Webdaten sind heutzutage so wertvoll wie Gold – aber sie sind über unzählige Webseiten verstreut, oft tief im unübersichtlichen HTML versteckt und werden von CAPTCHAs oder cleveren Anti-Bot-Systemen geschützt. Wer schon mal versucht hat, Produktpreise, Wettbewerberinfos oder Leads per Copy & Paste zu sammeln, weiß: Das ist nicht nur nervig, sondern auch eine echte Zeitverschwendung. Genau deshalb ist der Einsatz von Web-Scraping für Unternehmen heute ein echter Gamechanger. Kein Wunder, dass der Markt für alternative Daten (inklusive Web-Scraping) wert war – und das Wachstum geht weiter.

Jetzt kommt der spannende Teil: Während Python oft als die Einsteiger-Sprache für Web Scraping gilt, setzen viele der schnellsten und stabilsten Scraper weltweit auf Go (auch Golang genannt). Was macht Go so besonders? Die Sprache punktet mit extrem effizienter Parallelisierung, einer starken Standardbibliothek und einer Performance, die Backend-Entwickler begeistert. Ich habe schon Teams erlebt, die durch den Wechsel zu Go ihre Scraping-Zeiten halbiert haben – und mit den richtigen Tools klappt der Einstieg auch ohne Google-Background.
Willst du Go zu deinem Web Scraping-Turbo machen? Hier findest du die fünf wichtigsten Schritte – von der Einrichtung bis zu fortgeschrittenen Techniken, inklusive Praxistipps, Codebeispielen und einem Blick darauf, wie KI-Tools wie deinen Workflow aufs nächste Level bringen.
Warum Go für Web Scraping? Die Business-Perspektive
Gerade wenn du tausende oder sogar Millionen von Seiten scrapen willst, zählt jede Sekunde. Go ist genau für solche Aufgaben gemacht. Deshalb setzen immer mehr Unternehmen auf Go für Web Scraping:
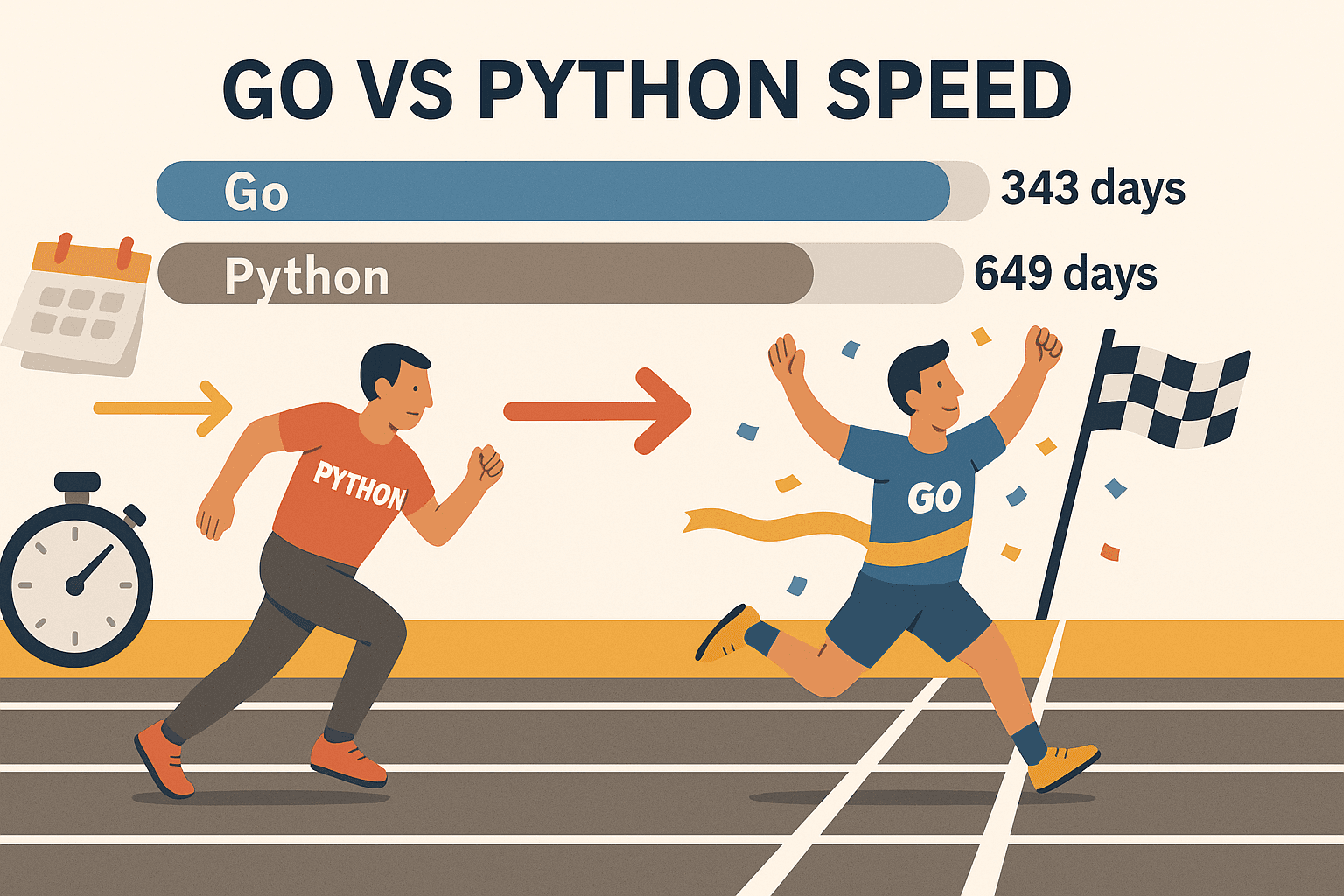
- Skalierbare Parallelität: Mit Go’s Goroutines (leichte Threads) kannst du hunderte Seiten gleichzeitig scrapen – ohne dass dein Rechner schlappmacht. In einem Benchmark hat Go verarbeitet, während Python für die gleiche Menge 649 Tage brauchte. Das ist nicht nur schneller – das ist eine ganz andere Liga.
- Stabilität und Zuverlässigkeit: Dank starker Typisierung und effizientem Speichermanagement ist Go ideal für große, langlaufende Crawler. Keine bösen Überraschungen mehr mitten in der Nacht.
- Erstklassige Netzwerkfunktionen: Die Standardbibliothek von Go bietet alles, was du für HTTP-Anfragen, HTML-Parsing und JSON brauchst – ohne auf externe Pakete angewiesen zu sein.
- Einfache Bereitstellung: Go-Programme werden zu einer einzigen ausführbaren Datei kompiliert. Du kannst deinen Scraper überall laufen lassen – ganz ohne virtuelle Umgebungen oder Abhängigkeitsprobleme.
- Branchenstandard: Go ist inzwischen die (vor Node.js) und wird von Unternehmen wie Google, Uber und Netflix eingesetzt.
Natürlich bleibt Python eine gute Wahl für schnelle Prototypen oder wenn du auf Machine-Learning-Bibliotheken angewiesen bist. Aber wenn es auf Geschwindigkeit, Skalierbarkeit und Zuverlässigkeit ankommt, ist Go kaum zu schlagen – vor allem mit Libraries wie Colly und Goquery.
Schritt 1: Go-Umgebung für Web Scraping einrichten
Bevor du loslegst, musst du Go installieren. Die gute Nachricht: Das geht fix und unkompliziert.
1. Go installieren
- Lade den Installer für dein Betriebssystem (Windows, macOS oder Linux) von der herunter.
- Starte die Installation und folge den Anweisungen. Unter Linux kannst du auch den Paketmanager nutzen.
- Öffne ein Terminal und gib ein:
Wenn du eine Ausgabe wie1go versiongo version go1.21.0 darwin/amd64siehst, bist du startklar.
Fehlerbehebung: Falls go nicht gefunden wird, prüfe deine PATH-Variable. Unter Linux/macOS ggf. export PATH=$PATH:/usr/local/go/bin in die ~/.bash_profile oder ~/.zshrc eintragen.
2. Neues Go-Projekt anlegen
- Erstelle ein neues Verzeichnis für deinen Scraper:
1mkdir my-scraper && cd my-scraper - Initialisiere ein Go-Modul:
Dadurch wird eine1go mod init github.com/yourname/my-scrapergo.mod-Datei für die Abhängigkeitsverwaltung angelegt.
3. Editor wählen
- mit Go-Erweiterung ist super (Auto-Vervollständigung, Linting, Debugging).
- JetBrains GoLand ist bei Go-Profis beliebt.
- Vim/Neovim mit Go-Plugins funktioniert für Puristen.
4. Testlauf
Erstelle eine schnelle main.go:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go ist installiert und läuft!")
5}Starte das Programm:
1go run main.goWenn die Nachricht erscheint, bist du bereit.
Schritt 2: Erste HTTP-Anfrage mit Go stellen
Jetzt holen wir uns die erste Webseite! Mit Go’s net/http-Paket ist das ganz easy.
Beispiel für einen einfachen HTTP-GET:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Fehler beim Abrufen der URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Fehler beim Lesen der Antwort:", err)
17 return
18 }
19 fmt.Println(string(body))
20}Wichtige Hinweise:
- Nach jedem
http.Getauf Fehler prüfen. - Mit
defer resp.Body.Close()Ressourcen freigeben. - Mit
io.ReadAllden gesamten Inhalt lesen.
Profi-Tipps:
- Um eigene Header (z.B. User-Agent) zu setzen, nutze
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - Immer
resp.StatusCodeprüfen – 200 bedeutet Erfolg, 403 oder 404 deuten auf Blockierung oder fehlende Seite hin.
Schritt 3: HTML parsen und Daten extrahieren mit Go
Das rohe HTML ist erst der Anfang. Jetzt geht’s darum, die gewünschten Infos – Produktnamen, Preise, Links usw. – herauszufiltern.
Goquery im Einsatz: Diese Go-Bibliothek bietet jQuery-ähnliche Selektoren für das HTML-Parsing.
Goquery installieren:
1go get github.com/PuerkitoBio/goqueryBeispiel: Produktnamen und Preise extrahieren
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Produkt %d: %s - %s\n", i+1, name, price)
21 })
22}So funktioniert’s:
doc.Find("div.product")wählt alle Produkt-Container aus.- Innerhalb jedes Containers holt
s.Find("h2").Text()den Produktnamen unds.Find(".price").Text()den Preis.
Reguläre Ausdrücke: Für einfache Muster (z.B. E-Mails) eignet sich Go’s regexp-Paket. Für komplexere Strukturen ist Goquery die bessere Wahl.
Schritt 4: Scraper mit Go-Bibliotheken (Colly & Gocolly) auf das nächste Level bringen
Bereit für den nächsten Schritt? ist das führende Web-Scraping-Framework für Go. Es übernimmt das Crawling, die Parallelisierung, Cookie-Verwaltung und vieles mehr – so kannst du dich voll auf die Daten konzentrieren.
Warum Colly überzeugt:
- Einfache API: Callbacks für die gewünschten Elemente registrieren.
- Parallelisierung: Mit
colly.Async(true)hunderte Seiten gleichzeitig scrapen. - Automatisches Crawling: Links und Paginierung einfach folgen.
- Anti-Bot-Features: Eigene Header setzen, User-Agents rotieren, Cookies verwalten.
- Fehlerbehandlung: Integrierte Hooks für fehlgeschlagene Anfragen.
Colly installieren:
1go get github.com/gocolly/colly/v2Beispiel für einen Colly-Scraper:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Produkt: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Anfrage fehlgeschlagen:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Feature-Vergleich: Goquery vs. Colly
| Funktion | Goquery | Colly |
|---|---|---|
| HTML-Parsing | Ja | Ja (nutzt Goquery intern) |
| HTTP-Anfragen | Manuell | Integriert |
| Parallelisierung | Manuell (Goroutines) | Einfach (Async(true)) |
| Crawling/Link-Follow | Manuell | Automatisch |
| Anti-Bot-Features | Manuell | Integriert |
| Fehlerbehandlung | Manuell | Integriert |
Colly spart dir richtig viel Zeit, sobald es über einfache Scrapes hinausgeht.
Schritt 5: Typische Herausforderungen beim Web Scraping mit Go meistern
Web Scraping in der Praxis ist selten ein Spaziergang. So gehst du die größten Hürden an:
1. IP-Blockaden
- Proxies rotieren – entweder mit Go’s
http.Transportoder Colly’s Proxy-Support. - Anfragen mit zufälligen Pausen verlangsamen.
2. User-Agent und Header
- Immer einen realistischen User-Agent setzen (z.B. Chrome oder Firefox).
- Echte Browser-Header nachahmen (Accept-Language etc.).
3. CAPTCHAs
- Wenn CAPTCHAs auftauchen, scrapest du vermutlich zu schnell oder zu auffällig.
- Nutze Headless-Browser (wie ) für Seiten, die JavaScript oder Interaktion verlangen.
- Bei besonders hartnäckigen Seiten ggf. einen CAPTCHA-Lösungsdienst einbinden.
4. Paginierung
- Mit Colly kannst du „Weiter“-Links automatisch folgen:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. Dynamische Inhalte (JavaScript)
- Go’s HTTP-Bibliotheken führen kein JavaScript aus. Nutze einen Headless-Browser (Rod, chromedp) oder greife – falls möglich – direkt auf die API-Endpunkte zu.
6. Wenn es zu kompliziert wird… Thunderbit nutzen
Manchmal stößt du an Grenzen – etwa bei sehr dynamischen Seiten oder wenn du schnell Daten brauchst, aber nicht programmieren willst. Hier kommt ins Spiel. Thunderbit ist eine KI-gestützte Web-Scraper Chrome-Erweiterung, die:
- Mit KI Felder erkennt und extrahiert – einfach auf „AI Suggest Columns“ klicken.
- Unterseiten und Paginierung automatisch abarbeitet.
- Im echten Browser (oder in der Cloud) läuft und so auch JavaScript-lastige Seiten und viele Anti-Bot-Maßnahmen meistert.
- Direkt nach Excel, Google Sheets, Airtable oder Notion exportiert – ganz ohne Code.
- Scrapes planen und die Datensammlung für dein Team automatisieren lässt.
Thunderbit ist ein echter Gamechanger für Business-Anwender, Vertriebsteams oder alle, die strukturierte Daten ohne Programmieraufwand brauchen. Und ja, ich bin voreingenommen – mein Team und ich haben es genau für diese Probleme entwickelt.
Go und Thunderbit kombinieren: Das Beste aus beiden Welten
Das Beste: Du musst dich nicht zwischen Go und Thunderbit entscheiden. Die cleversten Teams nutzen beides.
Beispiel-Workflow:
- Mit Go (und Colly) eine große Liste von URLs crawlen oder Basisdaten im großen Stil sammeln.
- Die URLs an Thunderbit übergeben, um detaillierte, strukturierte Infos zu extrahieren – besonders bei Unterseiten, dynamischen Inhalten oder schwierigen Anti-Bot-Maßnahmen.
- Die Daten aus Thunderbit nach Google Sheets oder als CSV exportieren.
- Mit Go die Daten weiterverarbeiten, zusammenführen oder analysieren.
So kombinierst du die Geschwindigkeit und Kontrolle von Go mit der Flexibilität und KI-Power von Thunderbit – wie ein Schweizer Taschenmesser und ein Akkuschrauber im Werkzeugkasten.
Go Web Scraping-Lösungen im Vergleich: Core Go vs. Colly vs. Thunderbit
Hier ein schneller Überblick, welches Tool für welchen Zweck am besten passt:
| Aspekt | Plain Go (net/http + html) | Go + Colly (Library) | Thunderbit (KI No-Code) |
|---|---|---|---|
| Einrichtung & Lernkurve | Anspruchsvoll (viel Code) | Mittel (einfachere API) | Am einfachsten (kein Code, KI) |
| Parallelisierung | Manuell (Goroutines) | Integriert (Async(true)) | Cloud/Browser-Parallelisierung |
| Dynamische Inhalte (JS) | Headless-Browser nötig | Teilweise JS, oder Rod | Vollständiger Browser, JS nativ |
| Anti-Bot-Handling | Manuell (Proxies, Header) | Integrierte Features | Meist automatisch, Cloud-IPs |
| Datenstrukturierung | Eigener Code | Callbacks, eigene Structs | KI-gestützt, automatisch formatiert |
| Exportoptionen | Individuell (CSV, DB, etc.) | Individuell | Excel, Sheets, Notion, Airtable |
| Wartung | Hoch (häufige Updates) | Mittel | Gering (KI passt sich an) |
| Am besten für | Entwickler, Speziallösungen | Entwickler, schnelles Prototyping | Nicht-Programmierer, Business-User |
Tipp: Nutze Go/Colly für individuelle, groß angelegte oder Backend-Projekte. Thunderbit ist ideal, wenn es schnell gehen soll oder du komplexe Frontend-Seiten scrapen willst.
Fazit: So startest du mit Web Scraping in Go
- Go ist ein echtes Kraftpaket für Web Scraping – besonders wenn Geschwindigkeit, Parallelisierung und Zuverlässigkeit gefragt sind.
- Starte einfach: Go-Umgebung einrichten, HTTP-Anfragen stellen, HTML mit Goquery parsen.
- Mit Colly aufrüsten: Für Crawling, Parallelisierung und Anti-Bot-Tricks ist Colly dein Freund.
- Praxisprobleme meistern: Proxies rotieren, Header setzen und bei schwierigen Seiten Headless-Browser oder Thunderbit nutzen.
- Tools kombinieren: Go und Thunderbit zusammen nutzen bringt maximale Flexibilität und Effizienz.
Web Scraping ist ein echter Hebel für Vertrieb, Operations und Research. Mit Go und den richtigen Libraries (plus etwas KI) automatisierst du Routineaufgaben und gewinnst wertvolle Einblicke für dein Business.
Weitere Ressourcen für Web Scraping mit Go
Du willst tiefer einsteigen? Hier findest du meine Favoriten:
Viel Erfolg beim Scrapen – auf dass deine Daten immer strukturiert, deine Scraper schnell und dein Kaffee stark sind.
FAQs
1. Warum sollte ich Go fürs Web Scraping statt Python oder JavaScript nutzen?
Go bietet überlegene Parallelisierung, Geschwindigkeit und Stabilität – besonders bei großen oder langlaufenden Scraping-Projekten. Ideal, wenn du tausende Seiten schnell scrapen und ein portables, kompiliertes Programm willst.
2. Was ist der einfachste Weg, HTML in Go zu parsen?
Nutze die Library. Sie bietet jQuery-ähnliche Selektoren für einfaches DOM-Parsing und Datenextraktion.
3. Wie gehe ich mit JavaScript-basierten Seiten in Go um?
Dafür brauchst du eine Headless-Browser-Library wie oder . Alternativ kannst du nutzen – eine No-Code-Lösung, die JS direkt im Browser verarbeitet.
4. Wie verhindere ich, dass ich beim Scraping geblockt werde?
User-Agent rotieren, Proxies nutzen, Pausen zwischen Anfragen einbauen und echtes Browserverhalten nachahmen. Colly macht das einfach, Thunderbit übernimmt die meisten Anti-Bot-Maßnahmen automatisch.
5. Kann ich Go und Thunderbit im Workflow kombinieren?
Absolut! Nutze Go für großflächiges Crawling oder Backend-Integration und Thunderbit für KI-gestützte Extraktion, Unterseiten-Scraping und Export in Business-Tools. Die perfekte Kombination für Entwickler und Business-Anwender.
Bereit, dein Web Scraping auf das nächste Level zu bringen? Probiere die aus oder schau im vorbei – für mehr Tipps, Tutorials und Deep Dives zu Scraping, Automatisierung und KI.