Wer schon mal versucht hat, Daten von einer Website zu sammeln – egal ob für neue Vertriebskontakte, Preisvergleiche oder um ein chaotisches Produktverzeichnis zu sortieren – weiß: Copy-Paste ist im Web meistens ein echter Krampf. Die Datenflut im Netz ist riesig: Bis 2025 werden wir mit digitaler Inhalte zu tun haben. Das eigentliche Problem dabei: – sie verstecken sich in Webseiten, PDFs, Bildern oder dynamischen Feeds. Die meisten Teams – ich inklusive – verbringen viel zu viel Zeit damit, dieses Datenchaos zu bändigen, nur um am Ende mit halbfertigen Tabellen und dem Gefühl von „Das kenn ich doch schon…“ dazustehen.

Genau deshalb bin ich ein Fan davon, Websites effizient zu crawlen. In dieser Anleitung zeige ich dir Schritt für Schritt, wie du jede Website crawlen kannst – ganz ohne Programmierkenntnisse und ohne Stress – mit , unserem KI-gestützten Web-Scraper. Egal ob du im Vertrieb arbeitest, für die Organisation zuständig bist oder einfach keine Lust mehr auf manuelle Dateneingabe hast: Ich zeige dir, wie du auch komplexe Layouts, Paginierung, Unterseiten und sogar Daten aus PDFs und Bildern extrahierst. Mach das Web-Chaos zu deinem Vorteil!
Was bedeutet effizientes Website-Crawlen?
Kurz gesagt: Eine Website zu crawlen heißt, mit einem automatisierten Tool (quasi deinem digitalen Assistenten) gezielt Webseiten zu besuchen und die Infos rauszufiltern, die du brauchst – Namen, Preise, E-Mails, Produktspezifikationen und vieles mehr. Effizientes Crawlen bedeutet nicht nur Schnelligkeit, sondern auch Präzision, wenig Handarbeit und die Fähigkeit, mit echten Web-Herausforderungen wie Paginierung, Unterseiten und unstrukturierten Daten klarzukommen ().
Was unterscheidet effizientes Crawlen vom endlosen Copy-Paste? Darauf kommt’s an:
- Geschwindigkeit: Hunderte Seiten oder Datensätze in wenigen Minuten abgreifen.
- Genauigkeit: Genau die Daten extrahieren, die du brauchst – ohne Lücken oder Tippfehler.
- Automatisierung: Das Tool übernimmt wiederkehrende Aufgaben wie „Weiter“-Klicks oder das Folgen von Links zu Detailseiten.
- Robustheit: Komplexe Layouts, dynamische Inhalte und sogar Änderungen an der Website-Struktur sind kein Problem.
- Minimaler Aufwand: Kein Programmieren, kein Basteln an Selektoren, keine ständige Nacharbeit.
Die Realität sieht selten nach perfekten Tabellen aus. Moderne Websites haben Endlos-Scroll, verschachtelte Navigation, Login-Pflicht und Daten, die in PDFs oder Bildern versteckt sind. Effizientes Crawlen heißt, all das zu meistern – damit du weniger Zeit mit Fleißarbeit und mehr mit Analyse und Umsetzung verbringst ().
Warum effizientes Website-Crawlen für Vertrieb und Operations so wichtig ist
Warum ist Website-Crawlen für Unternehmen so ein Gamechanger? Weil die richtigen Daten – schnell geliefert – über den Erfolg deiner nächsten Kampagne, Produkteinführung oder deines Quartals entscheiden können. Hier sind typische (und besonders lohnende) Anwendungsfälle, die ich immer wieder sehe:
| Anwendungsfall | Vorteil & ROI | Beispiel-Ergebnis |
|---|---|---|
| Lead-Generierung | Vertriebs-Pipeline schneller füllen, stundenlange Recherche sparen, Fehlerquellen minimieren | Über Nacht 5.000 gezielte Leads extrahieren, Kampagnen 2 Wochen früher starten, 30 % mehr Termine |
| Wettbewerber-Preisüberwachung | Dynamische Preisgestaltung ermöglichen, in Echtzeit auf Marktveränderungen reagieren, Margen schützen | Händler passt Preise täglich an, erzielt 4 % mehr Umsatz |
| Produktkatalog-/Bestands-Extraktion | Angebote aktuell halten, manuelle Dateneingabe reduzieren, Überverkäufe oder Fehlpreise vermeiden | E-Commerce-Team aktualisiert 10.000 SKUs täglich, spart 90 % der Zeit für Updates |
| Marktforschung & Review-Analyse | Kundenstimmung und Trends großflächig erkennen, Chancen vor der Konkurrenz entdecken | Über 10.000 Bewertungen analysieren, neue Produktideen identifizieren, Marketingbotschaften optimieren |
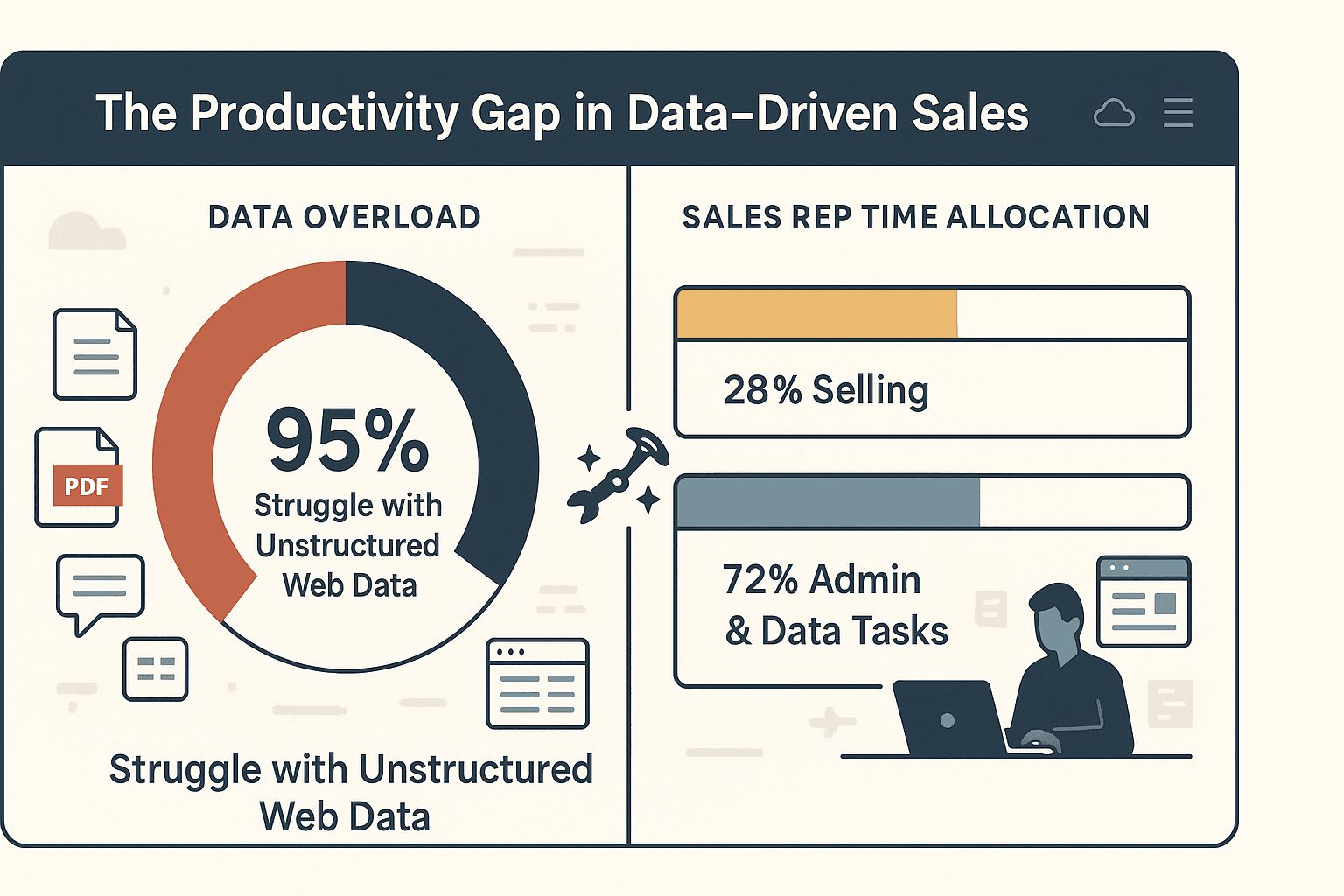
Das Fazit: Effizientes Crawlen ermöglicht schnellere, fundiertere Entscheidungen – und spart dir jede Menge Zeit beim Kopieren und Einfügen. Tatsächlich geben an, dass sie Schwierigkeiten haben, unstrukturierte Webdaten zu nutzen. Und Vertriebsmitarbeiter verbringen nur – der Rest geht für manuelle Dateneingabe und Verwaltung drauf.
Thunderbit: Die einfachste Lösung zum Website-Crawlen
Mal ehrlich: Die meisten Web-Scraping-Tools sind für Entwickler gemacht, nicht für Business-Anwender. Deshalb haben wir entwickelt – einen KI-Web-Scraper, der so einfach zu bedienen ist wie eine Essensbestellung. Das macht Thunderbit besonders:
- Einfache Spracheingabe: Sag einfach, welche Daten du brauchst („Alle Produktnamen und Preise von dieser Seite extrahieren“), und Thunderbits KI erledigt den Rest.
- KI-Feldvorschläge: Mit „KI-Felder vorschlagen“ scannt Thunderbit die Seite, schlägt die besten Spalten vor und richtet den Crawler automatisch ein.
- 2-Klick-Workflow: Felder ausgewählt? Einmal auf „Scrapen“ klicken – fertig. Kein Programmieren, keine Vorlagen, kein Ärger mit Selektoren.
- Automatische Paginierung & Unterseiten: Thunderbit erkennt und navigiert durch mehrseitige Listen und folgt Links zu Detailseiten, um deine Daten zu vervollständigen.
- Sofort-Export: Exportiere deine Daten direkt nach Excel, Google Sheets, Airtable oder Notion – oder lade sie als CSV/JSON herunter, alles kostenlos.
- OCR für PDFs & Bilder: Du brauchst Daten aus einem PDF, Bild oder Scan? Thunderbits integrierte Texterkennung (OCR) extrahiert und strukturiert auch diese Inhalte.
Thunderbit ist für alle gemacht, die keine Technikfreaks sind – wer surfen und einen Satz tippen kann, kann auch Websites crawlen. Und ja, es gibt eine , mit der du risikofrei starten kannst.
Website-Crawlen im Vergleich: Thunderbit vs. klassische Methoden
Schauen wir uns mal an, wie Thunderbit im Vergleich zu den üblichen Alternativen abschneidet:
| Methode | Einrichtungsaufwand & Komplexität | Erforderliche Kenntnisse | Wartung & Zuverlässigkeit |
|---|---|---|---|
| Manuelles Copy-Paste | Extrem hoch, nicht skalierbar | Keine, aber fehleranfällig | 100 % manuell, bei jedem Update neu |
| Eigener Code (Python etc.) | Hoher Initialaufwand, Stunden/Tage pro Seite | Programmierkenntnisse nötig | Bricht bei Website-Änderungen, ständiger Pflegebedarf |
| Klassisches No-Code-Tool | Mittel, Point-and-Click-Einrichtung | Gering/mittel | Muss bei Layout-Änderungen angepasst werden, kommt mit dynamischen Seiten oft nicht klar |
| Thunderbit (KI-basiert) | Sehr gering, 2-Klick-Einrichtung | Keine | KI passt sich an Änderungen an, minimaler Pflegeaufwand |
Klassische Tools bringen dich oft nur halb ans Ziel: Sie scheitern an dynamischen Inhalten, Paginierung oder brauchen ständige Nacharbeit. Thunderbits KI liest die Seite wie ein Mensch, passt sich neuen Layouts an und übernimmt die schwierigen Aufgaben – damit du dich nicht mehr darum kümmern musst ().
Schritt 1: Website-Crawl mit Thunderbit einrichten
Der Einstieg ist super easy:
- Installiere die . Registriere dich kostenlos.
- Öffne die Ziel-Website. Lade die Seite, die du crawlen willst – egal ob Produktliste, Verzeichnis oder PDF.
- Thunderbit öffnen. Klick auf das Thunderbit-Icon in deiner Chrome-Leiste.
- Beschreibe deine Datenwünsche. Entweder „KI-Felder vorschlagen“ nutzen oder einfach in natürlicher Sprache eingeben (z. B. „Produktname, Preis und Bild-URL für jeden Artikel extrahieren“).
- Vorschau prüfen und anpassen. Thunderbit zeigt eine Vorschau-Tabelle – Feldnamen bearbeiten, Spalten entfernen oder eigene Anweisungen ergänzen.
Tipp: Sei in deinen Prompts klar und knapp. Nenne die Datenpunkte so, wie sie auf der Seite stehen („Preis“, „Adresse“ etc.) – Thunderbits KI macht den Rest.
Schritt 2: Paginierung und Unterseiten beim Crawlen meistern
Hier zeigt Thunderbit, was es kann. Die meisten Daten sind nicht auf einer Seite, sondern über mehrere Seiten oder Unterseiten verteilt.
- Paginierung: Thunderbit erkennt automatisch „Weiter“-Buttons, Seitennummern oder Endlos-Scroll. Beim Klick auf „Scrapen“ lädt es alle Seiten nach und nach – du musst keine URLs eingeben oder manuell durchklicken.
- Unterseiten-Crawling: Du brauchst mehr Details? Nach dem Hauptcrawl einfach „Unterseiten scrapen“ wählen. Thunderbit folgt Links (z. B. zu Produktdetails oder Firmenprofilen), extrahiert Zusatzinfos und fügt sie deiner Tabelle hinzu.
Beispiel: Du crawlst einen Online-Shop? Thunderbit holt die Produktliste, besucht dann jede Detailseite und sammelt Spezifikationen, Bewertungen oder Bilder – alles in einem Rutsch.
Best Practice: Lass Thunderbit erst den Hauptcrawl abschließen, dann nutze das Unterseiten-Feature für tiefere Daten. Du siehst den Fortschritt und erkennst fehlende Einträge sofort.
Schritt 3: Intelligente Extraktion unstrukturierter Daten mit Thunderbit
Nicht alle Daten liegen schön in Tabellen vor. Produktbeschreibungen, Bewertungen oder gemischte Felder sind für klassische Scraper oft ein Problem. Thunderbits KI geht das gezielt an:
- Daten bereinigen & formatieren: Entfernt Währungssymbole, erkennt Zahlen, trennt komplexe Felder (z. B. „USD 299 (50 % Rabatt)“ wird zu „299“ und „50 % Rabatt“).
- Komplexe Texte parsen: Holt strukturierte Infos aus Fließtexten (z. B. „Standort: Berlin“ in einer Stellenanzeige).
- Kategorisieren & labeln: Fügt je nach Inhalt Kategorien oder Tags hinzu (z. B. „Elektronik“ vs. „Bekleidung“).
- Mit Unstimmigkeiten umgehen: Passt sich fehlenden Feldern oder Layout-Änderungen an, damit deine Daten konsistent und korrekt bleiben.
- Zusammenfassen oder übersetzen: Du brauchst eine Kurzfassung oder Übersetzung? Einfach als Anweisung ergänzen – Thunderbits KI macht das.
Das Ergebnis: Saubere, sofort nutzbare Daten – kein stundenlanges Nachbearbeiten in Excel mehr.
Schritt 4: Cloud-Crawling oder Browser-Crawling – was passt besser?
Thunderbit bietet zwei Crawling-Optionen, je nach Bedarf:
- Browser-Crawling: Läuft direkt im Chrome-Browser und nutzt deine eingeloggte Sitzung. Ideal für Seiten mit Login oder starkem Bot-Schutz. Du siehst den Crawl live und das Verhalten ist wie echtes Surfen.
- Cloud-Crawling: Die Arbeit läuft auf Thunderbits Servern. Bis zu 50 Seiten gleichzeitig – perfekt für große Projekte oder geplante Aufgaben. Du kannst den Laptop zuklappen und Thunderbit macht weiter.
Wann was nutzen?
- Browser-Modus: Für Seiten mit Login oder wenn du mit der Seite interagieren musst.
- Cloud-Modus: Für öffentliche Seiten, große Datenmengen oder wenn du maximale Geschwindigkeit und Automatisierung willst.
Der Wechsel ist easy – einfach vor dem Start den gewünschten Modus auswählen.
Schritt 5: Daten aus Dokumenten und Bildern per OCR extrahieren
Manchmal stecken die gesuchten Daten in PDFs, Bildern oder Scans. Thunderbits integrierte Texterkennung (OCR) macht Schluss mit Abtippen:
- PDFs: Tabellen, E-Mails oder Texte aus Berichten, Rechnungen oder Katalogen extrahieren.
- Bilder: Text aus Screenshots, Produktetiketten oder Infografiken auslesen.
- Gescanntes: Automatisierte Datenerfassung aus Quittungen, Verträgen oder Visitenkarten.
Einfach die PDF- oder Bild-URL angeben – Thunderbit extrahiert und strukturiert die Inhalte, ganz ohne Zusatzsoftware. Du kannst OCR sogar mit KI-Prompts kombinieren („Finde alle E-Mail-Adressen in diesem PDF“).
Schritt 6: Export und Nutzung deiner gecrawlten Daten
Nach dem Crawl kannst du deine Daten direkt weiterverwenden:
- Export-Optionen: Download als CSV oder JSON, oder direkter Export nach . Alle Formate sind auch im Gratis-Tarif verfügbar.
- Vertrieb & CRM: Lead-Listen ins CRM importieren, Kampagnen starten oder bestehende Kontakte anreichern.
- Marketing & Analyse: Wettbewerberpreise analysieren, Markttrends verfolgen oder Daten in Dashboards visualisieren.
- Operations & Bestand: Lagerbestände überwachen, Kataloge aktualisieren oder Benachrichtigungen bei Änderungen auslösen.
- Automatisierung: Mit Integrationen (z. B. Zapier oder Google Apps Script) Folgeaktionen, Berichte oder Datenanreicherung automatisieren.
Dank Thunderbits strukturierter Ausgabe kannst du in Minuten – nicht Tagen – von der Datensammlung zur Umsetzung wechseln.
Fazit & wichtigste Erkenntnisse
Effizientes Website-Crawlen ist kein Techniktraum, sondern ein echter Business-Booster. Mit Thunderbit kannst du:
- In Sekunden einen Crawl einrichten – per Spracheingabe oder KI-Feldvorschlag.
- Komplexe Seiten meistern – mit Paginierung, Unterseiten und dynamischen Inhalten, ganz ohne Code.
- Saubere, strukturierte Daten extrahieren – auch aus unübersichtlichen Webseiten, PDFs und Bildern.
- Den passenden Modus wählen – Browser oder Cloud, je nach Tempo, Umfang und Sicherheit.
- Daten sofort exportieren – in deine bevorzugten Tools und Workflows.
Die Zeiten von endlosem Copy-Paste und fehleranfälligen Scraper-Skripten sind vorbei. , kostenlosen Crawl starten und erleben, wie viel Zeit (und Nerven) du sparst. Dein nächster großer Aha-Moment – oder Vertriebserfolg – ist nur einen Klick entfernt.
Mehr Tipps und Praxisbeispiele? Im findest du Anleitungen, Use Cases und alles rund um KI-gestütztes Website-Crawlen.
FAQs
1. Was ist der Unterschied zwischen Website-Crawlen und Web-Scraping?
Website-Crawlen bedeutet, systematisch Websites zu durchsuchen und Seiten sowie Links zu entdecken. Web-Scraping bezieht sich auf das gezielte Extrahieren bestimmter Daten von diesen Seiten. Thunderbit vereint beides – findet, navigiert und extrahiert die gewünschten Informationen.
2. Kann Thunderbit auch Websites mit Login crawlen?
Klar! Nutze den Browser-Modus von Thunderbit, um Seiten mit Login zu crawlen. Dabei wird deine eingeloggte Chrome-Sitzung verwendet, sodass du auch auf geschützte Daten zugreifen kannst (sofern das laut Nutzungsbedingungen erlaubt ist).
3. Wie geht Thunderbit mit Paginierung und Endlos-Scroll um?
Thunderbit erkennt und navigiert automatisch durch paginierte Listen und Endlos-Scroll-Seiten. Es klickt auf „Weiter“, scrollt oder lädt mehr Inhalte, bis alle Daten erfasst sind – ganz ohne manuelle Einrichtung.
4. Welche Datentypen kann Thunderbit extrahieren?
Thunderbit kann Texte, Zahlen, Datumsangaben, URLs, E-Mails, Telefonnummern, Bilder und sogar Daten aus PDFs und Bildern per OCR extrahieren. Du kannst Felder individuell anpassen und mit KI-Prompts für fortgeschrittene Strukturierung und Bereinigung sorgen.
5. Ist Thunderbit kostenlos nutzbar?
Thunderbit bietet eine kostenlose Version, mit der du eine begrenzte Anzahl an Seiten crawlen kannst. Alle Exportformate (CSV, Excel, Google Sheets, Airtable, Notion) sind inklusive. Bezahlpläne starten ab 15 $/Monat für größere Volumen und erweiterte Funktionen.
Bereit für smarteres Crawlen? und lass die KI die Arbeit für dein nächstes Webdaten-Projekt übernehmen. Mehr erfahren