSoup, Scrapy und Selenium sowie seiner starken Community (PromptCloud).
2. Welche Python-Bibliothek sollte ich fürs Web Scraping verwenden?
Nimm BeautifulSoup für einfache, statische Seiten, Scrapy für Crawling im großen Maßstab oder über mehrere Seiten und Selenium für dynamische oder JavaScript-lastige Websites. Je nach Bedarf hat jede Bibliothek ihre eigenen Stärken (IPRoyal).
3. Wie gehe ich mit Websites um, die Daten mit JavaScript laden?
Für von JavaScript gerenderte Inhalte nutzt du Selenium (oder Playwright), um einen Browser zu simulieren und auf das Laden der Inhalte zu warten, bevor du Daten extrahierst. Manchmal stößt du beim Prüfen des Netzwerkverkehrs auch auf einen zugrunde liegenden API-Endpunkt.
4. Was ist Thunderbit und wie vereinfacht es Web Scraping?
Thunderbit ist eine KI-gestützte Chrome-Erweiterung, mit der du Daten von jeder Website ohne Programmierung abrufst. Sie nutzt KI, um Felder vorzuschlagen, Unterseiten und Pagination zu verarbeiten und Daten direkt nach Excel, Google Sheets, Notion oder Airtable zu exportieren.
5. Wie kann ich gescrapte Daten in Python bereinigen und analysieren?
Mit pandas entfernst du Duplikate, behandelst fehlende Werte, konvertierst Datentypen und führst Analysen durch. NumPy ist stark bei numerischen Operationen. Für Visualisierungen kombinierst du pandas mit Matplotlib für schnelle Diagramme (10 Minutes to pandas).
Viel Erfolg beim Scraping — und mögen deine Daten stets sauber, strukturiert und einsatzbereit sein.
KI-Web-Scraper ausprobieren Get Started Free
Mehr erfahren
- Wie man Daten mit Python scrapt: Ein Tutorial für Einsteiger
- Umfassender Leitfaden zum Web Scraping in Python: Schritt für Schritt
- Schritt-für-Schritt Python-Scraping-Tutorial für Einsteiger
- Schritt-für-Schritt-Leitfaden: Web Scraping in Python Tutorial
- Scrapy Python Tutorial: Ein praktischer Leitfaden für Web Scraping




