Hier ein kleiner Geheimtipp: Das Internet ist wie die größte Bibliothek der Welt – nur sind die meisten Bücher zugeklebt. Jeden Tag spreche ich mit Unternehmern, Marketing-Expert:innen und Vertriebsteams, die wissen, dass auf Webseiten wertvolle Infos schlummern – Produktdetails, Preise der Konkurrenz, Kundenmeinungen, Kontaktdaten. Aber wie kommt man an diese Texte ran? Genau da wird’s oft knifflig. Nach vielen Jahren im SaaS- und Automatisierungsbereich habe ich schon jede „Copy-Paste-Odyssee“ und jedes „Python-Bastelprojekt“ gesehen. Die gute Nachricht: Mit modernen KI-Web-Scrapern und cleveren Browser-Add-ons ist das Extrahieren von Texten heute so einfach wie nie – und endlich ohne Frust.
In diesem Leitfaden zeige ich dir alle gängigen Methoden – vom klassischen Kopieren und Einfügen bis hin zu fortschrittlichen KI-Lösungen wie (ja, das ist unser eigenes Tool, aber ich bleibe ehrlich bei Vor- und Nachteilen). Egal, ob du Excel-Profi bist, Entwickler oder einfach nur genervt vom ewigen Durchklicken: Hier findest du die passende Schritt-für-Schritt-Anleitung. Lass uns die digitalen Bücher aufschlagen und die gewünschten Texte herausholen.
Was bedeutet es, Text von einer Website zu extrahieren?
Wenn wir von „Textextraktion“ sprechen, meinen wir das Herausziehen von Infos, die du auf einer Webseite siehst (und manchmal auch die, die im Hintergrund versteckt sind), um sie in ein brauchbares Format zu bringen – zum Beispiel eine Tabelle, Datenbank oder ein sauberes Word-Dokument. Aber nicht jeder Website-Text ist gleich:
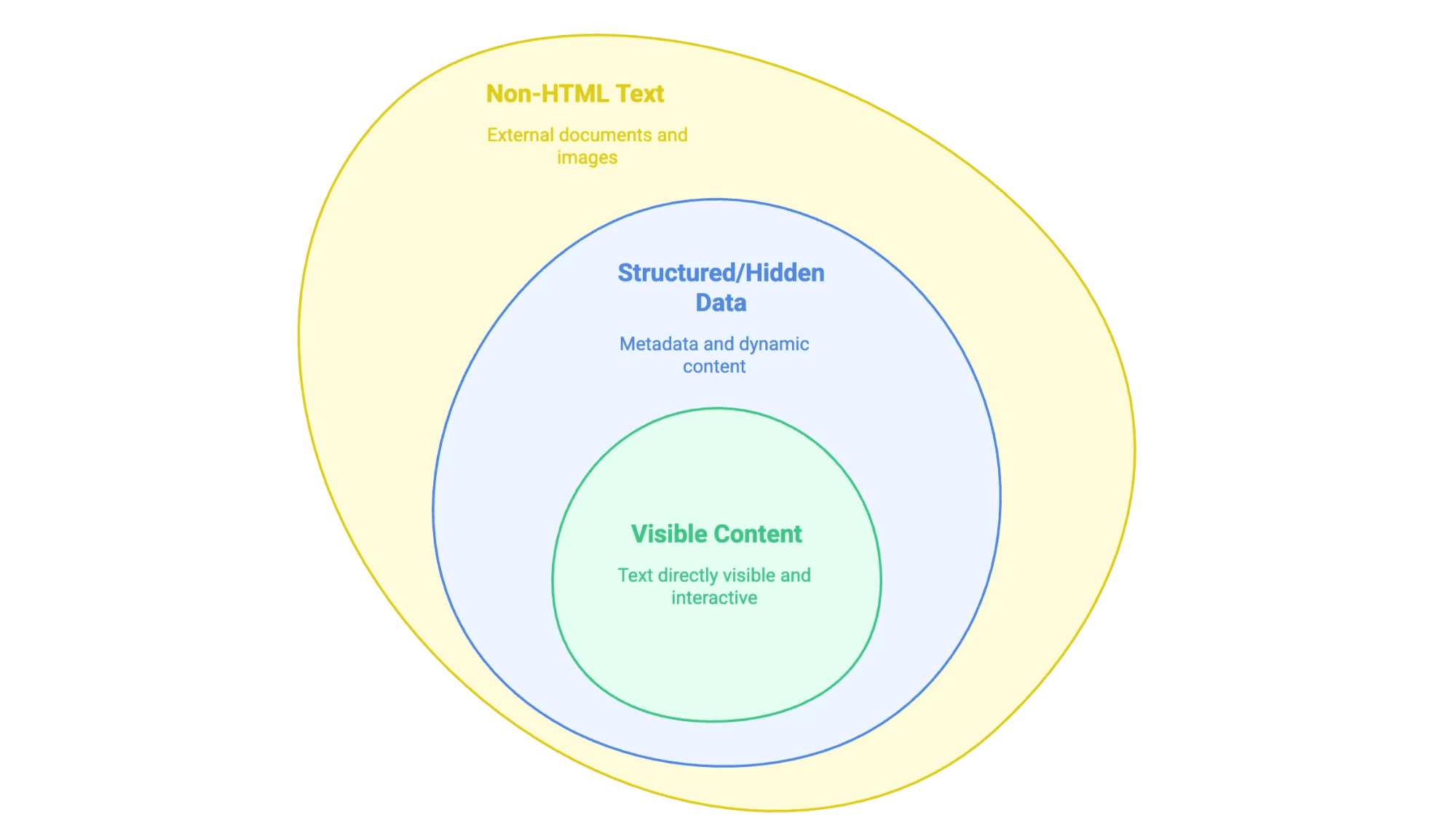
- Sichtbare Inhalte: Alles, was du mit der Maus markieren kannst – Fließtext, Überschriften, Listen, Tabellen, Produktbeschreibungen, Blogartikel usw.
- Strukturierte oder versteckte Daten: Dazu gehören Metadaten in
<meta>-Tags, JSON-LD-Skripte oder Infos, die erst durch JavaScript nachgeladen werden, wenn du klickst oder scrollst. - Nicht-HTML-Texte: PDFs, Word-Dokumente oder sogar Bilder mit Text (wie gescannte Verträge oder Infografiken), die auf der Seite eingebettet oder verlinkt sind.
Wichtig ist, zu wissen, welche Art von Text du brauchst – denn jede Variante braucht eine andere Herangehensweise.
Warum Text von einer Website extrahieren? Geschäftliche Vorteile und Anwendungsfälle
Mal ehrlich: Niemand extrahiert Website-Texte zum Spaß (außer du hast wirklich ausgefallene Hobbys). Unternehmen machen das, weil es sich lohnt. Der Markt für Web-Scraping-Software hat – und wächst weiter. Warum?
| Team | Anwendungsbeispiel | Vorteil |
|---|---|---|
| Vertrieb | Verzeichnisse nach Leads & Kontaktdaten durchsuchen | Schnellere, bessere Akquise |
| Marketing | Wettbewerber-Blogs & SEO-Daten extrahieren | Content-Lücken erkennen, Trends aufspüren |
| Operations | Produktpreise auf E-Commerce-Seiten überwachen | Dynamische Preisgestaltung, Lagerbestandskontrolle |
| Immobilien | Exposés & Objektdetails sammeln | Marktanalyse, Lead-Generierung |
| Support | Kundenbewertungen & Forenbeiträge sammeln | Stimmungsanalyse, frühzeitige Problemerkennung |
Ein paar Beispiele aus der Praxis:

- Lead-Generierung: Ein Gastronomie-Großhändler .
- Wettbewerbsbeobachtung: Einzelhändler wie John Lewis durch automatisiert gesammelte Preisdaten.
- SEO-Analyse: Teams extrahieren Meta-Tags und Keywords, um .
Und mit KI-gestützten Tools sparen Unternehmen im Vergleich zu klassischen Methoden.
Manuelle Methoden: Die Grundlagen des Kopierens und Einfügens
Fangen wir ganz bodenständig an. Manchmal reicht es, einen kleinen Textschnipsel zu kopieren – ganz ohne Tools.
So extrahierst du Text manuell
- Kopieren und Einfügen: Seite öffnen, gewünschten Text markieren, mit Strg+C (oder Rechtsklick > Kopieren) kopieren und in dein Dokument oder deine Tabelle einfügen.
- Seite speichern unter: Im Browser unter Datei > Seite speichern unter. Als „Webseite, nur HTML“ bekommst du den Quellcode, manchmal auch als .txt nur den Text.
- Als PDF drucken: Über die Druckfunktion des Browsers „Als PDF speichern“ wählen. Danach kannst du den Text aus dem PDF kopieren (oder mit einem PDF-Reader als Text speichern).
- Entwicklertools: Rechtsklick > Untersuchen oder F12 drücken, um die DevTools zu öffnen. Hier findest du den HTML-Quelltext, Meta-Tags oder versteckte JSON-Daten und kannst sie kopieren.
Grenzen der manuellen Methode
Für kleine Aufgaben reicht das, aber bei größeren Datenmengen wird’s schnell zur Geduldsprobe. Es ist . Ich habe schon Praktikant:innen gesehen, die tagelang Tabellen Zeile für Zeile kopiert haben – das will wirklich niemand.
Browser-Erweiterungen und Online-Tools zum Extrahieren von Website-Texten
Bereit für den nächsten Schritt? Browser-Add-ons und Online-Tools sind für die meisten Unternehmen die perfekte Lösung: Kein Programmieren, kein Stress – einfach klicken und loslegen.
Warum diese Tools nutzen?

- Schneller als manuelles Kopieren
- Keine Programmierkenntnisse nötig
- Kann Tabellen, Listen und manchmal sogar Dateien verarbeiten
- Export nach Excel, Google Sheets, CSV usw.
Hier die beliebtesten Optionen im Überblick.
Thunderbit: KI-Web-Scraper für schnelle und präzise Textextraktion
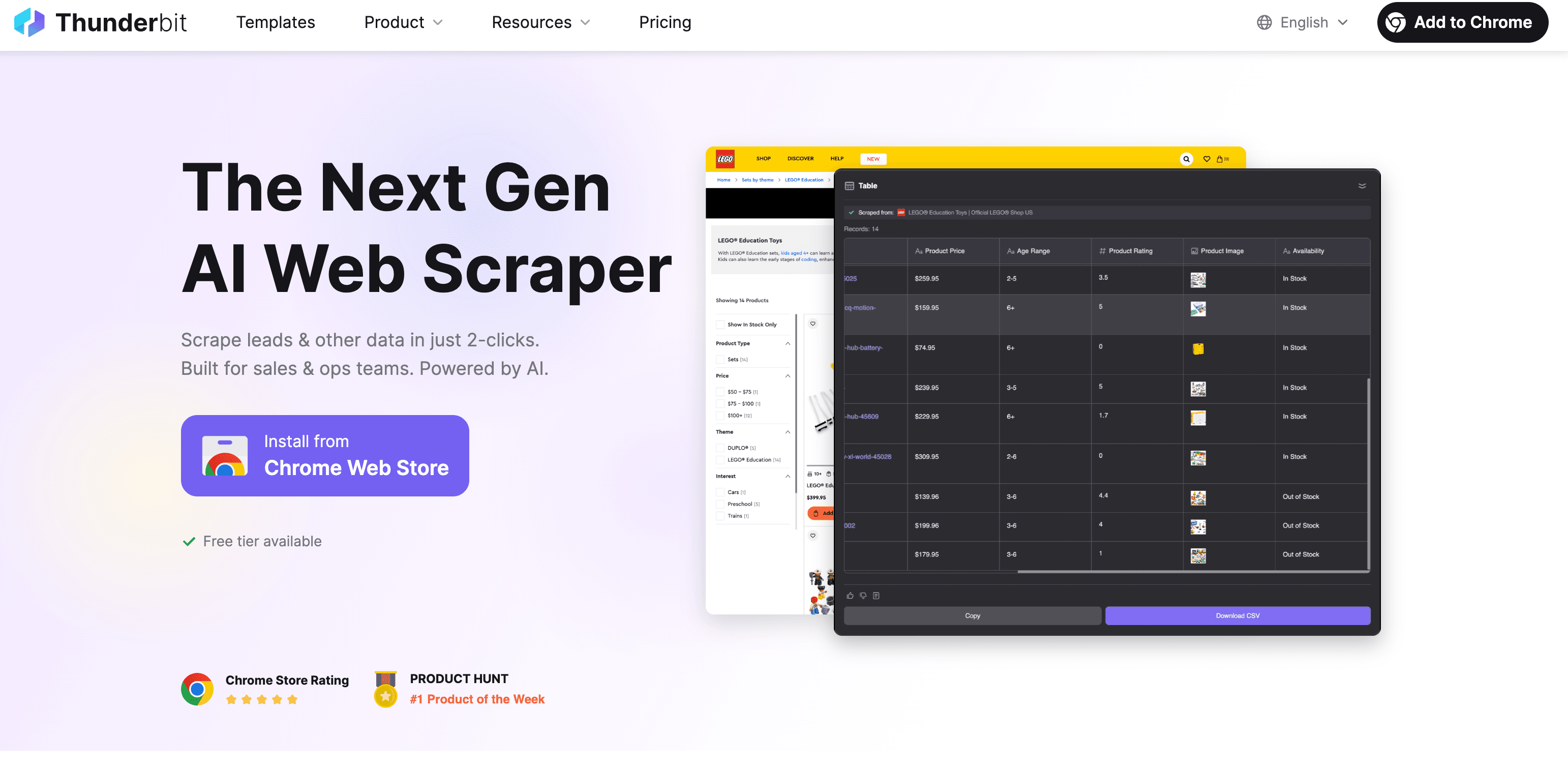
Ich bin da vielleicht etwas voreingenommen, aber macht das Extrahieren von Webtexten wirklich so einfach wie eine Essensbestellung. So funktioniert’s:
Schritt-für-Schritt: Text mit Thunderbit extrahieren
- Chrome-Erweiterung installieren: aus dem Chrome Web Store.
- Website öffnen: Gehe auf die Seite, von der du Text extrahieren möchtest.
- „KI-Felder vorschlagen“ klicken: Thunderbits KI analysiert die Seite und schlägt relevante Felder (Spalten) vor – z.B. Produktname, Preis, Beschreibung.
- Überprüfen & Anpassen: Du kannst die Vorschläge anpassen oder eigene Felder hinzufügen.
- „Scrapen“ klicken: Thunderbit sammelt die Daten – auch von Unterseiten oder paginierten Listen.
- Exportieren: Exportiere die Daten nach Excel, Google Sheets, Airtable, Notion oder als CSV/JSON. Für den Export fallen keine Zusatzkosten an.
Was macht Thunderbit besonders?
- KI-gestützte Feldvorschläge: Kein mühsames Auswählen von Selektoren oder Programmieren. Die KI erkennt automatisch die wichtigsten Inhalte.
- Unterseiten & Paginierung: Du brauchst Details von allen Produktseiten einer Kategorie? Thunderbit klickt sich automatisch durch.
- Extrahiert auch aus PDFs, Bildern und Dokumenten: Du hast ein PDF-Handbuch oder ein Produktbild mit Text? Thunderbits integrierte Texterkennung (OCR) holt auch daraus die Infos.
- Mehrsprachigkeit: Unterstützt 34 Sprachen (Klingonisch fehlt noch, aber wir arbeiten dran).
- Kostenloser Datenexport: Keine Bezahlschranke für den Export.
- Einsatzmöglichkeiten: Produktbeschreibungen, Kontaktdaten, Blog-Inhalte, Lead-Listen und vieles mehr.
Du willst Thunderbit in Aktion sehen? Im findest du Anleitungen wie .
Weitere Browser-Erweiterungen und Online-Tools
Hier noch ein kurzer Überblick über andere Tools, die dir begegnen könnten:
- Web-Scraper (): Kostenlos, per Klick bedienbar, aber mit Lernkurve. Ideal für technisch versierte Analyst:innen, da du „Sitemaps“ und Selektoren einrichten musst. Unterstützt Paginierung, aber keine PDFs oder Bilder. .
- CopyTables: Extrem einfach – kopiert HTML-Tabellen direkt in die Zwischenablage oder nach Excel. Perfekt für schnelle Einmal-Aktionen, funktioniert aber nur seitenweise und nur für Tabellen. .
- ScraperAPI (): Für Entwickler:innen. Du schickst eine URL, bekommst das HTML zurück (inkl. Proxy-Handling, Blockaden etc.), musst den Text aber selbst parsen. .
Wann welches Tool?
- Thunderbit: Wenn du Geschwindigkeit, KI-Unterstützung und viele Exportformate (inkl. PDFs/Bilder) willst.
- Web-Scraper: Wenn du gerne tüftelst und mehr Kontrolle brauchst.
- CopyTables: Wenn du nur schnell eine Tabelle brauchst.
- ScraperAPI: Wenn du deinen eigenen Scraper programmierst.
Automatisiertes Web Scraping: Programmierlösungen für die Textextraktion
Wenn du Entwickler:in bist (oder jemanden im Team hast), bietet ein eigener Scraper maximale Flexibilität. So läuft’s ab:
- HTTP-Anfrage senden: Mit Python
requestsoder ähnlichem die Seite abrufen. - HTML parsen: Mit
BeautifulSoup,lxmloderScrapygezielt die gewünschten Texte finden. - Extrahieren & Exportieren: Text herausziehen, bereinigen und als CSV, JSON oder in eine Datenbank speichern.
Beispiel: Python + Beautiful Soup
1import requests
2from bs4 import BeautifulSoup
3url = "<http://quotes.toscrape.com>"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6quotes = [q.get_text() for q in soup.find_all("span", class_="text")]
7for qt in quotes:
8 print(qt)Vorteile & Nachteile
- Vorteile: Maximale Anpassbarkeit, für jede Website und jeden Datentyp geeignet, lässt sich in eigene Systeme integrieren.
- Nachteile: Programmierkenntnisse erforderlich, laufende Wartung nötig, Anti-Bot-Maßnahmen müssen umgangen werden.
Wann lohnt sich dieser Weg?
- Du willst tausende oder Millionen Seiten scrapen.
- Die Seite ist komplex (Logins, mehrstufige Formulare).
- Du möchtest das Scraping direkt in deine App oder deinen Workflow integrieren.
Text aus Nicht-HTML-Formaten extrahieren: PDFs, Word-Dokumente und Bilder
Webseiten bestehen nicht nur aus HTML – oft sind auch PDFs, Word-Dateien oder Bilder mit wichtigen Texten eingebettet. So kommst du an die Inhalte:
PDFs
- Textbasierte PDFs: Mit Tools wie Adobe Acrobat oder Bibliotheken wie
PDFMineroderPyPDF2den Text extrahieren. - Gescanntes PDF: Mit OCR-Tools (Texterkennung) wie Tesseract, oder arbeiten.
Word/Excel-Dokumente
- Word: Mit
python-docx.docx-Dateien auslesen. - Excel: Mit
openpyxloderpandas.xlsx-Dateien verarbeiten.
Bilder
- OCR-Tools: Tesseract als Open-Source-Lösung oder Cloud-Dienste für höhere Genauigkeit. Am besten funktionieren Bilder mit 150–300 DPI.
Thunderbits Ansatz
Mit dem „Image/Document Parser“ kannst du PDFs, Bilder oder Dokumente hochladen oder verlinken – die KI extrahiert den Text (und erkennt sogar Tabellen). Du brauchst keine verschiedenen Tools, sondern behandelst Dateien wie jede andere Webseite.
Methoden im Vergleich: Welche Textextraktion passt zu dir?
Hier ein schneller Überblick zum Vergleich:
| Methode | Bedienkomfort | Skalierbarkeit | Technisches Know-how | Unterstützte Datentypen | Ideal für |
|---|---|---|---|---|---|
| Manuell (Copy-Paste) | Sehr einfach | Gering | Keins | Nur sichtbarer Text | Einzelne, kleine Aufgaben |
| Browser-Tools/Erweiterungen | Einfach–Mittel | Mittel | Gering–Mittel | HTML, einige Tabellen | Nicht-Techniker, kleine–mittlere Aufgaben |
| KI-Tools (Thunderbit) | Sehr einfach | Hoch | Keins | HTML, PDFs, Bilder, mehr | Business-Anwender, gemischte Inhalte |
| Programmierung (Code) | Schwierig | Sehr hoch | Hoch | Alles (mit passenden Bibliotheken) | Entwickler, Großprojekte |
| Nicht-HTML (OCR) | Mittel | Gering–Mittel | Mittel | PDFs, Bilder, Dokumente | Wenn Dateien/Bilder im Fokus stehen |
Wenn du eine schnelle, flexible und stressfreie Lösung suchst – vor allem im Business-Umfeld – sind KI-Tools wie Thunderbit kaum zu schlagen. Für maximale Kontrolle oder riesige Datenmengen kann sich aber auch ein eigener Code lohnen.
Fazit: So startest du mit der Textextraktion von Webseiten
- Das Web ist voller wertvoller Textdaten, aber der Zugriff ist oft nicht trivial.
- Manuelle Methoden eignen sich nur für Kleinstaufgaben und sind nicht skalierbar.
- Browser-Erweiterungen und KI-Web-Scraper wie machen die Textextraktion schnell, präzise und für jeden zugänglich – ganz ohne Programmierkenntnisse.
- Für nicht-HTML-Inhalte (PDFs, Bilder) solltest du Tools mit integrierter OCR und Dokumentenparser nutzen.
- Wähle die Methode, die zu den Fähigkeiten deines Teams, dem Umfang deines Projekts und den benötigten Datentypen passt.
Viel Erfolg beim Scrapen – und möge deine Zeit mit Strg+C bald der Vergangenheit angehören. Mit den richtigen Tools wird die Datenerfassung aus dem Web zum automatisierten Kinderspiel und du hast mehr Zeit für die wirklich wichtigen Aufgaben. Schluss mit endlosem Kopieren und Einfügen – jetzt heißt es: smart, effizient und zukunftsorientiert arbeiten!
Häufige Fragen (FAQ)
Frage 1: Kann ich von jeder Website Daten extrahieren?
Antwort: Nicht immer. Manche Seiten blockieren Scraper oder verbieten das Scraping in ihren Nutzungsbedingungen. Schau dir immer zuerst die Richtlinien der Website an.
Frage 2: Wie genau arbeiten KI-basierte Web-Scraper?
Antwort: KI-Scraper wie Thunderbit sind sehr präzise, bei besonders komplexen oder dynamischen Seiten kann aber manchmal Nacharbeit nötig sein.
Frage 3: Brauche ich Programmierkenntnisse für Web-Scraping-Tools?
Antwort: Nein, Tools wie Thunderbit und andere Browser-Erweiterungen sind für Nicht-Techniker gemacht und funktionieren ohne Programmierkenntnisse.
Frage 4: Welche Daten kann ich aus PDFs oder Bildern extrahieren?
Antwort: Mit OCR-Tools lassen sich Texte, Tabellen und sogar versteckte Daten aus gescannten PDFs und Bildern extrahieren – das macht die Datenerfassung noch vielseitiger.