
Das Web quillt über vor Daten, und seien wir ehrlich: Niemand hat Zeit, sich durch tausend Produktlisten oder Preisseiten von Wettbewerbern zu kopieren und einzufügen. Wenn du Linux nutzt, so wie ich für den Großteil meiner Automatisierungs- und Entwicklungsarbeit, weißt du bereits, dass die Plattform ein echtes Kraftpaket für datengetriebene Teams ist. Tatsächlich treibt Linux inzwischen über 80 % der Webserver weltweit an](https://electroiq.com/stats/linux-statistics/#:~:text=was%20worth%20USD%207,of%20embedded%20systems%2C%20while%20security), und 85 % der großen Unternehmen nutzen Linux für Server, Cloud und Entwicklung](https://electroiq.com/stats/linux-statistics/#:~:text=was%20worth%20USD%207,of%20embedded%20systems%2C%20while%20security). Der Haken dabei: Den richtigen Web-Scraper für Linux zu finden, der wirklich zu deinem Workflow passt – egal, ob du ein nicht-technischer Business-User oder ein Hardcore-Entwickler bist –, kann sich anfühlen wie die Suche nach der Nadel im Heuhaufen.
Genau deshalb habe ich diesen Deep Dive in die Top 18 Linux-Web-Scraping-Tools für 2026 zusammengestellt. Von KI-gestützten No-Code-Lösungen wie (ja, die, die mein Team und ich gebaut haben) bis zu klassischen Entwickler-Frameworks wie Scrapy und Beautiful Soup ist diese Liste dein Shortcut, um den besten Linux-Web-Scraper für deine Anforderungen zu finden – ganz ohne frustrierendes Ausprobieren.
Warum Linux-Web-Scraping-Tools für Business-User wichtig sind
Mal ehrlich: Manuelle Datenerfassung ist ein echter Produktivitätskiller. Studien zeigen, dass Teams, die auf Copy-Paste setzen, jede Woche Stunden verlieren und Fehlerquoten von fast 5 % anhäufen – das ist ein Rezept für teure Fehler und verpasste Chancen (). Linux ist mit seiner Stabilität, Sicherheit und Flexibilität die bevorzugte Plattform für Scraper, die rund um die Uhr laufen müssen – egal, ob auf dem Desktop, auf einem Server oder in der Cloud.
Häufige Business-Use-Cases für Linux-Web-Scraping-Tools:
- Lead-Generierung: Vertriebsteams scrapen Verzeichnisse, soziale Medien oder Bewertungsseiten nach frischen Kontakten und sparen sich so die manuelle Fleißarbeit ().
- Preisüberwachung: E-Commerce-Teams ziehen automatisch Wettbewerberpreise und Bestandsdaten, damit die eigene Preisgestaltung scharf und aktuell bleibt.
- Wettbewerbsanalyse: Marketing- und Ops-Teams verfolgen Produktlaunches, Bewertungen und SEO-Keywords – kein „Fliegen im Blindflug“ mehr.
- Market Intelligence: Analysten aggregieren News, Foren- und Social-Daten, um Trends in Echtzeit zu erkennen.
- Workflow-Automatisierung: Einige Tools (vor allem KI-gestützte) können sogar Web-Workflows automatisieren, etwa Formulare ausfüllen oder Dashboards navigieren – direkt von deinem Linux-Rechner aus.
Das Beste daran? Das richtige Linux-Web-Scraping-Tool kann nicht-technische Nutzer befähigen – nicht nur Entwickler –, Webdaten zu nutzen und daraus schnellere und bessere Geschäftsentscheidungen abzuleiten.
Wie wir den besten Web-Scraper für Linux ausgewählt haben
Nicht jeder Scraper ist gleich, besonders unter Linux. Darauf habe ich geachtet:
- Linux-Kompatibilität: Jedes Tool hier läuft nativ auf Linux, im Browser oder mit einem einfachen Workaround (z. B. Wine oder Cloud-Zugriff).
- Benutzerfreundlichkeit: Von KI-Prompts in natürlicher Sprache bis zu visuellen Point-and-Click-Oberflächen habe ich Tools priorisiert, mit denen auch Nicht-Programmierer schnell Ergebnisse erzielen – aber Power-User mit vollem Kontrollbedarf habe ich nicht vergessen.
- Datenextraktionsleistung: Kann es dynamische Inhalte, Pagination, Unterseiten und verschiedene Datentypen verarbeiten? Kommt es mit Anti-Scraping-Tricks klar?
- Skalierbarkeit & Automatisierung: Planung, Cloud-Scraping, verteiltes Crawling – das sind Pflichtfunktionen für ernsthafte Datenprojekte.
- Integration & Export: CSV, Excel, Google Sheets, APIs – wenn du deine Daten nicht herausbekommst, wozu dann?
- Preis & Lizenzmodell: Kostenlos, Open Source oder kostenpflichtig – für jedes Budget ist etwas dabei, von Solo-Gründern bis zu Enterprise-Teams.
- Community & Support: Eine aktive Nutzerbasis, gute Doku und reaktionsschneller Support machen einen enormen Unterschied, wenn du auf ein Problem stößt.
Ich habe außerdem echtes Nutzerfeedback, Branchenreviews und meine eigene praktische Erfahrung mit diesen Tools einfließen lassen. Legen wir los.
1. Thunderbit
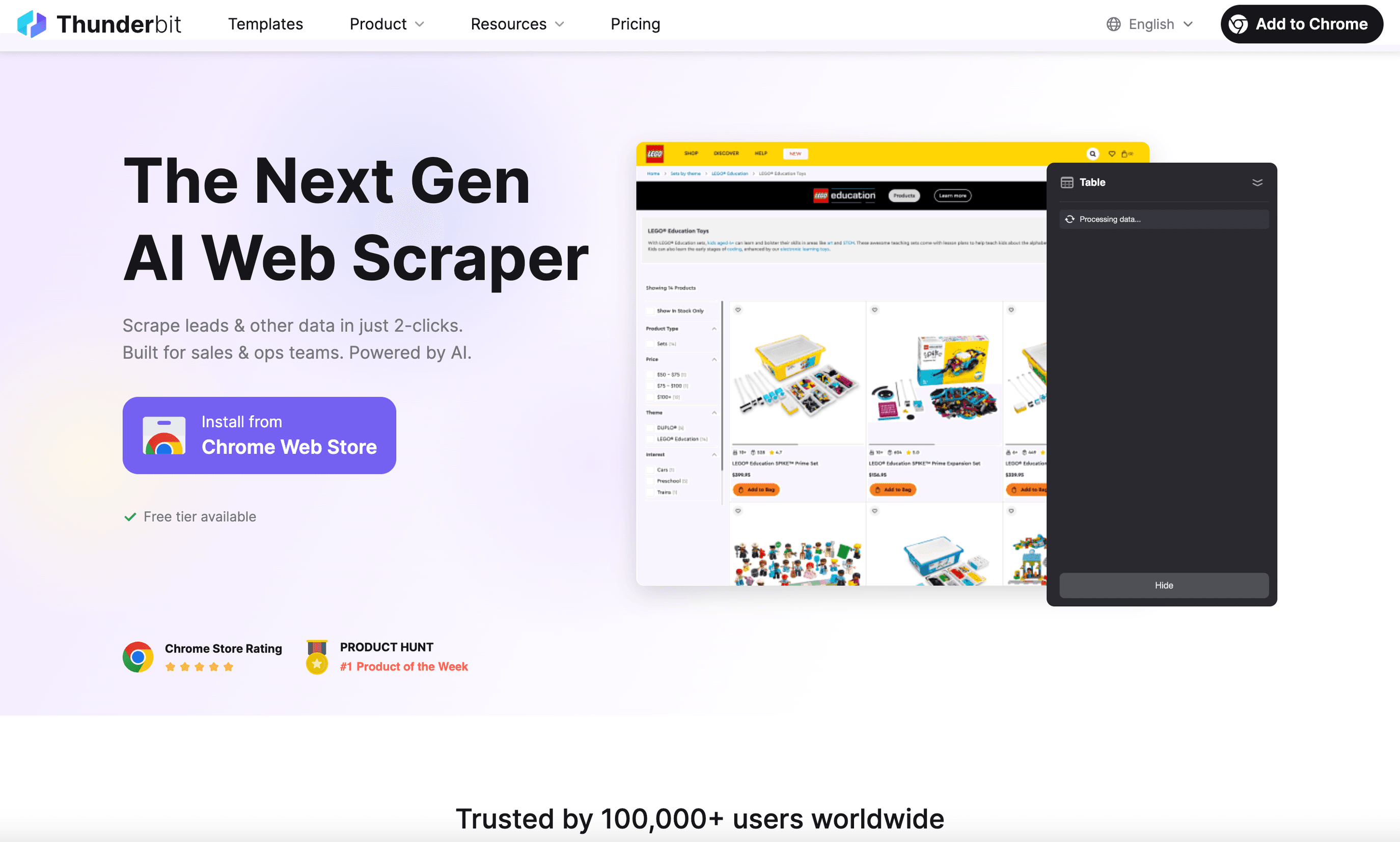 ist meine erste Wahl für Business-User, die einen Web-Scraper für Linux wollen, der wirklich einfach zu bedienen ist. Als läuft sie unter Linux problemlos (einfach Chrome oder Chromium öffnen) und ermöglicht es dir, Daten von jeder Website in nur zwei Klicks zu extrahieren.
ist meine erste Wahl für Business-User, die einen Web-Scraper für Linux wollen, der wirklich einfach zu bedienen ist. Als läuft sie unter Linux problemlos (einfach Chrome oder Chromium öffnen) und ermöglicht es dir, Daten von jeder Website in nur zwei Klicks zu extrahieren.
Was Thunderbit besonders macht:
- Prompts in natürlicher Sprache: Beschreibe einfach, was du brauchst („Extrahiere alle Produktnamen und Preise von dieser Seite“), und die KI von Thunderbit macht den Rest.
- KI-Spaltenvorschläge: Ein Klick genügt, und Thunderbit scannt die Seite und schlägt Spalten sowie Datentypen vor – ganz ohne manuelle Feldauswahl.
- Scraping von Unterseiten & Pagination: Du brauchst mehr Details? Thunderbit kann jede Unterseite besuchen (z. B. Produktdetailseiten) und deine Tabelle automatisch anreichern.
- Cloud- oder lokales Scraping: Scrape bis zu 50 Seiten gleichzeitig in der Cloud oder nutze den Browser-Modus für Seiten, die einen Login erfordern.
- Sofortiger Export: Ein Klick exportiert nach Excel, Google Sheets, Airtable, Notion, CSV oder JSON – immer kostenlos.
- Bonus-Tools: E-Mails, Telefonnummern und Bilder mit einem einzigen Klick extrahieren. KI-Autofill kann sogar Formulareingaben automatisieren.
Preis: Kostenloser Tarif (6–10 Seiten scrapebar), kostenpflichtige Pläne ab 15 $/Monat für 500 Zeilen (). Nutzer lieben die „Null-Einarbeitung“ und dass es „Stunden Arbeit in Minuten verwandelt“ (). Bei großen Jobs musst du möglicherweise in kleinere Durchläufe aufteilen, aber für die meisten Business-Use-Cases ist es ein enormer Zeitgewinn.
Linux-Kompatibilität: 100 %. Einfach Chrome/Chromium auf deinem Linux-Desktop oder Server ausführen.
Am besten geeignet für: Nicht-technische Business-User (Sales, Marketing, Ops), die die schnellste und einfachste Einrichtung wollen.
2. Scrapy
 ist der Goldstandard für Python-Entwickler, die einen flexiblen, skalierbaren Web-Scraper für Linux wollen. Es ist Open Source, blitzschnell (asynchrones Crawling) und kann alles von einfachen Scrapes bis hin zu massiven, verteilten Crawls bewältigen.
ist der Goldstandard für Python-Entwickler, die einen flexiblen, skalierbaren Web-Scraper für Linux wollen. Es ist Open Source, blitzschnell (asynchrones Crawling) und kann alles von einfachen Scrapes bis hin zu massiven, verteilten Crawls bewältigen.
Wichtige Funktionen:
- Asynchrones, ultraschnelles Crawling – perfekt für das Scraping von Tausenden Seiten.
- Hochgradig erweiterbar: Plugins für Proxys, CAPTCHAs und mehr.
- Integration in den Python-Data-Stack: Ausgabe nach JSON, CSV, Datenbanken oder pandas.
- Verarbeitet Cookies, Sessions und Auto-Throttling.
Preis: 100 % kostenlos und Open Source.
Linux-Kompatibilität: Nativ (Installation via pip). Läuft hervorragend auf Servern und in Containern.
Am besten geeignet für: Entwickler, die maßgeschneiderte Scraper in großem Maßstab bauen.
Hinweis: Für Nicht-Programmierer gibt es eine steile Lernkurve, aber wenn du Python kannst, ist Scrapy kaum zu schlagen.
3. Beautiful Soup
 ist eine leichte Python-Bibliothek zum Analysieren von HTML und XML. Sie ist die erste Wahl für schnelles, pragmatisches Scraping oder zum Bereinigen unübersichtlicher Webseiten.
ist eine leichte Python-Bibliothek zum Analysieren von HTML und XML. Sie ist die erste Wahl für schnelles, pragmatisches Scraping oder zum Bereinigen unübersichtlicher Webseiten.
Wichtige Funktionen:
- Einfache, nutzerfreundliche API – ideal für Einsteiger.
- Lässt sich gut mit requests kombinieren zum Abrufen von Seiten.
- Kommt mit kaputtem HTML gut zurecht.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: 100 % (reines Python).
Am besten geeignet für: Entwickler und Data Scientists für kleine bis mittlere Scraping- oder Parsing-Aufgaben.
Einschränkungen: Verarbeitet weder JavaScript noch dynamische Inhalte – kombiniere es bei Bedarf mit Selenium oder Puppeteer.
4. Selenium
 ist das klassische Browser-Automatisierungs-Framework. Damit kannst du Chrome, Firefox oder andere Browser steuern, um dynamische, stark JavaScript-lastige Websites zu scrapen.
ist das klassische Browser-Automatisierungs-Framework. Damit kannst du Chrome, Firefox oder andere Browser steuern, um dynamische, stark JavaScript-lastige Websites zu scrapen.
Wichtige Funktionen:
- Automatisiert echte Browser – kann sich einloggen, klicken, scrollen und wie ein Mensch interagieren.
- Unterstützt Python, Java, C# und mehr.
- Headless-Modus für den Einsatz auf Linux-Servern.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Voller Support (einfach den passenden Browser-Treiber installieren).
Am besten geeignet für: QA-Engineers, Scraping-Entwickler und alle, die Nutzerverhalten simulieren müssen.
Hinweis: Ressourcenintensiv und langsamer als reine HTTP-Scraper, aber manchmal der einzige Weg, an die benötigten Daten zu kommen.
5. Puppeteer
 ist eine Node.js-Bibliothek von Google zur Steuerung von Headless Chrome/Chromium. Es ist wie Selenium, aber mit moderner JavaScript-API und enger Integration in die Chrome-Funktionen.
ist eine Node.js-Bibliothek von Google zur Steuerung von Headless Chrome/Chromium. Es ist wie Selenium, aber mit moderner JavaScript-API und enger Integration in die Chrome-Funktionen.
Wichtige Funktionen:
- Führt JavaScript aus, verarbeitet dynamische Inhalte und erstellt Screenshots.
- Schnell, stabil und für Node.js-Entwickler leicht zu nutzen.
- Intercepted Netzwerk-Requests und blockiert unerwünschte Ressourcen.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Installiert Chromium automatisch; läuft standardmäßig headless.
Am besten geeignet für: Entwickler, die moderne Web-Apps oder Single-Page-Sites scrapen.
6. Octoparse
 ist ein No-Code-Web-Scraper mit Drag-and-drop-Oberfläche und vielen vorgefertigten Vorlagen. Die Desktop-App gibt es zwar nur für Windows/Mac, aber Linux-Nutzer können auf Octoparses Cloud-Plattform per Browser zugreifen oder die Windows-App mit Wine ausführen.
ist ein No-Code-Web-Scraper mit Drag-and-drop-Oberfläche und vielen vorgefertigten Vorlagen. Die Desktop-App gibt es zwar nur für Windows/Mac, aber Linux-Nutzer können auf Octoparses Cloud-Plattform per Browser zugreifen oder die Windows-App mit Wine ausführen.
Wichtige Funktionen:
- Über 100 fertige Scraping-Vorlagen für Seiten wie Amazon, eBay, Zillow usw.
- Visueller Workflow-Designer – per Point-and-Click den eigenen Scraper bauen.
- Cloud-Scraping und Zeitplanung – Octoparses Server übernehmen die schwere Arbeit.
- Export nach Excel, CSV, JSON und Datenbanken.
Preis: Kostenloser Tarif (eingeschränkte Funktionen), kostenpflichtige Pläne ab 75–89 $/Monat.
Linux-Kompatibilität: Cloud-/Web-Zugriff; Desktop-App über Wine.
Am besten geeignet für: Nicht-Programmierer, die schnell E-Commerce- oder Marktplatzdaten brauchen.
7. PhantomJS
 ist ein headless WebKit-Browser, der früher die erste Wahl für leichte Browser-Automatisierung war. Er ist inzwischen veraltet, läuft aber unter Linux weiterhin für Legacy- oder einfache Aufgaben.
ist ein headless WebKit-Browser, der früher die erste Wahl für leichte Browser-Automatisierung war. Er ist inzwischen veraltet, läuft aber unter Linux weiterhin für Legacy- oder einfache Aufgaben.
Wichtige Funktionen:
- Per JavaScript skriptbar.
- Verarbeitet moderates JavaScript und erstellt Screenshots/PDFs.
- Keine GUI erforderlich.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Natives Binary.
Am besten geeignet für: Legacy-Projekte oder Umgebungen, in denen Chrome nicht installiert werden kann.
Achtung: Wird nicht mehr gepflegt – moderne Websites funktionieren möglicherweise nicht gut.
8. ParseHub
 ist ein visueller, plattformübergreifender Web-Scraper mit nativer Linux-App. Er ist ideal für Nicht-Programmierer, die komplexe, dynamische Websites scrapen möchten.
ist ein visueller, plattformübergreifender Web-Scraper mit nativer Linux-App. Er ist ideal für Nicht-Programmierer, die komplexe, dynamische Websites scrapen möchten.
Wichtige Funktionen:
- Point-and-Click-Oberfläche – Elemente auswählen und Workflows visuell bauen.
- Verarbeitet dynamische Inhalte, Karten, endloses Scrollen und mehr.
- Cloud-Ausführung und Zeitplanung.
- Export nach CSV, JSON oder per API.
Preis: Kostenloser Plan (5 Projekte), kostenpflichtige Pläne ab 189 $/Monat.
Linux-Kompatibilität: Native App für Linux, Windows und Mac.
Am besten geeignet für: Analysten und semi-technische Nutzer, die Kontrolle ohne Programmieren wollen.
9. Kimurai
 ist ein Ruby-Web-Scraping-Framework, das Linux nativ unterstützt. Es ist wie Scrapy, nur für Ruby-Entwickler.
ist ein Ruby-Web-Scraping-Framework, das Linux nativ unterstützt. Es ist wie Scrapy, nur für Ruby-Entwickler.
Wichtige Funktionen:
- Unterstützt mehrere Browser: Headless Chrome, Firefox, PhantomJS oder reines HTTP.
- Asynchrone Verarbeitung für hohe Parallelität.
- Saubere Ruby-DSL zum Schreiben von Spidern.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: 100 % (Ruby).
Am besten geeignet für: Ruby-Entwickler oder Rails-Teams, die individuelles Scraping mit hoher Parallelität brauchen.
10. Apify
 ist eine cloudbasierte Web-Scraping-Plattform mit Open-Source-SDKs und einem Marktplatz für fertige „Actors“. Du kannst Scraper auf deinem Linux-Rechner oder in der Cloud ausführen.
ist eine cloudbasierte Web-Scraping-Plattform mit Open-Source-SDKs und einem Marktplatz für fertige „Actors“. Du kannst Scraper auf deinem Linux-Rechner oder in der Cloud ausführen.
Wichtige Funktionen:
- SDKs für Node.js, Python und mehr.
- Marktplatz mit vorgefertigten Scraper.
- Cloud-Ausführung, Zeitplanung und API-Integration.
Preis: Kostenloser Tarif, Pay-as-you-go für Cloud-Nutzung.
Linux-Kompatibilität: CLI/SDK läuft unter Linux; Cloud-Plattform per Browser erreichbar.
Am besten geeignet für: Entwickler, die eine Mischung aus eigenem Code und fertiger Cloud-Infrastruktur wollen.
11. Colly
 ist ein Go-basiertes Web-Scraping-Framework, das auf Geschwindigkeit und Effizienz ausgelegt ist. Wenn du Go-Entwickler bist, ist das dein Tool.
ist ein Go-basiertes Web-Scraping-Framework, das auf Geschwindigkeit und Effizienz ausgelegt ist. Wenn du Go-Entwickler bist, ist das dein Tool.
Wichtige Funktionen:
- Extrem schnelles, paralleles Scraping – über 1.000 Requests/Sekunde auf einem einzelnen Kern.
- Rücksichtsvolles Crawling (beachtet robots.txt), Session-/Cookie-Management.
- Geringer Speicherverbrauch.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Native Go-Binaries.
Am besten geeignet für: Go-Entwickler, die High-Performance-Scraping brauchen.
12. PySpider
 ist ein Python-Web-Crawler-System mit Web-UI. Du kannst Crawls über deinen Browser verwalten, planen und überwachen.
ist ein Python-Web-Crawler-System mit Web-UI. Du kannst Crawls über deinen Browser verwalten, planen und überwachen.
Wichtige Funktionen:
- Webbasierte Oberfläche für Scripting und Monitoring.
- Verteiltes Crawling, Zeitplanung und Wiederholungen.
- Integration mit Datenbanken und Message Queues.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Für Linux-Deployments konzipiert.
Am besten geeignet für: Teams, die mehrere Scraping-Projekte über eine Web-UI verwalten.
13. WebHarvy
 ist ein visueller Point-and-Click-Scraper für Windows, kann aber unter Linux über Wine laufen. Bekannt ist er für seine Mustererkennung und das Einmalkauf-Modell.
ist ein visueller Point-and-Click-Scraper für Windows, kann aber unter Linux über Wine laufen. Bekannt ist er für seine Mustererkennung und das Einmalkauf-Modell.
Wichtige Funktionen:
- Durchsuchen und anklicken, um Daten auszuwählen – kein Coding nötig.
- Automatische Mustererkennung für Listen.
- Export nach CSV, JSON, XML, SQL.
Preis: Ca. 139 $ Einmallizenz.
Linux-Kompatibilität: Läuft unter Wine oder in einer VM.
Am besten geeignet für: Einsteiger oder Solo-Profis, die einen schnellen visuellen Scraper wollen.
14. OutWit Hub
 ist eine native Linux-GUI-Anwendung für Web-Scraping. Sie erkennt Datenmuster automatisch und bietet starke Extraktions- und Automatisierungsfunktionen.
ist eine native Linux-GUI-Anwendung für Web-Scraping. Sie erkennt Datenmuster automatisch und bietet starke Extraktions- und Automatisierungsfunktionen.
Wichtige Funktionen:
- Erkennt Links, Bilder, Tabellen, E-Mails und mehr automatisch.
- Script-Editor für individuelle Extraktion.
- Makro-Automatisierung und Zeitplanung.
Preis: Kostenlose Version (eingeschränkt), Pro-Lizenz ca. 50–100 $.
Linux-Kompatibilität: Native App für Linux, Windows und Mac.
Am besten geeignet für: Nicht-Programmierer mit etwas technischem Interesse, die einen Desktop-GUI-Scraper wollen.
15. Portia
 ist ein Open-Source-, visueller Web-Scraper von Scrapinghub. Er läuft im Browser und ermöglicht es dir, Seiten zu annotieren, um Scraper zu trainieren.
ist ein Open-Source-, visueller Web-Scraper von Scrapinghub. Er läuft im Browser und ermöglicht es dir, Seiten zu annotieren, um Scraper zu trainieren.
Wichtige Funktionen:
- Browserbasierte Oberfläche für visuelle Extraktion.
- Integration mit Scrapy für individuelle Projekte.
- Open Source und erweiterbar.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Browserbasiert; läuft auf jedem Betriebssystem.
Am besten geeignet für: Nutzer, die Open-Source-Visual-Scraping mit Scrapy-Integration möchten.
16. Content Grabber
 ist ein Enterprise-Visual-Scraper für Windows, kann aber über Wine oder Virtualisierung unter Linux ausgeführt werden.
ist ein Enterprise-Visual-Scraper für Windows, kann aber über Wine oder Virtualisierung unter Linux ausgeführt werden.
Wichtige Funktionen:
- Visueller Editor plus C#-Scripting für fortgeschrittene Logik.
- Verwaltung mehrerer Agenten und Zeitplanung.
- Integration mit Datenbanken, APIs und mehr.
Preis: Lizenzen im vierstelligen Bereich; Server-Edition ab 69 $/Monat.
Linux-Kompatibilität: Über Wine oder VM.
Am besten geeignet für: Agenturen und große Teams, die viele Scraping-Projekte verwalten.
17. Helium
 ist eine Python-Bibliothek, die Selenium-Automatisierung vereinfacht. Sie wurde entwickelt, um Browser-Scripting menschenfreundlicher zu machen.
ist eine Python-Bibliothek, die Selenium-Automatisierung vereinfacht. Sie wurde entwickelt, um Browser-Scripting menschenfreundlicher zu machen.
Wichtige Funktionen:
- Intuitive Befehle wie
click("Login")oderwrite("email"). - Automatisiert Chrome und Firefox.
- Ideal für schnelle Scripting- und Automatisierungsaufgaben.
Preis: Kostenlos und Open Source.
Linux-Kompatibilität: Läuft unter Linux (auf Selenium aufgebaut).
Am besten geeignet für: Python-Nutzer, denen Selenium zu umständlich ist.
18. Dexi.io
 ist eine cloudbasierte Plattform für Datenextraktion und Automatisierung. Sie ist über den Browser zugänglich, sodass Linux-Nutzer sie ohne Installation verwenden können.
ist eine cloudbasierte Plattform für Datenextraktion und Automatisierung. Sie ist über den Browser zugänglich, sodass Linux-Nutzer sie ohne Installation verwenden können.
Wichtige Funktionen:
- Visueller Workflow-Designer für Scraping und Automatisierung.
- Zeitplanung, Datentransformation und API-Integration.
- Skalierbarkeit und Support auf Enterprise-Niveau.
Preis: Ab 119 $/Monat (Standard); höhere Tarife für größere Umfänge.
Linux-Kompatibilität: Web-App – läuft auf jedem Betriebssystem.
Am besten geeignet für: Profis und Unternehmen, die skalierbare, integrierte Web-Datenextraktion benötigen.
Kurze Vergleichstabelle: Linux-Web-Scraping-Tools auf einen Blick
| Tool | Typ / Hauptfunktionen | Ideal für | Preis | Linux-Kompatibilität |
|---|---|---|---|---|
| Thunderbit | KI-Chrome-Erweiterung, 2-Klick, Unterseiten, Cloud/Lokal | Nicht-technische Business-User | Kostenlos, ab 15 $/Monat | ✔ Chrome auf Linux |
| Scrapy | Python-Framework, async, CLI, hoch erweiterbar | Entwickler, maßgeschneiderte Scraper in großem Maßstab | Kostenlos | ✔ Nativ |
| Beautiful Soup | Python-Bibliothek, einfaches HTML-/XML-Parsing | Entwickler, Data Scientists, kleine Aufgaben | Kostenlos | ✔ Nativ |
| Selenium | Browser-Automatisierung, Seiten mit viel JavaScript | QA, Entwickler, dynamische Inhalte | Kostenlos | ✔ Nativ |
| Puppeteer | Node.js, Headless Chrome, JavaScript-Rendering | Node-Entwickler, moderne Web-Apps | Kostenlos | ✔ Nativ |
| Octoparse | No-Code, Drag-and-drop, Cloud-Vorlagen | Nicht-Programmierer, E-Commerce | Kostenlos, ab 75 $/Monat | ◐ Cloud/Wine |
| PhantomJS | Headless WebKit, per JS skriptbar | Legacy, leichtgewichtig, ohne Chrome | Kostenlos | ✔ Nativ |
| ParseHub | Visuell, plattformübergreifend, Point-and-Click | Analysten, semi-technische Nutzer | Kostenlos, ab 189 $/Monat | ✔ Nativ |
| Kimurai | Ruby-Framework, mehrere Browser, async | Ruby-Entwickler, hohe Parallelität | Kostenlos | ✔ Nativ |
| Apify | Cloud-Plattform, SDKs, Marktplatz | Entwickler, Hybrid aus Code und Cloud | Kostenloser Tarif, nutzungsbasiert | ✔ Nativ/Cloud |
| Colly | Go-Framework, schnell, parallel | Go-Entwickler, High-Performance | Kostenlos | ✔ Nativ |
| PySpider | Python, Web-UI, Zeitplanung, verteilt | Teams, mehrere Projekte | Kostenlos | ✔ Nativ |
| WebHarvy | Visuell, Mustererkennung, Einmallizenz | Einsteiger, Einzelprofis | Ca. 139 $ einmalig | ◐ Wine/VM |
| OutWit Hub | Native GUI, erkennt Daten automatisch, Scripting | Nicht-Programmierer, Desktop-GUI | Kostenlos, Pro 50–100 $ | ✔ Nativ |
| Portia | Open Source, visuell, browserbasiert | Open Source, Scrapy-Integration | Kostenlos | ✔ Browser |
| Content Grabber | Enterprise, visuell, Scripting, Multi-Agent | Agenturen, große Teams | $$$, ab 69 $/Monat | ◐ Wine/VM |
| Helium | Python, vereinfachtes Selenium, intuitive API | Python-Nutzer, schnelle Automatisierung | Kostenlos | ✔ Nativ |
| Dexi.io | Cloud, visueller Workflow, Zeitplanung, API | Enterprise, skalierbare Automatisierung | Ab 119 $/Monat | ✔ Browser |
So wählst du den richtigen Web-Scraper für Linux: Wichtige Überlegungen
Das richtige Tool zu wählen, bedeutet vor allem, deine Anforderungen und Fähigkeiten sauber abzugleichen:
- Technisches Niveau: Nicht-Programmierer sollten eher zu Thunderbit, ParseHub, Octoparse oder OutWit Hub greifen. Entwickler holen mit Scrapy, Puppeteer, Colly oder Kimurai deutlich mehr heraus.
- Datenkomplexität: Für statische Seiten sind Beautiful Soup oder Colly schnell und einfach. Für dynamische, stark JavaScript-lastige Websites brauchst du Selenium, Puppeteer oder ein visuelles Tool mit JS-Unterstützung.
- Umfang & Häufigkeit: Für einmalige Jobs reichen No-Code-Tools oder Cloud-Scraper. Für geplante Crawls im großen Stil sind Scrapy, PySpider oder Apify die bessere Wahl.
- Integrationsbedarf: Du musst nach Excel, Sheets oder in eine Datenbank exportieren? Dann stell sicher, dass dein Tool zu deinem Workflow passt.
- Budget: Für Entwickler gibt es viele kostenlose und Open-Source-Optionen. Für Business-User bieten Thunderbit und ParseHub günstige Einstiegspunkte, während Enterprise-Teams eher in Dexi.io oder Content Grabber investieren.
- Support & Community: Open-Source-Tools haben große Communities; kommerzielle Tools bieten dedizierten Support.
Profi-Tipp: Hab keine Angst, Tools zu kombinieren. Nutze Thunderbit, um Prototypen zu bauen und Datenmuster zu erkennen, und wechsle dann für Crawls im Produktivmaßstab zu Scrapy. Oder verwende Selenium, um dich einzuloggen und Session-Cookies zu holen, und gib dann an Colly oder Scrapy für High-Speed-Scraping weiter.
Fazit: Finde deinen besten Linux-Web-Scraping-Tool für 2026
Linux-Nutzer haben 2026 die Qual der Wahl. Ob du ein No-Code-, KI-gestütztes Tool willst, das dir in Minuten Ergebnisse liefert (Thunderbit), ein robustes Entwickler-Framework (Scrapy, Colly) oder eine Plattform auf Enterprise-Niveau (Dexi.io) – es gibt einen Web-Scraper für Linux, der zu deinen Anforderungen und deinem Workflow passt.
Wichtige Erkenntnisse:
- Linux ist das Rückgrat moderner Dateninfrastrukturen – die meisten Top-Scraper laufen nativ oder im Browser.
- KI- und No-Code-Tools demokratisieren Web-Scraping für Business-User.
- Entwickler-Frameworks bleiben in Sachen Flexibilität, Geschwindigkeit und Skalierung die erste Wahl.
- Erst testen, dann kaufen – die meisten Tools bieten kostenlose Tarife oder Testversionen.
Bereit zum Start? oder den für weitere Anleitungen zu Web-Scraping, Automatisierung und datengetriebenem Wachstum besuchen.
FAQs
1. Was ist der einfachste Web-Scraper für Linux, wenn ich nicht programmieren kann?
ist die erste Wahl für nicht-technische Nutzer. Es läuft als Chrome-Erweiterung unter Linux, nutzt KI zur Automatisierung von allem und lässt dich Daten in nur zwei Klicks scrapen.
2. Welcher Linux-Web-Scraper ist am besten für große, individuelle Projekte?
ist die Standardwahl für Entwickler. Es ist schnell, skalierbar und hochgradig anpassbar – perfekt für große, wiederkehrende Crawls.
3. Kann ich unter Linux Websites mit viel JavaScript oder dynamischen Inhalten scrapen?
Ja! Nutze oder , um echte Browser zu steuern und dynamische Inhalte zu extrahieren. Visuelle Tools wie ParseHub und Thunderbit unterstützen ebenfalls dynamische Websites.
4. Gibt es kostenlose Linux-Web-Scraping-Tools für Business-Anwendungen?
Absolut. Scrapy, Beautiful Soup, Selenium, Colly, PySpider und Kimurai sind alle kostenlos und Open Source. Thunderbit und ParseHub bieten kostenlose Tarife für kleinere Aufgaben.
5. Wie entscheide ich zwischen No-Code- und codebasierten Linux-Scrapern?
Wenn du Geschwindigkeit und Einfachheit willst, nimm No-Code (Thunderbit, ParseHub, Octoparse). Wenn du Flexibilität, Automatisierung oder Integration mit anderen Systemen brauchst, sind codebasierte Tools (Scrapy, Puppeteer, Colly) die beste Wahl.
Viel Spaß beim Scraping – und mögen deine Linux-gestützten Datenprojekte reibungsloser laufen als eine frisch installierte Ubuntu-Session. Wenn du mehr Web-Scraping-Tipps sehen willst, schau im vorbei oder abonniere unseren für praktische Tutorials.
Mehr erfahren