YouTube hat über und . Gleichzeitig gehört die Plattform zu den schwierigsten, wenn es ums Scrapen geht, ohne in einer Wand aus CAPTCHAs, 429-Fehlern oder direkten IP-Sperren zu landen.
Wenn du schon einmal versucht hast, Kanaldaten, Kommentare oder Transkripte in größerem Umfang abzurufen, kennst du die Frustration bereits. Erst kommen ein paar hundert Ergebnisse, dann macht YouTube dicht. Ich habe viel Zeit damit verbracht zu prüfen, wie verschiedene Scraping-Ansätze gegen YouTubes sich ständig weiterentwickelnde Anti-Bot-Abwehr bestehen, und der Unterschied zwischen Tools, die zuverlässig funktionieren, und Tools, die dich innerhalb von Minuten blockieren, ist enorm.
Dieser Leitfaden stellt die 6 besten YouTube-Scraper für 2026 vor – Tools, die tatsächlich dafür gebaut sind, mit YouTubes Abwehrmaßnahmen zurechtzukommen, ohne deine IP oder deinen Workflow zu ruinieren. Egal, ob du als Marketer konkurrierende Kanäle beobachtest, als Vertriebsteam Creator-Kontakte recherchierst oder als Entwickler eine Datenpipeline aufbaust: Hier ist eine passende Option dabei.
Was YouTube 2026 tatsächlich blockiert (und warum die meisten Scraper scheitern)
YouTubes Anti-Bot-Abwehr ist keine einzelne Mauer, sondern ein mehrschichtiges System. Zu verstehen, womit du es zu tun hast, ist der erste Schritt, um nicht blockiert zu werden.
Das tut YouTube 2026, um automatisierten Zugriff zu erkennen und zu unterbinden:

- IP-Reputation und Geschwindigkeitsprüfungen: Wiederholte Anfragen von Rechenzentrums-IPs, VPNs oder geteilten Proxys werden schnell markiert. Du siehst dann 403-Fehler, 429-Rate-Limits oder Bildschirme mit „Anmelden, um zu bestätigen, dass du kein Bot bist“.
- Browser- und JavaScript-Fingerprinting: YouTube prüft, ob sich der Client wie ein echter Browser verhält – also Skripte ausführt, Elemente rendert und den erwarteten Status beibehält. Headless-Browser und rohe HTTP-Clients scheitern an diesen Prüfungen oft stillschweigend; du bekommst dann einfach leere oder unvollständige Daten.
- Vertrauen in Cookies und Sessions: Wenn deine Anfragen nicht aus einer erkannten, länger bestehenden Browser-Session kommen, erhöht YouTube die Verifikationsstufe. Eingeloggte Sessions mit Browserverlauf genießen mehr Vertrauen als frische, anonyme Sitzungen.
- Verhaltensanalyse: Gleichmäßige Anfrageintervalle, zu schnelles Scrollen oder wiederholte Seitenmuster lösen Drosselung aus. YouTube achtet auf Navigation, die kein Mensch so ausführen würde.
- CAPTCHA-Sperren: Wenn das Risiko hoch ist, erzwingt YouTube eine menschliche Verifizierung – besonders bei Suchergebnissen und Kommentarbereichen.
- API-Quota-Durchsetzung: Die offizielle YouTube Data API setzt tägliche Kontingente auf Projektebene durch (standardmäßig 10.000 Einheiten/Tag), und suchlastige Workflows verbrauchen diese in Minuten.
Die typische Nutzererfahrung: Du startest das Scraping, bekommst ein paar hundert Ergebnisse und stößt dann auf Error 429, eine CAPTCHA-Wand oder stillschweigend schlechtere Daten. Cloud-basierte Scraper, die von Rechenzentrums-IPs laufen, sind besonders anfällig.
| Erkennungsmethode | Was sie macht | Typisches Symptom | Tools, die das Risiko senken |
|---|---|---|---|
| IP-Reputation/Geschwindigkeit | Markiert Rechenzentrums-, VPN- und geteilte IPs | 403, 429, Bot-Bestätigung | Scraping in Browser-Sessions, Residential Proxies |
| JS-Fingerprinting | Prüft echte Browser-Ausführung | Still fehlende Daten, CAPTCHA | Echte Browser-Erweiterung, vollständiges Rendering |
| Cookie-/Session-Vertrauen | Vergleicht mit eingeloggten Profilen | „Anmelden, um zu bestätigen“ | Nutzer-Cookies, authentifizierte Session |
| Verhaltensanalyse | Erkennt nicht-menschliche Muster | Drosselung nach ca. 200 Zeilen | Menschliche Verzögerungen, Randomisierung, kleine Batches |
| API-Quota-Durchsetzung | Begrenzt tägliche API-Einheiten | 403 quotaExceeded | Scraper für Suche/Kommentare, API für gezielte Abfragen |
| CAPTCHA-Sperren | Erzwingt menschliche Verifizierung | Extraktion stoppt mitten im Lauf | Browser-Session, Proxy/Unblocker, langsamere Taktung |
Die Quintessenz: Tools, die in einer echten Browser-Session arbeiten, wie Thunderbit, umgehen viele dieser Prüfungen ganz natürlich, weil die Anfrage für YouTube genauso aussieht wie normales Browsen durch einen Menschen. Cloud-only-Scraper brauchen Proxy-Rotation, CAPTCHA-Lösungen und sorgfältige Taktung, um zu überleben.
YouTube API vs. beste YouTube-Scraper: Ein praktischer Entscheidungsrahmen
Die YouTube Data API v3 ist der „offizielle“ Weg, um programmatisch auf YouTube-Daten zuzugreifen. Für einfache Metadaten bei niedrigem Volumen ist sie zuverlässig – aber ihr Quota-Modell macht sie für die meisten realen Workflows im Bereich Competitive Intelligence und Recherche unpraktisch.
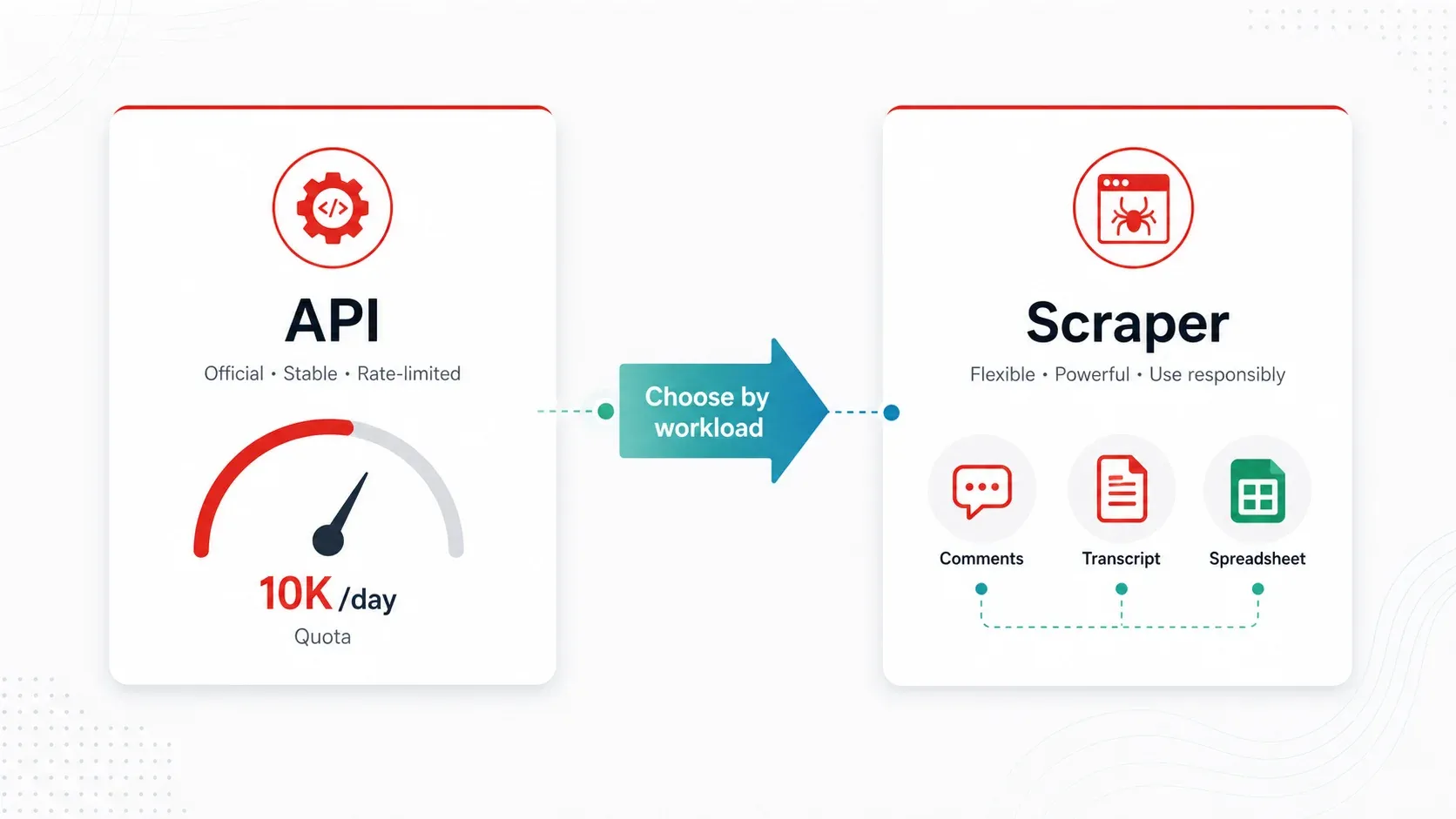
Hier die Rechnung. Jedes API-Projekt erhält . Wichtige Endpunktkosten:
search.list= 100 Einheiten pro Seite (maximal 50 Ergebnisse pro Seite)videos.list= 1 Einheit pro Aufruf (bis zu 50 Video-IDs pro Aufruf)commentThreads.list= 1 Einheit pro Aufruf (bis zu 100 Threads pro Aufruf)
Wenn du also täglich 100 Keyword-Suchen ausführst, ist dein gesamtes Tageskontingent bereits verbraucht, bevor du auch nur ein einziges Video angereichert hast. Ein kommentarlastiger Workflow ist pro Aufruf günstiger, aber echte Paginierung, deaktivierte Kommentare und das Aufklappen von Antworten fressen die Kapazität schnell auf.
Wann die API ausreicht:
- Du brauchst weniger als 100 Videos/Tag und nur öffentliche Metadaten (Titel, Aufrufe, Likes, Dauer)
- Ein Entwickler kann OAuth einrichten und das Quota verwalten
Wann ein Scraper besser ist:
- Du brauchst Kommentare in großem Umfang (die API funktioniert, aber das Quota ist ein echter Reibungspunkt)
- Du brauchst Transkripte/Untertitel als Text (die API stellt Untertiteltext für Massennutzung nicht einfach bereit)
- Du beobachtest regelmäßig mehr als 100 Kanäle (Quota wird schnell knapp, Planung ist manuell)
- Du brauchst angereicherte oder gelabelte Daten (Kategorisierung, Übersetzung oder KI-gestützte Felderkennung)
- Du bist kein technischer Nutzer und willst einfach eine Tabelle
Die API zeigt außerdem nicht alles, was du auf der Website sehen würdest: Shorts-Shelf-Daten, öffentliche E-Mails aus Kanalbeschreibungen, Community-Beiträge und einige Kanalmetadaten sind nur über das Scrapen der eigentlichen YouTube-Seiten zugänglich.
Für die meisten Business-Nutzer, die Wettbewerbsanalysen, Creator-Recherche oder Content-Strategie betreiben, ist ein Scraper-Tool praktischer als die API.
Wie wir die 6 besten YouTube-Scraper ausgewählt haben
Jedes Tool auf dieser Liste wurde anhand derselben Kriterien bewertet – mit Schwerpunkt auf dem, was wirklich zählt, wenn YouTube aktiv versucht, dich zu blockieren:
| Kriterium | Warum es wichtig ist |
|---|---|
| Zuverlässigkeit gegen Sperren | Das größte Problem der Nutzer – Rate-Limits und IP-Sperren in großem Maßstab |
| Kosten pro 1.000 Ergebnisse | Einheitliche Preise machen den Vergleich für budgetbewusste Nutzer fair |
| Unterstützte Datentypen | Metadaten, Kommentare, Transkripte, Shorts, Thumbnails – je nach Tool stark unterschiedlich |
| Skalierbarkeit | Schafft es 100+ Kanäle oder 10.000+ Videos ohne Absturz? |
| Einrichtungsaufwand | Erstnutzer brauchen praktische, no-code-freundliche Optionen |
| Exportformate | CSV, JSON, Google Sheets, Airtable – verschiedene Workflows brauchen verschiedene Ausgaben |
| Wartungsaufwand | YouTube-Änderungen brechen Tools; wer behebt das? |
Alle Tools wurden anhand der aktuellen YouTube-Blockmuster bewertet, denen Nutzer 2026 begegnen.
1. Thunderbit
ist eine KI-gestützte Chrome-Erweiterung, die YouTube-Seiten in etwa zwei Klicks in strukturierte Daten verwandelt. Statt über einen Cloud-Server zu laufen, den YouTube leicht markiert, arbeitet Thunderbit in deiner eigenen Browser-Session – für YouTube sieht es also so aus, als würdest du ganz normal browsen.
Der Kernablauf für YouTube: Installiere die , öffne eine YouTube-Kanal-, Suchergebnis- oder Videoseite und klicke auf „AI Suggest Fields“. Die KI liest die Seite und schlägt Spalten vor – Videotitel, URL, Aufrufe, Upload-Datum, Beschreibung, Thumbnail-URL, Kommentartext, Autor, Likes und mehr. Du prüfst die Vorschläge, klickst auf „Scrape“ und exportierst direkt nach Google Sheets, Excel, Airtable, Notion, CSV oder JSON. Kein Code, keine Selektoren, keine API-Keys.
Wichtige Funktionen für YouTube-Scraping:
- KI-Felderkennung: Thunderbits KI liest jede YouTube-Seite, auf der du dich befindest, und schlägt automatisch relevante Spalten vor. Du musst CSS-Selektoren oder XPaths nicht manuell zuordnen.
- Subpage-Scraping: Scrape die Videoliste eines Kanals und klicke dann in jede Videoseite hinein, um Kommentare, Beschreibungen, Tags und Transkripte anzureichern, sofern sichtbar.
- Geplantes Scraping: Richte wiederkehrende Jobs ein, um Kanäle wöchentlich ohne manuelle Eingriffe zu überwachen.
- Browser-Modus: Läuft in deiner authentifizierten Browser-Session und reduziert das „Cloud-Rechenzentrums-IP“-Fingerprinting, das die meisten YouTube-Sperren auslöst.
- Kostenloser Export: Daten gehen an Google Sheets, Excel, Airtable oder Notion, ohne dass der Export hinter einer Paywall verschwindet.
Anti-Ban-Ansatz: Browserbasiertes Session-Scraping mit der authentifizierten Session des Nutzers. YouTube sieht einen echten Browser, echte Cookies, echten Sitzungsverlauf. Bei Jobs mit hohem Volumen senken kleinere, geplante Batches das Risiko zusätzlich.
Preis: Kostenloser Tarif (6 Seiten), Trial-Boost (10 Seiten). Bezahlte Pläne sind kreditbasiert. Aktuelle Zahlen findest du auf der .
Am besten geeignet für: Marketer, Vertriebsteams, Content-Strategen und Operations-Nutzer, die schnell Kanäle, Suchergebnisse und Kommentare recherchieren wollen, ohne technische Einrichtung.
So scrape ich YouTube mit Thunderbit (Schritt für Schritt)
- Installiere die .
- Navigiere zu einer YouTube-Kanalseite, zu Suchergebnissen, einer Playlist oder einer Videoseite.
- Klicke auf „AI Suggest Fields“ – die KI liest die Seite und schlägt Spalten vor (Titel, URL, Aufrufe, Datum, Beschreibung, Thumbnail usw.).
- Prüfe und passe die vorgeschlagenen Felder bei Bedarf an.
- Klicke auf „Scrape“ – die Daten werden in eine strukturierte Tabelle extrahiert.
- Exportiere nach Google Sheets, Excel, Airtable, Notion, CSV oder JSON.
Für tiefere Extraktion (z. B. das Ziehen von Kommentaren aus jedem Video eines Kanals) nutze Subpage-Scraping: Zuerst die Videoliste scrapen, dann Thunderbit jede Videoseite besuchen lassen und Kommentar-Daten, Beschreibungen oder die Verfügbarkeit von Transkripten extrahieren.
Der gesamte Prozess dauert bei einer typischen Kanalrecherche weniger als zwei Minuten. Keine API-Keys, kein Proxy-Setup, kein Code.
2. Apify
Apify ist eine cloudbasierte Scraping-Plattform mit vorgefertigten YouTube-„Actors“ – spezialisierten Scrapern für Videos, Kommentare, Kanäle, Shorts und Transkripte. Sie ist für Entwickler gedacht, die automatisierte Datenpipelines aufbauen wollen statt einmalige Recherchen durchzuführen.
Apifys YouTube-Ökosystem umfasst separate Actors für unterschiedliche Aufgaben. Ein gut gepflegter Actor mit dem Titel „YouTube Scraper — Videos, Comments & Transcripts“ akzeptiert Kanäle, Playlists, Suchanfragen und direkte Video-URLs. Er unterstützt Shorts-Filterung, Kommentar-Scraping und Transkripte mit Zeitstempeln.
Wichtige Funktionen:
- Separate Actors für Videos, Kommentare, Kanäle, Shorts und Transkripte
- Akzeptiert Suchbegriffe, Kanal-URLs und Playlist-IDs als Eingabe
- Cloud-Scheduling und Webhook-Integrationen
- Export nach JSON, CSV, Excel oder Push in Datenbanken per API
- Rate-Steuerung und Proxy-Rotation auf Actor-Ebene
Anti-Ban-Ansatz: Actor-spezifische Taktung, Apifys Proxy-Infrastruktur und – wo anwendbar – Zugriff auf YouTubes interne API (Innertube). Jeder Actor implementiert seine eigene Retry- und Rate-Limit-Logik.
Preis: Der genannte YouTube-Scraper-Actor listet ungefähr 15 $ pro 1.000 Videos, 8 $ pro 1.000 Kommentare und 5 $ pro Transkript. Plattformpläne starten bei 49 $/Monat.
Nachteile: Die Nutzungskosten steigen bei großen Jobs schnell. Die Oberfläche ist entwicklerorientiert – nicht-technische Nutzer finden sie möglicherweise komplex. Die Ausgabeschemata unterscheiden sich zwischen den Actors, daher ist oft Datenbereinigung nötig. Die Qualität der Actors variiert je nach Marketplace.
Am besten geeignet für: Entwickler, die automatisierte Datenpipelines bauen, Teams, die geplante Extraktion in APIs oder Datenbanken benötigen, und Marketing-Ops-Teams mit wiederkehrenden Workflows zur Kommentar-Analyse.
3. Bright Data
Bright Data ist eine Enterprise-Dateninfrastruktur-Plattform mit dem größten Residential-Proxy-Netzwerk der Branche und dedizierten YouTube-Scrapern. Wenn du YouTube in massivem Umfang über viele Regionen hinweg scrapen musst, ist das die schwere Artillerie.
Bright Data bietet mehrere YouTube-Scraper (Kanalprofile, Videos, Kommentare) sowie fertige YouTube-Datensätze zum Kauf. Der verwaltete Scraping-Service bedeutet, dass sie den Scraper für dich bauen und pflegen.
Wichtige Funktionen:
- Über 150 Mio. Residential IPs in 195 Ländern
- YouTube-spezifische Scraper für Kanäle, Videos und Kommentare
- Vollständiges Browser-Rendering und CAPTCHA-Lösung
- Geo-Targeted Scraping (YouTube-Ergebnisse zwischen Ländern vergleichen)
- Verwalteter Service möglich (Wartung wird übernommen)
- Batch-Verarbeitung von bis zu 5.000 URLs pro Anfrage
Anti-Ban-Ansatz: Riesiger Pool an Residential Proxies, automatisierte IP-Rotation, Emulation von Browser-Fingerprints und integrierte CAPTCHA-Lösung. Das ist die stärkste Anti-Block-Infrastruktur in dieser Liste.
Preis: Kostenloser Test (1.000 Requests für eine Woche), Pay-as-you-go ab 3,50 $ pro 1.000 Datensätze, Scale-Tarif ab 499 $/Monat mit 384.000 enthaltenen Datensätzen und 2,30 $ pro weitere 1.000.
Nachteile: Für kleine Projekte überdimensioniert. Die Preisstruktur ist komplex (Bandbreite + Requests + IPs können zu „bill shock“ führen, wenn Limits nicht gesetzt werden). Die Plattform erfordert mehr Einrichtung als eine Chrome-Erweiterung.
Am besten geeignet für: Große Unternehmen, Agenturen, die Hunderte Kanäle überwachen, und Teams, die YouTube-Daten mit geografischem Bezug im Enterprise-Maßstab brauchen.
4. Octoparse
Octoparse ist ein Desktop- und Cloud-Scraping-Tool mit einer visuellen Point-and-Click-Oberfläche. Du baust YouTube-Extraktions-Workflows, indem du Elemente auf der Seite anklickst – kein Code nötig, aber mit mehr Anpassungsmöglichkeiten als eine einfache Erweiterung.
Octoparse hat vorgefertigte YouTube-Vorlagen, darunter einen YouTube Comments & Replies Scraper, der im April 2026 aktualisiert wurde. Er extrahiert Nutzernamen, Kommentartext, Likes, Veröffentlichungszeit und Antwort-Threads aus Video-URLs.
Wichtige Funktionen:
- No-Code visueller Workflow-Builder – Elemente anklicken, um die Scraping-Logik zu definieren
- Vorgefertigte YouTube-Vorlagen für Kommentare, Suchergebnisse und Videometadaten
- Cloud-Scheduling mit automatischer Proxy-Rotation
- Export nach Excel, CSV, JSON und Datenbankverbindungen
- Integrierte IP-Rotation und Anti-Detection in Cloud-Tarifen
Anti-Ban-Ansatz: Cloud-Ausführung mit integrierter IP-Rotation und Anti-Detection-Maßnahmen. Vorlagen behandeln endloses Scrollen und dynamisches Laden auf gängigen YouTube-Seiten.
Preis: Die YouTube-Kommentarvorlage ist mit 0,20 $ pro 1.000 Zeilen angegeben. Plattformpläne starten bei rund 75 $/Monat (Standard, jährlich abgerechnet) mit Cloud-Servern, Scheduling und Proxy-Optionen.
Nachteile: Komplexe YouTube-Seiten (endloses Scrollen, lazy geladene Kommentare, Shorts-Tabs) können Anpassungen bei Wartezeiten und Scroll-Verhalten erfordern. Die Extraktion von Transkripten/Untertiteln ist im Vergleich zu yt-dlp oder spezialisierten Transcript-Actors eingeschränkt. Lernkurve bei fortgeschrittenen Workflows.
Am besten geeignet für: Marketing-Analysten und Business-Researcher, die visuelle Workflow-Tools bevorzugen, aber mehr Anpassung als eine Chrome-Erweiterung brauchen.
5. YT-DLP
YT-DLP (auf GitHub verfügbar) ist ein Open-Source-Kommandozeilen-Tool, das Videometadaten, Untertitel, Transkripte und mehr von YouTube (und über 1.000 weiteren Websites) extrahiert. Es ist das Schweizer Taschenmesser für technische Nutzer, die maximale Kontrolle und null Abo-Kosten wollen.
Für Scraping-ähnliche Aufgaben kann yt-dlp Metadaten extrahieren, ohne Videodateien herunterzuladen, mit Flags wie --skip-download, --write-info-json, --dump-json und --flat-playlist. Es unterscheidet zwischen automatisch generierten und manuell geschriebenen Untertiteln – ein Unterschied, den die meisten anderen Tools übersehen.
Wichtige Funktionen:
- Extrahiert Videometadaten (Titel, Aufrufe, Likes, Upload-Datum, Beschreibung, Tags), ohne das Video herunterzuladen
- Lädt komplette Playlists und Kanäle in großen Mengen herunter
- Zugriff auf Untertitel/Transkripte (automatisch UND manuell, getrennt voneinander)
- Batch-Verarbeitung mit eigenen Ausgabevorlagen
- Cookie-/Authentifizierungs-Support für sitzungsbasierten Zugriff
- Komplett kostenlos, aktive Open-Source-Community
Anti-Ban-Ansatz: Nutzer-Cookies zur Authentifizierung (--cookies-from-browser), konfigurierbare Drosselungs-Einstellungen und von der Community gepflegte Extraktor-Updates, die sich an YouTube-Änderungen anpassen.
Preis: Kostenlos.
Nachteile: Erfordert Kompetenz in der Kommandozeile. Keine visuelle Oberfläche. Bricht bei YouTube-Änderungen gelegentlich – die Community behebt das zwar schnell, aber du musst trotzdem aktualisieren und Fehler beheben. Kein integriertes Scheduling oder Export in Tabellen – du baust deine eigene Pipeline.
Am besten geeignet für: Entwickler, Datenwissenschaftler und technische Teams, die maximale Kontrolle über Metadaten- und Transkript-Extraktion brauchen und mit Terminal-Befehlen kein Problem haben.
6. Phantombuster
Phantombuster ist eine Cloud-Automatisierungsplattform mit YouTube-spezifischen „Phantoms“, die eher für Growth Marketing und Lead-Generierung als für reines Data Warehousing gedacht sind. Sie ist die richtige Wahl, wenn dein Ziel ist, Creator-Kontakte zu finden und Outreach-Listen aufzubauen.
Phantombusters YouTube Channel Video Extractor zieht Kanalinfos, Videolisten und öffentliche E-Mails aus Kanalbeschreibungen. Die offizielle Rate-Limit-Dokumentation sagt, dass der YouTube Channel Video Extractor bis zu 100 Videos pro Lauf unterstützt und warnt, dass ungewöhnliche Aktivitäten dennoch YouTube-Beschränkungen auslösen können.
Wichtige Funktionen:
- YouTube-Kanal-Scraper (Abonnentenzahl, Videoliste, Kanalinfos, öffentliche E-Mails)
- Video- und Kommentar-Extraktion für Wettbewerbsanalysen
- Integration mit CRM- und Outreach-Tools
- Scheduling und Workflow-Automatisierung
- 14-tägige kostenlose Testphase, Start-Tarif ab 56 $/Monat (jährlich abgerechnet, 20 Std./Monat Ausführungszeit)
Anti-Ban-Ansatz: Integrierte Verzögerungen zwischen Aktionen, Phantom-Browser-Sessions, Cloud-Ausführung mit getakteter Automatisierung. Für sichere, langsame Workflows statt schnelle Massenextraktion entwickelt.
Preis: Start-Tarif bei 56 $/Monat (jährlich), Grow bei 128 $/Monat, Scale bei 352 $/Monat. Die Kosten pro 1.000 Ergebnisse hängen von der Ausführungszeit ab, nicht von einem sauberen Preis pro Datensatz.
Nachteile: Langsamer als Pipeline-orientierte Tools. Die Preisgestaltung basiert auf Ausführungsstunden und Credits, nicht auf einem klaren Preis pro Zeile. Eingeschränkte Unterstützung für Transkripte/Untertitel. Das Limit von 100 Videos pro Lauf bedeutet, dass große Kanäle mehrere Durchläufe brauchen.
Am besten geeignet für: Growth-Marketer, die Influencer-Recherche betreiben, Vertriebsteams, die Creator-Kontaktdaten extrahieren, und Agenturen, die die YouTube-Aktivität von Wettbewerbern beobachten.
Alle Datentypen, die du aus YouTube extrahieren kannst (Matrix nach Tool)
Verschiedene Tools unterstützen unterschiedliche YouTube-Datentypen. Bevor du dich für ein Tool entscheidest, solltest du genau wissen, was du bekommst. Hier ist die Aufschlüsselung:
| Datentyp | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Videometadaten (Titel, Aufrufe, Likes, Dauer, Datum) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Kommentare (Massenextraktion mit Autor, Zeitstempel, Likes) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Kommentar-Antworten | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Transkripte/Untertitel | ⚠️ (seitenabhängig) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Automatische vs. manuelle Untertitel (unterschieden) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Shorts-Metriken | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Kanal-Analysen (Abonnenten, Gesamtaufrufe, Beitrittsdatum) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Thumbnails/Bilder | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Öffentliche E-Mails aus Kanalbeschreibungen | ✅ (wenn sichtbar) | vom Actor abhängig | ⚠️ | ⚠️ | ❌ | ✅ |
Die wertvollsten Daten je nach Business-Use-Case:
- Kommentare → Sentiment-Analyse, Einwand-Mining, Beschwerden über Wettbewerber, Zielgruppenforschung
- Transkripte → LLM-/RAG-Pipelines, Analyse der Wettbewerbsbotschaften, Wiederverwendung von Inhalten
- Kanalmetadaten → Creator-Recherche, Wettbewerbsbeobachtung, Vertriebs-/Influencer-Prospecting
- Videometadaten → Content-Strategie, Titel-/Thumbnail-Analyse, Upload-Frequenz, SEO-Ideenfindung
- Öffentliche E-Mails → Creator-Outreach (verantwortungsvoll und im Einklang mit E-Mail-/Datenschutzregeln verwenden)
Beste YouTube-Scraper im Vergleich: Tabelle nebeneinander
| Tool | Typ | Anti-Ban-Ansatz | Kosten/1K Ergebnisse | Am besten für | Einrichtung | Exportformate | Skalierung |
|---|---|---|---|---|---|---|---|
| Thunderbit | KI-Chrome-Erweiterung | Browser-Session, KI-Felderkennung | Kostenloser Tarif (6 Seiten); bezahlt kreditbasiert | No-Code-Recherche zu Kanälen/Suchen | Sehr einfach | Sheets, Excel, Airtable, Notion, CSV/JSON | Klein bis mittel, geplant |
| Apify | Cloud-Actor-Plattform | Actor-spezifische Taktung, Proxies, Innertube | ca. 5–15 $/1K (je nach Actor) | Entwickler-Pipelines | Mittel | JSON, CSV, Excel, API, Webhooks | Mittel bis hoch |
| Bright Data | Enterprise-Scraper/Proxy | 150 Mio.+ Residential IPs, CAPTCHA-Lösung | 3,50 $/1K Datensätze (PAYG) | Enterprise-Extraktion | Mittel bis schwierig | JSON, NDJSON, CSV, Webhooks | Sehr hoch |
| Octoparse | Visueller Workflow-Builder | Cloud-IP-Rotation, Anti-Detection | ca. 0,20 $/1K Zeilen (Vorlage) + Plan | Visuelle, individuelle Workflows | Mittel | Excel, CSV, JSON, DB | Mittel |
| YT-DLP | Open-Source-CLI | Cookies, Drosselungseinstellungen, Community-Updates | Kostenlos | Technische Metadaten-/Transkript-Extraktion | Schwer (für Nicht-Techniker) | JSON, Untertitel, eigene Ausgabe | Hängt von der Nutzerkonfiguration ab |
| Phantombuster | Cloud-Growth-Automation | Integrierte Verzögerungen, getaktete Sessions | planbasiert (ab 56 $/Monat); ca. 100 Videos/Lauf | Creator-Lead-Gen, Growth-Workflows | Einfach bis mittel | CSV/JSON/API/CRM | Mittel, getaktet |
Kategorie-Sieger:
- Am besten für nicht-technische Nutzer: Thunderbit
- Am besten für Entwickler-Pipelines: Apify
- Am besten für Enterprise-Skalierung: Bright Data
- Bester visueller Builder: Octoparse
- Beste kostenlose technische Option: YT-DLP
- Bester Workflow für Growth Marketing: Phantombuster
Kostenlose vs. kostenpflichtige YouTube-Scraper: Wann Gratis-Tools ausreichen
Kostenlose Tools funktionieren, wenn deine Aufgabe eng umrissen und selten ist und du mit technischer Wartung klarkommst. Hier ist der Punkt, an dem du kostenlos bleibst und wann sich ein Upgrade lohnt:
| Szenario | Beste kostenlose Option | Wann auf kostenpflichtig upgraden | Warum |
|---|---|---|---|
| Einmaliger Transkript-Download | YT-DLP | Du brauchst 500+ Videos oder nicht-technische Teamkollegen | CLI-Setup und Cookie-Verwaltung erzeugen Reibung |
| Schneller Check eines Konkurrenzkanals | Thunderbit kostenloser Tarif (6 Seiten) | Regelmäßige Überwachung oder mehr als 10 Seiten | Geplantes Scraping spart Stunden pro Woche |
| Aufbau eines LLM-Trainingsdatensatzes | YT-DLP + eigene Skripte | Du brauchst Filterung automatischer/manueller Untertitel im großen Stil | Dedizierte Actors von Apify decken Sonderfälle ab |
| Wöchentliche Überwachung von 10+ Kanälen | — | Sofort | Scheduling und Wiederverwendung des Schemas sparen echte Zeit |
| Marketingteam extrahiert Creator-Leads | Thunderbit kostenlose Testphase | 10+ Kanäle/Woche | Skalierung über Credits ist günstiger als die Zeit fürs Skripten |
Die ehrliche Einschätzung: Kostenlose Tools wie YT-DLP sind stark, aber sie brauchen laufende technische Wartung. YouTube-Layoutänderungen, Cookie-Ablauf, Drosselungsanpassungen und Ausgabeformatierung erfordern allesamt manuelle Aufmerksamkeit. Ein Skript, das alle zwei Wochen kaputtgeht, kann in Entwicklerzeit teurer sein als ein bezahltes Scraper-Abo.
KI-gestützte Tools wie Thunderbit lesen die Seiten jedes Mal frisch und passen sich Layoutänderungen automatisch an. Diese versteckten Wartungskosten sind der Grund, warum bezahlte Tools für die meisten Business-Teams sinnvoll sind.
Wie gescrapte YouTube-Daten tatsächlich aussehen (echte Ausgabe-Beispiele)
Eine der größten Lücken in Scraper-Tests ist, dass niemand zeigt, was du wirklich bekommst. Hier sind realistische Beispiele für gescrapte YouTube-Ausgaben:
Beispiel 1: Kanalmetadaten
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Example SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Wöchentliche Produkt-Tutorials und Workflow-Guides | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Analytics, Automatisierung und AI-Workflow-Demos | Nicht sichtbar |
Beispiel 2: Kommentar-Export
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Das hat die Preisfrage besser beantwortet als die Anbieterseite. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Ich würde gern einen Follow-up-Vergleich mit Apify sehen. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Guter Punkt, wir testen das als Nächstes. | 4 | 0 |
Beispiel 3: Transkript-Extraktion
100:00:00.000 - 00:00:04.200 Heute vergleichen wir sechs YouTube-Scraping-Workflows für Marketer.
200:00:04.200 - 00:00:09.800 Der wichtigste Unterschied ist, ob du Metadaten, Kommentare oder Transkripte brauchst.
300:00:09.800 - 00:00:15.300 Für nicht-technische Nutzer ist ein browserbasierter Scraper in der Regel einfacher zu warten.Typische Bereinigungsprobleme, mit denen du rechnen solltest:
- Aufrufzahlen können lokalisierte Suffixe (K, M) oder nicht-englische Bezeichnungen enthalten
- Upload-Daten sind manchmal relativ („vor 3 Jahren“) statt als ISO-Datum
- Kommentare können standardmäßig nach „Top“ statt „Neu“ sortiert sein
- Versteckte Antworten und lazy geladene Kommentare erfordern Scrollen oder Paginierung
- Öffentliche E-Mail-Felder können hinter Interaktionen oder Kontobeschränkungen verborgen sein
- Transkripte sind eventuell nicht verfügbar, automatisch generiert oder in einer unerwarteten Sprache
Für Thunderbit ist der Ablauf besonders einfach: AI Suggest Fields → Scrape → Export to Google Sheets. Die KI übernimmt die Felderkennung, sodass du nicht manuell definieren musst, wie „views“ oder „upload date“ auf der Seite aussehen.
Ist Scraping von YouTube 2026 legal?
Kurz gesagt: Das Scraping öffentlich zugänglicher YouTube-Daten ist in der Regel weniger riskant als der Zugriff auf private Daten, aber es ist kein rechtsfreier Raum.
YouTubes verbieten automatisierten Zugriff ausdrücklich, außer für öffentliche Suchmaschinen, die robots.txt befolgen, oder mit vorheriger schriftlicher Genehmigung von YouTube. Die Durchsetzung gegen legitime Business-Recherche ist jedoch selten – YouTube zielt vor allem auf massiven Missbrauch, Content-Piraterie und Datenschutzverstöße.
US-amerikanische Rechtsprechung bietet etwas Orientierung. Die Entscheidung des Ninth Circuit in stellte ernsthafte Fragen dazu, ob das Scraping öffentlich zugänglicher Daten gegen den CFAA verstößt. Die , dass das Scrapen öffentlicher Websites kein Verbrechen ist. Aber Plattform-AGB, Urheberrecht, Datenschutz und Anti-Spam-Gesetze gelten weiterhin.
Praktische Leitlinien:
- Sammle nur öffentliche Daten, die dein Konto auch sehen darf
- Scrape personenbezogene Daten nicht in unnötig großem Umfang
- Umgehe keine Zugriffskontrollen oder Paywalls
- Respektiere Urheberrecht – republiziere Transkripte oder Videoinhalte nicht pauschal
- Rate-Limit für Jobs und vermeide, YouTubes Server zu überlasten
- Halte dich bei Outreach an CAN-SPAM, DSGVO und lokale Regeln
- Konsultiere bei riskanten Anwendungsfällen eine Rechtsberatung
Die Tools auf dieser Liste enthalten alle Rate-Limiting und respektvolle Taktung von Haus aus. Das ist nicht nur gute Ethik – es ist auch das, was dein Scraping langfristig funktionsfähig hält.
Welchen YouTube-Scraper solltest du wählen?
Hier ist die schnelle Entscheidungshilfe:
- Thunderbit → Am besten für nicht-technische Nutzer, die schnelles, sperrresistentes YouTube-Scraping in Tabellen wollen. Starte hier, wenn du Marketer, Sales Rep oder Content-Stratege bist.
- Apify → Am besten für Entwickler, die automatisierte Pipelines mit geplanten Jobs, Webhooks und API-Auslieferung bauen.
- Bright Data → Am besten für Extraktion im Enterprise-Maßstab über mehrere Regionen hinweg mit verwalteter Anti-Block-Infrastruktur.
- Octoparse → Am besten für Analysten, die visuelle Workflow-Erstellung mit mehr Anpassung als eine Chrome-Erweiterung wollen.
- YT-DLP → Beste kostenlose Option für technische Nutzer, die maximale Kontrolle über Metadaten und Transkripte brauchen.
- Phantombuster → Am besten für Growth Marketer, die Creator-Recherche und YouTube-basierte Lead-Generierung betreiben.
Der Schlüssel, um nicht gesperrt zu werden, ist nicht ein geheimer Trick – sondern ein Tool mit eingebauter intelligenter Anti-Detection. Browserbasierte Session-Scrapes, Proxy-Rotation, Taktung und geplante kleine Batches senken das Risiko. Tausende Anfragen mit Gewalt von einer einzigen Cloud-IP zu schicken, das ist der Weg in die Sperre.
Wenn du sehen möchtest, wie modernes YouTube-Scraping ohne Code aussieht, probiere den kostenlosen Tarif von aus. Zwei Klicks zu strukturierten Daten. Und wenn deine Anforderungen technischer oder auf Enterprise-Skalierung ausgelegt sind, decken die anderen Tools auf dieser Liste dich ab. Mehr zu Web-Scraping-Ansätzen findest du in unseren Leitfäden zu den und zum . Du kannst dir auch Tutorials auf dem ansehen.
FAQs
Welche Daten kann man von einem YouTube-Kanal scrapen?
Zu den extrahierbaren öffentlichen Daten gehören Videotitel, URLs, Thumbnails, Aufrufe, Likes (wo sichtbar), Upload-Daten, Beschreibungen, Dauer, Kommentare, Antworten, Namen/Handles der Kommentierenden, Kommentar-Likes, Transkripte/Untertitel (automatisch generiert und manuell geschrieben), Shorts-Indikatoren, Kanalname, Handle, Abonnentenzahl, Videozahl, Gesamtaufrufe, Beschreibung, Links und öffentliche E-Mails, falls auf der Kanalseite sichtbar.
Wie viele YouTube-Videos kann ich pro Tag scrapen, ohne gesperrt zu werden?
Es gibt keine allgemeingültige Zahl. Browserbasierte Tools wie Thunderbit sind für nutzerähnliche Workflows risikoärmer, weil sie in einer echten Session arbeiten. Phantombusters YouTube Channel Video Extractor unterstützt bis zu 100 Videos pro Lauf. Cloud-Plattformen mit Proxy-Rotation können bei richtiger Taktung Tausende verarbeiten. Rohe Skripte von Cloud-Servern ohne Rate-Limiting werden schnell blockiert. Der sicherste Ansatz sind kleinere, geplante Batches statt eines einzigen riesigen Laufs.
Kann ich YouTube-Kommentare für Sentiment-Analyse scrapen?
Ja. Thunderbit, Apify, Bright Data und Octoparse unterstützen alle die Massenextraktion von Kommentaren mit Autor, Zeitstempel, Likes und Antwortanzahl. Exportiere die Daten zur Analyse nach Google Sheets oder CSV. Der YouTube-Actor von Apify unterstützt für diesen Anwendungsfall explizit konfigurierbare Maximalwerte für Kommentare pro Video.
Gibt es 2026 einen kostenlosen YouTube-Scraper, der wirklich funktioniert?
YT-DLP ist die beste kostenlose Option für technische Nutzer – besonders für Metadaten und Transkripte. Thunderbit bietet für nicht-technische Nutzer einen kostenlosen Tarif (6 Seiten, mit Trial-Boost auf 10), der direkt nach Google Sheets exportiert. Beide funktionieren, aber YT-DLP verlangt Kommandozeilen-Kenntnisse, während Thunderbit nur einen Browser braucht.
Wie vermeiden YouTube-Scraper, blockiert zu werden?
Verschiedene Tools nutzen verschiedene Ansätze: browserbasiertes Session-Scraping (Thunderbit) verwendet den authentifizierten Browser-Kontext des Nutzers; Residential-Proxy-Rotation (Bright Data, Apify) verteilt Anfragen über Millionen von IPs; Cookie-Authentifizierung (YT-DLP) erhält das Session-Vertrauen; integrierte Verzögerungen und Taktung (Phantombuster) vermeiden Verhaltens-Erkennung. Der zuverlässigste Ansatz kombiniert echten Browser-Kontext mit konservativer Taktung und geplanten kleineren Jobs.
Mehr erfahren