
Die E-Commerce-Welt im Nahen Osten boomt, und steht mittendrin. Mit Millionen von Produkten, unzähligen Verkäufern und einer täglich wachsenden Nutzerbasis ist Noon zu einer echten Goldgrube für alle geworden, die im Einzelhandel, im Vertrieb oder in der Marktforschung mit Daten arbeiten. Doch es gibt einen Haken: Noons Produktdaten manuell zu sammeln und zu ordnen, macht ungefähr so viel Spaß wie IKEA-Möbel ohne Anleitung aufzubauen – mühsam, verwirrend und mit hoher Wahrscheinlichkeit am Ende mit ein paar fehlenden Teilen.
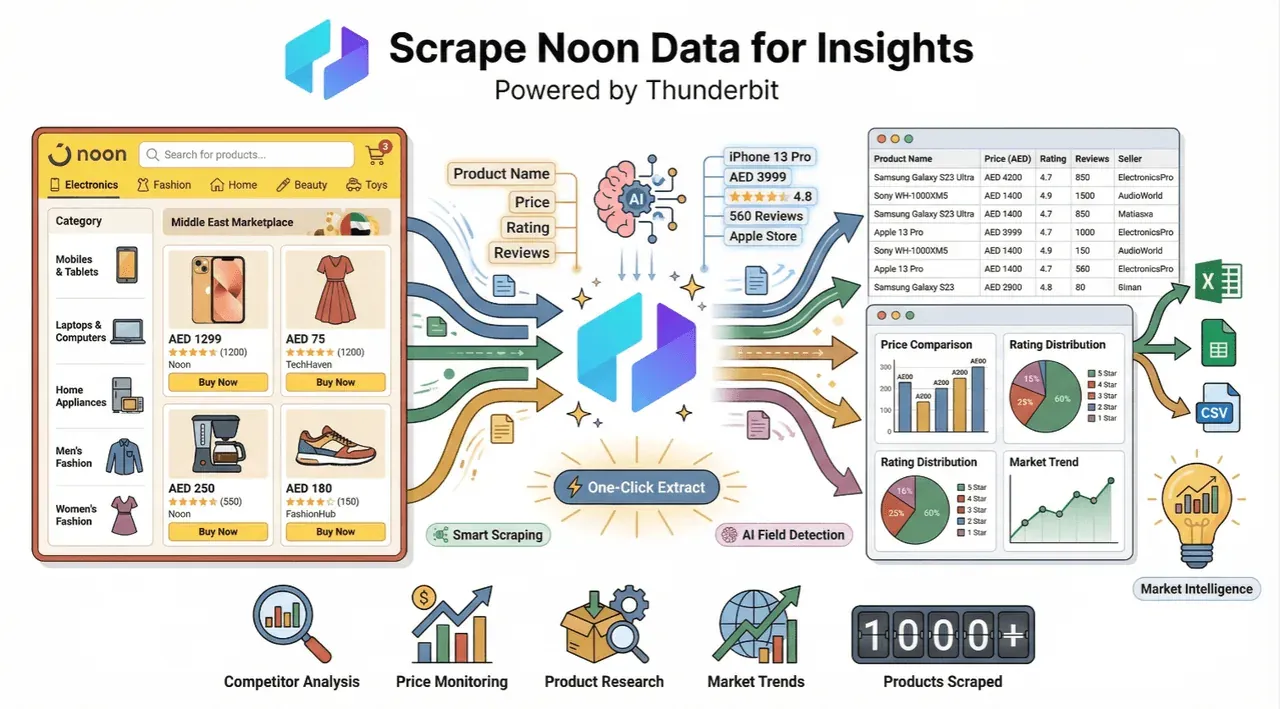 Ich habe selbst erlebt, wie viel Zeit Teams damit verlieren, Preise, Produktnamen und Lagerbestände von Noon per Copy-and-Paste zusammenzutragen. Deshalb freue ich mich, Ihnen zu zeigen, wie – unser KI-gestützter Web-Scraper – diesen Marathon in einen Sprint verwandeln kann. Ob Sie Wettbewerber beobachten, Bestände im Blick behalten oder einfach Ihre Preisstrategie schärfen wollen: Die Automatisierung der Noon-Datenextraktion ist ein echter Gamechanger für Ihren Workflow. Schauen wir uns Schritt für Schritt an, wie das funktioniert – und warum Thunderbit das Tool ist, das Sie an Ihrer Seite haben wollen.
Ich habe selbst erlebt, wie viel Zeit Teams damit verlieren, Preise, Produktnamen und Lagerbestände von Noon per Copy-and-Paste zusammenzutragen. Deshalb freue ich mich, Ihnen zu zeigen, wie – unser KI-gestützter Web-Scraper – diesen Marathon in einen Sprint verwandeln kann. Ob Sie Wettbewerber beobachten, Bestände im Blick behalten oder einfach Ihre Preisstrategie schärfen wollen: Die Automatisierung der Noon-Datenextraktion ist ein echter Gamechanger für Ihren Workflow. Schauen wir uns Schritt für Schritt an, wie das funktioniert – und warum Thunderbit das Tool ist, das Sie an Ihrer Seite haben wollen.
Lernen Sie Noon kennen: Die Grundlage für erfolgreiches Data Scraping
Bevor Sie mit dem Scraping loslegen, lohnt sich ein Blick auf die Struktur von Noon. Noon ist nicht einfach nur ein riesiger Online-Shop; es ist ein Labyrinth aus Kategorien, Unterkategorien, Produktlisten und Detailseiten. Wenn Sie saubere, vollständige Daten wollen, müssen Sie die Karte dieses Geländes kennen.
- Kategorien und Navigation: Noons Hauptnavigation teilt Produkte in große Kategorien auf – Elektronik, Mode, Wohnen, Beauty und mehr. Jede Kategorie verzweigt sich in Unterkategorien und Filter wie Marke, Preis, Bewertung und vieles mehr.
- Produktlisten: Kategorien- und Suchergebnisseiten zeigen Dutzende, manchmal Hunderte von Produkten, jeweils mit Thumbnail, Preis und Link zur Produktdetailseite.
- Pagination: Listen erstrecken sich über mehrere Seiten, entweder mit klassischen „Weiter“-Buttons oder über unendliches Scrollen. Eine übersehene Seite bedeutet verpasste wertvolle SKUs.
- Produktdetailseiten: Hier steckt das eigentliche Gold – ausführliche Spezifikationen, Beschreibungen, Bilder, Verkäuferinformationen sowie aktuelle Bestands- oder Preisänderungen.
Diese Struktur zu verstehen, ist entscheidend. Wenn Sie nur die erste Seite einer Kategorie scrapen, bleibt der Großteil der Produkte liegen. Wenn Sie Unterseiten ignorieren, verpassen Sie wichtige Produktdetails. Deshalb empfehle ich beim Aufbau einer Scraping-Strategie immer:
- den Navigationsfluss zu skizzieren
- zu identifizieren, wo Ihre Ziel-Daten liegen (Listen vs. Detailseiten)
- zu notieren, wie die Pagination in den gewählten Kategorien funktioniert
So stellen Sie sicher, dass Ihre Daten vollständig und präzise sind – keine Überraschungen mehr à la „Wo ist dieses Produkt geblieben?“
Warum Noon-Daten scrapen? Geschäftswert erschließen
Warum also den Aufwand betreiben, Noon zu scrapen? Weil strukturierte Daten die Geheimwaffe für E-Commerce-Teams sind, die der Konkurrenz einen Schritt voraus sein wollen. Hier sind einige der häufigsten Anwendungsfälle, die ich sehe:
| Anwendungsfall | Beschreibung |
|---|---|
| Preisüberwachung | Beobachten Sie die Preise der Wettbewerber, um Ihre eigenen anzupassen und wettbewerbsfähig zu bleiben (Octoparse). |
| Sortimentsanalyse | Sehen Sie, welche Produkte im Trend liegen oder in Ihrem Katalog fehlen. |
| Bestandsverfolgung | Überwachen Sie Lagerbestände, um Engpässe oder Überbestände zu erkennen (Octoparse). |
| Wettbewerbs-Benchmarking | Vergleichen Sie Ihre Angebote, Bewertungen und Rezensionen mit denen der Konkurrenz (Actowiz). |
| Trend-Erkennung | Identifizieren Sie schnell drehende Produkte oder Kategorien, um Marketing- und Einkaufsentscheidungen zu steuern (Octoparse). |
| Bessere Entscheidungen | Nutzen Sie Echtzeitdaten für intelligentere Aktionen, Bestandsplanung und Vertriebsprognosen (Octoparse). |
In einem hart umkämpften Markt wie den VAE, in dem Noon und Amazon sich bei Preisen und Sortiment ein Kopf-an-Kopf-Rennen liefern, sind aktuelle Daten nicht nur nett zu haben – sie sind überlebenswichtig ().
Noon-Data-Scraping-Tools im Vergleich: Warum Thunderbit heraussticht
Es gibt viele Wege, Daten aus Noon zu holen, aber nicht alle sind gleich gut. So schneiden die wichtigsten Ansätze ab:
| Methode | Vorteile | Nachteile |
|---|---|---|
| Manuelles Kopieren und Einfügen | Kein Setup, jeder kann es machen | Langsam, fehleranfällig, in großem Maßstab unmöglich |
| Code-basierte Scraper | Flexibel, anpassbar | Erfordert Programmierung, bricht bei Änderungen |
| Browser-Erweiterungen | Einfacher, teils Unterstützung für Pagination | Oft vorlagenbasiert, durch Layout begrenzt |
| KI-gestützte Tools | Schnell, passt sich Änderungen an, kein Coding | Neuere Technologie, aber rasant besser werdend |
vereint das Beste aus allen Welten: so einfach wie eine Browser-Erweiterung, aber angetrieben von KI, die Noons komplexe Layouts versteht, Pagination verarbeitet und sogar vorschlägt, welche Felder extrahiert werden sollten. Deshalb halte ich Thunderbit für die beste Wahl, wenn es darum geht, Noon zu scrapen:
| Funktion | Traditionelle Scraper | Thunderbit (KI-Web-Scraper) |
|---|---|---|
| No-Code-Setup | Manchmal | Immer (2-Klick-Setup) |
| Pagination / unendliches Scrollen | Manchmal | Ja (KI passt sich an, kein manuelles Setup) |
| KI-Feldvorschläge | Nein | Ja („KI-Felder vorschlagen“-Button) |
| Unterseiten-Scraping (Detailseiten) | Manuelle Skripte | Ja (1 Klick, KI-gestützt) |
| Kostenlose Vorlagen für Noon | Selten | Ja (Noon Scraper-Vorlage) |
| Datenexport (Excel, Sheets usw.) | Manchmal | Ja (kostenlos, sofort) |
| Wartungsaufwand | Hoch | Niedrig (KI passt sich an Website-Änderungen an) |
| Datenkennzeichnung/-übersetzung | Nein | Ja (integrierte KI-Funktionen) |
Thunderbit ist für Business-Anwender gebaut, nicht nur für Entwickler. Sie müssen kein XPath, keine CSS-Selektoren und kein Python-Debugging beherrschen. Einfach zeigen, klicken und die Daten erhalten.
Schritt für Schritt: So scrapen Sie Noon-Daten mit Thunderbit
Bereit, loszulegen? So holen Sie Noon-Daten in wenigen Minuten in Ihre Tabelle – ganz ohne technische Vorkenntnisse.
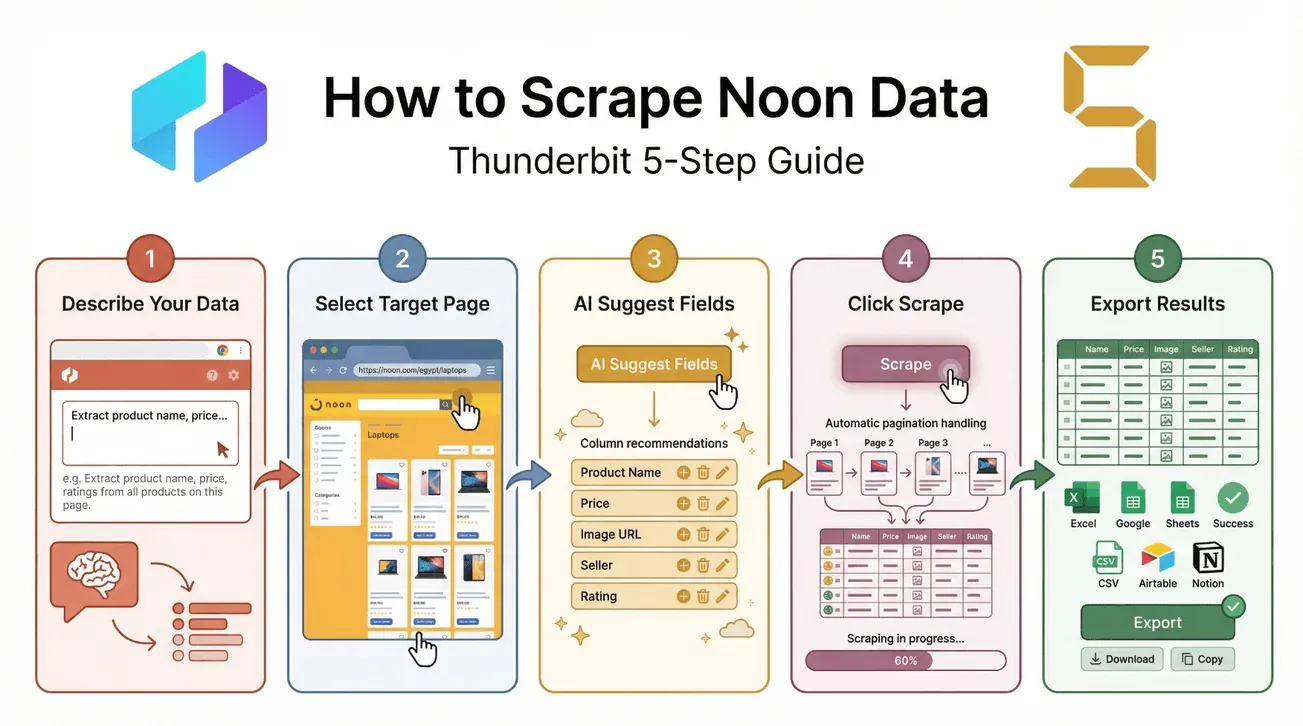
1. Beschreiben Sie Ihren Datenbedarf in natürlicher Sprache
Öffnen Sie die . Geben Sie im Feld „Beschreiben Sie Ihre Daten“ einfach ein, was Sie möchten, zum Beispiel:
„Produktname, Preis, Bewertung und Verkäufer aus der Elektronik-Kategorie von Noon extrahieren.“
Die KI von Thunderbit nutzt das als Ausgangspunkt für Feldvorschläge.
2. Wählen Sie die Zielseite bei Noon aus
Navigieren Sie zur Noon-Kategorie oder zur Suchergebnisseite, die Sie scrapen möchten. Stellen Sie sicher, dass alle benötigten Produkte sichtbar sind (oder paginiert werden können).
3. Verwenden Sie „KI-Felder vorschlagen“ für automatische Spaltenempfehlungen
Klicken Sie auf den Button „KI-Felder vorschlagen“. Thunderbit scannt die Seite und schlägt Spalten vor – etwa Produktname, Preis, Bild-URL, Verkäufer und mehr. Sie können Spalten bei Bedarf hinzufügen, entfernen oder umbenennen.
4. Klicken Sie auf „Scrapen“, um Daten zu extrahieren
Drücken Sie den Button „Scrapen“. Thunderbit wird:
- die Pagination automatisch handhaben (auch bei unendlichem Scrollen)
- jeden Produkteintrag besuchen und, wenn gewünscht, jede Produktdetailseite für mehr Informationen
- die Daten in einer sauberen Tabelle strukturieren
5. Exportieren Sie die Ergebnisse nach Excel, Google Sheets oder in andere Formate
Sobald der Scrape abgeschlossen ist, exportieren Sie Ihre Daten mit einem Klick:
- als CSV oder Excel herunterladen
- direkt nach Google Sheets, Airtable oder Notion exportieren
- in die Zwischenablage kopieren, um sie schnell einzufügen
Sie können sogar die von Thunderbit für ein vorgefertigtes Setup nutzen – einfach anwenden und loslegen.
Visuelle Anleitung: Screenshots und Tipps
- Screenshots: Eine visuelle Schritt-für-Schritt-Anleitung finden Sie in der von Thunderbit oder auf der .
- Fehlerbehebung:
- Wenn Noon Sie zum Einloggen auffordert, stellen Sie sicher, dass Sie vor dem Scrapen eingeloggt sind.
- Bei unendlichem Scrollen lassen Sie die Seite alle Produkte laden, bevor Sie starten, oder lassen Sie Thunderbit das Scrollen übernehmen.
- Wenn etwas hakt, wechseln Sie zwischen Browser- und Cloud-Scraping-Modus.
Mehr Insights gewinnen: Wie Thunderbits KI die Noon-Datenanalyse verbessert
Scraping ist nur der erste Schritt. Thunderbits KI-Funktionen verwandeln Ihre Noon-Daten von „roh“ in „einsatzbereit“:
- Kennzeichnung: Produkte automatisch nach Kategorie, Marke oder benutzerdefinierten Regeln markieren.
- Formatierung: Preise, Daten und Zahlen für die Analyse standardisieren.
- Übersetzung: Produktbeschreibungen oder Rezensionen sofort in Ihre bevorzugte Sprache übersetzen.
- Kategorisierung: Produkte nach Typ, Preisspanne oder Verkäufer gruppieren, um sie zu segmentieren.
Diese integrierten KI-Tools sorgen dafür, dass Sie von einem chaotischen Datenhaufen zu einem sauberen, verwertbaren Datensatz gelangen – ohne zusätzliche Software oder manuelle Bereinigung.
Praxisbeispiele: Von Rohdaten zu Geschäftserkenntnissen
So setzen Teams mit Thunderbit angereicherte Noon-Daten ein:
- Vertrieb: Unterbewertete Produkte oder Topseller identifizieren, um Preise oder Bestände anzupassen.
- Marketing: Trend-Kategorien für gezielte Kampagnen erkennen.
- Operations: Out-of-Stock-Situationen oder Preisänderungen überwachen, um Lieferkettenentscheidungen zu optimieren.
- Analytics: Strukturierte Noon-Daten in BI-Dashboards einspeisen, um den Markt in Echtzeit zu verfolgen.
Ein Nutzer erzählte mir, dass er seine wöchentliche Preisüberwachung mit Thunderbits KI-gestütztem Scraping und Kennzeichnung von 8 Stunden auf 30 Minuten reduziert hat. Genau diese Art von ROI macht den Morgenkaffee noch besser.
Compliance sicherstellen: Noon-Daten verantwortungsvoll scrapen
Sprechen wir über den Elefanten im Raum: Compliance. Daten von Noon (oder jeder anderen Website) zu scrapen bringt Verantwortung mit sich.
- Noons Bedingungen prüfen: Noons verbieten Scraping und automatisierten Zugriff ohne Genehmigung ausdrücklich. Prüfen Sie die aktuelle Version der Richtlinien, bevor Sie beginnen, und sprechen Sie bei allem, was über private Recherche hinausgeht, zuerst mit der Rechtsabteilung.
- robots.txt respektieren: Wenn Noons robots.txt das Scrapen bestimmter Seiten verbietet, halten Sie sich daran.
- Anfragen drosseln: Überlasten Sie Noons Server nicht – Thunderbit gibt Ihnen die Kontrolle über die Scraping-Geschwindigkeit.
- Daten ethisch nutzen: Verwenden Sie gescrapte Daten nur für legitime geschäftliche Zwecke und vermeiden Sie die Erfassung personenbezogener Informationen, sofern keine Einwilligung vorliegt.
Praktische Compliance-Checkliste
- [ ] Noons Nutzungsbedingungen prüfen
- [ ] robots.txt auf verbotene Pfade kontrollieren
- [ ] Scraping-Frequenz und -Menge begrenzen
- [ ] Keine sensiblen personenbezogenen Daten erfassen
- [ ] Datenquellen bei Bedarf angeben
- [ ] Über lokale Datenschutzgesetze auf dem Laufenden bleiben
Ein guter Web-Bürger zu sein ist nicht nur höflich – es bewahrt Ihr Unternehmen auch vor Ärger ().
Typische Herausforderungen beim Scrapen von Noon meistern
Noon wirft wie viele moderne E-Commerce-Seiten Scrapern einige Hindernisse in den Weg:
- Dynamische Inhalte: Produktlisten werden möglicherweise per JavaScript oder unendlichem Scrollen geladen. Der Browser-Modus von Thunderbit kann solche Fälle bewältigen ().
- Anti-Bot-Maßnahmen: Noon nutzt Rate-Limiting und CAPTCHAs, um automatisierten Traffic herauszufiltern. Thunderbit erlaubt Ihnen, zwischen Browser-Modus (läuft in Ihrem eingeloggten Tab, sieht aus wie normales Browsing) und Cloud-Modus (separate IPs, besser für große Mengen) zu wechseln, und Sie können die Anfragegeschwindigkeit drosseln, wenn eine Kategorieseite plötzlich leere Ergebnisse liefert. Das garantiert zwar nicht, dass Sie bei einem Lauf mit hohem Volumen nicht geblockt werden – falls doch, verlangsamen Sie den Prozess oder teilen Sie den Job auf.
- Komplexe Pagination: Ob „Weiter“-Buttons oder endloses Scrollen – Thunderbit kann dem Flow folgen und jedes Produkt erfassen ().
- Wechselnde Layouts: Noon aktualisiert die Website regelmäßig. Thunderbits KI liest die Seite jedes Mal neu ein, sodass Sie nicht an kaputten Vorlagen herumdoktern müssen.
Wenn Probleme auftreten, versuchen Sie:
- zwischen Browser- und Cloud-Scraping zu wechseln
- die Scraping-Geschwindigkeit anzupassen
- Thunderbits Funktion „Benutzerdefinierte Anweisung“ zu nutzen, um schwierige Felder klarer zu definieren
Ihre Noon-Daten exportieren und nutzen: Nächste Schritte
Sobald Sie Ihre Noon-Daten gescrapt und angereichert haben, ist es Zeit, sie einzusetzen:
- Exportoptionen: Thunderbit exportiert nach Excel, CSV, Google Sheets, Airtable oder Notion – ganz wie es zu Ihrem Workflow passt ().
- Integration: Speisen Sie Ihre Daten in BI-Dashboards, Preistools oder Bestandsverwaltungssysteme ein.
- Automatisierung: Planen Sie regelmäßige Scrapes, damit Ihre Daten frisch und Ihre Berichte aktuell bleiben.
Für wiederkehrende Aufgaben speichern Sie Ihre Thunderbit Scraper-Vorlage und planen Sie sie so, dass sie automatisch ausgeführt wird. Ihr Team wird Ihnen die eingesparte Zeit danken.
Fazit und wichtigste Erkenntnisse
Noon-Daten zu scrapen muss kein Kopfzerbrechen sein. Mit Thunderbit können Sie:
- Strukturierte Daten schnell extrahieren aus Noons komplexer Website – ganz ohne Coding
- KI nutzen für Feldvorschläge, Unterseiten-Scraping und Datenanreicherung
- Ihre Ergebnisse exportieren in die Tools, die Sie ohnehin verwenden (Excel, Sheets, Notion, Airtable)
- Konform bleiben, indem Sie Best Practices befolgen und Noons Richtlinien respektieren
- Rohdaten in umsetzbare Erkenntnisse verwandeln für Preise, Bestände, Marketing und mehr
Wenn Sie bereit sind, die manuelle Mühe hinter sich zu lassen und das volle Potenzial der Noon-Daten zu nutzen, dann für Ihr nächstes Projekt. Mit der kostenlosen Version können Sie bis zu 6 Seiten scrapen – genug, um die Magie in Aktion zu erleben.
Sie möchten mehr Tipps zu Web Scraping, E-Commerce-Analysen oder KI-gestützter Produktivität? Schauen Sie im vorbei und abonnieren Sie unseren für Tutorials und Schritt-für-Schritt-Anleitungen.
Viel Erfolg beim Scrapen – und mögen Ihre Daten immer sauber, vollständig und der Konkurrenz einen Schritt voraus sein.
FAQs
1. Ist es legal, Noon-Daten zu scrapen?
Das hängt von Noons Nutzungsbedingungen und den lokalen Datenschutzgesetzen ab. Prüfen Sie immer Noons , kontrollieren Sie robots.txt und verwenden Sie die Daten verantwortungsvoll. Thunderbit befürwortet ethisches Scraping und Compliance.
2. Welche Daten kann ich mit Thunderbit aus Noon extrahieren?
Sie können Produktnamen, Preise, Bewertungen, Bilder, Beschreibungen, Verkäuferinformationen und mehr extrahieren. Thunderbits KI schlägt relevante Felder vor und kann sogar Detailseiten für reichhaltigere Daten scrapen.
3. Wie geht Thunderbit mit Noons Pagination und dynamischen Inhalten um?
Thunderbits KI erkennt und verarbeitet automatisch sowohl klassische Pagination als auch unendliches Scrollen. Sie kann sich außerdem an per JavaScript geladene Inhalte im Browser-Modus anpassen.
4. Kann ich Noon-Daten nach Excel oder Google Sheets exportieren?
Absolut. Thunderbit unterstützt den sofortigen Export nach Excel, CSV, Google Sheets, Airtable und Notion – ohne zusätzliche Schritte.
5. Was passiert, wenn Noon sein Website-Layout ändert?
Da Thunderbits KI die Seite bei jedem Lauf neu liest, statt sich auf eine manuell gebaute Vorlage zu verlassen, bringen kleine Layout-Änderungen das Scraping meist nicht aus dem Tritt – Sie klicken einfach erneut auf „KI-Felder vorschlagen“. Die ehrliche Einschränkung: Ein komplettes Redesign von Noon, eine neue CAPTCHA-Barriere oder eine A/B-Variante kann jeden Scraper durcheinanderbringen. Wenn etwas nicht stimmt, führen Sie „KI-Felder vorschlagen“ erneut aus, wechseln Sie zwischen Browser- und Cloud-Modus oder präzisieren Sie Ihr Feld mit einer benutzerdefinierten Anweisung.
Bereit zum Start? und sehen Sie selbst, wie einfach das Scrapen von Noon-Daten sein kann.
Mehr erfahren