
Das Internet fühlt sich heutzutage manchmal wie ein echtes Minenfeld an. Zwischen Bots, Geo-Blockaden und Datenschutzsorgen ist das Surfen oder großflächige Datensammeln oft ein Balanceakt – als würde man bei jedem Klick aufpassen müssen, nicht in ein digitales Loch zu treten. Ich spreche da aus Erfahrung – als SaaS-Gründer und als jemand, der schon viele Nächte damit verbracht hat, herauszufinden, warum ein 웹 스크래퍼 auf Seite 12.001 plötzlich blockiert wird. Die Wahrheit ist: Proxys sind die unsichtbaren Helfer für alle, die sicher, schnell und zuverlässig im Netz unterwegs sein wollen – egal ob du im Business arbeitest, als Growth Hacker unterwegs bist oder einfach Wert auf Privatsphäre legst.
Und das Thema ist längst Mainstream: Der globale Proxy-Markt boomt – . Über die Hälfte des gesamten Web-Traffics stammt mittlerweile von Bots – viele davon nutzen Proxys, vor allem in Vertrieb, Marketing und Operations, um Blockaden zu umgehen, Daten zu schützen und Prozesse zu automatisieren (). Wer ernsthaft Web Scraping, Marktforschung oder einfach schnelles, privates Surfen betreiben will, kommt an einem guten, kostenpflichtigen Proxy nicht vorbei.
Deshalb stelle ich dir die 15 besten kostenpflichtigen Proxys für sicheres und schnelles Surfen im Jahr 2025 vor. Du erfährst, was jeden Anbieter besonders macht, für wen er geeignet ist und wie du die richtige Wahl für deine Anforderungen (und dein Budget) triffst.
Warum kostenpflichtige Proxys für sicheres und schnelles Surfen wählen?
Mal ehrlich: Kostenlose Proxys sind wie Sushi aus dem Convenience Store – klingt erstmal spannend, aber meistens bereut man es hinterher. Sie sind langsam, unzuverlässig und speichern oder verkaufen oft deine Daten (). Kostenpflichtige Proxys dagegen sind auf Geschwindigkeit, Sicherheit und Zuverlässigkeit ausgelegt. Deshalb setzen immer mehr Unternehmen und Profis darauf:
- Mehr Privatsphäre & Sicherheit: Kostenpflichtige Proxys verstecken deine echte IP, sorgen für anonymes Surfen und (bei seriösen Anbietern) werden keine Aktivitäten geloggt. Das ist besonders wichtig für Journalist:innen, Forscher:innen und alle, die mit sensiblen Daten arbeiten ().
- Höhere Geschwindigkeit & unbegrenztes Datenvolumen: Premium-Proxys nutzen leistungsstarke Rechenzentren oder optimierte Peer-Netzwerke. Viele bieten unbegrenztes oder sehr großzügiges Datenvolumen, sodass du nicht mitten im Prozess ausgebremst wirst ().
- Zuverlässiger Zugriff auf geo-blockierte Inhalte: Top-Anbieter haben Server in über 100 Ländern, oft sogar mit Auswahl auf Stadtebene. Das ist unverzichtbar für Ad-Verification, Marktforschung oder das Management von Accounts in verschiedenen Regionen ().
- Web Scraping & Automatisierung im großen Stil: Für ernsthaftes Web Scraping sind rotierende Residential-Proxys Pflicht, um IP-Sperren zu vermeiden. Kostenpflichtige Netzwerke übernehmen die Rotation, lösen CAPTCHAs und halten deine Automatisierung am Laufen ().
- Compliance und Support: Kostenpflichtige Proxys bieten rechtliche Sicherheit, ethische IP-Quellen und echten Kundensupport. Wenn mal was hakt, bist du nicht auf dich allein gestellt ().
Kein Wunder, dass 70 % der Web-Scraper ohne Proxy bei Google blockiert werden (). Für Vertrieb, Marketing und Operations sind kostenpflichtige Proxys heute das Rückgrat jeder ernsthaften Web-Automatisierung.
So haben wir die besten kostenpflichtigen Proxys ausgewählt
Bei so vielen Anbietern stellt sich die Frage: Wie findet man den richtigen? Das waren meine wichtigsten Kriterien (und darauf solltest du auch achten):
- Zuverlässigkeit & Verfügbarkeit: Über 99 % Uptime sind Pflicht. Ausfälle bedeuten Datenverlust und verpasste Chancen.
- Geschwindigkeit & Datenvolumen: Schnelle Antwortzeiten und großzügiges (oder unbegrenztes) Datenvolumen sind entscheidend für Scraping, Streaming und Automatisierung.
- Größe & Vielfalt des IP-Pools: Je größer und vielfältiger der Pool, desto geringer das Risiko, geblockt zu werden.
- Geografische Abdeckung: Brauchst du Proxys in Paris, São Paulo oder Singapur? Top-Anbieter bieten weltweite (oft sogar stadtgenaue) Abdeckung.
- Proxy-Typen & Protokoll-Unterstützung: Residential, Datacenter, Mobile, ISP, SOCKS5, HTTP/HTTPS – je nach Anwendungsfall brauchst du unterschiedliche Lösungen.
- Benutzerfreundlichkeit & Verwaltung: Übersichtliche Dashboards, API-Zugriff und Features wie Auto-Rotation oder Session-Steuerung erleichtern die Arbeit.
- Kundensupport: 24/7-Support und schnelle Hilfe sind besonders bei geschäftskritischen Prozessen unverzichtbar.
- Preis-Leistungs-Verhältnis: Von Pay-as-you-go bis Enterprise – ich habe auf flexible Optionen für jedes Budget geachtet.
- Compliance & Datenschutz: Nur seriöse, ethische Anbieter kamen in die Auswahl – keine dubiosen IP-Quellen oder Datenprotokollierung.
Jetzt geht’s los mit der Übersicht.
1. Thunderbit
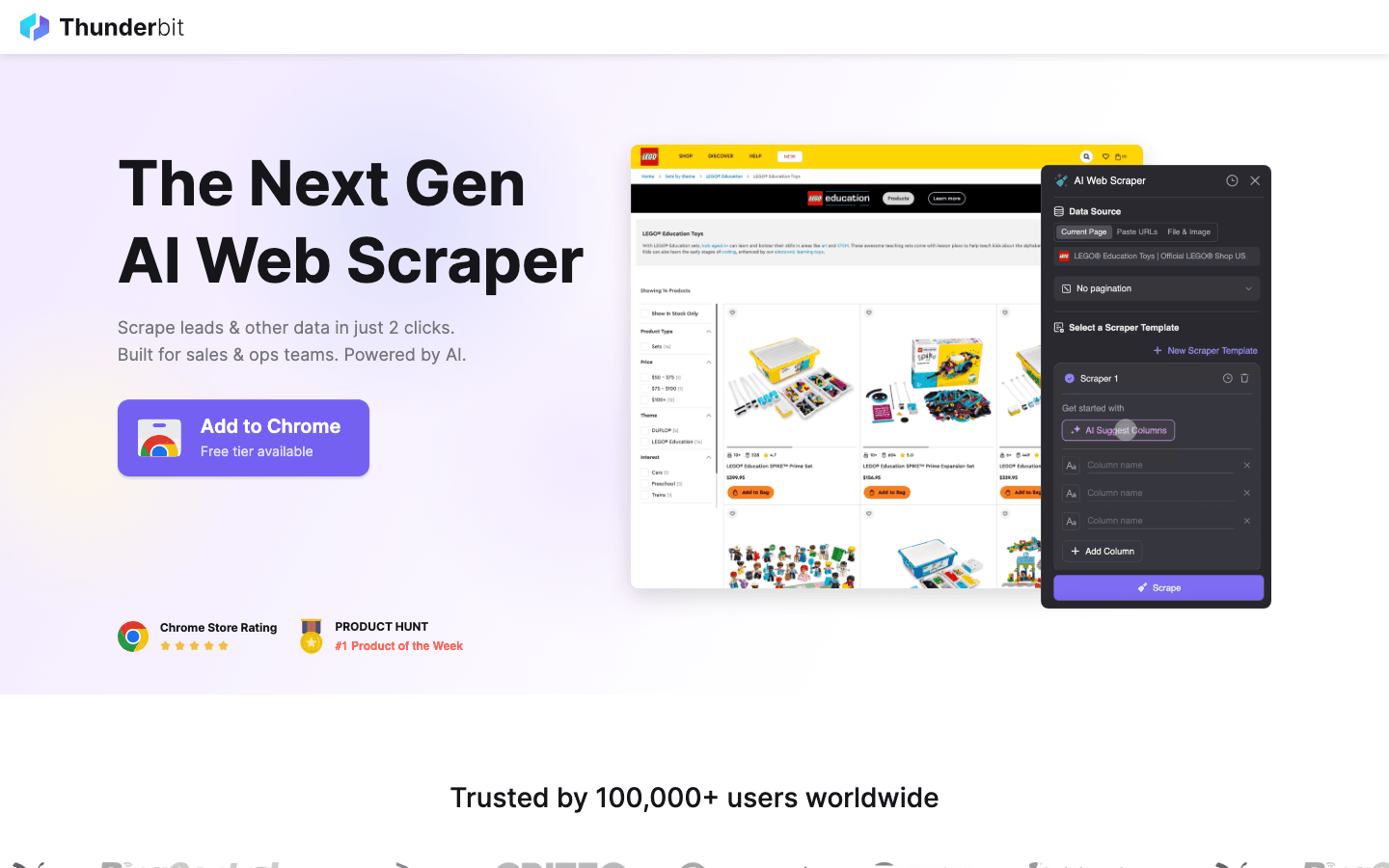 ist kein klassischer Proxy-Anbieter, sondern eine KI-gestützte 웹 스크래퍼-Chrome-Erweiterung, die Proxys im Hintergrund für dich steuert. Wer Webseiten im großen Stil auslesen will, ohne sich um Proxy-Listen zu kümmern, findet hier eine echte Erleichterung.
ist kein klassischer Proxy-Anbieter, sondern eine KI-gestützte 웹 스크래퍼-Chrome-Erweiterung, die Proxys im Hintergrund für dich steuert. Wer Webseiten im großen Stil auslesen will, ohne sich um Proxy-Listen zu kümmern, findet hier eine echte Erleichterung.
- All-in-One-Lösung: Thunderbit vereint KI-Web-Scraping und gemanagte Proxy-Rotation. Einfach Webseite öffnen, „AI Suggest Fields“ klicken und die KI erkennt, welche Daten extrahiert werden sollen. Dann auf „Scrape“ klicken – Proxys, Anti-Bot-Mechanismen und sogar CAPTCHA-Lösungen laufen automatisch im Hintergrund ().
- Subpage- & Pagination-Scraping: Details von Unterseiten oder endloses Scrollen? Thunderbit automatisiert das und erweitert deinen Datensatz mit wenigen Klicks.
- Cloud- & Browser-Modus: Nutze Thunderbits Cloud-IPs für Geschwindigkeit (bis zu 50 Seiten parallel) oder deinen eigenen Browser für eingeloggte Sessions.
- Compliance & Datenschutz: Thunderbit setzt auf Cloud-Server in den USA, der EU und Asien und positioniert sich als ethische, DSGVO-konforme Lösung – keine fragwürdigen IP-Quellen.
- Für wen geeignet? Vertriebs-, Marketing- und Operationsteams, die Webdaten ohne technischen Aufwand benötigen. Ideal für Lead-Generierung, Preisüberwachung und Content-Recherche.
- Preise: Kostenloses Kontingent (6–10 Seiten), danach kreditbasiert. Keine separaten Proxy-Gebühren – alles inklusive.
Thunderbit ist das einzige Tool auf dieser Liste, das sowohl 웹 스크래퍼 als auch Proxy-Lösung in einem ist – die perfekte All-in-One-Lösung für Business-Anwender.
2. Oxylabs
 ist der Goldstandard für Enterprise-Proxys. Wer Millionen von Seiten pro Tag scrapen, globale Preise überwachen oder groß angelegte Forschung betreiben will, ist hier richtig.
ist der Goldstandard für Enterprise-Proxys. Wer Millionen von Seiten pro Tag scrapen, globale Preise überwachen oder groß angelegte Forschung betreiben will, ist hier richtig.
- Riesiger Pool: Über 175 Mio. Residential-IPs, 2 Mio. Datacenter-IPs sowie ISP- und Mobile-Proxys in über 180 Ländern.
- Unbegrenzte Threads: Keine Begrenzung gleichzeitiger Verbindungen – auch bei Einsteiger-Tarifen.
- Fortschrittliche Tools: Web Unblocker und spezialisierte Scraper-APIs übernehmen CAPTCHAs und Anti-Bot-Maßnahmen.
- Compliance: Ethisch bezogene IPs, dedizierte Account-Manager und 24/7-Support.
- Preise: Ab ca. 300 $/Monat. Premium, aber für große, kritische Projekte lohnenswert.
Ideal für Unternehmen und Datenteams, die Skalierbarkeit, Zuverlässigkeit und Compliance brauchen.
3. Bright Data
 (ehemals Luminati) ist das Nonplusultra unter den Proxy-Anbietern – funktionsreich, riesiger IP-Pool und für Power-User gemacht.
(ehemals Luminati) ist das Nonplusultra unter den Proxy-Anbietern – funktionsreich, riesiger IP-Pool und für Power-User gemacht.
- Größtes Netzwerk: Über 72 Mio. Residential-IPs sowie Datacenter-, Mobile- und ISP-Proxys in 195+ Ländern.
- Feinste Zielgenauigkeit: Auswahl nach Land, Stadt, Postleitzahl und ASN.
- Proxy Manager & Web Unlocker: Fortgeschrittene Tools für Rotation, CAPTCHA-Lösung und Automatisierung.
- Compliance: Starker Fokus auf ethische Beschaffung und Business-Verifizierung.
- Preise: Ca. 4,20 $/GB (7 Tage kostenlos für qualifizierte Nutzer). Komplexe, aber flexible Tarife.
Ideal für Unternehmen und Forscher, die maximale Kontrolle und Features brauchen.
4. Smartproxy
 (jetzt Decodo) macht Premium-Proxys einfach und zugänglich.
(jetzt Decodo) macht Premium-Proxys einfach und zugänglich.
- Riesiger Pool: Über 115 Mio. Residential-IPs, Datacenter-, ISP- und Mobile-Proxys in 195+ Ländern.
- Benutzerfreundlich: Übersichtliches Dashboard, Chrome-Erweiterung und Multi-Login-Browser.
- KI-Parser: Extrahiere strukturierte Daten von jeder Website – ganz ohne Programmierkenntnisse.
- 24/7 Support: Schnelle Hilfe und starke Community.
- Preise: 75 $ für 5 GB (3 Tage Geld-zurück-Garantie). Top Preis-Leistung für KMU und Entwickler.
Perfekt für kleine und mittlere Unternehmen sowie alle, die ein gutes Preis-Leistungs-Verhältnis suchen.
5. Private Internet Access
 (PIA) ist vor allem als VPN bekannt, aber jedes Abo enthält auch einen SOCKS5-Proxy-Server.
(PIA) ist vor allem als VPN bekannt, aber jedes Abo enthält auch einen SOCKS5-Proxy-Server.
- Fokus auf Privatsphäre: Strikte No-Logs-Policy, gerichtlich und durch unabhängige Audits bestätigt.
- SOCKS5-Proxy: Schnell, einfach und im VPN-Abo enthalten – ideal zum Verschleiern der IP oder für Torrenting.
- Globales Netzwerk: Über 30.000 VPN-Server in 80+ Ländern.
- Preise: Ca. 2–3 $/Monat (VPN-Abo).
Ideal für Privatanwender, die VPN und Proxy in einem wollen. Für großflächiges Scraping weniger geeignet.
6. MyPrivateProxy
 ist ein erfahrener Anbieter für dedizierte Datacenter-Proxys.
ist ein erfahrener Anbieter für dedizierte Datacenter-Proxys.
- Schnell & stabil: Über 100.000 IPs in 24 US/EU-Rechenzentren, 1 Gbps-Server und unbegrenztes Datenvolumen.
- Spezialisierte Pakete: Für SEO, Social Media, Ticketing und Sneaker-Bots.
- Günstig: Ca. 2,49 $/IP pro Monat, Mengenrabatte möglich.
- Support: Reaktionsschnell und mit gutem Ruf.
Ideal für Social-Media-Manager, SEO-Profis und alle, die schnelle, stabile IPs brauchen.
7. IPRoyal
 steht für günstige und flexible Proxy-Lösungen.
steht für günstige und flexible Proxy-Lösungen.
- Pay-as-you-go: Residential-Proxys ab ca. 1,75 $/GB, ohne Ablaufdatum – einfach kaufen und flexibel nutzen.
- Proxy-Typen: Residential, Datacenter, Mobile und Sneaker-Proxys.
- Unbegrenzte Threads: Keine Begrenzung gleichzeitiger Verbindungen.
- Weltweite Abdeckung: 195+ Länder.
Ideal für Startups, Hobby-Projekte oder alle mit wechselndem oder kleinem Proxy-Bedarf.
8. Proxy-Seller
 bietet maßgeschneiderte Proxys für Social Media, Gaming und mehr.
bietet maßgeschneiderte Proxys für Social Media, Gaming und mehr.
- 220+ Standorte: IPv4/IPv6-Datacenter, Residential-, ISP- und Mobile-Proxys.
- Individuelle Pakete: Proxys für Instagram, Facebook, TikTok, Gaming usw. auswählbar.
- Flexible Laufzeiten: Miete für eine Woche oder ein Jahr, große Rabatte bei längerer Laufzeit.
- Günstig: Ab ca. 0,75 $/IP.
Perfekt für Social-Media-Manager, Gamer und alle, die spezialisierte Proxys zum kleinen Preis suchen.
9. ProxyEmpire
 bietet günstige, anpassbare Proxys mit globaler Reichweite.
bietet günstige, anpassbare Proxys mit globaler Reichweite.
- 9,5 Mio.+ IPs: Residential-, Mobile- und Datacenter-Proxys in 170+ Ländern.
- Datenübertragungs-Rollover: Nicht genutztes Datenvolumen wird in den nächsten Monat übernommen.
- Günstige Testphase: 1,97 $ Test, danach flexible Tarife.
- Keine versteckten Kosten: Transparente Preise und unbegrenzte gleichzeitige Sessions.
Ideal für Startups und Datenenthusiasten, die Flexibilität und weltweite Abdeckung suchen.
10. Blazing SEO Proxy (Rayobyte)
 (jetzt Rayobyte) steht für hohe Performance und flexible Skalierung.
(jetzt Rayobyte) steht für hohe Performance und flexible Skalierung.
- Alle Proxy-Typen: Residential, Datacenter, ISP und Mobile.
- Flexible Tarife: Ab 5 Proxys bis zu Tausenden skalierbar.
- Günstig: 15 $/GB für Residential, 2,50 $/IP für Datacenter.
- Ethische Beschaffung: Opt-in Residential-Peers.
Ideal für Marktforschung, Vertrieb und alle, die schnell skalieren wollen.
11. HighProxies
 ist besonders für Social Media und Kleinanzeigen beliebt.
ist besonders für Social Media und Kleinanzeigen beliebt.
- Dedizierte & Shared Proxys: Optimiert für Instagram, Facebook, Craigslist usw.
- 33 Standorte: 68.000 IPs in 11 Ländern, mit Stadt-Auswahl.
- Unbegrenztes Datenvolumen: Bis zu 100 Threads pro Proxy.
- Günstig: 1,40 $/IP (privat), 2,60 $ für spezialisierte Proxys.
Ideal für Social-Media-Manager, Kleinanzeigen-Poster und alle, die stabile Datacenter-IPs brauchen.
12. Shifter
 punktet mit unbegrenztem Datenvolumen bei Residential-Proxys.
punktet mit unbegrenztem Datenvolumen bei Residential-Proxys.
- 31 Mio.+ IPs: Riesiges Peer-to-Peer-Netzwerk.
- Unbegrenzte Daten: Abrechnung pro Port, nicht pro GB – ideal für massives Scraping.
- Geo-Targeting: In „Special“-Tarifen verfügbar.
- Preise: 299,99 $ für 25 Ports (unbegrenzte Daten).
Ideal für datenintensives Scraping, Streaming oder alle, bei denen Bandbreite zählt.
13. Geonode
 ist die günstige Wahl für Startups und kleine Teams.
ist die günstige Wahl für Startups und kleine Teams.
- Pauschalpreis: 50 $/Monat für 100 GB (0,50 $/GB).
- 30 Mio.+ IPs: Rotierende Residential-Proxys in 190+ Ländern.
- Unbegrenzte Verbindungen: Keine Zusatzkosten für Targeting oder Sticky Sessions.
- Einfache Tarife: Ein Tarif für alle, mit Datenübertragungs-Rollover.
Ideal für Startups, Forscher oder alle, die einfache und günstige Proxys suchen.
14. NetNut
 ist für große, datenintensive Projekte gemacht.
ist für große, datenintensive Projekte gemacht.
- Direkte ISP-Verbindungen: Statische Residential-Proxys direkt von ISPs, nicht von Endgeräten.
- 20 Mio.+ Residential-, 5 Mio.+ Mobile-IPs: Schnell, stabil und zuverlässig.
- Enterprise-Qualität: Unbegrenzte gleichzeitige Verbindungen, 24/7-Support und hohe Compliance.
- Preise: Ab ca. 300 $/Monat.
Ideal für Unternehmen, Echtzeit-Datenüberwachung und alle, die Geschwindigkeit und Zuverlässigkeit im großen Stil brauchen.
15. ProxyRack
 steht für Vielseitigkeit und breite Protokoll-Unterstützung.
steht für Vielseitigkeit und breite Protokoll-Unterstützung.
- Verschiedene Proxy-Typen: Rotierende Residential-, Datacenter- und Mobile-Proxys.
- Unbegrenzte Tarife: Viele Tarife mit unbegrenztem Datenvolumen.
- Protokoll-Unterstützung: HTTP, HTTPS, SOCKS5 und sogar UDP.
- Günstig: 49,95 $/Monat für unbegrenzten Einstiegstarif oder ca. 2 $/GB Pay-as-you-go.
Ideal für Entwickler, QA-Tester und alle, die maximale Kompatibilität und flexible Integration brauchen.
Vergleichstabelle: Die besten kostenpflichtigen Proxys im Überblick
| Anbieter | Proxy-Typen | Netzwerkgröße / Geo | Preise (ab) | Ideal für |
|---|---|---|---|---|
| Thunderbit | KI-Web-Scraper + Proxys | Cloud (US/EU/Asien) | Kostenlos, dann kreditbasiert | No-Code-Scraping, Vertriebs-/Marketingteams |
| Oxylabs | Res, DC, Mobile, ISP | 175M+ IPs, 180+ Länder | ca. 300 $/Monat | Enterprise-Scraping, Compliance |
| Bright Data | Res, DC, Mobile, ISP | 72M+ IPs, 195+ Länder | ca. 4,20 $/GB | Business Intelligence, gezieltes Targeting |
| Smartproxy | Res, DC, Mobile, ISP | 115M+ IPs, 195+ Länder | 75 $/5GB | KMU, Entwickler, einfache Bedienung |
| PIA | SOCKS5 Proxy + VPN | 30k+ Server, 80+ Länder | ca. 2–3 $/Monat | Privatsphäre, leichter Proxy-Einsatz |
| MyPrivateProxy | Datacenter (Privat/Shared) | 100k+ IPs, US/EU | ca. 2,49 $/IP | Social Media, SEO, Sneaker-Bots |
| IPRoyal | Res, DC, Mobile, Sneaker | Millionen, 195+ Länder | ca. 1,75 $/GB | Budget, Pay-as-you-go, kleine Projekte |
| Proxy-Seller | Res, ISP, DC, Mobile | 40M+ IPs, 220+ Länder | ca. 0,75 $/IP, 7 $/GB | Social Media, Gaming, flexible Tarife |
| ProxyEmpire | Res, Mobile, DC | 9,5M+ IPs, 170+ Länder | 1,97 $ Test, 49 $/3GB | Startups, globale Reichweite, Rollover-Daten |
| Blazing SEO | Res, DC, Mobile, ISP | 100k+ IPs, 100+ Länder | 15 $/GB, 2,50 $/IP | Marktforschung, flexible Skalierung |
| HighProxies | Datacenter (Privat/Shared) | 68k IPs, 11 Länder | 1,40 $/IP | Social/Kleinanzeigen, stabile DC-IPs |
| Shifter | Rotierende Residential, DC | 31M+ IPs, global | 299,99 $/25 Ports | Unbegrenzte Bandbreite, massives Scraping |
| Geonode | Rotierende Residential | 30M+ IPs, 190+ Länder | 50 $/100GB | Startups, einfache Pauschalpreise |
| NetNut | Rotierende Res, statische ISP | 20M+ Res, 5M+ Mobile | ca. 300 $/Monat | Enterprise, Geschwindigkeit, statische Res |
| ProxyRack | Rotierende Res, Mobile, DC | 5M+ IPs, 140+ Länder | 49,95 $/Monat, 2 $/GB | Vielseitig, Entwickler, Protokoll-Support |
Wie wähle ich den besten kostenpflichtigen Proxy für meine Anforderungen?
Hier meine Schnellübersicht für die richtige Proxy-Wahl:
- Web Scraping auf schwierigen Seiten: Oxylabs, Bright Data oder NetNut für robuste Residential/Mobile-Proxys und hohe Erfolgsraten.
- Social Media Management: HighProxies, MyPrivateProxy oder Proxy-Seller für stabile, dedizierte IPs und gezieltes Targeting.
- Marktforschung & Vertrieb: Blazing SEO, ProxyEmpire oder Smartproxy für günstige, flexible Tarife und guten Support.
- Budget- oder Einzelprojekte: IPRoyal oder Geonode für Pay-as-you-go oder Pauschalpreise.
- No-Code-Automatisierung: Thunderbit, wenn du Scraping und Proxys in einem Tool ohne Setup willst.
- Persönliche Privatsphäre: PIA für VPN + Proxy mit strikter No-Logs-Policy.
- Große Datenmengen: Shifter oder ProxyRack für unbegrenzte Bandbreite und unlimitierte Tarife.
- Globale/Geo-Targeting-Anforderungen: Bright Data, Proxy-Seller oder ProxyEmpire für die größte Standortauswahl.
Tipp: Starte immer mit einer kostenlosen Testphase oder einem günstigen Tarif. Teste deinen Anwendungsfall – jedes Proxy-Netzwerk verhält sich je nach Zielseite anders.
Fazit: So findest du deinen idealen Proxy
Die Proxy-Welt war nie vielfältiger – und nie wichtiger. Egal, ob du Millionen von Seiten scrapen, Dutzende Social-Accounts verwalten oder einfach sicher surfen willst: In dieser Liste findest du garantiert den passenden kostenpflichtigen Proxy. Entscheidend ist, das richtige Tool für deinen Workflow, deine Skalierung und deine Compliance-Anforderungen zu wählen.
Scheue dich nicht, verschiedene Anbieter zu kombinieren – viele Profis nutzen mehrere Services parallel und setzen sie je nach Stärken ein. Das Beste: Die meisten bieten kostenlose Testphasen oder Geld-zurück-Garantie, sodass du risikofrei ausprobieren kannst, was am besten passt.
Viel Erfolg bei der Proxy-Suche – auf schnelle Verbindungen, sichere Daten und immer freie IPs!
FAQs
1. Warum sollte ich einen kostenpflichtigen Proxy statt eines kostenlosen nutzen?
Kostenpflichtige Proxys bieten höhere Geschwindigkeit, mehr Zuverlässigkeit, besseren Datenschutz und echten Support. Kostenlose Proxys sind oft langsam, instabil und verkaufen oder speichern deine Daten ().
2. Was ist der Unterschied zwischen Residential-, Datacenter- und Mobile-Proxys?
Residential-Proxys nutzen IPs echter Geräte und sind schwerer zu blockieren. Datacenter-Proxys sind schneller und günstiger, werden aber leichter erkannt. Mobile-Proxys laufen über Mobilfunknetze, bieten höchste Vertrauenswürdigkeit, sind aber teurer.
3. Welcher Proxy ist am besten für Web Scraping?
Für schwierige Ziele: Oxylabs, Bright Data oder NetNut mit Residential/Mobile-Proxys. Für No-Code-Scraping mit integrierten Proxys ist eine einzigartige All-in-One-Lösung.
4. Wie bleibe ich beim Proxy-Einsatz compliant und schütze meine Privatsphäre?
Wähle seriöse Anbieter mit ethischer IP-Beschaffung und klaren Datenschutzrichtlinien. Meide Scraping auf Seiten, die es verbieten, und halte dich immer an lokale Gesetze und Nutzungsbedingungen.
5. Kann ich mehrere Proxy-Anbieter gleichzeitig nutzen?
Absolut! Viele Nutzer kombinieren verschiedene Anbieter – z. B. einen fürs Scraping, einen für Social Media und einen als Backup oder für Budget-Projekte.
Mehr Infos? Schau im vorbei – dort findest du weitere Guides, Tipps und ausführliche Reviews der besten Proxy-Tools 2025.
Mehr erfahren