

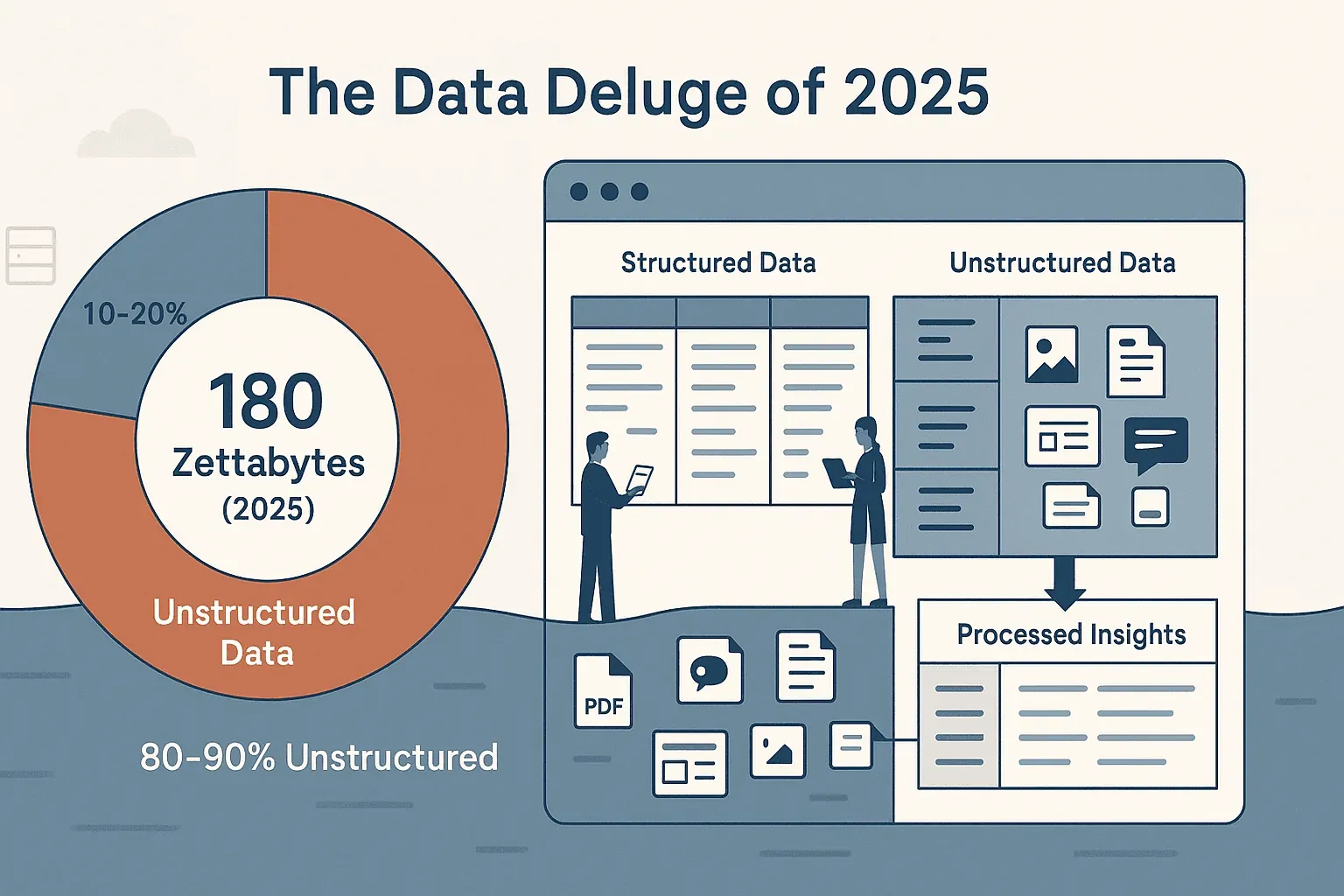
Wer schon einmal versucht hat, Daten von einer Website zusammenzutragen – ob für Sales-Leads, Wettbewerberpreise oder einfach, um einen chaotischen Produktkatalog in den Griff zu bekommen –, weiß: Fürs mühelose Kopieren und Einfügen ist das Web nicht gemacht. Die Datenmengen im Netz sind gewaltig: IDC und Statista bezifferten das weltweite Datenvolumen für 2025 auf rund 180 Zettabyte, und für 2026 steuern wir bereits auf etwa 221 Zettabyte zu. Das eigentliche Problem ist aber nicht die Menge, sondern die Struktur: Rund 80 % dieser Daten sind unstrukturiert und stecken in Webseiten, PDFs, Bildern und dynamischen Feeds. Die meisten Business-Teams – mich eingeschlossen – haben viel zu viel Zeit damit verbracht, sich mit diesem Wust herumzuschlagen, nur um am Ende halbgare Tabellen und ein vertrautes Déjà-vu-Gefühl zu ernten.
Daten von jeder Website mit KI extrahieren Get Started Free
Genau deshalb beschäftigt mich effizientes Website-Crawling so sehr. In diesem Leitfaden zeige ich dir einen praktischen Ansatz Schritt für Schritt, mit dem du jede Website crawlen kannst – ohne Code, ohne Kopfzerbrechen – mithilfe von Thunderbit, unserem KI-gestützten Web-Scraper. Ob du im Vertrieb arbeitest, im Operations-Bereich oder einfach die manuelle Dateneingabe satthast: Ich zeige dir, wie du komplexe Layouts, Paginierung, Unterseiten und sogar Daten aus PDFs und Bildern extrahierst. Machen wir aus dem Chaos des Webs deinen nächsten Geschäftsvorteil.
Was heißt es, eine Website effizient zu crawlen?
Zerlegen wir das Ganze: Eine Website crawlen bedeutet, ein automatisiertes Tool einzusetzen – im Grunde einen Roboterassistenten –, das Webseiten systematisch besucht und genau die Informationen extrahiert, die dich interessieren: Namen, Preise, E-Mails, Produktspezifikationen, was auch immer. Bei effizientem Crawling geht es nicht nur um Geschwindigkeit; es geht um Genauigkeit, minimalen Handaufwand und die Fähigkeit, mit den echten Hürden des Webs umzugehen – Paginierung, Unterseiten, unstrukturierte Daten (Wikipedia).
Was unterscheidet einen effizienten Crawl von einem Kopier-Einfüge-Marathon? Darauf kommt es an:
- Geschwindigkeit: Hunderte Seiten oder Datensätze in Minuten abrufen statt in Stunden.
- Genauigkeit: Genau die Daten erfassen, die du brauchst – ohne Einträge zu übersehen oder Tippfehler einzubauen.
- Automatisierung: Das Tool erledigt die wiederkehrenden Aufgaben, etwa auf „Weiter" klicken oder Links zu Detailseiten folgen.
- Robustheit: Sich an komplexe Layouts, dynamische Inhalte und sogar Änderungen an der Website-Struktur anpassen.
- Wenig Einrichtung: Kein Coding, kein Herumhantieren mit Selektoren, keine ständige Wartung.
Die reale Welt besteht eben nicht aus perfekten Tabellen. Moderne Websites haben Infinite Scroll, mehrstufige Navigation, Login-Anforderungen und Daten, die in PDFs oder Bildern versteckt sind. Effizientes Crawling heißt, all das zu meistern – damit du weniger Zeit mit Fleißarbeit und mehr mit Analyse und Umsetzung verbringst (AIMultiple).
Warum effizientes Website-Crawling für Vertrieb und Operations zählt
Warum kümmern sich Business-Teams so sehr ums Web-Crawling? Weil die richtigen Daten – schnell zur Hand – über die nächste Kampagne, einen Produktlaunch oder das Vertriebsergebnis eines Quartals entscheiden können. Hier einige der häufigsten (und ertragreichsten) Anwendungsfälle, die mir jede Woche begegnen:
| Anwendungsfall | Nutzen & ROI | Beispielergebnis |
|---|---|---|
| Lead-Generierung | Den Sales-Funnel schneller füllen, Stunden bei der Prospektrecherche sparen, manuelle Fehler reduzieren | 5.000 gezielte Leads über Nacht extrahieren, Kampagnen 2 Wochen früher starten, Termine um 30 % steigern |
| Wettbewerber-Preisüberwachung | Dynamische Preisgestaltung ermöglichen, in Echtzeit auf Marktveränderungen reagieren, Margen schützen | Händler passt Preise täglich an und erzielt eine Umsatzsteigerung von 4 % |
| Extraktion von Produktkatalogen/Beständen | Listings aktuell halten, manuelle Dateneingabe reduzieren, Überverkäufe oder falsche Preise vermeiden | E-Commerce-Team aktualisiert 10.000 SKUs täglich und reduziert die Aktualisierungszeit um 90 % |
| Marktforschung & Analyse von Bewertungen | Große Einblicke in Kundenstimmung und Trends gewinnen, Chancen vor der Konkurrenz erkennen | 10.000+ Bewertungen analysieren, neue Produktchancen identifizieren, Marketingbotschaften verbessern |
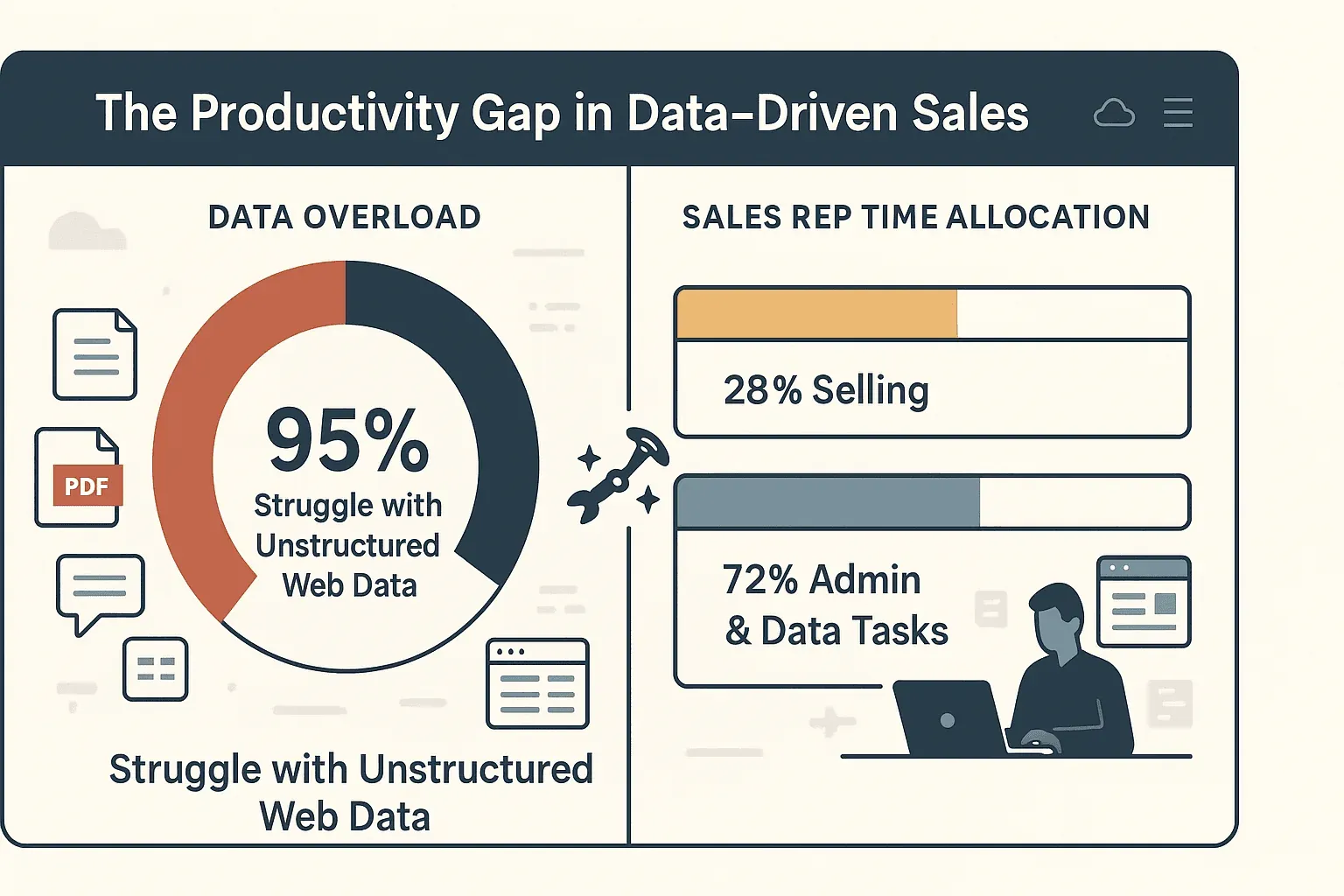
Kurz gesagt: Effizientes Crawling bedeutet schnellere, klügere Entscheidungen – und viel weniger Zeit mit Kopieren und Einfügen. Tatsächlich geben 95 % der Unternehmen zu, dass sie sich schwertun, unstrukturierte Webdaten zu nutzen, und Vertriebsmitarbeiter verbringen nur 28 % ihrer Zeit tatsächlich mit Verkaufen. Der Rest versickert in manueller Dateneingabe und Verwaltung.
Thunderbit: der einfachste Weg, eine Website zu crawlen
Klartext: Die meisten Web-Scraping-Tools sind für Entwickler gebaut, nicht für Business-User. Deshalb haben wir Thunderbit entwickelt – einen KI-gestützten Web-Crawler, der so einfach zu bedienen ist wie eine Essensbestellung. Das zeichnet Thunderbit aus:
- Eingaben in natürlicher Sprache: Beschreibe einfach die gewünschten Daten („Hole alle Produktnamen und Preise von dieser Seite"), und Thunderbits KI erledigt den Rest.
- KI-Felder vorschlagen: Klicke auf „KI-Felder vorschlagen", und Thunderbit scannt die Seite, empfiehlt die besten zu extrahierenden Spalten und richtet den Crawler für dich ein.
- Workflow in 2 Klicks: Sobald du mit den Feldern zufrieden bist, klickst du auf „Scrape". Mehr nicht – kein Coding, keine Vorlagen, kein Ringen mit Selektoren.
- Beherrscht Paginierung & Unterseiten: Thunderbit erkennt und navigiert mehrseitige Listen automatisch und kann Links zu Detailseiten (Unterseiten) folgen, um deine Daten anzureichern.
- Sofortiger Export: Sende deine Daten direkt an Excel, Google Sheets, Airtable oder Notion – oder lade sie kostenlos als CSV/JSON herunter.
- OCR für PDFs & Bilder: Du brauchst Daten aus einer PDF, einem Bild oder einem gescannten Dokument? Thunderbits integrierte OCR extrahiert und strukturiert auch solche Inhalte.
Thunderbit ist für nicht-technische Nutzer gemacht – wenn du im Web surfen und einen Satz tippen kannst, crawlst du eine Website wie ein Profi. Und ja, es gibt einen kostenlosen Tarif, damit du es risikofrei ausprobieren kannst.
Thunderbit kostenlos testen – sofort mit dem Crawlen starten
Website-Crawling im Vergleich: Thunderbit gegen traditionelle Methoden
Stellen wir Thunderbit direkt neben die gängigen Alternativen:
| Ansatz | Einrichtungszeit & Komplexität | Erforderliche Kenntnisse | Wartung & Zuverlässigkeit |
|---|---|---|---|
| Manuelles Copy-and-paste | Extrem hoch, nicht skalierbar | Keine, aber fehleranfällig | 100 % manuell, bei jedem Update neu machen |
| Individueller Code (Python usw.) | Hohe Anfangseinrichtung, Stunden/Tage pro Website | Programmierkenntnisse erforderlich | Bricht bei Website-Änderungen, braucht ständige Fixes |
| Traditionelles No-Code-Tool | Mittel, Klick-und-Konfigurations-Setup | Gering/mittel | Braucht Updates bei Layoutänderungen, kommt nicht immer mit dynamischen Seiten klar |
| Thunderbit (KI-gestützt) | Sehr gering, 2-Klick-Setup | Keine | KI passt sich Änderungen an, minimaler Pflegeaufwand |
Traditionelle Tools bringen dich vielleicht halbwegs ans Ziel, scheitern aber oft an dynamischen Inhalten oder Paginierung – oder sie verlangen, dass du jede Änderung beaufsichtigst. Thunderbits KI liest die Website wie ein Mensch, passt sich neuen Layouts an und übernimmt den unübersichtlichen Teil, damit du das nicht musst (Thunderbit Blog).
Schritt 1: Dein Website-Crawling mit Thunderbit einrichten
Der Einstieg ist kinderleicht:
- Installiere die Thunderbit Chrome-Erweiterung. Erstelle ein kostenloses Konto.
- Öffne deine Zielwebsite. Lade die Seite, die du crawlen möchtest – eine Produktliste, ein Verzeichnis oder sogar eine PDF.
- Öffne Thunderbit. Klicke in der Chrome-Symbolleiste auf das Thunderbit-Symbol.
- Beschreibe deinen Datenbedarf. Entweder klickst du auf „KI-Felder vorschlagen", damit Thunderbit Spalten empfiehlt, oder du gibst einen Prompt in natürlicher Sprache ein (z. B. „Extrahiere für jeden Eintrag Produktname, Preis und Bild-URL").
- Vorschau prüfen und anpassen. Thunderbit zeigt dir eine Vorschau-Tabelle – bearbeite Feldnamen, entferne Überflüssiges oder ergänze bei Bedarf eigene Anweisungen.
Profi-Tipp: Formuliere deine Prompts konkret, aber knapp. Nenne die Datenpunkte so, wie sie auf der Seite erscheinen („Preis", „Adresse" usw.), und überlass Thunderbits KI die eigentliche Arbeit.
Schritt 2: Paginierung und Unterseiten beim Website-Crawling handhaben
Hier spielt Thunderbit seine Stärke voll aus. Die meisten realen Daten liegen nicht auf einer einzigen Seite – sie verteilen sich über paginierte Listen oder stecken in Unterseiten.
- Paginierung: Thunderbit erkennt automatisch „Weiter"-Schaltflächen, Seitennummern oder Infinite Scroll. Klickst du auf „Scrape", lädt es weitere Seiten nach, bis alles erfasst ist – du musst keine URLs von Hand eingeben und dich nicht durch jede Seite klicken.
- Unterseiten-Crawling: Du brauchst mehr Details? Nachdem die Hauptliste extrahiert ist, klicke auf „Unterseiten scrapen". Thunderbit folgt den Links (etwa zu Produktdetailseiten oder Unternehmensprofilen), extrahiert die zusätzlichen Informationen und führt sie in deiner Tabelle zusammen.
Beispiel: Du scrapest eine E-Commerce-Website? Thunderbit holt die Produktliste und besucht dann die Detailseite jedes Produkts, um Spezifikationen, Bewertungen oder Bilder zu ziehen – alles in einem Durchgang.
Best Practice: Lass Thunderbit zuerst den Haupt-Crawl abschließen und nutze danach das Scraping von Unterseiten für die tieferen Daten. Du siehst Fortschrittsmeldungen und kannst prüfen, ob Einträge fehlen.
Schritt 3: Unstrukturierte Daten intelligent mit Thunderbit extrahieren
Nicht alle Daten liegen in sauberen Tabellen vor. Produktbeschreibungen, Bewertungen oder Felder mit gemischtem Format werden für traditionelle Scraper schnell zum Albtraum. Thunderbits KI packt das direkt an:
- Bereinigt und formatiert Daten: Entfernt Währungssymbole, parst Zahlen und trennt komplexe Felder auf (z. B. wird aus „USD 299 (50 % Rabatt!)" einmal „299" und einmal „50 % Rabatt").
- Parst komplexen Text: Extrahiert strukturierte Informationen aus Absätzen (z. B. findet „Standort: New York" in einer Stellenbeschreibung).
- Klassifiziert und labelt: Fügt Kategorien oder Tags anhand des Inhalts hinzu (z. B. „Elektronik" vs. „Kleidung").
- Geht mit Inkonsistenzen um: Passt sich fehlenden Feldern oder Layoutänderungen an und hält deine Daten sauber und korrekt ausgerichtet.
- Fasst zusammen oder übersetzt: Du brauchst eine Ein-Satz-Zusammenfassung oder eine Übersetzung? Füge eine eigene Anweisung hinzu – auch das kann Thunderbits KI.
Das Ergebnis? Saubere, sofort nutzbare Daten – kein stundenlanges Aufräumen mehr in Excel.
Schritt 4: Zwischen Cloud-Crawling und Browser-Crawling wählen
Thunderbit bietet dir zwei Wege zu crawlen, je nach Bedarf:
- Browser-Crawling: Läuft in deinem Chrome-Browser und nutzt deine angemeldete Sitzung. Perfekt für Websites, die eine Authentifizierung verlangen oder starke Anti-Bot-Maßnahmen haben. Du siehst den Crawl live und er ahmt menschliches Surfen nach.
- Cloud-Crawling: Verlagert die Arbeit auf Thunderbits Cloud-Server. Verarbeitet bis zu 50 Seiten parallel – ideal für große Jobs oder geplante Aufgaben. Du kannst deinen Laptop zuklappen und Thunderbit die Schwerarbeit überlassen.
Wann du was verwenden solltest:
- Nutze den Browser-Modus für Seiten mit Login-Pflicht oder wenn du mit der Seite interagieren musst.
- Nutze den Cloud-Modus für öffentliche Seiten, große Mengen oder wenn es dir um Geschwindigkeit und Automatisierung geht.
Der Wechsel zwischen den Modi ist einfach – wähle vor dem Start des Crawls einfach deine bevorzugte Option.
Schritt 5: Daten aus Dokumenten und Bildern mit OCR extrahieren
Manchmal stecken die benötigten Daten in PDFs, Bildern oder gescannten Dokumenten. Thunderbits integrierte OCR (Optical Character Recognition) macht den entscheidenden Unterschied:
- PDFs: Extrahiere Tabellen, E-Mails oder Text aus Berichten, Rechnungen oder Katalogen.
- Bilder: Ziehe Text aus Screenshots, Produktetiketten oder sogar Infografiken.
- Gescanntes Papier: Automatisiere die Dateneingabe aus Quittungen, Verträgen oder Visitenkarten.
Richte Thunderbit einfach auf die PDF- oder Bild-URL, und es extrahiert und strukturiert den Inhalt – ganz ohne Zusatzsoftware. Du kannst OCR sogar mit KI-Prompts kombinieren, um anspruchsvollere Extraktionen durchzuführen („Finde alle E-Mail-Adressen in dieser PDF").
Schritt 6: Deine gecrawlten Daten exportieren und nutzen
Sobald dein Crawl fertig ist, geht es darum, die Daten in die Praxis zu bringen:
- Exportoptionen: Als CSV oder JSON herunterladen oder direkt nach Google Sheets, Excel, Airtable oder Notion exportieren. Alle Formate sind kostenlos – sogar im Basistarif.
- Sales & CRM: Lead-Listen ins CRM importieren, Outreach-Kampagnen starten oder bestehende Kontakte anreichern.
- Marketing & Analyse: Wettbewerberpreise analysieren, Markttrends verfolgen oder Daten in Dashboards visualisieren.
- Operations & Bestand: Lagerbestände überwachen, Kataloge aktualisieren oder bei wichtigen Änderungen Warnungen auslösen.
- Automatisierung: Nutze Integrationen wie Zapier oder Google Apps Script, um Follow-ups, Reporting oder Datenanreicherung zu automatisieren.
Dank Thunderbits strukturierter Ausgabe kommst du in Minuten vom Crawl zur Aktion – nicht erst in Tagen.
Mit Thunderbit AI mit dem Crawlen starten
Fazit und wichtigste Erkenntnisse
Eine Website effizient zu crawlen ist nicht nur ein Wunschtraum für Technikbegeisterte – es ist ein echter Vorteil fürs Geschäft. Mit Thunderbit kann jede und jeder:
- Einen Crawl in Sekunden einrichten – per natürlicher Sprache oder mit KI-vorgeschlagenen Feldern.
- Komplexe Websites bewältigen – mit Paginierung, Unterseiten und dynamischen Inhalten, ganz ohne Code.
- Saubere, strukturierte Daten extrahieren – aus unübersichtlichen Webseiten, PDFs und Bildern.
- Den besten Modus wählen – Browser oder Cloud, je nach Geschwindigkeit, Umfang und Sicherheit.
- Daten sofort exportieren – in deine bevorzugten Tools und Workflows.
Die Zeiten von endlosem Kopieren und Einfügen und ständig kaputten Scrapern sind vorbei. Lade Thunderbit herunter, teste einen kostenlosen Crawl und sieh selbst, wie viel Zeit – und Nerven – du sparst. Dein nächster großer Erkenntnisgewinn oder Vertriebserfolg ist vielleicht nur einen Klick entfernt.
Du willst mehr Tipps und Hintergründe? Schau im Thunderbit Blog vorbei – mit Tutorials, Anwendungsfällen und dem Neuesten rund um KI-gestütztes Web-Crawling.
FAQs
1. Was ist der Unterschied zwischen Web-Crawling und Web-Scraping?
Web-Crawling bedeutet, Websites systematisch zu durchsuchen, um Seiten und Links zu entdecken, während Web-Scraping darauf abzielt, bestimmte Daten aus diesen Seiten zu extrahieren. Thunderbit kombiniert beides – es findet, navigiert und extrahiert die Informationen, die du brauchst.
2. Kann Thunderbit Websites mit Login-Anforderungen verarbeiten?
Ja! Nutze Thunderbits Browser-Modus, um Seiten zu crawlen, die eine Authentifizierung verlangen. Er verwendet deine eingeloggte Chrome-Sitzung, sodass du auf Daten hinter Logins oder Paywalls zugreifst – solange das innerhalb der Nutzungsbedingungen der Website bleibt.
3. Wie geht Thunderbit mit Paginierung und Infinite Scroll um?
Thunderbit erkennt und navigiert automatisch durch paginierte Listen und Seiten mit Infinite Scroll. Es klickt auf „Weiter", scrollt oder lädt weitere Inhalte, bis alle Daten erfasst sind – ganz ohne manuelle Einrichtung.
4. Welche Arten von Daten kann Thunderbit extrahieren?
Thunderbit kann Text, Zahlen, Datumsangaben, URLs, E-Mails, Telefonnummern, Bilder und sogar Daten aus PDFs und Bildern per OCR extrahieren. Du kannst Felder anpassen und KI-Prompts für anspruchsvollere Strukturierung und Bereinigung nutzen.
5. Ist Thunderbit kostenlos nutzbar?
Thunderbit bietet einen kostenlosen Tarif, mit dem du eine begrenzte Anzahl von Seiten crawlen kannst. Alle Exportformate (CSV, Excel, Google Sheets, Airtable, Notion) sind kostenlos enthalten. Bezahlte Tarife starten bei 15 $/Monat (ca. 14 €/Monat) für größere Volumen und erweiterte Funktionen.
Bereit, klüger statt härter zu crawlen? Teste Thunderbit noch heute und lass die KI die Schwerarbeit für dein nächstes Web-Datenprojekt übernehmen. Mehr erfahren
- Wie crawlt man eine Website? Ein Leitfaden für Anfänger
- Wie man Websites crawlt: Eine Schritt-für-Schritt-Anleitung für Anfänger
- Wie man alle Links auf einer Website crawlt: Ein umfassender Leitfaden
KI-Web-Scraper kostenlos testen Get Started Free




