Wer schon mal versucht hat, Produktpreise, Bewertungen von Mitbewerbern oder potenzielle Kundenlisten aus dem Netz zu sammeln, kennt das: Klick, Copy, Paste – immer wieder, bis der Kaffee kalt oder die Nerven blank liegen. Fakt ist: Webdaten-Extraktion ist längst ein echter Geheimtipp für Teams in Vertrieb, Operations und Marketing. Es geht nicht nur darum, Zeit zu sparen (auch wenn das ein fetter Pluspunkt ist). Es geht darum, wertvolle Insights zu bekommen, Routinejobs zu automatisieren und der Konkurrenz mit smarteren Entscheidungen immer einen Schritt voraus zu sein.
Ich hab’s selbst erlebt: Ein cleverer Webdaten-Workflow macht aus einer Woche Recherche einen Fünf-Minuten-Job. Egal, ob du gerade erst einsteigst oder deine Scraping-Skills aufs nächste Level bringen willst – dieses Tutorial zeigt dir die Basics, typische Stolperfallen und die wichtigsten Schritte – sowohl mit klassischen Methoden als auch mit KI-Tools wie . Lass uns gemeinsam das Web zu deiner persönlichen Datenquelle machen.
Was steckt hinter Webdaten-Extraktion? Die Basics auf einen Blick
Im Kern heißt Webdaten-Extraktion (oft auch Web Scraping genannt): Infos automatisiert von Webseiten abgreifen und in ein strukturiertes Format bringen – zum Beispiel in eine Tabelle oder Datenbank, damit du sie easy weiterverarbeiten kannst. Statt stundenlang zu kopieren und einzufügen, übernimmt ein Web-Scraper den Job: Er durchforstet Webseiten, findet gezielt die Daten, die du brauchst (z. B. Preise, Produktnamen, E-Mails, Bewertungen) und sortiert sie übersichtlich für dich ().
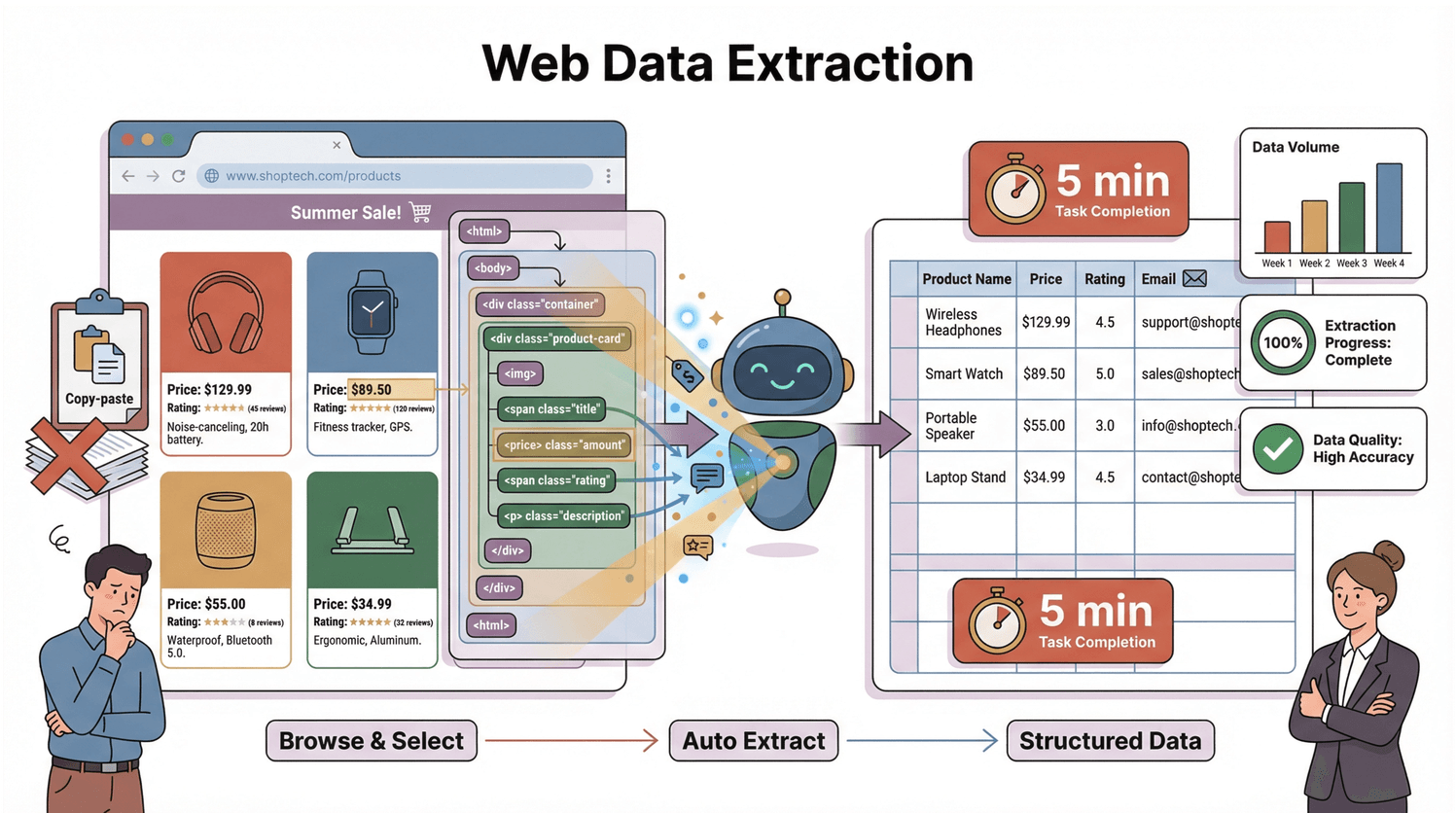
Wie läuft das ab? Jede Webseite basiert auf einer Struktur namens DOM (Document Object Model) – quasi der Bauplan, der dem Browser (und jedem Scraper) zeigt, wo welcher Inhalt steckt. Ein Scraper liest diesen Bauplan, findet die relevanten Elemente und zieht sie in Zeilen und Spalten. Stell dir vor, du hast einen super organisierten Assistenten, der nie müde wird und sich nicht von Katzenvideos ablenken lässt.
Warum Webdaten-Extraktion für Vertrieb und Operations so ein Gamechanger ist
Klartext: Webdaten-Extraktion ist kein Nerd-Hobby, sondern ein echter Business-Booster. Deshalb setzen immer mehr Teams aus Vertrieb, Operations und Marketing darauf:
| Anwendungsfall | Business-Vorteil | Konkreter Nutzen |
|---|---|---|
| Lead-Generierung | Pipeline schnell mit qualifizierten Kontakten füllen | 70% ROI in 6 Monaten; 40% mehr hochwertige Leads; hunderte Stunden eingespart (Grepsr) |
| Preisüberwachung | Dynamische Preise, Margen schützen | 65% ROI in 6 Monaten; 12% mehr Umsatz; 75% weniger manuelle Arbeit (Grepsr) |
| Wettbewerbsanalyse | Aktuelle Marktinformationen | 55% ROI bei Airlines; 68% ROI bei E-Commerce-Trends (Grepsr) |
| Betriebsüberwachung | Engpässe vermeiden, Lieferketten optimieren | 62% ROI für globale Händler; keine überraschenden Lagerengpässe mehr (Grepsr) |
Und es geht um mehr als nur ROI. Automatisierte Datensammlung nimmt deinem Team die Fleißarbeit ab, damit mehr Zeit für Strategie bleibt. Manche Firmen haben ihre Kosten für Datenerhebung um 40% gedrückt (), und der globale Markt für Web Scraping soll von 5 Milliarden Dollar (2023) auf über 140 Milliarden bis 2032 wachsen (). Das ist eine Menge Daten – und eine riesige Chance.
Wie läuft Webdaten-Extraktion ab? Vom DOM zur Datentabelle
Schauen wir mal, was im Hintergrund passiert (ohne Technik-Kauderwelsch):
- Anfrage: Der Scraper schickt eine Anfrage an die Webseite und lädt den HTML-Code.
- Parsen: Er liest das DOM – die Baumstruktur, die alle Elemente der Seite organisiert.
- Extrahieren: Er findet die gewünschten Daten (z. B. Preise, Namen, E-Mails) und packt sie in eine strukturierte Tabelle (CSV, Excel, Google Sheets usw.) ().
Das DOM verstehen: Das Fundament der Webdaten-Extraktion
Das DOM ist wie der Stammbaum einer Webseite. Ganz oben steht das Dokument, das sich in <html>, dann <head> und <body> verzweigt – und weiter bis zu jedem <div>, <span> und Text (). Jedes Element in diesem Baum kann gezielt angesprochen werden.
Um zum Beispiel einen Produktpreis zu erfassen, sucht der Scraper nach einem <span class="price"> innerhalb eines <div> im <body>. Es ist, als würdest du deinem Assistenten sagen: „Geh in die Küche, öffne den Kühlschrank, finde die Milch.“ Das DOM ist die Karte, der Scraper der Entdecker.
Aber: Viele moderne Webseiten laden Inhalte erst per JavaScript nach. Die Daten sind oft nicht im ursprünglichen HTML, sondern tauchen erst auf, wenn die Seite komplett geladen ist. Dein Scraper muss also das gerenderte DOM sehen, nicht nur den Rohcode (). Hier scheitern viele klassische Tools – moderne Lösungen meistern das.
Typische Stolperfallen bei der Webdaten-Extraktion (und wie du sie clever umgehst)
Web Scraping läuft nicht immer reibungslos. Hier die häufigsten Probleme – und wie du sie löst:
- Dynamische Inhalte & Endlos-Scroll: Viele Seiten laden Daten erst beim Scrollen oder per Klick nach. Holt dein Scraper nur das Anfangs-HTML, fehlt dir vieles. Lösung: Nutze Tools, die JavaScript ausführen oder Scrollen simulieren (Thunderbit macht das automatisch) ().
- Paginierung & Unterseiten: Daten sind oft auf mehrere Seiten oder Detailseiten verteilt. Dein Tool sollte „Weiter“-Buttons folgen und Unterseiten öffnen können. Thunderbits „Subpages scrapen“-Funktion ist hier Gold wert ().
- Änderungen an der Webseitenstruktur: Schon kleine Layout-Änderungen können klassische Scraper aus dem Tritt bringen. KI-Tools wie Thunderbit passen sich automatisch an, sodass du nicht ständig nachbessern musst ().
- Anti-Scraping-Maßnahmen: CAPTCHAs, IP-Sperren und Zugriffsbeschränkungen können dich ausbremsen. Scrape immer mit Bedacht (langsam, mit zufälligen Abständen), nutze browserbasierte Tools und halte dich an die Nutzungsbedingungen ().
- Unstrukturierte oder inkonsistente Daten: Nicht jede Seite ist sauber aufgebaut. Manchmal helfen KI-Prompts oder eigene Regeln, um die richtigen Infos zu bekommen (Thunderbits Field AI Prompt ist dafür ideal).
Dynamische Seiten und JavaScript-Inhalte meistern
Manche Seiten zeigen Daten erst nach Scrollen oder Klicks – sie werden per JavaScript nachgeladen. Klassische Scraper übersehen das, aber Browser-Erweiterungen wie Thunderbit erfassen alles, was du auch siehst – selbst bei Endlos-Scroll oder Pop-ups ().
Anti-Scraping-Schutz umgehen
Wenn du blockiert wirst oder CAPTCHAs siehst, verlangsame deine Anfragen, wechsle die IP und nutze browserbasierte Tools, die wie echte Nutzer wirken. Und prüfe immer die Nutzungsbedingungen und robots.txt ().
Webdaten-Extraktion im Vergleich: Thunderbit vs. klassische Lösungen
Es gibt viele Wege, Daten zu extrahieren – manche sind mühsamer als andere. Hier der Überblick:
| Lösung | Einrichtungszeit | Erforderliche Kenntnisse | Wartung | Funktionen & Exportmöglichkeiten |
|---|---|---|---|---|
| Manuelles Kopieren & Einfügen | Keine | Keine | Ständig manuell | Keine Automatisierung; fehleranfällig |
| Eigener Code (Python etc.) | Stunden bis Tage | Programmieren + HTML | Hoch | Flexibel; Export überallhin; hohe Lernkurve |
| Klassische No-Code-Tools | ~1 Stunde/Seite | Etwas Technikverständnis | Mittel | Visuelle Einrichtung; Paginierung; mittlere Lernkurve |
| Thunderbit (KI No-Code) | Minuten | Keine (normale Sprache) | Gering (KI passt an) | KI-Felderkennung; Unterseiten; Zeitplanung; Export zu Sheets/Excel/Notion |
Thunderbit punktet besonders bei Business-Anwendern, weil es auf maximale Einfachheit ausgelegt ist. Du brauchst keine Programmierkenntnisse – beschreibe einfach, was du willst, und die KI erledigt den Rest ().
Warum Thunderbit für Unternehmen besonders praktisch ist
- Zwei-Klick-Bedienung: „KI-Felder vorschlagen“ und dann „Scrapen“ – fertig.
- KI-Felderkennung: Die KI liest die Seite und schlägt passende Spalten vor – kein Rätselraten.
- No-Code, natürliche Sprache: Einfach eintippen, was du brauchst („Alle Produktnamen und Preise erfassen“), Thunderbit erledigt den Rest.
- Automatisches Scrapen von Unterseiten & Paginierung: Mit einem Klick alle Seiten und Detail-Links erfassen.
- Schneller Export: Daten direkt nach Excel, Google Sheets, Notion oder Airtable senden – ohne Zusatzkosten.
- Cloud- oder Browser-Modus: Im Cloud-Modus für Geschwindigkeit, im Browser für eingeloggte Seiten.
Thunderbit ist für die Praxis gemacht – wo Webseiten sich ändern, Daten chaotisch sind und Business-Anwender Ergebnisse brauchen, keine Kopfschmerzen.
Schritt-für-Schritt-Anleitung: Webdaten-Extraktion mit Thunderbit
Bereit, loszulegen (ohne dich schmutzig zu machen)? So extrahierst du Daten von jeder Webseite mit :
Schritt 1: Thunderbit Chrome-Erweiterung installieren
Geh in den und füge Thunderbit hinzu. Registriere dich kostenlos – mit dem Gratis-Tarif kannst du einige Seiten testen.
Schritt 2: Ziel-Webseite öffnen
Ruf die Seite auf, die du scrapen willst. Logg dich ggf. ein und sorg dafür, dass alle gewünschten Daten sichtbar sind (scrollen, klicken etc.).
Schritt 3: Thunderbit öffnen und Datenwunsch beschreiben
Klick auf das Thunderbit-Icon. Du kannst:
- „KI-Felder vorschlagen“ anklicken, damit die KI passende Spalten erkennt.
- Oder einen eigenen Prompt eingeben: „Produktname, Preis und Bewertungen extrahieren.“
Thunderbit zeigt dir eine Vorschau der gefundenen Felder. Du kannst Spalten umbenennen, löschen oder hinzufügen.
Schritt 4: Scraping starten
Klick auf „Scrapen“. Thunderbit extrahiert die Daten in eine Tabelle. Gibt es mehrere Seiten oder Unterseiten, fragt das Tool nach – einfach bestätigen.
Schritt 5: Prüfen und exportieren
Check die Ergebnisse. Fehlt was, formuliere deinen Prompt um oder schau, ob alle Inhalte geladen sind. Zufrieden? Dann auf „Exportieren“ klicken – als CSV runterladen oder direkt nach Google Sheets, Excel, Notion oder Airtable schicken.
Praxisbeispiel: Amazon-Produktbewertungen mit Thunderbit extrahieren
Du willst Amazon-Bewertungen eines Konkurrenzprodukts analysieren? So easy geht’s mit Thunderbit:
- Amazon-Produktseite aufrufen und auf „Alle Bewertungen anzeigen“ klicken.
- Thunderbit aktivieren. Falls die Amazon Reviews Scraper-Vorlage erscheint, nutze sie – sie ist für alle relevanten Felder vorkonfiguriert ().
- „Scrapen“ klicken. Thunderbit sammelt Namen, Bewertungen, Texte, Daten und mehr – seitenübergreifend.
- Exportieren. Jetzt hast du eine Tabelle für Sentiment-Analysen, Wettbewerbsvergleiche oder schnelle Reports.
Du willst anpassen? Einfach einen Prompt wie „Reviewer-Name, Sternebewertung, Datum und Bewertungstext extrahieren“ eingeben. Thunderbits KI erledigt den Rest – selbst wenn Amazon das Layout ändert.
Profi-Tipps: Webdaten-Extraktion anpassen und automatisieren
Wenn du die Basics drauf hast, kannst du mit Thunderbits erweiterten Features noch mehr rausholen:
- Field AI Prompts: Für jedes Feld eigene Anweisungen geben (z. B. „Nur Bewertungen mit 1 oder 2 Sternen extrahieren“ oder „Bewertungstexte ins Deutsche übersetzen“).
- Geplanter Scraper: Wiederkehrende Jobs (täglich, wöchentlich etc.) einrichten, um Daten aktuell zu halten – perfekt für Preisüberwachung oder Lead-Generierung ().
- KI-Autofill: Formulare automatisch ausfüllen oder mehrstufige Workflows automatisieren (z. B. für Suchanfragen oder Logins).
- Cloud-Scraping: Große Jobs in der Cloud ausführen – für Tempo und Zuverlässigkeit.
- Sofort-Vorlagen: Vorgefertigte Templates für beliebte Seiten wie Amazon, Zillow, Yelp, LinkedIn und mehr nutzen ().
Thunderbit lässt sich auch easy in Team-Workflows einbinden – Daten nach Google Sheets exportieren, Ergebnisse teilen oder mit anderen Tools verbinden.
Die Zukunft der Webdaten-Extraktion: KI-Trends und Business-Chancen
KI krempelt die Webdaten-Extraktion komplett um:
- Widerstandsfähigkeit: KI-Scraper passen sich automatisch an Webseitenänderungen an – weniger Wartung, weniger Ausfälle ().
- Agentives Scraping: Bots können wie Menschen klicken, navigieren und interagieren – neue Datenquellen werden erschlossen.
- Kontinuierliche Datenströme: Unternehmen setzen immer mehr auf Echtzeit- und Dauer-Scraping statt Einmal-Extraktion.
- Zugänglichkeit: No-Code-Tools mit natürlicher Sprache wie Thunderbit machen Webdaten-Extraktion für alle zugänglich – nicht nur für Entwickler.
- Sofortige Insights: Die nächste Generation kombiniert Scraping mit KI-Analyse – z. B. Bewertungen extrahieren und direkt die wichtigsten Kritikpunkte zusammenfassen.
Fazit: KI-gestützte Webdaten-Extraktion wird so unverzichtbar wie Tabellenkalkulationen oder CRM-Systeme. Wer sie beherrscht, ist der Konkurrenz immer einen Schritt voraus – während andere noch kopieren und einfügen.
Fazit & wichtigste Learnings
- Webdaten-Extraktion macht das Internet zur eigenen Datenbank – Leads, Preise, Bewertungen und mehr automatisiert sammeln.
- Das DOM ist der Bauplan jeder Webseite; wer ihn versteht, kann effektiv scrapen.
- Typische Stolperfallen (dynamische Inhalte, Anti-Bot-Schutz, chaotische Daten) lassen sich mit den richtigen Tools und etwas Know-how vermeiden.
- Thunderbit macht Webdaten-Extraktion für alle zugänglich: Zwei Klicks, KI-Felderkennung, Unterseiten-Scraping und direkter Export zu deinen Lieblingstools.
- KI ist die Zukunft – schneller, smarter und zuverlässiger Scrapen für Business-Anwender.
Neugierig geworden? und erleben, wie einfach Webdaten-Extraktion sein kann. Für mehr Tipps, Deep Dives und Praxisbeispiele schau im vorbei.
Häufige Fragen (FAQ)
1. Was ist Webdaten-Extraktion und wie funktioniert sie?
Webdaten-Extraktion (Web Scraping) ist das automatisierte Sammeln von Infos aus Webseiten, die in strukturierte Daten wie Tabellen umgewandelt werden. Das läuft so: Das DOM (Document Object Model) der Seite wird ausgelesen, die gewünschten Daten werden erkannt und für die Analyse exportiert ().
2. Was sind die größten Herausforderungen bei der Webdaten-Extraktion?
Die größten Hürden sind dynamische Inhalte (per JavaScript geladene Daten), Anti-Scraping-Maßnahmen (CAPTCHAs, IP-Sperren) und unstrukturierte Datenlayouts. Moderne Tools wie Thunderbit nutzen KI und browserbasiertes Scraping, um diese Probleme zu lösen ().
3. Was unterscheidet Thunderbit von anderen Web-Scraping-Tools?
Thunderbit ist ein KI-gestützter, No-Code Web-Scraper speziell für Business-Anwender. Es bietet Zwei-Klick-Setup („KI-Felder vorschlagen“, dann „Scrapen“), Prompts in natürlicher Sprache, Unterseiten-Scraping und sofortigen Export zu Excel, Google Sheets, Notion und Airtable ().
4. Kann ich mit Thunderbit auch dynamische oder mehrseitige Webseiten scrapen?
Ja, Thunderbit erkennt dynamische Inhalte (wie Endlos-Scroll oder JavaScript-Daten) automatisch und kann mit einem Klick mehrere Seiten oder Unterseiten erfassen ().
5. Ist Webdaten-Extraktion legal?
Das Scrapen öffentlicher Daten ist in der Regel legal, besonders für Business Intelligence. Prüfe aber immer die Nutzungsbedingungen und robots.txt der Seite. Verzichte auf das Scrapen persönlicher oder privater Daten und geh verantwortungsvoll vor – überlaste keine Webseiten und halte dich an die Regeln ().
Viel Erfolg beim Scrapen – auf dass deine Tabellen immer voll, deine Daten aktuell und das Copy & Paste bald Geschichte sind.
Mehr erfahren