Fühlst du dich manchmal, als würdest du in der endlosen Flut digitaler Infos untergehen? Damit bist du definitiv nicht allein. Heute sorgt jeder Klick, jedes Scrollen und Wischen dafür, dass irgendwo auf der Welt neue Daten entstehen. Bis 2025 werden wir voraussichtlich unfassbare an Daten weltweit erreichen – das bringt selbst die erfahrensten Excel-Profis ins Schwitzen. Doch die eigentliche Herausforderung ist nicht die Masse, sondern zu wissen, wie man die richtigen Infos zur richtigen Zeit einsammelt und daraus echten Mehrwert fürs eigene Business zieht.
Genau hier kommt Data Harvesting ins Spiel. Und 2025, mit KI-Web-Scrapern an vorderster Front, ist Datensammeln längst nicht mehr nur das bloße Zusammentragen von Infos – es ist der Startpunkt für eine smarte Datenstrategie. Aus meiner langjährigen Erfahrung im SaaS- und Automatisierungsbereich weiß ich, wie der Wechsel von Handarbeit zu KI-Tools ganze Teams in Vertrieb, E-Commerce und Operations verändert. Also, schauen wir uns an: Was steckt hinter Data Harvesting, warum ist es so wichtig und wie krempelt KI-gestützte Datensammlung Unternehmen jeder Größe um?
Data Harvesting einfach erklärt: Was steckt dahinter?
Fangen wir ganz von vorne an. Data Harvesting bedeutet, systematisch große Mengen an Daten aus verschiedensten Quellen zu sammeln und zu extrahieren – dazu zählen Webseiten, APIs, Online-Datenbanken, soziale Netzwerke und vieles mehr – um sie für Analysen und Entscheidungen zu nutzen (). Kurz gesagt: So kommst du an die Rohdaten, die alles antreiben – von Marktforschung bis KI-Modellen.
Richtig spannend wird’s, wenn man den Vergleich zu früher zieht. Damals war Datensammeln oft mühsame Handarbeit: Copy & Paste, fehleranfällige Skripte schreiben und hoffen, dass die Website über Nacht nicht ihr Design ändert. Modernes Data Harvesting – vor allem mit KI – ist ein ganz anderes Level. KI-Web-Scraper können selbst unstrukturierte Webseiten „lesen“, verstehen und strukturieren, indem sie Methoden wie Natural Language Processing (NLP) und maschinelles Lernen nutzen, um sich flexibel an neue Situationen anzupassen ().
Ein häufiger Irrtum: Data Harvesting ≠ Data Thinking. Data Harvesting ist nur der erste Schritt – das reine Sammeln der Daten. Data Thinking heißt, diese Rohdaten in strategische Erkenntnisse und Maßnahmen zu verwandeln. Beides gehört zusammen, aber verwechsel das Werkzeug nicht mit dem Ziel.
Warum Data Harvesting für Unternehmen so wichtig ist
Warum solltest du dich 2025 mit Data Harvesting beschäftigen? Ganz einfach: Es ist das Rückgrat moderner Unternehmensstrategien. Egal ob Vertrieb, Marketing, E-Commerce oder Immobilien – wer Daten clever sammelt und nutzt, verschafft sich einen echten Vorsprung.
Hier die wichtigsten Gründe:
![]()
- ROI und Effizienz: berichten, dass Investitionen in Daten und KI richtig was bringen. KI-gestütztes Data Harvesting spart Handarbeit, minimiert Fehler und liefert aktuellere, nutzbare Infos.
- Wettbewerbsanalyse: Mit Echtzeit-Datensammlung kannst du Wettbewerber beobachten, Markttrends erkennen und schneller reagieren als je zuvor.
- Leadgenerierung & Automatisierung: Vertriebsteams bauen gezielte Leadlisten in Minuten statt Wochen. Marketing automatisiert die Recherche für Kampagnen. Operations optimiert interne Abläufe.
Hier ein schneller Überblick über typische Anwendungsfälle:
| Branche | Data Harvesting Anwendungsfall | Strategischer Nutzen |
|---|---|---|
| E-Commerce | Preisüberwachung, SKU-Scraping | Dynamische Preisgestaltung, Bestandsoptimierung |
| Immobilien | Immobilienangebote, Preistracking | Schnellere Objektsuche, Marktanalysen |
| Vertrieb | Leadgenerierung, Kontaktdaten-Extraktion | Qualifizierte Leads, personalisierte Ansprache |
| Marketing | Social Sentiment, Wettbewerber-Kampagnen | Trendanalysen in Echtzeit, Kampagnen-Benchmarking |
| Finanzen | News-Scraping, alternative Datenquellen | Schnellere Handelssignale, Risikobewertung |
Fazit: Data Harvesting ist kein reines IT-Thema – es ist ein strategischer Hebel für Wachstum, Effizienz und Innovation.
Die Entwicklung: Von Handarbeit zu KI-gestützter Datenerfassung
Ich erinnere mich noch gut an die Zeiten, als „Datensammeln“ bedeutete, stundenlang zu kopieren, einzufügen und zu hoffen, dass die Website nicht plötzlich ihr Layout ändert. (Wer schon mal einen Web-Scraper nach einem Website-Update reparieren musste, weiß, was ich meine.) Aber diese Zeiten sind vorbei.
Der Wechsel zu KI-gestützter Datenerfassung ist eine echte Revolution. So sieht der Unterschied heute aus:
| Aspekt | Manuelles Scraping | KI-gestütztes Scraping |
|---|---|---|
| Geschwindigkeit | 2–3 Seiten pro Minute | 1000+ Seiten pro Minute |
| Genauigkeit | Fehleranfällig | Über 99 % Genauigkeit |
| Skalierbarkeit | Begrenzung durch menschliche Arbeit | Nahezu unbegrenzte parallele Aufgaben |
| Anpassung an Änderungen | Bricht bei Website-Updates | ML-Algorithmen passen sich automatisch an |
| Dynamische Inhalte | Probleme mit JavaScript-Seiten | Verarbeitet dynamische, JS-lastige Inhalte |
| Kosteneffizienz | Hohe Personalkosten | Geringere Kosten pro Datensatz |
KI-Web-Scraper nutzen NLP und intelligente Felderkennung, um Webseiten fast wie ein Mensch zu „lesen“ – nur eben mit Maschinen-Tempo und -Skalierung. Sie passen sich Layout-Änderungen an, verarbeiten dynamische Inhalte und strukturieren Daten automatisch. Das heißt: weniger Fleißarbeit, weniger Fehler, mehr Zeit für echte Analysen.
KI-Web-Scraper-Tools: Wie Thunderbit Data Harvesting smarter macht
Ein kurzer Blick auf Thunderbit. Als Mitgründer und CEO bin ich überzeugt, dass wir Data Harvesting für Business-Anwender radikal vereinfachen.
ist eine KI-Web-Scraper Chrome-Erweiterung, mit der jeder Webdaten sammeln kann – ganz ohne Programmierkenntnisse. Das macht Thunderbit besonders:
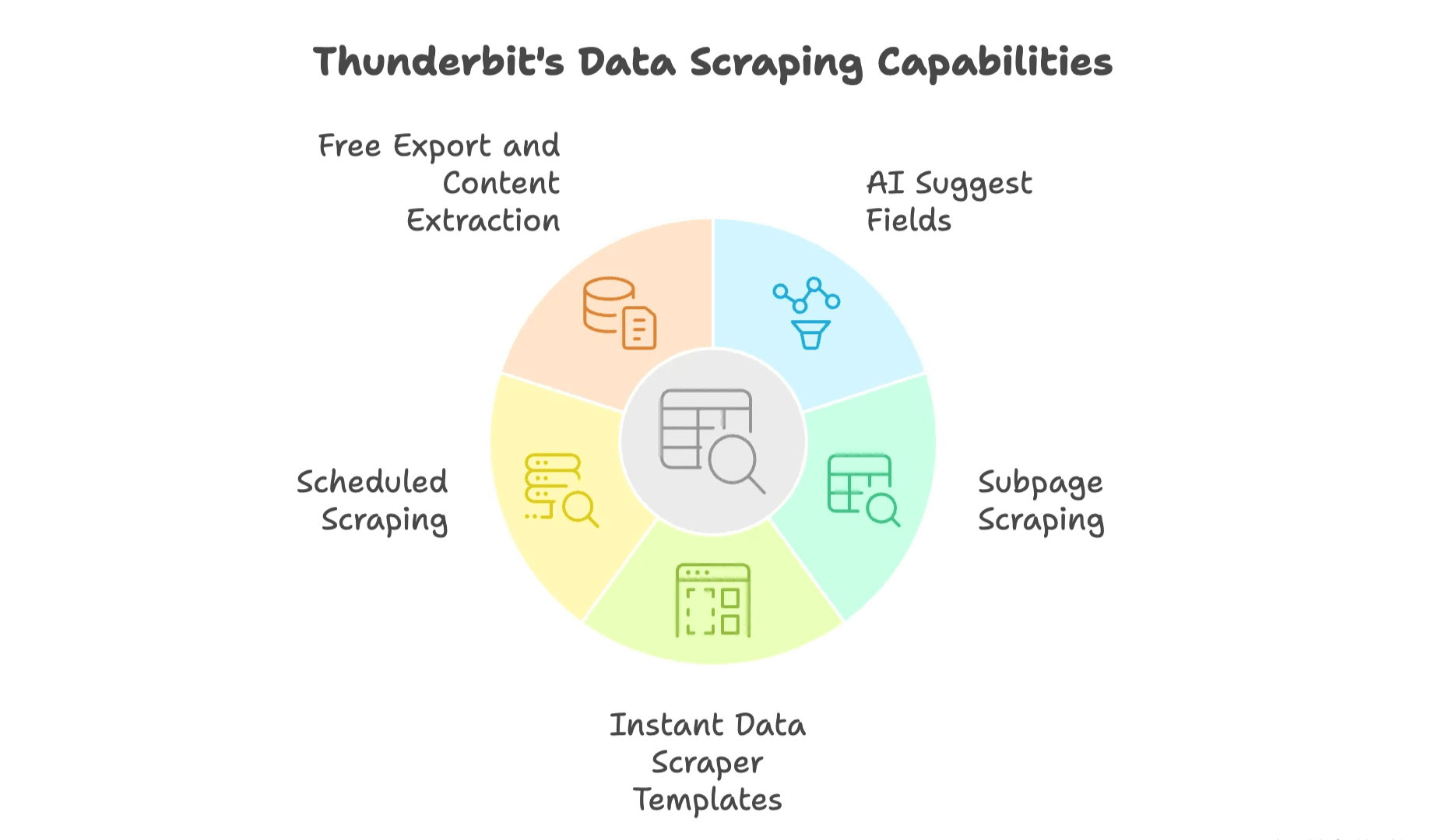
- KI-Feldvorschläge – Thunderbit analysiert die Seite und schlägt automatisch die wichtigsten Spalten und Datentypen vor. So sparst du dir stundenlanges Einrichten und Rätselraten.
- Subpage-Scraping – Thunderbit klickt sich automatisch durch Unterseiten (z. B. Produktdetailseiten oder Profile) und sammelt zusätzliche Daten für eine umfassende Tabelle.
- Fertige Scraper-Vorlagen – Für bekannte Seiten wie Amazon, Zillow oder Instagram gibt’s Vorlagen, mit denen du Daten mit nur einem Klick extrahierst – perfekt für wiederkehrende Aufgaben.
- Geplantes Scraping – Halte deine Datensätze automatisch aktuell. Beschreibe einfach deinen Zeitplan in Alltagssprache (z. B. „jeden Montag um 9 Uhr“) und Thunderbit erledigt den Rest – ganz ohne Erinnerungen oder manuelles Nacharbeiten.
- Kostenloser Export und Content-Extraktion – Exportiere deine Daten direkt nach Google Sheets, Excel, Airtable oder Notion – ohne Bezahlschranke. Außerdem kannst du E-Mails, Telefonnummern und Bilder mit nur einem Klick extrahieren.
Und ja, wir unterstützen 34 Sprachen – denn das Web ist global, und unsere Nutzer auch. Mehr dazu findest du in unserem .
Branchenspezifische Data-Harvesting-Strategien
Wichtig zu wissen: Data Harvesting ist nie ein Einheitsbrei. Methoden, Nutzen und sogar die „Dichte“ wertvoller Daten unterscheiden sich je nach Branche enorm.
- E-Commerce: Hier geht’s um Preisüberwachung, SKU-Scraping und Bestandsmanagement. Der Mehrwert liegt in aktuellen Daten und großer Breite – je mehr Produkte und Wettbewerber, desto besser.
- Immobilien: Im Fokus stehen Immobilienangebote, Preishistorien und Standortdaten. Hier zählt die Tiefe – Details zu jedem Objekt können entscheidend sein.
- Vertrieb: Leadgenerierung ist das A und O. Ziel ist es, saubere, nutzbare Kontaktdaten und Unternehmensinfos aus Nischenverzeichnissen oder sozialen Netzwerken zu extrahieren.
Die „Wertdichte“ der gesammelten Daten ist entscheidend. Im E-Commerce braucht man oft tausende SKUs, um Preistrends zu erkennen. Im Immobilienbereich kann ein einziges Objekt mehrere Tausend Euro wert sein. Wer die Datenlandschaft seiner Branche kennt, kann gezielter und effizienter sammeln.
Automatisierte Dateneingabesysteme mit KI aufbauen
Jetzt wird’s richtig spannend (ja, ich bin Daten-Nerd): Data Harvesting ist nur der Anfang. Die eigentliche Power entfaltet sich, wenn du KI-gestützte Datensammlung in deine Automatisierungssysteme einbaust.
Stell dir vor: Thunderbit sammelt jeden Morgen aktuelle Produktdaten von deinen Lieferanten, überträgt sie direkt ins Warenwirtschaftssystem und löst automatische Preisupdates im Onlineshop aus. Oder dein Vertrieb bekommt täglich neue, bereits bereinigte und formatierte Leads – bereit für die Ansprache.
Praktische Tipps für deine eigene automatisierte Datenpipeline:
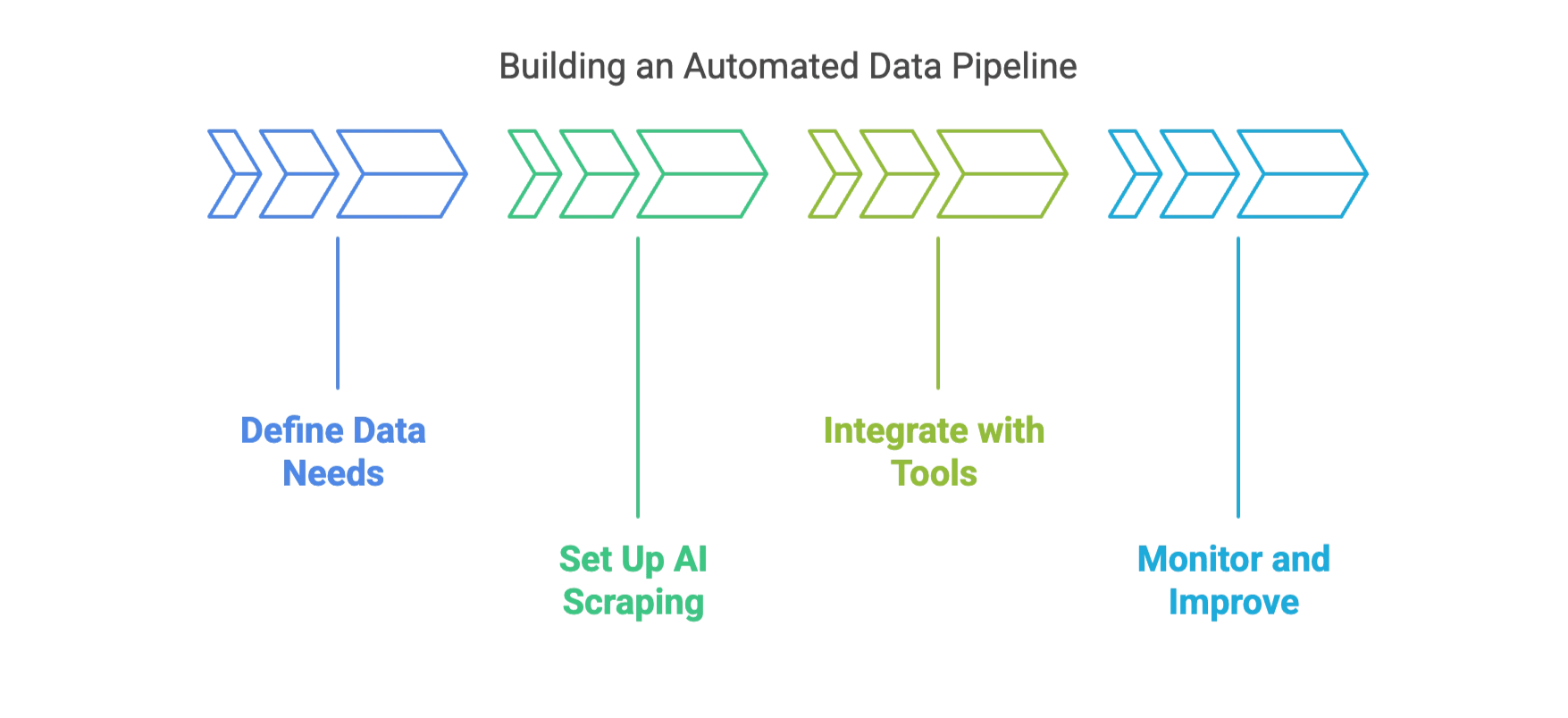
- Definiere deinen Datenbedarf: Überlege zuerst, welche Daten du wirklich brauchst und in welchem Format.
- Richte KI-Scraping-Workflows ein: Nutze Thunderbits und Zeitplanungsfunktionen für die Automatisierung.
- Integriere deine Tools: Exportiere direkt nach Excel, Google Sheets, Airtable oder Notion. Nutze APIs oder Automatisierungsplattformen für die Anbindung an dein CRM oder ERP.
- Überwache und optimiere: Prüfe regelmäßig die Datenqualität und passe deine Pipeline bei Bedarf an.
Das spart nicht nur Zeit, sondern sorgt für ein System, in dem Daten automatisch fließen – und so schnellere, fundiertere Entscheidungen ermöglichen.
Best Practices für Data Harvesting 2025
Mit großer Macht kommt große Verantwortung (und, ehrlich gesagt, auch einiges an Compliance-Aufwand). Hier die wichtigsten Tipps für effektives und faires Data Harvesting 2025:
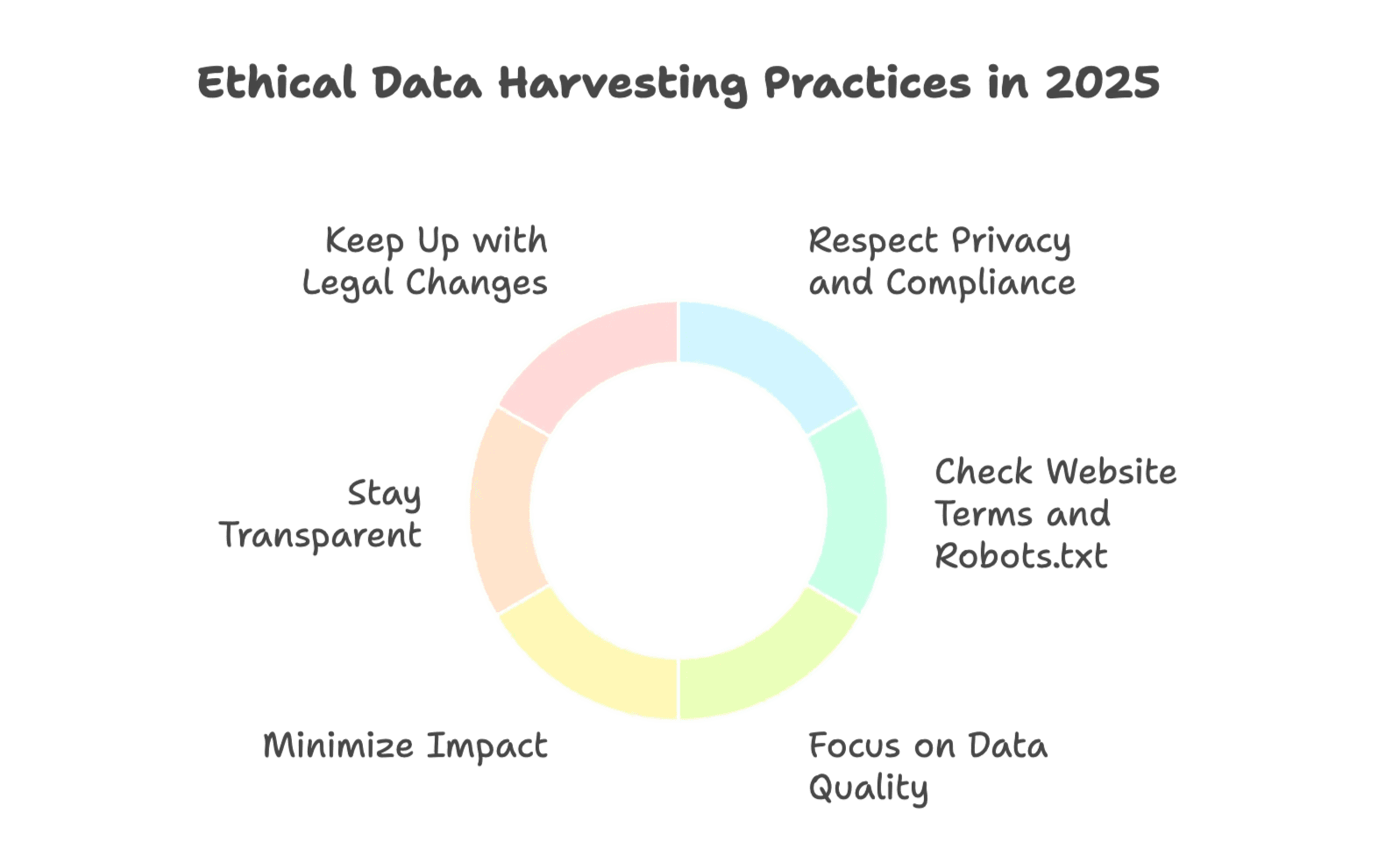
- Datenschutz und Compliance beachten: Halte dich immer an Vorschriften wie . Sammle keine personenbezogenen Daten ohne klare rechtliche Grundlage.
- Website-Regeln und Robots.txt prüfen: Extrahiere keine Daten, die laut Website-Bedingungen oder robots.txt nicht erlaubt sind.
- Datenqualität im Fokus: Nutze KI-Tools zur Bereinigung, Validierung und Duplikaterkennung. Prüfe regelmäßig Stichproben deiner Datensätze.
- Ressourcenschonend arbeiten: Konfiguriere deine Scraper so, dass Zielseiten nicht überlastet werden. Nutze angemessene Abfrageintervalle und Backoff-Strategien.
- Transparenz wahren: Kommuniziere intern (und ggf. extern), welche Daten gesammelt werden und zu welchem Zweck.
- Rechtliche Entwicklungen verfolgen: Die Regeln für Webdaten ändern sich laufend. Bleib informiert und hol dir bei größeren Projekten juristischen Rat.
Eine kompakte Checkliste für Unternehmen:
- Datenquellen und -bedarf identifizieren
- KI-gestützte Tools für Einrichtung und Extraktion nutzen
- Daten regelmäßig validieren und bereinigen
- Einhaltung von Gesetzen und Website-Regeln sicherstellen
- Automatisierte Integration in deine Systeme
- Laufende Überwachung und Anpassung
Mehr dazu findest du in unserem .
Typische Herausforderungen bei KI-gestützter Datensammlung meistern
Auch mit modernster KI läuft Data Harvesting nicht immer wie am Schnürchen. Hier die häufigsten Stolpersteine – und wie KI-Web-Scraper sie meistern:

- Website-Änderungen: Layouts ändern sich ständig. KI-Scraper passen sich dank Machine Learning automatisch an, sodass du nicht jede Woche deine Workflows anpassen musst ().
- Dynamische Inhalte: JavaScript-lastige Seiten waren früher ein Problem. Heute können KI-gesteuerte Headless-Browser wie ein Mensch mit Seiten interagieren und selbst komplexe Inhalte extrahieren.
- Datenqualität: Rohdaten aus dem Web sind oft unstrukturiert. Integrierte KI-Tools zur Bereinigung und Validierung filtern Störfaktoren, entfernen Duplikate und erkennen Fehler frühzeitig.
- Anti-Scraping-Maßnahmen: Viele Seiten setzen CAPTCHAs und IP-Sperren ein. KI-Scraper rotieren Proxys, simulieren menschliches Verhalten und lösen sogar CAPTCHAs, um unauffällig zu bleiben.
- Kompetenzlücke: Nicht jeder ist Programmierer. No-Code-KI-Tools wie Thunderbit machen es auch Fachabteilungen möglich, Scraper visuell einzurichten und zu steuern – so wird Datensammlung für alle zugänglich.
Das Ergebnis: Weniger Zeit mit Technikproblemen, mehr Zeit für die eigentliche Nutzung der Daten.
Fazit: Die Zukunft des Data Harvesting mit KI
Zum Schluss der Blick aufs große Ganze: 2025 ist Data Harvesting längst nicht mehr nur eine technische Aufgabe, sondern ein echter Erfolgsfaktor. Die weltweite Datenexplosion und der Siegeszug von KI-Web-Scrapern machen es Unternehmen möglich, Infos in nie dagewesenem Tempo und Umfang zu sammeln, zu bereinigen und zu nutzen.
Doch der eigentliche Mehrwert entsteht erst, wenn du KI-gestützte Datensammlung in deine Gesamtstrategie einbaust – mit automatisierten Pipelines, branchenspezifischen Ansätzen und Fokus auf Datenqualität und Compliance.
Wer noch auf Handarbeit setzt, sollte jetzt umdenken. Mit den richtigen Tools wird es so einfach wie nie, die Vorteile von KI-gestützter Datensammlung zu nutzen. Und in Zukunft werden die Unternehmen vorne liegen, die Data Harvesting als strategischen, automatisierten und branchenspezifischen Prozess verstehen.
Bereit, die Datenflut in deinen Wettbewerbsvorteil zu verwandeln? Die Zukunft ist da – und sie wird von KI angetrieben.
FAQs
1. Was ist ein KI-Web-Scraper?
Ein KI-Web-Scraper nutzt künstliche Intelligenz, um automatisch Daten von Webseiten zu extrahieren – ganz ohne Programmierkenntnisse.
2. Ist Data Harvesting legal?
Ja, solange Datenschutzgesetze (wie DSGVO/CCPA) eingehalten und die Nutzungsbedingungen sowie robots.txt der Website respektiert werden.
3. Welche Branchen profitieren besonders von Data Harvesting?
Vor allem E-Commerce, Immobilien und Vertrieb profitieren stark von strukturierter Webdatenerfassung.
4. Unterstützt Thunderbit Automatisierung?
Ja, Thunderbit bietet geplantes Scraping und nahtlosen Export zu Tools wie Google Sheets oder Notion.
Mehr erfahren