

An einem Dienstag stand auf meinem OpenRouter-Dashboard schon vor dem Mittagessen ein Verbrauch von 47 $. Erledigt hatte ich vielleicht ein Dutzend Programmieraufgaben — nichts Großes, etwas Refactoring und ein paar Bugfixes. In dem Moment dämmerte mir, dass OpenClaw mit seinen Standardwerten klammheimlich jede einzelne Interaktion, inklusive der Background-Heartbeat-Pings, über Claude Opus zu über 15 $ pro Million Tokens leitete.
Falls dir so eine Überraschung bekannt vorkommt — und den Foren nach zu urteilen bist du damit nicht allein („Ich habe schon 40 $ ausgegeben und benutze es kaum“, schrieb ein Nutzer) —, dann bekommst du in diesem Leitfaden den kompletten Audit- und Optimierungsansatz, mit dem ich meine monatlichen Kosten um rund 90 % gedrückt habe. Nicht das übliche „nimm ein günstigeres Modell“, sondern eine systematische Analyse, wohin die Tokens wirklich fließen, wie du sie überwachst, welche Budget-Modelle sich in echter Agentenarbeit bewähren und welche drei Copy-Paste-Konfigurationen du sofort übernehmen kannst. Der ganze Prozess hat einen Nachmittag gedauert.
Was ist der OpenClaw-Tokenverbrauch – und warum ist er standardmäßig so hoch?
Tokens sind die Abrechnungseinheit für jede KI-Interaktion in OpenClaw. Stell sie dir als winzige Textbausteine vor — grob 4 englische Zeichen pro Token. Jede Nachricht, die du sendest, jede Antwort, die du bekommst, jeder Hintergrundprozess, der anspringt: alles wird in Tokens abgerechnet.
Das Problem: Die Standardwerte von OpenClaw zielen auf maximale Leistungsfähigkeit, nicht auf minimale Kosten. Out of the box steht das Primärmodell auf anthropic/claude-opus-4-5 — also auf der teuersten verfügbaren Option. Heartbeat-Pings? Laufen ebenfalls über Opus. Sub-Agents, die für Nebenaufgaben gestartet werden? Auch Opus. Opus für einen Heartbeat-Ping zu nutzen, ist, als beauftragtest du einen Neurochirurgen damit, ein Pflaster aufzukleben. Fachlich machbar, finanziell absurd teuer.
Den meisten Nutzern ist gar nicht bewusst, dass sie für triviale Hintergrundaufgaben Premiumpreise zahlen. Die Standardkonfiguration unterstellt im Grunde, dass du immer und für alles das beste Modell willst — und rechnet genau danach ab.
Warum es mehr bringt, den OpenClaw-Tokenverbrauch zu senken als nur Geld zu sparen
Der naheliegende Vorteil sind niedrigere Kosten. Doch es kommen Effekte hinzu, die sich mit der Zeit aufschaukeln.
Günstigere Modelle sind oft schneller. Gemini 2.5 Flash-Lite schafft etwa 214 Tokens pro Sekunde gegenüber rund 51 bei Opus — also rund 4x mehr Tempo bei jeder Interaktion. GPT-OSS-120B auf Cerebras erreicht 1.917 Tokens pro Sekunde, also etwa 35x schneller als Opus. In einer Agenten-Schleife mit mehr als 50 Tool-Calling-Runden heißt dieser Geschwindigkeitsvorsprung, dass Aufgaben in Minuten erledigt sind, statt bei jedem Round-Trip die schmerzhaften 13,6 Sekunden bis zum ersten Token von Opus abzuwarten.
Obendrein hast du mehr Luft, bevor Rate Limits greifen, weniger gedrosselte Sessions und Spielraum zum Skalieren, ohne dass die Rechnung dein Nervenkostüm gleich mit hochskaliert.
Prognostizierte Einsparungen für verschiedene Nutzungsprofile:
| Nutzerprofil | Geschätzte monatliche Kosten (Standard) | Nach vollständiger Optimierung | Monatliche Ersparnis |
|---|---|---|---|
| Gering (~10 Abfragen/Tag) | ~$100 | ~$12 | ~88% |
| Mittel (~50 Abfragen/Tag) | ~$500 | ~$90 | ~82% |
| Stark (~200+ Abfragen/Tag) | ~$1,750 | ~$220 | ~87% |
Das ist nicht aus der Luft gegriffen. Ein Entwickler dokumentierte, wie er von 600–750 Dollar/Monat auf 3–4 Dollar/Tag kam — also echte 90 % weniger —, indem er Modell-Routing mit den später in diesem Leitfaden beschriebenen Maßnahmen gegen versteckte Kostentreiber kombinierte.
Anatomie des OpenClaw-Tokenverbrauchs: Wohin jeder Token tatsächlich geht
Das ist der Teil, den die meisten Optimierungsleitfäden überspringen — und genau er ist der wichtigste. Was du nicht siehst, kannst du nicht beheben.
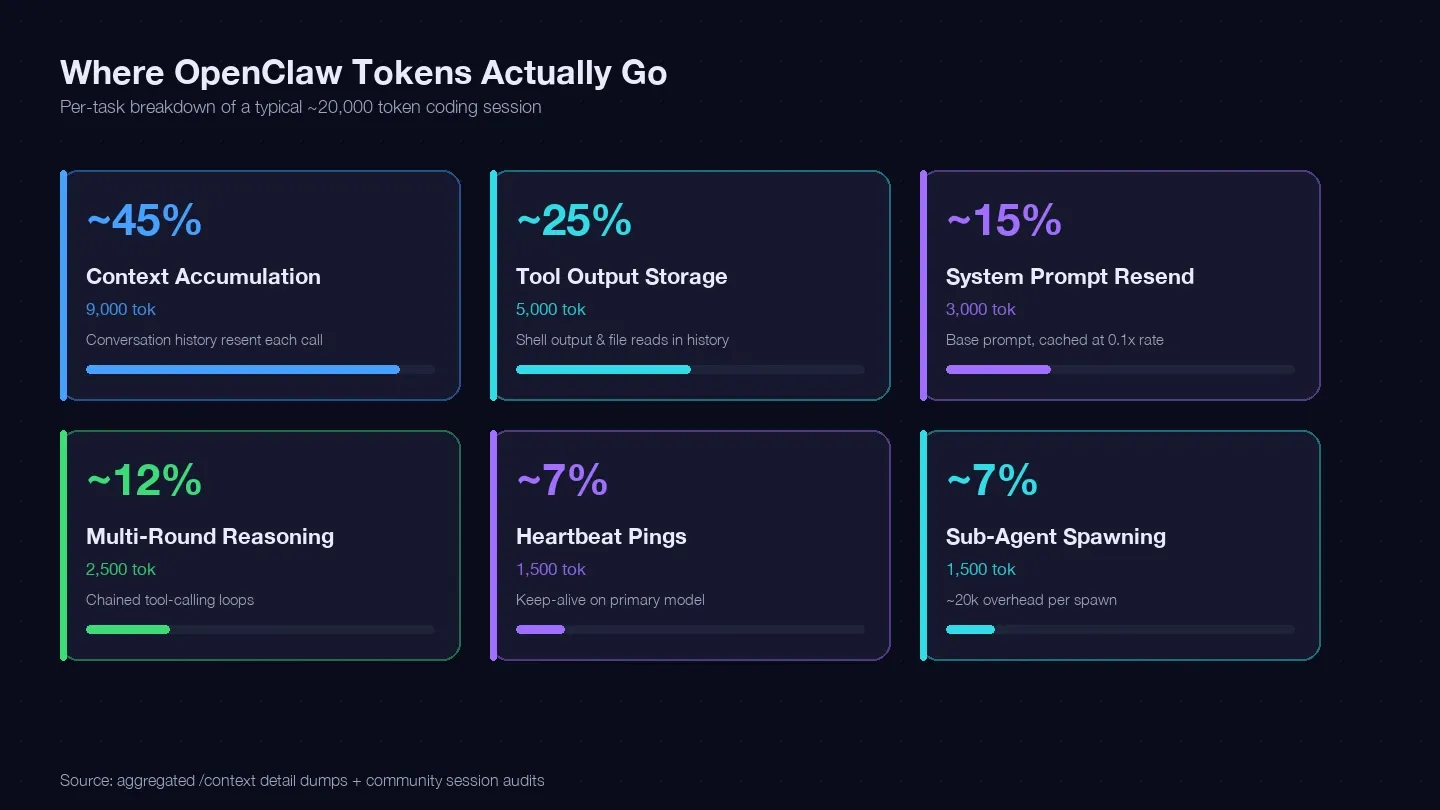
Ich habe mehrere Sessions auseinandergenommen und sie mit dem LaoZhang-Leitfaden zur Kostenoptimierung sowie Community- und Context-Dumps abgeglichen, um ein Token-Ledger für eine typische einzelne Coding-Aufgabe aufzustellen. Hier sind rund 20.000 Tokens tatsächlich hingegangen:
| Token-Kategorie | Typischer Anteil am Gesamtvolumen | Beispiel (1 Coding-Aufgabe) | Kannst du es beeinflussen? |
|---|---|---|---|
| Kontextaufbau (Konversationsverlauf wird bei jedem Call erneut gesendet) | ~40–50% | ~9.000 Tokens | Ja — /clear, /compact, kürzere Sessions |
| Speicherung von Tool-Ausgaben (Shell-Output, Dateiinhalte bleiben im Verlauf) | ~20–30% | ~5.000 Tokens | Ja — kleinere Reads, engerer Tool-Umfang |
| Erneutes Senden des System-Prompts (~15K Basis) | ~10–15% | ~3.000 Tokens | Teilweise — Cache-Reads mit 0,1x Rate |
| Mehrstufiges Reasoning (verkettete Tool-Calling-Schleifen) | ~10–15% | ~2.500 Tokens | Modellwahl + bessere Prompts |
| Heartbeat-/Keep-Alive-Pings | ~5–10% | ~1.500 Tokens | Ja — Konfigurationsänderung |
| Sub-Agent-Aufrufe | ~5–10% | ~1.500 Tokens | Ja — Model Routing |
Der größte Einzelposten — der Kontextaufbau — entsteht dadurch, dass dein Gesprächsverlauf bei jedem API-Call erneut mitgeschickt wird. Ein realer Session-Dump wies allein im Messages-Bucket 185.400 Tokens aus, noch bevor das Modell überhaupt geantwortet hatte. System-Prompt und Tools schlugen obendrein mit rund 35.800 Tokens an Fixkosten zu Buche.
Die zentrale Erkenntnis: Wer Sessions zwischen unabhängigen Aufgaben nicht leert, zahlt bei jedem einzelnen Schritt dafür, den kompletten Gesprächsverlauf erneut zu übertragen.
So überwachst du den OpenClaw-Tokenverbrauch (man kann nicht sparen, was man nicht sieht)
Bevor du irgendetwas änderst, brauchst du Klarheit darüber, wohin deine Tokens gehen. Gleich mit „nimm ein günstigeres Modell“ loszulegen, ohne zu messen, ist wie Abnehmen, ohne je auf die Waage zu steigen.
Schau in dein OpenRouter-Dashboard
Wenn du über OpenRouter routest, ist die Activity-Seite das einfachste Dashboard ganz ohne Setup. Du kannst nach Modell, Provider, API-Key und Zeitraum filtern. Die Usage-Accounting-Ansicht trennt Prompt-, Completion-, Reasoning- und Cached-Tokens pro Request auf. Für längere Auswertungen gibt es einen Export-Button (CSV oder PDF).
Worauf du achten solltest: Welches Modell die meisten Tokens verbraucht hat und ob Heartbeat- oder Sub-Agent-Requests als unerwartet dicke Posten auftauchen.
Prüfe deine lokalen API-Logs
OpenClaw legt Session-Daten in ~/.openclaw/agents.main/sessions/sessions.json ab; dort steckt totalTokens pro Session. Zusätzlich kannst du openclaw logs --follow --json für Live-Logging pro Request nutzen.
Ein wichtiger Hinweis: sessions.json totalTokens wird nach dem Compacting nicht aktualisiert, weshalb das Dashboard veraltete Werte von vor dem Compacting anzeigen kann. Verlass dich lieber auf /status und /context detail als auf die gespeicherten Gesamtzahlen.
Nutze Tracking von Drittanbietern (für mittlere bis starke Nutzer)
LiteLLM Proxy stellt dir einen OpenAI-kompatiblen Endpunkt vor mehr als 100 Providern bereit und protokolliert die Ausgaben automatisch pro virtuellem Key, Modell, Nutzer und Team. Der größte Vorteil: harte Budgets pro Key, die /clear überleben — ein außer Kontrolle geratener Sub-Agent kann also dein gesetztes Limit nicht sprengen.
Helicone ist noch simpler — ein Wechsel der Base-URL mit einer einzigen Zeile, der dir eine Sessions-Ansicht für zusammengehörige Requests liefert. Ein einzelner „Beheb diesen Bug“-Prompt, der in 8+ Sub-Agent-Aufrufe ausufert, erscheint als eine Session-Zeile mit den echten Gesamtkosten. Free Tier: 10.000 Requests/Monat.
Schnelle Kontrollchecks direkt in OpenClaw
Fürs tägliche Monitoring reichen vier Befehle in der Session:
/status— zeigt Kontextnutzung, letzte Input-/Output-Tokens, geschätzte Kosten/usage full— Nutzungs-Footer pro Antwort/context detail— Token-Aufschlüsselung nach Datei, Skill und Tool/compact [guidance]— erzwingt Compacting mit optionalem Fokus-String
Führe /context detail vor und nach Konfigurationsänderungen aus. So siehst du schwarz auf weiß, ob deine Optimierungen wirklich etwas gebracht haben.
Das OpenClaw-Showdown der günstigsten Modelle: Welche Budget-LLMs echte Agentenarbeit können
Hier laufen die meisten Leitfäden in die falsche Richtung. Sie zeigen dir eine Preistabelle, deuten auf die billigste Zeile und erklären die Sache für erledigt. Benchmarks sagen aber kaum etwas über reale Agentenleistung aus — darauf weist die Community seit Langem und sehr deutlich hin. Ein Nutzer brachte es so auf den Punkt: „Benchmarks helfen überhaupt nicht dabei zu verstehen, welches Modell für agentische KI am besten funktioniert.“
Die entscheidende Einsicht: Das günstigste Modell ist nicht immer die günstigste Lösung. Ein Modell, das scheitert und viermal nachsetzen muss, kostet mehr als ein Mittelklassemodell, das beim ersten Versuch klappt. In produktiven Agentensystemen solltest du mit einer Retry-Rate von 5–10 % rechnen — und wenn fünf LLM-Calls verkettet sind und Schritt vier scheitert, startet ein naives Retry die kompletten fünf Schritte von vorn.
Hier meine Fähigkeitsmatrix mit einem „Real Agentic Score“, der auf echten Nutzerberichten statt auf synthetischen Benchmarks beruht:
| Modell | Input $/1M | Output $/1M | Zuverlässigkeit beim Tool-Calling | Mehrstufiges Reasoning | Real Agentic Score (1–5) | Am besten geeignet für |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Gemischt — gelegentliche Schleifen | Grundlegend | ⭐2.5 | Heartbeats, einfache Abfragen |
| GPT-OSS-120B | $0.04 | $0.19 | Ausreichend | Ausreichend | ⭐3.0 | Budget-Experimente, geschwindigkeitskritisch |
| DeepSeek V3.2 | $0.26 | $0.38 | Inkonsistent (6 offene Issues) | Gut | ⭐3.0 | Reasoning-lastig, wenig Tool-Calling |
| Kimi K2.5 | $0.38 | $1.72 | Gut (über :exacto) | Ausreichend | ⭐3.5 | Einfache bis mittlere Coding-Aufgaben |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Gut | Gut | ⭐4.0 | Allzweckmodell für den täglichen Einsatz |
| Claude Haiku 4.5 | $1.00 | $5.00 | Exzellent | Gut | ⭐4.5 | Zuverlässiger Fallback der Mittelklasse |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Exzellent | Exzellent | ⭐5.0 | Komplexe mehrstufige Aufgaben |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Exzellent | Exzellent | ⭐5.0 | Nur für die schwierigsten Probleme reservieren |
Eine Warnung zu DeepSeek und Gemini Flash beim Tool-Calling
DeepSeek V3.2 macht auf dem Papier viel her — 72–74 % auf SWE-Bench, 11–36x günstiger als Sonnet. In der Praxis dokumentieren sechs separate GitHub-Issues aus Cline, Roo Code, Continue und NVIDIA NIM defektes Tool-Calling-Verhalten. Das Fazit von Composio im Direktvergleich: „DeepSeek V3.2 hat Teile der App gebaut, stieß aber bei Ausführung, Geschwindigkeit und Zuverlässigkeit an Grenzen.“ Der Kurzkommentar von Zvi Mowshowitz: „okay and cheap, but.“
Bei Gemini 2.5 Flash klafft eine ähnliche Lücke. Ein Thread im Google AI Developers Forum mit dem Titel „Very frustrating experience with Gemini 2.5 function calling performance“ beginnt mit: „the function calling behavior of Gemini models has become completely unreliable and unpredictable.“
OpenRouter hat eine wichtige Nuance hervorgehoben: „die Neigung eines Modells, Tools aufzurufen, und die Genauigkeit dieser Aufrufe können sich je nach Host mit denselben Gewichten dramatisch unterscheiden.“ Wenn du günstige Modelle über OpenRouter routest, halte Ausschau nach dem :exacto-Tag — ein stiller Provider-Wechsel kann aus einem zuverlässigen Budget-Modell über Nacht eine teure Retry-Schleife machen.
Wann du welches Modell einsetzen solltest
- Gemini Flash-Lite: Heartbeats, Keep-Alive-Pings, einfache Q&A. Niemals für mehrstufiges Tool-Calling.
- MiniMax M2.5/M2.7: Dein tägliches Standardmodell für allgemeine Coding-Aufgaben. SWE-Pro 56.22, Terminal-Bench 2 57.0 % zu einem Bruchteil des Sonnet-Preises.
- Claude Haiku 4.5: Der verlässliche Fallback, wenn günstige Modelle beim Tool-Calling hängen bleiben. Stark bei der Tool-Calling-Zuverlässigkeit und rund 3x günstiger als Sonnet.
- Claude Sonnet 4.6: Komplexe, mehrstufige Agentenarbeit. Hier bekommst du echten Gegenwert.
- Claude Opus: Nur für die härtesten Probleme reservieren. Lass es niemals dein Standardmodell für irgendetwas sein.
(Die Modellpreise ändern sich häufig — prüfe die aktuellen Tarife auf OpenRouter oder direkt auf den Seiten der Provider, bevor du eine Konfiguration festschreibst.)
Die versteckten Token-Lecks, die die meisten Leitfäden auslassen
In Foren berichten Nutzer, dass das Abschalten bestimmter Funktionen die Kosten drastisch senkt, aber kein Leitfaden, den ich gefunden habe, liefert eine gemeinsame Checkliste aller versteckten Kostentreiber samt ihrem tatsächlichen Token-Effekt. Hier die komplette Analyse:
| Versteckter Kostentreiber | Token-Kosten pro Auftreten | So behebst du es | Konfigurationsschlüssel |
|---|---|---|---|
| Standard-Heartbeat auf Opus | ~100.000 Tokens/Lauf ohne Isolierung | Haiku-Override + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Erzeugung von Sub-Agents | ~20.000 Tokens pro Spawn noch vor der eigentlichen Arbeit | Sub-Agents auf Haiku routen | subagents.model |
| Vollständiges Laden des Codebase-Kontexts | ~3.000–15.000 Tokens pro Auto-Explore | .clawignore für node_modules, dist, Lockfiles | .clawrules + .clawignore |
| Automatisches Zusammenfassen des Speichers | ~500–2.000 Tokens/Session | Deaktivieren oder Frequenz senken | memory: false oder memory.max_context_tokens |
| Anhäufung des Konversationsverlaufs | ~500+ Tokens/Turn (kumulativ) | Zwischen unabhängigen Aufgaben neue Sessions starten | /clear-Disziplin |
| Tool-Overhead durch MCP-Server | ~7.000 Tokens für 4 Server; 50.000+ bei 5+ | MCPs minimal halten | Unbenutzte MCPs entfernen |
| Initialisierung von Skills/Plugins | 200–1.000 Tokens pro geladenem Skill | Unbenutzte Skills deaktivieren | skills.entries.<name>.enabled: false |
| Agent Teams (Plan-Modus) | ~7x Standard-Session-Kosten | Nur für echte Parallelarbeit nutzen | Sequenziell bevorzugen |
Der Heartbeat-Kostentreiber verdient eine eigene Erwähnung. Standardmäßig laufen Heartbeats alle 30 Minuten auf dem Primärmodell (Opus). Mit isolatedSession: true sinkt das von rund 100.000 Tokens pro Lauf auf 2.000–5.000 Tokens — also 95–98 % weniger in genau diesem Posten.
Drei schnelle Maßnahmen, die in unter zwei Minuten die meisten Tokens sparen
Alle drei sind risikofrei und in weniger als zwei Minuten erledigt:
-
Zwischen unabhängigen Aufgaben
/clearnutzen (5 Sekunden). Das ist der größte einzelne Sparhebel. Der Forenkonsens sieht hier 50–70 % weniger Verbrauch allein dadurch, dass man den Session-Verlauf vor der nächsten Aufgabe leert. Erinnerst du dich an den 185k-Token-Messages-Bucket aus dem /context-Dump?/clearräumt ihn weg. -
Für Routineaufgaben
/model haiku-4.5verwenden (10 Sekunden). Ein taktischer Modellwechsel bringt 60–80 % Kostenersparnis bei Standardaufgaben. Haiku stemmt die meisten einfachen Coding-Aufgaben, Dateiabfragen und Commit-Nachrichten mühelos. -
.clawrulesauf unter 200 Zeilen kürzen +.clawignoreergänzen (90 Sekunden). Deine Rules-Datei wird bei jeder einzelnen Nachricht geladen. Bei 200 Zeilen sind das etwa 1.500–2.000 Tokens pro Turn; bei 1.000 Zeilen belastet sie dauerhaft jede Anfrage mit 8.000–10.000 Tokens. Kombiniert mit einer.clawignore, dienode_modules/,dist/, Lockfiles und generierten Code ausschließt, berichtet ein Entwickler von einer Reduzierung um 92 % allein durch diese Disziplin.
Schritt für Schritt: Drei sofort nutzbare Konfigurationen, um den OpenClaw-Tokenverbrauch zu senken

Im Folgenden findest du drei vollständige, kommentierte openclaw.json-Konfigurationen — von „einfach nur loslegen“ bis „kompletter Optimierungs-Stack“. Jede enthält Inline-Kommentare und Schätzungen der monatlichen Kosten.
Bevor du startest:
- Schwierigkeit: Anfänger (Config A) → Fortgeschritten (Config B) → Pro (Config C)
- Zeitbedarf: ca. 5 Minuten für Config A, ca. 15 Minuten für Config C
- Was du brauchst: installierter OpenClaw, ein Texteditor, Zugriff auf
~/.openclaw/openclaw.json
Config A: Anfänger — einfach Kosten sparen
Fünf Zeilen. Keine Komplexität. Tauscht das Standardmodell von Opus auf Sonnet, schaltet den Memory-Overhead ab und isoliert Heartbeats auf Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // war Opus — sofort 3–5x günstiger
"heartbeat": {
"every": "55m", // auf 1h Cache-TTL abgestimmt für maximale Cache-Hits
"model": "anthropic/claude-haiku-4-5", // Haiku für Pings, nicht Opus
"isolatedSession": true // ~100k → 2–5k Tokens pro Lauf
}
}
},
"memory": { "enabled": false } // spart ~500–2k Tokens/Session
}
Was du nach der Anwendung sehen solltest: Führe /status davor und danach aus. Deine Kosten pro Anfrage sollten spürbar fallen, und Heartbeat-Einträge auf deiner OpenRouter-Activity-Seite sollten Haiku statt Opus zeigen.
| Nutzungsstufe | Standard (Opus) | Config A (Sonnet + Haiku-Heartbeats) | Ersparnis |
|---|---|---|---|
| Gering (~10 Abfragen/Tag) | ~$100 | ~$35 | 65% |
| Mittel (~50 Abfragen/Tag) | ~$500 | ~$250 | 50% |
| Stark (~200 Abfragen/Tag) | ~$1,750 | ~$900 | 49% |
Config B: Fortgeschritten — intelligentes Drei-Stufen-Routing
Sonnet als Primärmodell für echte Arbeit. Haiku für Sub-Agents und Compacting. Gemini Flash-Lite als Budget-Fallback, wenn Claude gedrosselt ist. Fallback-Ketten fangen Provider-Ausfälle automatisch ab.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // falls Sonnet gedrosselt wird
"google/gemini-2.5-flash-lite" // ultra-günstige letzte Option
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55 Min < 1h Cache-TTL = Cache-Treffer
"model": "google/gemini-2.5-flash-lite", // Centbeträge pro Ping
"isolatedSession": true,
"lightContext": true // minimaler Kontext für Heartbeat-Calls
},
"subagents": {
"maxConcurrent": 4, // runter von standardmäßig 8
"model": "anthropic/claude-haiku-4-5" // Sub-Agents brauchen kein Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // Komprimierungszusammenfassungen via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Erwartetes Ergebnis: Sub-Agent-Einträge in deinen Logs sollten jetzt Haiku-Preise zeigen. Heartbeats sollten nahezu nichts kosten. Deine Fallback-Kette sorgt dafür, dass ein Claude-Ausfall deine Session nicht blockiert — sie fällt sauber auf Gemini zurück.
| Nutzungsstufe | Standard | Config B | Ersparnis |
|---|---|---|---|
| Gering | ~$100 | ~$20 | 80% |
| Mittel | ~$500 | ~$150 | 70% |
| Stark | ~$1,750 | ~$500 | 71% |
Config C: Power User — vollständiger Optimierungs-Stack
Modellzuweisung pro Sub-Agent, Kontext-Compacting fest auf Haiku, Vision-Routing auf Gemini Flash, schlanke .clawrules + .clawignore, ungenutzte Skills deaktiviert. Das ist die Konfiguration, mit der du in den Bereich von 85–90 % Ersparnis vorstößt.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // anderer Provider als Backup
"minimax/minimax-m2-7", // günstiger Daily-Driver-Fallback
"anthropic/claude-haiku-4-5" // letzte Option
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // nachts keine Heartbeats
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // runter vom Standard 20000
"imageModel": "google/gemini-3-flash" // Vision-Aufgaben über günstiges Modell
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // minimales Memory
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Per-Sub-Agent-Override-Beispiel — in ~/.openclaw/agents/lint-runner/SOUL.md einfügen:
---
name: lint-runner
description: Führt Lint-/Format-Checks aus und behebt triviale Fehler
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Minimal brauchbare .clawignore — schon das allein senkt typische Bootstraps von 150k Zeichen auf etwa 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Nutzungsstufe | Standard | Config C | Ersparnis |
|---|---|---|---|
| Gering | ~$100 | ~$12 | 88% |
| Mittel | ~$500 | ~$90 | 82% |
| Stark | ~$1,750 | ~$220 | 87% |
Diese Zahlen decken sich mit zwei unabhängigen Berichten aus der Praxis: Praney Behl dokumentierte einen Rückgang von $600–750/Monat auf $3–4/Tag (90 % weniger), und die LaoZhang-Case-Studies zeigen mit teilweiser Optimierung $943 → $347 (63 %), $1.750 → $1.000 (64 %), $200 → $70 (65 %).
Mit dem /model-Befehl den OpenClaw-Tokenverbrauch spontan steuern
Der /model-Befehl wechselt das aktive Modell für die nächste Runde, ohne deinen Gesprächskontext zu verlieren — kein Reset, kein Datenverlust. Das ist die tägliche Gewohnheit, die sich über die Zeit ordentlich auszahlt.
Praktischer Ablauf:
- Du arbeitest an einem kniffligen Multi-File-Refactor? Bleib auf Sonnet.
- Kurze Frage wie „Was macht dieser Regex?“?
/model haiku, Frage stellen, danach mit/model sonnetzurückwechseln. - Commit-Message oder Feinschliff an der Doku?
/model flash-lite, fertig.
In openclaw.json kannst du unter commands.aliases Aliase einrichten, die kurze Namen (haiku, sonnet, opus, flash) auf vollständige Provider-Strings abbilden. Spart bei jedem Wechsel ein paar Tastenanschläge.
Die Rechnung: 50 Abfragen pro Tag mit Sonnet kosten rund 3 $ pro Tag. Dieselben 50 Abfragen, im Verhältnis 70/20/10 über Haiku/Sonnet/Opus verteilt, kosten etwa 1,10 $ pro Tag. Auf den Monat hochgerechnet sind das 90 $ → 33 $ — 63 % günstiger, ohne das Tool zu wechseln, nur durch Gewohnheit.
Bonus: OpenClaw-Modellpreise über mehrere Provider mit Thunderbit verfolgen
Modellpreise über mehrere Provider hinweg mit KI tracken Get Started Free
Bei so vielen Modellen und Providern — OpenRouter, direkte Anthropic-API, Google AI Studio, DeepSeek, MiniMax — sind Preise ständig in Bewegung. Anthropic hat den Opus-Output-Preis über Nacht um rund 67 % gesenkt. Google hat im Dezember 2025 die Gemini-Free-Tier-Limits um 50–80 % gekürzt. Eine statische Preis-Tabelle von Hand aktuell zu halten, ist ein aussichtsloser Kampf.
Thunderbit löst das ganz ohne Scraping-Code. Es ist eine Chrome-Erweiterung fürs KI-Web-Scraping, wie gemacht für strukturierte Datenerfassung dieser Art.
So arbeite ich damit:
- Die OpenRouter-Modelle-Seite in Chrome öffnen und in Thunderbit auf „AI Suggest Fields“ klicken. Die Seite wird ausgelesen und die Spalten vorgeschlagen — Modellname, Input-Preis, Output-Preis, Context Window, Provider.
- Auf Scrape klicken und direkt nach Google Sheets exportieren.
- Einen geplanten Scrape in normalem Deutsch einrichten — „jeden Montag um 9 Uhr die OpenRouter-Modellliste neu auslesen“ — und die Cloud erledigt das automatisch.
Ab da hält sich dein persönlicher Preis-Tracker von selbst aktuell. Jedes Modell, das plötzlich 30 % günstiger wird — oder jeder Provider, der ein Exacto-Tag bekommt —, taucht am Montagmorgen in deiner Tabelle auf, ohne dass du einen Finger rührst. Mehr über KI-Datenextraktion für Business liest du in unserem Blog.
Du vergleichst Preise direkt auf den Provider-Seiten (Anthropic, Google, DeepSeek)? Thunderbits Subpage-Scraping folgt jedem Modell-Link zur Detailseite und zieht die jeweiligen Tarife heraus — praktisch, wenn du wissen willst, ob das Routing von Kimi K2.5 über OpenRouter günstiger ist als direkt über NVIDIA Build. Free-Tier- und Plan-Details findest du unter Thunderbit Pricing.
Zentrale Erkenntnisse zur Senkung des OpenClaw-Tokenverbrauchs
Das Framework: Verstehen → Überwachen → Routen → Optimieren.
Die wirksamsten Maßnahmen, sortiert nach Wirkung:
- Nicht standardmäßig Opus verwenden. Stell dein Primärmodell auf Sonnet oder MiniMax M2.7 um. Das allein drückt die Kosten um das 3–5-Fache.
- Heartbeats isolieren. Setze
isolatedSession: trueund route Heartbeats zu Gemini Flash-Lite. Damit wird aus rund 100k Tokens Verbrauch ein Wert von etwa 2–5k. - Sub-Agents auf Haiku routen. Jeder Spawn lädt vor der eigentlichen Arbeit rund 20k Tokens Kontext. Das sollte nicht auf Opus passieren.
/clearkonsequent nutzen. Kostenlos, fünf Sekunden, und laut Community bringt keine andere Einzelmaßnahme mehr..clawignorehinzufügen. Das Ausschließen vonnode_modules, Lockfiles und Build-Artefakten reduziert den Bootstrap-Kontext drastisch.- Vor und nach Änderungen mit
/context detailmessen. Was du nicht messen kannst, kannst du nicht verbessern.
Das günstigste Modell hängt von der Aufgabe ab. Gemini Flash-Lite für Heartbeats. MiniMax M2.7 fürs tägliche Coding. Haiku für zuverlässiges Tool-Calling. Sonnet für komplexe mehrstufige Arbeit. Opus nur für die wirklich härtesten Probleme — und sonst für nichts.
Die meisten Leser kommen mit Config A oder B schon an einem einzigen Nachmittag auf 50–70 % weniger Kosten. Die vollen 85–90 % verlangen das Stapeln aller Maßnahmen — Model Routing, Beheben versteckter Kostentreiber, .clawignore, Disziplin bei Sessions —, aber es ist machbar und hält dauerhaft.
FAQs
1. Was kostet OpenClaw pro Monat?
Das hängt vollständig von deiner Konfiguration, deinem Nutzungsvolumen und der Modellwahl ab. Nutzer mit geringer Aktivität (~10 Abfragen/Tag) geben mit Optimierung typischerweise 5–30 $/Monat aus, oder über 100 $ mit den Standardwerten. Bei mittlerer Nutzung (~50 Abfragen/Tag) liegt die Spanne bei 90–400 $/Monat. Vielnutzer erreichen mit den Standardwerten 600–2.000+ Dollar/Monat — ein dokumentierter Extremfall lag bei 5.623 $ in nur einem Monat. Anthropics eigene Telemetrie deutet auf einen Median von 13 Dollar pro Entwickler und aktivem Tag hin.
2. Welches OpenClaw-Modell ist am günstigsten und trotzdem gut zum Coden?
MiniMax M2.5/M2.7 ist der beste Allround-Daily-Driver — solide Tool-Calling-Zuverlässigkeit, SWE-Pro 56.22, bei rund 0,28/1,10 $ pro Million Tokens. Für Heartbeats und einfache Abfragen ist Gemini 2.5 Flash-Lite mit 0,10/0,40 $ kaum zu schlagen. Claude Haiku 4.5 mit 1/5 $ ist der verlässliche Fallback der Mittelklasse, wenn du exzellentes Tool-Calling brauchst, ohne Sonnet-Preise zu zahlen.
3. Kann ich kostenlose Modelle mit OpenClaw verwenden?
Technisch ja. GPT-OSS-120B gibt es kostenlos über das :free-Tag von OpenRouter und über NVIDIA Build. Gemini Flash-Lite hat ein Free Tier (15 RPM, 1.000 Requests/Tag). DeepSeek gewährt bei der Anmeldung 5 Mio. kostenlose Tokens. Aber Free Tiers haben harte Rate Limits, sind langsamer und oft unzuverlässig verfügbar. Günstige kostenpflichtige Modelle — also nur Centbeträge pro Million Tokens — sind im Dauerbetrieb deutlich verlässlicher.
4. Verliere ich meinen Kontext, wenn ich mitten im Gespräch mit /model das Modell wechsle?
Nein. /model behält den vollständigen Session-Kontext bei — die nächste Runde läuft dann mit dem neuen Modell, aber die komplette Historie bleibt erhalten. Das bestätigt die OpenClaw-Dokumentation zu den Konzepten, und in Claude Code funktioniert es genauso. Du kannst also problemlos zwischen Haiku für schnelle Fragen und Sonnet für komplexe Arbeit hin- und herwechseln, ohne etwas zu verlieren.
5. Was ist der schnellste Weg, um heute meine OpenClaw-Rechnung zu senken?
Tippe zwischen unabhängigen Aufgaben /clear. Das ist kostenlos, dauert fünf Sekunden und löscht den Gesprächsverlauf, der bei jedem API-Call erneut mitgesendet wird. Eine reale Session zeigte 185.000 Tokens angesammelten Nachrichtenverlauf — alles wurde bei jedem Turn erneut übertragen und erneut berechnet. Diesen Verlauf vor neuen Aufgaben zu leeren, ist die Gewohnheit mit dem höchsten ROI.
Thunderbit für KI-Web-Scraping ausprobieren Get Started Free




