
Executive Summary
Diese Analyse bewertet 1.238 DTC-Domains auf ihre KI-Suchbereitschaft anhand von vier Ebenen: Qualität der KI-Datei, allgemeine strukturierte Daten, strukturierte Signale auf Produktseiten und Metadaten. Der durchschnittliche Score liegt bei 36,4 von 100, der Median bei 37,0. Nur 11 Domains erreichten nach diesem Modell die Stufe ai_ready.
Die wichtigste Erkenntnis ist die Lücke zwischen bloßer Auffindbarkeit und echtem Produktverständnis. Die größte llms.txt-Qualitätskategorie ist platform_default mit 629 Domains. Das heißt: Viele Marken haben bereits eine grundlegende, KI-lesbare Datei, weil ihre Plattform sie automatisch erstellt. Doch Product-Schema auf der Startseite findet sich nur auf 0,9 % der bewerteten Domains, und Product-Schema auf Produktseiten auf 39,2 % der bewerteten Domains, bei denen Produktseiten untersucht wurden. Preissignale auf Produktseiten erscheinen auf 48,1 %, Bewertungs- oder Reviewsignale auf 43,5 %.
Die Verteilung der Stufen zeigt, wie früh der Markt noch ist:
| KI-Bereitschaftsstufe | Domains |
|---|---|
| Nicht bereit | 435 |
| Teilweise bereit | 425 |
| Grundlegende Auffindbarkeit | 367 |
| KI-bereit | 11 |
Diese Einteilung ist hilfreich, weil sie drei Dinge trennt, die oft durcheinandergeraten. Eine Marke kann auffindbar sein. Eine Marke kann Metadaten haben. Eine Marke kann llms.txt haben. Aber auffindbar zu sein ist nicht dasselbe wie auf Produktebene verstanden zu werden.
Die Verteilung der llms.txt-Qualität macht das noch klarer:
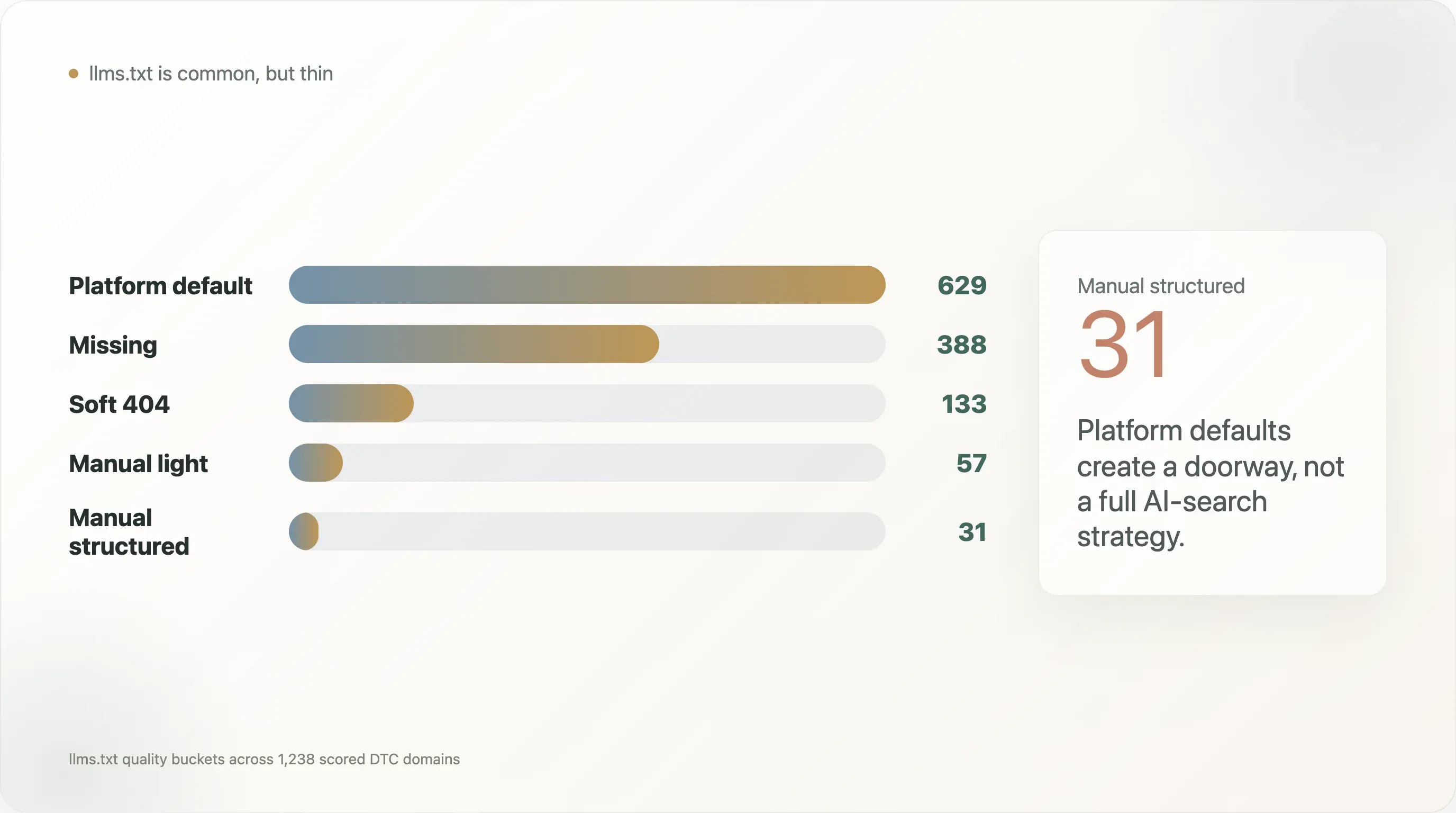
| llms.txt-Qualitätsstufe | Domains |
|---|---|
| Plattformstandard | 629 |
| Fehlend | 388 |
| Soft 404 | 133 |
| Manuell, leicht | 57 |
| Manuell, strukturiert | 31 |
Der stärkste Aufhänger für den Bericht ist deshalb nicht: „DTC-Marken haben llms.txt.“ Diese Aussage ist zu oberflächlich. Der treffendere Befund lautet: Plattformstandards haben zwar eine dünne erste Schicht der KI-Auffindbarkeit geschaffen, aber die meisten DTC-Marken haben die strukturierte Datenebene auf Produktebene noch nicht aufgebaut, die für KI-Shopping und Antwortsysteme nötig ist.
Positive Beispiele zeigen, wie bessere Bereitschaft aussehen kann. Zur Stufe ai_ready gehören Marken wie Mokobara, Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods, La Maison Convertible, Unbloat, NuRange Coffee, Three Ships Beauty und Manukora. Diese Beispiele sind wichtig, weil sie zeigen, dass KI-Bereitschaft nicht auf eine einzige Kategorie oder eine bestimmte Art von Marke beschränkt ist. Lebensmittel, Beauty, Wellness, Möbel, Bekleidung und Spezialhandel können ihre maschinenlesbare Produktebene alle verbessern.
Die am besten teilbaren Erkenntnisse
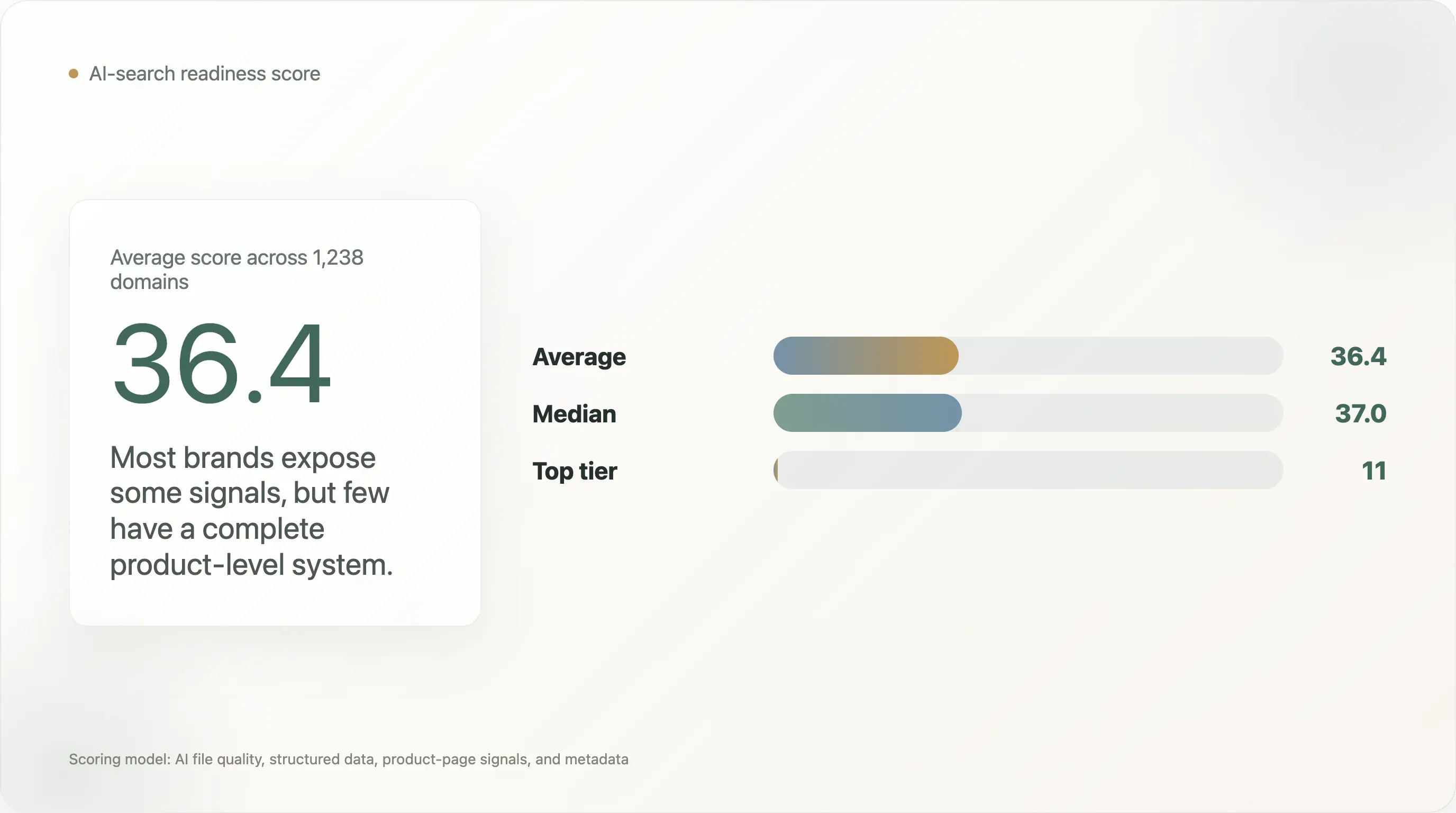
-
Der durchschnittliche DTC-Score für KI-Bereitschaft liegt nur bei 36,4/100.
-
Nur 11 von 1.238 bewerteten Domains erreichten die Stufe
ai_ready. -
llms.txt ist weit verbreitet, aber meist von der Plattform generiert. Die größte Qualitätskategorie ist der Plattformstandard mit 629 Domains.
-
Manuell strukturierte llms.txt-Dateien sind selten. Nur 31 Domains fallen in die Kategorie „manuell, strukturiert“.
-
Product-Schema auf der Startseite ist fast nicht vorhanden. Es erscheint nur auf 0,9 % der bewerteten Domains.
-
Product-Schema auf Produktseiten ist besser, aber immer noch unvollständig. Es erscheint auf 39,2 % der bewerteten Domains, bei denen Produktseiten untersucht wurden.
-
KI-Shopping-Bereitschaft braucht Produktfakten, nicht nur Crawler-Zugriff. Preis-, Angebots-, Review-, Verfügbarkeits- und Product-Schema-Signale sind wichtiger als eine dünne Datei allein.
1. Warum sich KI-Suchbereitschaft von den SEO-Grundlagen unterscheidet
Klassisches SEO fragt, ob eine Seite gecrawlt, indexiert, gerankt und angeklickt werden kann. KI-Suche ergänzt eine andere Ebene: Kann das System Marke, Produkt, Angebot, Preis, Bewertungen, Verfügbarkeit, Richtlinien und Entitätsbeziehungen gut genug verstehen, um Fragen zu beantworten oder Produkte zu empfehlen?
Dieser Unterschied ist für DTC wichtig, weil E-Commerce-Seiten voller Details sind, die für Menschen einfach, für Maschinen aber chaotisch wirken können. Ein Käufer kann eine Produktseite ansehen und Produktname, Preis, Größe, Abo-Option, Rabatt, Bewertungen, Lagerbestand und Rückgaberichtlinie verstehen. Ein Crawler oder KI-Agent braucht dieselben Fakten in konsistenter Form.
Metadaten helfen. Open Graph hilft. Canonical-Tags helfen. llms.txt kann helfen, wichtige Inhalte zu finden. Aber die Struktur auf Produktebene ist der eigentliche Test. Wenn ein KI-Shopping-Assistent fünf Proteinpulver, Pflegeprodukte, Kerzen, Kleider oder Kaffee-Abos vergleicht, braucht er strukturierte Fakten. Ohne diese Fakten kann eine Marke sichtbar sein, aber nicht zuverlässig verstanden werden.
Dieser Bericht trennt vier Bereitschaftsebenen:
- KI-Datei-Ebene: ob llms.txt existiert und ob sie fehlt, ein Soft 404 ist, dem Plattformstandard entspricht, nur leicht manuell erstellt oder manuell strukturiert ist.
- Ebene der allgemeinen strukturierten Daten: JSON-LD, Organization, WebSite, BreadcrumbList und Product-Schema.
- Produktseiten-Ebene: Product-Schema, Angebots- oder Preissignale, Bewertungs- oder Reviewsignale und Verfügbarkeitssignale.
- Metadaten-Ebene: Canonical, Meta Description, Open-Graph-Bild, Twitter Card, hreflang und ähnliche maschinenlesbare Kontexte.
Das Ebenenmodell ist wichtig, weil es vorschnelle Schlüsse verhindert. Eine Marke mit llms.txt, aber ohne Produktfakten, ist nicht so bereit, wie sie scheint. Eine Marke ohne llms.txt, aber mit reichhaltigem Product-Schema auf Produktseiten, kann für Maschinen verständlicher sein, als die Dateiebene vermuten lässt.
2. Die llms.txt-Geschichte: Eine dünne Schicht, meist von Plattformen erstellt
Die llms.txt-Prüfung ergab fünf Qualitätsbereiche:
| Qualitätsbereich | Domains | Interpretation |
|---|---|---|
| Plattformstandard | 629 | Eine standardmäßige, von der Plattform erzeugte Datei, meist dünn, aber gültig |
| Fehlend | 388 | Keine nutzbare Datei gefunden |
| Soft 404 | 133 | Eine irreführende oder nicht nützliche Antwort |
| Manuell, leicht | 57 | Menschlich erstellte oder benutzerdefinierte Datei, aber mit begrenzter Struktur |
| Manuell, strukturiert | 31 | Umfangreichere manuelle Datei mit Überschriften, Links sowie Produkt- oder Richtlinienbegriffen |
Das ist die wichtigste Nuance im Bericht. Oberflächlich betrachtet wirkt die llms.txt-Verbreitung stark, weil Plattformstandard-Dateien häufig sind. Aber Plattformstandard ist nicht dasselbe wie eine durchdachte KI-Suchstrategie. Meist ist es nur eine grundlegende Orientierungsebene.
Das macht Plattformstandard-Dateien nicht wertlos. Sie können Crawlern helfen, wichtige Pfade zu finden. Und sie zeigen, wie schnell Entscheidungen auf Plattformebene den Markt bewegen können. Eine Plattform kann Hunderten von Shops eine neue maschinenlesbare Datei geben, bevor die meisten Brand-Teams überhaupt über KI-Suchprozesse gesprochen haben.
Der Bereich „manuell, strukturiert“ ist aber deutlich kleiner: 31 Domains. Zu den Beispielen in der Analyse gehören manuell strukturierte Dateien von Marken wie Dermalogica, Ad Hoc Atelier, DKNY und mehrere ai_ready-Beispiele wie Magic Mind, Le Petit Ballon, Maine Lobster Now, Yo Mama's Foods und Three Ships Beauty. Diese positiven Beispiele sind hilfreich, weil sie zeigen, was es bedeutet, über eine Standarddatei hinauszugehen: mehr Links, mehr Überschriften, mehr Produktbegriffe, mehr Richtlinienbegriffe und eine bewusstere Struktur.
Auch der Soft-404-Bereich ist wichtig. Ein Soft 404 bedeutet, dass zwar eine Antwort zurückgegeben wird, aber keine nützliche llms.txt-Datei. Das kann einfache Prüfungen in die Irre führen. Für KI-Suchbereitschaft reicht es nicht, ob etwas existiert. Entscheidend ist die Qualität.
3. Die Struktur auf Produktebene ist die eigentliche Lücke
Die größte Lücke in den Daten ist Product-Schema.
Product-Schema auf der Startseite erscheint nur auf 0,9 % der bewerteten Domains. Product-Schema auf Produktseiten erscheint auf 39,2 % der bewerteten Domains, bei denen Produktseiten untersucht wurden. Preissignale auf Produktseiten erscheinen auf 48,1 %, Bewertungs- oder Reviewsignale auf 43,5 %.
Diese Zahlen erzählen eine klare Geschichte. Grundlegende Produktfakten sind nicht durchgängig maschinenlesbar, selbst wenn die Marke einen E-Commerce-Shop betreibt.
Das ist wichtig, weil KI-Suche und KI-Shopping Klarheit belohnen dürften. Wenn eine Produktseite Product-Schema, Angebote, Preis, Verfügbarkeit, Bewertungssignale und Richtlinien-Links offenlegt, liefert sie Maschinen verlässlichere Fakten. Wenn diese Fakten in JavaScript, inkonsistenten Templates, Bildern oder dynamischen Widgets versteckt sind, können Maschinen sie missverstehen oder ignorieren.
Die Lücke bei der Bereitschaft betrifft also nicht nur das Ranking. Es geht um Repräsentation. Wenn KI-Systeme eine Produktkategorie zusammenfassen, Optionen vergleichen, Fragen nach dem „Besten für …“ beantworten oder Shopping-Empfehlungen erzeugen, lassen sich Marken mit saubereren Produktfakten möglicherweise genauer einbeziehen.
Positive Beispiele aus der ai_ready-Gruppe machen das deutlich:
- Mokobara erreichte mit 83 den höchsten Wert in der Auswertung.
- Magic Mind, Le Petit Ballon und Maine Lobster Now erzielten jeweils 81.
- Yo Mama's Foods erreichte 80.
- La Maison Convertible, Unbloat, Vinocheepo und NuRange Coffee erzielten 79.
- Three Ships Beauty erreichte 77.
- Manukora erreichte 75.
Diese Beispiele decken verschiedene Kategorien ab. KI-Bereitschaft ist kein reines Beauty-Thema und auch kein reines Tech-Thema. Sie ist relevant für Lebensmittel, Wellness, Möbel, Bekleidung, Spezialprodukte und jede Kategorie, in der Käufer eine KI nach Empfehlungen, Vergleichen oder Erklärungen fragen könnten.
4. KI-Bereitschaftsstufen: Die meisten Marken liegen noch unter der Schwelle
Die Verteilung der Stufen ist:
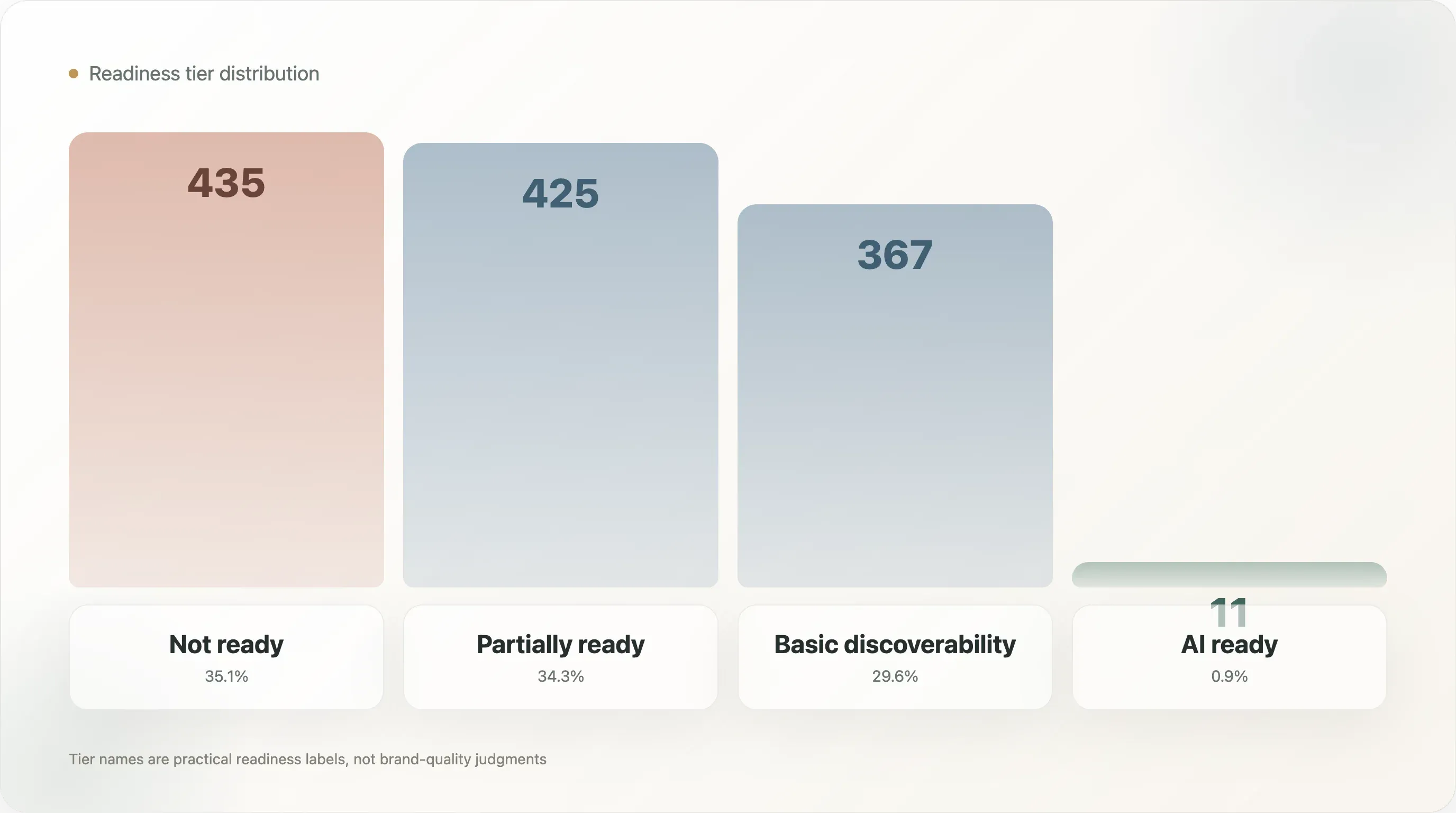
| Stufe | Domains | Anteil an der Stichprobe |
|---|---|---|
| Nicht bereit | 435 | 35,1 % |
| Teilweise bereit | 425 | 34,3 % |
| Grundlegende Auffindbarkeit | 367 | 29,6 % |
| KI-bereit | 11 | 0,9 % |
Die Bezeichnungen sind bewusst praxisnah gewählt. Not ready bedeutet nicht, dass die Marke schlecht ist. Es heißt, dass die öffentlichen Signale, die dieses Modell nutzt, nicht genug KI-Suchbereitschaft zeigen. Partially ready bedeutet, dass einige Bausteine vorhanden sind, aber wichtige Ebenen fehlen. Basic discoverability bedeutet, dass die Marke für Maschinen besser sichtbar ist, aber möglicherweise noch keine vollständige Produktstruktur hat. AI ready bedeutet, dass die Domain eine stärkere Kombination aus Dateiqualität, strukturierten Daten, Produktfakten und Metadaten zeigt.
Nur 11 Domains erreichten die oberste Stufe. Das ist die Schlagzeile, aber die nützlichere Erkenntnis ist die Form der Mitte. Die Stichprobe ist fast gleichmäßig in Nicht bereit, Teilweise bereit und Grundlegende Auffindbarkeit aufgeteilt. Der Markt ist nicht leer. Er ist in einem Übergang. Viele Marken haben einige Signale, aber nur wenige ein vollständiges System.
Das schafft kurzfristig eine Chance. KI-Suchbereitschaft ist noch früh genug, dass eine Marke mit relativ überschaubarer Arbeit von durchschnittlich zu stark wechseln kann: llms.txt verbessern, Schema validieren, Produktfakten offenlegen, Metadaten bereinigen und Produktseiten für Maschinen leichter parsebar machen.
5. Kategorie-Muster: Beauty und Apparel liegen vorne, aber keine Kategorie ist fertig
Die Kategorisierung ist richtungsweisend, nicht exakt. Dennoch zeigt die Tabelle nützliche Muster:
| Kategorie | Stichprobe | Ø KI-Bereitschaft | Manuelle oder strukturierte llms | Product-Schema auf Produktseiten | Rate Product-Schema auf Produktseiten |
|---|---|---|---|---|---|
| Beauty & Skincare | 98 | 46,2 | 3 | 56 | 57,1 % |
| Apparel & Footwear | 149 | 45,7 | 6 | 79 | 53,0 % |
| Jewelry & Accessories | 34 | 44,5 | 0 | 20 | 58,8 % |
| Pet | 15 | 43,5 | 0 | 8 | 53,3 % |
| Baby & Kids | 27 | 42,6 | 1 | 15 | 55,6 % |
| Food & Beverage | 118 | 42,5 | 5 | 58 | 49,2 % |
| Home & Furniture | 48 | 42,3 | 0 | 23 | 47,9 % |
| Health & Wellness | 58 | 40,7 | 6 | 27 | 46,6 % |
| Outdoor & Sports | 49 | 39,8 | 1 | 23 | 46,9 % |
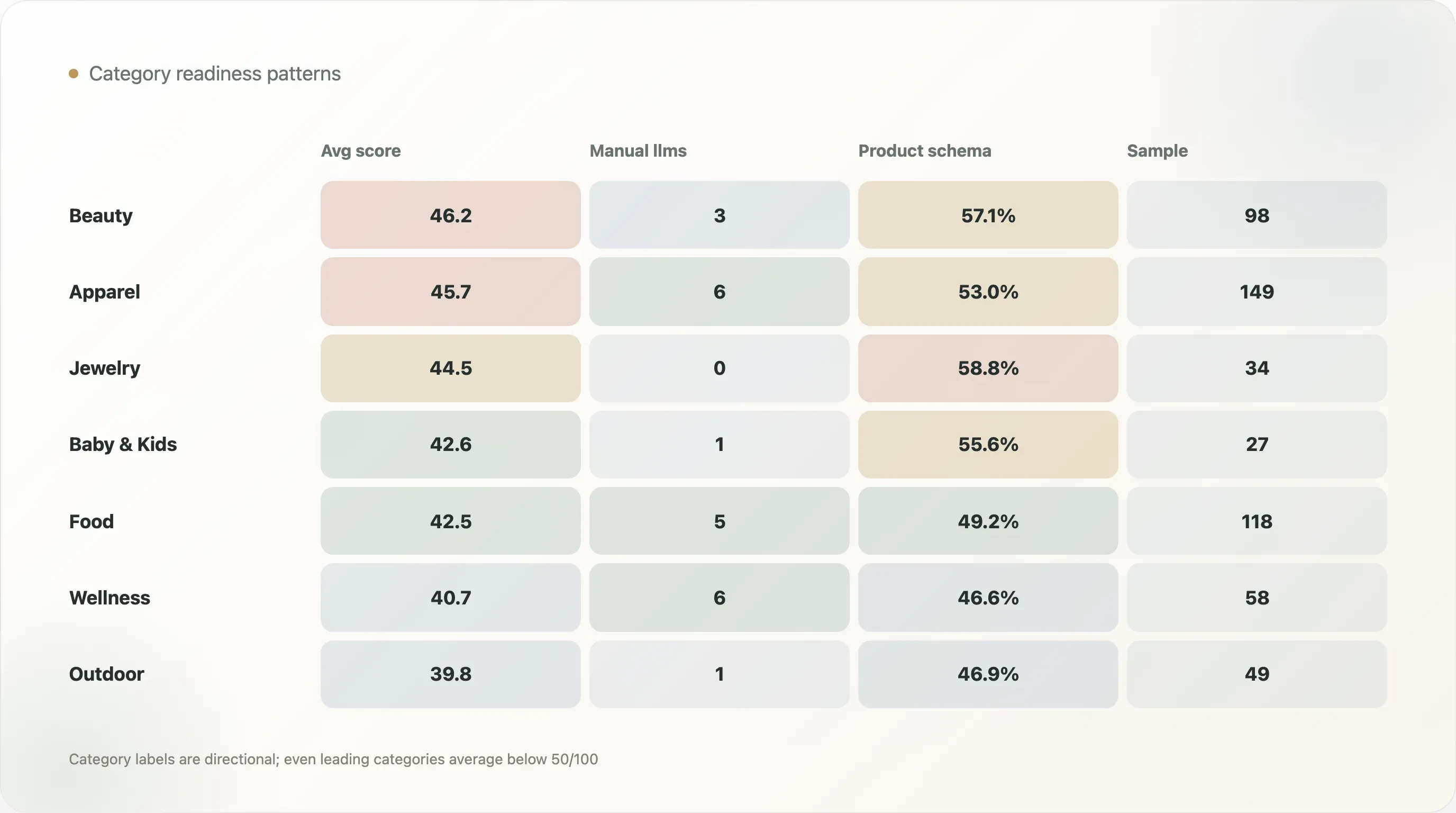
Beauty & Skincare hat mit 46,2 den höchsten durchschnittlichen KI-Bereitschaftsscore. Apparel & Footwear folgt mit 45,7. Diese Kategorien haben oft starke E-Commerce-Templates, umfangreiche Produktkataloge, Reviews, Varianten, visuelle Assets und Content-Bedarf. Sie profitieren möglicherweise schneller von strukturierter Produktarbeit.
Jewelry & Accessories hat mit 58,8 % eine hohe Rate an Product-Schema auf Produktseiten, aber in der Kategorietabelle keine Erkennung für manuelle oder strukturierte llms.txt-Dateien. Das zeigt, warum Bereitschaft in Ebenen gedacht werden muss. Eine Kategorie kann bei Product-Schema stark und bei der KI-Dateiqualität schwach sein.
Food & Beverage enthält mehrere starke positive Beispiele, darunter Maine Lobster Now, Yo Mama's Foods, NuRange Coffee und Manukora. Das ist wichtig, weil Lebensmittel- und Getränkeprodukte oft klare Fakten brauchen: Zutaten, Nährwerte, Portionsgröße, Abo-Option, Herkunft, Versand, Lagerung, Bewertungen und Verfügbarkeit. KI-Systeme können diese Details nur dann korrekt darstellen, wenn die Website sie sauber ausspielt.
Health & Wellness hat mit 10,3 % die höchste Rate an manueller oder strukturierter llms unter den großen Kategorien der Tabelle, aber einen durchschnittlichen Score von 40,7. Das deutet darauf hin, dass einige Marken in dieser Kategorie aktiv mit KI-lesbaren Dateien experimentieren, während die Struktur auf Produktseiten noch Luft nach oben hat. Angesichts des Vertrauens- und Erklärungsbedarfs im Wellness-Bereich sollte diese Kategorie besonders konsequent auf strukturierte Fakten setzen.
Keine Kategorie ist fertig. Selbst die führenden Kategorien liegen im Schnitt unter 50/100. Das macht kategoriespezifische Inhalte zur KI-Bereitschaft zu einer starken Chance für SEO-Autoren und Berater.
6. Wie gute Praxis aussieht: Positive Muster von KI-bereiten Marken
Die Gruppe ai_ready ist klein, aber nützlich, weil sie Muster zeigt, die sich übertragen lassen.
Mokobara erreichte mit 83 den höchsten Wert im Output. Es ist ein Beispiel für starke kombinierte Bereitschaft und nicht nur für einen einzelnen guten Signalwert.
Magic Mind, Le Petit Ballon und Maine Lobster Now erzielten jeweils 81 und fallen in die Kategorie „manuell, strukturiert“ bei llms. Das ist wichtig, weil es bewusst erzeugte Arbeit auf Dateiebene zeigt, nicht nur Plattformstandards.
Yo Mama's Foods erzielte 80, ebenfalls mit manuell strukturierten llms. Lebensmittelmarken profitieren von KI-lesbarer Struktur, weil KI-Systeme nach Zutaten, Geschmack, Einsatzfällen, Rezepten, Ernährungsprofilen und Vergleichen gefragt werden können.
Three Ships Beauty erreichte 77 mit manuell strukturierten llms. Beauty ist eine ideale Kategorie für strukturierte KI-Bereitschaft, weil Käufer nach Hauttyp, Inhaltsstoffen, Routinen, Textur, Bewertungen und Alternativen fragen.
Manukora erzielte 75. Honig und wellnessnahe Lebensmittel erfordern oft Aufklärung zu Herkunft, Qualität, Vorteilen, Zertifizierungen und Anwendung, weshalb strukturierte Produkt- und Richtliniensignale besonders wertvoll sind.
Die Lehre ist nicht, dass jede Marke identisch aussehen muss. Die Lehre ist, dass KI-Bereitschaft ein System ist:
- Eine nützliche llms.txt-Datei
- Saubere Metadaten
- Strukturierte Organization- und WebSite-Daten
- Product-Schema auf Produktseiten
- Preis- und Angebotsignale
- Bewertungs- oder Reviewsignale
- Verfügbarkeitssignale
- Klarheit bei Richtlinien und Support
Jede einzelne Ebene hilft. Die Kombination schafft Bereitschaft.
7. Warum llms.txt allein nicht ausreicht
llms.txt ist zu einem bequemen Synonym für KI-Bereitschaft geworden. Das ist nachvollziehbar, weil sie sichtbar, leicht prüfbar und neu genug ist, um strategisch zu wirken. Doch diese Untersuchung zeigt, warum sie nicht als ganze Geschichte betrachtet werden sollte.
Eine llms.txt-Datei im Plattformstandard kann eine grundlegende Eingangstür schaffen. Sie kann Crawler auf wichtige Seiten hinweisen. Sie kann Maschinen mitteilen, dass die Website einen KI-lesbaren Einstiegspunkt hat. Aber wenn die Produktseiten Produktfakten nicht klar ausspielen, führt die Tür in einen unübersichtlichen Raum.
Das Problem der KI-Suche lautet nicht nur: „Kann der Crawler die Seite finden?“ Es lautet auch:
- Kann der Crawler das Produkt identifizieren?
- Kann er die Marke identifizieren?
- Kann er den Preis parsen?
- Kann er die Verfügbarkeit parsen?
- Kann er Bewertungen oder Rezensionen erkennen?
- Kann er Produktinhalte von Marketinginhalten unterscheiden?
- Kann er Richtlinien verstehen?
- Kann er Varianten vergleichen?
- Kann er die richtige Canonical-Seite zitieren?
llms.txt hilft bei Navigation und Priorisierung. Strukturierte Produktdaten helfen beim Verständnis. KI-Bereitschaft braucht beides.
8. Das Operator-Handbuch: So verbessert man die KI-Suchbereitschaft
Für DTC- und E-Commerce-Teams ist der praktische Ablauf ziemlich klar.
Schritt 1: Die KI-Datei-Ebene prüfen. Hat die Domain llms.txt? Ist sie echt oder ein Soft 404? Entspricht sie dem Plattformstandard, ist sie leicht manuell oder strukturiert? Verweist sie auf nützliche Seiten?
Schritt 2: Metadaten prüfen. Canonical-Tags, Meta Descriptions, Open-Graph-Bilder, Twitter Cards, hreflang, wo relevant, und Mobile-Viewport bestätigen. Das ist nicht glamourös, hilft Maschinen aber beim Aufbau von Kontext.
Schritt 3: JSON-LD validieren. Organization, WebSite, BreadcrumbList und Product-Schema prüfen. Product-Schema ist die wichtigste Lücke im E-Commerce.
Schritt 4: Produktseiten und nicht nur die Startseite prüfen. KI-Shopping wird sich um Produktseiten kümmern. Produktname, Beschreibung, Bild, Preis, Angebot, Verfügbarkeit, SKU, Bewertungen, Varianten und Rückgaberichtlinie sollten bestätigt werden.
Schritt 5: Produktfakten stabil halten. Wichtige Produktfakten nicht nur in Bildern, in Tabs, die nicht sauber rendern, oder in JavaScript-Widgets verstecken, die Crawler möglicherweise nicht parsen.
Schritt 6: Richtlinien klarer machen. Versand, Rückgaben, Abo-Bedingungen, Garantien, Zertifizierungen und Sicherheitsangaben sollten leicht zu finden und leicht zu parsen sein.
Schritt 7: Nach Template-Änderungen erneut testen. Schema bricht oft bei Redesigns, Theme-Wechseln, App-Änderungen und Headless-Migrationen. Strukturierte Daten als Teil der QA behandeln.
Schritt 8: Das System verantworten. KI-Bereitschaft sollte nicht nur bei SEO liegen. Sie betrifft E-Commerce, Produkt, Content, Engineering, Recht und Kundensupport.
9. Was SEO- und Content-Teams zitieren können
Diese Untersuchung liefert mehrere starke Zitatwinkel:
„Nur 11 von 1.238 bewerteten DTC-Domains erreichten die Stufe KI-bereit.“ Das ist der breiteste Aufhänger für Bereitschaft.
„llms.txt ist weit verbreitet, aber meist von der Plattform generiert.“ Der Plattformstandard-Bereich umfasst 629 Domains, manuell strukturierte Dateien erscheinen nur auf 31.
„Product-Schema auf der Startseite erscheint nur auf 0,9 % der bewerteten Domains.“ Das ist die schärfste Lücke bei strukturierten Daten.
„Product-Schema auf Produktseiten erscheint bei 39,2 %, wenn Produktseiten untersucht wurden.“ Das bringt Nuance hinein: Produktseiten sind besser als Startseiten, aber immer noch unvollständig.
„Beauty und Apparel führen die Kategorietabelle an, liegen aber im Schnitt immer noch unter 50/100.“ Das schafft einen kategorienbezogenen Aufhänger.
„KI-Bereitschaft ist mehrschichtig.“ Das ist der wichtigste Lernpunkt für Leser, die llms.txt sonst mit Bereitschaft gleichsetzen würden.
Die Einschränkung ist wichtig: Die Daten spiegeln öffentliche Website-Signale in dieser Stichprobe wider, nicht die gesamte Branchenadoption und nicht die interne Suchleistung.
10. Was KI-Shopping für DTC-Teams verändert
Klassische E-Commerce-Auffindbarkeit beruhte auf Seiten, Rankings, Anzeigen und Klicks. Ein Käufer suchte, verglich Ergebnisse, öffnete Seiten, las Bewertungen und traf Entscheidungen. KI-Shopping und Antwortsysteme verkürzen diesen Weg. Ein Käufer kann nach „der besten zuckerarmen Sauce für Pasta unter der Woche“, „einem Handgepäck-Rucksack unter 200 Dollar mit guten Bewertungen“ oder „einem milden Reiniger für empfindliche Haut ohne Duftstoffe“ fragen. Das KI-System kann Optionen zusammenfassen, bevor der Käufer überhaupt die Seite einer Marke sieht.
Das verändert die Aufgabe der Produktseite. Die Seite muss Menschen weiterhin überzeugen, aber sie muss das Produkt auch so klar beschreiben, dass Maschinen es vergleichen können. Markenton reicht nicht. Schöne Bilder reichen nicht. Ein cleverer Produktname reicht nicht. Die Maschine braucht Fakten: Was ist es, für wen ist es gedacht, was kostet es, ist es verfügbar, welche Varianten gibt es, was sagen Bewertungen, welche Behauptungen sind belegt, welche Zutaten oder Materialien sind relevant und welche Richtlinien gelten.
Deshalb ist die Struktur auf Produktebene wichtiger als eine generische KI-Datei. llms.txt kann einem Crawler helfen zu verstehen, wo er suchen soll. Product-Schema und saubere Produktfakten helfen ihm zu verstehen, was er gefunden hat.
Das Risiko für DTC-Marken besteht nicht nur darin, übergangen zu werden. Es besteht auch darin, falsch dargestellt zu werden. Wenn eine Produktseite unklar ist, kann eine KI-Antwort das falsche Merkmal zusammenfassen, einen wichtigen Unterschied übersehen, eine wesentliche Richtlinie weglassen oder das Produkt unfair mit besser strukturierten Wettbewerbern vergleichen. In diesem Sinne ist KI-Bereitschaft auch ein Thema des Markenschutzes.
In Kategorien mit komplexen Entscheidungswegen ist der Einsatz noch höher. Beauty-Käufer fragen nach Hauttyp, Inhaltsstoffen, Routinen, Empfindlichkeit und Ergebnissen. Lebensmittelkäufer fragen nach Nährwerten, Allergenen, Herkunft, Geschmack, Rezepten und Eignung für bestimmte Ernährungsweisen. Bekleidungskäufer fragen nach Passform, Größe, Materialien, Rückgaben und Styling. Wellness-Käufer fragen nach Evidenz, Anwendung, Sicherheit und Vertrauen. Home-Käufer fragen nach Maßen, Materialien, Lieferung, Montage und Haltbarkeit. Das sind ebenso sehr Probleme maschinenlesbarer Inhalte wie Marketingthemen.
Die Chance ist: Die meisten Marken sind noch früh dran. Der durchschnittliche Bereitschaftsscore liegt nur bei 36,4/100, und nur 11 Domains erreichten die Stufe ai_ready. Eine Marke muss nicht auf einen kompletten Website-Relaunch warten. Sie kann mit Templates, Schema, Richtlinienklarheit und Produktfakten anfangen.
11. Ein KI-Bereitschaftsplan nach Abteilungen
KI-Bereitschaft sollte nicht nur SEO gehören. Sie betrifft mehrere Teams.
SEO verantwortet Auffindbarkeit und Schema-Validierung. SEO-Teams sollten Canonical-Tags, Metadaten, strukturierte Daten, Product-Schema, Breadcrumbs, hreflang und Crawlability prüfen. Sie sollten außerdem überwachen, ob Product-Schema bei Theme-Änderungen und App-Updates erhalten bleibt.
E-Commerce verantwortet Produktseitenfakten. Produktnamen, Preise, Varianten, Verfügbarkeit, Bundles, Abos, Bewertungen, Versandbedingungen und Rückgabedetails müssen klar und konsistent sein. Wenn diese Fakten über Widgets, Tabs, Bilder und Skripte verteilt sind, haben Maschinen Probleme.
Content verantwortet erklärende Tiefe. KI-Systeme belohnen Seiten, die Fragen klar beantworten. Kaufratgeber, Vergleichstabellen, Erklärungen zu Inhaltsstoffen, Seiten für Anwendungsfälle, Größenratgeber und FAQ-Bereiche helfen Mensch und Maschine.
Engineering verantwortet die Implementierungsqualität. Schema sollte valide, stabil und template-basiert sein. Produktfakten sollten nicht vollständig von fragiler clientseitiger Darstellung abhängen. Produktseiten-Templates sollten nach Releases getestet werden.
Recht und Compliance verantworten Aussagen. Wenn ein Produkt Gesundheits-, Nachhaltigkeits-, Sicherheits-, Inhaltsstoff- oder Leistungsversprechen macht, sollten diese korrekt, belegbar und leicht interpretierbar sein. KI-Systeme können unklare Behauptungen verstärken.
Kundensupport verantwortet wiederkehrende Fragen. Support-Tickets zeigen, was Käufer und KI-Systeme fragen könnten: Lieferzeit, Passform, Zutaten, Kompatibilität, Rückgaben, Kündigung von Abos, Pflegehinweise und Produktvergleiche. Diese Fragen sollten in den Produktseiten-Content einfließen.
Die Führungsebene verantwortet Priorisierung. KI-Bereitschaft konkurriert mit vielen anderen Projekten. Das Argument für die Führung ist einfach: Strukturierte Produktfakten unterstützen SEO, KI-Suche, Produktfeeds, bezahltes Shopping, die interne Suche, den Support und die Conversion. Das ist nicht nur ein KI-Projekt.
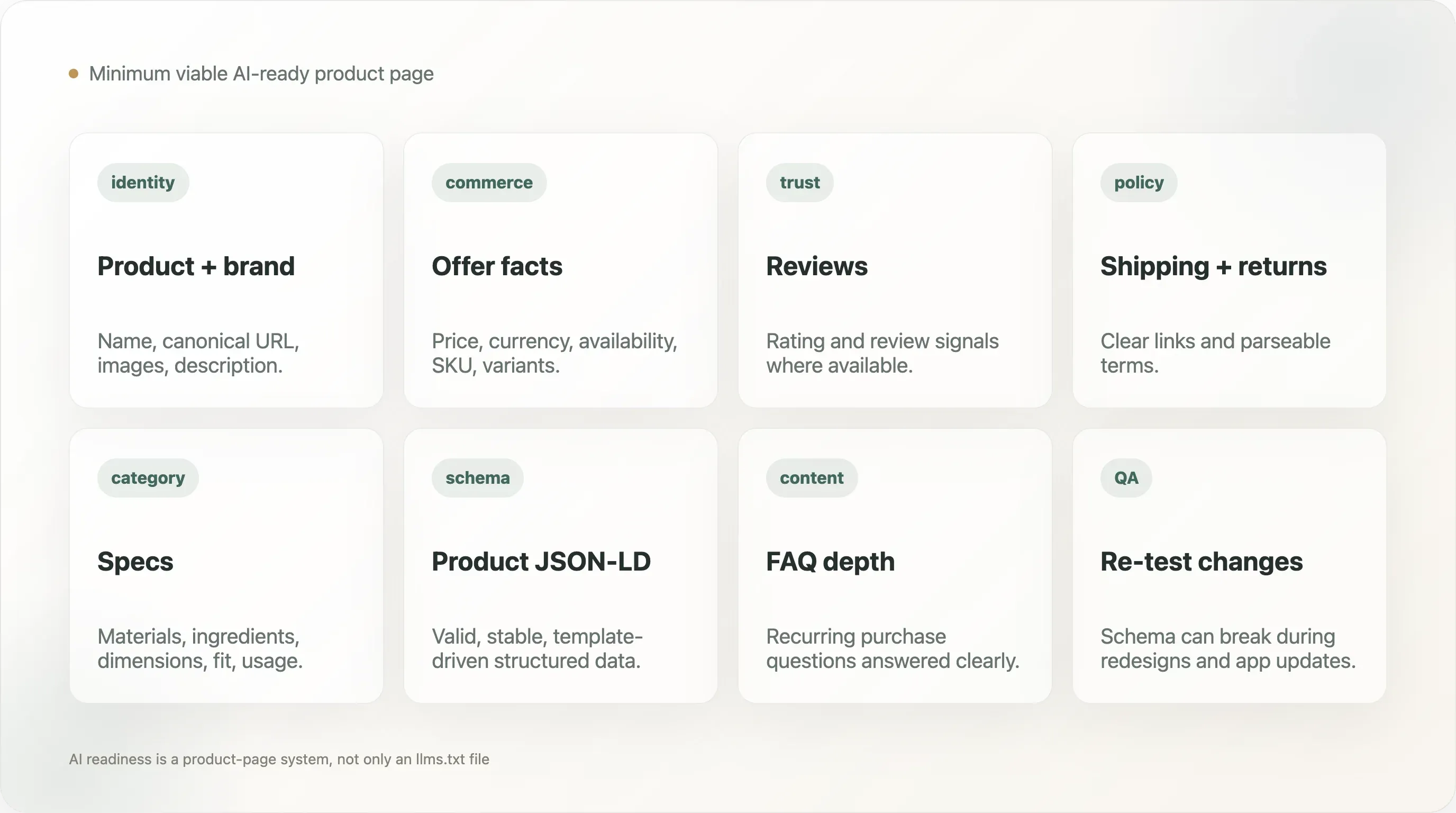
12. Die minimal funktionsfähige KI-bereite Produktseite
Eine praxisnahe DTC-Produktseite sollte Folgendes offenlegen:
- Produktname
- Markenname
- Canonical-URL
- Produktbeschreibung
- Produktbilder
- Preis
- Währung
- Verfügbarkeit
- Varianteninformationen
- SKU oder Produktkennung, wo relevant
- Bewertungs- oder Reviewsignale, falls verfügbar
- Angebotsdetails
- Links zu Versand- und Rückgaberichtlinien
- Material-, Zutaten- oder Spezifikationsdaten, wo für die Kategorie relevant
- FAQ- oder Support-Inhalte für wiederkehrende Kauffragen
Die Seite sollte außerdem valides Product-Schema enthalten und wichtige Fakten nicht nur in Bildern oder Skripten verstecken, die Crawler möglicherweise nicht parsen. Das erfordert keine langweiligen Produktseiten. Es erfordert eine Trennung von überzeugendem Design und verlässlichen strukturierten Fakten.
Für viele Marken ist der schnellste Gewinn nicht das Schreiben eines langen KI-Strategiepapiers. Es ist die Validierung von zehn wichtigen Produktseiten, das Beheben des Schemas und das Sicherstellen, dass die wichtigsten Produktfakten im HTML und in den strukturierten Daten sichtbar sind.
Methodik
Diese Untersuchung nutzt den DTC-Dual-Report-Datensatz, der am 11. Mai 2026 erhoben wurde. Bewertet werden 1.238 Domains mithilfe von master.csv, detection.csv, seo_signals.csv, den rohen llms.txt-Dateien und dem rohen HTML der Produktseiten, sofern verfügbar.
Das Scoring-Modell trennt vier Ebenen:
- KI-Datei-Ebene: Existenz und Qualität von llms.txt.
- Ebene der allgemeinen strukturierten Daten: JSON-LD, Organization, WebSite, BreadcrumbList, Product und verwandte strukturierte Signale.
- Produktseiten-Ebene: Product-Schema, Angebots- oder Preissignale, Bewertungs- oder Reviewsignale und Verfügbarkeitssignale.
- Metadaten-Ebene: Canonical, Meta Description, Open-Graph-Bild, Twitter Card, hreflang und verwandter Seitenkontext.
Das Modell erzeugt einen KI-Bereitschaftsscore von 0 bis 100 und ordnet Domains einer von vier Stufen zu: nicht bereit, teilweise bereit, grundlegende Auffindbarkeit und ai_ready.
Hinweise und Einschränkungen
-
KI-Bereitschaft ist nicht gleich KI-Traffic. Der Score misst keine tatsächlichen Verweise von KI-Suchsystemen oder Shopping-Agenten.
-
Öffentliche Signale sind eine Untergrenze. Manche strukturierten Daten können dynamisch geladen werden oder in Formen erscheinen, die der Crawl nicht erfasst hat.
-
llms.txt-Qualität ist heuristisch. Manuell strukturierte Dateien werden anhand sichtbarer Dateieigenschaften wie Überschriften, Links, Produktbegriffen und Richtlinienbegriffen identifiziert.
-
Die Erkennung von Produktseiten hängt von versuchten Produktseiten-Abrufen ab. Die Prozentwerte für Product-Schema gelten dort, wo Produktseiten versucht und verfügbar waren.
-
Die Stichprobe ist keine vollständige DTC-Volkszählung. Sie ist zugunsten von Marken verzerrt, die in E-Commerce-Tool-Ökosystemen und öffentlichen DTC-Listen sichtbar sind.
-
Kategorien sind richtungsweisend. Sie sind nützlich für einen groben Vergleich, aber keine exakte Taxonomie.
-
KI-Suchstandards entwickeln sich weiter. Das Scoring-Modell ist als praktischer Benchmark für 2026 gedacht, nicht als dauerhafte Definition.
Hinweise zur Reproduzierbarkeit
Der Lieferordner enthält:
analyze_ai_search_readiness.py— Scoring-Skript zur Bewertung von DTC-Domains überllms.txt, strukturierte Daten, Produktseiten-Signale und Metadaten-Signale.ai_search_readiness_scores.csv— KI-Bereitschaftsscores auf Domain-Ebene, Stufen und Komponenten-Signale.llms_quality_audit.csv— Qualitätsprüfung vonllms.txtauf Domain-Ebene, einschließlich der Klassifikationen Plattformstandard, Soft-404, fehlend, manuell-leicht und manuell-strukturiert.category_ai_readiness.csv— Vergleich der KI-Bereitschaft auf Kategorie-Ebene.top_ai_ready_brands.csv— Domains mit den höchsten Scores für redaktionelle Prüfung und Beispiels-Auswahl.lowest_ai_ready_brands.csv— Domains mit den niedrigsten Scores für Lückenanalyse und redaktionelle Prüfung.summary.json— die in diesem Bericht zitierten Kennzahlen, einschließlich Stichprobengröße, Stufenzählung, Durchschnittsscore, Median und Raten von Produktseiten-Signalen.
Korrekturen zur Methodik, Probleme mit dem Datensatz und Folgeanalysen sind willkommen unter support@thunderbit.com. Dieser Bericht erscheint unabhängig von jeder kommerziellen Position, die Thunderbit innehat; wir bauen einen KI-gestützten Web-Scraper und haben ein strukturelles Interesse daran, dass öffentliche E-Commerce-Websites für Menschen, Suchmaschinen und KI-Agenten präziser verständlich werden. Der Benchmark basiert auf 1.238 bewerteten DTC-Domains aus öffentlichen Website-Signalen, die am 11. Mai 2026 erhoben wurden. Die Daten in diesem Bericht stehen für sich. — Das Thunderbit-Forschungsteam, Mai 2026.