Das Internet ist ein riesiger Schatz an Informationen – aber die wenigsten Daten lassen sich einfach so herunterladen. Im Jahr 2025 ist web scraping von einer Spezialdisziplin zu einer Kernkompetenz für alle geworden, die Preise, Jobs, Immobilien oder die Konkurrenz im Blick behalten wollen. Die Krux: Auf Github tummeln sich unzählige web scraping github Projekte. Manche sind top gepflegt, andere eher Bastelware, viele wurden seit Ewigkeiten nicht mehr angefasst. Wie findest du also das richtige github projekte – vor allem, wenn du kein Hardcore-Entwickler bist?
In diesem Guide zeige ich dir die 15 spannendsten Web-Scraping-Projekte auf Github für 2025. Aber keine Sorge, es gibt nicht nur eine schnöde Liste: Ich erkläre dir, wie sich die python scraper und Tools in Sachen Installation, Einsatzgebiet, Umgang mit dynamischen Inhalten, Pflegezustand, Exportmöglichkeiten und Zielgruppe unterscheiden. Und falls du keine Lust auf Programmieren hast, erfährst du, warum No-Code- und KI-Lösungen wie für Unternehmen und Nicht-Entwickler ein echter Gamechanger sind.
So haben wir die Top 15 Web-Scraping-Projekte auf Github ausgewählt
Mal ehrlich: Nicht jedes github projekte ist gleich brauchbar. Manche sind von tausenden Usern getestet, andere sind Wochenend-Experimente, die nie fertig wurden. Für diese Auswahl habe ich Projekte ausgesucht, die folgende Kriterien erfüllen:
- Github-Stars & Community: Projekte mit großer Verbreitung (von ein paar tausend bis über 90.000 Stars) und aktiven Mitstreitern.
- Aktualität: Tools, die auch 2025 noch weiterentwickelt werden – keine digitalen Staubfänger.
- Dokumentation & Bedienung: Verständliche Anleitungen, Beispielcode und eine moderate Lernkurve.
- Echter Nutzen: Wird das Tool wirklich für Business oder Forschung eingesetzt und nicht nur für „Hello World“-Demos?
Weil web scraping für jeden anders aussieht, vergleiche ich jedes Projekt außerdem nach:
- Einrichtungsaufwand: Kannst du in wenigen Minuten loslegen oder musst du dich erst mit Treibern und Abhängigkeiten rumschlagen?
- Einsatzgebiet: Ist das Tool für E-Commerce, News, Forschung oder was ganz anderes gedacht?
- Dynamische Webseiten: Kommt das Tool mit modernen, JavaScript-lastigen Seiten klar?
- Projektgesundheit: Wird das Projekt aktiv gepflegt oder ist der letzte Commit schon Jahre her?
- Datenexport: Liefert das Tool direkt nutzbare Daten oder nur rohen HTML-Code?
- Zielgruppe: Eher für Python-Einsteiger, Data Engineers oder nicht-technische Teams?
Jedes Projekt bekommt eine Schnellübersicht zu diesen Punkten, damit du direkt das passende Tool für deine Anforderungen findest – egal, ob du ein Code-Profi bist oder deine Daten einfach nur in Google Sheets brauchst.

Einrichtung & Start: Wie schnell kannst du mit dem Scraping loslegen?
Für viele ist die größte Hürde, einen Web-Scraper überhaupt zum Laufen zu bringen. So lassen sich die Tools nach Aufwand einteilen:
- Plug & Play (ohne Konfiguration): Installieren und direkt loslegen. Perfekt für Einsteiger.
- Mittel (Kommandozeile, wenig Code): Etwas Programmiererfahrung oder CLI-Kenntnisse nötig, aber machbar, wenn du schon mal Skripte geschrieben hast.
- Fortgeschritten (Treiber, Anti-Bot, viel Code): Erfordert Set-up der Umgebung, Browser-Treiber oder tiefere Python/JS-Kenntnisse.
So schneiden die Top-Projekte ab:
- Plug & Play: MechanicalSoup (Python), Nokogiri (Ruby), Maxun (für Endnutzer nach Deployment)
- Mittel: Scrapy, Crawlee, Node Crawler, Selenium, Playwright, Colly, Puppeteer, Katana, Scrapling, WebMagic
- Fortgeschritten: Heritrix, Apache Nutch (beide brauchen Java, Konfigurationsdateien oder Big-Data-Stacks)
Für Nicht-Entwickler sind „Plug & Play“- oder No-Code-Lösungen die beste Wahl. Wer ein bisschen Erfahrung mitbringt, kommt mit den „mittleren“ Tools gut klar – solange man keine Angst vor geschweiften Klammern hat.
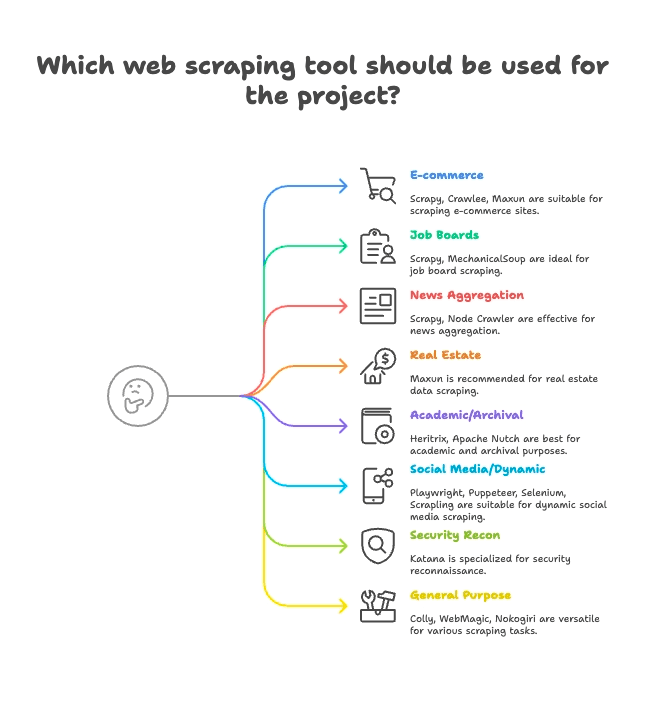
Anwendungsorientierte Gruppierung: Welcher Scraper passt zu deiner Branche?
Nicht jeder Scraper ist für jede Aufgabe gemacht. Hier die Top 15 nach ihrem optimalen Einsatzgebiet:
E-Commerce & Preisüberwachung
- Scrapy: Großflächiges Scraping von Produktlisten über mehrere Seiten
- Crawlee: Vielseitig, für statische und dynamische E-Commerce-Seiten
- Maxun: No-Code, ideal für schnelle Produktdaten-Extraktion
Jobbörsen & Recruiting
- Scrapy: Beherrscht Paginierung und strukturierte Listings
- MechanicalSoup: Gut für Jobbörsen mit Login
Nachrichten & Content-Aggregation
- Scrapy: Für das großflächige Crawlen von Nachrichtenseiten
- Node Crawler: Schnell für statische News-Aggregation
Immobilien
- Thunderbit: KI-gestütztes Scraping von Listen- und Detailseiten
- Maxun: Visuelle Auswahl für Immobiliendaten
Wissenschaft & Web-Archivierung
- Heritrix: Komplettarchivierung von Webseiten (WARC-Dateien)
- Apache Nutch: Verteiltes Crawling für Forschungsdaten
Soziale Medien & dynamische Inhalte
- Playwright, Puppeteer, Selenium: Scraping von dynamischen Feeds, Login-Simulation
- Scrapling: Stealth-Scraping für Seiten mit Anti-Bot-Schutz
Security & Reconnaissance
- Katana: Schnelle URL-Erkennung, Security-Crawling
Allrounder / Multipurpose
- Colly: Hochperformantes Go-Scraping für beliebige Seiten
- WebMagic: Java-basiert, flexibel für viele Bereiche
- Nokogiri: Ruby-Parser für individuelle Skripte
Dynamische Webseiten: Kommen diese Github-Projekte mit modernen Seiten klar?
Moderne Webseiten setzen auf JavaScript: React, Vue, Infinite Scroll, AJAX – wer schon mal versucht hat, so eine Seite zu scrapen und nur leere Daten bekam, kennt das Problem.
So gehen die Projekte mit dynamischen Inhalten um:
- Vollständige JS-Unterstützung (Headless Browser):
- Selenium: Steuert echte Browser, führt sämtliches JS aus
- Playwright: Multi-Browser, Multi-Sprache, robustes JS-Handling
- Puppeteer: Headless Chrome/Firefox, vollständiges JS-Rendering
- Crawlee: Wechselt zwischen HTTP und Browser (über Puppeteer/Playwright)
- Katana: Optionaler Headless-Modus für JS
- Scrapling: Nutzt Playwright für Stealth-JS-Scraping
- Maxun: Nutzt Browser im Hintergrund für dynamische Inhalte
- Keine native JS-Unterstützung (nur statisches HTML):
- Scrapy: Benötigt Selenium/Playwright-Plugin für JS
- MechanicalSoup, Node Crawler, Colly, WebMagic, Nokogiri, Heritrix, Apache Nutch: Alle holen nur HTML, kein JS out-of-the-box
Thunderbits KI ist hier besonders: Sie erkennt und extrahiert dynamische Inhalte automatisch – ohne manuelle Einstellungen, Plugins oder komplizierte Selektoren. Einfach auf „KI-Felder vorschlagen“ klicken und die Arbeit erledigen lassen, selbst auf React-Seiten. Mehr dazu im .
Projektgesundheit & Zuverlässigkeit: Funktioniert der Scraper auch nächstes Jahr noch?
Nichts ist ärgerlicher, als einen Workflow um ein Tool herum aufzubauen, das dann nicht mehr gepflegt wird. So sieht es bei den Top-Projekten aus:
- Aktiv gepflegt (häufige Updates):
- Scrapy:
- Crawlee:
- Playwright:
- Puppeteer:
- Katana:
- Colly:
- Maxun:
- Scrapling:
- Stabil, aber langsamere Updates:
- MechanicalSoup:
- Node Crawler:
- WebMagic:
- Nokogiri:
- Wartungsmodus (spezialisiert, langsam):
- Heritrix:
- Apache Nutch:
Thunderbit ist ein Managed Service – du musst dir also keine Sorgen um veralteten Code machen. Das Team hält KI, Vorlagen und Integrationen aktuell – inklusive Onboarding, Tutorials und Support, falls du mal nicht weiterkommst.
Datenverarbeitung & Export: Von rohem HTML zu nutzbaren Geschäftsdaten
Daten zu extrahieren ist nur die halbe Miete. Sie müssen auch in einem Format vorliegen, das dein Team direkt nutzen kann – etwa CSV, Excel, Google Sheets, Airtable, Notion oder sogar als Live-API.
- Strukturierter Export integriert:
- Scrapy: CSV, JSON, XML Exporter
- Crawlee: Flexible Datasets, verschiedene Speicher
- Maxun: CSV, Excel, Google Sheets, JSON API
- Thunderbit:
- Manuelle Datenverarbeitung (selbst programmieren):
- MechanicalSoup, Node Crawler, Selenium, Playwright, Puppeteer, Colly, WebMagic, Nokogiri, Scrapling: Export muss selbst programmiert werden
- Spezialisierter Export:
- Heritrix: WARC (Webarchiv-Dateien)
- Apache Nutch: Rohdaten in Speicher/Index
Thunderbits strukturierter Export und die Integrationen sparen Business-Usern viel Zeit. Kein CSV-Gefrickel oder eigene Export-Skripte mehr – einfach klicken und die Daten sind einsatzbereit.
Zielgruppen: Für wen eignet sich welches Web-Scraping-Projekt auf Github?
Nicht jedes Tool passt zu jedem Nutzer. Meine Empfehlungen:
- Python-Einsteiger: MechanicalSoup, Scrapling (für Mutige)
- Data Engineers: Scrapy, Crawlee, Colly, WebMagic, Node Crawler
- QA & Automatisierung: Selenium, Playwright, Puppeteer
- Security Researcher: Katana
- Ruby-Entwickler: Nokogiri
- Java-Entwickler: WebMagic, Heritrix, Apache Nutch
- Nicht-Techniker / Business-Teams: Maxun, Thunderbit
- Growth Hacker, Analysten: Maxun, Thunderbit
Wer nicht programmieren möchte oder schnelle Ergebnisse braucht, ist mit Thunderbit und Maxun bestens beraten. Alle anderen wählen das Tool, das zu ihrer Sprache und ihrem Anwendungsfall passt.
Die Top 15 Web-Scraping-Projekte auf Github: Detaillierter Vergleich
Hier findest du alle Projekte, nach Anwendungsfall gruppiert, mit Kurzbeschreibung und Highlights.
E-Commerce, Preisüberwachung und allgemeines Crawling
— 57.1k Stars, Update Juni 2025

- Kurzbeschreibung: Asynchrones Python-Framework für großflächiges Crawling und Scraping.
- Einrichtung: Mittel (Python, Async-Framework)
- Einsatzgebiet: E-Commerce, News, Forschung, Multi-Page-Spider
- JS-Unterstützung: Nein (Selenium/Playwright-Plugin nötig)
- Projektstatus: Aktiv gepflegt
- Datenexport: CSV, JSON, XML integriert
- Zielgruppe: Entwickler, Data Engineers
- Highlights: Skalierbar, robust, viele Plugins. Für Einsteiger steile Lernkurve.
— 17.9k Stars, 2025

- Kurzbeschreibung: Voll ausgestattete Node.js-Bibliothek für statisches und dynamisches Web Scraping.
- Einrichtung: Mittel (Node/TS-Programmierung)
- Einsatzgebiet: E-Commerce, Social Media, Automatisierung
- JS-Unterstützung: Ja (Puppeteer/Playwright-Integration)
- Projektstatus: Sehr aktiv
- Datenexport: Flexibel (Datasets, Speicher)
- Zielgruppe: Entwicklerteams in JS/TS
- Highlights: Anti-Blocking-Toolkit, einfacher Wechsel zwischen HTTP/Browser.
— 13k Stars, Juni 2025

- Kurzbeschreibung: Open-Source No-Code-Plattform für Webdaten-Extraktion mit visueller Oberfläche.
- Einrichtung: Mittel (Server-Deployment), Einfach (für Endnutzer)
- Einsatzgebiet: Allrounder, E-Commerce, Business-Scraping
- JS-Unterstützung: Ja (Browser im Hintergrund)
- Projektstatus: Aktiv & wachsend
- Datenexport: CSV, Excel, Google Sheets, JSON API
- Zielgruppe: Nicht-Techniker, Analysten, Teams
- Highlights: Point-and-Click-Scraping, Multi-Level-Navigation, selbst hostbar.
Jobbörsen, Recruiting und einfache Interaktionen
— 4.8k Stars, 2024

- Kurzbeschreibung: Python-Bibliothek für Formular-Automatisierung und einfache Navigation.
- Einrichtung: Plug & Play (Python, wenig Code)
- Einsatzgebiet: Jobbörsen mit Login, statische Seiten
- JS-Unterstützung: Nein
- Projektstatus: Ausgereift, wenig Updates
- Datenexport: Kein Export integriert (manuell)
- Zielgruppe: Python-Einsteiger, schnelle Skripte
- Highlights: Simuliert Browsersitzungen mit wenigen Zeilen. Nicht für dynamische Seiten.
News-Aggregation & statische Inhalte
— 6.8k Stars, 2024

- Kurzbeschreibung: Schneller, paralleler Server-Crawler mit Cheerio-Parsing.
- Einrichtung: Mittel (Node-Callbacks/Async)
- Einsatzgebiet: News, schnelles statisches Scraping
- JS-Unterstützung: Nein (nur HTML)
- Projektstatus: Moderate Aktivität (v2 Beta)
- Datenexport: Kein Export integriert (selbst programmieren)
- Zielgruppe: Node.js-Entwickler, hohe Parallelität
- Highlights: Async-Crawling, Rate-Limiting, jQuery-ähnliche API.
Immobilien, Listings & Subpage-Scraping

- Kurzbeschreibung: KI-gestützter, No-Code Web-Scraper für Business-Anwender.
- Einrichtung: Plug & Play (Chrome-Erweiterung, 2-Klick-Setup)
- Einsatzgebiet: Immobilien, E-Commerce, Vertrieb, Marketing, jede Website
- JS-Unterstützung: Ja (KI erkennt dynamische Inhalte automatisch)
- Projektstatus: Laufend aktualisiert, Managed Service
- Datenexport: Ein-Klick zu Sheets, Airtable, Notion, CSV, JSON
- Zielgruppe: Nicht-Techniker, Business-Teams, Vertrieb, Marketing
- Highlights: KI „Felder vorschlagen“, Subpage-Scraping, Sofort-Export, Onboarding, Vorlagen, .
Wissenschaft & Web-Archivierung
— 3k Stars, 2023

- Kurzbeschreibung: Web-Archiver des Internet Archive für großflächiges Crawling.
- Einrichtung: Fortgeschritten (Java-App, Konfigurationsdateien)
- Einsatzgebiet: Web-Archivierung, Domain-weites Crawling
- JS-Unterstützung: Nein (nur Fetch)
- Projektstatus: Gepflegt (langsam, aber stabil)
- Datenexport: WARC (Webarchiv-Dateien)
- Zielgruppe: Archive, Bibliotheken, Institutionen
- Highlights: Skalierbar, robust, standardkonform. Nicht für gezieltes Scraping.
— 3k Stars, 2024

- Kurzbeschreibung: Open-Source-Crawler für Big Data und Suchmaschinen.
- Einrichtung: Fortgeschritten (Java+Hadoop für Skalierung)
- Einsatzgebiet: Suchmaschinen-Crawling, Big Data
- JS-Unterstützung: Nein (nur HTTP)
- Projektstatus: Aktiv (Apache)
- Datenexport: Rohdaten in Speicher/Index
- Zielgruppe: Unternehmen, Big Data, Forschung
- Highlights: Plugin-Architektur, verteiltes Crawling.
Soziale Medien, dynamische Inhalte & Automatisierung
— ~30k Stars, 2025

- Kurzbeschreibung: Browser-Automatisierung für Scraping und Testing, unterstützt alle gängigen Browser.
- Einrichtung: Mittel (Treiber, Multi-Sprache)
- Einsatzgebiet: JS-lastige Seiten, Testflows, Social Media
- JS-Unterstützung: Ja (volle Browser-Automatisierung)
- Projektstatus: Aktiv, ausgereift
- Datenexport: Kein Export integriert (manuell)
- Zielgruppe: QA-Engineers, Entwickler
- Highlights: Multi-Sprache, simuliert echtes Nutzerverhalten.
— 73.5k Stars, 2025

- Kurzbeschreibung: Moderne Browser-Automatisierung für Scraping und End-to-End-Tests.
- Einrichtung: Mittel (Multi-Sprache-Skripting)
- Einsatzgebiet: Moderne Web-Apps, Social Media, Automatisierung
- JS-Unterstützung: Ja (Headless oder echter Browser)
- Projektstatus: Sehr aktiv
- Datenexport: Kein Export integriert (selbst programmieren)
- Zielgruppe: Entwickler mit Bedarf an robuster Browser-Steuerung
- Highlights: Cross-Browser, Auto-Wait, Netzwerk-Interception.
— 90.9k Stars, 2025

- Kurzbeschreibung: High-Level-API für Chrome/Firefox-Automatisierung.
- Einrichtung: Mittel (Node-Skripting)
- Einsatzgebiet: Headless Chrome Scraping, dynamische Inhalte
- JS-Unterstützung: Ja (Chrome/Firefox)
- Projektstatus: Aktiv (Chrome-Team)
- Datenexport: Kein Export integriert (selbst programmieren)
- Zielgruppe: Node.js-Entwickler, Frontend-Profis
- Highlights: Umfangreiche Browser-Steuerung, Screenshots, PDF, Netzwerk-Interception.
— 5.4k Stars, Juni 2025

- Kurzbeschreibung: Stealthy, performantes Scraping mit Anti-Bot-Funktionen.
- Einrichtung: Mittel (Python-Code)
- Einsatzgebiet: Stealth-Scraping, Anti-Bot, dynamische Seiten
- JS-Unterstützung: Ja (Playwright-Integration)
- Projektstatus: Aktiv, Cutting Edge
- Datenexport: Kein Export integriert (manuell)
- Zielgruppe: Python-Entwickler, Hacker, Data Engineers
- Highlights: Stealth, Proxy, Anti-Blocking, Async.
Security Reconnaissance
— 13.8k Stars, 2025

- Kurzbeschreibung: Schneller Web-Crawler für Security, Automatisierung und Link-Discovery.
- Einrichtung: Mittel (CLI-Tool oder Go-Lib)
- Einsatzgebiet: Security-Crawling, Endpoint-Discovery
- JS-Unterstützung: Ja (Headless-Modus optional)
- Projektstatus: Aktiv (ProjectDiscovery)
- Datenexport: Textausgabe (URL-Listen)
- Zielgruppe: Security-Researcher, Go-Entwickler
- Highlights: Geschwindigkeit, Parallelität, Headless-JS-Parsing.
Allrounder / Multipurpose Scraping
— 24.3k Stars, 2025

- Kurzbeschreibung: Schnelles, elegantes Scraping-Framework für Go.
- Einrichtung: Mittel (Go-Code)
- Einsatzgebiet: Hochperformantes, allgemeines Scraping
- JS-Unterstützung: Nein (nur HTML)
- Projektstatus: Aktiv, aktuelle Commits
- Datenexport: Kein Export integriert (selbst programmieren)
- Zielgruppe: Go-Entwickler, Performance-Fans
- Highlights: Async, Rate-Limiting, verteiltes Scraping.
— 11.6k Stars, 2023

- Kurzbeschreibung: Flexibles Java-Crawler-Framework im Scrapy-Stil.
- Einrichtung: Mittel (Java, einfache API)
- Einsatzgebiet: Allgemeines Web Scraping in Java
- JS-Unterstützung: Nein (erweiterbar mit Selenium)
- Projektstatus: Aktive Community
- Datenexport: Pluggable Pipelines
- Zielgruppe: Java-Entwickler
- Highlights: Thread-Pool, Scheduler, Anti-Blocking.
— 6.2k Stars, 2025

- Kurzbeschreibung: Schneller, nativer HTML/XML-Parser für Ruby.
- Einrichtung: Plug & Play (Ruby-Gem)
- Einsatzgebiet: HTML/XML-Parsing in Ruby-Apps
- JS-Unterstützung: Nein (nur Parsing)
- Projektstatus: Aktiv, hält Schritt mit Ruby
- Datenexport: Kein Export integriert (mit Ruby formatieren)
- Zielgruppe: Ruby-Entwickler, Rails-Dev
- Highlights: Schnell, konform, sicher per Default.
Schnellvergleich: Feature-Tabelle
Hier ein schneller Überblick – inklusive Thunderbit zum Vergleich:
| Projekt | Einrichtungsaufwand | Einsatzgebiet | JS-Unterstützung | Wartung | Datenexport | Zielgruppe | Github Stars |
|---|---|---|---|---|---|---|---|
| Scrapy | Mittel | E-Commerce, News | Nein | Aktiv | CSV, JSON, XML | Devs, Data Engineers | 57.1k |
| Crawlee | Mittel | Vielseitig, Automatisierung | Ja | Sehr aktiv | Flexible Datasets | JS/TS-Dev-Teams | 17.9k |
| MechanicalSoup | Plug & Play | Statisch, Formulare | Nein | Ausgereift | Kein Export (manuell) | Python-Einsteiger | 4.8k |
| Node Crawler | Mittel | News, statisch | Nein | Moderat | Kein Export (manuell) | Node.js-Entwickler | 6.8k |
| Selenium | Mittel | JS-lastig, Testing | Ja | Aktiv | Kein Export (manuell) | QA, Devs | ~30k |
| Heritrix | Fortgeschritten | Archivierung, Forschung | Nein | Gepflegt | WARC | Archive, Institutionen | 3k |
| Apache Nutch | Fortgeschritten | Big Data, Suche | Nein | Aktiv | Rohdaten | Unternehmen, Forschung | 3k |
| WebMagic | Mittel | Java, allgemein | Nein | Aktive Community | Pluggable Pipelines | Java-Entwickler | 11.6k |
| Nokogiri | Plug & Play | Ruby-Parsing | Nein | Aktiv | Kein Export (manuell) | Rubyists | 6.2k |
| Playwright | Mittel | Dynamisch, Automatisierung | Ja | Sehr aktiv | Kein Export (manuell) | Devs, QA | 73.5k |
| Katana | Mittel | Security, Discovery | Ja | Aktiv | Textausgabe | Security, Go-Entwickler | 13.8k |
| Colly | Mittel | High-Perf, allgemein | Nein | Aktiv | Kein Export (manuell) | Go-Entwickler | 24.3k |
| Puppeteer | Mittel | Dynamisch, Automatisierung | Ja | Aktiv | Kein Export (manuell) | Node.js-Entwickler | 90.9k |
| Maxun | Einfach (User) | No-Code, Business | Ja | Aktiv | CSV, Excel, Sheets, API | Nicht-Techniker, Analysten | 13k |
| Scrapling | Mittel | Stealth, Anti-Bot | Ja | Aktiv | Kein Export (manuell) | Python-Dev, Hacker | 5.4k |
| Thunderbit | Plug & Play | No-Code, Business | Ja | Managed, aktuell | Sheets, Airtable, Notion | Nicht-Techniker, Business | N/A |
Warum Thunderbit die beste Wahl für Nicht-Techniker und Business-Anwender ist
Ganz ehrlich: Die meisten Open-Source-Projekte auf Github sind von Entwicklern für Entwickler gebaut. Das heißt: Installation, Pflege und Fehlersuche gehören dazu. Für Business-Anwender, Marketer, Vertrieb oder alle, die einfach Ergebnisse wollen – und keine Regex-Kopfschmerzen – ist Thunderbit gemacht.
Das macht Thunderbit besonders:
- No-Code, KI-gestützte Einfachheit: , auf „KI-Felder vorschlagen“ klicken und loslegen. Kein Python, keine Selektoren, kein „pip install“-Stress.
- Dynamische Seiten: Thunderbits KI liest und extrahiert Daten auch aus modernen, JavaScript-lastigen Seiten (React, Vue, AJAX) – ganz ohne manuelle Einstellungen.
- Subpage-Scraping: Du willst Details aus allen Produkten oder Listings? Thunderbits KI klickt sich durch Unterseiten und führt die Daten automatisch zusammen – ohne eigenen Code.
- Business-Export: Ein-Klick-Export zu Google Sheets, Airtable, Notion, CSV oder JSON. Perfekt für Leads, Preisüberwachung oder Content-Aggregation.
- Ständige Updates & Support: Thunderbit ist ein Managed Service – kein Risiko für „Abandonware“. Onboarding, Tutorials und eine wachsende Vorlagenbibliothek inklusive.
- Zielgruppe: Thunderbit richtet sich an Nicht-Techniker, Business-Teams und alle, die Wert auf Geschwindigkeit und Zuverlässigkeit legen.
Über 30.000 Nutzer weltweit – darunter Teams von Accenture, Grammarly und Puma – vertrauen bereits auf Thunderbit. Und ja, wir waren sogar #1 Product of the Week auf Product Hunt.
Du willst sehen, wie einfach Scraping sein kann? .
Fazit: Das richtige Web-Scraping-Tool für 2025 finden
Unterm Strich: Github bietet eine riesige Auswahl an mächtigen Scraping-Tools – aber die meisten richten sich an Entwickler. Wer gerne programmiert, findet mit Scrapy, Crawlee, Playwright und Colly maximale Flexibilität. Für Forschung oder Security sind Heritrix, Nutch und Katana die erste Wahl.
Wer aber als Business-Anwender, Analyst oder einfach nur schnell strukturierte Daten braucht, ist mit Thunderbit bestens beraten. Kein Setup, keine Wartung, kein Code – einfach Ergebnisse.
Was jetzt? Probiere ein Github-Projekt aus, das zu deinem Skill-Level und Anwendungsfall passt. Oder überspringe die Lernkurve und sieh in wenigen Minuten echte Resultate – und starte noch heute mit dem Scraping.
Mehr Tipps und Guides rund ums web scraping findest du im , zum Beispiel oder .
Viel Erfolg beim Scraping – auf dass deine Daten immer sauber, strukturiert und einsatzbereit sind. Und falls du mal nicht weiterkommst: Es gibt bestimmt ein Github-Repo dafür… oder du lässt einfach Thunderbits KI die Arbeit machen.