
Was Unternehmen 2026 fehlt, sind selten die Daten – es sind die passenden Workflows. Das World Economic Forum rechnet für 2025 mit weltweit 181 Zettabyte an Daten, während IBM schätzt, dass rund 68 % der Unternehmensdaten ungenutzt brachliegen. Genau hier setzt Data-Mining-Software an – nicht als Modewort, sondern als praktische Schicht, die aus Rohdaten, Dokumenten, Webdaten und Event-Streams verwertbare Muster macht.
Die Definition von IBM trifft es bis heute am besten: Data Mining nutzt Machine Learning und statistische Analyse, um aus großen Datensätzen brauchbare Erkenntnisse zu gewinnen. In der Praxis fällt die Kaufentscheidung allerdings über einen breiteren Stack, als die alte Lehrbuchdefinition nahelegt. Manche Teams brauchen visuelle Modellierungswerkzeuge, andere setzen auf gesteuerte Enterprise-Analytics, wieder andere skalieren ML in der Cloud und verarbeiten Streams. Und einige müssen erst unübersichtliche Webdaten einsammeln, bevor überhaupt eine Analyse möglich ist.
Schnelle Empfehlungen nach Workflow
- Sie müssen Website-Daten zügig erfassen, bevor die Analyse beginnt? Starten Sie mit Thunderbit.
- Sie suchen eine visuelle No-Code-Data-Science-Plattform? Werfen Sie einen Blick auf Altair AI Studio und KNIME.
- Sie wollen den einfachsten Open-Source-Einstieg zum Lernen oder für Prototypen? Sehen Sie sich Orange und Weka an.
- Sie brauchen Enterprise-Predictive-Analytics mit Governance? Vergleichen Sie IBM SPSS Modeler, SAS Enterprise Miner und Spotfire Statistica.
- Sie setzen auf Cloud-natives ML und Deployment? Prüfen Sie Microsoft Azure Machine Learning, Dataiku und H2O.ai.
- Sie benötigen große Pipelines oder In-Database-Analytics? Konzentrieren Sie sich auf Teradata und Google Cloud Dataflow.
Sehen Sie, ob Thunderbit zu Ihrem Daten-Workflow passt
Was gilt 2026 als Data-Mining-Software?
Der Begriff deckt heute vier sehr verschiedene Kaufkontexte ab:
- Datenakquise-Tools: sammeln oder strukturieren Rohdaten, bevor die Analyse startet.
- Visuelle Workflow-Tools: Analysten bereinigen Daten, bauen Modelle und bewerten Ergebnisse – weitgehend ohne Code.
- Enterprise-Suiten für Statistik und Vorhersagen: gesteuerte Systeme für größere Organisationen und regulierte Teams.
- Cloud- und Infrastrukturebenen: trainieren, rollen aus oder verarbeiten in Echtzeit – im großen Maßstab.
Deshalb ist diese Liste bewusst gemischt. Kopiert Ihr Team noch stundenlang Felder von Websites, bringt ein browserbasiertes Erfassungstool oft mehr als eine Modellierungs-Suite, die nie produktiv geht. Hakt es dagegen am kontrollierten Ausrollen von Modellen oder an Daten in Warehouse-Größenordnung, ist es genau umgekehrt.
Ein Aspekt wiegt im DACH-Raum schwerer als anderswo: Sobald Sie personenbezogene Daten erfassen oder auswerten, greift die DSGVO. Wer Webdaten sammelt, Kundendaten anreichert oder Profile bildet, braucht eine Rechtsgrundlage, dokumentierte Zwecke und – je nach Risiko – eine Datenschutz-Folgenabschätzung. Das ist kein Bremsklotz, sondern Teil der Werkzeugauswahl: Ein Tool, das sauber exportiert und nachvollziehbar protokolliert, erspart Ihnen später Ärger mit der Aufsichtsbehörde.
Sie möchten sich vorab kurz orientieren? Dieser IBM-Überblick bleibt die beste kompakte Einführung, weil er einordnet, wo Data Mining im Verhältnis zu Analytics, Machine Learning und Prozessverbesserung steht:
Schnelle Vergleichstabelle: Die besten Data-Mining-Softwares 2026
| Tool | Am besten geeignet für | Was hervorsticht | Preissignal |
|---|---|---|---|
| Thunderbit | Business-Teams, die Rohdaten aus dem Web brauchen, bevor die Analyse beginnt | KI-Feldvorschläge, Unterseiten, Pagination, Export nach Sheets / Excel / Airtable / Notion | Kostenloser Plan; kostenpflichtige Self-Service-Tarife; Business-Pläne |
| Altair AI Studio | Visuelle ML-Workflows ohne viel Code | Drag-and-drop-Design, AutoML, interaktive Datenaufbereitung; früher RapidMiner Studio | Kostenlose Testversion; kommerzielle Editionen |
| KNIME | Open-Source-Workflow-Analytics und Automatisierung | Node-basierte Pipelines, starke Community, viele Erweiterungen | Kostenlose Plattform; kostenpflichtige Business-Produkte |
| Orange | Einsteiger und visuell orientiertes Lernen | Sehr zugängliche visuelle Widgets und Explorations-Workflows | Kostenlos und Open Source |
| Weka | Algorithmus-Tests und Ausbildung | Große Bibliothek klassischer ML-Verfahren in einer schlanken GUI | Kostenlos und Open Source |
| IBM SPSS Modeler | Enterprise-Teams für Predictive Analytics | Visuelle Streams, Textanalyse, governance-freundliches Deployment | Angebot / Enterprise |
| SAS Enterprise Miner | Regulierte Branchen und SAS-zentrierte Teams | Ausgereifte Modellierungstiefe, große Datenmengen, SAS-Integration | Angebot / Enterprise |
| Azure Machine Learning | Cloud-Analytics und ML für Microsoft-first-Teams | AutoML, MLOps, Azure-Integration, verwaltetes Deployment | Cloud-Preise nach Nutzung |
| Alteryx | Analysten, die Aufbereitung und Self-Service-Analytics automatisieren | Drag-and-drop-Aufbereitung, wiederholbare Workflows, breite geschäftliche Nutzung | Testversion plus Enterprise-Preise |
| Spotfire Statistica | Statistische Tiefe plus Enterprise-Kontrollen | Fortgeschrittene Analysen, wiederverwendbare Workflows, compliance-orientiertes Monitoring | Angebot / Enterprise |
| Teradata | In-Database-Analytics in Massenskalierung | Starke Performance bei sehr großen Unternehmensdatensätzen und kontrollierten Datenlandschaften | Enterprise / Vertrag |
| Rattle | R-basiertes Lernen und kostengünstige Prototypen | GUI für R-Workflows mit sichtbarem Code | Kostenlos und Open Source |
| Dataiku | Cross-funktionale Data-Science-Teams | No-Code plus Code-Zusammenarbeit, Automatisierung, Governance | Kostenlose Version; Enterprise-Preise |
| H2O.ai | AutoML und skalierbare Modellentwicklung | Schnelle Modellierung, Erklärbarkeit, starkes ML-Ökosystem | Open-Source- und Enterprise-Angebote |
| Google Cloud Dataflow | Echtzeit- und große Batch-Datenverarbeitung | Verwaltete Apache-Beam-Pipelines, Autoscaling, Streaming-Unterstützung | Cloud-Preise nach Nutzung |
Die 15 besten Data-Mining-Software-Tools für Unternehmen 2026
Am besten für schnelle Datenerfassung und visuelles Workflow-Mining
1. Thunderbit
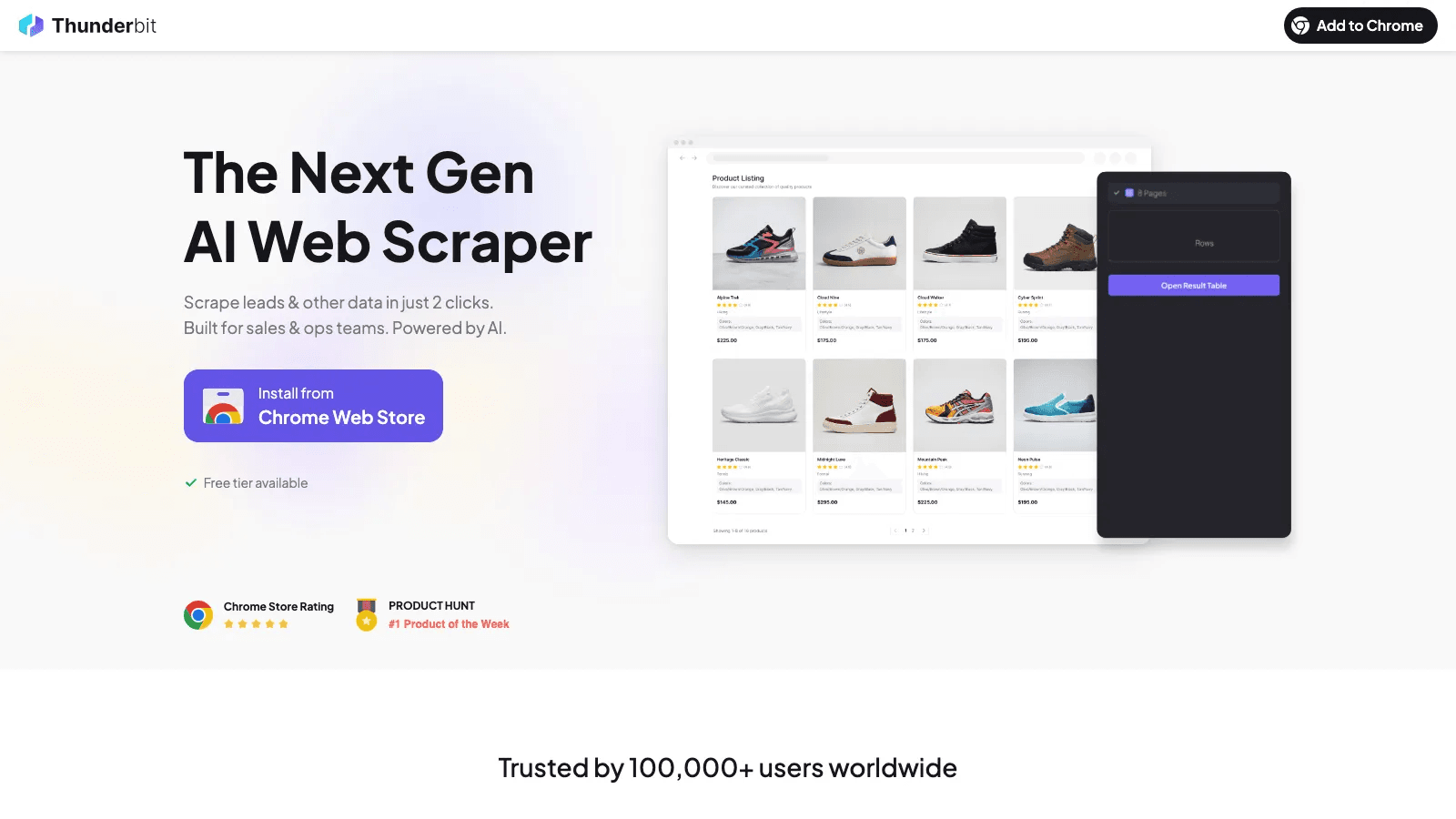
Thunderbit steht auf dieser Liste, weil viele Data-Mining-Projekte schon scheitern, bevor die Modellierung überhaupt beginnt. Die Daten stecken auf Websites, in PDFs, auf internen Rechercheseiten, in Portalen oder bildlastigen Listings. Bekommen Sie sie nicht sauber heraus, nützt der beste Analytics-Stack nichts.
Seine Stärke spielt Thunderbit aus, wenn die Aufgabe im Browser anfängt und das Team rasch strukturierte Ausgaben braucht. Es schlägt Felder per KI vor, scrapt Unterseiten, kommt mit Pagination zurecht und exportiert direkt – ideal für Sales-, E-Commerce-, Operations-, Recruiting- und Marktforschungsteams, die nicht erst eine Scraping-Pipeline aufsetzen wollen.
- Am besten geeignet für: webbasierte Datenakquise für Business-Anwender.
- Was hervorsticht: KI-Feldvorschläge, Anreicherung von Unterseiten, Ausführung im Browser oder in der Cloud, Exporte nach Sheets / Excel / Airtable / Notion.
- Warum es auf der Liste steht: Es löst den Erfassungsengpass, der die nachgelagerte Analyse blockiert.
- Preissignal: Kostenloser Plan, kostenpflichtige Self-Service-Pläne und Business-Optionen.
Thunderbit AI Web Scraper kostenlos testen
2. Altair AI Studio
Altair AI Studio sollte man richtig einordnen, wenn man die Kategorie aus älteren Übersichten kennt: Es ist der heutige Produktname für das, was viele Käufer noch als RapidMiner Studio im Kopf haben. Altair beschreibt es als visuelles Data-Science-Tool zur Bedienung per Drag-and-drop, mit AutoML, interaktiver Datenaufbereitung und Unterstützung für neuere KI-Workflows ebenso wie für klassisches Machine Learning.
Es bleibt eine starke Wahl für Teams, die ernsthaft modellieren wollen, ohne jeden Workflow in Notebooks zu gießen. Gegenüber rein didaktischen Tools schlägt es die bessere Brücke zur wiederholbaren geschäftlichen Nutzung.
- Am besten geeignet für: Analysten und Fachexperten, die geführte visuelle ML-Workflows wollen.
- Was hervorsticht: Drag-and-drop-Canvas, AutoML, interaktive Aufbereitung, breite Datenanbindung.
- Achtung: Kommerzieller ausgerichtet als Open-Source-Optionen, die Beschaffung gewinnt dadurch an Gewicht.
3. KNIME Analytics Platform

KNIME ist nach wie vor das vielseitigste Open-Source-Workflow-Tool der Liste. Die knotenbasierte Oberfläche bleibt für Analysten zugänglich und reicht zugleich tief genug für Teams, die Datenaufbereitung, statistische Analyse, ML, Automatisierung und Erweiterungen in einer wiederholbaren Pipeline bündeln wollen.
Seine Stärke zeigt KNIME überall dort, wo Transparenz zählt. Nutzer prüfen, teilen und erweitern jeden Schritt eines Workflows über Integrationen mit Python, R, Datenbanken und weiteren Tools.
- Am besten geeignet für: Open-Source-first-Teams und analytische Workflows mit hohem Prozessanteil.
- Was hervorsticht: Wiederverwendbare Pipelines, großes Erweiterungs-Ökosystem, starke Community-Akzeptanz.
- Achtung: Die Flexibilität überzeugt, doch die Oberfläche wirkt ingenieurnäher als bei leichten Einsteiger-Tools.
4. Orange
Orange bleibt die freundlichste Data-Mining-Umgebung für alle, die visuell lernen. Die Widget-Oberfläche macht Klassifikation, Clustering, Visualisierung und Text Mining deutlich greifbarer als Tools, die hauptsächlich über die Kommandozeile laufen.
Business-Teams setzen Orange vor allem zum Prototyping oder zum Lernen ein, nicht als gesteuerte Enterprise-Plattform.
- Am besten geeignet für: Einsteiger, Lehrende, Workshops und frühe Exploration.
- Was hervorsticht: Zugängliche visuelle Oberfläche und starke explorative Visualisierung.
- Achtung: Für Enterprise-Deployment oder konsequente Operationalisierung nicht die erste Wahl.
5. Weka
Weka ist aus gutem Grund ein Klassiker geblieben. Es vereint viele Machine-Learning-Algorithmen in einer kompakten Oberfläche, die sich für Experimente, Benchmarking und Lehre eignet.
Geschäftlich zählt es heute weniger als früher, doch für schnelle Tests, Lernzwecke und kleine Datensätze bleibt es nützlich, sobald man viele Algorithmen ohne große Plattform durchprobieren will.
- Am besten geeignet für: Algorithmusvergleich, Ausbildung und Experimente im kleinen Maßstab.
- Was hervorsticht: Breite Abdeckung klassischer ML-Verfahren und eine schlanke GUI.
- Achtung: Neben neueren Workflow-Produkten wirkt es altbacken und ist nicht für modernes MLOps gebaut.
Sie möchten vor der Entscheidung erst sehen, wie ein aktuelles visuelles Workflow-Produkt aussieht? Dieser offizielle Rundgang durch die GUI von Altair AI Studio ist ein hilfreicher Zwischenstopp:
Am besten für Enterprise-Predictive-Analytics und kontrollierte Modellierung
6. IBM SPSS Modeler
IBM SPSS Modeler bleibt die sicherste Option für Organisationen, die Enterprise-Predictive-Analytics wollen, ohne jeden Analysten in codeintensive Tools zu zwingen. Die visuelle Stream-Oberfläche hat sich bewährt, weil auch Business-Stakeholder nachvollziehen können, wie Modelle entstehen, Daten aufbereitet und Ergebnisse gescort werden.
- Am besten geeignet für: große Organisationen, die zugängliche Predictive Analytics mit Governance wollen.
- Was hervorsticht: visuelle Streams, Unterstützung für Textanalyse, Enterprise-Deployment-Optionen.
- Achtung: Ein Plattformkauf, kein Gelegenheits-Tool für einzelne Teams.
7. SAS Enterprise Miner
SAS Enterprise Miner punktet vor allem in regulierten und SAS-zentrierten Umgebungen. Es ist nicht das modischste Werkzeug der Kategorie, bleibt aber dort glaubwürdig, wo Nachvollziehbarkeit, institutionelles Vertrauen und vorhandene SAS-Infrastruktur mehr zählen als Trends – etwa bei deutschen Banken und Versicherern, die Modelle gegenüber BaFin und Wirtschaftsprüfern belegen müssen.
- Am besten geeignet für: Finanzdienstleistungen, Gesundheitswesen, Versicherungen und andere regulierte Workflows.
- Was hervorsticht: Ausgereifte Modellierungstiefe, passende SAS-Integration, Verarbeitung großer Datenmengen.
- Achtung: Ohne bestehende SAS-Investitionen sind neuere Plattformen oft leichter zugänglich.
8. Microsoft Azure Machine Learning
Azure Machine Learning ist die stärkste Option für Teams, die ohnehin im Microsoft-Cloud-Stack zu Hause sind und eine Umgebung zum Experimentieren, für AutoML, Deployment und Monitoring suchen. Microsoft betreibt Azure-Regionen in Deutschland; wer Daten im Inland halten muss, sollte das bei der Region-Wahl von Anfang an mitdenken.
- Am besten geeignet für: Azure-first-Organisationen, die Cloud-ML samt Betrieb wollen.
- Was hervorsticht: AutoML, Modellverwaltung, Deployment-Tools, Integration ins Microsoft-Ökosystem.
- Achtung: Die Cloud-Flexibilität ist eine Stärke, doch je mehr Sie nutzen, desto wichtiger wird die Kostenkontrolle.
9. Alteryx

Alteryx hat sich seinen Platz verdient, weil viel Business-Data-Mining im Kern noch immer darum kreist, Datenarbeit zu bereinigen, zu kombinieren und zu operationalisieren, die früher in Tabellenkalkulationen feststeckte. Analysten kaufen Alteryx, wenn sie dieselben mühsamen Transformationsschritte nicht jede Woche von Hand wiederholen wollen.
- Am besten geeignet für: Business-Analysten, die aufbereitungsintensive Workflows automatisieren.
- Was hervorsticht: Drag-and-drop-Aufbereitung, wiederholbare Analytics-Workflows, starke Akzeptanz bei Business-Anwendern.
- Achtung: Leistungsstark, für kleinere Teams aber selten die günstigste Variante.
10. Spotfire Statistica
Spotfire Statistica gehört zu den besseren Optionen, wenn Organisationen tiefe statistische Methoden mit kontrollierter operativer Nutzung verbinden wollen. Die Positionierung stellt fortgeschrittene Analysen, wiederverwendbare Workflows und compliance-freundliche Governance in den Vordergrund.
- Am besten geeignet für: Fertigung, Gesundheitswesen, Qualitätssicherung und compliance-orientierte Analytics-Teams.
- Was hervorsticht: Ausgereifte statistische Tiefe, wiederverwendbare Modell-Workflows, Monitoring und Governance.
- Achtung: Eher für strukturierte Enterprise-Programme als für leichtes Experimentieren.
Am besten für fortgeschrittene Datenplattformen, Zusammenarbeit und Skalierung
11. Teradata
Teradata steht aus einem klaren Grund hier: Steckt Ihr Data-Mining-Problem in einer riesigen, kontrollierten Datenlandschaft, zählen Performance und Architektur ebenso viel wie die Algorithmen. Teradata bleibt relevant für In-Database-Analytics, Data Warehousing im großen Maßstab und Enterprise-Workloads, die kleinere Spezialtools überfordern.
- Am besten geeignet für: sehr große Unternehmensdatensätze und In-Database-Analytics.
- Was hervorsticht: Skalierung, Performance und Passung zu Unternehmens-Datenlandschaften.
- Achtung: Für die meisten KMU- und Mid-Market-Teams überdimensioniert.
12. Rattle
Rattle baut eine Brücke für Teams oder Lernende, die das R-Ökosystem zum Modellieren nutzen wollen, ohne von Beginn an viel zu skripten. Verstehen Sie es als günstige Oberfläche zum Lernen und Prototypen, nicht als moderne Kollaborationsplattform.
- Am besten geeignet für: R-Lernende und leichtes Prototyping.
- Was hervorsticht: GUI auf Basis von R-Workflows plus sichtbarer Code.
- Achtung: Neben neueren Kollaborationstools wirkt es in die Jahre gekommen.
13. Dataiku
Dataiku zählt zu den ausgewogensten Produkten der Liste, wenn Sie zusammenarbeiten und skalieren wollen. Es funktioniert gut, weil es No-Code-Nutzer und fortgeschrittene Anwender nicht gegeneinander ausspielt: Business-Anwender arbeiten mit Recipes und Dashboards, technische Nutzer behalten dort die Code-Kontrolle, wo sie sie brauchen.
- Am besten geeignet für: funktionsübergreifende Analytics- und Data-Science-Teams.
- Was hervorsticht: No-Code plus Code-Zusammenarbeit, starke Governance, Automatisierung und Deployment-Unterstützung.
- Achtung: Mehr Plattform, als viele kleinere Teams bei einem eng umrissenen Anwendungsfall brauchen.
14. H2O.ai
H2O.ai gehört weiterhin zur Spitzengruppe, wenn Organisationen skalierbar modellieren, AutoML einsetzen und Modelle erklärbar halten wollen. Besonders attraktiv wird es, sobald Geschwindigkeit und Iteration mehr wiegen als ein von Grund auf gebauter Workflow.
- Am besten geeignet für: ML-Teams, die schnelle Iteration und skalierbare Automatisierung wollen.
- Was hervorsticht: AutoML, Modellgeschwindigkeit, Erklärbarkeit, starkes Ökosystem.
- Achtung: Stärker ML-zentriert, als manche Business-Teams es benötigen.
15. Google Cloud Dataflow
Google Cloud Dataflow ist kein klassisches Desktop-Tool fürs „Data Mining“, verdient den letzten Platz aber, weil viele moderne Mining-Projekte vor der Analyse auf Echtzeit- oder große Batch-Pipelines angewiesen sind. Umfasst Ihr Use Case Streaming-Daten, Event-Verarbeitung oder groß angelegte Feature-Aufbereitung, gehört Dataflow zum Mining-Stack.
- Am besten geeignet für: Streaming-Pipelines und groß angelegte Batch-Aufbereitung.
- Was hervorsticht: Verwaltetes Apache Beam, Autoscaling, starke GCP-Integration.
- Achtung: Infrastrukturlastig und kein Analytics-Tool für Business-Anwender.
So wählen Sie, ohne zu viel zu kaufen
Die meisten Fehlkäufe entstehen, weil Teams den eigentlichen Engpass verwechseln:
- Beim Datenzugriff: ein Erfassungstool wie Thunderbit.
- Bei der Produktivität der Analysten: zuerst Altair AI Studio, KNIME, Alteryx und Orange.
- Bei der Enterprise-Governance: SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica oder Dataiku.
- Bei den Cloud-ML-Operations: Azure Machine Learning, H2O.ai oder Dataiku.
- Bei Streaming oder Architektur in riesigem Maßstab: eher Teradata oder Dataflow.

Eine einfache Faustregel hilft: Kaufen Sie das am wenigsten komplexe Tool, das Ihren Engpass beseitigt. Viele Teams brauchen keine riesige Data-Science-Plattform, sondern bessere Datenerfassung, sauberere Aufbereitung und einen Workflow, den ihre Analysten wirklich nutzen.
Enthält Ihre Shortlist webbasierte Datenerfassung, ist dieses Thunderbit-Schnellstartvideo das nützlichste Praxisbeispiel: Es zeigt, wie aus einer unübersichtlichen Seite eine strukturierte Tabelle wird, ohne sich in unnötigen Engineering-Details zu verlieren:
Finale Shortlist nach Teamtyp

- Sales-, E-Commerce- und browserlastige Ops-Teams: Thunderbit, Alteryx, KNIME.
- Analysten, die visuelle Workflows ohne starke Code-Bindung wollen: Altair AI Studio, KNIME, Alteryx, Orange.
- Enterprise-Teams für Predictive Analytics: IBM SPSS Modeler, SAS Enterprise Miner, Spotfire Statistica.
- Funktionsübergreifende Data-Science-Organisationen: Dataiku, Azure Machine Learning, H2O.ai.
- Data-Engineering- und Plattform-Teams: Teradata, Google Cloud Dataflow, Azure Machine Learning.
- Preisbewusste Lernende oder Prototypenbauer: Orange, Weka, Rattle, KNIME.
Müsste ich diese Liste für die meisten Business-Käufer 2026 auf die kürzeste Auswahl eindampfen, sähe sie so aus:
- Thunderbit, um Website- und Dokumentendaten zu erfassen, bevor die Analyse beginnt.
- Altair AI Studio für visuelle Data Science und AutoML, ohne notebook-first arbeiten zu müssen.
- KNIME für flexible Open-Source-Workflows.
- IBM SPSS Modeler für Enterprise-Predictive-Analytics mit businessfreundlicher Oberfläche.
- Dataiku für Teams, die Zusammenarbeit, Governance und Skalierung zugleich brauchen.
Fazit
Die entscheidende Frage lautet nicht, welches Produkt die längste Feature-Liste mitbringt, sondern welches Tool Ihr Team mit möglichst wenig Reibung von Rohdaten zu einer belastbaren Entscheidung führt. 2026 heißt das meistens, Datenerfassung, Aufbereitung, Modellierung und Deployment getrennt zu betrachten, statt auf den einen Kauf zu hoffen, der jede Ebene auf einmal löst. Und im DACH-Raum gehört der Datenschutz von Anfang an in die Rechnung, nicht erst kurz vor dem Go-live.
Beginnt Ihre Arbeit mit öffentlichen Websites, PDFs und unstrukturierten Seiten, starten Sie mit Thunderbit. Beginnt sie mit kontrollierter Enterprise-Modellierung, steigen Sie höher im Stack ein – etwa mit SPSS Modeler, Dataiku oder Azure Machine Learning. Und falls Sie noch herausfinden, welche Plattformklasse Sie überhaupt brauchen, liefern KNIME, Orange und Altair AI Studio am schnellsten klare Signale.
Weiterführende Lektüre
- Was ist Data Scraping und wie macht man es 2025?
- Wie man jede Website mit KI scrapt
- Die besten Web-Scraping-Tools für 2026
FAQs
1. Was ist Data-Mining-Software, einfach aus geschäftlicher Sicht?
Data-Mining-Software hilft Teams, in Rohdaten Muster, Segmente, Anomalien, Trends und Vorhersagesignale aufzuspüren. Im echten Business-Workflow heißt das meist: Daten erfassen, bereinigen, modellieren, scoren und berichten.
2. Ist Data-Mining-Software nur für Data Scientists gedacht?
Nein. Der Markt teilt sich heute in technische und nicht-technische Käufer. Thunderbit, Altair AI Studio, KNIME, Orange und Alteryx senken die Einstiegshürde für Analysten und Business-Teams; Dataiku, Azure ML und H2O.ai bedienen zusätzlich fortgeschrittene Nutzer.
3. Was ist die beste Data-Mining-Software für ein nicht-technisches Team?
Beginnen Ihre Daten im Web, ist Thunderbit der schnellste erste Schritt. Für breitere visuelle Analysen und Workflow-Modellierung sind Altair AI Studio, KNIME, Orange und Alteryx die stärksten Low-Code-Optionen.
4. Sollte ich ein Open-Source-Tool oder eine Enterprise-Plattform wählen?
Wählen Sie Open Source, wenn Sie Flexibilität, niedrigere Einstiegskosten und Raum zum Experimentieren brauchen. Wählen Sie eine Enterprise-Plattform, wenn Governance, Support, Deployment-Kontrollen und Compliance mehr wiegen als einfache Lizenzierung – ein Punkt, der in regulierten DACH-Branchen oft den Ausschlag gibt.
5. Kann ich mehrere dieser Tools zusammen einsetzen?
Ja, und viele Teams sollten genau das tun. Ein typischer Stack erfasst Daten mit Thunderbit, bereitet sie in KNIME oder Alteryx auf und überwacht sie anschließend in einer Cloud- oder Enterprise-Plattform – jede Ebene mit dem passenden Werkzeug statt alles in einem.




