

Temu zählt inzwischen über 416 Millionen monatlich aktive Nutzer in mehr als 50 Märkten, und der Katalog reicht vom Küchen-Gadget über Haustierzubehör bis zum LED-Streifen. Wer im E-Commerce, im Dropshipping oder in der Wettbewerbsanalyse arbeitet, wollte Temu-Daten vermutlich schon einmal in eine Tabelle ziehen – und musste dann feststellen, dass Temu davon herzlich wenig hält.
Ich habe viel Zeit in die Recherche und das Testen von Scraping-Tools für geschützte E-Commerce-Websites gesteckt, und Temu gehört zu den härtesten Zielen überhaupt. Die meisten Anleitungen im Netz bieten entweder ein Python-Tutorial, das nach einer Woche zerbricht, oder verweisen auf Enterprise-APIs, die mehr verschlingen als Ihr monatliches Werbebudget.
Die Realität sieht so aus: Die meisten Business-Anwender – Dropshipper, Solo-Selbstständige, Marketing-Teams – wollen schlicht eine saubere Tabelle mit Produktnamen, Preisen, Bildern, Bewertungen und Verkäuferinfos. Sie haben keine Lust, nachts um 2 Uhr Playwright-Skripte zu debuggen.
Genau diese Lücke schließt dieser Leitfaden: eine praxisnahe, nach Kenntnisstand sortierte Übersicht der besten Temu-Scraper, die 2026 tatsächlich liefern – plus die Best Practices, mit denen aus einem Roh-Scrape eine laufende Wettbewerbsanalyse wird. Ob blutiger Anfänger oder Entwickler, der eine Datenpipeline baut: Den passenden Abschnitt finden Sie hier.
Thunderbit für Temu-Scraping testen
Warum Temu scrapen? Die wichtigsten Anwendungsfälle für Business-Teams
Temu-Daten sind nicht bloß interessant – sie sind strategisch wertvoll.
In Kategorien mit niedrigen und mittleren Preispunkten hat sich die Plattform zur maßgeblichen Preisreferenz entwickelt. Selbst wer nicht auf Temu verkauft, wird von seinen Kunden an dem gemessen, was sie dort sehen. So holen verschiedene Teams Wert aus Temu-Daten:
| Anwendungsfall | Benötigte Daten | Warum das wichtig ist |
|---|---|---|
| Produktrecherche für Dropshipping | Titel, Preis, Bild, Bewertung, Anzahl der Rezensionen, Verkaufszahl, Varianten | Findet günstige Produkte mit Nachfrage-Signalen für den Vergleich über Amazon, Shopify, AliExpress und TikTok Shop hinweg |
| Wettbewerbsfähige Preisgestaltung | Aktueller Preis, Originalpreis, Rabatt %, Währung, Versand, Zeitstempel | Schafft eine Grundlage für Preisstrategie und Aktionsplanung |
| Produktsourcing | Spezifikationen, Bilder, Varianten, Verkäufer/Shop, Artikel-ID, Kategorie | Identifiziert Produkttypen und Anbieter-Listings, die eine genauere Prüfung wert sind |
| Analyse von Markttrends | Suchbegriff, Kategorie, Verkaufszahl, Rezensionsanzahl, Bewertung | Zeigt, welche Produkte in den Kategorien an Zugkraft gewinnen |
| Marketing- und Kreativrecherche | Titel, Bild, Rezensionsanzahl, Bewertung, Beschreibungen, Kategorien | Macht Messaging, visuelle Aufhänger, Bundles und Claims sichtbar, die bei Listings mit hohem Volumen verwendet werden |
| Bestands- und Verfügbarkeitsmonitoring | Produkt-URL, Verfügbarkeit, Versandprognose, Preis, Zeitstempel | Erfasst Ausverkäufe, Änderungen im lokalen Lagerbestand und Preisbewegungen im Zeitverlauf |
Wer nach „best Temu scrapers“ sucht, lässt sich meist in drei Gruppen einteilen. Nicht-technische Nutzer wollen eine Chrome-Erweiterung, die eine Tabelle ausspuckt. Halb-technische Anwender wollen ein visuelles Tool mit Vorlagen und Zeitplanung. Entwickler wollen eine API, ein Playwright-Skript und eine Proxy-Strategie.
Dieser Artikel deckt alle drei ab – beginnt aber bei der größten Gruppe: bei den Leuten, die Daten brauchen, nicht Code.
Woran man die besten Temu-Scraper 2026 erkennt
Ein Scraper, der Amazon oder Shopify meistert, übersteht Temu noch lange nicht. Diese Kriterien liegen dem Artikel zugrunde:
- Zuverlässigkeit bei Temu — Liefert er wirklich saubere Daten, oder wird er blockiert, gibt leere Zeilen zurück oder bricht nach einem Layout-Wechsel ab?
- Benutzerfreundlichkeit — Kommt ein nicht-technischer Business-Nutzer ohne Code an den Start?
- Vollständigkeit der Daten — Beherrscht er die Anreicherung über Unterseiten (jede Produktdetailseite für Spezifikationen, Varianten, Verkäuferinfos)?
- Wartungsaufwand — Stellt er sich um, wenn Temu seine Seitenstruktur ändert?
- Zeitplanung und Monitoring — Kann er wiederkehrende Scrapes ausführen und in ein dauerhaftes Datenziel exportieren?
- Export-Ziele — CSV, Excel, Google Sheets, Airtable, Notion, JSON?
- Kostenklarheit — Was kostet ein realistischer Temu-Scraping-Workflow tatsächlich pro Monat?
Community-Berichte auf Reddits r/webscraping beschreiben Temu durchweg als eine der schwierigsten E-Commerce-Websites zum Scrapen. Ein Nutzer schrieb, er könne „als Käufer nicht einmal einen Preis bekommen“, während ein anderer anmerkte, Temu und Shopee hätten Teams, die ihre Anti-Bot-Mechanismen laufend nachschärfen. Temu-spezifische, öffentliche Ausfallraten-Benchmarks existieren nicht, doch der Imperva Bad Bot Report 2025 zeigt, dass automatisierter Traffic den menschlichen überholt hat und Bots inzwischen 51 % des gesamten Internetverkehrs ausmachen. Gegen genau dieses Umfeld wehrt sich Temu.
Temus Anti-Bot-Abwehr: Warum die meisten Scraper scheitern
Die meisten Artikel zum Temu-Scraping gönnen dem Thema Anti-Bot genau einen Satz: „Temu nutzt Anti-Bot.“ Das bringt Sie nicht weiter.
Wenn Sie ein Tool auswählen, müssen Sie wissen, welche Abwehrmechanismen Temu fährt und welche Tool-Funktion jeden einzelnen davon aushebelt. Hier die praktische Zuordnung:
| Temu-Abwehr | Was sie bewirkt | Benötigte Tool-Funktion | Beispiel-Tools |
|---|---|---|---|
| Cloudflare WAF / Browser-Checks | Blockiert automatisierte User-Agents, erkennt Bot-Fingerprints, liefert Challenge-Seiten aus | Cloud-Infrastruktur mit rotierenden Residential IPs und echten Browser-Fingerprints | Thunderbit (Cloud-Scraping), Bright Data, Oxylabs, ScraperAPI |
| Starkes JavaScript-Rendering | Produktdaten werden per JS geladen; rohes HTML ist leer | Headless-Browser oder vollständiges Browser-Rendering | Thunderbit (Browser-Scraping-Modus), Playwright, Selenium, ParseHub, Apify Browser Actors |
| Dynamische CSS-Selektoren | Klassennamen ändern sich zwischen Deployments und brechen CSS-basierte Scraper | KI-gestützte Felderkennung (nicht abhängig von festen Selektoren) | Thunderbit (KI liest die Seite jedes Mal neu), Bright Data AI Scraper Builder |
| Rate Limiting | Drosselt schnelle aufeinanderfolgende Anfragen | Gleichzeitige Cloud-Anfragen mit intelligenter Drosselung | Thunderbit (bis zu 50 Seiten gleichzeitig per Cloud), ScraperAPI, Bright Data |
| CAPTCHA-Abfragen | Unterbrechen Sitzungen nach verdächtigem Verhalten | Integriertes CAPTCHA-Lösen oder eine weniger triggernde Strategie | Bright Data, Oxylabs, ScraperAPI Premium/Ultra-Premium |
| Endloses Scrollen / Lazy Loading | Nur die ersten Produkte erscheinen ohne Interaktion | Intelligentes Scrollen, Erkennung von Paginierung, Interaktionsautomatisierung | Thunderbit Paginierung, Apify Smart Scrolling, Octoparse Workflow Builder |
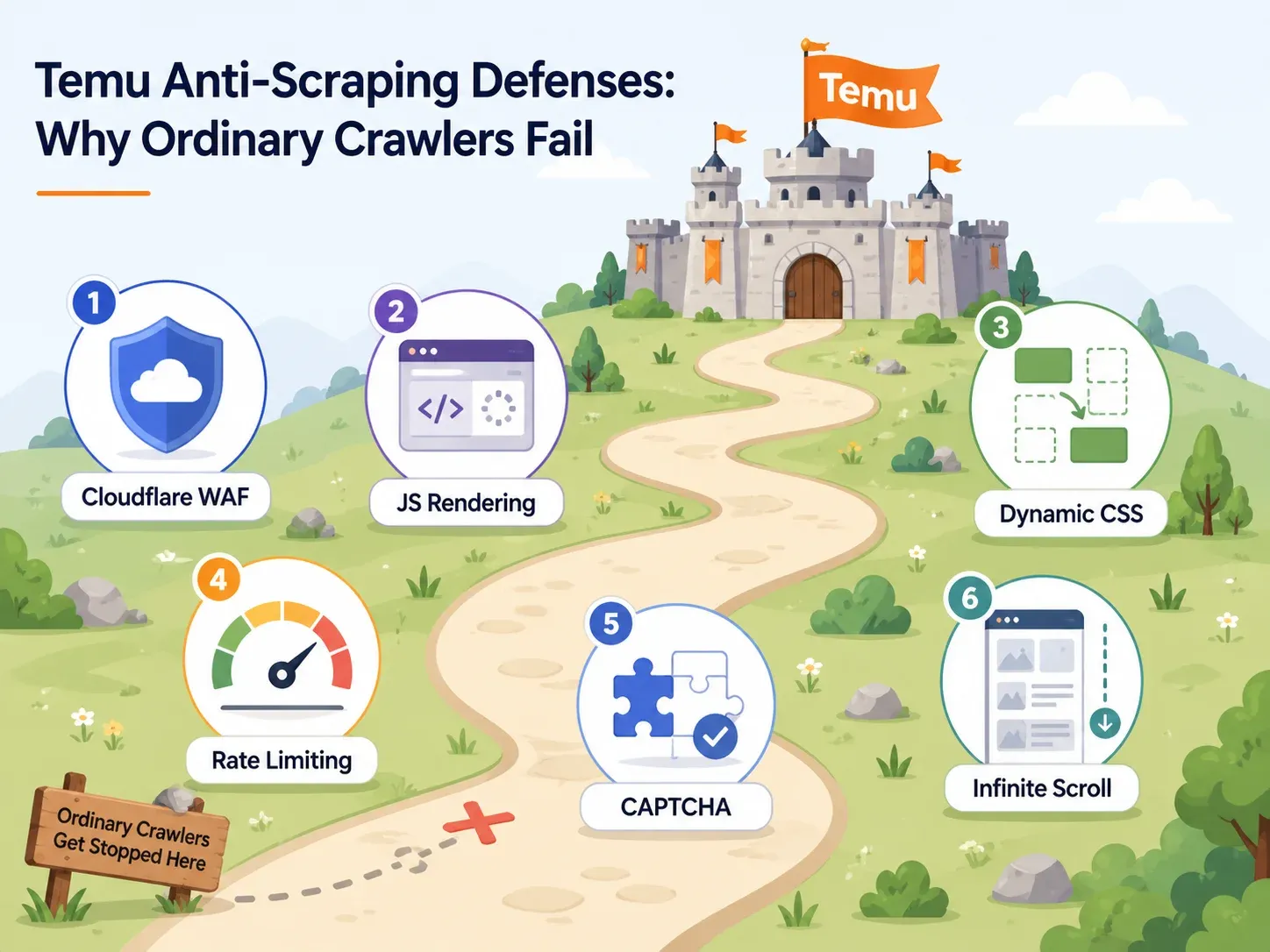
Cloudflare WAF und IP-Blockierung
Temus Eingangstür wird von browserbasierten Integritätsprüfungen im Cloudflare-Stil bewacht. Schlichte HTTP-Anfragen – wie sie ein einfaches Python-requests.get() absetzt – werden abgefangen, mit 403 abgespeist oder mit unvollständigen Daten versorgt.
Tools, die hier durchkommen, brauchen rotierende Residential- oder Mobile-IPs und echte Browser-Fingerprints. Der Cloudflare Radar Jahresrückblick 2025 berichtete, dass Nicht-KI-Bots Anfang 2025 für etwa die Hälfte aller HTML-Seitenanfragen verantwortlich waren. In genau dieser Größenordnung verteidigen sich Plattformen wie Temu gegen Automatisierung.
JavaScript-Rendering und dynamische Selektoren
Hier scheitern die meisten Anfänger-Scraper sang- und klanglos.
Schauen Sie sich den Quelltext einer Temu-Seite an, finden Sie oft nur eine leere Hülle – die eigentlichen Produktkarten, Preise und Bilder schiebt JavaScript erst nach dem Laden nach. Ein Scraper, der nur das rohe HTML liest, bringt also nichts Brauchbares zurück. Dazu kommt: Temus CSS-Klassennamen und DOM-Strukturen ändern sich von Deployment zu Deployment. Ein Scraper, der an einem festen CSS-Selektor wie .product-card__price hängt, läuft heute und liefert morgen leere Spalten.
KI-basierte Scraper (wie Thunderbit) lesen die Seite jedes Mal semantisch und hängen damit nicht daran, dass bestimmte Klassennamen gleich bleiben.
Rate Limiting und CAPTCHA-Abfragen
Sprechen Sie Temu von einer IP-Adresse aus zu schnell oder zu oft an, lösen Sie Rate Limits oder CAPTCHA-Abfragen aus. Manche Tools lösen das über intelligente Drosselung und eingebautes CAPTCHA-Solving. Andere überlassen es Ihnen – was für nicht-technische Nutzer praktisch eine Sackgasse bedeutet.
Beim Cloud-Scraping kommt es auf eines an: gleichzeitige Anfragen, über saubere IPs verteilt, mit automatischer Wiederholungslogik.
Die besten Temu-Scraper nach Kenntnisstand: Vollständiger Überblick
Suchen Sie Ihre Zeile und springen Sie zum passenden Abschnitt:
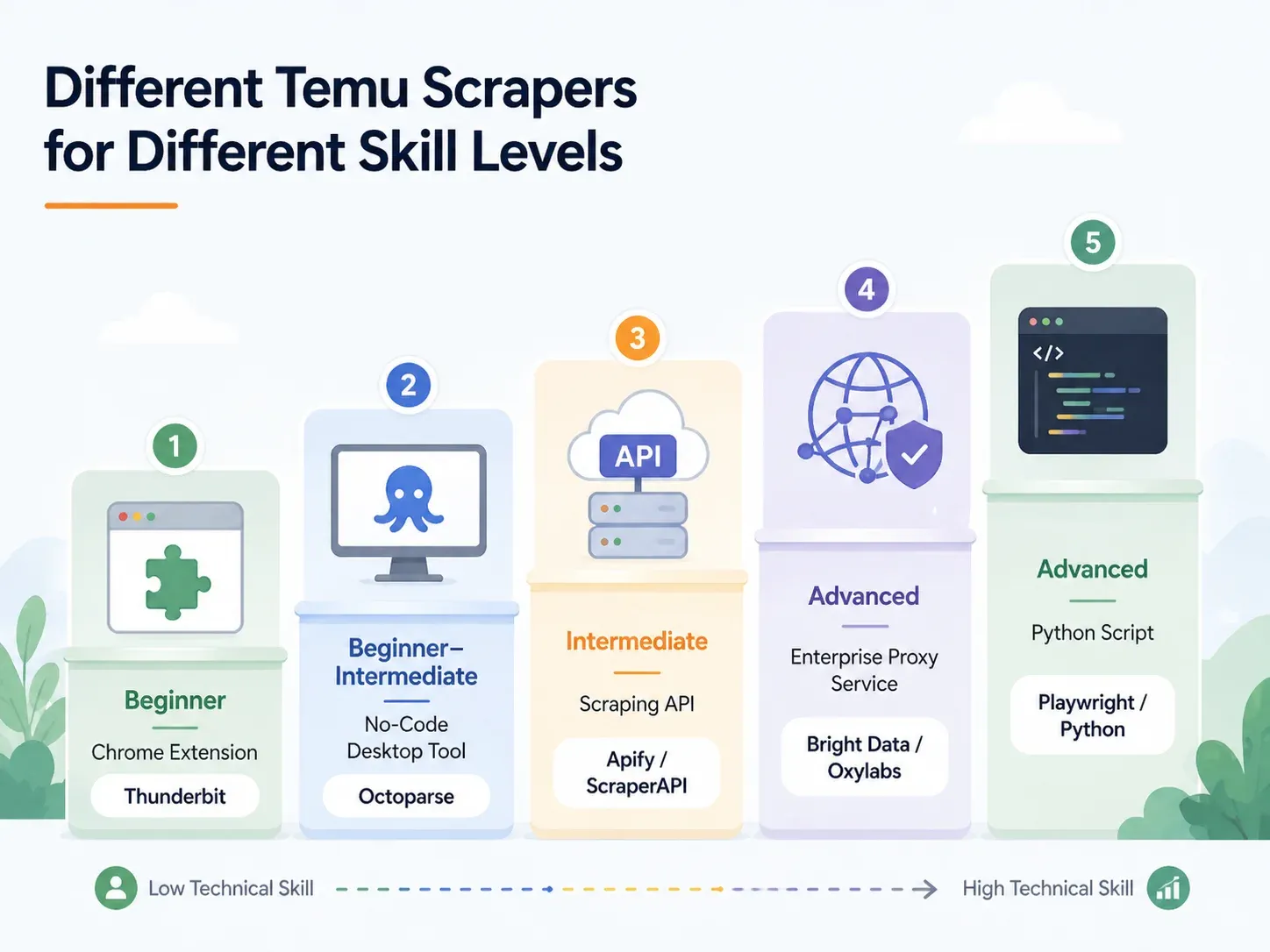
| Ansatz | Kenntnisstand | Einrichtungszeit | Anti-Bot-Handhabung | Am besten geeignet für |
|---|---|---|---|---|
| KI-Chrome-Erweiterung (z. B. Thunderbit) | Anfänger | < 2 Min. | Abgedeckt (Cloud oder Browser) | Dropshipper, Marketer, E-Commerce-Operations |
| No-Code-Desktop-Tool (z. B. Octoparse, ParseHub) | Anfänger–Fortgeschritten | 10–60 Min. | Teilweise (Proxy-Konfiguration nötig) | Regelmäßiges Scraping mit Vorlagen |
| Scraping-API/Service (z. B. ScraperAPI, Apify) | Fortgeschritten | 15–45 Min. | Integriert | Entwickler, die in Pipelines integrieren |
| Managed Proxy/Enterprise (z. B. Bright Data, Oxylabs) | Fortgeschritten/Enterprise | Stunden–Tage | Vollständige Infrastruktur | Hohe Volumina, Warehouse-Zustellung |
| Eigenes Python-Skript (Playwright/Selenium) | Fortgeschritten | 1–4 Std.+ | Manuell (Proxy- und CAPTCHA-Setup) | Volle Kontrolle, Sonderfälle, Anpassungen |
Thunderbit: Der beste Temu-Scraper für nicht-technische Nutzer
Thunderbit ist eine KI-gestützte Chrome-Erweiterung für Business-Anwender – Vertriebsteams, E-Commerce-Operatoren, Dropshipper, Marketer –, die strukturierte Daten von Websites brauchen, ohne eine Zeile Code zu schreiben. Ich arbeite im Thunderbit-Team und kenne das Produkt deshalb sehr genau. Ich sage offen, was es kann und wofür es taugt.
Der Kern-Workflow ist mit zwei Klicks erledigt: Eine Temu-Seite öffnen, auf KI-Felder vorschlagen klicken, die vorgeschlagenen Spalten prüfen (Produktname, Preis, Bild, Bewertung usw.) und dann auf Scrapen klicken.
Die KI von Thunderbit liest die Seitenstruktur aus und schlägt Spaltennamen und Datentypen automatisch vor. Da sie nicht an festen CSS-Selektoren hängt, stellt sich der Scraper um, sobald Temu seine Klassennamen oder Kartenlayouts ändert.
Die wichtigsten Funktionen für Temu:
- Cloud-Scraping-Modus: Schneller für öffentliche Seiten, verarbeitet bis zu 50 Seiten gleichzeitig. Ideal für Kategorieseiten, Suchergebnisse und Produktlisten ohne Login.
- Browser-Scraping-Modus: Nutzt Ihre aktuelle Chrome-Sitzung inklusive Cookies, Spracheinstellung und Login-Status. Ideal, wenn Region, Pop-ups oder eingeloggte Inhalte das angezeigte Ergebnis beeinflussen.
- Unterseiten scrapen: Nach dem Scrapen einer Listing-Seite klicken Sie auf „Unterseiten scrapen“, um jede Produktdetailseite zu besuchen und Spalten wie vollständige Beschreibung, Varianten, Verkäuferinfos, Versandprognose und Spezifikationen zu ergänzen – ganz ohne zusätzliche Konfiguration.
- KI-Eingabeaufforderungen für Felder: Daten schon während des Scrapes klassifizieren, übersetzen oder umformatieren. Beispiel: „Kategorisiere dieses Produkt in Küchenutensilien, Kleingeräte, Aufbewahrung oder Sonstiges.“
- Geplantes Scraping: Einen Zeitplan in natürlicher Sprache festlegen („jeden Montag um 9 Uhr“), URLs eingeben, und Thunderbit führt den Scrape in der Cloud aus und exportiert nach Google Sheets, Airtable oder einem anderen Ziel.
- Kostenlose Exporte: Excel, CSV, Google Sheets, Airtable, Notion, JSON – keine Paywall beim Export. Bilder landen in Airtable und Notion als echte Anhänge.
Preis: Gratis-Stufe mit bis zu 6 Seiten (oder 10 mit Test-Boost); kostenpflichtige Pläne starten bei rund 15 $/Monat (monatlich, ca. 14 €/Monat) oder 9 $/Monat (jährlich, ca. 8 €/Monat) für 500 Credits, wobei 1 Credit = 1 Ergebniszeile entspricht.
Temu-Daten mit KI scrapen Get Started Free
Direktvergleich: Thunderbit vs. Python-Skript auf derselben Temu-Seite
Der Unterschied ist eindeutig:
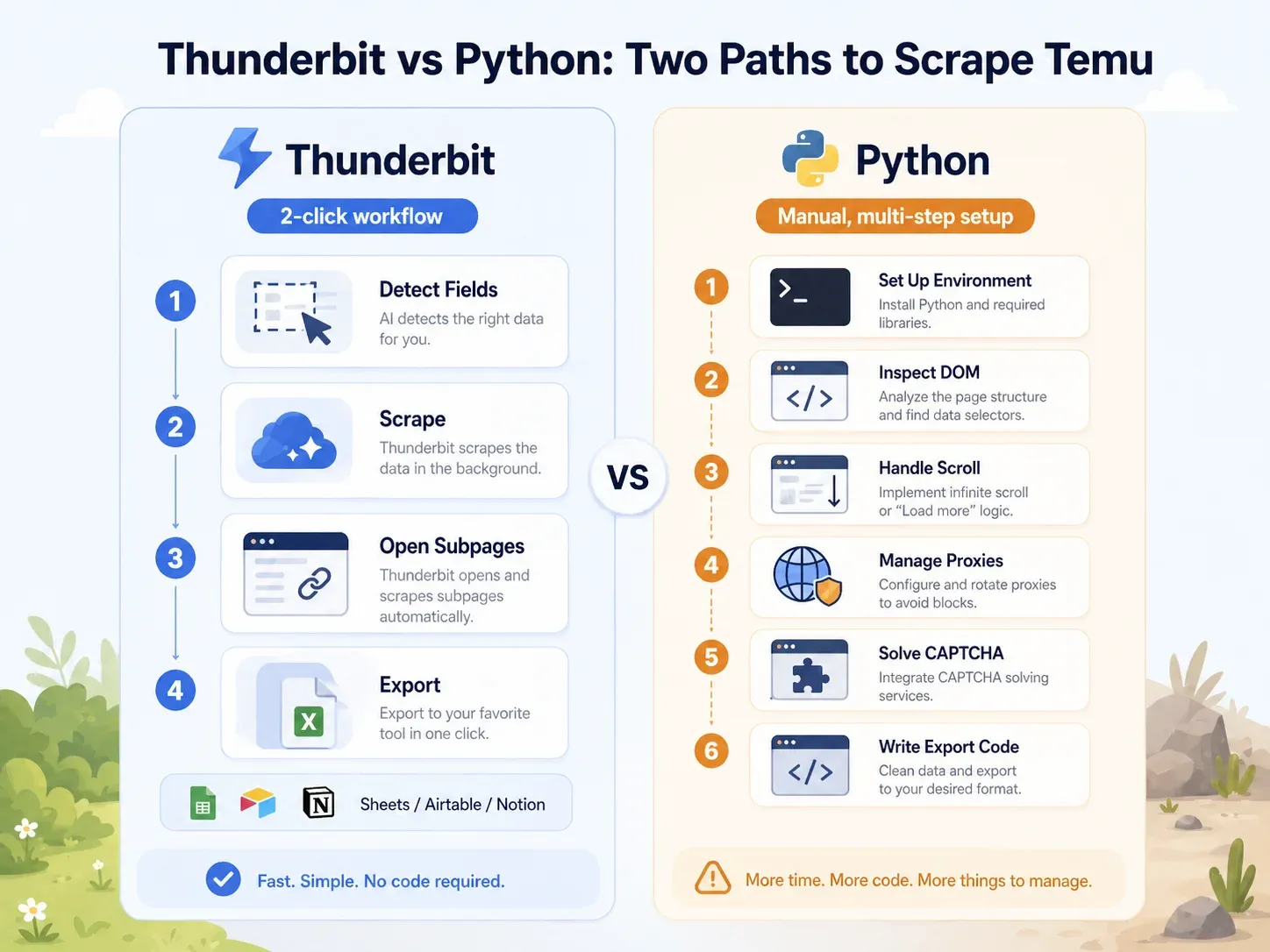
| Aufgabe | Thunderbit | Python (Playwright) |
|---|---|---|
| Temu-Kategorieseite öffnen | Seite in Chrome öffnen | Python-Umgebung einrichten, Playwright installieren, Browser installieren |
| Felder erkennen | Auf „KI-Felder vorschlagen“ klicken | DOM, Netzwerkaufrufe und JSON-Payloads analysieren |
| Dynamisches Laden behandeln | Browser-/Cloud-Modus plus Paginierung | Scroll-/Warte-Logik schreiben, Anfragen abfangen |
| Blocks behandeln | Cloud-Modus oder Browser-Modus versuchen | Proxys, Header, Fingerprinting, Retries, CAPTCHA hinzufügen |
| Listing-Felder extrahieren | Auf „Scrapen“ klicken | Selektoren oder API-Parsing-Logik schreiben |
| Produktseiten anreichern | Auf „Unterseiten scrapen“ klicken | Einen separaten PDP-Crawler bauen |
| Export | Auf Sheets/Airtable/Notion/Excel klicken | CSV-/JSON-/Sheets-Integrationscode schreiben |
| Typisches Setup für einen Business-Nutzer | Unter 2 Minuten | Mindestens 1–4 Stunden; laufende Wartung |
Ein minimaler Playwright-Prototyp für Temu könnte so aussehen (Pseudocode – nicht produktionsreif):
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("https://www.temu.com/search_result.html?search_key=kitchen+organizer")
page.wait_for_load_state("networkidle")
for _ in range(8):
page.mouse.wheel(0, 2000)
page.wait_for_timeout(1200)
cards = page.locator("[data-product-id], a[href*='goods.html']")
# Produktionscode braucht trotzdem noch Selektoren, Proxys, Retries,
# CAPTCHA-Behandlung, PDP-Crawling und Exportlogik.
print(cards.count())
Das sind schon mehr als 10 Zeilen, bevor Sie ein einziges Feld extrahiert haben – und Proxys, CAPTCHA, PDP-Anreicherung oder Export sind dabei noch gar nicht berücksichtigt. Für nicht-technische Nutzer schrumpft Thunderbit diesen gesamten Ablauf auf ein paar Klicks. Entwicklern gibt der Python-Weg mehr Kontrolle – allerdings zu deutlich höheren Wartungskosten.
Octoparse und ParseHub: No-Code-Desktop-Scraper für Temu
Wenn Sie mehr Kontrolle wollen als bei einer Chrome-Erweiterung, aber keinen Code schreiben möchten, sind Octoparse und ParseHub die naheliegenden Optionen.
Octoparse bietet eine öffentliche Temu-Details-Scraper-Vorlage. Die Beispielausgabe enthält Produkt-IDs, Titel, Preise, Verkäufer-/Shop-Daten, Bild-URLs, Rabatte, Shop-URLs und ausführliche Spezifikationen. Das ist ein echter Pluspunkt – Sie starten mit einer Vorlage, statt einen Workflow von Grund auf zu bauen. Octoparse beherrscht außerdem Cloud-Extraktion, Zeitplanung und visuelles Workflow-Building.
Die Einschränkungen bei Temu:
- Anti-Bot-Add-ons (Residential Proxys zu 3 $/GB, ca. 2,80 €/GB; CAPTCHA-Lösen für 1–1,50 $ pro Tausend) summieren sich schnell.
- Vorlagen können brechen, wenn Temu sein Layout ändert. Dann müssen Sie womöglich Selektoren aktualisieren oder warten, bis Octoparse die Vorlage pflegt.
- Das Setup dauert je nach Seitenkomplexität 10–60 Minuten.
Octoparse-Preise: kostenloser Plan mit 10 Aufgaben und 50.000 monatlichem Datenexport; Standard rund 75 $/Monat (ca. 69 €/Monat) jährlich; Professional rund 108 $/Monat (ca. 99 €/Monat) jährlich. Add-ons für Proxys, CAPTCHA und Managed Services kosten extra.
ParseHub ist ein visueller Desktop-/Web-Scraper, der dynamische Seiten gut beherrscht (er fährt einen vollständigen Chromium-Browser). Die bezahlten Pläne beginnen jedoch bei 189 $/Monat (ca. 174 €/Monat), was für einen Solo-Anwender happig ist. In meiner Recherche fand sich keine starke öffentliche Temu-spezifische Vorlage. ParseHub passt eher zu Teams, die bereits mit visuellen Scraping-Projekten vertraut sind.
| Tool | Stärken für Temu | Schwächen bei Temu | Preis |
|---|---|---|---|
| Octoparse | Öffentliche Temu-Vorlage, visueller Workflow, Cloud-Extraktion, Zeitplanung | Vorlagen müssen gepflegt werden, Anti-Bot-Add-ons erhöhen die Kosten | Kostenlos; ca. $75/Monat jährlich Standard; ca. $108/Monat jährlich Pro; Add-ons extra |
| ParseHub | Handhabung dynamischer Seiten, Projekt-Workflow-Builder, IP-Rotation in bezahlten Plänen | Höherer Einstiegspreis, keine öffentliche Temu-Vorlage gefunden | Bezahlte Pläne ab $189/Monat |
Scraping-APIs: ScraperAPI, Apify und Bright Data für Temu
API-basierte Scraping-Services nehmen Ihnen Proxys, Rendering und Anti-Bot-Logik ab, damit sich Entwickler aufs Parsen und Speichern der Daten konzentrieren können. Sie passen gut, wenn Sie eine Pipeline bauen und nicht nur einen einmaligen Tabellenexport brauchen.
ScraperAPI ist eine Entwickler-API für Proxy-Rotation und Rendering. Auf der Preisseite stehen ein 7-Tage-Test mit 5.000 Credits, Hobby für 49 $/Monat (ca. 45 €/Monat) mit 100.000 Credits sowie höhere Stufen darüber. Der Haken bei Temu: JavaScript-Rendering und Premium-Proxy-Pools schlagen je nach Tarif mit 10–75 Credits pro Anfrage zu Buche. Diese Credit-Multiplikation kann die effektiven Kosten pro Zeile weit über den angezeigten Preis treiben.
Apify ist eine Plattform mit einem Marktplatz vorgefertigter „Actors“ (Scraper). Mehrere Temu-Actors stehen bereit. Ein community-gepflegter Temu Scraper nennt ein Pay-per-Event-Modell von etwa 5 $ pro 1.000 Produkte (ca. 4,60 €) in der Gratis-Stufe. Ein anderer Temu Products Scraper nennt 4 $ pro 1.000 Ergebnisse (ca. 3,70 €). Das Risiko: Die Qualität der Actors schwankt, die Wartung hängt von der Community ab, und manche Actors sind veraltet oder brechen nach Temu-Updates. Prüfen Sie vor jeder Entscheidung das Änderungsdatum und die Nutzerbewertungen.
Bright Data ist die Enterprise-Option. Laut Temu-Scraper-Seite laufen die Jobs auf Bright-Data-Infrastruktur mit Proxy-Rotation, Geo-Targeting, CAPTCHA-/Unblocking-Logik und Autoscaling. Als Ausgabeformate stehen JSON, CSV und Parquet bereit, dazu die direkte Auslieferung an S3, GCS, Azure Blob, BigQuery und Snowflake. Branchenbewertungen nennen für die Web Scraper API ein Pay-as-you-go von etwa 2,50 $ pro 1.000 Datensätze (ca. 2,30 €), während vertraglich gebundene Pläne bei rund 499 $/Monat (ca. 459 €/Monat) beginnen. Leistungsstark, aber für Teams mit echtem Budget.
Oxylabs unterhält ebenfalls eine eigene Temu-Scraper-API-Seite. Die Pläne starten bei 49 $/Monat (ca. 45 €/Monat), mit einer kostenlosen Testphase über bis zu 2.000 Ergebnisse. Eine starke Alternative zu Bright Data für Entwicklerteams, die strukturierte Temu-Daten über eine API wollen.
| API/Plattform | Temu-spezifische Hinweise | Stärke | Schwäche | Am besten für |
|---|---|---|---|---|
| ScraperAPI | Keine Temu-spezifische Seite gefunden, aber E-Commerce-Anti-Bot-Funktionen dokumentiert | Einfacher Endpunkt, JS-Rendering, Premium-Proxys | Credit-Multiplikatoren für Premium-Funktionen; Entwickler müssen Daten parsen | Entwickler-Pipelines |
| Apify | Mehrere Temu-Actors im Marktplatz | Schnellster Entwicklerpfad, wenn der Actor passt und gepflegt wird | Actor-Qualität variiert; einige veraltet | Entwickler, die Marktplatz + Zeitplanung wollen |
| Bright Data | Eigene Temu-Scraper-Seite | Enterprise-Infrastruktur, Unblocking, Zustellung ans Data Warehouse | Teuer; Web-Scraping-Konzepte bleiben notwendig | Enterprise-Datenteams |
| Oxylabs | Eigene Temu-Scraper-API-Seite | Klare Preisgestaltung pro Ergebnis, JS-Verarbeitung, IP-/CAPTCHA-Ansprüche | Entwickler-API-Workflow | Entwicklerteams mit Bedarf an Temu-API-Zugang |
Eigene Python-Skripte (Playwright/Selenium): Volle Kontrolle, hoher Aufwand
Eigene Python-Scraper bieten maximale Flexibilität – das ist ihr Vorteil. Für Temu ist Playwright meist der bessere Ausgangspunkt als Selenium, weil es ein Auto-Wait-Modell mitbringt und mit JavaScript-lastigen Seiten besser umgeht.
Doch der Preis dafür ist hoch.
Ein Prototyp kostet 1–4 Stunden. Ein produktionsreifer Scraper verlangt Proxy-Rotation, realistische Browser-Fingerprints, eine CAPTCHA-Strategie, Retries, Schema-Validierung, einen Ausgabespeicher, Monitoring, Benachrichtigungen und eine rechtliche Prüfung.
Und er geht kaputt. Scraping-Communities auf Reddit beschreiben modernes E-Commerce-Scraping immer wieder als instabil, sobald Websites auf Cloudflare, JavaScript-Rendering und Anti-Bot-Fingerprints setzen.
| Fehlerbild | Typische Ursache | Gegenmaßnahme |
|---|---|---|
| Leeres HTML / fehlende Produkte | JS lädt Produktkarten erst nach dem initialen HTML | Playwright verwenden, auf Netzwerk und DOM warten |
| Nur die ersten paar Produkte | Endloses Scrollen / Lazy Loading | Scroll-Schleife, Netzwerk-Idle-Wartezeiten, Schwellenwerte für Kartenanzahl |
| Preise fehlen oder sind inkonsistent | Region-/Sitzungs-/Währungsstatus oder Anti-Bot-Antwort | Locale setzen, Cookies, geotargeteter Proxy |
| 403 / Challenge / CAPTCHA | IP-Reputation, Headless-Fingerprint, Anfragefrequenz | Residential Proxys, Stealth-Browser, niedrigere Rate |
| Selektoren brechen | DOM-/Klassennamen-Änderungen, A/B-Tests | Semantische Extraktion oder API-Parsing, falls verfügbar |
Eigene Skripte sind nicht die „kostenlose“ Option. Sie verlagern die Kosten lediglich von der Abo-Gebühr auf Entwicklerzeit, Proxy-Rechnungen, CAPTCHA-Kosten und Wartungsrisiko. Sitzt ein Scraping-Engineer im Haus und brauchen Sie ungewöhnliche Logik, ist das der richtige Weg. Für alle anderen ist es in der Praxis die teuerste Variante.
Best Practice: Unterseiten-Scraping für vollständige Temu-Produktdaten
Das ist die wirkungsvollste Best Practice dieses Artikels – und fast kein anderer Leitfaden geht darauf ein.
Eine Temu-Kategorie- oder Suchseite zeigt nur die Basics: Titel, Vorschaubild, Preis, grobe Bewertung. Aber die Felder, die eine Zeile wirklich handlungsfähig machen – ausführliche Beschreibungen, Variantenlisten, vollständige Rezensionszahlen, Versandprognosen, Verkäufernamen, Spezifikationstabellen –, stehen auf der Produktdetailseite (PDP).
Scrapen Sie nur die Listing-Seite, arbeiten Sie mit einem unvollständigen Datensatz.
Der Zwei-Schritte-Workflow:
- Schritt 1 — Listing-Seite scrapen (PLP): Produktname, Preis, Vorschaubild und Bewertung von einer Temu-Suche oder Kategorieseite extrahieren.
- Schritt 2 — Über Unterseiten anreichern: Jede PDP besuchen und Spalten wie vollständige Beschreibung, Anzahl der Rezensionen, Variantenoptionen, Lieferzeit und Verkäuferinfos ergänzen.
So sieht der Unterschied vorher und nachher aus:
| Feld | Aus der PLP (Schritt 1) | Von der PDP ergänzt (Schritt 2) | |---|---|---|---| | Produkttitel | ✅ | — | | Preis | ✅ | ✅ (verifiziert / Rabatt %) | | Vorschaubild | ✅ | — | | Sternebewertung | ✅ | ✅ (mit Rezensionsanzahl) | | Vollständige Beschreibung | ❌ | ✅ | | Varianten (Größen, Farben) | ❌ | ✅ | | Verkäufername | ❌ | ✅ | | Versandprognose | ❌ | ✅ | | Detaillierte Spezifikationen | ❌ | ✅ |
In Thunderbit ist das ein Klick: Nach dem ersten Scrape auf „Unterseiten scrapen“ klicken. Die KI besucht jede Produkt-URL und ergänzt die zusätzlichen Spalten – keine weitere Konfiguration, kein separater Spider, keine Selektorpflege. Die Temu-Details-Vorlage von Octoparse und der Temu-Actor von Apify unterstützen Felder auf PDP-Ebene ebenfalls, allerdings mit mehr Setup und Wartung. In Python müssten Sie einen separaten PDP-Crawler bauen, dessen Selektoren pflegen und die Paginierung innerhalb der Detailseiten behandeln – ein erheblicher Mehraufwand.
Best Practice: Geplantes Temu-Scraping für laufendes Preis- und Bestandsmonitoring
Einmalige Scrapes helfen bei der Produktentdeckung. Wettbewerbsanalyse aber verlangt wiederholte Beobachtung.
Preise ändern sich, Produkte gehen aus, neue Artikel erscheinen täglich, und mit jeder Aktion verschiebt sich die Rabatttiefe. Ein wöchentlicher oder täglicher Scrape baut eine Verlaufstabelle auf, mit der Ihr Team tatsächlich arbeiten kann.
Drei Automatisierungsfälle, die sich auszahlen:
- Preis-Monitoring: Verfolgen Sie wöchentlich die Top-50-SKUs eines Wettbewerbers auf Temu. Lassen Sie die aktualisierten Preise automatisch nach Google Sheets exportieren, um sie auf einen Blick mit Ihren eigenen zu vergleichen.
- Bestands- und Verfügbarkeitsmonitoring: Erkennen Sie, wenn ein Trendprodukt ausverkauft ist, eine neue Variante auftaucht oder sich die Versandprognosen verschieben.
- Erkennung neuer Produkte/Trends: Planen Sie täglich einen Scrape von Temus „Neu eingetroffen“-Bereich oder einer priorisierten Kategorieseite. Sortieren Sie nach Verkaufszahl oder Rezensionsanzahl, um aufkommende Produkte früh zu erwischen.
In Thunderbit richten Sie das ein, indem Sie das Intervall in natürlicher Sprache beschreiben („jeden Montag um 9 Uhr“), Ihre Ziel-URLs eingeben und auf „Planen“ klicken. Der Scrape läuft in der Cloud und exportiert ans gewünschte Ziel. Weil die KI die Seite jedes Mal frisch liest, stellen sich geplante Scrapes automatisch auf Layout-Änderungen bei Temu ein – Sie müssen keine Selektoren anfassen, wenn Temu eine Produktkarte neu gestaltet.
Die Alternative: einen Cron-Job aufsetzen, ein Python-Skript pflegen, die Proxy-Rotation konfigurieren, eine Export-Pipeline bauen und die Selektoren jedes Mal reparieren, wenn Temu sein Layout ändert. Für ein nicht-technisches Team ist das keine Option. Für Entwickler ist es Dauerarbeit. Apify und Bright Data unterstützen geplante Läufe ebenfalls, allerdings mit mehr technischem Setup und höheren Einstiegskosten.
Best Practice: Der komplette Temu-Datenworkflow (Scrapen → Bereinigen → Exportieren → Handeln)
Die meisten Scraping-Leitfäden hören bei „CSV herunterladen“ auf.
Business-Nutzer brauchen die Daten aber in den Tools, mit denen sie tatsächlich arbeiten – Google Sheets für die Zusammenarbeit, Airtable für Produktdatenbanken, Notion für Team-Dashboards. Die eigentliche Best Practice ist ein durchgängiger End-to-End-Workflow:
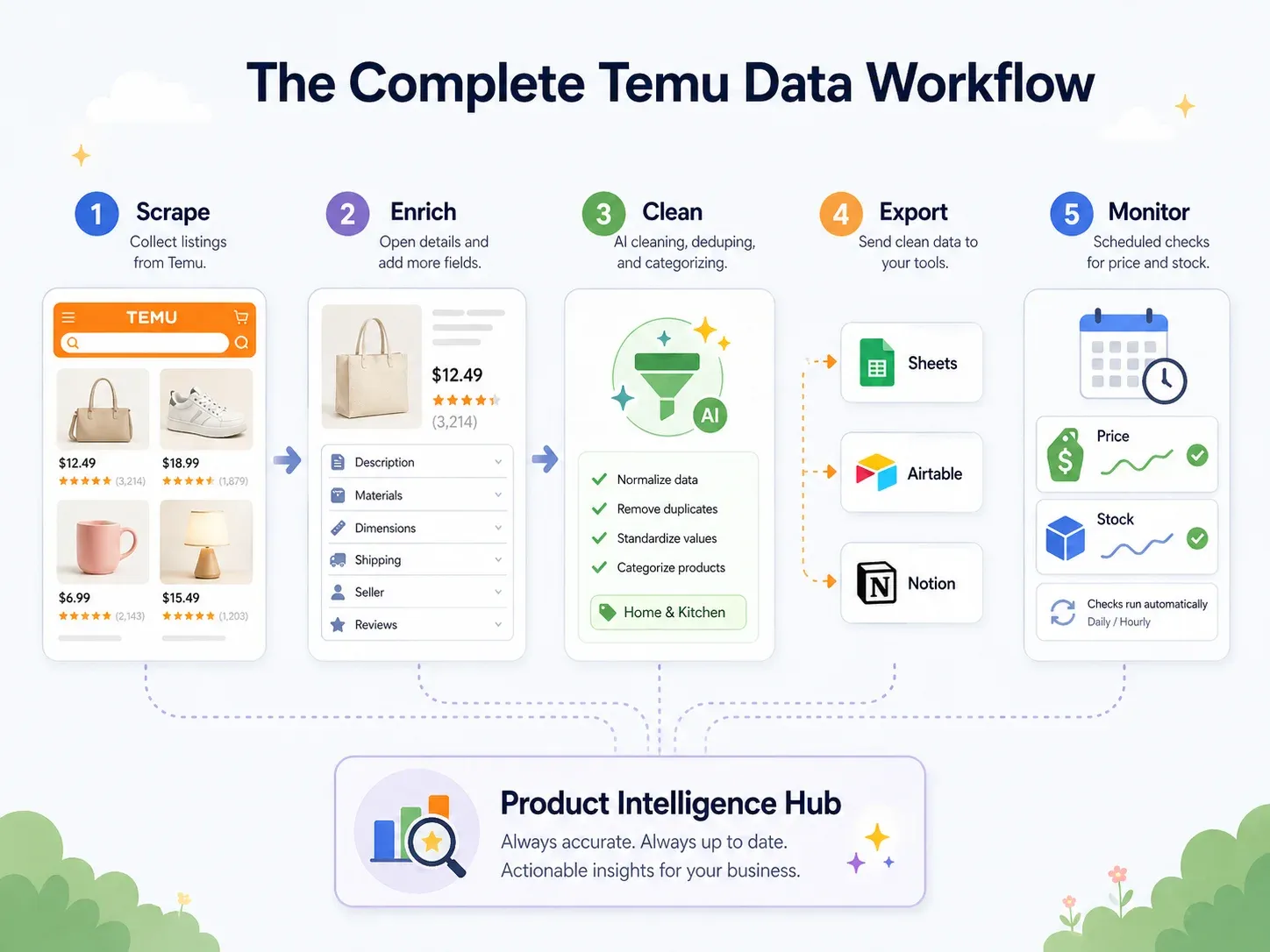
| Workflow-Schritt | Was passiert | Thunderbit-Funktion |
|---|---|---|
| Scrapen | Daten von Temu-Seiten extrahieren | KI-Felder vorschlagen → Scrapen (2 Klicks) |
| Anreichern | Jede Produktdetailseite besuchen | Unterseiten scrapen (1 Klick) |
| Bereinigen & Beschriften | Produkte kategorisieren, Preise normalisieren, Titel übersetzen | KI-Eingabeaufforderung für Felder — während des Scrapes labeln, formatieren, übersetzen |
| Exportieren | Daten in Business-Tools übertragen | Kostenloser Export zu Excel, Google Sheets, Airtable, Notion; CSV/JSON herunterladen |
| Überwachen | Änderungen im Zeitverlauf verfolgen | Geplanter Scraper mit Intervallen in natürlicher Sprache |
Ein konkretes Beispiel: Sie scrapen 200 Temu-Küchenprodukte. Während des Scrapes ordnet eine KI-Eingabeaufforderung jedes Produkt automatisch einer Kategorie zu – „Utensilien / Kleingeräte / Aufbewahrung / Reinigung / Deko“. Preise werden in numerische USD-Werte normalisiert. Chinesische Produkttitel werden ins Englische übersetzt. Die Daten gehen direkt in eine Airtable-Basis, inklusive Produktbildern (nicht nur URLs – echte Bildanhänge, wie in Thunderbits Leitfaden zum Bilder-Scraping beschrieben). Ein geplanter Scrape frischt die Daten wöchentlich auf.
Einige nützliche KI-Eingabeaufforderungen für Temu-Daten:
- „Kategorisiere dieses Produkt in eine der folgenden Kategorien: Küchenutensilien, Kleingeräte, Aufbewahrung, Reinigung, Deko, Sonstiges. Gib nur die Kategorie zurück.“
- „Übersetze den Produkttitel in prägnantes Englisch und behalte Marken, Mengen, Größen und Modellnummern bei.“
- „Normalisiere den Preis als Zahl ohne Währungssymbole.“
- „Bewerte die Nachfrage als Hoch, Mittel oder Niedrig anhand von Bewertung, Rezensionsanzahl und Verkaufszahl. Wenn Daten fehlen, gib Unbekannt zurück.“
So wird aus einem Roh-Scrape eine lebendige Produkt-Intelligence-Datenbank – ganz ohne dass ein Entwickler eine separate ETL-Pipeline bauen muss.
Die besten Temu-Scraper im Vergleich: Tabelle nebeneinander
| Tool | Kenntnisstand | Einrichtungszeit | Anti-Bot-Handhabung | Unterseiten-Scraping | Zeitplanung | Export-Optionen | Preisstufe | Am besten für |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Anfänger | Minuten | Browser-Modus, Cloud-Modus, KI-Felderkennung | Ja (Unterseiten scrapen) | Ja (Zeitpläne in natürlicher Sprache) | Excel, CSV, Google Sheets, Airtable, Notion, JSON | Kostenlos 6 Seiten; kostenpflichtig ab ca. $9–15/Monat für 500 Credits | Nicht-technische E-Commerce-Teams, Dropshipper |
| Octoparse | Anfänger–Fortgeschritten | 10–60 Min. | Cloud-Extraktion, Proxy/CAPTCHA-Add-ons | Ja (Vorlagen-Workflows) | Ja (bezahlte/Cloud-Pläne) | Excel, CSV, JSON, HTML, XML, Datenbank, Google Sheets | Kostenlos; ca. $75/Monat jährlich Standard; Add-ons extra | Anwender, die visuelle Workflows + Temu-Vorlage wollen |
| ParseHub | Anfänger–Fortgeschritten | 30–60 Min. | Dynamisches Rendering, bezahlte IP-Rotation | Ja (Projektflüsse) | Bezahlte Pläne | CSV/JSON, Dropbox/S3 in bezahlten Plänen | Ab $189/Monat | Teams, die visuelle Projekte für dynamische Websites bauen |
| ScraperAPI | Entwickler | Stunden | Proxy-Rotation, JS-Rendering, Premium-Pools | Eigene Programmierung erforderlich | DataPipeline/Planer | HTML/JSON/CSV | Test mit 5K Credits; Hobby $49/Monat; höhere Stufen verfügbar | Entwickler, die benutzerdefinierte Temu-Pipelines bauen |
| Apify | Fortgeschritten | 10–30 Min., wenn der Actor passt | Actor-spezifische Browser-/Proxy-Logik | Actor-abhängig | Ja | JSON, CSV, Excel, API/Datasets | Kostenlose Plattform; Temu-Actors ca. $4–5/1K Produkte | Entwickler/Anwender, die die Actor-Qualität prüfen können |
| Bright Data | Fortgeschritten/Enterprise | Stunden–Tage | Vollständige Proxy-, CAPTCHA-, Unblocking- und Autoscaling-Infrastruktur | Eigene Programmierung über Scraper/API | Ja | JSON, CSV, Parquet, S3, GCS, Azure, BigQuery, Snowflake | ca. $2,5/1K Datensätze PAYG; vertraglich ab ca. $499/Monat | Enterprise-Datenteams, Extraktion mit hohem Volumen |
| Oxylabs | Fortgeschritten | Stunden | JS-Verarbeitung, IP-/CAPTCHA-Ansprüche | Eigene Programmierung über API | Ja | JSON/API-Ausgabe | Ab $49/Monat; Test bis zu 2K Ergebnisse | Entwicklerteams mit Bedarf an Temu-API-Zugang |
| Custom Python (Playwright) | Fortgeschritten | 1–4 Std.+; laufende Wartung | Manuelle Proxys, CAPTCHA, Fingerprints | Vollständig individuell | Cron/Warteschlange/manuell | Individuell | Entwicklerzeit + Proxy-/CAPTCHA-/Hosting-Kosten | Sonderfälle, Teams mit Scraping-Engineers |
Welchen Temu-Scraper sollten Sie wählen? Schnelle Empfehlungen
- Dropshipper, der schnelle Produktrecherche braucht? Starten Sie mit Thunderbits Gratis-Stufe. Das ist der schnellste Weg von „Ich will Temu-Daten“ zu „Ich habe eine Tabelle“. Funktioniert es auf Ihren Zielseiten (und das sollte es bei den meisten öffentlichen Kategorien- und Produktseiten tun), sind Sie fertig.
- Anwender, der visuelle Kontrolle und wiederverwendbare Vorlagen möchte? Octoparse hat eine öffentliche Temu-Details-Vorlage und einen visuellen Workflow-Builder. Rechnen Sie mit 10–30 Minuten Einrichtung und etwas Proxy-/CAPTCHA-Konfiguration.
- Entwickler, der eine Datenpipeline oder ein internes Tool baut? ScraperAPI oder Apify bieten API-/Actor-Workflows, die sich in Code und geplante Jobs einbinden lassen. Prüfen Sie Apify-Actors sorgfältig – achten Sie auf Wartungsstatus und Nutzerbewertungen.
- Enterprise-Team mit Bedarf an Temu-Daten in großem Volumen und Warehouse-Zustellung? Bright Data ist der Infrastruktur-Ansatz. Teuer, aber es beherrscht Skalierung, Unblocking und die Zustellung an S3/BigQuery/Snowflake.
- Scraping-Engineer mit Sonderlogik? Eigenes Playwright/Selenium gibt Ihnen volle Kontrolle. Planen Sie aber laufende Wartung, Proxy-Kosten und CAPTCHA-Behandlung von vornherein ein.
Den meisten nicht-technischen Business-Nutzern würde ich raten, zuerst die Gratis-Stufe von Thunderbit zu testen. Die erste Frage lautet immer: „Bekomme ich die Zeilen, die ich von genau dieser Temu-Seite brauche?“ – und die beantworten Sie in unter zwei Minuten, ohne einen Cent auszugeben. Entwickler sollten vor der Budget-Freigabe einen Benchmark der Kosten pro erfolgreicher Zeile zwischen Apify, ScraperAPI und einem kleinen Playwright-Prototyp fahren.
Thunderbit kostenlos für Temu-Scraping testen
FAQs zum Scrapen von Temu
Ist es legal, Temu zu scrapen?
Das hängt von der Gerichtsbarkeit ab, von den gesammelten Daten, der Zugriffsmethode und der Verwendung der Daten. Temus Nutzungsbedingungen schränken den automatisierten Zugriff ausdrücklich ein, einschließlich Crawling, Scraping oder Spidering von Seiten oder Daten. US-Gerichte haben für den Zugriff auf öffentlich verfügbare Daten einige günstige Präzedenzfälle geschaffen (die hiQ-v.-LinkedIn-Entscheidung des Ninth Circuit), aber spätere Urteile haben auch Vertragsverletzungs- und Trespass-Ansprüche bestätigt. Kurz gesagt: Das Scrapen öffentlich verfügbarer Produktdaten zu Forschungszwecken kann in manchen Kontexten vertretbar sein, doch Nutzungsbedingungen, Datenschutzrecht (DSGVO), Urheberrecht und der Verwendungszweck spielen allesamt eine Rolle. Das ist keine Rechtsberatung – ziehen Sie für die kommerzielle Nutzung einen Anwalt hinzu.
Wie oft ändert Temu sein Website-Layout?
Ein offizieller Rhythmus ist nicht dokumentiert. Community-Berichte und das Tool-Ökosystem behandeln Temu als dynamisches, häufig aktualisiertes Ziel. Gehen Sie davon aus, dass CSS-Selektoren jederzeit brechen können, und setzen Sie eher auf KI-/semantische Extraktion oder aktiv gepflegte Vorlagen als auf fest kodierte Selektoren.
Kann ich Temu scrapen, ohne blockiert zu werden?
Bei begrenzten öffentlichen Seiten mit verantwortungsvoller Taktung: ja – besonders mit Tools, die echtes Browser-Rendering, Sitzungsunterstützung und Drosselung mitbringen. Kein Tool ist als universelle Garantie zu verstehen. Cloud-Scraping mit rotierenden IPs funktioniert gut für öffentliche Katalogseiten; Browser-Scraping mit Ihrer aktuellen Sitzung ist besser, sobald Region, Login oder Pop-ups die Daten beeinflussen.
Welche Daten kann ich aus Temu-Produktseiten extrahieren?
Häufige öffentliche Felder sind Produkttitel, URL, aktueller Preis, Originalpreis, Rabattprozentsatz, Bild-URLs, Sternebewertung, Anzahl der Rezensionen, Verkaufszahl, Verkäufer-/Shop-Name, Versandinformationen, Kategorie, Produktspezifikationen, Varianten (Farben, Größen) und der Scrape-Zeitstempel. Welche Felder konkret verfügbar sind, hängt vom Seitentyp (Listing vs. Detailseite) und der Region ab.
Brauche ich Proxys, um Temu zu scrapen?
Für kleine manuelle Extraktionen im Browser-Modus (ein paar Seiten auf einmal) eventuell nicht. Für Cloud-, geplante oder hochvolumige Erfassung sind Proxys oder eine verwaltete Anti-Blocking-Infrastruktur in der Regel nötig. Tools wie Thunderbit, Bright Data und ScraperAPI bündeln die Proxy-Verwaltung in ihrer Plattform, sodass Sie sie nicht separat einrichten müssen.
Wenn Sie tiefer in verwandte Themen einsteigen möchten, schauen Sie sich unsere Leitfäden zu Web-Scraping für Preisvergleiche, den besten E-Commerce-Web-Scrapern, Daten von Websites nach Excel scrapen und Scraping in Google Sheets an. Außerdem finden Sie Walkthroughs auf dem Thunderbit-YouTube-Kanal.
Thunderbit für Temu-Scraping testen Get Started Free
Mehr erfahren




