Ich erinnere mich noch ganz genau an mein erstes Datenprojekt: Ich sollte ein paar Dutzend Produktseiten analysieren. Mit einer großen Tasse Kaffee, einer geöffneten Tabelle und viel Elan ging’s los – aber nach zwei Stunden war ich immer noch am Kopieren und Einfügen, die Finger schon ganz steif und die Augen müde. Wer schon mal versucht hat, Infos von einer langen Liste an Webseiten händisch zu sammeln, weiß: Das dauert ewig, ist fehleranfällig und macht einfach keinen Spaß.
Genau deshalb bin ich ein echter Fan von Bulk Scraping – und bei haben wir es uns zur Mission gemacht, das Extrahieren von Daten aus vielen URLs so einfach wie möglich zu machen. In diesem Guide zeige ich dir, was Bulk Scraping eigentlich ist, warum es für Unternehmen so wichtig ist, wie sich die Technik entwickelt hat und wie du mit Thunderbit in wenigen Klicks von „Ich hab 200 URLs“ zu „Hier ist meine fertige Tabelle“ kommst – ganz ohne Programmieren, Vorlagen oder Frust.
Was ist Bulk Scraping? Die Basics des Bulk Web Scraping
Fangen wir mal ganz vorne an. Bulk Scraping (auch List Crawling oder URL Scraping genannt) bedeutet, dass du Daten aus einer ganzen Liste von Webseiten auf einmal extrahierst – statt Seite für Seite einzeln abzuarbeiten. Anstatt jeden Link zu öffnen, die Infos zu kopieren und in eine Tabelle zu packen (und das immer und immer wieder), gibst du beim Bulk Scraping einfach deine URL-Liste in ein Tool ein, das die Arbeit für dich übernimmt.
Stell dir Bulk Scraping wie einen superflinken, nie müden Assistenten vor, der jede Seite deiner Liste besucht und die relevanten Daten direkt in eine Tabelle überträgt. Es ist Web-Scraping – aber eben im großen Stil. Im Unterschied zum klassischen Web-Scraping, das meist auf einzelne Seiten oder das schrittweise Durchsuchen einer Website abzielt, gibst du beim URL Scraping dem Tool direkt eine Liste: „Hier sind meine Links – hol mir die Daten.“
Technisch gesehen ist es wie der Unterschied zwischen dem Kopieren einer einzelnen Tabellenzeile und dem Importieren einer kompletten Tabelle auf einmal. Bulk Scraping ist quasi der „Importieren“-Button fürs Web.
Mehr dazu findest du in .
Warum ist Bulk Scraping für Unternehmen so wichtig?
Mal ehrlich: Niemand freut sich darauf, Daten von 100 Webseiten per Hand zu kopieren. Aber für Teams in Vertrieb, E-Commerce, Operations oder Forschung gehört das Sammeln von Webdaten zum Alltag. Bulk Scraping ist dabei kein Buzzword, sondern ein echter Produktivitäts-Booster.
Warum?
- Geschwindigkeit: Was früher Stunden oder Tage dauerte, geht jetzt in Minuten oder sogar Sekunden ().
- Genauigkeit: Automatisierung reduziert Fehler und sorgt für einheitliche Daten.
- Skalierbarkeit: 200 Produktseiten? 500 Immobilienanzeigen? Mit Bulk Scraping kein Problem.
- Mehrwert: Unternehmen, die auf moderne, KI-gestützte Web-Scraper umsteigen, sparen bis zu 30–40 % Zeit bei der Datenerfassung ().
Typische Anwendungsfälle:
| Anwendungsfall | Problem bei Handarbeit | Vorteil von Bulk Scraping |
|---|---|---|
| Lead-Generierung | Kontaktdaten einzeln kopieren dauert ewig | Tausende Leads auf einmal extrahieren, Tabelle mit Namen, E-Mails, Telefonnummern füllen |
| Preisbeobachtung bei Wettbewerbern | Tägliches Prüfen der Konkurrenzseiten | Alle Produkt-URLs auf Preisänderungen überwachen, schneller reagieren |
| Markt-/Content-Research | Viele Artikel/Bewertungen manuell lesen | Daten aus mehreren Artikeln oder Reviews gleichzeitig extrahieren, größere und aktuellere Datensätze |
| Produktdaten-Management | Infos aus verschiedenen Quellen zusammenführen ist fehleranfällig | Spezifikationen, Lagerbestand etc. von allen Lieferanten konsistent in einer Datei |
| Immobilienanzeigen | Manuelles Sammeln dauert Stunden | Dutzende Inserate von verschiedenen Seiten für einen aktuellen Gesamtüberblick zusammenführen |
Fazit: Bulk Web-Scraping steigert die Effizienz und ermöglicht datenbasierte Entscheidungen – egal ob Vertrieb, Marketing, Operations oder Forschung ().
Bulk Scraping im Vergleich: Von Handarbeit bis KI-Tools
Bulk Scraping hat sich rasant weiterentwickelt. Schauen wir uns die wichtigsten Methoden an – vom „alten Weg“ bis zu modernen KI-Lösungen – und warum Thunderbit hier besonders ist.
Manuelles Bulk Scraping: Die klassische Methode
Erinnerst du dich an meine Copy-Paste-Odyssee? Das ist manuelles Bulk Scraping: Jede Seite öffnen, Infos kopieren, in Excel einfügen, wiederholen. Für fünf URLs machbar – für 50 oder mehr kaum noch. Es dauert, ist eintönig und Fehler oder verpasste Updates sind vorprogrammiert ().
Vorlagenbasierte und Code-basierte Bulk Scraping Tools
Nächster Schritt: Skripte (z. B. Python mit BeautifulSoup) oder Tools mit Vorlagen. Wer programmieren kann, schreibt ein Skript, das alle URLs abarbeitet und die gewünschten Daten extrahiert. Sehr mächtig, aber eben nur für Entwickler – und sobald sich die Website ändert, muss das Skript angepasst werden.
Vorlagenbasierte Tools erlauben es, Felder auf einer Seite visuell auszuwählen und diese „Vorlage“ dann auf ähnliche Seiten anzuwenden. Praktisch für Nicht-Programmierer, aber für jede neue Seite oder Struktur muss eine eigene Vorlage gebaut werden. Kommen die URLs von verschiedenen Seiten oder sind unterschiedlich aufgebaut, wird es schnell kompliziert.
Thunderbits One-Click-Bulk-Scrape: Einfacher geht’s nicht
Hier setzt Thunderbit an. Unser Ansatz: URL-Liste einfügen, einmal klicken, strukturierte Daten erhalten – ohne Vorlagen, ohne Code, ohne Aufwand. Die KI erkennt anhand deiner Spaltennamen oder Vorschläge, welche Daten extrahiert werden sollen. Selbst bei leicht unterschiedlichen Seiten passt sich Thunderbit flexibel an.
Im Vergleich:
| Methode | Benutzerfreundlichkeit | Flexibilität | Technisches Know-how nötig | Einrichtungsaufwand | Geschwindigkeit | Verschiedene Seitentypen möglich? |
|---|---|---|---|---|---|---|
| Manuelles Copy-Paste | Gering | Hoch | Keins | Hoch | Langsam | Ja (aber mühsam) |
| Code-Skript | Gering | Sehr hoch | Hoch | Hoch | Schnell | Ja (wenn programmiert) |
| Vorlagenbasiertes Tool | Mittel | Mittel | Gering | Mittel | Schnell | Nur bei ähnlichen Seiten |
| Thunderbit (KI-Bulk) | Sehr hoch | Hoch | Keins | Niedrig | Sehr schnell | Ja |
Praxisbeispiel: 100 Produkt-URLs manuell zu scrapen dauert Stunden, mit einem Vorlagen-Tool vielleicht eine Stunde – mit Thunderbit nur wenige Minuten ().
Schritt-für-Schritt: So funktioniert Bulk Scraping mit Thunderbit
Jetzt wird’s praktisch. So kannst du mit eine Liste von URLs in wenigen Schritten auslesen – ganz ohne Vorkenntnisse.
Schritt 1: Thunderbit Chrome-Erweiterung installieren
Lade zuerst die herunter. Such einfach nach „Thunderbit KI-Web-Scraper“ im Chrome Web Store oder geh auf unsere . Klicke auf „Zu Chrome hinzufügen“, bestätige – fertig. Über vertrauen bereits auf Thunderbit.
Du musst dich eventuell registrieren oder einloggen – keine Sorge, mit dem kostenlosen Tarif kannst du Bulk Scraping direkt ausprobieren.
Schritt 2: Deine URL-Liste vorbereiten
Sammle jetzt deine URLs. Zum Beispiel:
- Export aus einem CRM oder einer Tabelle
- Produktseiten-Links von einer Konkurrenzseite kopieren
- LinkedIn-Profil-URLs für die Lead-Generierung sammeln
- Manuell gewünschte Links zusammenstellen
Formatier die Liste einfach – eine URL pro Zeile in einer Textdatei oder Tabelle. Zum Beispiel:
1https://www.example.com/product/123
2https://www.example.com/product/456
3https://www.example.com/product/789Tipp: Entferne doppelte Einträge und schau, dass die Seiten erreichbar sind (bei Login-Seiten muss Thunderbit ebenfalls eingeloggt sein).
Schritt 3: URLs einfügen und Bulk Scrape starten
Jetzt geht’s los:
- Klicke auf das Thunderbit-Icon in deiner Chrome-Leiste.
- Wähle als Datenquelle „URLs“ oder „URL-Liste“.
- Füge deine URLs in das Eingabefeld ein (oder lade eine CSV hoch).
- Klicke auf „KI schlägt Spalten vor“ – Thunderbits KI analysiert eine der Seiten und schlägt passende Felder vor (z. B. „Produktname“, „Preis“, „E-Mail“ usw.).
- Passe die Spalten bei Bedarf an oder ergänze eigene.
- Klicke auf „Scrapen“. Thunderbit besucht jede URL, extrahiert die Daten und erstellt eine Tabelle.
Du kannst währenddessen in anderen Tabs weiterarbeiten. Bei großen Listen arbeitet Thunderbit mit mehreren Threads und hält sich an Geschwindigkeitslimits, um Blockierungen zu vermeiden.
Schritt 4: Ergebnisse prüfen und exportieren
Nach Abschluss zeigt Thunderbit die Ergebnisse als Tabelle an. Jede Zeile entspricht einer Seite, jede Spalte einem von dir definierten Feld.
Exportmöglichkeiten:
- In die Zwischenablage kopieren oder als CSV herunterladen (ideal für Excel oder Google Sheets)
- Direkter Export zu Google Sheets, Airtable oder Notion (mit nur einem Klick)
- Als JSON herunterladen (für Entwickler oder komplexe Workflows)
Du kannst deine Scraper-Vorlage auch für spätere Projekte speichern.
Schritt 5: Tipps & Tricks für besseres Bulk Scraping
Auch mit KI kann es beim Web Scraping zu Problemen kommen. Hier ein paar Hinweise:
- Einige URLs wurden nicht gescrapt? Prüfe, ob ein Login nötig ist oder die Seiten ungewöhnlich aufgebaut sind. Nutze ggf. Thunderbits „Browser-Modus“.
- Daten fehlen in einer Spalte? Benenne die Spalte eindeutiger oder nutze die „Custom Instruction“-Funktion von Thunderbit, um die KI gezielt zu steuern.
- Große Listen langsam? Teile sie in kleinere Blöcke (z. B. je 200 URLs) oder nutze Thunderbits Cloud-Scraping.
- Blockierungen vermeiden: Nicht zu schnell scrapen, Pausen einbauen und die
robots.txtsowie die Nutzungsbedingungen der Website beachten. - Mehr Daten von Unterseiten nötig? Aktiviere das Subpage Scraping, um z. B. Produktbewertungen oder Autorenprofile mitzuerfassen.
Weitere Hilfe findest du in der und beim Support.
Erweiterte Bulk Scraping Features: Subpage Scraping, Zeitplanung & mehr
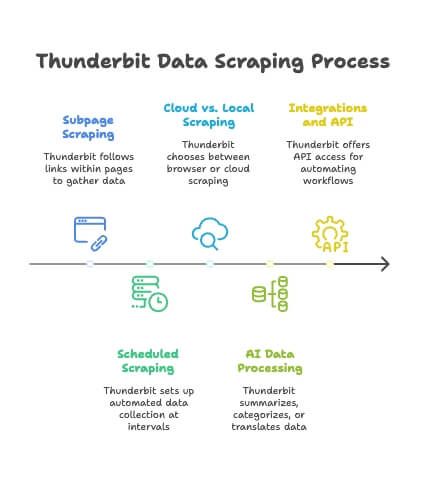
Thunderbit kann mehr als nur Einmal-Scrapes. Hier ein paar Profi-Features, die Bulk Scraping noch mächtiger machen:
- Subpage Scraping: Thunderbit folgt Links innerhalb jeder Seite (z. B. „Bewertungen“-Tabs oder Autorenprofile) und fügt die Daten automatisch in deine Haupttabelle ein. Die KI erkennt verschiedene Unterseitenstrukturen – ohne Zusatzaufwand ().
- Geplanter Scraper: Du brauchst täglich frische Daten? Richte einen geplanten Bulk Scrape ein (stündlich, täglich, wöchentlich) – deine Google-Tabelle oder Datenbank aktualisiert sich automatisch.
- Cloud- vs. lokales Scraping: Standardmäßig läuft Thunderbit im Browser, für große Jobs kannst du aber auch Cloud Scraping nutzen.
- KI-Datenverarbeitung: Thunderbit kann Daten beim Scrapen zusammenfassen, kategorisieren oder übersetzen – für direkt nutzbare, angereicherte Datensätze.
- Integrationen & API: Für Profis gibt’s API-Zugänge und Integrationsmöglichkeiten, um Scraping-Workflows zu automatisieren.
Mehr dazu in den .
Bulk Scraping für verschiedene Teams: Vertrieb, E-Commerce, Immobilien & mehr
Bulk Scraping ist nicht nur was für Daten-Nerds (auch wenn wir eine coole Community sind). So nutzen verschiedene Teams die Technik:
- Vertrieb: LinkedIn- oder Branchenverzeichnis-Profile für Leads scrapen. Listen mit Namen, Titeln, E-Mails etc. direkt ins CRM importieren.
- E-Commerce: Preise, Lagerbestand und Produktdetails der Konkurrenz auf Hunderten Seiten überwachen. Mit geplanten Scrapes bleibt deine Preisstrategie immer aktuell.
- Marktforschung: News-Artikel, Bewertungen oder Forenbeiträge für Trendanalysen sammeln. Größere und aktuellere Datensätze liefern bessere Insights.
- Operations: Spezifikationen, Compliance-Infos oder Lieferantendaten automatisch und regelmäßig von verschiedenen Seiten erfassen.
- Immobilien: Immobilienanzeigen von Portalen wie Zillow oder bündeln – für einen Gesamtüberblick in einer Tabelle.
Tipp: Für wiederkehrende Aufgaben Vorlagen speichern und Scrapes planen. Für einmalige Recherchen einfach URLs einfügen und loslegen.
Best Practices für Bulk Scraping: Organisation & Compliance
Mit großer Scraping-Power kommt auch Verantwortung. So bleibst du organisiert und rechtlich auf der sicheren Seite:
- Daten organisieren: Klare Dateinamen (z. B.
leads_scraped_Aug2025.csv), Zeitstempel und Quellen dokumentieren. - Bereinigen & Duplikate entfernen: Doppelte Einträge löschen, Daten prüfen und offensichtliche Fehler vor der Analyse korrigieren.
- Website-Regeln beachten: Nur öffentlich zugängliche Daten scrapen und immer die Nutzungsbedingungen sowie
robots.txtder Seite prüfen. - Personenbezogene Daten sensibel behandeln: Bei E-Mails oder Namen auf Datenschutz (z. B. DSGVO) achten und keine sensiblen Infos missbrauchen.
- Fair bleiben: Websites nicht überlasten – Scraping-Geschwindigkeit anpassen und möglichst außerhalb der Stoßzeiten scrapen.
Mehr dazu in .
Fazit & wichtigste Erkenntnisse
Bulk Scraping ist heute unverzichtbar für alle, die Webdaten in großem Stil brauchen. Mit Thunderbit brauchst du weder Programmierkenntnisse noch Vorlagen oder Excel-Tricks. Einfach URLs einfügen, klicken – und die Daten sind da.
Die wichtigsten Vorteile von Bulk Scraping mit Thunderbit:
- Einfache Bedienung: Keine technischen Vorkenntnisse nötig – einfach einfügen und starten ().
- Schnelligkeit & Skalierbarkeit: Tausende Datenpunkte in Minuten statt Stunden sammeln ().
- Flexibilität: Funktioniert auf fast jeder Website, die KI passt sich verschiedenen Layouts an ().
- Datenqualität: KI-gestützte Extraktion sorgt für präzise, direkt nutzbare Daten ().
- Teams stärken: Vertrieb, Marketing, Operations und Forschung erhalten die Daten, die sie brauchen – ohne IT-Umwege ().
Neugierig geworden? , mit dem du Bulk Scraping direkt ausprobieren kannst. Überleg dir, bei welcher Datenaufgabe du dir schon lange eine schnelle Lösung wünschst – und probier’s einfach aus. Vielleicht erledigst du in wenigen Minuten, was sonst Wochen dauert.
Webdaten im großen Stil zu nutzen, verschafft dir einen echten Wettbewerbsvorteil. Mit Bulk Scraping und Tools wie Thunderbit ist dieser Vorteil jetzt für alle erreichbar. Viel Erfolg beim Scrapen – und lass Copy & Paste endgültig hinter dir.
Du willst mehr über Web-Scraping, List Crawling oder fortgeschrittene Scraping-Techniken erfahren? Schau im vorbei und entdecke unsere Deep Dives:
Oder abonniere unseren für Tutorials und Tipps.
Häufige Fragen (FAQ)
1. Was ist Bulk Web Scraping und wie unterscheidet es sich vom klassischen Scraping?
Bulk Web Scraping – auch URL Scraping oder List Crawling genannt – bedeutet, Daten aus einer vordefinierten Liste von Webseiten gleichzeitig zu extrahieren. Im Gegensatz zum klassischen Scraping, das meist ganze Websites oder einzelne Seiten nacheinander durchsucht, kannst du beim Bulk Scraping eine Liste von URLs einfügen und gezielt bestimmte Datenfelder aus jeder Seite extrahieren – ideal für Produktseiten, Verzeichnisse oder Listings.
2. Wer profitiert am meisten von Bulk Scraping?
Bulk Scraping ist für viele Teams und Branchen nützlich. Vertriebsteams nutzen es zur Lead-Generierung, indem sie Kontaktdaten aus LinkedIn oder Verzeichnissen extrahieren. E-Commerce-Unternehmen überwachen damit Preise und Lagerbestände der Konkurrenz. Immobilienmakler bündeln Inserate, Marktforscher sammeln Bewertungen oder Artikel in großen Mengen. Kurz: Wer strukturierte Daten aus vielen URLs braucht, profitiert.
3. Was unterscheidet Thunderbit von anderen Bulk Scraping Tools?
Thunderbit überzeugt durch eine komplett codefreie, KI-gestützte Bedienung. Im Gegensatz zu klassischen Tools, die Programmierung oder Vorlagen erfordern, kannst du bei Thunderbit einfach eine URL-Liste einfügen und mit einem Klick strukturierte Daten extrahieren. Unterschiedliche Seitentypen werden erkannt, Felder automatisch vorgeschlagen, Subpage Scraping ist möglich und die Integration mit Google Sheets, Airtable und Notion ist direkt eingebaut.
4. Welche Daten kann Thunderbit beim Bulk Scraping extrahieren?
Thunderbit kann Produktnamen, Preise, Lagerstatus, Kontaktdaten (E-Mail, Telefon), Titel, Bewertungen, Spezifikationen und vieles mehr extrahieren. Die KI erkennt relevante Felder anhand deiner Spaltenvorgaben oder der Seitenstruktur. Du kannst sogar Unterseiten scrapen, Inhalte übersetzen oder zusammenfassen – alles direkt im Extraktionsprozess.
5. Ist Bulk Scraping legal und sicher für Unternehmen?
Bulk Scraping ist legal, wenn es verantwortungsvoll und im Rahmen der Gesetze erfolgt. Du solltest nur öffentlich zugängliche Daten scrapen, die robots.txt und die Nutzungsbedingungen der Website beachten und keine personenbezogenen Daten ohne Einwilligung sammeln. Thunderbit unterstützt Compliance durch regulierte Scraping-Geschwindigkeiten, Login-Support und Funktionen zur verantwortungsvollen Datenorganisation.