

Daten sind für moderne Unternehmen längst zum entscheidenden Rohstoff geworden – und das Netz ist voll davon. Ob im Vertrieb, im E-Commerce, in der Immobilienbranche oder einfach beim Blick auf die Konkurrenz: Wer die passenden Informationen sofort zur Hand hat, ist klar im Vorteil. Nur will eben niemand stundenlang Daten von Websites in Tabellen übertragen. Genau dafür gibt es Web-Scraping – und es ist deutlich weniger kompliziert, als der Begriff vermuten lässt.
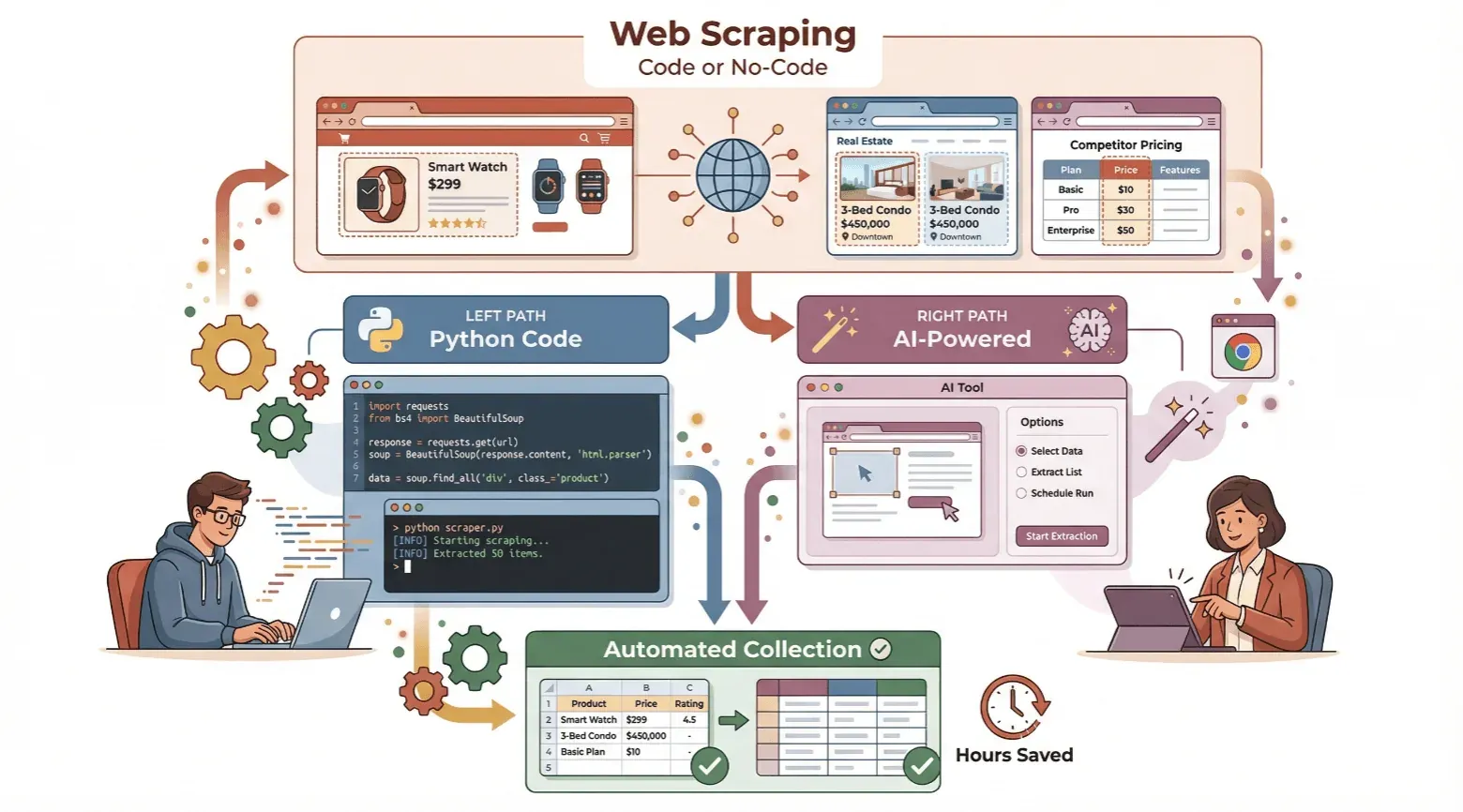
In diesem Leitfaden zeige ich Ihnen, wie Sie einen Web-Scraper erstellen – egal ob Sie als Einsteiger Python ausprobieren oder lieber komplett ohne Code mit einem KI-Tool wie Thunderbit arbeiten möchten. Ich erkläre die Grundlagen, führe Sie durch beide Wege und helfe Ihnen, den passenden für Ihre Anforderungen zu finden. Wenn Sie Zeit sparen und die automatisierte Datenerfassung für sich nutzen wollen, fangen wir am besten direkt an.
Was ist ein Web-Scraper? Die Grundlagen verstehen
Ein Web-Scraper ist im Kern nichts anderes als ein Tool – also Software oder ein Dienst –, das Informationen automatisch von Websites herauszieht. Nehmen wir an, Sie brauchen eine Liste aller Cafés Ihrer Stadt, samt Adressen und Telefonnummern. Entweder klicken Sie sich stundenlang durch Seite um Seite und tippen jede Angabe von Hand ab (Stichwort: Ctrl+C-Dauerschleife), oder Sie überlassen die ganze Arbeit einem Web-Scraper.
Stellen Sie sich einen Web-Scraper wie einen digitalen Assistenten vor: Er liest Webseiten, pickt die gewünschten Daten heraus – Preise, Produktnamen, Kontaktdaten – und legt sie ordentlich in einer Tabelle oder Datenbank ab. Statt zwischen Browser-Tabs und Excel hin- und herzuspringen, übernimmt der Scraper den ganzen Ablauf und ruft, analysiert und speichert die Daten in einem Bruchteil der Zeit.
Im Hintergrund läuft das in drei Schritten ab:
- Anfrage: Der Scraper schickt eine Anfrage an eine Webseite und lädt das rohe HTML herunter.
- Analyse: Er durchsucht das HTML nach den gewünschten Daten, etwa dem Preis in einem
<span>-Tag. - Extraktion: Er zieht die Daten heraus und legt sie in einem strukturierten Format ab (CSV, Excel, Google Sheets usw.).
Manuelles Kopieren ist, als würde man ein Loch mit dem Löffel graben. Web-Scraping ist der Bagger dafür.
Warum die Erstellung eines Web-Scrapers für Unternehmen wichtig ist
Web-Scraping ist nicht länger nur ein Thema für Techies oder Datenwissenschaftler – es ist Pflicht für alle, die auf verlässliche, aktuelle Informationen angewiesen sind. Fast 97 % der großen Organisationen treffen ihre Entscheidungen inzwischen datengetrieben, und Marktanalysen zum Web-Scraping-Sektor sagen durchweg weiteres Wachstum bis zum Ende des Jahrzehnts voraus.
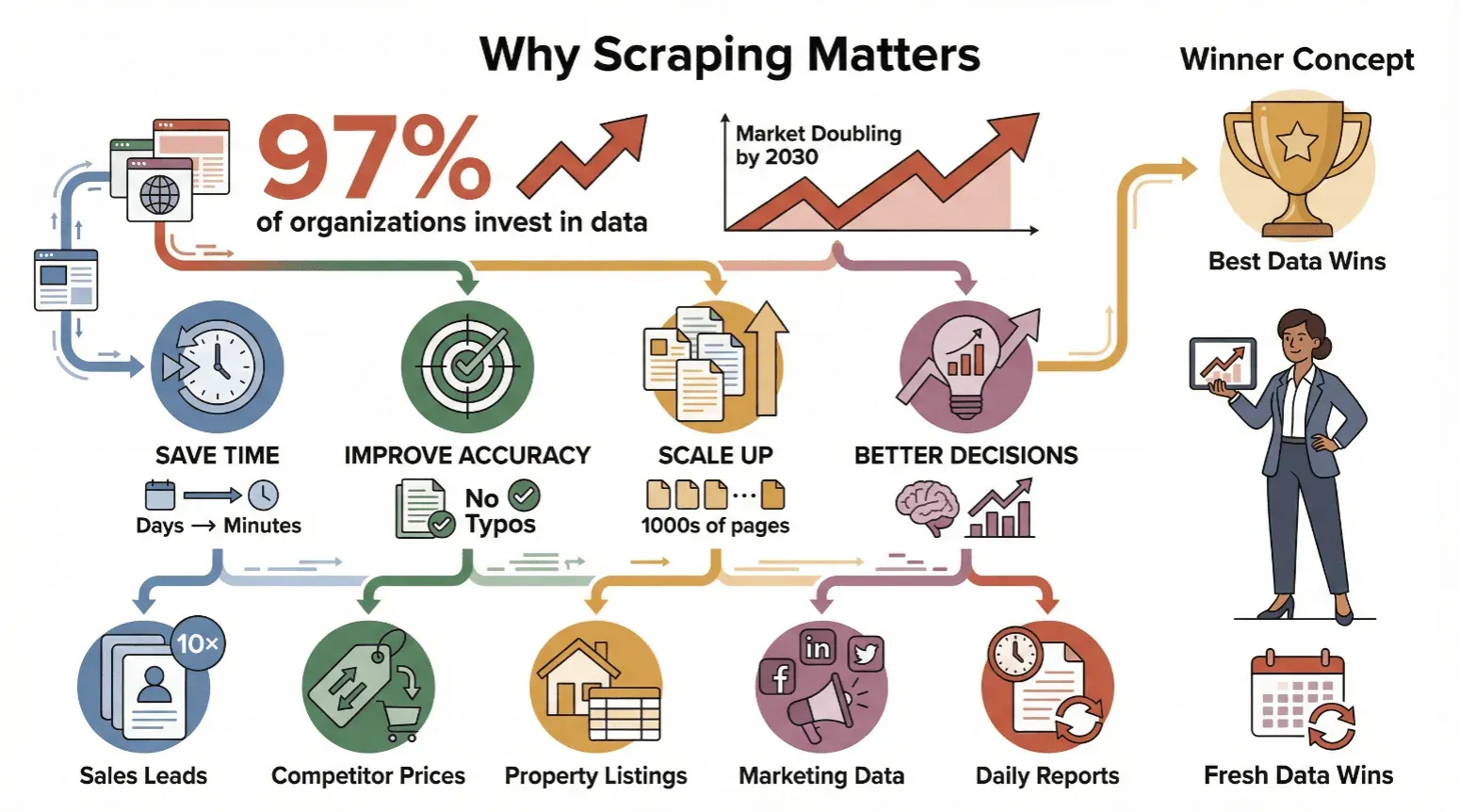
Darum setzen Unternehmen jeder Größe auf Web-Scraping:
- Zeit sparen: Automatisches Scraping schrumpft Tage manueller Arbeit auf Minuten.
- Genauigkeit verbessern: Software wird nicht müde und vertippt sich nicht.
- Skalieren: Scrapen Sie Tausende Seiten statt einer Handvoll.
- Bessere Entscheidungen treffen: Aktuelle Daten führen zu klügeren Entscheidungen – ob bei Preisänderungen, Lead-Generierung oder Trendbeobachtung.
Werfen wir einen Blick auf ein paar konkrete Anwendungsfälle:
| Anwendungsfall | Wer profitiert | Typisches Ergebnis |
|---|---|---|
| Vertriebsleads aus Verzeichnissen extrahieren | Vertriebsteams | 10× mehr Leads, stundenlange Zeitersparnis bei der Akquise |
| Konkurrenzpreise auf E-Commerce-Seiten überwachen | E-Commerce-Manager | Preisanpassungen in Echtzeit, Schutz der Gewinnmarge |
| Immobilienangebote zusammenführen | Immobilienagenturen | Schnellere Objektfindung, aktuelle Marktdaten |
| Marketingdaten aus Web- und Social-Media-Kanälen sammeln | Marketingteams | Besser ausgerichtete Kampagnen, verbessertes Performance-Tracking |
| Tägliche Web-Datenberichte automatisieren | Operations, Analysten | Geringere Arbeitskosten, weniger Fehler, konsistente und pünktliche Berichte |
Kurz gesagt: Wer die besten und aktuellsten Daten hat, gewinnt.
Einsteigerleitfaden: So erstellen Sie einen einfachen Web-Scraper mit Python
Wenn Sie wissen wollen, wie Web-Scraping unter der Haube funktioniert, ist Python ein hervorragender Einstieg. Selbst ohne Programmiererfahrung bauen Sie in wenigen Schritten einen einfachen Scraper. So gehen Sie vor:
Ihre Umgebung einrichten
Als Erstes brauchen Sie Python auf Ihrem Rechner. Laden Sie die neueste Version von python.org herunter und folgen Sie der Installationsanleitung für Ihr Betriebssystem (Windows oder Mac). Wichtig: Setzen Sie während der Installation das Häkchen bei „Add Python to PATH“.
Öffnen Sie danach Ihr Terminal bzw. die Eingabeaufforderung und installieren Sie die benötigten Bibliotheken:
pip install requests
pip install bs4
pip install pandas
requestsruft die Webseiten für Sie ab.bs4(Beautiful Soup) übernimmt das Analysieren des HTML.pandasist perfekt, um Daten als CSV oder Excel zu speichern.
Die Struktur der Website untersuchen
Bevor Sie eine Zeile Code schreiben, müssen Sie wissen, wo im HTML Ihre Daten stecken. Öffnen Sie die Zielwebsite in Chrome, klicken Sie mit der rechten Maustaste auf die gewünschte Angabe – etwa einen Jobtitel – und wählen Sie „Untersuchen“. Das passende HTML-Element wird hervorgehoben, vielleicht ein <a>-Tag mit einer Klasse wie jobtitle. Merken Sie sich diese Tags und Klassen; Sie brauchen sie gleich, um dem Scraper zu sagen, wonach er suchen soll.
Den Scraper schreiben und ausführen
Angenommen, Sie wollen Jobtitel und Firmennamen von einer Jobbörse scrapen. Hier ein einfaches Skript:
import requests
from bs4 import BeautifulSoup
import pandas as pd
URL = "https://example.com/jobs" # Ersetzen Sie dies durch Ihre Ziel-URL
response = requests.get(URL)
soup = BeautifulSoup(response.text, 'html.parser')
# Alle Jobtitel und Firmennamen finden (Selektoren bei Bedarf anpassen)
titles = [t.get_text().strip() for t in soup.find_all('a', class_='jobtitle')]
companies = [c.get_text().strip() for c in soup.find_all('div', class_='company')]
# Als CSV speichern
df = pd.DataFrame({'Job Title': titles, 'Company': companies})
df.to_csv('jobs.csv', index=False)
print("Scraping abgeschlossen! Daten wurden in jobs.csv gespeichert")
- Passen Sie URL und Klassennamen an die Zielseite an.
- Führen Sie das Skript im Terminal aus:
python yourscript.py - Öffnen Sie
jobs.csv, um die Ergebnisse zu sehen.
Profi-Tipp: Bei komplexeren Websites mit Paginierung oder dynamischen Inhalten brauchen Sie zusätzliche Schleifen oder Tools wie Selenium. Für viele statische Seiten reicht dieser Ansatz aber problemlos.
Ohne Code: So erstellen Sie mit Thunderbit einen Web-Scraper
Und wenn Sie mit Code lieber gar nichts zu tun haben wollen? Genau für diesen Fall gibt es Thunderbit – einen KI-gestützten No-Code-Web-Scraper für den geschäftlichen Einsatz. Bei klar strukturierten Seiten bringt Sie Thunderbit in wenigen Klicks von „Ich brauche diese Daten“ zur fertigen Tabelle – bei anspruchsvolleren Seiten mit Logins, Bot-Schutz oder ungewöhnlichen Layouts braucht es zwar gelegentlich etwas Feinarbeit, aber die Einstiegshürde liegt weit unter der, einen Parser von Hand zu schreiben.
Daten von jeder Website mit KI extrahieren Get Started Free
So funktioniert es:
Schritt 1: Thunderbit Chrome-Erweiterung installieren
Rufen Sie die Download-Seite der Thunderbit Chrome-Erweiterung auf und fügen Sie sie Ihrem Browser hinzu. Legen Sie ein kostenloses Konto an (im Gratis-Tarif können Sie ein paar Seiten testen).
Schritt 2: Zur Zielwebsite navigieren
Öffnen Sie die Seite, die Sie scrapen wollen, in Chrome. Loggen Sie sich bei Bedarf ein und scrollen Sie nach unten, damit dynamische Inhalte nachladen.
Schritt 3: Ihre Datenanforderungen beschreiben
Klicken Sie auf das Thunderbit-Symbol, um die Seitenleiste zu öffnen. Sie haben zwei Möglichkeiten:
- auf „KI-Felder vorschlagen“ klicken und Thunderbits KI die Seite scannen und Spalten vorschlagen lassen, etwa „Produktname“, „Preis“ oder „Bild“.
- oder eine Anweisung in einfachem Deutsch eingeben, zum Beispiel: „Extrahiere alle Buchtitel und Autoren von dieser Seite“.
Thunderbits KI empfiehlt automatisch Felder und Datentypen. Bei Bedarf können Sie Felder umbenennen, ergänzen oder löschen.
Schritt 4: Ihren ersten Scrape ausführen
Sobald Ihre Felder stehen, klicken Sie einfach auf „Scrapen“. Thunderbit zieht die Daten heraus, kümmert sich bei Bedarf um die Paginierung und zeigt alles in einer übersichtlichen Tabelle. Brauchen Sie mehr Details von Unterseiten – etwa von einzelnen Produktseiten –, klicken Sie auf „Unterseiten scrapen“. Thunderbit ruft dann jeden Link auf und holt zusätzliche Informationen.
Schritt 5: Ergebnisse prüfen und exportieren
Sehen Sie Ihre Daten in der Thunderbit-Tabelle durch. Passt alles, klicken Sie auf „Exportieren“ und wählen das Format: Excel, CSV, Google Sheets, Airtable, Notion oder JSON. Exporte sind kostenlos und unbegrenzt.
Das war’s. Kein Code, keine Vorlagen, kein Kopfzerbrechen.
Thunderbit KI-Web-Scraper kostenlos testen
Traditionelle und No-Code-Web-Scraper-Lösungen im Vergleich
Sehen wir uns an, wie die beiden Ansätze im direkten Vergleich abschneiden:
| Lösung | Einrichtungszeit | Benötigte Kenntnisse | Wartung | Flexibilität | Exportoptionen |
|---|---|---|---|---|---|
| Python + Beautiful Soup | Stunden/Tage | Programmierung, HTML-Grundlagen | Hoch (bricht leicht) | Sehr hoch | CSV, Excel, JSON (per Code) |
| Ältere No-Code-Tools | 30–60 Min. | Etwas technisches Wissen | Mittel (manuelle Korrektur) | Gut für statische Seiten | CSV, Excel |
| Thunderbit (KI-No-Code) | Minuten | Keine (einfaches Deutsch) | Gering (KI passt sich an) | Hoch (dynamische Seiten) | Excel, CSV, Sheets, Notion... |
Der KI-gestützte Ansatz von Thunderbit heißt im Klartext: weniger Zeit für Einrichtung und Fehlersuche – und mehr Zeit für das, worauf es ankommt, nämlich die Daten tatsächlich zu nutzen.
Typische Herausforderungen traditioneller Web-Scraper überwinden
Traditionelle Scraper haben ein paar bekannte Schwachstellen:
- Website-Änderungen: Stellt eine Seite ihr Layout um, kann Ihr Code brechen. Thunderbits KI passt sich den meisten Änderungen automatisch an, sodass Sie nichts neu programmieren müssen.
- Anti-Bot-Maßnahmen: Viele Seiten blockieren automatisierte Skripte. Thunderbit läuft wahlweise direkt in Ihrem Browser (mit Ihrer Anmeldung und Session) oder für mehr Tempo in der Cloud.
- Dynamische Inhalte: Seiten mit Infinite Scroll oder „Mehr laden“-Schaltflächen bringen einfache Scraper schnell aus dem Tritt. Thunderbits KI verarbeitet automatisches Scrollen und interaktive Elemente von Haus aus.
- Daten hinter Logins: Mit Thunderbits Browser-Modus gilt: Was Sie in Chrome sehen, können Sie auch scrapen.
Kurz gesagt: Thunderbit ist dafür gebaut, mit den unordentlichen Realitäten moderner Websites zurechtzukommen – damit Sie es nicht müssen.
Mehr Effizienz: Thunderbits erweiterte Web-Scraping-Funktionen
Thunderbit geht es nicht nur darum, Daten überhaupt zu bekommen – sondern sie schnell, sauber und einsatzbereit zu liefern. Diese Funktionen schätze ich dabei besonders:
Automatische Paginierung und Unterseiten-Scraping
Sie müssen Hunderte Produkte über mehrere Seiten hinweg scrapen? Thunderbit erkennt die Paginierung (Weiter-Buttons, Infinite Scroll) und holt alles in einem Durchgang. Wollen Sie mehr Details von Unterseiten? Ein Klick auf „Unterseiten scrapen“, und Thunderbit ruft jeden Link auf und zieht zusätzliche Felder herein – etwa Verkäuferinformationen oder Produktspezifikationen.
KI-Feldvorschläge und Datenstrukturierung
Thunderbits KI rät nicht einfach an Spalten herum – sie versteht den Kontext. Sie kann Spalten benennen, Datentypen zuweisen (Text, Zahl, Bild, E-Mail) und sogar eigene Anweisungen umsetzen, etwa „nur Preise über 100 $“ oder „Beschreibungen ins Englische übersetzen“. Per Prompt lassen sich Daten gleich beim Scraping kategorisieren, zusammenfassen oder umformatieren.
Vorlagen und Sofort-Scraping
Für beliebte Seiten (Amazon, Zillow, Google Maps, Instagram) hält Thunderbit sofort einsatzbereite Vorlagen bereit – Seite auswählen, fertig, alle Felder sind bereits vorkonfiguriert. Keine Einrichtung nötig.
Planung und Automatisierung
Sie brauchen jeden Tag frische Daten? Richten Sie einen Zeitplan ein („jeden Montag um 9 Uhr“), und Thunderbit scrapt von selbst und aktualisiert Ihre Google-Tabelle oder Datenbank, ohne dass Sie eingreifen müssen.
Cloud- vs. lokales Scraping
Sie entscheiden, ob Scrapes direkt im Browser laufen – ideal für eingeloggte oder interaktive Seiten – oder in der Cloud, wo es für öffentliche Daten schneller geht, bis zu 50 Seiten parallel.
Was ist Data Scraping und wie funktioniert es 2025? Get Started Free
Mit diesen erweiterten Funktionen wird Thunderbit zur Top-Wahl für alle im Business-Umfeld, die zuverlässiges, skalierbares und einfach zu bedienendes Web-Scraping brauchen.
Schritt-für-Schritt-Anleitung: So erstellen Sie mit Thunderbit einen Web-Scraper
Hier Ihre Schnellstart-Checkliste:
- Thunderbit installieren: Chrome-Erweiterung hinzufügen und registrieren.
- Ihre Zielwebsite öffnen: Bei Bedarf einloggen, zum Laden des Inhalts scrollen.
- Thunderbit-Seitenleiste öffnen: Auf das Erweiterungssymbol klicken.
- Ihre Daten beschreiben: Auf „KI-Felder vorschlagen“ klicken oder Ihren Prompt eingeben.
- Felder prüfen: Spalten bei Bedarf umbenennen, hinzufügen oder löschen.
- Auf „Scrapen“ klicken: Thunderbit erledigt den Rest.
- (Optional) Unterseiten scrapen: Für tiefere Daten auf „Unterseiten scrapen“ klicken.
- Ergebnisse prüfen: Die Tabelle auf Korrektheit überprüfen.
- Daten exportieren: Excel, CSV, Google Sheets, Notion, Airtable oder JSON auswählen.
- Speichern/Vorlage/Planung: Ihre Konfiguration für später speichern oder wiederkehrende Scrapes planen.
Tipps zur Fehlerbehebung:
- Fehlen Daten, formulieren Sie Ihren Prompt um oder arbeiten Sie mit benutzerdefinierten Anweisungen.
- Bei dynamischen Inhalten darauf achten, im Browser-Modus zu sein.
- Stoßen Sie an das Limit des Gratis-Tarifs, lohnt sich ein Upgrade für mehr Seiten.
Thunderbit-Preise und Tarife ansehen
Fazit und wichtigste Erkenntnisse
Einen Web-Scraper zu bauen ist längst nicht mehr Programmierern vorbehalten. Ob Sie selbst Hand anlegen und Python schreiben oder die schwere Arbeit lieber der KI überlassen: Die Werkzeuge sind heute so zugänglich wie nie.
Das sollten Sie mitnehmen:
- Web-Scraping spart Zeit, erhöht die Genauigkeit und ermöglicht datengetriebene Entscheidungen.
- Python ist ideal zum Lernen und für individuelle Projekte, verlangt aber Programmierung und Wartung.
- Thunderbit bietet eine schnelle No-Code-Lösung – einfach beschreiben, was Sie möchten, und auf „Scrapen“ klicken.
- Erweiterte Funktionen wie automatische Paginierung, Unterseiten-Scraping und KI-Feldvorschläge machen Thunderbit zum Kraftpaket für den Business-Einsatz.
- Sie können Thunderbit kostenlos testen und innerhalb weniger Minuten Ergebnisse sehen.
Bereit, das Kopieren und Einfügen hinter sich zu lassen und stattdessen zu automatisieren? Laden Sie Thunderbit herunter und überzeugen Sie sich selbst, wie einfach Web-Scraping sein kann. Wenn Sie tiefer einsteigen möchten, finden Sie im Thunderbit-Blog weitere Anleitungen und Tipps.
Thunderbit KI-Web-Scraper kostenlos testen Get Started Free
FAQs
1. Muss ich programmieren können, um einen Web-Scraper zu erstellen?
Nein! Programmierung (etwa Python + Beautiful Soup) gibt Ihnen volle Kontrolle, aber No-Code-Tools wie Thunderbit ermöglichen es jedem, leistungsstarke Web-Scraper mit einfachen Prompts auf Deutsch und ein paar Klicks zu bauen.
2. Welche Art von Daten kann ich mit Thunderbit scrapen?
Thunderbit extrahiert Text, Zahlen, Bilder, E-Mails, Telefonnummern und mehr von fast jeder Website – einschließlich paginierter Listen und Unterseiten. Für beliebte Seiten stehen außerdem Vorlagen bereit.
3. Wie geht Thunderbit mit Websites um, die ihr Layout ändern?
Thunderbits KI passt sich den meisten Layoutänderungen automatisch an. Anders als traditionelle Scraper, die nach einem Seiten-Update ausfallen, arbeitet Thunderbit dank semantischem Verständnis mit minimalen Anpassungen weiter.
4. Ist Web-Scraping legal und sicher?
Web-Scraping ist legal, solange Sie öffentlich verfügbare Daten sammeln und die Nutzungsbedingungen einer Website respektieren. Thunderbit setzt auf verantwortungsvolle Nutzung und bietet Funktionen, die Ihnen helfen, konform zu bleiben.
5. Kann ich wiederkehrende Scrapes planen oder Exporte automatisieren?
Ja! Mit Thunderbit planen Sie Scrapes in jedem beliebigen Intervall – täglich, wöchentlich usw. – und exportieren die Ergebnisse direkt nach Google Sheets, Notion, Airtable, Excel oder CSV, ganz ohne Handarbeit.
Bereit, Ihre Datenerfassung zu automatisieren? Testen Sie Thunderbit kostenlos und erleben Sie, wie einfach Web-Scraping für alle sein kann.
Mehr erfahren
- So beginnen Sie mit dem Aufbau eines Web-Scrapers: Ein Leitfaden für Einsteiger
- So scrapen Sie eine Website: Ein Einsteigerleitfaden für 2025
- So crawlen Sie Websites: Eine Schritt-für-Schritt-Anleitung für Einsteiger
- So schreiben Sie einen Web-Scraper mit Python: Von Anfang bis Ende
- Umfassender Leitfaden für Web-Scraping in Python: Schritt für Schritt




