Das Internet wächst so rasant, dass ich kaum meinen Morgenkaffee austrinken kann – und glaub mir, ich bin echt fix. Im Jahr 2026 ist das Extrahieren von Webdaten längst kein Spielzeug mehr für Technik-Nerds, sondern ein echter Gamechanger für Vertrieb, Preisbeobachtung im E-Commerce, Marktanalysen oder Immobilienbewertungen. . Das richtige Tool entscheidet, ob du stundenlang Daten manuell zusammensuchst – oder schon vor der Konkurrenz mit frischen Insights glänzt.
Das Beste: Die Auswahl an Web-Scraping-Bibliotheken ist 2026 so bunt wie nie – von KI-gestützten Chrome-Add-ons ohne eine Zeile Code bis zu mächtigen Entwickler-Frameworks. Egal, ob du als Vertriebler Leads in Excel brauchst, als Operations-Manager 500 Produkte im Blick behalten willst oder als Python-Profi deinen eigenen Crawler baust: Für jeden gibt’s das passende Werkzeug. Nach Jahren in der SaaS- und Automatisierungswelt (und etlichen Nachtschichten) stelle ich dir die 10 wichtigsten Web-Scraping-Bibliotheken vor – und zeige, wie du die richtige für deinen Use Case findest.
Was macht eine Web-Scraping-Bibliothek 2026 wirklich stark?
Bevor wir in die Liste einsteigen, lass uns kurz klären, worauf es bei einer Web-Scraping-Bibliothek wirklich ankommt. Aus meiner Sicht sind die besten Tools 2026 durch diese Punkte gekennzeichnet:
- Einfache Bedienung: Kommt auch jemand ohne Programmierkenntnisse schnell ans Ziel? Oder brauchst du einen Python-Guru?
- Umgang mit dynamischen Inhalten: Kann die Bibliothek moderne, JavaScript-lastige Seiten auslesen? Oder scheitert sie schon an etwas komplexerem HTML?
- Sprachen- & Plattformunterstützung: Läuft sie in deiner Lieblingssprache – Python, JavaScript, Java – oder sogar direkt im Browser?
- Skalierbarkeit: Schafft das Tool hunderte oder tausende Seiten, ohne ins Schwitzen zu kommen?
- Integration & Export: Kannst du die Ergebnisse easy nach Excel, Google Sheets, Notion oder in deine Datenpipeline bringen?
- KI & Automatisierung: 2026 sind KI-gestützte Tools, die mit natürlicher Sprache funktionieren, ein riesiger Vorteil – vor allem für Business-User, die nicht coden wollen.
Fakt ist: Unternehmen wollen Tempo, Präzision und möglichst wenig Aufwand. Je weniger Zeit du mit fehlerhaften Scraper-Skripten oder Code verbringst, desto schneller kannst du die Daten nutzen. Dank KI und Browser-Automatisierung können heute auch Nicht-Techniker Daten extrahieren, für die früher ein Entwickler nötig war ().
Kommen wir zu meinen Favoriten.
Die 10 besten Web-Scraping-Bibliotheken für 2026
- für No-Code, KI-gestütztes Web Scraping direkt im Browser
- für einfaches HTML-Parsen und Datenbereinigung in Python
- für großflächiges, schnelles Crawling und Datenpipelines
- für Browser-Automatisierung und Scraping dynamischer, JavaScript-lastiger Seiten
- für ultraschnelles XML/HTML-Parsen in Python
- für jQuery-ähnliche HTML-Auswahl in Python
- für HTTP, HTML-Parsen und JS-Rendering in Python
- für Formular-Automatisierung und einfache Browseraufgaben in Python
- für Headless-Chrome-Automatisierung in Node.js
- für robustes HTML-Parsen in Java
1. Thunderbit
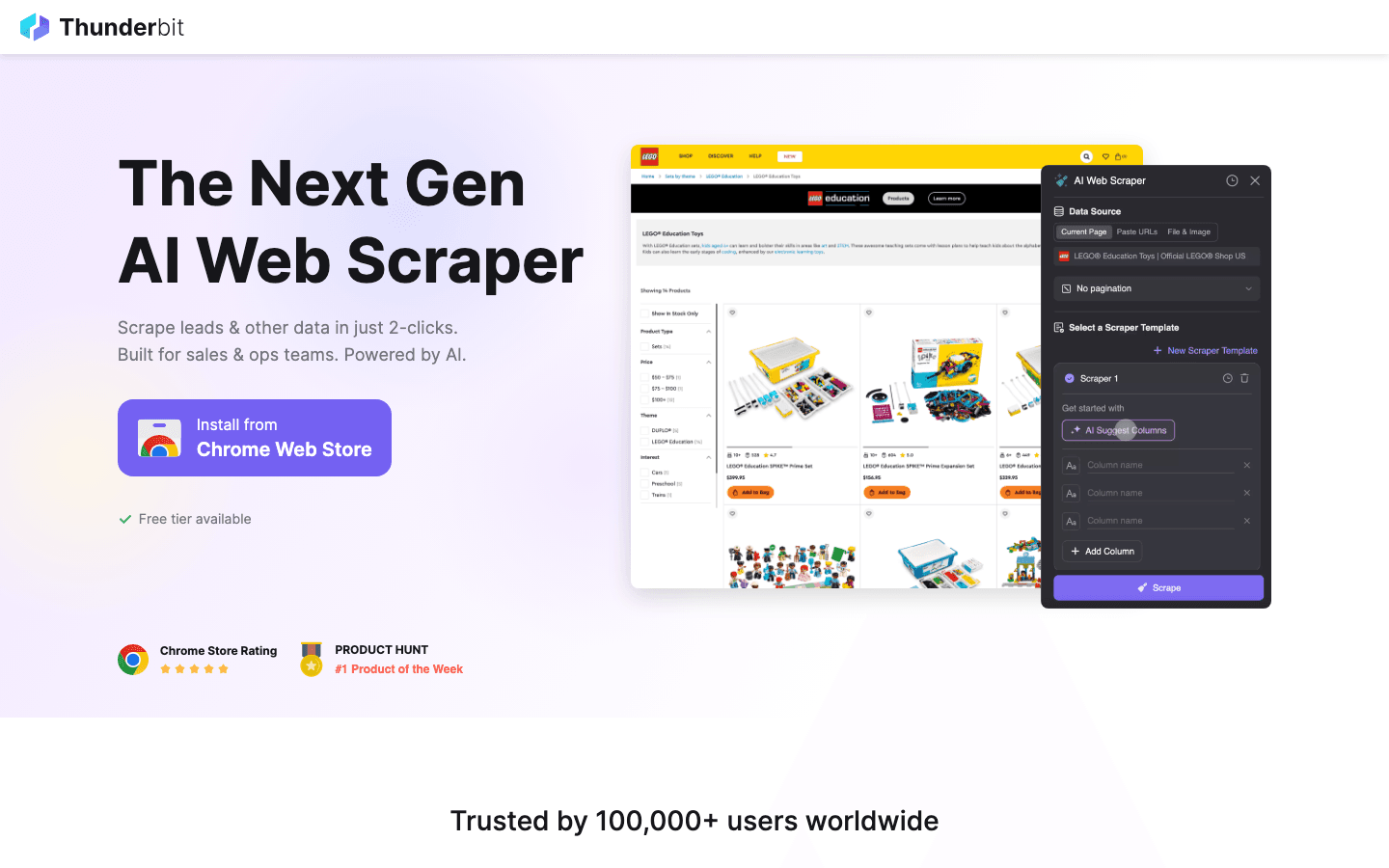
ist meine absolute Empfehlung für alle, die Webdaten extrahieren wollen, ohne sich mit Code rumzuschlagen. Die versteht deine Beschreibung („Alle Produktnamen, Preise und Bilder dieser Seite extrahieren“) und erledigt den Rest automatisch. Keine Vorlagen, kein Setup – einfach auf „KI-Felder vorschlagen“ klicken, ggf. anpassen und loslegen.
Warum Thunderbit 2026 heraussticht:
- No-Code, natürliche Sprache: Jeder kann’s nutzen – Vertrieb, Operations, Marketing, Immobilien. Python-Kenntnisse? Nicht nötig.
- KI-Feldvorschläge: Die KI liest die Seite und schlägt passende Spalten vor.
- Subseiten-Scraping: Mehr Details nötig? Thunderbit besucht automatisch Unterseiten (z. B. Produkt- oder Profilseiten) und ergänzt deine Tabelle ().
- Sofort-Vorlagen für bekannte Seiten: Amazon, Zillow, Shopify und viele mehr – mit einem Klick loslegen.
- Export nach Excel, Google Sheets, Notion, Airtable: Deine Daten landen direkt dort, wo dein Team sie braucht.
- Unterstützt 34 Sprachen: Perfekt für internationale Teams.
- Cloud- oder Browser-Scraping: Wähle, was zu deinem Workflow passt – Cloud ist blitzschnell für öffentliche Seiten, Browser-Modus für Logins.
Thunderbit wird weltweit von über 30.000 Nutzern eingesetzt. Mit dem Gratis-Tarif kannst du bis zu 6 Seiten (bzw. 10 mit Test-Boost) extrahieren. Wer modernes Web Scraping erleben will, sollte hier starten.
2. Beautiful Soup

ist ein echter Klassiker unter den Python-Bibliotheken und bei Data Scientists und Analysten beliebt, weil sie auch mit chaotischem HTML super klarkommt. Wer schon mal Daten aus Seiten mit kaputten Tags oder seltsamer Formatierung extrahieren musste, weiß Beautiful Soup zu schätzen.
Was Beautiful Soup ausmacht:
- Kommt mit unstrukturiertem HTML klar: Ideal, um Daten aus „unschönen“ Webseiten zu bereinigen und zu extrahieren ().
- Leicht zu lernen: Auch Python-Einsteiger kommen schnell ans Ziel.
- Flexibel: Funktioniert gut mit HTTP-Clients wie Requests und lässt sich mit lxml für mehr Speed kombinieren.
- Typische Anwendungsfälle: Schnelle Datenauszüge, Bereinigung von Webdaten, kleine Skripte.
Wer mit statischen Seiten oder unordentlichem Markup arbeitet, ist mit Beautiful Soup bestens bedient.
3. Scrapy

ist das Schwergewicht unter den Python-Web-Scraping-Frameworks. Es bietet alles, was man für skalierbare Crawler und Datenpipelines braucht. Wer tausende Seiten durchsuchen, Links folgen und große Datenmengen verarbeiten will, ist hier goldrichtig.
Warum Scrapy überzeugt:
- Modularer Aufbau: Komplexe Spider, Pipelines und Middlewares lassen sich flexibel zusammenstellen ().
- Für große Projekte gemacht: Perfekt für Marktanalysen, Wettbewerbsbeobachtung oder das Crawlen vieler Seiten.
- Asynchron und schnell: Entwickelt für hohe Geschwindigkeit und Effizienz.
- Große Community: Viele Plugins, Tutorials und Support.
Scrapy hat eine gewisse Lernkurve, ist aber für große Aufgaben unschlagbar.
4. Selenium

ist das Standardwerkzeug zur Browser-Automatisierung. Es wird nicht nur für Web-Tests genutzt, sondern auch, um Seiten mit Logins, Klicks oder Pop-ups zu scrapen. Wer mit JavaScript-lastigen oder sehr dynamischen Seiten arbeitet, kann mit Selenium echte Nutzerinteraktionen nachbilden ().
Stärken von Selenium:
- Automatisiert echte Browser: Chrome, Firefox, Safari, Edge – alles möglich.
- Meistert Logins, Pop-ups und Nutzeraktionen: Ideal für Scraping nach Authentifizierung oder bei mehrstufigen Workflows.
- Mehrsprachig: Python, Java, C# und mehr.
- Am besten geeignet für: Seiten, die einfache Scraper blockieren, oder wenn echtes Nutzerverhalten simuliert werden muss.
Selenium ist etwas schwergewichtiger als reine HTTP-Bibliotheken, aber manchmal unverzichtbar.
5. lxml
ist ein extrem schneller XML- und HTML-Parser für Python. Wer Wert auf Performance legt (z. B. beim Parsen tausender großer Dokumente), kommt an lxml kaum vorbei ().
Warum lxml so beliebt ist:
- Extrem schnell: Übertrifft die meisten anderen Python-Parser, besonders bei großen Dateien.
- Robust: Unterstützt XML und HTML, lässt sich gut mit anderen Tools kombinieren.
- Ideal für: Verarbeitung großer Datenmengen, in Kombination mit Beautiful Soup oder Scrapy.
Wer im großen Stil scrapen oder riesige Dateien verarbeiten muss, sollte lxml nutzen.
6. PyQuery
bringt die beliebte jQuery-Selektorsyntax nach Python. Wer das einfache Auswählen von Elementen mit $('.class') aus jQuery kennt, kann das mit PyQuery auch in Python-Skripten nutzen ().
PyQuery-Highlights:
- jQuery-ähnliche Selektoren: Intuitiv für alle mit Frontend-Erfahrung.
- Kompakter, lesbarer Code: Komplexe Auswahlen werden einfach.
- Integration mit lxml: Schnell und effizient im Hintergrund.
- Ideal für: Projekte, bei denen schnelle, jQuery-ähnliche HTML-Manipulation in Python gefragt ist.
Perfekt für den Umstieg von Webentwicklung auf Datenextraktion.
7. Requests-HTML
ist eine Python-Bibliothek, die die Einfachheit von Requests (für HTTP) mit integriertem HTML-Parsen und sogar JavaScript-Rendering kombiniert.
Was Requests-HTML besonders macht:
- All-in-One: Seiten abrufen, HTML parsen und sogar JavaScript rendern – alles in einem Paket.
- Einsteigerfreundlich: Perfekt für kleine bis mittlere Scraping-Projekte.
- Ideal für: Schnelle Skripte, Seiten mit etwas dynamischem Content und Nutzer, die es unkompliziert mögen.
Wer flexibel und einfach starten will, ist mit Requests-HTML gut beraten.
8. MechanicalSoup

ist eine Python-Bibliothek zur Automatisierung von Webformularen und einfachen Browser-Interaktionen. Sie basiert auf Beautiful Soup und Requests und macht es leicht, sich einzuloggen, Formulare auszufüllen und einfache Workflows zu automatisieren ().
Warum MechanicalSoup praktisch ist:
- Automatisiert Formulare und Logins: Ideal für Daten hinter Authentifizierung.
- Einfache API: Auch für Einsteiger leicht verständlich.
- Am besten für: Wiederkehrende Browseraufgaben, einfache Workflows und Seiten, bei denen volle Browser-Automatisierung zu viel wäre.
Nicht so mächtig wie Selenium für komplexe Seiten, aber für Basisaufgaben deutlich schlanker.
9. Puppeteer
ist eine Node.js-Bibliothek zur Steuerung von Headless Chrome oder Chromium. Sie ist besonders beliebt für das Scraping von JavaScript-lastigen, interaktiven Webseiten ().
Puppeteers Stärken:
- Vollständige Browser-Automatisierung: Klicken, scrollen, Formulare ausfüllen – wie ein echter Nutzer.
- Meistert dynamische Inhalte: Perfekt für Seiten, die Daten per JavaScript nachladen.
- Ideal für: E-Commerce, Social Media oder alle Seiten, bei denen klassische Scraper scheitern.
Für JavaScript-Entwickler oder das Scrapen moderner Webanwendungen ein Muss.
10. Jsoup
ist der Goldstandard für HTML-Parsen in Java. Im Prinzip das Beautiful Soup für Java-Entwickler ().
Warum Java-Teams Jsoup lieben:
- Einfache, leistungsstarke API: Daten mit wenigen Codezeilen extrahieren und bearbeiten.
- Kommt mit chaotischem HTML klar: Auch schlecht formatierte Seiten werden sauber geparst.
- Ideal für: Scraping in Java-basierten Business-Anwendungen oder Backend-Workflows.
Wer auf Java setzt, kommt an Jsoup nicht vorbei.
Vergleichstabelle der Web-Scraping-Bibliotheken
Hier ein schneller Überblick über alle 10 Bibliotheken:
| Bibliothek | Sprache | Bedienkomfort | Dynamische Inhalte | KI/No-Code | Typische Anwendungsfälle | Am besten für |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome-Erweiterung | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Ja | Vertrieb, Ops, Research, Immobilien | Nicht-Programmierer, Business-User |
| Beautiful Soup | Python | ⭐⭐⭐⭐ | ⭐ | Nein | HTML-Parsen, Datenbereinigung | Python-Einsteiger, Analysten |
| Scrapy | Python | ⭐⭐⭐ | ⭐⭐ | Nein | Großes Crawling, Pipelines | Entwickler, Big Data Projekte |
| Selenium | Multi | ⭐⭐ | ⭐⭐⭐⭐⭐ | Nein | Browser-Automatisierung, Logins | QA, dynamische Seiten |
| lxml | Python | ⭐⭐⭐ | ⭐ | Nein | Schnelles Parsen, große Dateien | Power-User, große Datensätze |
| PyQuery | Python | ⭐⭐⭐⭐ | ⭐ | Nein | jQuery-ähnliche Auswahl | Webentwickler, kompakte Skripte |
| Requests-HTML | Python | ⭐⭐⭐⭐ | ⭐⭐ | Nein | Schnelle Skripte, JS-Rendering | Einsteiger, kleine Projekte |
| MechanicalSoup | Python | ⭐⭐⭐⭐ | ⭐⭐ | Nein | Formular-Automatisierung, Logins | Einfache Browseraufgaben |
| Puppeteer | Node.js | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Nein | JS-lastige Seiten, Automatisierung | JS-Entwickler, dynamisches Scraping |
| Jsoup | Java | ⭐⭐⭐⭐ | ⭐ | Nein | HTML-Parsen in Java | Java-Teams, Backend-Workflows |
Wie wähle ich die richtige Web-Scraping-Bibliothek für mein Unternehmen?
Welche Bibliothek passt zu dir? Hier meine Tipps aus jahrelanger Praxis (und so mancher langen Debugging-Nacht):
- Nicht-Programmierer oder Business-User: Starte mit Thunderbit. Dank KI und No-Code bist du in Minuten am Ziel. Wer Daten einfach in Excel oder Sheets braucht, sollte es nicht unnötig kompliziert machen.
- Python-Entwickler: Beautiful Soup und Requests-HTML sind super für kleine Aufgaben. Scrapy ist für große Projekte ideal. Kombiniere mit lxml oder PyQuery für mehr Power.
- Du musst Logins oder dynamische Inhalte verarbeiten? Selenium (mehrsprachig) oder Puppeteer (Node.js) sind hier die beste Wahl.
- Java-Teams: Jsoup ist die erste Wahl für Scraping in Java-Anwendungen.
- Formulare oder einfache Workflows automatisieren? MechanicalSoup ist leichtgewichtig und einfach zu bedienen.
Wichtige Auswahlkriterien:
- Technisches Know-how: No-Code-Tools wie Thunderbit sind ideal für nicht-technische Teams. Entwickler bevorzugen oft die Flexibilität von Code-Bibliotheken.
- Datenkomplexität: Für einfache, statische Seiten sind Beautiful Soup oder Jsoup top. Für dynamische, JavaScript-lastige Seiten lieber Selenium oder Puppeteer.
- Skalierung: Scrapy und lxml sind für große, schnelle Projekte gemacht.
- Integration: Thunderbit exportiert direkt nach Sheets, Notion und Airtable – das spart viel Zeit im Business-Alltag.
Mehr Tipps zur Auswahl findest du im .
Fazit: Mit den richtigen Tools Webdaten erschließen
Web Scraping ist 2026 längst nicht mehr nur Sache von Entwicklern oder Data Scientists. Dank KI und No-Code-Tools kann heute jedes Team – vom Vertrieb bis zur Forschung – das Potenzial von Webdaten nutzen. Die richtige Bibliothek spart dir hunderte Stunden pro Jahr (), erhöht die Genauigkeit und verschafft deinem Unternehmen einen echten Vorsprung.
Mein Tipp: Überleg dir, was du brauchst – Geschwindigkeit, Skalierung, technisches Know-how – und probiere verschiedene Optionen aus. ist ein idealer Einstieg, und Open-Source-Bibliotheken wie Beautiful Soup oder Scrapy stehen bereit, wenn du tiefer einsteigen willst.
Mehr Anleitungen findest du im oder auf unserem mit praktischen Tutorials.
Viel Erfolg beim Scrapen – und mögen deine Daten immer sauber, strukturiert und einsatzbereit sein.
FAQs
1. Welche Web-Scraping-Bibliothek ist 2026 am einfachsten für Nicht-Programmierer?
ist die beste Wahl für Nicht-Programmierer. Die KI-basierte Chrome-Erweiterung ermöglicht das Extrahieren von Daten per natürlicher Sprache – ganz ohne Programmierung.
2. Welche Bibliothek eignet sich am besten für JavaScript-lastige oder dynamische Webseiten?
(Node.js) und (mehrsprachig) sind ideal für dynamische, JavaScript-gerenderte Seiten. Sie steuern echte Browser und meistern komplexe Interaktionen.
3. Was ist der Unterschied zwischen Beautiful Soup und Scrapy?
eignet sich hervorragend zum Parsen und Extrahieren von Daten aus einzelnen Seiten oder kleinen Projekten, besonders bei unstrukturiertem HTML. ist ein komplettes Framework für skalierbares Crawling und die Verarbeitung großer Datenmengen.
4. Kann ich extrahierte Daten direkt nach Google Sheets oder Notion exportieren?
Ja – bietet direkten Export nach Google Sheets, Notion, Airtable und Excel. Bei den meisten Code-Bibliotheken musst du den Export selbst programmieren.
5. Wie finde ich die passende Web-Scraping-Bibliothek für mein Unternehmen?
Berücksichtige dein technisches Know-how, die Komplexität der Zielseiten, das Datenvolumen und Integrationsanforderungen. No-Code-Tools wie Thunderbit sind ideal für Business-Teams, während Entwickler für mehr Kontrolle oft Scrapy, Beautiful Soup oder Puppeteer bevorzugen.
Mehr erfahren