„Man kann Daten ohne Informationen haben, aber man kann keine Informationen ohne Daten haben.“ — *
Schätzungen zufolge gibt es im Internet inzwischen über Websites, und täglich kommen rund 2 Millionen neue Beiträge dazu. In diesem riesigen Datenmeer stecken wertvolle Erkenntnisse für bessere Entscheidungen — allerdings gibt es einen Haken: Etwa davon sind unstrukturiert und müssen erst aufbereitet werden, bevor sie wirklich nutzbar sind. Genau hier kommen Web-Scraping-Tools ins Spiel; sie sind unverzichtbar für alle, die Online-Daten erschließen möchten.
Wenn du neu im Web-Scraping bist, klingen Begriffe wie und vielleicht erst einmal abschreckend. Doch im Zeitalter der KI lassen sich diese Hürden deutlich leichter nehmen. Moderne KI-gestützte Scraping-Tools helfen dir beim Einstieg, ohne dass du tiefes technisches Wissen brauchst. Damit kannst du Daten schnell sammeln und verarbeiten — ganz ohne Programmierkenntnisse.
Die besten Web-Scraping-Tools und Software
- für einen einfach zu bedienenden KI-Web-Scraper mit den besten Ergebnissen
- für Echtzeit-Monitoring und Massenextraktion von Daten
- für No-Code-Automatisierung mit umfangreichen App-Integrationen
- für visuelles Web-Scraping auf professionellerem Niveau
- für leistungsstarkes No-Code-Scraping mit Schutz vor IP-Sperren und Bot-Erkennung
- für eine fortschrittliche KI-gestützte Data-Extraction-API und Knowledge Graphs
Probier KI fürs Web-Scraping aus
Probier’s aus! Du kannst klicken, erkunden und den Workflow live mitverfolgen.
Wie funktioniert Web-Scraping?
Beim Web-Scraping geht es darum, Daten von Websites zu extrahieren. Du gibst einem Tool eine Reihe von Anweisungen, und es zieht dann Text, Bilder oder was auch immer du brauchst aus einer Webseite in eine Tabelle. Das ist nützlich für alles Mögliche — von der Preisverfolgung auf E-Commerce-Seiten bis hin zum Sammeln von Forschungsdaten oder dem Aufbau einer sauberen Excel-Tabelle oder Google-Sheets-Datei.
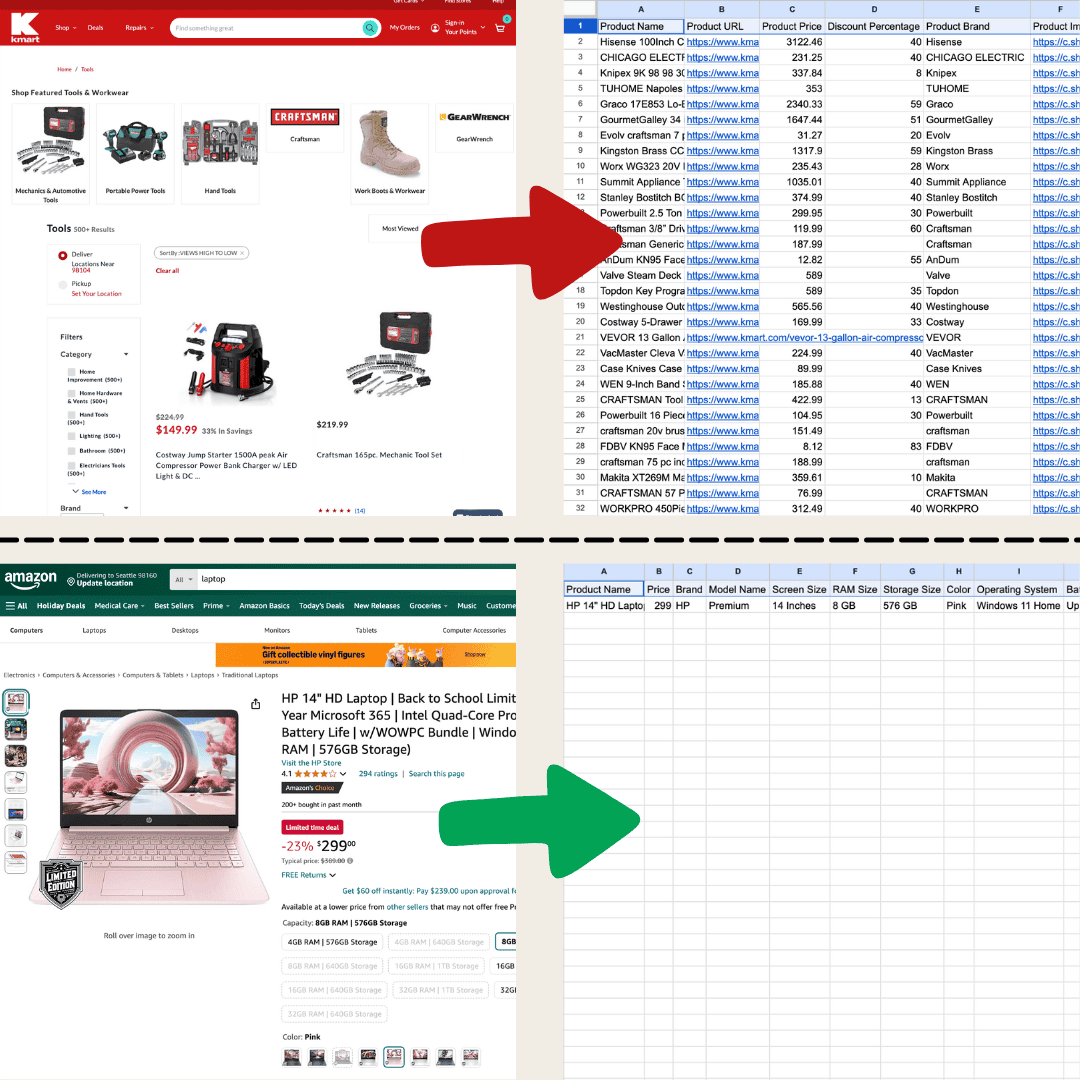 Ich habe das mit Thunderbit mithilfe des KI-Web-Scrapers erstellt.
Ich habe das mit Thunderbit mithilfe des KI-Web-Scrapers erstellt.
Es gibt mehrere Wege, das zu machen. Ganz simpel könntest du alles manuell per Copy-and-paste übernehmen — aber bei großen Datenmengen ist das ziemlich mühsam. Deshalb nutzen die meisten Menschen eine von drei Methoden: klassische Web-Scraper, KI-Web-Scraper oder individuellen Code.
Klassische Web-Scraper arbeiten mit festen Regeln, die festlegen, welche Daten anhand der Seitenstruktur erfasst werden sollen. Du kannst zum Beispiel einstellen, dass Produktnamen oder Preise aus bestimmten HTML-Tags gezogen werden. Sie funktionieren am besten auf Websites, die sich nicht ständig ändern, denn schon kleine Layout-Anpassungen bedeuten, dass du deinen Scraper neu anpassen musst.
 Einen klassischen Scraper zu lernen dauert lange, und für die Einrichtung brauchst du wahrscheinlich Dutzende Klicks.
Einen klassischen Scraper zu lernen dauert lange, und für die Einrichtung brauchst du wahrscheinlich Dutzende Klicks.
KI-Web-Scraper bedeuten im Grunde: ChatGPT liest die gesamte Website und extrahiert dann die Inhalte auf Basis deiner Anforderungen. Dabei kann es Datenerfassung, Übersetzung und Zusammenfassung gleichzeitig übernehmen. Sie nutzen Natural Language Processing, um das Layout der Website zu analysieren und zu verstehen. Dadurch kommen sie mit Änderungen an einer Website meist deutlich besser klar. Wenn eine Seite ihre Abschnitte etwas umstellt, kann sich ein KI-Web-Scraper oft anpassen, ohne dass du etwas neu schreiben musst. Deshalb sind sie ideal für wartungsintensive Seiten oder für Seiten mit komplexeren Strukturen.
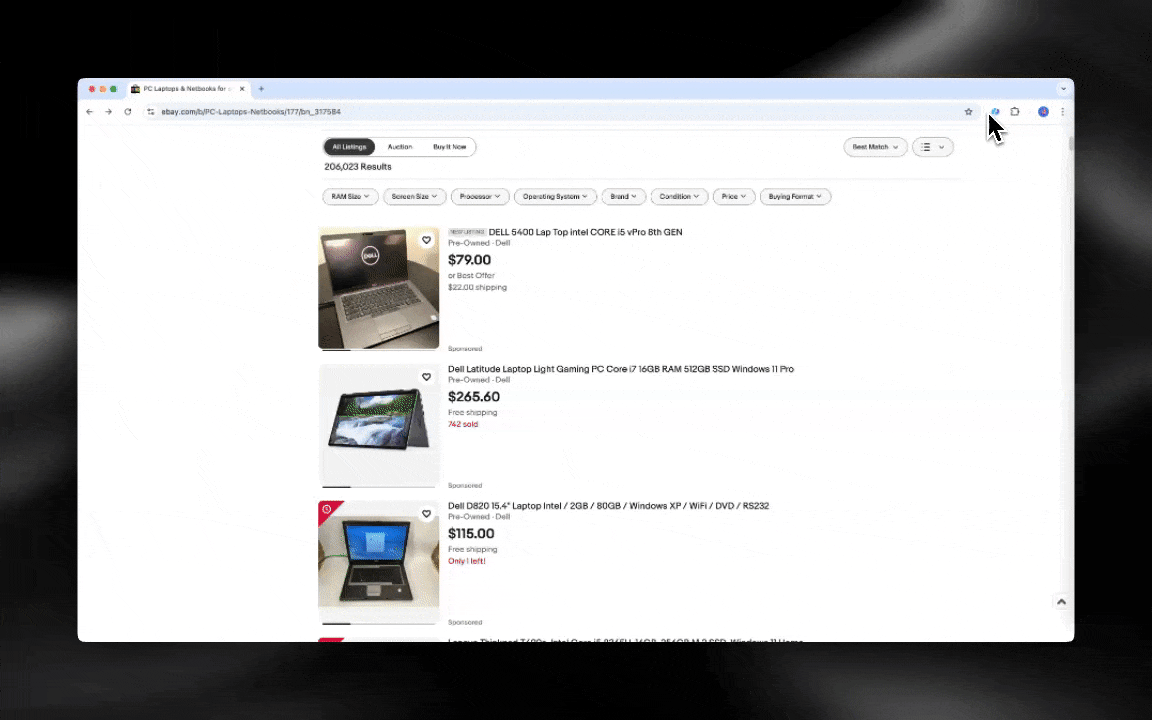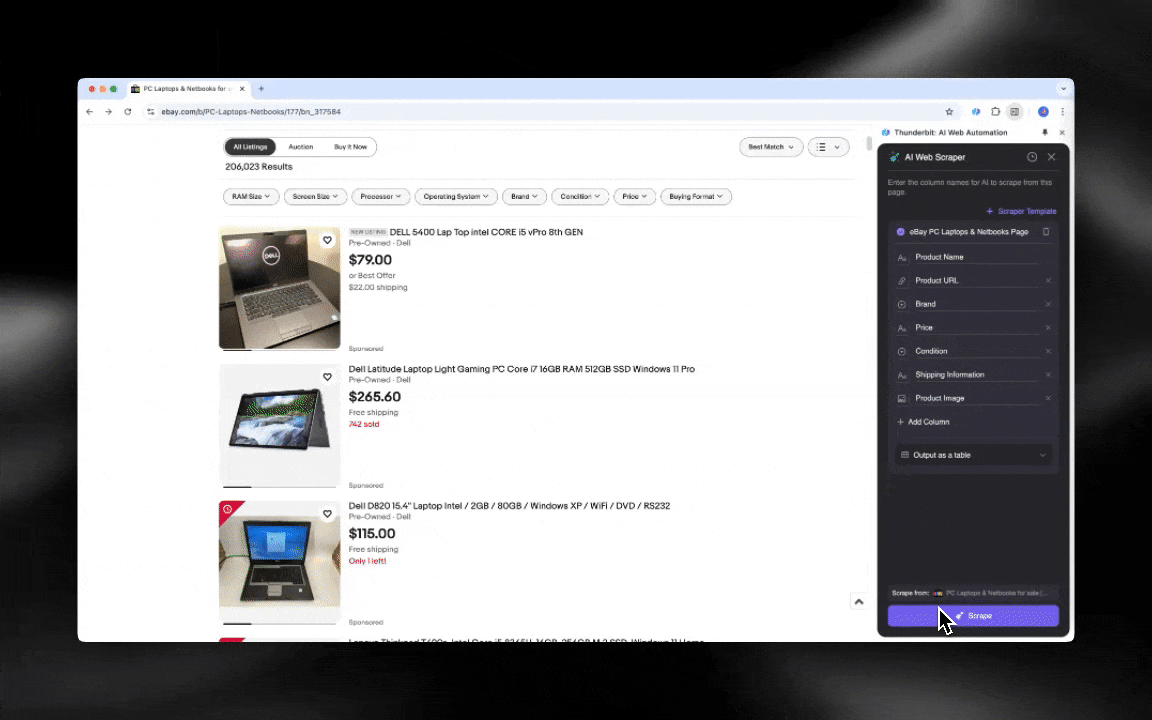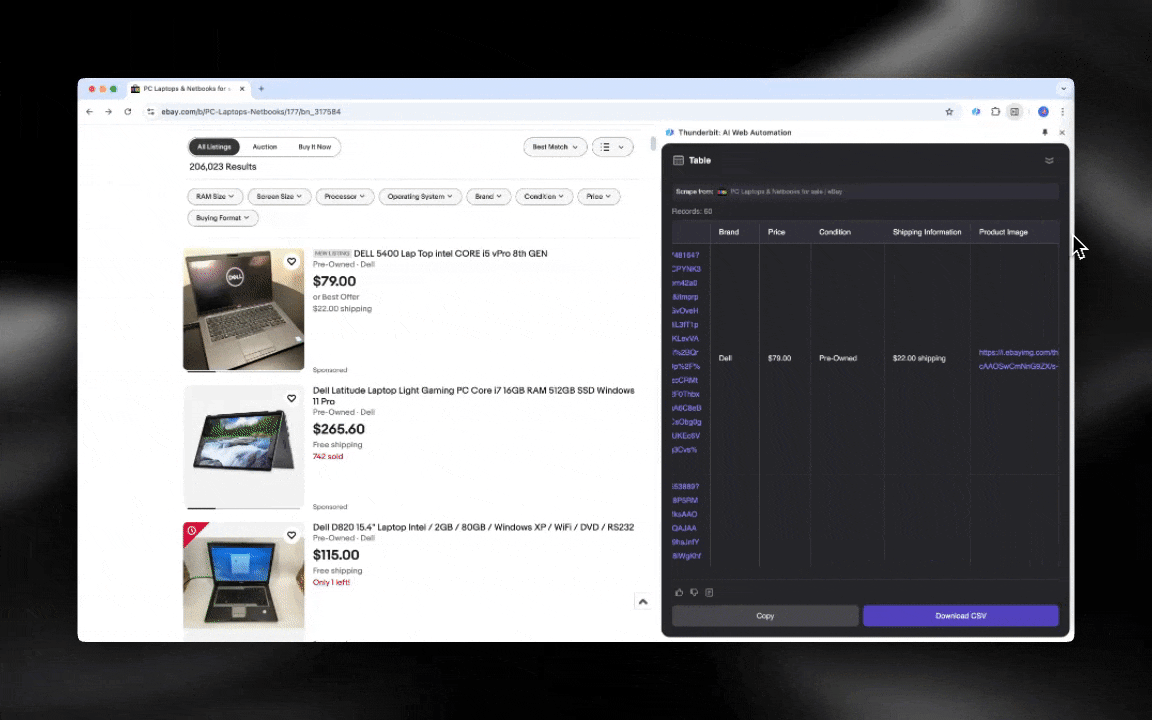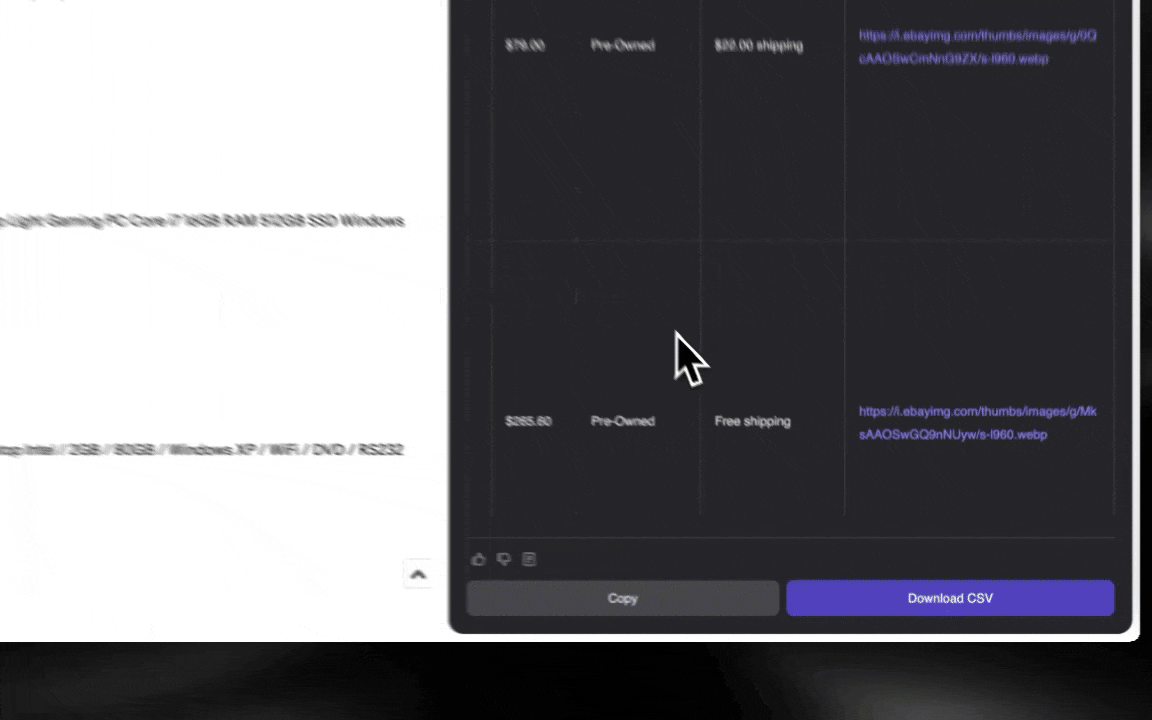 Der KI-Web-Scraper ist leicht einzurichten und liefert dir mit nur wenigen Klicks detaillierte Daten!
Der KI-Web-Scraper ist leicht einzurichten und liefert dir mit nur wenigen Klicks detaillierte Daten!
Welchen solltest du wählen? Das hängt davon ab. Wenn du gern mit Code arbeitest oder große Datenmengen von einer bekannten Website erfassen musst, können klassische Scraper sehr effizient sein. Wenn du aber neu im Web-Scraping bist oder etwas suchst, das mit Website-Updates gut mithält, sind KI-Web-Scraper meist die bessere Wahl. Schau dir die Tabelle unten für genauere Szenarien an!
| Szenario | Beste Wahl |
|---|---|
| Leichtgewichtiges Scraping auf Seiten wie Verzeichnissen, Shopping-Websites oder jeder Website mit einer Liste | KI-Web-Scraper |
| Die Seite enthält weniger als 200 Datenzeilen, und das Erstellen eines Scrapers mit einem klassischen Web-Scraper dauert zu lange | KI-Web-Scraper |
| Die Daten, die du scrapen möchtest, müssen in einem bestimmten Format vorliegen, um woanders hochgeladen werden zu können. Zum Beispiel: Kontaktdaten scrapen, um sie in HubSpot hochzuladen. | KI-Web-Scraper |
| Weit verbreitete Websites in großem Umfang, etwa zehntausende Amazon-Produktseiten oder Zillow-Immobilienangebote. | Klassischer Web-Scraper |
Die besten Web-Scraping-Tools und Software im Überblick
| Tool | Preis | Wichtige Funktionen | Vorteile | Nachteile |
|---|---|---|---|---|
| Thunderbit | Ab 9 $/Monat, kostenlose Stufe verfügbar | KI-Web-Scraper, erkennt und formatiert Daten automatisch, unterstützt mehrere Formate, Export mit einem Klick, benutzerfreundliche Oberfläche. | Kein Code nötig, KI-Unterstützung, Integrationen mit Apps wie Google Sheets | Scraping im großen Stil kann langsam sein, erweiterte Funktionen können mehr kosten |
| Browse AI | Ab 48,75 $/Monat, kostenlose Stufe verfügbar | No-Code-Oberfläche, Echtzeit-Monitoring, Massenextraktion von Daten, Workflow-Integration. | Benutzerfreundlich, integriert sich mit Google Sheets und Zapier | Komplexe Seiten brauchen zusätzliche Einrichtung, Bulk-Scraping kann zu Timeouts führen |
| Bardeen AI | Ab 60 $/Monat, kostenlose Stufe verfügbar | No-Code-Automatisierung, Integration mit über 130 Apps, MagicBox wandelt Aufgaben in Workflows um. | Umfangreiche Integrationen, skalierbar für Unternehmen | Steile Lernkurve für neue Nutzer, aufwendige Einrichtung |
| Web Scraper | Kostenlos lokal nutzbar, 50 $/Monat für die Cloud | Visuelle Erstellung von Aufgaben, unterstützt dynamische Seiten (AJAX/JavaScript), Cloud-Scraping. | Funktioniert gut mit dynamischen Seiten | Für die beste Einrichtung sind technische Kenntnisse nötig |
| Octoparse | Ab 119 $/Monat, kostenlose Stufe verfügbar | No-Code-Scraping, automatische Erkennung von Seitenelementen, Cloud-Scraping mit geplanten Aufgaben, Vorlagenbibliothek für gängige Websites. | Leistungsstark bei dynamischen Seiten, kommt mit Einschränkungen zurecht | Komplexe Seiten erfordern Einarbeitung |
| Diffbot | Ab 299 $/Monat | Data-Extraction-API, API ohne Regeln, NLP für unstrukturierten Text, umfangreicher Knowledge Graph. | Starke KI-Extraktion, umfangreiche API-Integration, Scraping im großen Maßstab | Lernkurve für nichttechnische Nutzer, Einrichtungszeit |
Der beste Web-Scraper im KI-Zeitalter
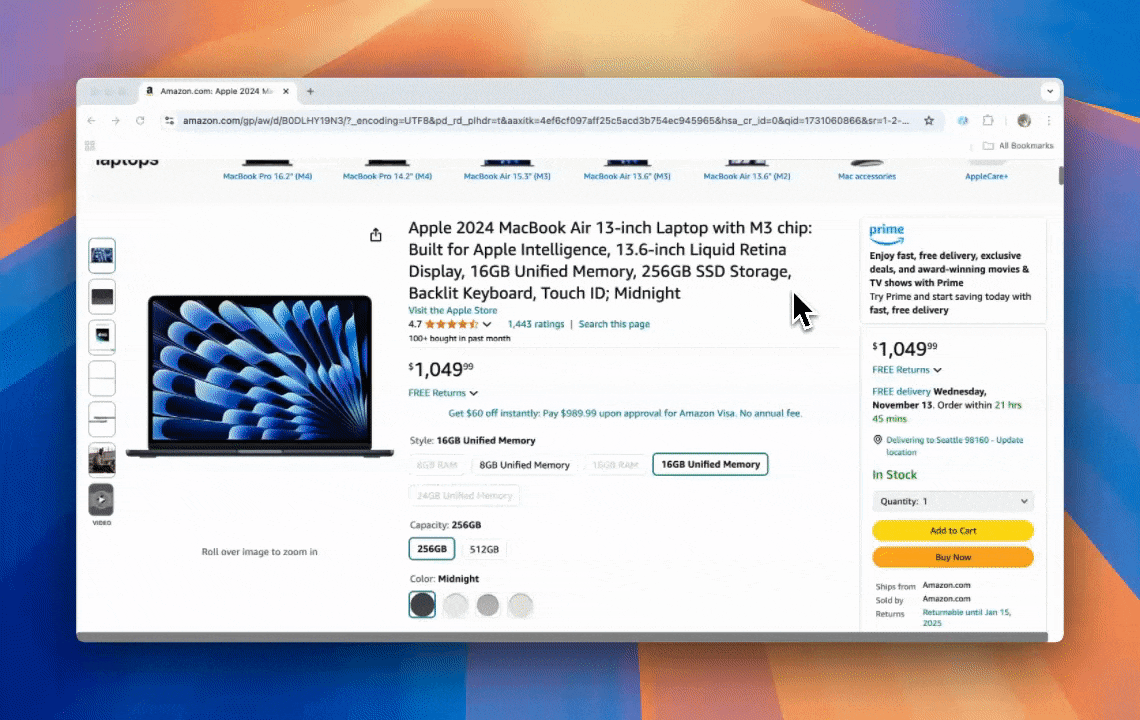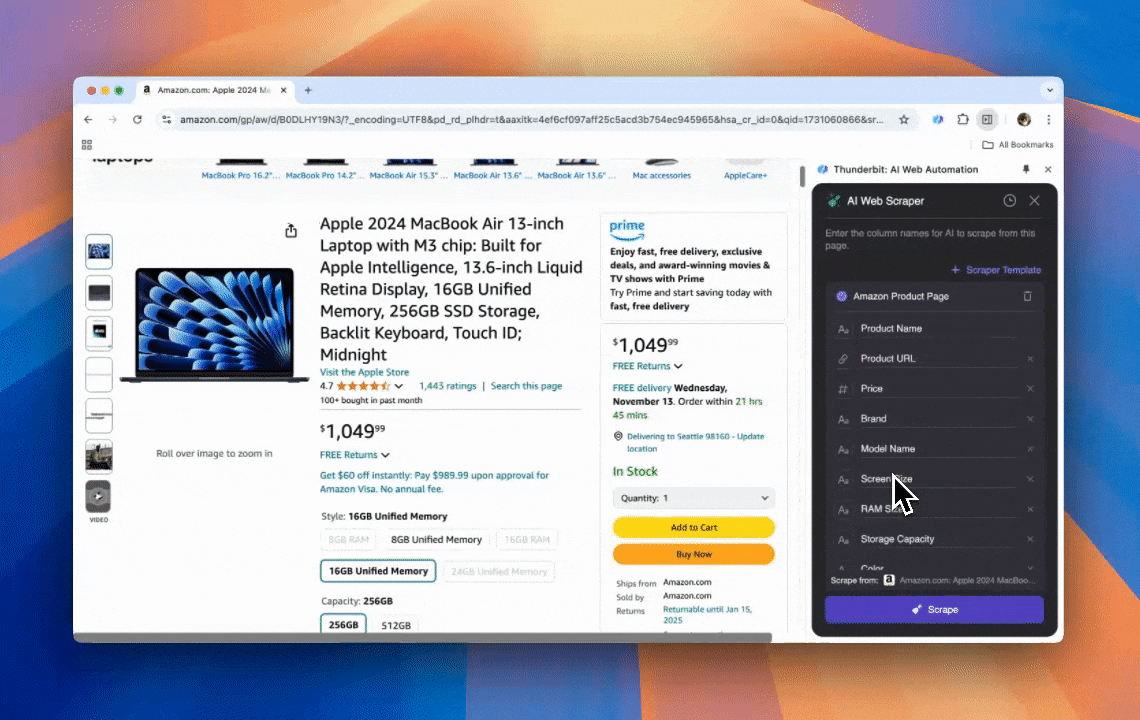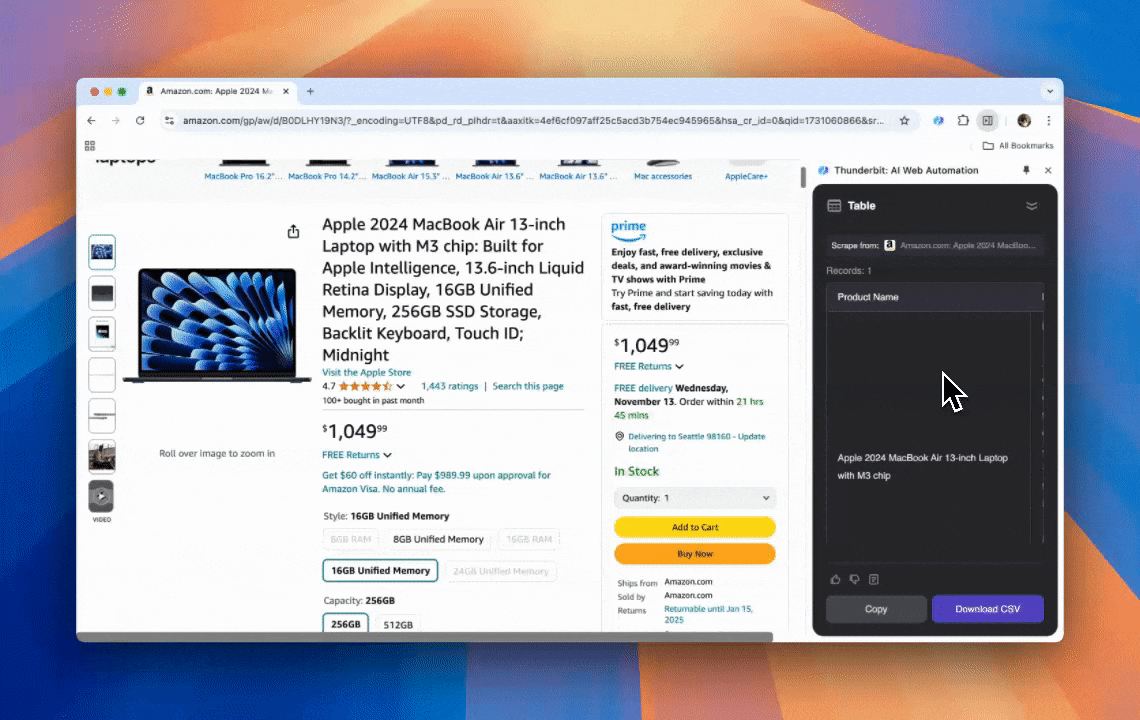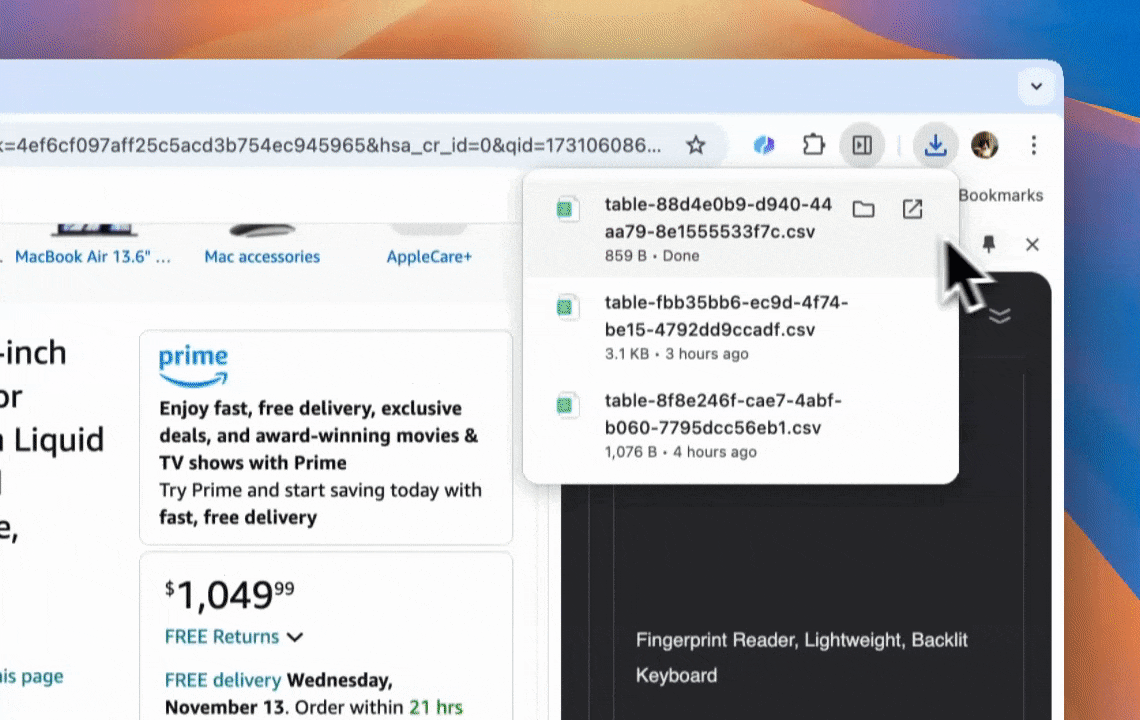
Thunderbit ist ein leistungsstarkes und zugleich einfach zu bedienendes KI-Web-Automatisierungstool, mit dem auch Nutzer ohne Programmierkenntnisse Daten leicht extrahieren und organisieren können. Mit der macht Thunderbits das Datenscraping deutlich einfacher — Nutzer können Webdaten schnell extrahieren, ohne manuell mit Web-Elementen zu arbeiten oder für unterschiedliche Seitenlayouts eigene Scraper einzurichten.
Wichtige Funktionen
- KI-gestützte Flexibilität: Thunderbits KI-Web-Scraper erkennt und formatiert Webdaten automatisch; CSS-Selektoren sind nicht nötig.
- Die einfachste Scraping-Erfahrung: Du musst nur auf „KI-Spalte vorschlagen“ klicken und dann auf der Seite, von der du Daten extrahieren willst, auf „Scrapen“ klicken. Das war’s.
- Unterstützung für verschiedene Datenformate: Thunderbit kann URLs und Bilder scrapen und erfasste Daten in mehreren Formaten anzeigen.
- Automatisierte Datenverarbeitung: Die KI von Thunderbit kann Daten unterwegs umformatieren, einschließlich Zusammenfassen, Kategorisieren und Übersetzen ins benötigte Format.
- Einfacher Datenexport: Daten mit einem Klick nach Google Sheets, Airtable oder Notion exportieren und so die Datenverwaltung vereinfachen.
- Benutzerfreundliche Oberfläche: Eine intuitive Oberfläche macht das Tool für Nutzer aller Erfahrungsstufen zugänglich.
Preisgestaltung
Thunderbit bietet gestaffelte Tarife ab 9 $ pro Monat für 5.000 Credits. Nach oben geht es bis 199 $ für 240.000 Credits. Beim Jahresplan erhältst du außerdem alle Credits im Voraus.
Vorteile:
- Starke KI-Unterstützung vereinfacht Datenerfassung und -verarbeitung.
- Kein Code nötig, für Nutzer aller Erfahrungsstufen zugänglich.
- Perfekt für leichtgewichtiges Scraping, etwa für Verzeichnisse, Shopping-Websites usw.
- Hohe Integrationsfähigkeit für direkte Exporte in beliebte Apps.
Nachteile:
- Das Scraping großer Datenmengen kann etwas Zeit brauchen, um Genauigkeit sicherzustellen.
- Für bestimmte erweiterte Funktionen ist möglicherweise ein kostenpflichtiges Abo nötig.
Mehr erfahren? Starte mit der oder entdecke mit Thunderbit.
Bester Web-Scraper für Datenmonitoring und Massenextraktion
Browse AI
Browse AI ist ein robustes No-Code-Tool zum Scrapen von Daten, das Nutzern hilft, Daten ohne Programmierung zu extrahieren und zu überwachen. Browse AI hat einige KI-Funktionen, erreicht aber noch nicht ganz das Niveau eines vollwertigen KI-Scraping-Tools. Trotzdem erleichtert es den Einstieg.
Wichtige Funktionen
- No-Code-Oberfläche: Ermöglicht es Nutzern, mit einfachen Klicks eigene Workflows zu erstellen.
- Echtzeit-Monitoring: Nutzt Bots, um Änderungen an Webseiten zu verfolgen und aktualisierte Informationen bereitzustellen.
- Massenextraktion von Daten: Kann bis zu 50.000 Datensätze in einem Durchgang verarbeiten.
- Workflow-Integration: Verbindet mehrere Bots für komplexere Datenverarbeitung.
Preisgestaltung
Ab 48,75 $ pro Monat, einschließlich 2.000 Credits. Eine kostenlose Stufe ist verfügbar und bietet 50 Credits pro Monat zum Testen der Basisfunktionen.
Vorteile:
- Bietet Integrationen mit Google Sheets und Zapier.
- Vorgefertigte Bots vereinfachen gängige Datenextraktionsaufgaben.
Nachteile:
- Für komplexe Seiten kann zusätzliche Konfiguration nötig sein.
- Die Geschwindigkeit beim Bulk-Scraping kann variieren und gelegentlich zu Timeouts führen.
Bester Web-Scraper für Workflow-Integration
Bardeen AI
Bardeen AI ist ein No-Code-Automatisierungstool, das Workflows durch die Verknüpfung verschiedener Apps optimiert. Zwar nutzt es KI, um individuelle Automatisierungen zu erstellen, doch es fehlt ihm die Anpassungsfähigkeit eines vollwertigen KI-Scraping-Tools.
Wichtige Funktionen
- No-Code-Automatisierung: Nutzer können Workflows per Klick einrichten.
- MagicBox: Beschreibt Aufgaben in einfacher Sprache, die Bardeen AI in Workflows umwandelt.
- Breite Integrationsmöglichkeiten: Lässt sich mit über 130 Apps integrieren, darunter Google Sheets, Slack und LinkedIn.
Preisgestaltung
Ab 60 $ pro Monat, mit 1.500 Credits (etwa 1.500 Datenzeilen). Eine kostenlose Stufe bietet monatlich 100 Credits zum Testen der Basisfunktionen.
Vorteile:
- Umfangreiche Integrationsoptionen unterstützen vielfältige Geschäftsanforderungen.
- Flexibel und skalierbar für Unternehmen jeder Größe.
Nachteile:
- Neue Nutzer brauchen möglicherweise Zeit, um die komplette Plattform zu lernen.
- Die erste Einrichtung kann zeitaufwendig sein.
Bester visueller Web-Scraper für erfahrene Nutzer
Web Scraper
Ja, du hast richtig gehört: Das Tool heißt „Web Scraper“. Web Scraper ist eine beliebte Browser-Erweiterung für Chrome und Firefox, mit der Nutzer ohne Programmierung Daten extrahieren und Scraping-Aufgaben visuell erstellen können. Du musst dir dafür aber vielleicht ein paar Tage lang Tutorials ansehen, um das Tool wirklich zu beherrschen. Wenn du es dir beim Scraping leichter machen willst, nimm den KI-Web-Scraper.
Wichtige Funktionen
- Visuelle Erstellung: Nutzer können Scraping-Aufgaben einrichten, indem sie auf Web-Elemente klicken.
- Unterstützung dynamischer Websites: Kann AJAX-Anfragen und JavaScript für dynamische Seiten verarbeiten.
- Cloud-Scraping: Aufgaben über Web Scraper Cloud für regelmäßiges Scraping planen.
Preisgestaltung
Für die lokale Nutzung kostenlos; kostenpflichtige Tarife beginnen bei 50 $/Monat für Cloud-Funktionen.
Vorteile:
- Funktioniert gut mit dynamischen Seiten.
- Für die lokale Nutzung kostenlos.
Nachteile:
- Für die optimale Einrichtung sind technische Kenntnisse nötig.
- Bei Änderungen sind aufwendige Tests erforderlich.
Bester Web-Scraper gegen IP-Sperren und Bot-Erkennung
Octoparse
Octoparse ist eine vielseitige Software für technisch versiertere Nutzer, mit der sich bestimmte Webdaten ohne Code sammeln und überwachen lassen — ideal für große Datenmengen. Octoparse arbeitet nicht über den Browser des Nutzers, sondern nutzt Cloud-Server für das Scraping. Dadurch kann es verschiedene Methoden einsetzen, um IP-Sperren und bestimmte Bot-Erkennungen von Websites zu umgehen.
Wichtige Funktionen
- No-Code-Betrieb: Nutzer können Scraping-Aufgaben ohne Programmierung erstellen; das ist für verschiedene technische Niveaus zugänglich.
- Intelligente automatische Erkennung: Erkennt Seitendaten automatisch und identifiziert schnell die extrahierbaren Elemente, was die Einrichtung vereinfacht.
- Cloud-Scraping: Unterstützt Cloud-Datenscraping rund um die Uhr mit geplanten Aufgaben für flexible Datenabrufe.
- Umfangreiche Vorlagenbibliothek: Bietet Hunderte voreingestellte Vorlagen, damit Nutzer schnell auf Daten beliebter Websites zugreifen können, ohne komplizierte Einrichtung.
Preisgestaltung
Der Tarif von Octoparse beginnt bei 119 $ pro Monat und umfasst 100 Aufgaben. Eine kostenlose Stufe mit 10 Aufgaben pro Monat ist ebenfalls verfügbar, um die Basisfunktionen zu testen.
Vorteile:
- Leistungsstarke Funktionen unterstützen dynamisches Scraping mit hoher Anpassungsfähigkeit.
- Bietet Lösungen für Scraping-Einschränkungen und Probleme mit dynamischen Inhalten.
Nachteile:
- Komplexe Website-Strukturen können mehr Einrichtungszeit erfordern.
- Neue Nutzer brauchen möglicherweise Zeit, um den Umgang zu lernen.
Bester Web-Scraper für fortschrittliche KI-gestützte Data-Extraction-API
Diffbot
Diffbot ist ein fortschrittliches Tool zur Webdatenextraktion, das KI nutzt, um unstrukturierte Webinhalte in strukturierte Daten zu verwandeln. Mit leistungsstarken APIs und einem Knowledge Graph hilft Diffbot Nutzern dabei, Informationen aus dem Web zu extrahieren, zu analysieren und zu verwalten — geeignet für verschiedene Branchen und Anwendungsfälle.
Wichtige Funktionen
- Data-Extraction-API: Diffbot bietet eine API zur Datenextraktion ohne Regeln, sodass Nutzer einfach eine URL angeben können und die Daten automatisch extrahiert werden; individuelle Regeln pro Website sind nicht nötig.
- Natural-Language-Processing-API: Extrahiert strukturierte Entitäten, Beziehungen und Stimmungen aus unstrukturiertem Text und hilft Nutzern beim Aufbau eigener Knowledge Graphs.
- Knowledge Graph: Diffbot verfügt über einen der größten Knowledge Graphs und verknüpft umfangreiche Entitätsdaten, darunter Details zu Personen und Organisationen.
Preisgestaltung
Der Tarif von Diffbot beginnt bei 299 $ pro Monat und enthält 250.000 Credits, was ungefähr 250.000 API-basierten Webseiten-Extraktionen entspricht.
Vorteile:
- Starke Datenextraktion ohne Regeln mit hoher Anpassungsfähigkeit.
- Umfangreiche API-Integrationsoptionen für die einfache Anbindung an bestehende Systeme.
- Unterstützt Scraping im großen Stil und eignet sich für Enterprise-Anwendungen.
Nachteile:
- Die erste Einrichtung kann für nichttechnische Nutzer etwas Einarbeitungszeit erfordern.
- Zur Nutzung muss ein Programm geschrieben werden, das die API aufruft.
Wofür kannst du Scraper verwenden?
Wenn du neu im Web-Scraping bist, findest du hier ein paar beliebte Anwendungsfälle zum Einstieg. Viele nutzen Scraper, um Amazon-Produktlisten abzurufen, Immobiliendaten von Zillow zu ziehen oder Geschäftsdaten von Google Maps zu sammeln. Aber das ist erst der Anfang — du kannst Thunderbits verwenden, um Daten von fast jeder Website zu erfassen, Aufgaben zu vereinfachen und in deinem Arbeitsalltag Zeit zu sparen. Ob für Recherche, Preisverfolgung oder den Aufbau von Datenbanken: Web-Scraping eröffnet unzählige Möglichkeiten, die Daten des Internets für dich nutzbar zu machen.
FAQs
-
Ist Web-Scraping legal?
Web-Scraping ist in der Regel legal, muss aber die Nutzungsbedingungen der Website und die Art der abgerufenen Daten berücksichtigen. Prüfe immer die relevanten Richtlinien und halte die rechtlichen Vorgaben ein.
-
Brauche ich Programmierkenntnisse, um Web-Scraping-Tools zu nutzen?
Die meisten der hier vorgestellten Tools erfordern keine Programmierkenntnisse, aber bei Tools wie Octoparse und Web Scraper können Grundwissen über Webstrukturen und eine programmatische Denkweise für die optimale Nutzung hilfreich sein.
-
Gibt es kostenlose Web-Scraping-Tools?
Ja, kostenlose Tools wie BeautifulSoup, Scrapy und Web Scraper sind verfügbar, und einige Tools bieten auch kostenlose Tarife mit eingeschränktem Funktionsumfang an.
-
Was sind häufige Herausforderungen beim Web-Scraping?
Zu den häufigen Herausforderungen gehören der Umgang mit dynamischen Inhalten, CAPTCHAs, IP-Sperren und komplexen HTML-Strukturen. Fortgeschrittene Tools und Techniken können diese Probleme effektiv lösen.
Mehr erfahren:
-
Mit KI ohne Aufwand arbeiten.