Wer 2026 Web-Scraping-Tools bewertet, sucht selten eine Philosophievorlesung. Gefragt ist eine belastbare Shortlist, ein schneller Weg, Business-Tools von engineeringlastigen Stacks zu trennen – und genug konkrete Belege, um nicht das Falsche zu kaufen. Genau dafür ist diese Seite gemacht.
Die kurze Antwort
Wer nur die Entscheidungslogik braucht, hält sich an folgenden Leitfaden:
- Greifen Sie zu einem KI-Web-Scraper, wenn Sie mit minimalem Aufwand möglichst schnell von der Website zur Tabelle kommen wollen.
- Greifen Sie zu einem No-Code-Scraper, sobald Sie mehr Aufgabensteuerung, Zeitplanung oder Cloud-Läufe ohne Programmierung brauchen.
- Greifen Sie zu einer API-Plattform, wenn Ihr Team Rendering, Proxy-Rotation, Anti-Bot-Handling oder die Einbettung in ein internes Produkt benötigt.
- Greifen Sie zu einer Open-Source-Bibliothek, wenn Sie volle Kontrolle wollen – inklusive Wartung, Selektoren, Infrastruktur und Fehlern.
Dieser Artikel listet alle 20 Tools, die Empfehlung bleibt aber bewusst schlicht: Beginnen Sie mit dem leichtesten Tool, das Ihren Workflow zuverlässig abbildet – und rücken Sie erst dann tiefer in den Stack, wenn Wartung, Blockaden oder Skalierung Sie dazu zwingen.
Schneller Vergleich: Die besten Web-Scraping-Tools 2026
Preise und Tarifmodelle unten wurden am 08.05.2026 anhand der offiziellen Produkt- oder Preisseiten geprüft. Wo Anbieter nutzungsbasiert oder über individuelle Enterprise-Angebote abrechnen, beschreibe ich das Preismodell – statt einen universell verlässlichen Listenpreis vorzutäuschen.
| Tool | Typ | Am besten geeignet für | Warum es 2026 auf der Liste steht | Preismodell (geprüft im Mai 2026) |
|---|---|---|---|---|
| Thunderbit | KI-Web-Scraper | Vertrieb, Ops, E-Commerce, Immobilien | Schnellster Weg für Nicht-Programmierer; KI-Feldvorschläge, Unterseiten, Exporte, Browser- + Cloud-Workflow | Kostenloser Tarif, kostenpflichtige Pläne, individuelle Business-Preise |
| Browse AI | KI-Web-Scraper | Business-Nutzer, die Websites überwachen | Starke No-Code-Robots, Monitoring und Ausgaben im Spreadsheet-/API-Stil | Kostenloser Plan, kostenpflichtige Pläne, Premium-Managed-Tier |
| Bardeen | KI-Automatisierung + Scraping | Revenue Ops und Browser-Workflows | Besser, wenn Scraping nur ein Schritt in einem größeren Automatisierungsworkflow ist | Kostenloser Plan und kostenpflichtige Pläne |
| Diffbot | KI-Extraktionsplattform | Enterprise- und Datenteams | Stärkste Option, wenn Sie KI-Extraktion plus strukturierte Daten-Workflows in großem Maßstab wollen | Enterprise-Preismodell |
| Instant Data Scraper | Leichter Browser-Scraper | Gelegenheitsnutzer und schnelle Tabellen-Extraktion | Immer noch eine der einfachsten Möglichkeiten, eine sichtbare Liste oder Tabelle schnell nach CSV zu ziehen | Kostenlos |
| Octoparse | No-Code-Scraper | Analysten und Ops-Teams mit größeren wiederkehrenden Jobs | Ausgereifter visueller Builder mit Cloud-Extraktion, Anti-Blocking und Vorlagen | Kostenloser Plan, kostenpflichtig ab 69 $/Monat, Enterprise individuell |
| ParseHub | Low-Code-Scraper | Analysten mit Bedarf an Logik und Desktop-Steuerung | Flexible Projektlogik und verschachtelte Navigation, mit steilerer Lernkurve als neuere KI-First-Tools | Kostenloser Plan und kostenpflichtige Pläne |
| Web Scraper | No-Code-Scraper | Einsteiger und leichte Cloud-Jobs | Guter Einstieg, wenn Sie Sitemap-basiertes Scraping und Browser-First-Setup mögen | Kostenlose Erweiterung, kostenpflichtige Cloud-Pläne |
| Data Miner | Browser-Scraper | Forscher und Growth-Operatoren | Weiterhin nützlich für schnelle, rezeptbasierte Extraktion direkt im Browser | Kostenloser Plan und kostenpflichtige Pläne |
| Apify | API- + Actor-Plattform | Technische Teams und hybride Operatoren | Exzellentes Ökosystem aus Actors plus eigene Laufzeit, wenn Browser-Erweiterungen nicht mehr reichen | Kostenloser Plan, Starter ab 29 $/Monat plus Nutzung, größere Tarife |
| ScrapingBee | Scraping-API | Entwickler, die JS-lastige Seiten scrapen | Gute Wahl, wenn Sie Rendering und Proxy-Handling wollen, ohne den Browser-Layer selbst zu bauen | Kostenlose Testphase und kostenpflichtige Pläne |
| ScraperAPI | Scraping-API | Entwickler, die Anfragen schnell skalieren | Unkomplizierte API, Testguthaben, strukturierte Produkte und einfachere Auslagerung der Infrastruktur | 7-Tage-Test mit 5.000 Credits, kostenpflichtig ab 49 $/Monat |
| Bright Data | Enterprise-API + Proxy-Plattform | Programme mit hohem Volumen und hohen Compliance-Anforderungen | Umfassendster Daten-Collection-Stack, wenn Unblocking, Proxy und Managed Acquisition wichtiger sind als Einfachheit | Nutzungsbasierte und produktbasierte Preise |
| Oxylabs | Enterprise-API + Proxy-Plattform | Teams, die Scraping als Infrastruktur einkaufen | Stark für großskalige Erfassung, besonders bei Preis-, SEO- und Marktforschungs-Workloads | Web Scraper API ab 49 $/Monat; breitere Proxy-Preise variieren |
| Zyte | API + Anti-Bot-Stack | Entwickler- und Datenteams | Gute Wahl, wenn Sie API-first-Extraktion mit starken Browser-, Rotations- und Anti-Detection-Bausteinen wollen | Test mit 5 $ Gratisguthaben, nutzungsbasierte Zusagen |
| Selenium | Open-Source-Browserautomatisierung | QA-ähnliche Automatisierung und komplexe Interaktionsabläufe | Weiterhin nützlich, wenn die Treue zur Nutzerinteraktion wichtiger ist als Durchsatz | Kostenlos und Open Source |
| BeautifulSoup4 | Open-Source-Parser | Einsteiger und leichte Parsing-Aufgaben | Am besten als Parser in einem einfachen Stack, nicht als vollständige Scraping-Plattform | Kostenlos und Open Source |
| Scrapy | Open-Source-Crawling-Framework | Produktive, individuelle Crawler | Beste Mischung aus Leistung und Reife, wenn Sie die Pipeline selbst betreiben wollen | Kostenlos und Open Source |
| Puppeteer | Open-Source-Browserautomatisierung | Node-first-Scraping und Browser-Scripting | Großartig, wenn Ihr Team bereits im Chrome-/Node-Ökosystem zu Hause ist | Kostenlos und Open Source |
| Playwright | Open-Source-Browserautomatisierung | Moderne Automatisierung für mehrere Browser | Oft die sauberste Wahl für moderne Browserautomatisierung mit starker Entwicklerfreundlichkeit | Kostenlos und Open Source |
So habe ich diese Tools bewertet
Vier Kriterien lagen meiner Bewertung zugrunde:
- Zeit bis zum ersten erfolgreichen Scrape
Kommt ein nicht-technischer Nutzer nicht zügig an brauchbare Daten, zählt das. - Wartungsaufwand
Schnelles Setup nützt wenig, wenn der Workflow bei jeder Website-Änderung bricht. - Skalierungsgrenze
Manche Tools sind ideal für 50 Seiten pro Woche – und katastrophal für 5 Millionen Anfragen pro Monat. - Workflow-Fit
Das beste Tool für ein Revenue-Ops-Team ist selten das beste Tool für ein Data-Platform-Team.
Das Ergebnis ist kein universelles Ranking, sondern eine Entscheidungsseite: zuerst die richtige Tool-Klasse wählen, dann das passende Produkt innerhalb dieser Klasse.
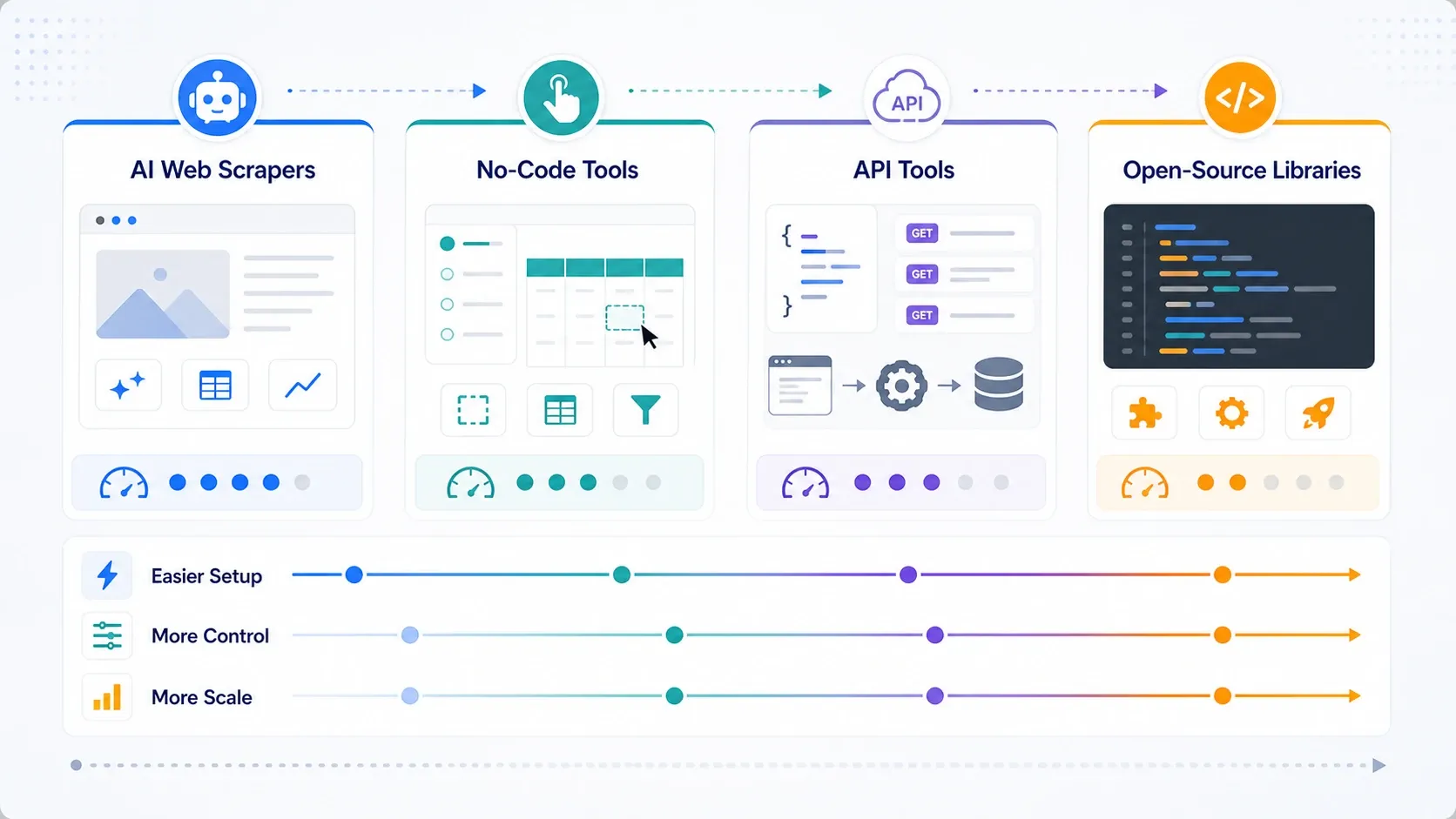
Welchen Web-Scraping-Tool-Typ brauchen Sie wirklich?
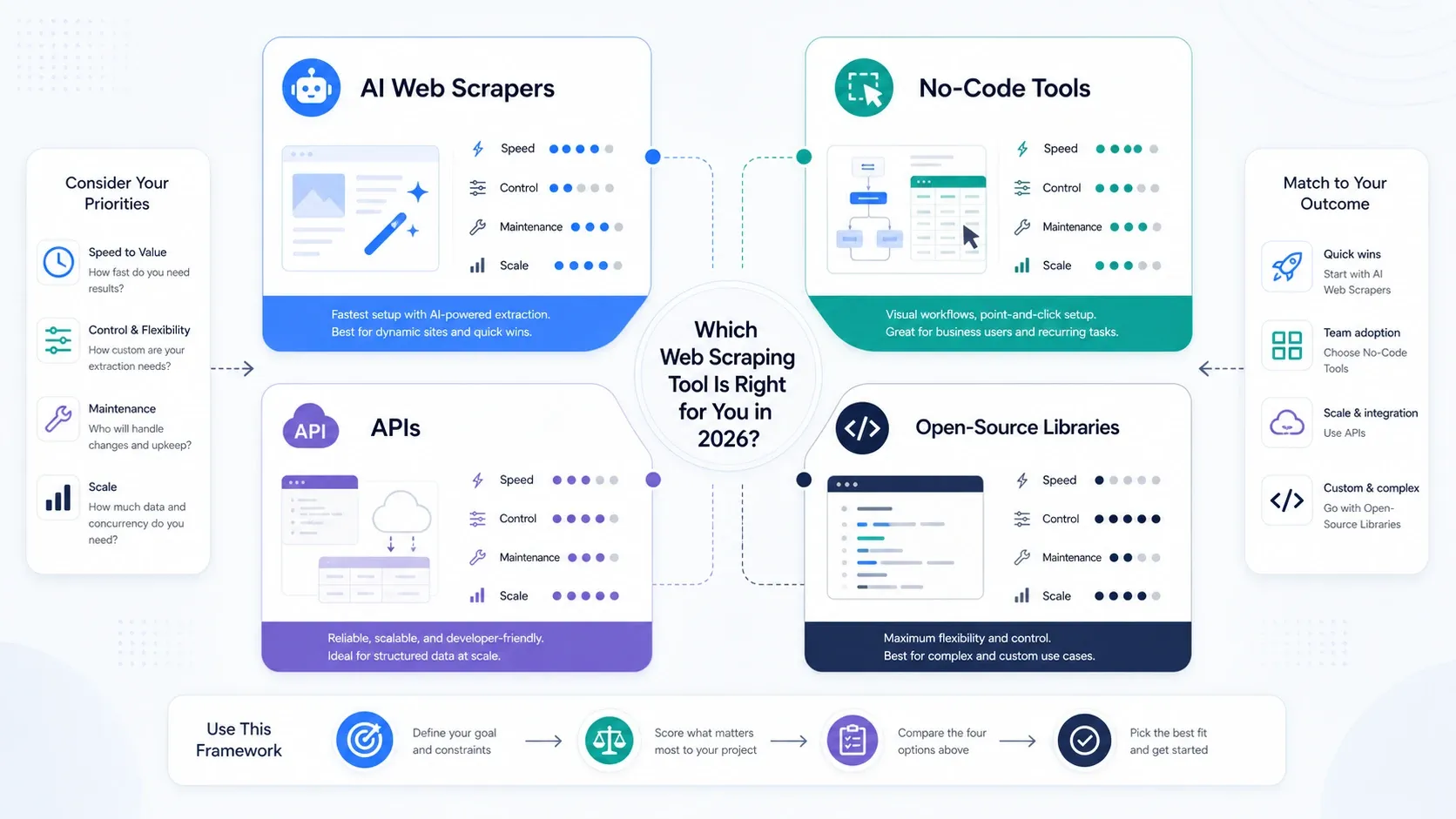
- Greifen Sie zu KI-Web-Scrapern, wenn operative Geschwindigkeit das Hauptziel ist.
- Greifen Sie zu No-Code-Tools, sobald Sie mehr Paginierung, Zeitplanung und wiederholbare Aufgabensteuerung brauchen.
- Greifen Sie zu APIs und Scraping-Plattformen, sobald Rendering, Rotation und Unblocking-Fähigkeit zum Engpass werden.
- Greifen Sie zu Open-Source-Bibliotheken, wenn Ihr Team Kontrolle höher gewichtet als Bequemlichkeit und den Stack intern selbst tragen kann.
Steht in Ihrem Team noch zur Debatte, ob Scraping bei Ops oder Engineering liegt, starten Sie zuerst mit einem KI- oder No-Code-Tool. Sie lernen schneller, was wirklich zählt, wenn Sie reale Jobs ausführen – statt den Stack von Anfang an zu überkonstruieren.
Die besten KI-Web-Scraper für Business-Teams
Diese Tools würde ich zuerst testen, wenn das Wunschergebnis tabellenfertige Daten sind – bei möglichst wenig Setup.
1. Thunderbit
Thunderbit ist hier die einfachste Option, sobald Ihr Team strukturierte Daten extrahieren will, ohne sich Selektoren, Browser-Scripting oder Scraping-Infrastruktur anzueignen. Der Workflow basiert auf KI-Feldvorschlägen, Unterseiten-Anreicherung und dem direkten Export in die Tools, in denen Business-Anwender ohnehin arbeiten.
- Am besten für: Vertrieb, Ops, E-Commerce, Immobilien und andere browserlastige Teams.
- Warum es heraussticht: Es drückt die Einrichtungszeit für Nicht-Programmierer stärker als alles andere auf dieser Liste.
- Zu beachten: Wer tiefgreifende Custom-Crawler-Logik oder hochspezialisierte Engineering-Kontrolle braucht, geht irgendwann tiefer in den Stack.
- Preismodell: kostenloser Tarif, Self-Service-Paid-Pläne und Business-Preise.
Wer vor dem Tool-Vergleich den schnellsten realen Workflow sehen will, holt sich aus diesem Walkthrough den passenden Einstieg:
2. Browse AI
Browse AI bleibt eine starke Wahl für Business-Nutzer, die Point-and-Click-Setup plus wiederkehrendes Monitoring wollen. Das Robotermodell ist besonders nützlich, wenn Scraping und Änderungsdetektion gleich wichtig wiegen.
- Am besten für: Preisseiten, Wettbewerberseiten und wiederholbare Listenextraktion.
- Warum es heraussticht: poliertes Onboarding, vorgefertigte Robots und ein klarer Pfad von der Website zur Tabelle oder API-ähnlichen Ausgabe.
- Zu beachten: Komplexe, hochvolumige Jobs können schneller teuer oder operativ umständlich werden – schneller als bei API-first-Stacks.
- Preismodell: kostenloser Plan, kostenpflichtige Pläne, Premium-/Managed-Tier.
3. Bardeen
Bardeen überzeugt am meisten, wenn Scraping nur eine Aktion in einem größeren Browser-Automatisierungsfluss ist. Sobald Sie Daten in CRMs, Tabellen oder Outbound-Workflows verschieben, wiegt der Automatisierungsaspekt mehr als reine Scraping-Tiefe.
- Am besten für: Revenue Ops, Lead-Workflows und browsernative Aufgabenautomatisierung.
- Warum es heraussticht: stärkere Workflow-Automatisierungs-Story als reine Extraktions-Tools.
- Zu beachten: Nicht die sauberste Lösung, wenn das Scraping selbst komplex und geschäftskritisch ist.
- Preismodell: kostenloser Plan und kostenpflichtige Pläne.
4. Diffbot
Diffbot richtet sich an Teams, die KI-Extraktion in Enterprise-Größe brauchen – nicht an Nutzer, die den billigsten oder einfachsten Weg suchen. Es spielt seine Stärken aus, wenn Datenqualität und großskalige Aufnahme wichtiger sind als praktische Kontrolle.
- Am besten für: Enterprise-Datenteams, Content Intelligence und große Extraktionsprogramme.
- Warum es heraussticht: computer-vision-ähnliche Extraktion und starke Ausrichtung auf strukturierte Ausgaben.
- Zu beachten: Für kleine Teams überdimensioniert und unpraktisch, wenn Ihr Use Case leichtgewichtig ist.
- Preismodell: Enterprise-Tarife und individueller Vertriebsprozess.
5. Instant Data Scraper
Instant Data Scraper verdient seinen Platz nach wie vor, weil es viele Situationen gibt, in denen Sie schlicht sofort die sichtbare Tabelle, das Verzeichnis oder die Liste brauchen. Keine Plattform – aber oft ausreichend.
- Am besten für: Einmal-Extraktion, schnelle Lead-Listen, einfache Verzeichnisse und sichtbare Tabellen.
- Warum es heraussticht: auf den passenden Seiten fast keine Hürden.
- Zu beachten: begrenzte Automatisierung, begrenzte Tiefe und nur schwacher Fit für anspruchsvolle Workflows.
- Preismodell: kostenlos.
Die besten No-Code-Web-Scraping-Tools für wiederholbare Jobs
Sobald der Job mehr ist als gelegentliches Scraping, werden visuelle Builder und Cloud-Ausführung wichtig.
6. Octoparse
Octoparse bleibt eine der stärksten No-Code-Plattformen, sobald Sie Cloud-Läufe, Vorlagenabdeckung und anspruchsvolleres Aufgabenmanagement brauchen, als eine Browser-Erweiterung leistet.
- Am besten für: Analysten, Preisteams und Operatoren mit wiederkehrenden Erfassungsjobs.
- Warum es heraussticht: ausgereifter Task-Builder, Cloud-Extraktion, Anti-Blocking-Funktionen und ein großes Vorlagen-Ökosystem.
- Zu beachten: Leistungsfähiger als KI-First-Browser-Tools – bedeutet aber auch mehr Setup-Aufwand.
- Preismodell: kostenloser Plan, kostenpflichtig ab 69 $/Monat, Enterprise individuell.
7. ParseHub
ParseHub bleibt relevant für Nutzer, die mehr Kontrolle als bei einem KI-Scraper wollen, aber keine eigene Codebasis bauen möchten. Belohnt wird Geduld, nicht Tempo.
- Am besten für: Analysten und technisch neugierige Operatoren, die eine steilere Lernkurve akzeptieren.
- Warum es heraussticht: flexible Navigationslogik und mehr Kontrolle als leichte Browser-Tools.
- Zu beachten: Produktgefühl wirkt schwerer als bei neueren Anbietern – besonders für schnelllebige Business-Teams.
- Preismodell: kostenloser Plan und kostenpflichtige Pläne.
8. Web Scraper
Web Scraper bleibt ein sinnvoller Einstiegspunkt, wenn Ihnen das Sitemap-Modell gefällt und Sie etwas wollen, das im Browser beginnt und später in geplante Cloud-Läufe hineinwächst.
- Am besten für: Einsteiger:innen, Hobbyprojekte und kleinere wiederholbare Jobs.
- Warum es heraussticht: zugänglicher Sitemap-Workflow und einfache Browser-First-Einführung.
- Zu beachten: Stößt schnell an Grenzen, sobald Sie anpassungsfähigere Extraktionslogik brauchen.
- Preismodell: kostenlose Browser-Erweiterung und kostenpflichtige Cloud-Pläne.
9. Data Miner
Data Miner versteht sich am besten als schnelles Extraktions-Tool – nicht als vollständige Scraping-Plattform. Trotzdem einen Platz wert, weil rezeptbasiertes Arbeiten für viele Recherche- und Prospecting-Aufgaben praktisch ist.
- Am besten für: Forscher:innen, Growth-Teams und schnelle Exporte direkt im Browser.
- Warum es heraussticht: Rezeptmodell, geringe Hürden und einfacher Browser-Export.
- Zu beachten: Nicht das richtige Tool für ernsthaftes Scraping auf Plattform-Niveau.
- Preismodell: kostenloser Plan und kostenpflichtige Pläne.
Die besten API-Plattformen, sobald Skalierung und Blockaden zum echten Problem werden
Auf dieser Ebene fragt sich Engineering nicht mehr „Wie scrape ich diese Seite?", sondern „Wie halte ich das bei Volumen zuverlässig?".
10. Apify
Apify ist in dieser Gruppe die flexibelste Plattform, wenn Sie sowohl einen Marktplatz für wiederverwendbare Scraper als auch einen Ort für eigenen Code wollen. Es überbrückt No-Code-Entdeckung und Entwickler-Ausführung besser als die meisten Wettbewerber.
- Am besten für: hybride Teams, developer-led Scraping und wiederverwendbare Automatisierungs-Workflows.
- Warum es heraussticht: Actor-Ökosystem plus eigene Laufzeit liefern eine ungewöhnliche Bandbreite.
- Zu beachten: Sobald Sie auf Custom gehen, sind Sie zurück in der Engineering-Welt, und der Einfachheitsvorteil schmilzt.
- Preismodell: kostenloser Plan, Starter ab 29 $/Monat plus Nutzung, größere Nutzungstarife und Enterprise.
11. ScrapingBee
ScrapingBee ist die gute Wahl, wenn Ihr echter Bedarf lautet: „Gib mir eine gerenderte Seite und nimm mir die hässliche Infrastruktur ab." Passt gut zu JS-lastigen Zielen.
- Am besten für: Entwickler:innen, die dynamische Seiten scrapen und wenig Lust auf Infrastrukturarbeit haben.
- Warum es heraussticht: einfache API rund um Rendering, Proxies und Browserautomatisierung.
- Zu beachten: Ein Infrastrukturdienst – Parsing, Retry-Logik und Datenqualität bleiben Ihre Aufgabe.
- Preismodell: Testphase und kostenpflichtige Pläne.
12. ScraperAPI
ScraperAPI bleibt einer der einfachsten Wege, Proxy-Management und Erfolgsraten von Requests auszulagern, wenn Sie schnell skalieren wollen.
- Am besten für: Entwickler:innen, die zügig vom Prototyp ins Volumen müssen.
- Warum es heraussticht: unkomplizierte API, Test-Credits, strukturierte Produkte und Skalierungsstufen.
- Zu beachten: Wie alle API-first-Produkte nimmt es Ihnen Parsing und Datenvalidierung nicht ab.
- Preismodell: 7-Tage-Test mit 5.000 Credits, kostenpflichtig ab 49 $/Monat.
13. Bright Data
Bright Data ist die Schwergewicht-Option, sobald Unblocking-Fähigkeit, Proxy-Inventar und Managed Acquisition wichtiger sind als Tool-Einfachheit.
- Am besten für: Enterprise-Programme, compliance-sensible großskalige Erfassung und Managed Data Acquisition.
- Warum es heraussticht: Breite an Proxy-, Scraper-, Browser- und Dataset-Produkten.
- Zu beachten: Teuer und leicht überdimensioniert, wenn Ihr Kernworkflow noch relativ einfach ist.
- Preismodell: nutzungsbasierte und produktbasierte Preise über APIs, Proxies und Managed Services hinweg.
14. Oxylabs
Oxylabs bleibt eine starke Wahl für Teams, die Scraping als Infrastruktur einkaufen – und nicht als Browser-Tool. Besonders relevant, wenn Zuverlässigkeit und Beschaffungsreife wichtig sind.
- Am besten für: Enterprise-Erfassung, Preisüberwachung, SEO-Monitoring und Marktforschung.
- Warum es heraussticht: robuste Infrastruktur-Story, tiefe Proxy-Abdeckung und ein klarerer Enterprise-Einkaufsprozess.
- Zu beachten: Nicht ideal, wenn Ihr Team einen lockeren Self-Service-Workflow will.
- Preismodell: Web Scraper API ab 49 $/Monat; andere Produkte variieren je Einheit und Nutzung.
15. Zyte
Zyte verdient weiterhin ernsthafte Beachtung von Entwickler- und Datenteams, die Anti-Detection, Browser-Aktionen, JS-Rendering und rotierende IPs hinter einer einzigen API-first-Story wollen.
- Am besten für: technische Teams, die wiederholbare Extraktionssysteme bauen.
- Warum es heraussticht: Browser-Aktionen, JS-Rendering, IP-Rotation und Anti-Bot-Ansatz in einem Stack.
- Zu beachten: Besser für Teams mit Engineering-Verantwortung als für nicht-technische Operatoren.
- Preismodell: Test mit 5 $ Gratisguthaben und nutzungsbasierten monatlichen Zusagen.
Die besten Open-Source-Bibliotheken für Entwickler:innen, die volle Kontrolle wollen
Wer den Scraper-Stack end-to-end selbst besitzen will, findet 2026 hier die nützlichsten Bausteine.
16. Selenium
Selenium bleibt nützlich, wenn Sie QA-ähnliche Interaktionsgenauigkeit, Legacy-Browserautomatisierung oder sehr explizite Kontrolle über Nutzerabläufe brauchen.
- Am besten für: interaktionslastige Automatisierung, QA-Überschneidungen und Seiten, bei denen Browserverhalten wichtiger ist als Crawl-Durchsatz.
- Warum es heraussticht: ausgereiftes Ökosystem und breite Browser-Unterstützung.
- Zu beachten: Für viele Scraping-Workloads schwerer und langsamer als neuere Browser-Tools.
- Preismodell: kostenlos und Open Source.
17. BeautifulSoup4

BeautifulSoup ist keine vollständige Scraping-Plattform – bleibt aber einer der einfachsten Wege, chaotisches HTML in leichten Workflows zu parsen.
- Am besten für: Einsteiger:innen, schnelle Skripte und parserorientierte Aufgaben.
- Warum es heraussticht: einfache API und geringe kognitive Last.
- Zu beachten: Kombinieren Sie es mit Request-, Browser- oder Crawler-Tools – allein bleibt es nur ein Parser.
- Preismodell: kostenlos und Open Source.
18. Scrapy
Scrapy ist nach wie vor die beste Antwort, sobald Sie ein echtes Crawling-Framework brauchen statt einer Handvoll Skripte.
- Am besten für: produktive Custom-Crawler und intern verantwortete Datenpipelines.
- Warum es heraussticht: hohe Leistung, Pipelines, Middleware und langfristige Erweiterbarkeit.
- Zu beachten: Echter Engineering-Aufwand – JS-lastige Ziele brauchen oft Begleit-Tools.
- Preismodell: kostenlos und Open Source.
19. Puppeteer
Puppeteer passt nach wie vor gut zu Node-first-Teams, die direkte Kontrolle über Chromium und Browser-Skripting wollen.
- Am besten für: Node-basiertes Scraping, Screenshots und Browserautomatisierungs-Aufgaben.
- Warum es heraussticht: direkte, leistungsstarke Kontrolle über das Verhalten von Chromium.
- Zu beachten: schmalere Browser-Story als Playwright und bei Skalierung weiterhin ressourcenhungrig.
- Preismodell: kostenlos und Open Source.
20. Playwright
Playwright ist meine Standardempfehlung für moderne Browserautomatisierung, sobald Ihr Team Code schreibt und eine modernere Abstraktion als Selenium möchte.
- Am besten für: moderne Browserautomatisierung, JS-lastige Seiten und Teams mit Anspruch an Developer Experience.
- Warum es heraussticht: starkes Multi-Browser-Modell, zuverlässiges Auto-Waiting und saubere APIs.
- Zu beachten: Browser-Infrastruktur, Parallelisierung, Selector-Drift und Datenvalidierung bleiben Ihre Verantwortung.
- Preismodell: kostenlos und Open Source.
Meine Shortlist nach Teamtyp
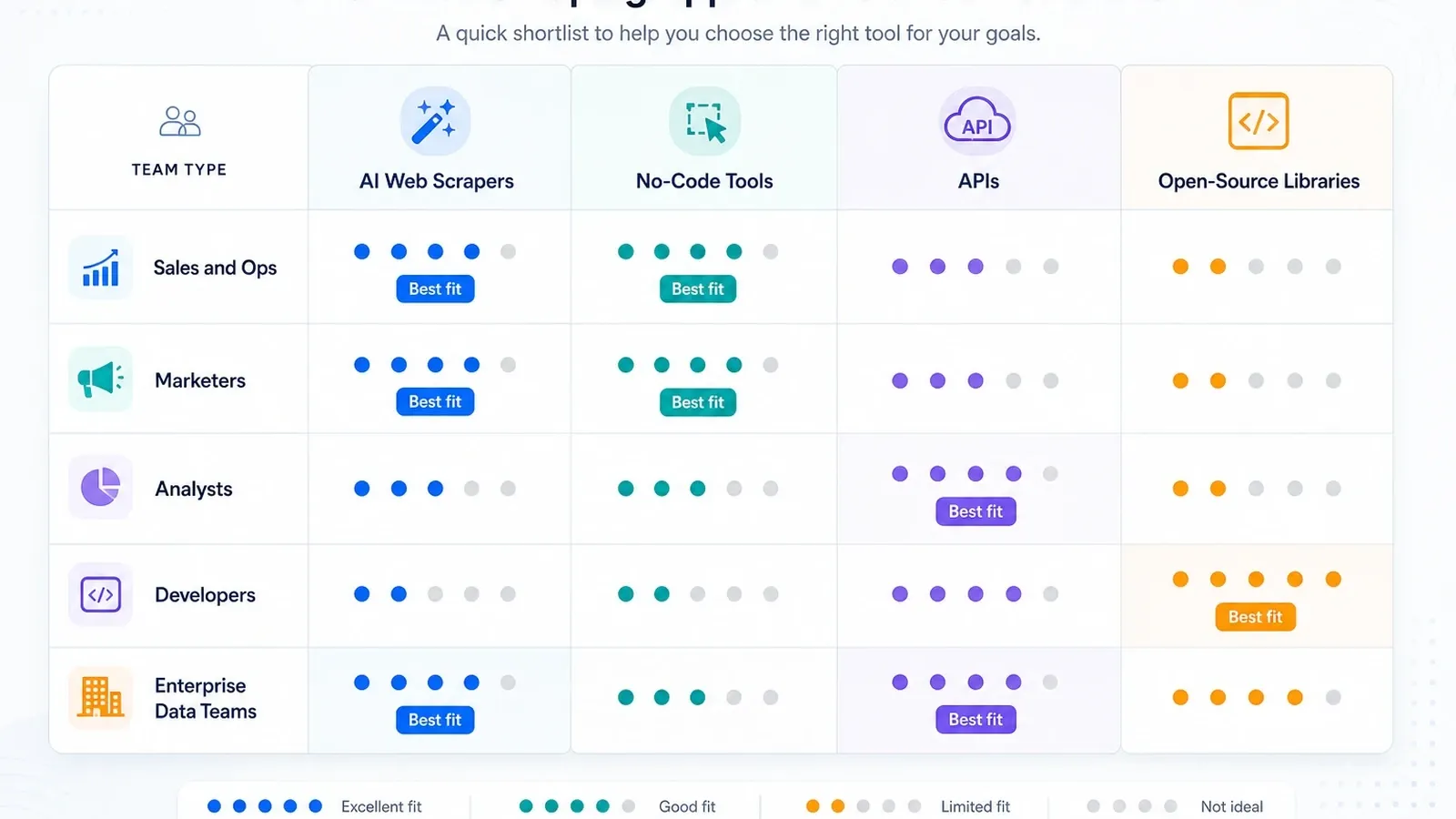
- Sales- und Ops-Teams: Start mit Thunderbit; ergänzend Browse AI, falls Monitoring wichtiger ist als Unterseiten-Anreicherung.
- Analysten- und Research-Teams: zuerst Octoparse, sobald wiederkehrende Jobs größer werden, als Browser-Erweiterungs-Tools bequem bewältigen.
- GTM-Teams mit viel Automatisierung: Bardeen, wenn Scraping nur ein Schritt in einem größeren Workflow ist.
- Entwicklerteams, die interne Tools bauen: Apify, Zyte, ScraperAPI oder Playwright – je nachdem, wie viel Stack-Verantwortung Sie übernehmen wollen.
- Enterprise-Datenprogramme: Bright Data, Oxylabs, Diffbot und Zyte sind die relevanten Infrastrukturgespräche.
Wann Sie tiefer in den Stack gehen sollten
Halten Sie sich an diese Regel:
- Bleiben Sie bei KI-Tools, bis Sie an Grenzen bei Wiederholbarkeit oder Sonderfällen stoßen.
- Wechseln Sie auf No-Code-Tools, sobald Zeitplanung, Paginierung, Anti-Blocking oder Cloud-Läufe schwerer wiegen als One-Click-Einfachheit.
- Wechseln Sie auf APIs, sobald Unblock-Rate, JS-Rendering und Parallelität zu den echten Engpässen werden.
- Wechseln Sie auf Open-Source-Bibliotheken, sobald die Kosten der Anbieter-Abstraktion die Kosten übersteigen, den gesamten Stack selbst zu besitzen.
Die meisten Teams rücken zu früh tiefer in den Stack. Das ist einer der häufigsten Fehler, den ich sehe.
Fazit
Für die meisten nicht-technischen Teams ist 2026 die richtige Antwort nicht „der leistungsstärkste Scraper". Es ist das Tool, das saubere Daten mit dem geringsten Wartungsaufwand in den nächsten Workflow bringt. Deshalb gewinnen KI-first-Tools weiterhin bei Operatoren, während APIs und Open-Source-Stacks besser zu technischen Teams mit klaren Skalierungsanforderungen passen.
Wer den kürzesten Weg von der Seite zur strukturierten Ausgabe will, startet mit Thunderbit. Wer weiß, dass der Job schwere Infrastruktur braucht, springt direkt in die API- und Developer-Ebene. Nur eines bitte nicht: Komplexität mit Raffinesse verwechseln.
FAQs
1. Was ist 2026 das beste Web-Scraping-Tool für nicht-technische Nutzer:innen?
Für die meisten nicht-technischen Nutzer:innen liefern KI-first-Tools wie Thunderbit und Browse AI den schnellsten Weg zu brauchbaren Daten – sie reduzieren Selektoren-Arbeit, Einrichtungs- und Wartungsaufwand.
2. Was wähle ich, wenn meine Seiten stark JavaScript-lastig sind oder Anfragen aggressiv blockieren?
Gehen Sie in Richtung ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright oder Selenium – je nachdem, ob Sie einen Managed Service oder direkte Engineering-Kontrolle wollen.
3. Sind No-Code-Tools noch relevant, jetzt wo KI-Web-Scraper besser werden?
Ja. No-Code-Tools wie Octoparse und ParseHub bleiben wichtig, sobald Sie mehr explizite Kontrolle über Aufgabenlogik, Cloud-Ausführung und wiederholbares Job-Management brauchen.
4. Welche Tools passen am besten zu Engineering-Teams?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer und Selenium sind die natürlichsten Optionen, sobald Entwickler:innen den Workflow verantworten.
5. Wie erstelle ich schnell eine Shortlist, statt zu viel zu recherchieren?
Wählen Sie zuerst den Tool-Typ, nicht den Anbieter. Entscheiden Sie, ob Sie KI-Einfachheit, No-Code-Kontrolle, API-Infrastruktur oder Open-Source-Eigentum brauchen – und vergleichen Sie dann die Produkte innerhalb dieser Ebene.
Weiterführende Lektüre