Haben Sie schon einmal ein Finanz- oder Operations-Team beim Monatsabschluss beobachtet? Da fliegen Belege, Tabellen und – ganz ehrlich – jede Menge Koffein durcheinander. Ich habe aus erster Hand gesehen, wie allein das Extrahieren von Daten aus Belegen ganze Geschäftsprozesse ausbremsen kann. Und das ist nicht nur eine kleine Unannehmlichkeit: . Das ist ein Berg aus verschwendeter Zeit, Geld und Motivation – nur um immer wieder „Anbieter: Coffee Shop, Betrag: 4,50 $“ abzutippen.
Kein Wunder also, dass immer mehr Teams nach einer intelligenteren Lösung suchen. Die Nachfrage nach Automatisierung – vor allem nach KI-gestützten Lösungen – ist regelrecht explodiert, weil Unternehmen erkannt haben, dass der alte Weg nicht mehr tragfähig ist. Wie kommen Sie also von mühsamer Handarbeit zu einer effizienten, genauen Beleg-Datenextraktion? Schauen wir uns das an – und ich zeige Ihnen, wie wir das bei gelöst haben.
Was ist Beleg-Datenextraktion? Ein kurzer Überblick
Beleg-Datenextraktion ist genau das, wonach es klingt: strukturierte Informationen wie Datum, Anbieter, Betrag und Einzelposten aus Belegen, Rechnungen oder Spesenbelegen herauszuziehen. Früher bedeutete das, dass jemand mit zusammengekniffenen Augen auf ein zerknittertes Blatt Papier oder ein unscharfes PDF starrte und die Details dann in eine Tabelle oder ein Finanzsystem eintippte. Heute kann das auch heißen, Software zu nutzen, die diese Daten scannt, liest und automatisch extrahiert – und aus chaotischen Belegen saubere, nutzbare Datensätze macht.
Die häufigsten Felder, die Teams aus Belegen benötigen, sind:
- Datum der Transaktion
- Name des Anbieters oder Händlers
- Gesamtbetrag
- Steuerbetrag
- Zahlungsart
- Beschreibungen der Einzelposten
- Belegnummer oder Referenzcode
Manuelle Extraktion ist langsam und fehleranfällig. Automatisierte Ansätze, besonders KI-gestützte, können Belege in Sekunden verarbeiten – mit höherer Genauigkeit und Konsistenz (, ).
Warum Beleg-Datenextraktion weiterhin ein Engpass für Unternehmen ist
 Trotz aller technischen Fortschritte ist die manuelle Beleg-Datenextraktion immer noch weit verbreitet – besonders in kleinen und mittelständischen Unternehmen. Warum? Weil Belege in allen möglichen Formen und Formaten vorliegen: Papier, PDFs, E-Mail-Anhänge, sogar unterwegs aufgenommene Fotos. Viele Teams setzen weiterhin auf manuelle Eingabe, weil sie Automatisierung für zu komplex oder zu teuer halten.
Trotz aller technischen Fortschritte ist die manuelle Beleg-Datenextraktion immer noch weit verbreitet – besonders in kleinen und mittelständischen Unternehmen. Warum? Weil Belege in allen möglichen Formen und Formaten vorliegen: Papier, PDFs, E-Mail-Anhänge, sogar unterwegs aufgenommene Fotos. Viele Teams setzen weiterhin auf manuelle Eingabe, weil sie Automatisierung für zu komplex oder zu teuer halten.
Doch dieser altmodische Ansatz hat einen hohen Preis:
- Hohe Fehlerquote: .
- Personalkosten: Manuelle Eingabe ist langsam – Finanzteams verbringen .
- Verzögerungen: Die Bearbeitung von Spesenabrechnungen kann Tage oder sogar Wochen dauern und Erstattungen sowie den Abschluss der Bücher verzögern ().
- Compliance-Risiken: Manuelle Fehler können zu verpassten Steuerabzügen, Compliance-Problemen und Ärger bei Prüfungen führen.
Schauen wir uns das im Vergleich an:
| Faktor | Manuelle Extraktion | Automatisierte Extraktion (KI) |
|---|---|---|
| Genauigkeit | Niedrig (fehleranfällig) | Hoch (99 %+ mit KI) |
| Geschwindigkeit | Langsam (Minuten/Beleg) | Schnell (Sekunden/Beleg) |
| Personalkosten | Hoch | Niedrig |
| Compliance | Risikoreich | Zuverlässig |
| Skalierbarkeit | Schwach | Exzellent |
Kein Wunder also, dass .
Lösungsansätze im Vergleich: Traditionelle vs. KI-gestützte Beleg-Datenextraktion
Welche Optionen haben Sie also? So sieht die Landschaft aus:
- Manuelle Eingabe: Altmodisch, langsam und fehleranfällig. Wird immer noch von Teams genutzt, die noch keinen besseren Weg gefunden haben.
- Vorlagenbasiertes OCR: Nutzt feste Vorlagen, um Belege zu „lesen“. Funktioniert gut bei Standardformaten, hat aber Probleme mit Ungewöhnlichem oder Handschriftlichem.
- KI-gestützte Extraktion (wie Thunderbit): Nutzt künstliche Intelligenz, um Daten aus jedem Beleg zu verstehen und zu extrahieren – egal ob Website, PDF oder Bild. Keine Vorlagen nötig.
Hier ein kurzer Vergleich:
| Methode | Einrichtungszeit | Flexibilität | Genauigkeit | Wartung | Unterstützt jedes Format? |
|---|---|---|---|---|---|
| Manuelle Eingabe | Keine | Hoch | Niedrig | N. z. | Ja (aber langsam) |
| Vorlagenbasiertes OCR | Hoch | Niedrig | Mittel | Hoch | Nein |
| KI-gestützt (Thunderbit) | Niedrig | Hoch | Hoch | Niedrig | Ja |
Mit müssen Sie keine Vorlagen bauen und keinen Code schreiben. Klicken Sie einfach auf „KI schlägt Felder vor“, lassen Sie die KI erkennen, was wichtig ist, und drücken Sie auf „Scrape“. So nah an „einmal einrichten und vergessen“ wie ich es in diesem Bereich gesehen habe.
Schritt-für-Schritt-Anleitung: Belegdaten mit Thunderbit extrahieren
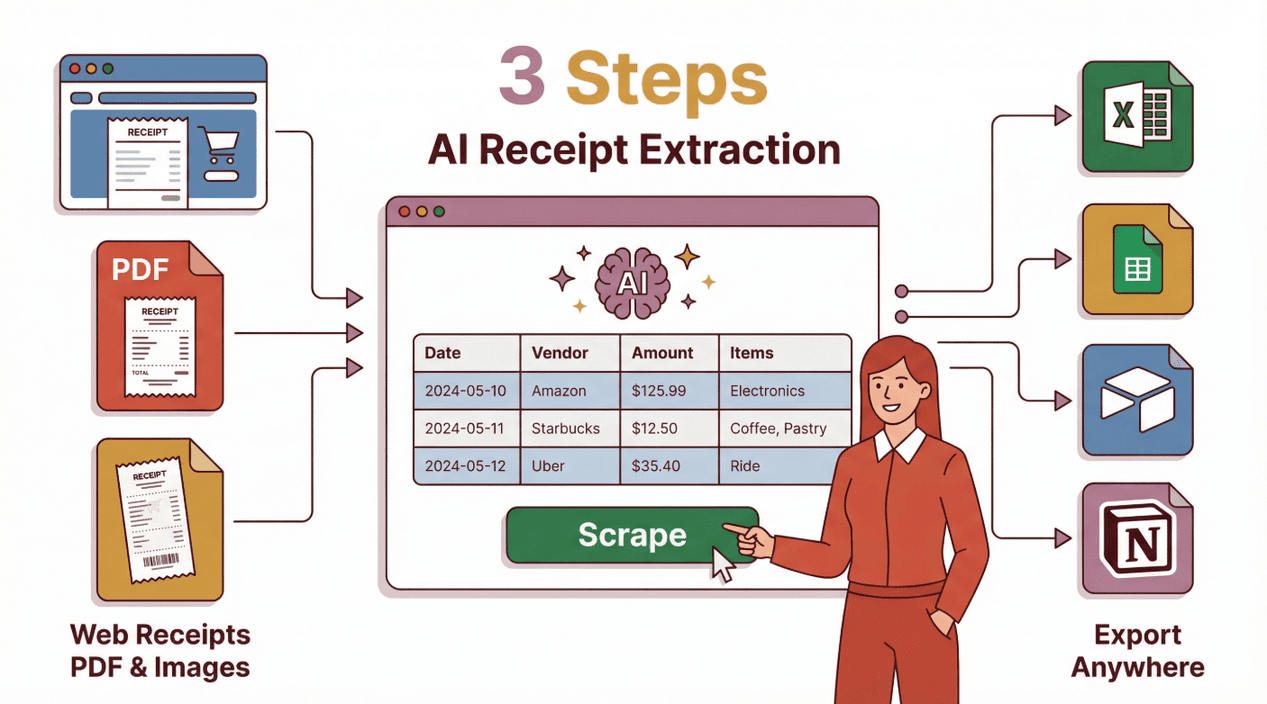 Packen wir es praktisch an. So können Sie Thunderbit nutzen, um Belegdaten zu extrahieren – egal ob Ihre Belege auf einer Website, in einem PDF oder als Bilder vorliegen.
Packen wir es praktisch an. So können Sie Thunderbit nutzen, um Belegdaten zu extrahieren – egal ob Ihre Belege auf einer Website, in einem PDF oder als Bilder vorliegen.
Daten aus Belegen auf Websites extrahieren
Viele Unternehmen stellen Belege inzwischen über Online-Portale aus – denken Sie an die Amazon-Bestellhistorie, Reisebuchungsseiten oder SaaS-Abrechnungs-Dashboards. Mit Thunderbit können Sie:
- Die Belegseite in Chrome öffnen.
- Die Thunderbit-Erweiterung anklicken.
- Auf „KI schlägt Felder vor“ klicken. Die KI von Thunderbit scannt die Seite und schlägt Felder wie „Datum“, „Anbieter“, „Betrag“ und „Einzelposten“ vor.
- Die Felder prüfen oder anpassen. Spalten nach Bedarf hinzufügen, entfernen oder umbenennen.
- Auf „Scrape“ klicken. Thunderbit extrahiert die Daten in eine strukturierte Tabelle.
- In Ihr bevorzugtes Tool exportieren: Excel, Google Sheets, Airtable, Notion, CSV oder JSON.
Das Beste daran? Thunderbit passt sich an unterschiedliche Layouts an, sodass Sie sich keine Sorgen machen müssen, wenn die Website ihr Design ändert ().
Dank der Flexibilität von Thunderbit können Sie Daten aus praktisch jedem Online-Beleg extrahieren, unabhängig davon, wie die Seite aufgebaut ist.
Daten aus PDF- und Bildbelegen extrahieren
Belege gibt es in allen möglichen Formaten und Dateitypen – PDFs, gescannte Bilder, sogar Smartphone-Fotos. Thunderbit macht es einfach:
- Laden Sie Ihre PDF- oder Bilddatei direkt in der Thunderbit-Erweiterung hoch.
- Nutzen Sie „KI schlägt Felder vor“, damit Thunderbit das Dokument analysiert und Spalten empfiehlt.
- Passen Sie die Felder bei Bedarf an – zum Beispiel „Steuerbetrag“ oder „Zahlungsart“ hinzufügen.
- Klicken Sie auf „Scrape“. Die KI von Thunderbit extrahiert die Daten sogar aus komplexen Layouts oder Bildern mit geringer Qualität ().
- Exportieren Sie Ihre Ergebnisse in jedes unterstützte Format.
Die KI von Thunderbit ist darauf trainiert, mehrere Sprachen zu verarbeiten, und kann sogar einige handschriftliche Belege bewältigen – auch wenn (ganz ehrlich) niemand die Kritzeleien eines Baristas entziffern möchte.
Mehr Automatisierung: Subpage-Scraping und Pagination in Thunderbit
Hier zeigt Thunderbit seinen eigentlichen Vorteil für Unternehmen mit großen Belegmengen – etwa monatliche Spesenordner oder Bestellverläufe über mehrere Seiten.
- Subpage-Scraping: Nehmen wir an, Sie haben eine Liste von Belegen, die jeweils auf eine Detailseite verlinken. Thunderbit kann automatisch jede Unterseite aufrufen, die Details extrahieren und alles in einer Tabelle zusammenführen. Kein mühsames Durchklicken jedes einzelnen Belegs mehr ().
- Unterstützung für Pagination: Haben Sie ein Portal mit 50 Seiten voller Belege? Thunderbit verarbeitet die Seitennavigation – egal ob per „Weiter“-Button oder unendlichem Scrollen – sodass Sie einen vollständigen Datensatz ohne manuelle Navigation erhalten.
Das spart Finanz-, Vertriebs- oder Operations-Teams enorm viel Zeit, wenn große Belegmengen schnell und präzise verarbeitet werden müssen.
Die Subpage- und Pagination-Funktionen von Thunderbit sind besonders nützlich, um wiederkehrende Extraktionsaufgaben über große Datensätze hinweg zu automatisieren.
Beleg-Datenextraktion plattformübergreifend mit Thunderbit-Vorlagen automatisieren
Thunderbit ist nicht nur eine leere Arbeitsfläche – Sie können fertige Vorlagen für beliebte Plattformen nutzen. Zum Beispiel:
- Amazon-Bestellungen: Bestelldaten, Artikel, Preise und Versanddetails sofort extrahieren.
- Zillow-Immobilienbelege: Immobiliendetails, Transaktionsbeträge und Daten für die Immobilienanalyse ziehen.
- Reise- und Spesenportale: Buchungsdetails, Anbieternamen und Ausgabenkategorien scrapen.
Diese Vorlagen lassen sich an Ihren Workflow anpassen – egal, ob Sie Daten in Finanzsoftware, ein CRM oder ein individuelles Analyse-Dashboard importieren. Das Ergebnis? Konsistente, zuverlässige Datenextraktion, die mit Ihrem Unternehmen mitwächst ().
Extrahierte Belegdaten exportieren: Flexible Optionen für jedes Unternehmen
Sobald Sie Ihre Daten haben, macht Thunderbit es leicht, sie weiterzuverwenden:
- Excel: Perfekt für klassische Finanzteams und Buchhalter.
- Google Sheets: Ideal für gemeinsame Analysen und Cloud-Workflows.
- Airtable: Geeignet für Teams, die Belege als Teil größerer Datenbanken oder Projekte verwalten.
- Notion: Für alle, die Belege in breitere Wissensdatenbanken oder Wikis integrieren möchten.
- CSV/JSON: Für Entwickler oder alle, die Daten in eigene Systeme importieren.
Sie können mit einem Klick exportieren, und Thunderbit verarbeitet sogar Bildfelder – wenn Ihre Belege also Logos oder Fotos enthalten, erscheinen diese in Ihrer Datenbank ().
Best Practices für genaue und effiziente Beleg-Datenextraktion
Möchten Sie das Beste aus Thunderbit (oder einem anderen Extraktionstool) herausholen? Hier sind meine wichtigsten Tipps:
- Hochwertige Scans oder Bilder verwenden: Unscharfe oder schiefe Belege sind für jede KI schwierig. Wenn möglich, nutzen Sie klare, gut ausgeleuchtete Fotos oder PDFs.
- Extrahierte Daten prüfen: KI ist großartig, aber ein kurzer menschlicher Kontrollblick schadet nie – besonders bei Steuer- oder Compliance-Arbeit.
- KI-Prompts nutzen: Wenn Sie benutzerdefinierte Felder benötigen, etwa zur Kategorisierung von Ausgaben, verwenden Sie die Feldanweisungen von Thunderbit, um die KI zu lenken.
- Wiederkehrende Aufgaben automatisieren: Für Monatsberichte oder laufendes Spesen-Tracking können Sie geplante Scrapes einrichten, damit Ihre Daten immer aktuell sind.
- Gut organisiert bleiben: Exportieren Sie mit klaren Dateinamen und Zeitstempeln und dokumentieren Sie Ihre Datenquellen für Audits oder Prüfungen.
Weitere detaillierte Tipps finden Sie im .
Fazit und wichtigste Erkenntnisse
Die manuelle Extraktion von Belegdaten ist ein Produktivitätskiller – und ganz ehrlich auch niemandes Vorstellung von einer guten Zeit. Mit KI-gestützten Tools wie können Sie einen mühsamen, fehleranfälligen Prozess in einen schnellen, genauen und skalierbaren Workflow verwandeln. Egal ob Ihre Belege online, in PDFs oder als Bilder vorliegen: Der Ablauf von Thunderbit mit „KI schlägt Felder vor“ und „Scrape“ macht die Extraktion kinderleicht. Funktionen wie Subpage-Scraping, Pagination und fertige Vorlagen sorgen dafür, dass Sie selbst die unordentlichsten Belegarchive souverän bewältigen.
Bereit zu sehen, wie viel Zeit – und Nerven – Sie sparen können? und testen Sie es selbst. Ihr Finanzteam wird es Ihnen danken – und vielleicht können Sie sogar den nächsten koffeingetriebenen Dateneingabe-Marathon auslassen.
Weitere Automatisierungstipps und Deep Dives finden Sie im .
FAQs
1. Was ist Beleg-Datenextraktion und warum ist sie wichtig?
Beleg-Datenextraktion ist der Prozess, strukturierte Informationen wie Datum, Anbieter und Betrag aus Belegen für Finanzen, Steuern und Analysen zu gewinnen. Die Automatisierung dieses Prozesses spart Zeit, reduziert Fehler und verbessert die Compliance.
2. Wie verarbeitet Thunderbit verschiedene Belegformate (Web, PDF, Bild)?
Thunderbit nutzt KI, um Daten aus jedem Format zu analysieren und zu extrahieren – laden Sie einfach Ihre Datei hoch oder öffnen Sie die Webseite, und Thunderbit erledigt den Rest. Vorlagen oder Programmierung sind nicht nötig.
3. Kann Thunderbit Daten aus Belegstapeln oder mehrseitigen Archiven extrahieren?
Ja! Mit Subpage-Scraping und Pagination können Sie ganze Ordner oder Beleglisten automatisch verarbeiten, ohne manuell navigieren zu müssen.
4. Welche Exportoptionen bietet Thunderbit für extrahierte Belegdaten?
Sie können nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON exportieren – so lässt sich alles einfach in Ihre Finanz-, CRM- oder Analyse-Tools integrieren.
5. Was sind Best Practices für eine genaue Beleg-Datenextraktion?
Nutzen Sie hochwertige Scans, prüfen Sie die extrahierten Daten auf Genauigkeit, verwenden Sie KI-Prompts für benutzerdefinierte Felder und automatisieren Sie wiederkehrende Aufgaben mit geplanten Scrapes. Gute Organisation und Dokumentation helfen außerdem bei Compliance und Audits.
Mehr erfahren