

Wer schon einmal Daten von einer modernen Website ziehen wollte — etwa von einem Immobilienportal, einem Onlineshop oder dem eigenen Social-Media-Feed — kennt den Moment der Ernüchterung: Du lädst die Seite, schaust ins HTML und ... da ist nichts. Die spannenden Details, hinter denen du her bist (Preise, Angebote, Bewertungen), tauchen schlicht nicht auf. Der Grund: Das Web von heute besteht nicht mehr nur aus HTML, es läuft auf JavaScript. Stand 2026 setzen rund 98,9 % aller Websites JavaScript als clientseitige Sprache ein — insgesamt etwa 51 Millionen Sites (Radixweb). Ein klassischer Crawler ist da, als würdest du einen Film verstehen wollen, indem du nur das Drehbuch liest — die lebendigen Momente bekommt er nie zu Gesicht.
Ich bin seit Jahren in SaaS und Automatisierung unterwegs und habe oft genug erlebt, wie dieser Wandel Geschäftsanwender, Vertriebsteams und Forschende ratlos zurücklässt. Die gute Nachricht: JavaScript-Crawling zu beherrschen, ist längst keine reine Entwicklersache mehr. Mit dem richtigen Ansatz — und etwas Rückenwind durch KI-Tools wie Thunderbit — holt heute jeder Daten selbst aus den dynamischsten, interaktivsten Seiten heraus. Sehen wir uns an, was JavaScript-Crawling überhaupt ist, warum es zählt und wie du loslegst — ganz ohne Programmierung.
Was ist JavaScript-Crawling? Warum ist es für moderne Web-Datenextraktion so wichtig?
Beginnen wir bei den Grundlagen. JavaScript-Crawling heißt, ein Tool oder einen Bot einzusetzen, der eine Webseite lädt, ihr gesamtes JavaScript ausführt und genau den Inhalt extrahiert, der nach dem Skriptlauf erscheint. Das ist ein riesiger Sprung gegenüber dem klassischen HTML-Scraping, das einfach nur den rohen Quellcode vom Server abgreift. Im heutigen Web ist dieses rohe HTML oft nur ein Gerüst — die eigentlichen Inhalte (Produktlisten, Bewertungen, Preise) lädt JavaScript nach, manchmal sogar erst, nachdem du scrollst, klickst oder anderweitig mit der Seite interagierst.
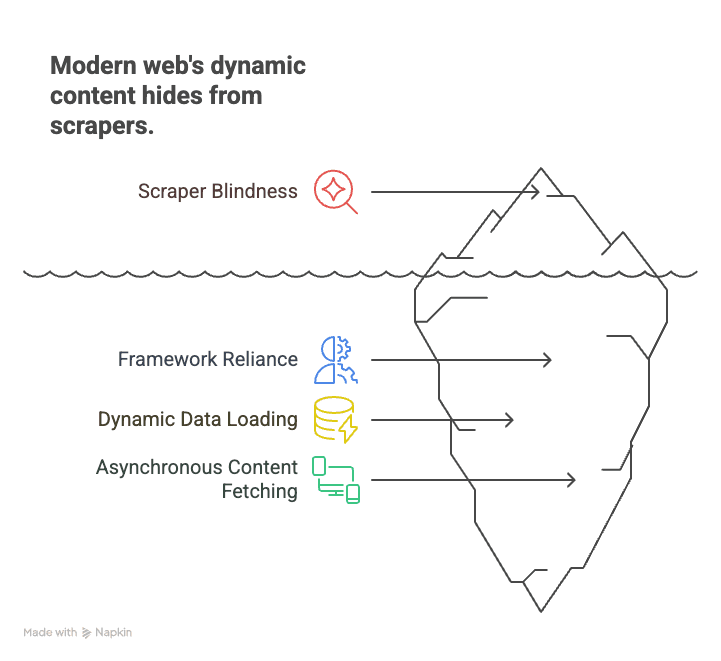
Warum das wichtig ist? Weil das moderne Web auf Frameworks wie React, Angular und Vue läuft. Diese Single-Page Applications (SPAs) laden ihre Daten dynamisch nach und machen statische Scraper für den Großteil der Inhalte praktisch blind. Ein paar Beispiele:
- E-Commerce: Produktpreise und Lagerbestände laden erst, wenn du scrollst oder einen Filter setzt.
- Immobilien: Angebote erscheinen beim Herunterscrollen, Details werden dynamisch nachgeladen.
- Social Media: Beiträge, Kommentare und Likes laden asynchron und stehen im ursprünglichen HTML gar nicht drin.
Ein klassischer Crawler ruft die Seite ab, sieht eine leere Hülle und verpasst alles Wesentliche. JavaScript-Crawling dagegen ist, als öffnest du die Seite in Chrome, lässt sämtliche Skripte durchlaufen und erfasst dann genau das, was du auch siehst — wie ein Mensch.
Kurz gesagt: Wer 2026 Daten von praktisch jeder modernen Website ziehen will, kommt um JavaScript-Crawling nicht herum. Sonst entgeht dir der Großteil des Geschehens — allein React steckt inzwischen hinter 6,2 % aller Websites, dazu kommen Vue, Angular und Next.js in den nächsten Rängen (W3Techs).
Quelle für die 6,2 %: Ich habe w3techs.com/technologies/details/js-react am 2026-05-13 abgerufen; auf der Seite steht „This is 6.2% of all websites.“ Der Zitier-Hash im Original war auf „7.4%“ festgenagelt, was nicht mehr mit dem Seitentext übereinstimmt, daher habe ich den Fragmentteil entfernt.
Zentrale Herausforderungen beim JavaScript-Crawling (und wie du sie überwindest)
JavaScript-Crawling ist nicht einfach „Scraping mit ein paar Schritten mehr“. Es bringt eigene Hürden mit. Hier kommt, womit du rechnen musst — und wie du jede davon nimmst.
Dynamisches Rendering von Inhalten
Die Herausforderung: Die meisten Inhalte stehen gar nicht im HTML. JavaScript lädt sie erst nach dem Seitenaufbau nach — manchmal erst nach Scrollen, Klick oder einem Netzwerkaufruf. Greifst du nur das HTML ab, bekommst du Platzhalter oder leere Container.
Die Lösung: Setze einen Headless-Browser ein — ein Werkzeug, das einen echten Browser simuliert, sämtliche Skripte ausführt und wartet, bis der Inhalt da ist. Tools wie Puppeteer und Playwright sind hier der Branchenstandard. Damit kannst du:
- Eine Seite öffnen und das JavaScript durchlaufen lassen.
- Auf das Laden bestimmter Elemente warten (etwa „.product-list“).
- Den vollständig gerenderten Inhalt aus dem DOM herausholen.
Dieser Ansatz gilt inzwischen als Goldstandard fürs Scraping dynamischer Websites (AIMultiple).
Anti-Bot- und Automatisierungsbarrieren
Die Herausforderung: Websites werden immer geschickter darin, Bots auszusperren. Rechne mit:
- CAPTCHAs
- IP-Sperren oder Rate-Limits
- Browser-Fingerprinting (die Prüfung, ob du ein echter Nutzer bist)
- Honeypot-Fallen (gefälschte Links, um Bots aufzuspüren)
Die Lösung: Scrape mit Augenmaß und bilde menschliches Verhalten nach:
- Beachte die robots.txt und die Nutzungsbedingungen.
- Drossele deine Anfragen — baue zufällige Pausen ein und überlaste den Server nicht.
- Wechsle IPs, wenn du im großen Stil scrapest (aber bitte fair).
- Nutze echte Browser-Header und vermeide offensichtliche Bot-Signaturen.
- Scrape nicht hinter Logins und umgehe keine CAPTCHAs ohne Erlaubnis.
Rechtliche Folgen des Web-Scrapings Lerne, wie du Daten verantwortungsvoll scrapest und dabei die Web-Scraping-Gesetze einhältst. Get Started Free
Thunderbit etwa legt seinen Nutzern nahe, nur öffentlich zugängliche Daten zu erfassen, und verankert Compliance-Best-Practices direkt im Produkt (Thunderbit Blog).
Endloses Scrollen und vom Nutzer ausgelöste Aktionen
Die Herausforderung: Viele Seiten setzen auf Infinite Scroll oder verlangen Klicks, um mehr Daten nachzuladen. Erfasst dein Scraper nur das, was anfangs sichtbar ist, entgeht dir der Großteil des Inhalts.
Die Lösung: Nutze Browser-Automatisierung, um:
- Scrollen zu simulieren (mehr Ergebnisse laden, so wie es ein Nutzer täte).
- „Mehr laden“-Buttons oder Tabs anzuklicken.
- Auf neue Inhalte zu warten, bevor du extrahierst.
Die KI von Thunderbit erkennt solche Muster und übernimmt Scrollen oder Paginierung für dich, ganz ohne eigene Skripte (Thunderbit Docs).
Leistung und Skalierung aufrechterhalten
Die Herausforderung: Für jede einzelne Seite einen Headless-Browser zu starten, frisst Ressourcen. Hunderte oder Tausende Seiten zu scrapen, kann zäh werden und deinen Rechner spürbar belasten.
Die Lösung: Setze auf Concurrent Crawling — mehrere Browser oder Tabs parallel. Oder, noch besser: Lagere die Arbeit in die Cloud aus. Thunderbits Cloud-Scraping-Beschleuniger (auch „Lightning Network“ genannt) scrapt bis zu 50 Seiten gleichzeitig und beschleunigt große Jobs damit enorm (Thunderbit Blog).
Thunderbit: JavaScript-Crawling einfach und leistungsstark machen
Seien wir ehrlich: Die meisten Business-Anwender wollen keinen Code schreiben, keine Selektoren debuggen und keine Skripte pflegen. Genau deshalb gibt es Thunderbit — einen KI-gestützten Web-Scraper für Nicht-Entwickler, die Daten von dynamischen, JavaScript-lastigen Websites brauchen.
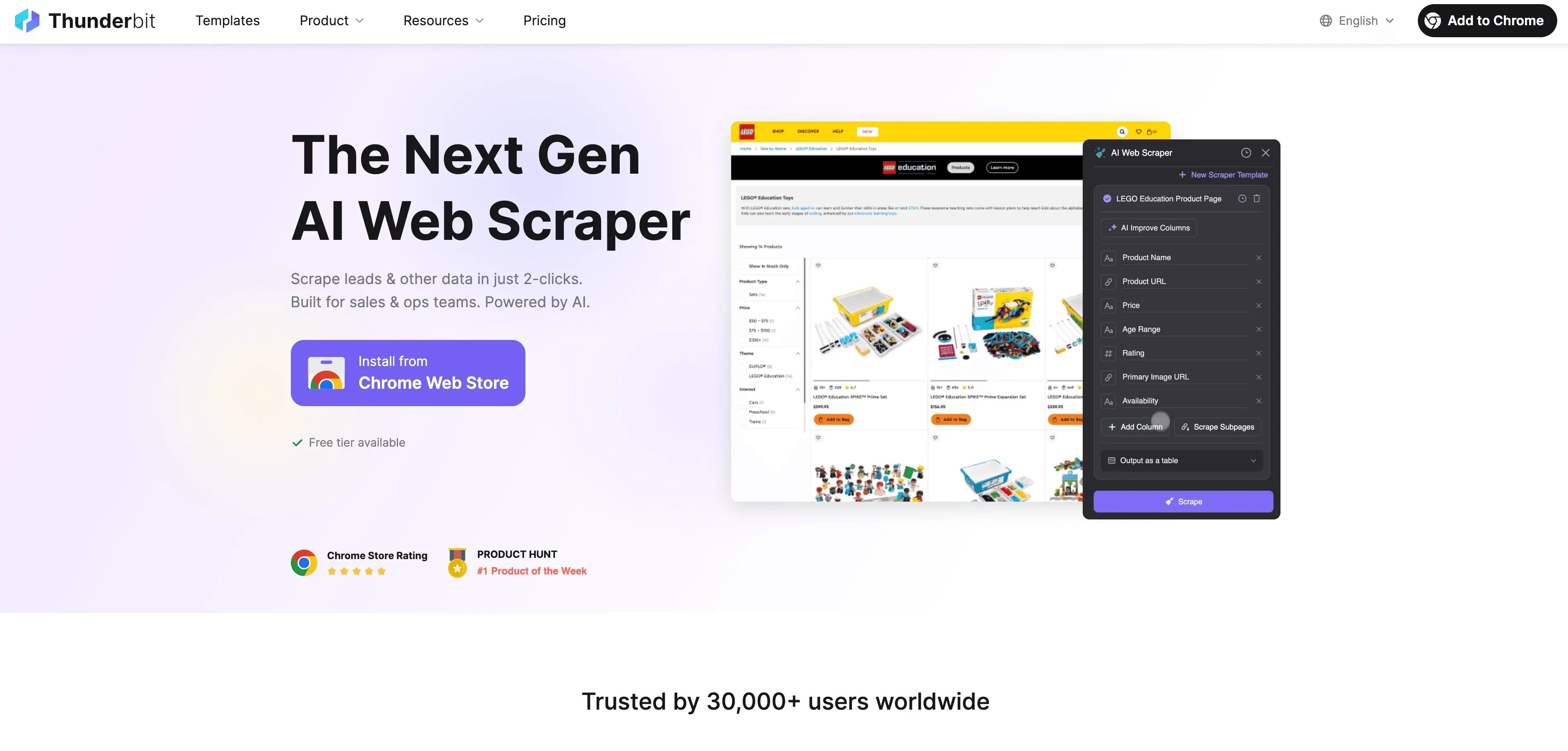
So nimmt dir Thunderbit den Aufwand beim JavaScript-Crawling ab:
- KI-Felder vorschlagen: Ein Klick auf „KI-Felder vorschlagen“ genügt, und Thunderbits KI scannt die Seite, empfiehlt die besten Spalten zum Extrahieren und legt die passenden Datentypen fest. Kein Rätselraten, kein Herumprobieren.
- Extraktion in natürlicher Sprache: Beschreibe einfach, was du brauchst („Produktname, Preis und Bewertung erfassen“), und Thunderbit findet den Weg dorthin.
- Kommt mit dynamischen Inhalten klar: Thunderbit läuft in einem echten Browser (deinem Chrome oder in der Cloud), führt also das gesamte JavaScript aus und wartet, bis die Inhalte geladen sind — wie ein Mensch.
- Unterseiten- und Paginierungs-Support: Mehrere Seiten scrapen oder Links zu Unterseiten folgen (etwa zu Produktdetails)? Thunderbit erledigt das automatisch und führt alle Daten in einer Tabelle zusammen.
- Cloud-Beschleunigung: Bei größeren Jobs scrapt Thunderbits Lightning Network in der Cloud bis zu 50 Seiten auf einmal und schont so deinen Rechner.
- No-Code-Oberfläche: Wer Excel bedienen kann, kommt auch mit Thunderbit klar. Punkt-und-Klick statt technischer Einrichtung.
- Kostenloser Datenexport: Exportiere deine Daten nach Excel, Google Sheets, Airtable, Notion oder als JSON — ohne Aufpreis.
Thunderbit vertrauen weltweit mehr als 100.000 Nutzer, von Vertriebs- über E-Commerce-Teams bis hin zu Immobilienprofis (Thunderbit Official Website).
KI-Felder vorschlagen und Extraktion in natürlicher Sprache
Genau hier spielt Thunderbit seine Stärken aus. Statt im HTML herumzustochern oder XPath-Selektoren zu tippen, klickst du auf einen Button, und Thunderbits KI übernimmt die Schwerarbeit. Sie liest die Seite, versteht die Struktur und empfiehlt dir genau, was extrahiert werden sollte. Brauchst du etwas Bestimmtes, tippst du es einfach in normalem Deutsch ein — die KI von Thunderbit ordnet deine Anfrage den passenden Elementen zu.
Für Einsteiger ist das ein echter Wendepunkt. Du musst nichts über HTML, CSS oder JavaScript wissen. Sag, was du brauchst, und überlass den Rest der KI (Futurepedia).
Paginierung und Crawling von Unterseiten
Thunderbit ist kein Ein-Seiten-Wunder. Es kann:
- Paginierung erkennen und abarbeiten („Weiter“ klicken oder zum Nachladen scrollen).
- Unterseiten scrapen (etwa Produktdetails, Autorenprofile oder Bewertungen) und die Daten in deine Haupttabelle einfließen lassen.
- Infinite Scroll bewältigen, indem es Nutzeraktionen nachstellt, damit du alle Daten bekommst — nicht nur das anfangs Sichtbare.
Ein Beispiel: Du scrapest eine E-Commerce-Kategorie mit 20 Produktseiten? Thunderbit klickt sich automatisch durch jede Seite und führt die Ergebnisse zusammen. Du willst Details von jeder Produktseite? Dann nutze das Unterseiten-Scraping — Thunderbit besucht jeden Link, holt die Zusatzinfos und reichert deinen Datensatz an (Thunderbit Docs).
Lightning Network & Cloud-Beschleunigung: JavaScript-Crawling skalieren
Sobald du Hunderte oder Tausende Seiten scrapen musst, ist es schlicht nicht mehr praktikabel, alles nacheinander abzuarbeiten. Genau dafür gibt es Thunderbits Lightning Network.
- Cloud-Scraping: Schiebe die Schwerarbeit auf Thunderbits Cloud-Server in den USA, der EU und Asien. Die Cloud scrapt bis zu 50 Seiten gleichzeitig und beschleunigt große Jobs damit enorm.
- Concurrent Crawling: Statt darauf zu warten, dass jede Seite in deinem Browser lädt, verteilt Thunderbits Cloud den Auftrag auf viele Worker. 1.000 Produktseiten scrapen? Die Cloud schafft das in Minuten statt in Stunden.
- Geplanter Scraper: Du willst Preise oder Angebote täglich im Blick behalten? Richte einen geplanten Scrape in natürlicher Sprache ein („jeden Tag um 9 Uhr“), und Thunderbit führt den Job automatisch aus und exportiert die Daten in dein Google Sheet oder deine Datenbank (Thunderbit Blog).
Für Vertriebs-, E-Commerce- und Operations-Teams, die frische Daten in großem Umfang brauchen, ist das die Rettung — ganz ohne eigene Entwickler oder Server.
Extraktion großer Datenmengen und über mehrere Seiten
Mit Thunderbit gelingt dir ohne Mühe:
- Komplette Verzeichnisse oder Kataloge scrapen — etwa alle Produkte einer Kategorie oder alle Angebote in einer Region.
- Die Ergebnisse mit einem Klick nach Excel, Google Sheets, Airtable oder Notion exportieren.
- Stunden oder Tage manueller Arbeit sparen — ein Nutzer hat Hunderte Immobilienangebote inklusive Maklerdetails in unter 10 Minuten extrahiert.
Schritt-für-Schritt-Anleitung: So startest du mit JavaScript-Crawling in Thunderbit
Lust, es selbst zu probieren? So legst du mit Thunderbit los — selbst wenn du noch nie eine Website gescrapt hast.
Dein erstes Crawling einrichten
- Thunderbit installieren: Lade die Thunderbit Chrome-Erweiterung herunter und registriere dich für ein kostenloses Konto.
- Ziel wählen: Öffne die Website, die du scrapen möchtest. Ist ein Login nötig, melde dich zuerst an (Thunderbit arbeitet im Kontext deines Browsers).
- Thunderbit öffnen: Klicke in der Chrome-Toolbar auf das Thunderbit-Symbol und wähle deine Datenquelle (aktuelle Seite, URL-Liste oder Dateiupload).
- Ausführungsmodus wählen: Für kleine Jobs oder Seiten mit Login nimm den Browser-Modus. Für große Jobs wechselst du in den Cloud-Modus und scrapest parallel.
- KI-Felder vorschlagen: Klicke auf „KI-Felder vorschlagen“. Thunderbits KI scannt die Seite und empfiehlt Spalten zum Extrahieren (etwa „Produktname“, „Preis“, „Bild-URL“).
- Spalten anpassen: Benenne Felder um, ergänze oder lösche sie nach Bedarf. Füge eigene KI-Anweisungen hinzu, wenn du Daten formatieren oder kategorisieren willst.
- Paginierung/Scrollen konfigurieren: Nutzt die Seite Paginierung oder Infinite Scroll, aktiviere die passende Option in Thunderbits Einstellungen.
- Auf „Scrapen“ klicken: Thunderbit lädt die Seite(n), führt das gesamte JavaScript aus und extrahiert die Daten in eine Tabelle.
Thunderbit für JavaScript-Crawling testen
Daten extrahieren und exportieren
- Ergebnisse prüfen: Thunderbit zeigt deine Daten in einer Tabelle. Checke stichprobenartig Vollständigkeit und Genauigkeit.
- Exportieren: Klicke auf „Exportieren“, um die Daten als Excel, CSV oder JSON herunterzuladen oder direkt an Google Sheets, Airtable oder Notion zu schicken.
- Validieren: Gleiche ein paar Zeilen mit der Live-Seite ab, damit auch alles stimmt.
- Fehlerbehebung: Fehlen Daten, scrolle erst die Seite, passe die KI-Anweisungen an oder wechsle für mehr Leistung in den Cloud-Modus.
Ausführlichere Anleitungen findest du in den Thunderbit Docs oder auf dem Thunderbit YouTube-Kanal.
Best Practices für sicheres und regelkonformes JavaScript-Crawling
Mit großer Scraping-Power kommt große Verantwortung. So bleibst du auf der sicheren Seite — rechtlich wie ethisch:
- Beachte robots.txt und die Nutzungsbedingungen: Prüfe immer, ob die Website Scraping erlaubt. Steht dort „keine Bots“, lass es lieber bleiben (Thunderbit Blog).
- Verzichte aufs Scrapen personenbezogener Daten: DSGVO und CCPA behandeln Namen, E-Mails und Profile als schützenswert — selbst wenn sie öffentlich sind. Erfasse persönliche Informationen nur, wenn du einen legitimen Grund und eine Einwilligung hast.
- Umgehe keine Logins oder CAPTCHAs: Das bewegt sich im rechtlichen Graubereich — oder schlimmer. Bleib bei öffentlichen Daten.
- Drossele deine Anfragen: Überlaste keine Server. Thunderbits Cloud-Modus verteilt Anfragen zeitlich und rotiert IPs, um Sperren zu vermeiden.
- Nutze Daten fair: Veröffentliche keine urheberrechtlich geschützten Inhalte erneut und missbrauche gescrapte Informationen nicht.
- Löschen auf Anfrage: Bittet dich jemand, seine Daten zu entfernen, dann tu es.
Thunderbit ist auf Compliance ausgelegt — nur öffentliche Daten, kein Hacken und klare Exportoptionen für den verantwortungsvollen Einsatz.
Rechtliche Risiken vermeiden
- Bleib bei öffentlichen, nicht-personenbezogenen Daten.
- Scrape keine Seiten, die es ausdrücklich verbieten.
- Bist du unsicher, frag um Erlaubnis oder nutze die offizielle API der Website.
- Halte fest, was du wann gescrapt hast.
- Befolge Unterlassungsaufforderungen sofort.
Tiefer ins Thema steigst du hier ein: Ist Web-Scraping illegal? Die rechtlichen Folgen verstehen.
JavaScript-Crawling-Lösungen im Vergleich: Thunderbit vs. klassische Tools
| Aspekt | Puppeteer/Playwright (Code) | Sitebulb (SEO-Crawler) | Thunderbit (KI, No-Code) |
|---|---|---|---|
| Einrichtungszeit | Stunden (Programmierung erforderlich) | Mittel (Konfiguration) | Minuten (Point & Click) |
| Benötigte Kenntnisse | Hoch (nur Entwickler) | Mittel | Gering (für alle) |
| Verarbeitet JS-Inhalte | Ja (manuelle Skripte) | Ja (für SEO) | Ja (KI, automatisch) |
| Paginierung/Unterseiten | Manuelle Skripte | Eingeschränkt | Automatisch (KI erkennt es) |
| Wartung | Hoch (bricht bei Änderungen) | Mittel | Gering (KI passt sich an) |
| Skalierbarkeit | Manuell (Code schreiben) | Eingeschränkt | Integrierte Cloud (50x) |
| Exportoptionen | Manuell (Code schreiben) | CSV/Excel | Excel, Sheets, Notion |
| Am besten geeignet für | Entwickler, individuelle Workflows | SEO-Audits | Business-Anwender, Analysten |
Für Business-Anwender, die schnell Ergebnisse wollen — ohne technische Kopfschmerzen —, ist Thunderbit die klare Wahl (Thunderbit Blog).
Fazit und wichtigste Erkenntnisse
JavaScript-Websites mit KI scrapen Erschließe dynamische Webdaten mit Thunderbits KI-gestütztem Web-Scraper. Get Started Free
JavaScript-Crawling ist kein Nischenthema mehr — 2026 ist es Pflicht für jeden, der auf Webdaten angewiesen ist.
--- Da 98,9 % der Websites 2026 clientseitige Skripte ausführen, reicht klassisches Scraping schlicht nicht mehr aus (Radixweb).
--- Die gute Nachricht? Entwickler musst du dafür nicht sein.
Das solltest du dir merken:
- Dynamische Inhalte sind überall: Wer moderne Seiten scrapen will, braucht ein Tool, das JavaScript ausführen kann.
- Die Hürden sind real, aber überwindbar: Headless-Browser, intelligentes Warten und Cloud-Beschleunigung holen selbst knifflige Daten heraus.
- Thunderbit macht es einfach: Mit KI-gestützten Feldvorschlägen, Extraktion in natürlicher Sprache, Support für Unterseiten und Paginierung sowie Cloud-Beschleunigung öffnet Thunderbit leistungsstarkes JavaScript-Crawling für alle.
- Bleib regelkonform: Halte dich immer an die Regeln der Website, an Datenschutzgesetze und an ethische Leitlinien.
- Leg heute los: Installiere Thunderbit, such dir eine Website aus und sieh, wie viele Daten du mit wenigen Klicks freisetzt.
Du willst tiefer einsteigen? Im Thunderbit Blog findest du weitere Anleitungen, und unsere YouTube-Tutorials zeigen dir alles Schritt für Schritt.
Viel Erfolg beim Crawlen — und mögen deine Daten stets dynamisch, vollständig und einsatzbereit sein.
Mit Thunderbit mit JavaScript-Crawling starten
FAQs
1. Was ist JavaScript-Crawling, und worin unterscheidet es sich vom klassischen Scraping?
JavaScript-Crawling nutzt ein Tool, das eine Webseite lädt, ihr gesamtes JavaScript ausführt und den Inhalt extrahiert, der nach dem Skriptlauf erscheint. Klassisches Scraping greift nur das rohe HTML ab und verpasst damit den Großteil der Inhalte moderner Websites.
2. Warum brauche ich JavaScript-Crawling für die Extraktion von Geschäftsdaten?
Weil fast alle modernen Websites JavaScript einsetzen, um Inhalte dynamisch zu laden. Ohne JavaScript-Crawling entgehen dir Produktlisten, Bewertungen, Preise und andere wichtige Daten.
3. Wie vereinfacht Thunderbit JavaScript-Crawling für Einsteiger?
Thunderbit nutzt KI, um Felder vorzuschlagen, dynamische Inhalte zu verarbeiten und Paginierung sowie das Scrapen von Unterseiten zu automatisieren. Du beschreibst in normalem Deutsch, was du willst — Programmierung ist nicht nötig.
4. Ist JavaScript-Crawling legal? Worauf sollte ich achten?
JavaScript-Crawling ist legal, solange du verantwortungsvoll vorgehst — bleib bei öffentlichen Daten, beachte robots.txt und die Nutzungsbedingungen und verzichte aufs Scrapen persönlicher Daten ohne Einwilligung. Thunderbit fördert Compliance und einen verantwortungsvollen Einsatz.
5. Wie kann ich mein JavaScript-Crawling für große Jobs skalieren?
Mit Thunderbits Lightning Network (Cloud-Scraping) scrapest du bis zu 50 Seiten gleichzeitig. So lassen sich große Aufgaben wie Preisüberwachung oder Lead-Generierung über Tausende von Seiten hinweg problemlos stemmen.
Mehr erfahren:
- Web-Scraping mit JavaScript: Eine Schritt-für-Schritt-Anleitung
- Schritt-für-Schritt-Anleitung zum Web-Scraping mit JavaScript
- Der ultimative Leitfaden für Web-Scraping mit JavaScript und Node.js
- Wie man eine JavaScript-Website crawlt
KI-Web-Scraper ausprobieren Get Started Free




