Firecrawl ist im Entwickler-Universum für KI inzwischen zu einer der meistgehypten Web-Scraping-APIs geworden — , Unterstützung durch Y Combinator und eine Kundenliste mit Shopify, Zapier und Apple. Doch wenn man Preisangaben, Nutzerbeschwerden, unabhängige Benchmarks und reale Kostenmodelle genauer betrachtet, liegen die Schlagzeilen und die tatsächliche Erfahrung ziemlich weit auseinander.
Dieser Firecrawl-Test ist keine weitere Feature-Liste. Wenn Sie sich angemeldet, ein paar Testläufe gemacht und sich nun fragen: „Was wird mich das in großem Maßstab eigentlich kosten?“ — oder wenn Sie überhaupt erst herausfinden wollen, ob Firecrawl das richtige Tool für Ihr Team ist — sind Sie hier genau richtig. Ich gehe die echten Kosten durch (einschließlich der oft übersehenen Falle der doppelten Abrechnung), zeige, wo Firecrawl wirklich stark ist, wo es schwächelt (vor allem auf botgeschützten Seiten) und wann ein völlig anderes Tool — inklusive No-Code-Optionen wie — die klügere Wahl ist. Mein Ziel: Sie vor der bösen Überraschung auf der Kreditkartenabrechnung zu bewahren.
Was ist Firecrawl und für wen ist es gemacht?
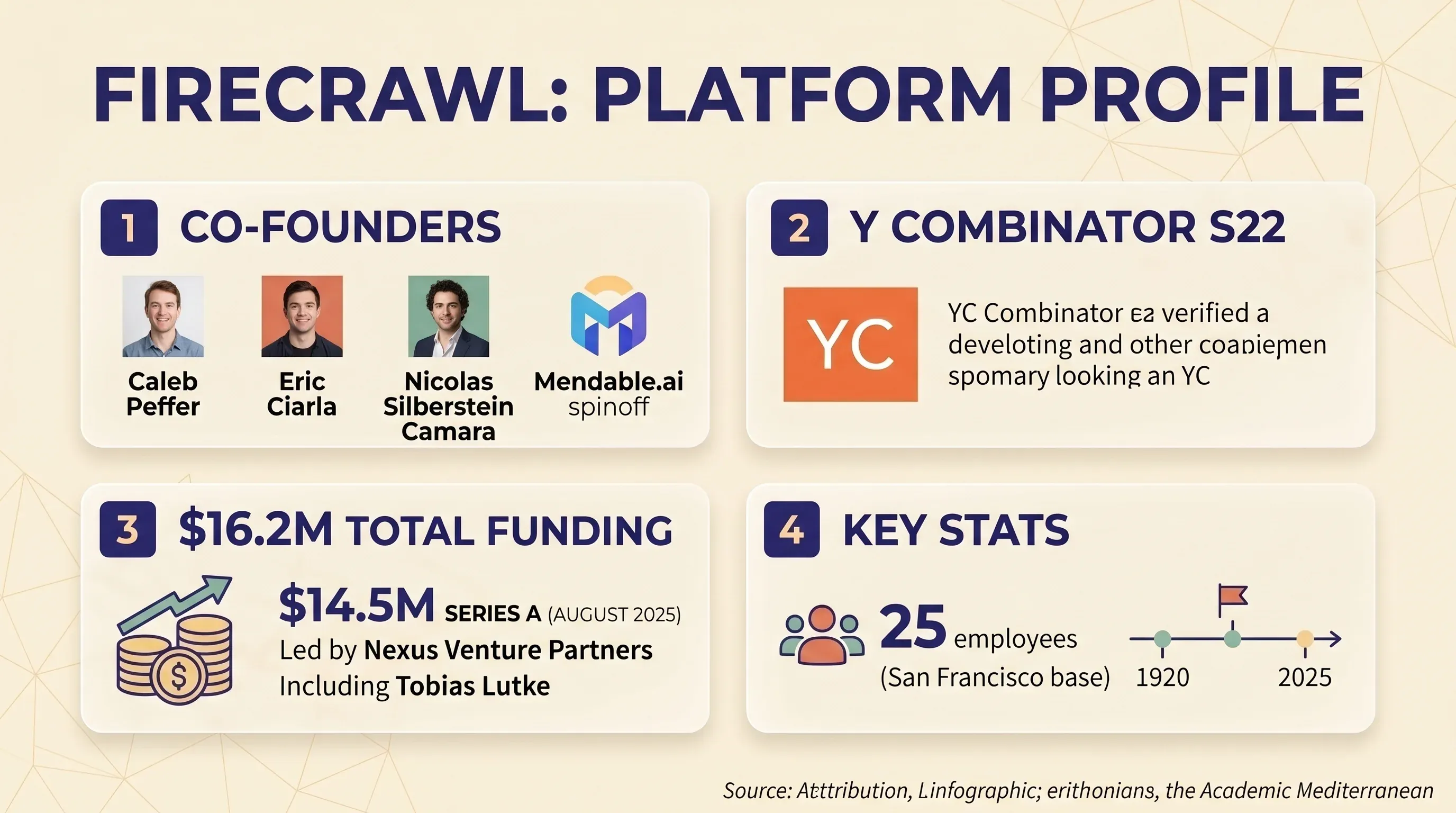
Firecrawl ist eine API-first-Plattform für Web Scraping und Crawling, die Websites in sauberes Markdown oder strukturiertes JSON umwandelt. Sie richtet sich in erster Linie an Entwickler, die KI- und LLM-Anwendungen bauen — also RAG-Pipelines, Chatbot-Wissensdatenbanken und Workflows für KI-Agenten. Das Unternehmen wurde von Caleb Peffer, Eric Ciarla und Nicolas Silberstein Camara als Spin-off aus Mendable.ai gegründet. Es durchlief und sammelte im August 2025 eine ein, angeführt von Nexus Venture Partners, mit Shopify-CEO Tobias Lütke als Teilnehmer. Gesamtfinanzierung: 16,2 Mio. US-Dollar. Das Team besteht aus 25 Personen und sitzt in San Francisco.
Firecrawl bietet vier Kernmodi plus zwei neuere Ergänzungen:
| Modus | Funktion |
|---|---|
| Scrape | Eine einzelne URL in Markdown, JSON oder einen Screenshot umwandeln |
| Crawl | Eine URL und alle Unterseiten crawlen |
| Map | Alle URLs einer Website in Sekunden entdecken (bis zu 100.000 URLs) |
| Search | Websuche mit vollständigem Abruf des Seiteninhalts |
| Extract | KI-gestützte strukturierte Extraktion per Prompt oder Schema |
| Agent (Research Preview) | Autonome Web-Recherche ohne Angabe von URLs |
Ich möchte hier gleich offen sein: Firecrawl ist ein Entwickler-Tool. Es erfordert API-Aufrufe, Programmierkenntnisse und technische Einrichtung. Wenn Sie als Business-User Daten von einer Website ziehen möchten, ohne Code zu schreiben, ist Firecrawl nicht für Sie gemacht (mehr zu Alternativen später). Aber für Dev-Teams, die KI-Apps bauen, ist das Versprechen überzeugend — saubere, LLM-fähige Webdaten ohne großen Infrastrukturaufwand.
Firecrawl-Test: Preisstufen auf einen Blick
Auf den ersten Blick wirkt Firecrawls Preisgestaltung recht übersichtlich. Auf der steht Folgendes:
| Plan | Monatlicher Preis | Credits/Monat | Gleichzeitige Ausführung | Jahrespreis |
|---|---|---|---|---|
| Free | 0 $ | 500 (einmalig, nicht monatlich) | 2 | — |
| Hobby | 19 $/Monat | 3.000 | 10 | 16 $/Monat bei jährlicher Abrechnung |
| Standard | 99 $/Monat | 100.000 | 50 | 83 $/Monat bei jährlicher Abrechnung |
| Growth | 399 $/Monat | 500.000 | 100 | 333 $/Monat bei jährlicher Abrechnung |
| Scale | 749 $/Monat | 1.000.000 | 1.000 | 599 $/Monat bei jährlicher Abrechnung |
Zwei Dinge springen sofort ins Auge. Die 500 Credits im Free-Plan sind einmalig, nicht monatlich — ein Detail, das vielen erst auffällt, wenn sie sie in einer einzigen Testsitzung aufgebraucht haben. Und die Stufen sehen zwar simpel aus, aber die tatsächlichen Kosten hängen stark davon ab, welche Funktionen Sie nutzen. Der angegebene Preis ist also nur der Startpunkt. Die echte Rechnung? Darum geht es im nächsten Abschnitt.
Die echten Kosten von Firecrawl: Ein Credit-Rechner für Ihren Anwendungsfall
Die Preisgestaltung ist der mit Abstand größte Schmerzpunkt bei echten Firecrawl-Nutzern — „es ist verdammt teuer“, „für meinen Bedarf müsste ich im 99-Dollar-Plan sein“ und „völlig überteuert“ sind echte Zitate aus Hacker News und Reddit. Der Grund? Es gibt ein doppeltes Abrechnungssystem, das die meisten Firecrawl-Tests komplett ignorieren.
Die Falle ist diese: Die Credit-Pläne von Firecrawl decken Scrape, Crawl, Map und Search ab. Aber Extract — die KI-gestützte strukturierte Extraktion, eines der Hauptverkaufsargumente von Firecrawl — läuft über ein vollständig separates, tokenbasiertes Abonnement.
| Extract-Plan | Monatlicher Preis | Tokens/Jahr | Tokens/Monat (ca.) |
|---|---|---|---|
| Starter | 89 $/Monat | 18 Mio. | ~1,5 Mio. |
| Standard | 189 $/Monat | 48 Mio. | ~4 Mio. |
| Growth | 389 $/Monat | 108 Mio. | ~9 Mio. |
| Pro | 719 $/Monat | 192 Mio. | ~16 Mio. |
Ein Startup im Standard-Credit-Plan (99 $/Monat), das zusätzlich Extraktion braucht, zahlt also mindestens 99 $ + 89 $ = 188 $/Monat — noch bevor irgendwelche Credit-Multiplikatoren greifen. Genau diese doppelte Abrechnung erwischt viele kalt.
Versteckte Credit-Multiplikatoren, die die meisten übersehen
Die Schlagzeile „1 Credit pro Seite“ ist irreführend. So viel kosten die Funktionen tatsächlich:
| Funktion | Credit-Kosten | Effektiver Multiplikator |
|---|---|---|
| Einfaches Scrape/Crawl | 1 Credit/Seite | 1x |
| Search | 2 Credits/10 Ergebnisse | 2x pro Ergebnissatz |
| JSON-Extraktion (über Scrape) | +4 Credits/Seite | 5x insgesamt |
| Enhanced Mode | +4 Credits/Seite | 5x insgesamt |
| JSON + Enhanced Mode | +8 Credits/Seite | 9x insgesamt |
| Browser-Interaktionen | 2 Credits/Minute | Variabel |
| Agent Mode (spark-1-mini) | Dynamisch, ca. 100–500/Abfrage | 100–500x |
| Agent Mode (spark-1-pro) | Dynamisch, ca. 200–1.500+/Abfrage | 200–1.500x |
Und noch ein paar weitere wichtige Details: Credits werden nicht von Monat zu Monat übertragen. Fehlgeschlagene Anfragen verbrauchen trotzdem Credits (Nutzer berichten von 20–30 % Verschwendung auf fehleranfälligen Seiten). Der Agent-Mode hat keinen Kostenrechner vor dem Lauf — Sie setzen zwar einen maxCredits-Parameter, aber im Grunde raten Sie nur. Die 500 Lifetime-Credits des Free-Plans reichen für ungefähr 56 Seiten, wenn Sie Extraktion aktivieren. Das ist kein Testlauf — das ist ein Vorgeschmack.
Beispielhafte monatliche Kosten nach Nutzerprofil
| Nutzerprofil | Seiten pro Monat | Genutzte Funktionen | Geschätzter Credit-Verbrauch | Geschätzte monatliche Kosten |
|---|---|---|---|---|
| Hobby-Nutzer / Nebenprojekt | 500 | Einfaches Scrape + Crawl | ~500 Credits | 19 $/Monat (Hobby-Plan) |
| Hobby-Nutzer + JSON-Extraktion | 500 | Scrape + Extract | ~2.500 Credits + 89 $ Extract | 108 $/Monat |
| Startup / KI-App | 5.000 | Scrape + Extract + Search | ~30.000 Credits + 89 $ Extract | 188 $/Monat (Standard + Extract) |
| Unternehmen / Datenpipeline | 50.000 | Voller Funktionsumfang + Agent | ~250.000–450.000 Credits + 389 $ Extract | 788–1.138 $/Monat |
Ein Hacker-News-Entwickler, der 190 $ pro Monat zahlte, nannte die Erfahrung „teuer und irgendwie halbfertig“ und ersetzte Firecrawl durch 2.700 Zeilen eigenen Elixir-Code. Das ist ein ziemlich deutliches Signal.
Firecrawl selbst hosten: Was wirklich kostenlos ist und was nur in der Cloud verfügbar ist
„Kann ich Firecrawl nicht einfach kostenlos selbst hosten?“ ist eine der häufigsten Fragen, die ich sehe. Die Antwort lautet: so ungefähr — aber wahrscheinlich nicht so, wie Sie hoffen.
Firecrawl hat einen Open-Source-Kern (AGPL-3.0-Lizenz), aber mehrere wichtige Funktionen gibt es nur in der Cloud. Hier die klare Aufschlüsselung:
| Fähigkeit | Self-Hosted (kostenlos) | Cloud (kostenpflichtig) |
|---|---|---|
| Einfaches Scrape/Crawl zu Markdown | ✅ | ✅ |
| Map (URL-Entdeckung) | ✅ | ✅ |
| LLM-gestütztes Extract | ⚠️ (eigene LLM-Keys erforderlich) | ✅ (verwaltet) |
| Agent Mode | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Anti-Bot / Proxy-Rotation (Fire-engine) | ❌ (nutzt Ihre statische IP) | ✅ |
| Batch-Verarbeitung | ❌ | ✅ |
| Dashboard / Analysen | ❌ | ✅ |
| Verwaltete Infrastruktur | ❌ (Docker + PostgreSQL + Redis erforderlich) | ✅ |
Fire-engine, Firecrawls proprietäres Anti-Bot-System, ist . Selbst gehostete Nutzer erhalten keinerlei Anti-Bot-Funktionen und müssen eigene Proxys bereitstellen.
Für wen Self-Hosting trotzdem sinnvoll ist
Self-Hosting funktioniert, wenn Sie Entwickler sind, die eine einfache Crawl-zu-Markdown-Pipeline wollen und sich mit Docker Compose und 5+ Diensten wohlfühlen. Mindestanforderungen: 4 GB RAM, 2 CPU-Kerne sowie LLM-API-Keys für die Extraktion (0,01–0,10 $/Seite) und bei Bedarf Proxy-Dienste. Insgesamt liegen die Kosten für Self-Hosting bei 90–340 $/Monat — also oft ähnlich wie die Cloud-Pläne bei mittlerem Volumen.
Warum Nutzer mit der selbst gehosteten Version frustriert sind
Echtes Nutzerfeedback zeichnet ein eher raues Bild. Mehrere Reddit- und GitHub-Threads beschreiben, dass die selbst gehostete Version mit der Zeit schlechter wird, weil Funktionen in die Cloud verschoben werden. Ein Nutzer brachte es auf den Punkt: Das Unternehmen versuche, „alle Nutzer jetzt zum Bezahlen zu drängen und Self-Hosting nutzlos zu machen“. Die Community hat sogar einen firecrawl-simple-Fork erstellt, um Schwachstellen zu beheben. Wenn Sie Self-Hosting als langfristige kostenlose Lösung betrachten, sollten Sie Ihre Erwartungen entsprechend anpassen — es ist ein guter Ausgangspunkt zum Experimentieren, aber kein Ersatz für das kostenpflichtige Cloud-Produkt im großen Maßstab.
Firecrawl Anti-Bot-Performance: Wo es funktioniert und wo nicht
Das ist der Abschnitt, der am wichtigsten ist, wenn Sie sich fragen: „Funktioniert Firecrawl auf den Seiten, die ich scrapen will, überhaupt?“
Die kurze Antwort: Es hängt vollständig davon ab, wie gut diese Seiten geschützt sind.
Die Benchmark-Zahlen
hat unabhängig 10 Web-Scraping-APIs gegen 15 stark botgeschützte Seiten getestet. Firecrawls Ergebnisse:
| Anbieter | Erfolgsrate (2 Anfragen/s) | Erfolgsrate (10 Anfragen/s) |
|---|---|---|
| Zyte | 93,14 % | 89,2 % |
| ScrapFly | 91,8 % | 88,5 % |
| Bright Data | 88,7 % | 84,9 % |
| Firecrawl | 33,69 % | 26,69 % |
Firecrawl landete von 10 Anbietern bei geschützten Seiten. Die schnelle Antwortzeit (durchschnittlich 7,92 Sekunden) erklärt sich teilweise durch eine „fail fast“-Strategie — Fehler werden schnell zurückgegeben, statt erneut zu versuchen.
Der breitere laufende Benchmark von bescheinigt Firecrawl eine Gesamterfolgsrate von 65,4 % (über dem Branchendurchschnitt von 59,5 %), mit starken Ergebnissen bei einfachen Zielen, aber schwachen bei geschützten Seiten.
Aufteilung nach Schwierigkeitsgrad: einfache, mittlere und schwierige Ziele
| Schwierigkeit | Beispielseiten | Firecrawl-Erfolgsrate | Empfehlung |
|---|---|---|---|
| Einfach | Blogs, Dokumentation, öffentliche SaaS-Seiten | 85–98 % | Firecrawl bedenkenlos nutzen |
| Mittel | Produktkataloge, News-Seiten mit einfachem Bot-Schutz, Etsy, Realtor.com | 53–65 % | Sorgfältig testen, mit Ausfällen rechnen |
| Schwer | Amazon, LinkedIn, Instagram, Seiten mit starkem Cloudflare-Einsatz | 0–33 % | Nicht auf Firecrawl verlassen — spezialisierte Anti-Bot-Anbieter nutzen |
Cloudflare-geschützte Seiten sind der am häufigsten gemeldete Ausfallpunkt. Mehrere GitHub-Issues dokumentieren das Problem: Cloudflares Fingerprint-Erkennung blockiert Firecrawl sogar dann, wenn IP-Rotation verwendet wird. Am stärksten betroffen sind Selbst-Hosting-Nutzer, da ihnen die Proxy-Infrastruktur von Fire-engine fehlt.
Was tun, wenn Firecrawl nicht ausreicht?
Bei stark geschützten Seiten greifen Nutzer typischerweise zu spezialisierten Proxy-Diensten wie ScrapFly oder Bright Data oder zu Headless-Browser-Tools mit eigenen Stealth-Konfigurationen. Wenn Sie als Business-User sich nicht mit Proxy-Rotation oder Erfolgsquoten beschäftigen möchten, kümmern sich No-Code-Tools wie im Hintergrund um Anti-Bot-Themen — Sie klicken einfach und erhalten Ihre Daten.
Firecrawl: Vor- und Nachteile im ehrlichen Überblick
Was Firecrawl gut kann
- Saubere, LLM-fähige Markdown-Ausgabe — durchgehend gut formatiert mit sauberer Überschriftenstruktur. Das ist Firecrawls stärkstes Verkaufsargument.
- Kein Infrastrukturaufwand für Cloud-Nutzer — keine Browser-Einrichtung, kein Proxy-Management, keine Headless-Browser-Konfiguration.
- Breite Framework-Integrationen — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (7+ Integrationen für KI-Pipelines).
- Schnelle URL-Entdeckung über den Map-Endpunkt — 2–3 Sekunden für eine komplette Sitemap.
- Open-Source-Kern mit — Transparenz und Community-Beiträge.
- MCP-Server-Support mit dem FIRE-1-Modell für KI-Agenten-Workflows.
- bei JS-lastigen Seiten (React-, Vue- und Angular-SPAs).
Wo Firecrawl Schwächen hat
- Doppelte Preisstruktur (Credits + separates Extract-Token-Abo) sorgt für Überraschungen bei der Abrechnung.
- Credit-Multiplikatoren treiben die tatsächlichen Kosten 5–9x über den beworbenen Preis.
- Anti-Bot-Performance: letzter Platz im Proxyway-Benchmark ( gegenüber 93,14 % beim Spitzenreiter).
- Agent Mode verbraucht unvorhersehbar Credits und hat keinen Kostenrechner vor dem Lauf.
- Fehlgeschlagene Anfragen verbrauchen trotzdem Credits — 20–30 % Verschwendung auf instabilen Seiten.
- Selbst gehostete Version ohne Agent, Browser Sandbox, Fire-engine-Anti-Bot und Dashboard.
- Kein natives CAPTCHA-Lösen — ein deutlicher Rückstand gegenüber Bright Data und Zyte.
- Nicht für nicht-technische Nutzer zugänglich — erfordert Programmier- und API-Kenntnisse.
- Die 500 Credits im Free-Plan sind lifetime, nicht monatlich — für ernsthafte Tests zu wenig.
Über Entwickler-Tools hinaus: No-Code-Alternativen, die Firecrawl-Tests nie erwähnen
Jeder Firecrawl-Test, den ich gelesen habe, vergleicht es ausschließlich mit anderen Entwickler-Tools — Crawl4AI, Scrapy, Playwright, Apify. Das ergibt Sinn, wenn Sie Entwickler sind. Aber ein großer Teil der Menschen, die nach Web-Scraping-Lösungen suchen, sind keine Entwickler: Vertriebsteams, die Interessentenlisten aufbauen, E-Commerce-Teams, die Konkurrenzpreise überwachen, Marketing-Teams, die Inhaltsdaten sammeln, Immobilienmakler, die Listings verfolgen.
Diese Lücke lohnt es sich zu schließen.
Vergleichstabelle der Firecrawl-Alternativen
| Tool | Am besten für | Code erforderlich? | LLM-fähige Ausgabe | Startpreis |
|---|---|---|---|---|
| Firecrawl | Entwickler, die KI-Apps bauen | Ja (API) | ✅ Markdown/JSON | 19 $/Monat |
| Crawl4AI | Entwickler, die Free/OSS wollen | Ja (Python) | ✅ Markdown | Kostenlos |
| Apify | Entwickler mit Bedarf an Skalierung + Marktplatz | Ja (SDK) | ⚠️ Mit Einrichtung | 39 $/Monat |
| Thunderbit | Business-User (No-Code) | Nein (Chrome-Erweiterung) | ✅ Strukturierte Daten | Kostenloser Tarif verfügbar |
| ScrapingBee | Entwickler mit Proxy-Bedarf | Ja (API) | ❌ Rohes HTML | 49 $/Monat |
| Bright Data | Enterprise-Datenteams | Ja (API/SDK) | ⚠️ Mit Einrichtung | 500 $+/Monat |
Warum Thunderbit die erste Wahl für nicht-technische Teams ist
Ich arbeite im Thunderbit-Team, deshalb bin ich damit transparent. Thunderbit gehört in diesen Vergleich, weil es ein anderes Problem löst als Firecrawl, für ein anderes Publikum, ganz ohne Code.
Der Thunderbit-Workflow besteht aus zwei Klicks: Öffnen Sie die , klicken Sie auf „KI-Felder vorschlagen“ und dann auf „Scrapen“. Die KI liest die Seite, schlägt die passenden Spalten vor und extrahiert strukturierte Daten in eine Tabelle. Keine API-Keys, keine Selektoren, kein Programmieren. Sie können kostenlos nach Excel, Google Sheets, Airtable oder Notion exportieren.
Wichtige Vorteile für Business-User:
- Unterseiten-Anreicherung — Detailseiten anklicken und zusätzliche Felder automatisch abrufen
- KI, die sich an Layout-Änderungen anpasst — kein Wartungsaufwand bei Website-Redesigns
- Integrierte Datenbeschriftung und Übersetzung — nützlich für mehrsprachige Datensätze
- Sofortvorlagen für beliebte Seiten (Amazon, Zillow, LinkedIn usw.)
Für Entwickler, die eine API-Alternative suchen, bietet Thunderbit außerdem mit einfacherer Preisgestaltung als Firecrawls doppelte Credit-/Token-Struktur. Es wird Firecrawl für Entwickler von LLM-Pipelines nicht vollständig ersetzen. Aber für Vertriebs-, E-Commerce-, Marketing- und Operations-Teams, die strukturierte Daten ohne Code brauchen, ist es der schnellere und günstigere Weg.
Build vs. Buy: Wann sich Firecrawl rechnet und wann nicht
„Ich dachte darüber nach, meinen eigenen Web-Scraper zu schreiben … einfacher als Firecrawl, aber zumindest billiger.“ Diesen Punkt bringen mehrere Nutzer auf. Statt einer subjektiven Einschätzung hier ein strukturierter Entscheidungsrahmen.
Tabelle zum Entscheidungsrahmen
| Faktor | Eigenentwicklung (Scrapy/Playwright) | Firecrawl Cloud kaufen | Thunderbit nutzen (No-Code) |
|---|---|---|---|
| Einrichtungszeit | 10–40+ Stunden | ~30 Minuten | ~5 Minuten |
| Laufender Wartungsaufwand | Hoch (Selektoren brechen) | Nahezu null (verwaltet) | Null (KI passt sich an) |
| Anti-Bot-Handling | Manuell (Proxy, Header, Retries) | Integriert (teilweise — schwach bei geschützten Seiten) | Integriert (Browser + Cloud-Modi) |
| Kosten bei 1.000 Seiten/Monat | 50–150 $ (Server + Proxy) | 19–108 $ (abhängig von Funktionen) | 0–15 $ |
| Kosten bei 50.000 Seiten/Monat | 500–1.500 $ (Infrastruktur) | 399–1.138 $ | 39–249 $ |
| LLM-fähige Ausgabe | Eigener Code erforderlich | Integriert (Markdown/JSON) | Strukturierte Tabellen (exportierbar) |
| Am besten für | Volle Kontrolle, Nischen-Seiten, DevOps-Teams | KI-/LLM-Entwickler, RAG-Pipelines | Vertrieb, E-Commerce, Marketing, Ops |
Eine Eigenentwicklung ist über drei Jahre hinweg für die meisten Organisationen als APIs. Der Punkt, an dem Eigenbau günstiger wird, liegt ungefähr bei 10 Mio.+ Seiten pro Monat — ein Maßstab, den nur sehr wenige Teams tatsächlich erreichen.
Das ehrliche Fazit: Welcher Weg passt zu Ihnen?
Firecrawl rechnet sich, wenn:
- Ihr Team bereits in Python/JS programmiert und sauberes Markdown für LLM-/RAG-Pipelines braucht
- Sie vor allem ungeschützte oder leicht geschützte Seiten anvisieren
- Sie verwaltete Infrastruktur ohne DevOps-Overhead wollen
- das Volumen unter etwa 50.000 Seiten pro Monat bleibt
Firecrawl rechnet sich nicht, wenn:
- Sie als Business-User Extraktionen ohne Dev-Team durchführen → Thunderbit ist einfacher und schneller
- Sie stark geschützte Seiten anvisieren (Amazon, LinkedIn, Cloudflare-lastige Seiten) → Bright Data oder Zyte
- Sie planbare Kosten im großen Maßstab brauchen → Credit-Multiplikatoren machen die Kosten unvorhersehbar
- Sie mit vollem Funktionsumfang selbst hosten wollen → Agent, Browser Sandbox, Fire-engine sind nur in der Cloud verfügbar
Eigenentwicklung lohnt sich nur, wenn:
- Ihr Team dedizierte DevOps-Kapazitäten hat
- Sie in sehr großem Maßstab arbeiten (10 Mio.+ Seiten/Monat)
- Sie volle Kontrolle über spezielle oder ungewöhnliche Seiten brauchen
- Sie mit laufender Selektor-Pflege leben können
Firecrawl-Bewertung: Vergleichstabelle Seite an Seite
Hier alles im direkten Vergleich:
| Tool | Typ | Am besten für | Code erforderlich | Anti-Bot-Handling | LLM-fähige Ausgabe | Self-Host-Option | Startpreis |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | KI-/LLM-Entwickler | Ja | Schwach auf geschützten Seiten | ✅ Markdown/JSON | ✅ (eingeschränkt) | 19 $/Monat |
| Crawl4AI | Python-Bibliothek | OSS-orientierte Entwickler | Ja | Keines (DIY) | ✅ Markdown | ✅ | Kostenlos |
| Apify | Cloud-Plattform | Skalierung + Marktplatz | Ja | Mittel | ⚠️ Mit Einrichtung | ✅ | 39 $/Monat |
| Thunderbit | Chrome-Erweiterung + API | Business-User, No-Code | Nein | Integriert | ✅ Strukturierte Daten | ❌ | Kostenloser Tarif |
| ScrapingBee | API | Proxy-fokussierte Entwickler | Ja | Stark | ❌ Rohes HTML | ❌ | 49 $/Monat |
| Bright Data | API + Proxy-Netzwerk | Enterprise-Datenteams | Ja | Am besten (~99,9 %) | ⚠️ Mit Einrichtung | ❌ | 500 $+/Monat |
Abschließendes Urteil: Lohnt sich Firecrawl?
Firecrawl ist ein solides Tool für einen klar umrissenen Anwendungsfall: Entwicklerteams, die LLM-Apps, RAG-Pipelines oder KI-Agenten bauen, saubere Webdaten in mittlerem Umfang brauchen und mit API-basierten Workflows vertraut sind. Die Qualität der Markdown-Ausgabe ist tatsächlich erstklassig, und die Framework-Integrationen (LangChain, LlamaIndex, CrewAI) sind ausgereift. Wenn Ihr Team ohnehin in Python oder JavaScript arbeitet und Ihre Zielseiten nicht stark bot-geschützt sind, kann Firecrawl Ihnen echte Entwicklungszeit sparen.
Die Nachteile sind jedoch real. Das doppelte Preismodell (Credits plus separates Extract-Abo) sorgt für echte Überraschungen bei der Abrechnung. Die auf geschützten Seiten bedeutet, dass Sie sich bei Amazon, LinkedIn oder Cloudflare-lastigen Zielen nicht darauf verlassen können. Die selbst gehostete Version hat zu viele fehlende Funktionen, um als echte kostenlose Alternative zu dienen. Und wenn Sie kein technischer Nutzer sind — etwa jemand aus Vertrieb, E-Commerce oder Marketing — ist Firecrawl überhaupt nicht für Sie gemacht.
Testen Sie Firecrawls kostenlose 500 Credits, um zu sehen, ob die Ausgabequalität zu Ihrer Pipeline passt. Aber kalkulieren Sie vor einem kostenpflichtigen Plan Ihre realen monatlichen Kosten mit dem obigen Rechner. Wenn Sie als Business-User nur strukturierte Daten von Websites brauchen, ohne Code zu schreiben, starten Sie stattdessen mit — Sie extrahieren Daten in Minuten, nicht in Stunden. Sie können die jetzt sofort ausprobieren oder sich die ansehen, um zu prüfen, was für Ihr Team skalierbar ist. Für Video-Anleitungen bietet der Schritt-für-Schritt-Demos.
FAQs
Wie viel kostet Firecrawl pro gescrapter Seite?
Ein einfaches Scrape oder Crawl kostet 1 Credit pro Seite. JSON-Extraktion fügt 4 Credits/Seite hinzu (insgesamt 5). Der Enhanced Mode fügt weitere 4 hinzu (bis zu 9 insgesamt). Search kostet 2 Credits pro 10 Ergebnisse, und der Agent Mode kann 100–1.500+ Credits pro Abfrage verbrauchen. Zusätzlich erfordert die Extract-Funktion ein separates Token-Abo ab 89 $/Monat. Für realistische Schätzungen nach Nutzerprofil siehe den Kostenrechner oben.
Kann man Firecrawl kostenlos selbst hosten?
Ja, der Open-Source-Kern (AGPL-3.0) kann kostenlos selbst gehostet werden. Aber Sie verlieren den Agent Mode, die Browser Sandbox, Anti-Bot-/Proxy-Rotation (Fire-engine ist Closed Source), Batch-Verarbeitung und das Verwaltungs-Dashboard. Für die Extraktion müssen Sie eigene LLM-Keys mitbringen und Docker, PostgreSQL und Redis selbst verwalten. Self-Hosting funktioniert für einfache Crawl-zu-Markdown-Pipelines, ist aber kein Ersatz für das Cloud-Produkt im Produktionsmaßstab.
Ist Firecrawl gut für Amazon, LinkedIn oder andere geschützte Seiten?
Der zeigt, dass Firecrawl auf stark botgeschützten Seiten eine Erfolgsrate von 33,69 % erreicht — letzter Platz unter 10 getesteten Anbietern. Auf ungeschützten Seiten (Blogs, Dokus, SaaS-Seiten — 85–98 % Erfolg) funktioniert es gut, ist aber für große E-Commerce- oder Social-Plattformen nicht zuverlässig. Für solche Ziele sollten Sie spezialisierte Anti-Bot-Anbieter wie Bright Data oder Zyte oder No-Code-Tools wie Thunderbit in Betracht ziehen, die Anti-Bot-Themen im Hintergrund abwickeln.
Was ist die beste Firecrawl-Alternative für nicht-technische Nutzer?
ist die beste No-Code-Alternative. Es ist eine Chrome-Erweiterung, bei der Sie auf „KI-Felder vorschlagen“ und dann auf „Scrapen“ klicken — keine API-Aufrufe, kein Programmieren, keine Selektoren. Daten lassen sich kostenlos nach Excel, Google Sheets, Airtable oder Notion exportieren. Es ist für Vertriebs-, E-Commerce-, Marketing- und Operations-Teams gemacht, die strukturierte Webdaten ohne Entwickler brauchen.
Bietet Firecrawl einen kostenlosen Test an?
Firecrawl bietet ohne Kreditkarte an. Das reicht, um die grundlegende Scrape-/Crawl-Funktionalität an einigen Seiten zu testen, aber nicht für den produktiven Einsatz — vor allem nicht, wenn Sie Extraktion aktivieren (dann werden 5 Credits pro Seite verbraucht). Die Credits erneuern sich im Free-Plan nicht monatlich.
Mehr erfahren