

„Bis Freitag brauche ich Preise, Beschreibungen und Variantendaten aus 14 konkurrierenden Shopify-Stores“ – mit dieser Bitte meldete sich kürzlich einer unserer Nutzer. Hinter dieser einen Zeile stecken rund 4.000 Produktseiten. Per Hand kopieren? Keine Chance.
Den Schmerz kennst du, wenn du je versucht hast, Produktdaten aus einem Shopify-Store herauszuholen – Preise, Bilder, Beschreibungen, Varianten, Bewertungen. 2026 zählt das Netz über 2,8 Millionen aktive Shopify-Stores, und keiner davon stellt dir einen Button für „Export für Außenstehende“ bereit. Parallel überwachen laut Umfrage 72 % der Unternehmen aktiv die Preise ihrer Wettbewerber, und E-Commerce-Dienstleister berichten, dass allein das händische Hochladen eines einzelnen Produkts samt Varianten und Bildern 15 bis 30 Minuten frisst. Rechne das auf ein paar Hundert Produkte hoch – und schon ist die ganze Woche dahin.
Kein Wunder also, dass Shopify-Scraper-Chrome-Erweiterungen im E-Commerce inzwischen zum Standardrepertoire gehören – für Wettbewerbsanalysen, Dropshipping-Recherche, Katalogmigration und vieles mehr. Die meisten „beste Scraper“-Artikel klappern allerdings bloß Funktionslisten ab, ohne zu zeigen, was tatsächlich passiert, sobald man sie auf echte Shopify-Stores loslässt. Dieser hier macht es anders. Ich habe acht Erweiterungen an echten Stores getestet, bin auf echte Anti-Bot-Hürden gestoßen und herausgefunden, welche Tools dir die tiefen Produktdaten liefern, die du brauchst – und welche schon an der Oberfläche schlappmachen.
Warum E-Commerce-Teams eine Shopify-Scraper-Chrome-Erweiterung brauchen
Shopify-Stores sind randvoll mit kommerziell wertvollen Produktdaten. Doch als Außenstehender bekommst du keinen CSV-Download – du bekommst einen Onlineshop. Um diesen Shop in verwertbare Erkenntnisse zu übersetzen, brauchst du einen Scraper, und die Anwendungsfälle reichen weit über „Ich hätte gern eine Liste von Produktnamen“ hinaus.
Die entscheidende Frage lautet: Welche Daten brauchst du wirklich, und für welchen Workflow? So lassen sich die häufigsten E-Commerce-Use-Cases konkreten Datenfeldern zuordnen:
Wettbewerbsrecherche zu Preisen
Du brauchst: Produkttitel, Preise, Vergleichspreise und Preise auf Variantenebene. Das ist das Fundament jeder dynamischen Preisstrategie – nicht nur zu wissen, was ein Wettbewerber verlangt, sondern auch, wie er rabattiert, bündelt und nach Größen oder Farben staffelt.
Produktrecherche für Dropshipping
Du brauchst: Titel, alle Bilder (nicht nur Thumbnails), vollständige Beschreibungen und Veröffentlichungsdaten. Sortierst du nach dem jüngsten Veröffentlichungsdatum, fischst du Trendprodukte oder frisch gelaunchte Artikel heraus, bevor der Markt sie überschwemmt.
Katalogimport in deinen eigenen Store
Du brauchst: Titel, Body-HTML, alle Bilder, Varianten, SKUs und Preise – im Idealfall in einer Shopify-Import-CSV. Das bekommt nicht jedes Tool sauber hin.
Schätzung der Verkaufsdynamik
Du brauchst: Produkttitel und Bestandsmengen, über die Zeit hinweg erfasst. Wer Bestände regelmäßig als Snapshot festhält, kann abschätzen, wie zügig ein Wettbewerber Produkte verkauft – ein grober, aber brauchbarer Näherungswert, solange direkte Verkaufsdaten fehlen.
Lead-Generierung (Store-Betreiber finden)
Du brauchst: Store-Name, Kontakt-E-Mail, Telefonnummer und mitunter die Apps oder den Tech-Stack eines Stores. Vertriebsteams segmentieren damit ihre Outreach-Listen nach Nische oder Technologie.
Hier eine kurze Übersicht:
| Anwendungsfall | Benötigte Schlüsseldatenfelder | Empfohlener Workflow |
|---|---|---|
| Wettbewerbsrecherche zu Preisen | Titel, Preis, Vergleichspreis, Variantenpreise | Listing-Seite scrapen + Unterseiten-Anreicherung für Varianten |
| Produktrecherche für Dropshipping | Titel, Preis, Bilder (alle), Beschreibung, Veröffentlichungsdatum | Unterseiten-Scrape + Sortierung nach neuestem Veröffentlichungsdatum |
| Katalogimport in deinen Store | Titel, Body-HTML, Bilder, Varianten, SKU, Preis | Vollständiger Unterseiten-Scrape → Export als Shopify-Import-CSV |
| Verkaufsschätzung | Titel, Bestandsmenge (über die Zeit) | Geplantes Scraping → Tracking in Google Sheets |
| Lead-Generierung (Store-Betreiber) | Store-Name, E-Mail, Telefon, verwendete Apps | Store-Kontaktseiten scrapen + E-Mail-/Telefon-Extraktoren |
Wie ich diese 8 Shopify-Scraper-Chrome-Erweiterungen bewertet habe
Ich habe alle acht Erweiterungen installiert und gegen denselben Satz echter Shopify-Stores antreten lassen – öffentliche Stores, von Cloudflare geschützte Stores und solche, bei denen products.json deaktiviert war. Funktionslisten allein haben mich nicht interessiert. Ich wollte sehen, was wirklich passiert, sobald man auf einer Live-Collection-Seite von Shopify auf „Scrape“ klickt.
Das sind die acht Kriterien, die ich angelegt habe, und warum jedes davon speziell bei Shopify zählt:
| Kriterium | Warum es beim Shopify-Scraping wichtig ist |
|---|---|
| Einrichtungsaufwand | Kann ein technisch nicht versierter Dropshipper in unter 5 Minuten mit dem Scrapen beginnen? |
| Extrahierte Datenfelder | Erfasst das Tool Titel, Preis, Bilder, Beschreibungen, Varianten UND Bewertungen — oder nur Oberflächendaten? |
| Unterseiten-Anreicherung | Kann es eine Listing-Seite scrapen und dann automatisch jede Produktseite für vollständige Details besuchen? |
| Paginierung | Kann es über die erste Produktseite hinaus scrapen (Pagination klicken oder endloses Scrollen)? |
| Anti-Bot-Resistenz | Kommt es mit Cloudflare Turnstiles oder Shopifys Bot-Schutz zurecht, ohne zu brechen? |
| Exportformate | CSV, Excel, Google Sheets, Airtable, Notion, Shopify-Import-CSV? |
| Geplantes/wiederkehrendes Scraping | Kann es Preise oder Lagerbestände automatisch über die Zeit überwachen? |
| Preistransparenz | Freemium-Limits, Credit-System, Pauschalpreis — und was du tatsächlich bekommst |
Mit diesem Rahmen sehen wir uns nun an, wie jedes Tool abgeschnitten hat.
1. Thunderbit — Der KI-gestützte Shopify-Scraper für Nicht-Programmierer
Thunderbit ist das Tool, das wir bei Thunderbit eigens für Business-Anwender gebaut haben, die tiefe Produktdaten wollen, ohne Code zu schreiben, CSS-Selektoren zu konfigurieren oder 20 Minuten in die Einrichtung zu stecken. In einem Shopify-Store läuft das in zwei Klicks: Collection-Seite öffnen, auf „KI-Felder vorschlagen“ klicken – die KI liest die Seite und schlägt Spalten vor (Titel, Preis, Bild usw.). Ein Klick auf „Scrape“, und die Listing-Seite steht.
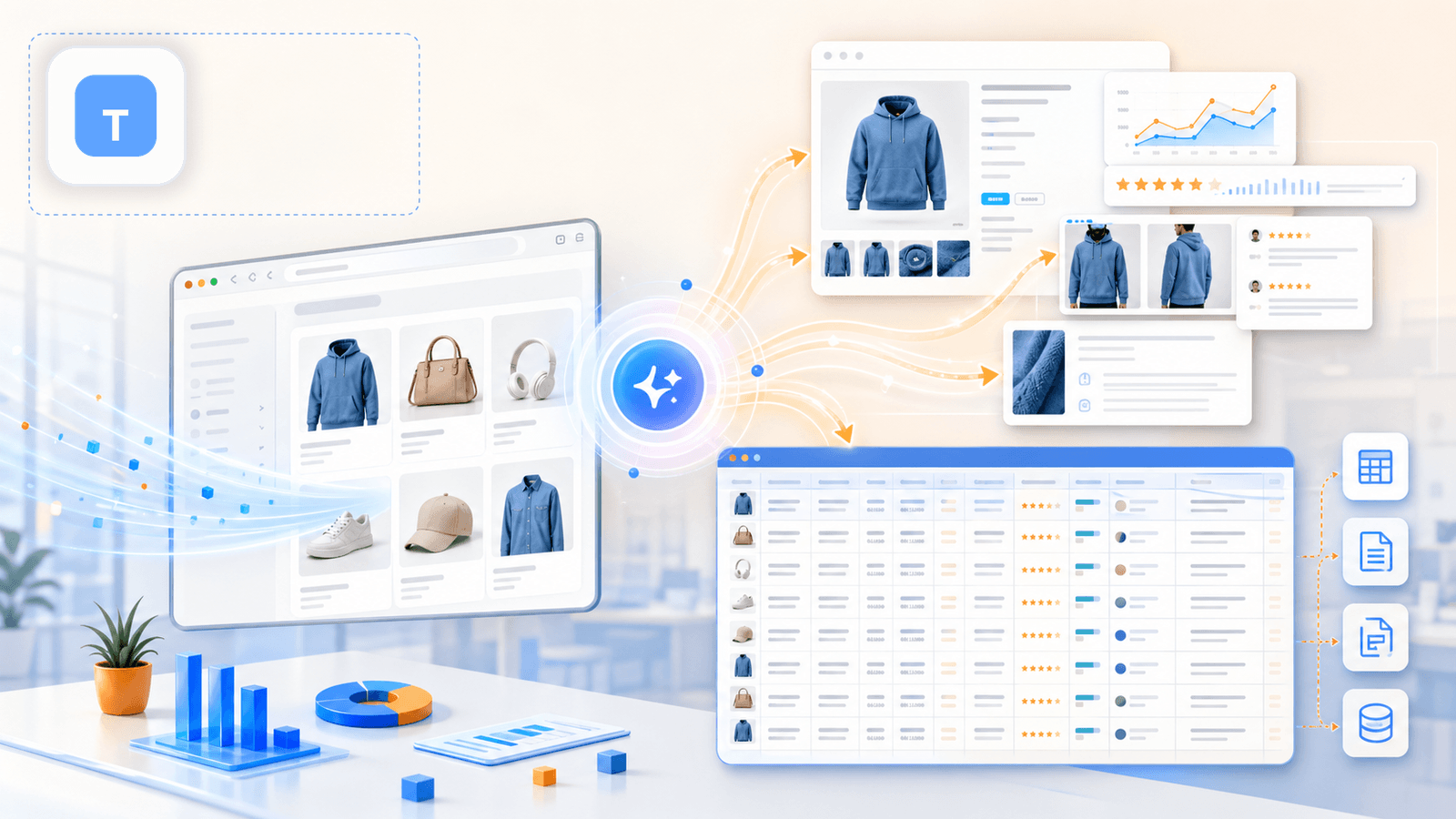
Der eigentliche Unterschied – und genau das übergehen die meisten Vergleichsartikel – kommt erst danach.
Unterseiten-Anreicherung: Die Funktion, die alles verändert
Sobald die Listing-Seite gescrapt ist, klickst du auf „Unterseiten scrapen“. Die KI von Thunderbit steuert jede einzelne Produkt-URL an und hängt die Detailseitendaten an deine ursprüngliche Tabelle: vollständige Beschreibungen, sämtliche Galeriebilder, Variantenoptionen, SKUs, Anzahl der Bewertungen und mehr. Genau dieser Schritt macht aus einer flachen Tabelle einen brauchbaren Datensatz für die Wettbewerbsanalyse.
Warum das so wichtig ist und wie der Vorher-Nachher-Vergleich ausfällt, zeige ich weiter unten in einem eigenen Abschnitt.
Stärken beim Shopify-Scraping
- KI-Felder vorschlagen liest die Shopify-Seite und erzeugt automatisch die passende Spaltenstruktur — keine CSS-Selektoren, keine manuelle Einrichtung
- Unterseiten-Scraping füllt die Lücken, die Listing-Seiten offenlassen (vollständige Beschreibungen, Variantenoptionen, Bildergalerien, Bewertungen)
- Cloud-Scraping-Modus für schnelles Massen-Extrahieren auf öffentlichen Stores; Browser-Scraping-Modus für Cloudflare-geschützte oder loginpflichtige Stores
- Paginierung per Klick und mit Endlos-Scroll
- Geplantes Scraping für laufende Preis-/Bestandsüberwachung — den Zeitplan einfach in normalem Deutsch beschreiben (z. B. „jeden Montag um 9 Uhr“)
- Kostenlose E-Mail- und Telefon-Extraktoren für Lead-Gen-Anwendungsfälle
- Export nach Excel, Google Sheets, Airtable, Notion, CSV, JSON — einschließlich Shopify-freundlicher Importformate
- Feld-KI-Prompt ermöglicht benutzerdefinierte Anweisungen pro Spalte (z. B. „in 3 Produkttypen einordnen“ oder „Beschreibung ins Englische übersetzen“)
Wo es Schwächen hat
- Die Credit-basierte Preisstruktur bedeutet, dass sehr große Scrapes (Zehntausende Produkte) einen kostenpflichtigen Plan erfordern
- Die KI-Verarbeitung dauert pro Zeile ein paar Sekunden länger als templatebasierte Scraper bei sehr einfachen Seiten
Preise
- Gratis-Tarif: 6 Seiten (oder bis zu 10 mit der kostenlosen Testphase), alle Exporte gratis
- Starter: 15 $/Monat, 500 Credits/Monat
- Professional-Tarife: ab 38 $/Monat (3.000 Credits) bis 249 $/Monat (20.000 Credits)
- Credit-Regeln: 1 Ausgabereihe = 1 Credit beim Web-Scraping; 1 Ausgabereihe = 2 Credits beim Unterseiten-Scraping; Exporte sind immer kostenlos
Am besten für: Nicht-technische E-Commerce-Teams, die die tiefsten Shopify-Produktdaten mit minimalem Aufwand brauchen — und Wettbewerber über Zeit überwachen wollen.
Thunderbit für Shopify-Scraping testen
2. Instant Data Scraper — Die Zero-Config-Auto-Erkennung
Instant Data Scraper ist eine kostenlose Chrome-Erweiterung, die mit heuristischen Algorithmen tabellarische Daten auf Webseiten automatisch aufspürt. Konfiguriert wird hier überhaupt nichts – Shopify-Collection-Seite öffnen, aufs Erweiterungs-Icon klicken, und das Tool versucht, die Produktdaten als Tabelle zu erkennen und anzuzeigen.
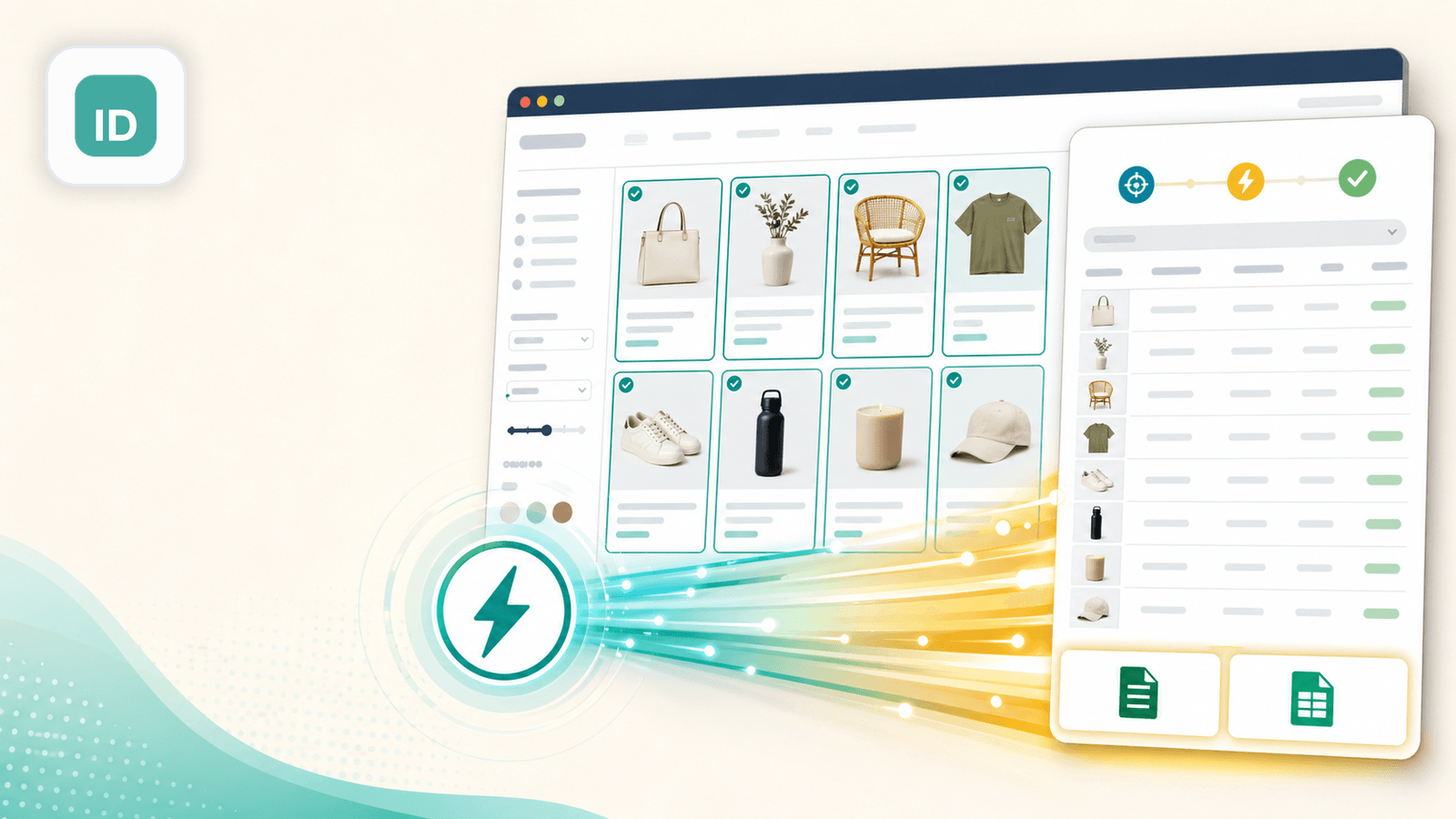
In meinen Tests klappte das auf gewöhnlichen Shopify-Dawn-Theme-Collection-Seiten gut und schnappte sich binnen Sekunden Titel, Preise und Thumbnail-URL-Bilder. Bei Stores mit unüblichen Layouts zog es hin und wieder Navigationslinks oder Footer-Inhalte statt Produkte – die Ausgabe solltest du also genau prüfen.
Stärken beim Shopify-Scraping
- Komplett kostenlos, ohne Nutzungslimits
- Auto-Erkennung bedeutet null Einrichtungszeit — gut für schnelle Einmal-Exporte
- Unterstützt Paginierung (kann automatisch auf „nächste Seite“ klicken)
- Export nach CSV und XLSX
Wo es Schwächen hat
- Die Auto-Erkennung ist bei Shopify-Stores mit ungewöhnlichen Layouts nicht immer zuverlässig
- Keine Unterseiten-Anreicherung: Du bekommst, was auf der Listing-Seite steht (Titel, Preis, Thumbnail), aber keine vollständigen Beschreibungen, Varianten oder Bewertungen
- Keine KI zum Bereinigen, Labeln oder Transformieren von Daten
- Kein Scheduling, kein Cloud-Scraping
- Kein direkter Export nach Google Sheets, Airtable oder Notion
Preise
- Komplett kostenlos
Am besten für: Alle, die einen schnellen, kostenlosen und einrichtungsfreien Export sichtbarer Listing-Daten aus einem Standard-Shopify-Store brauchen.
3. Web Scraper — Der visuelle Sitemap-Builder
Web Scraper (webscraper.io) ist der Klassiker zum Anklicken und Konfigurieren von „Sitemaps“ – Scraping-Rezepten, bei denen du Seitenelemente auswählst und einen Scraping-Flow definierst. Bei Shopify würdest du eine Sitemap erstellen, indem du Produkttitel, Preise und Bilder anklickst und Regeln für Paginierung und Link-Folgen festlegst.
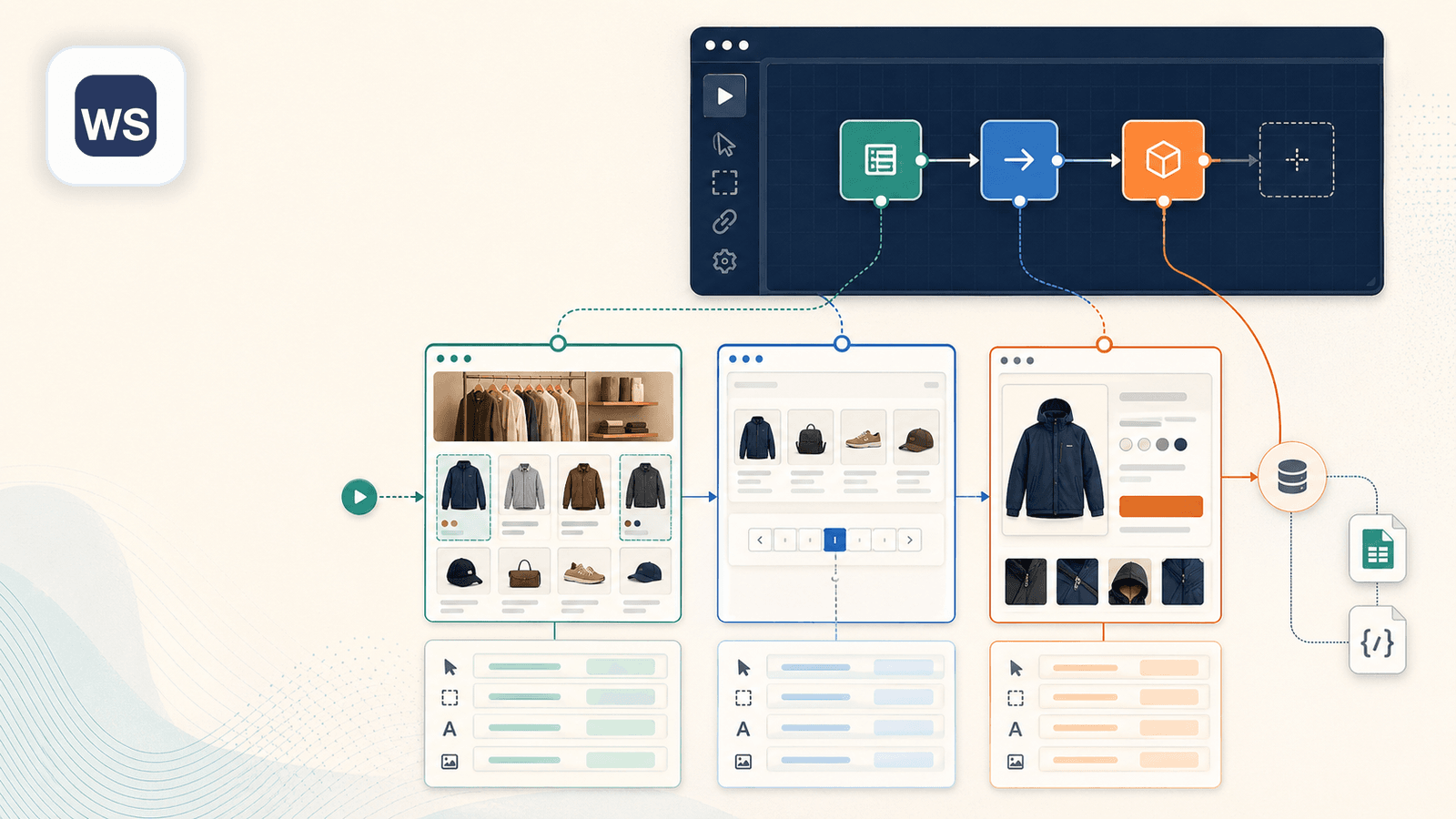
Stärken beim Shopify-Scraping
- Visueller Selektor-Builder bietet mehr Kontrolle als Auto-Erkennungs-Tools
- Kann Links zu Unterseiten folgen (Produktdetailseiten) — erfordert aber, dass du Parent-Child-Selektoren in der Sitemap manuell konfigurierst
- Handhabt Paginierung mit korrekter Einrichtung
- Kostenloses browserbasiertes Scraping; bezahlte Cloud-Scraping-Pläne verfügbar (ab 50 $/Monat)
- Export nach CSV; Cloud-Pläne unterstützen Google Sheets und andere Formate
Wo es Schwächen hat
- Die Einrichtung ist zeitaufwendiger: Für einen neuen Shopify-Store hat das Erstellen einer Sitemap mit Parent-Child-Selektoren etwa 15 Minuten gedauert
- Unterseiten-Scraping erfordert manuelle Konfiguration von Link-Selektoren und Child-Sitemaps — also keine Anreicherung per Klick
- Sitemaps brechen, wenn Shopify-Stores ihr Layout oder ihre CSS-Klassen ändern
- Die Lernkurve ist steiler als bei KI-gestützten Alternativen
Preise
- Browser-Erweiterung: Kostenlos
- Cloud-Pläne: Project 50 $/Monat, Professional 100 $/Monat, Scale ab 200 $/Monat
Am besten für: Technische Nutzer, die granulare Kontrolle über ihren Scraping-Flow wollen und kein Problem damit haben, das Rezept selbst zu bauen.
4. Data Miner — Der rezeptbasierte Scraper
Data Miner (dataminer.io) baut auf „Rezepten“ – vorgefertigten oder selbst erstellten Scraping-Vorlagen, die du auf eine Seite anwendest. Dank öffentlicher Rezeptbibliothek findest du vielleicht eine von anderen Nutzern geteilte Shopify-Vorlage, oder du strickst dir deine eigene, indem du Seitenelemente auswählst.
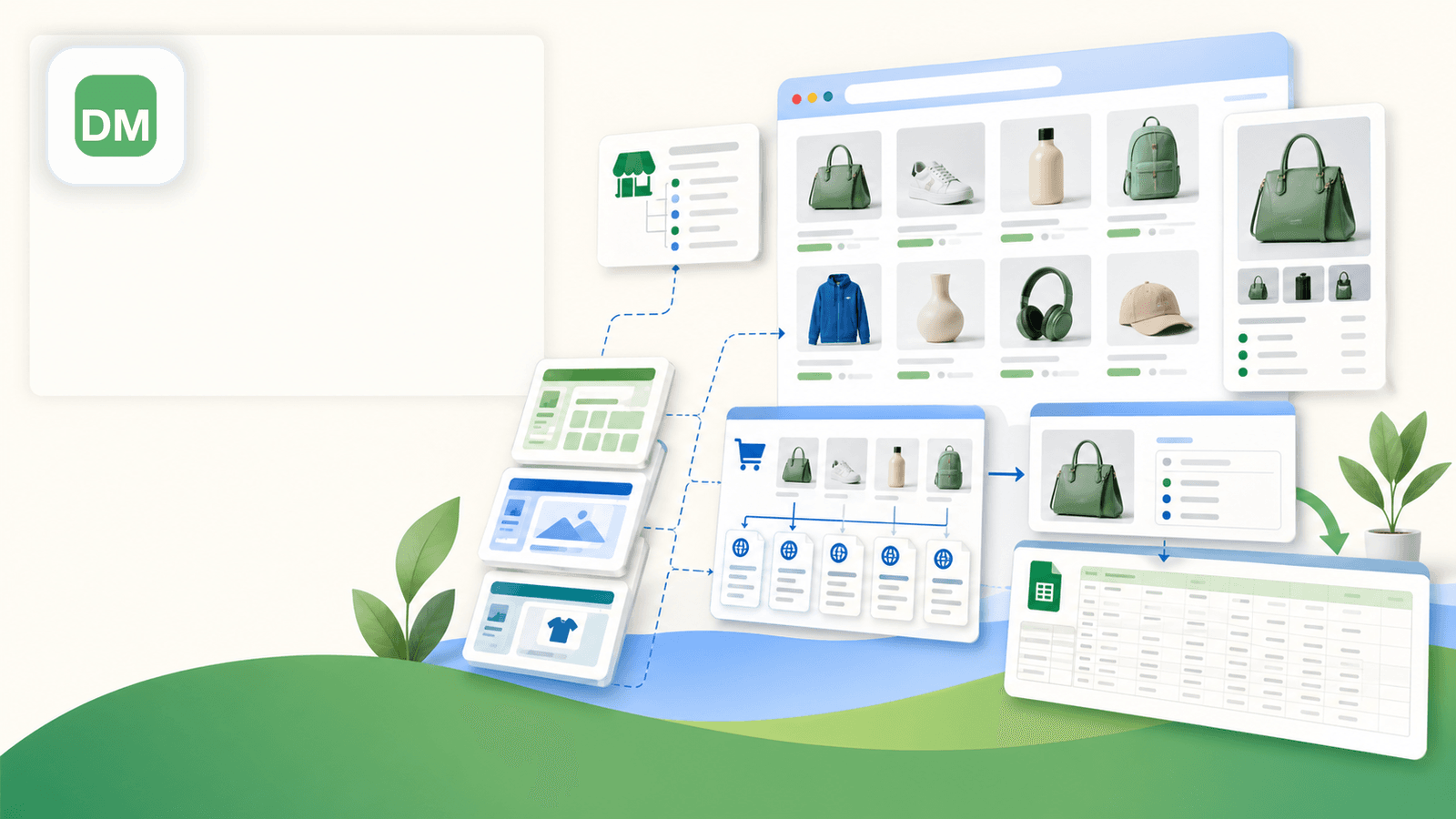
Stärken beim Shopify-Scraping
- Die Rezeptbibliothek kann vorgefertigte Shopify-Vorlagen von anderen Nutzern enthalten
- Visueller Rezept-Builder für benutzerdefinierte Scraping-Konfigurationen
- Handhabt Paginierung über die Rezeptkonfiguration
- Export nach CSV, Excel, Google Sheets und TSV
- Crawl-Workflows zum Besuchen von Detailseiten nach Listenseiten
Wo es Schwächen hat
- Der Gratis-Tarif ist auf 500 Seiten/Monat begrenzt
- Rezepte basieren auf CSS-Selektoren und brechen daher, wenn sich Layouts ändern
- Keine KI-gestützten Feldvorschläge oder Datentransformation
- Kein integrierter Ein-Klick-Workflow für Unterseiten-Anreicherung — dafür ist ein separater Crawl-Rezept für Detailseiten nötig
- Geplante Crawls gibt es zwar, aber das Scheduling ist nicht das simpelste
Preise
- Gratis: 500 Seiten/Monat
- Solo: 19,99 $/Monat
- Small Business: 49 $/Monat
- Business: 99 $/Monat
- Business Plus: 200 $/Monat
Am besten für: Nutzer, die gern mit Vorlagen arbeiten und eine Rezeptbibliothek nutzen wollen, um die Einrichtung bei gängigen Seiten zu beschleunigen.
5. Simplescraper — Der leichte Extraktor
Simplescraper (simplescraper.io) ist eine minimalistische Chrome-Erweiterung samt cloudbasiertem Scraper, der ganz auf Schlichtheit setzt. Du klickst Datenelemente auf einer Shopify-Seite an, Simplescraper erzeugt daraus CSS-Selektoren und extrahiert die passenden Daten.
Stärken beim Shopify-Scraping
- Aufgeräumte, minimalistische Oberfläche — schnell zu lernen
- Cloud-Scraping für geplante und Massen-Jobs verfügbar
- API-Zugang für Entwickler, die Scrapedaten in Workflows integrieren wollen
- Export nach CSV, JSON, Google Sheets, Airtable und per Webhooks
- Konzept für Deep Scraping zum Folgen von Links zu Detailseiten
- Login-fähige Workflows für session-sensitive Stores
Wo es Schwächen hat
- Manueller, selektorbasierter Ansatz — keine KI zur automatischen Felderkennung
- Unterseiten-Scraping erfordert zusätzliche Konfiguration
- Kleinere Community und weniger vorgefertigte Vorlagen als Web Scraper oder Data Miner
- Gratis-Tarif: 100 Credits (1 JS-gerenderte Seite = 2 Credits)
- Die Preise der kostenpflichtigen Tarife sind auf der offiziellen Website weniger transparent als bei den meisten Wettbewerbern
Preise
- Gratis: 100 Credits
- Bezahlte Pläne: Drittanbieterquellen nennen Plus mit ca. 39 $/Monat, Pro mit ca. 70 $/Monat, Premium mit ca. 150 $/Monat (laut G2-Preisdaten)
Am besten für: Nutzer, die einen leichten, modernen Cloud-Scraper mit guten Integrationen wollen und keine KI-gestützte Felderkennung brauchen.
6. Octoparse — Die Chrome-Erweiterung mit Desktop-Power
Octoparse (octoparse.com) ist vor allem eine Desktop-Anwendung mit zugehöriger Chrome-Erweiterung. Sie bringt sowohl einen visuellen Workflow-Builder als auch fertige Vorlagen für beliebte Seiten mit, darunter ein Shopify-spezifisches Scraping-Tutorial.

Stärken beim Shopify-Scraping
- Vorgefertigte Shopify-Vorlagen für gängige Aufgaben
- Leistungsstarke Desktop-App mit erweiterten Funktionen: IP-Rotation, geplantes Scraping, Cloud-Extraktion
- Handhabt Paginierung, Endlos-Scrollen und AJAX-geladene Inhalte gut
- In dieser Liste die stärkste dokumentierte Anti-Bot-Unterstützung, einschließlich automatischer CAPTCHA-Behandlung
- Export nach CSV, Excel, JSON, HTML, XML, Datenbanken und Google Sheets
Wo es Schwächen hat
- Die Chrome-Erweiterung allein ist eingeschränkt — die meisten Power-Funktionen erfordern die Desktop-App
- Die Desktop-App hat mit ihrem visuellen Workflow-Builder eine steilere Lernkurve
- Der Gratis-Tarif ist eingeschränkt; sinnvoll nutzbar ist das Tool erst mit einem kostenpflichtigen Plan
- Schwerfälligeres Setup als reine Chrome-Erweiterungs-Tools — nicht ideal für einen schnellen 5-Minuten-Scrape
- Die Desktop-App gibt es nur für Windows/Mac (also nicht rein browserbasiert)
Preise
- Gratis-Plan verfügbar
- Basic: 39 $/Monat
- Standard: ca. 83 $/Monat (monatlich), ca. 75 $/Monat (jährlich)
- Professional: ca. 299 $/Monat (monatlich), ca. 208 $/Monat (jährlich)
- Enterprise: individuell
Am besten für: Teams, die Scraping auf Enterprise-Niveau mit IP-Rotation, Anti-Bot-Handling und wiederkehrenden Cloud-Jobs brauchen — und denen eine Desktop-App nichts ausmacht.
7. Bardeen — Der Automatisierungs-Scraper zuerst
Bardeen (bardeen.ai) ist eine Browser-Automatisierungsplattform, die Web-Scraping mit Workflow-Automatisierung verbindet. Nutzer bauen „Playbooks“, die Daten scrapen und anschließend an andere Apps weiterreichen – nach dem Motto „Wenn ich das scrape, schiebe ich es in mein CRM“.

Stärken beim Shopify-Scraping
- Workflow-Automatisierung über das reine Scraping hinaus: Shopify-Daten scrapen → anreichern → in einem Playbook an CRM oder Tabellenkalkulation senden
- Integrationen mit über 100 Apps (Google Sheets, Airtable, Notion, HubSpot, Slack usw.)
- KI-gestützte Funktionen für Datenerfassung und Klassifizierung
- Läuft im Browser — keine Desktop-App nötig
- Zeit-/datumsbasierte Automatisierungen für Scheduling
Wo es Schwächen hat
- Primär ein Automatisierungstool, kein dedizierter Scraper — die Scraping-Funktionen sind weniger tief als bei spezialisierten Tools
- Das Erstellen von Playbooks kann für Nutzer verwirrend sein, die einfach nur eine Produktliste extrahieren wollen
- Gratis-Tarif auf 100 Credits begrenzt
- Unterseiten-Anreicherung und Paginierung sind weniger intuitiv als bei dedizierten Scraping-Tools
- Overkill, wenn du nur Daten scrapen willst, ohne nachgelagerte Automatisierung
Preise
- Gratis: 100 Credits
- Basic: 10 $/Monat, 100 Credits/Monat
- Premium: 50 $/Monat, 1.000 Credits/Monat (ca. 40 $/Monat bei jährlicher Zahlung)
- Enterprise: individuell
- Credit-Modell: 1 Credit pro Scraper-Zeile, 3 Credits pro Anreicherungszeile
Am besten für: Teams, die Shopify-Daten scrapen und sie sofort in nachgelagerte Apps (CRMs, Tabellen, Slack) in einem automatisierten Workflow weitergeben wollen.
8. Listly — Der Listen-zu-Tabellen-Converter
Listly (listly.io) wurde von Grund auf dafür entworfen, Listen und Tabellen von Webseiten in tabellenfertige Daten zu verwandeln. Du klickst die Erweiterung auf einer Shopify-Collection-Seite an, und Listly versucht, die Produktliste zu erkennen und als Tabelle auszugeben.

Stärken beim Shopify-Scraping
- Extrem einfache Oberfläche — für Ein-Klick-Listenextraktion gemacht
- Gut darin, wiederholte Listenstrukturen zu erkennen (wie Produktgitter)
- Export direkt nach Excel und Google Sheets
- Gruppen-Scraping-Funktion für mehrere URLs auf einmal
- Scheduling in Business-Plänen verfügbar
Wo es Schwächen hat
- Beschränkt auf das, was auf der Seite automatisch erkannt wird — keine benutzerdefinierte Feldkonfiguration
- Keine Unterseiten-Anreicherung — exportiert nur Daten auf Listing-Ebene
- Hat Probleme mit unüblichen Shopify-Themes oder stark JavaScript-gerenderten Stores
- Der Gratis-Tarif ist sehr limitiert (10 URLs/Monat)
- Weniger Exportoptionen als die Konkurrenz (hauptsächlich Excel und Sheets)
Preise
- Gratis: 10 URLs/Monat, einfache Extraktion einer Seite, Excel-Download, Google-Sheets-Export
- Light: 30 $/Monat (187,20 $/Jahr bei jährlicher Zahlung)
- Business: 90 $/Monat (993,60 $/Jahr bei jährlicher Zahlung) — inklusive erweiterter Extraktion, Gruppenextraktion, Scheduling, Auto-Scroll/Klick, API-Beta
Am besten für: Nutzer, die den einfachsten Weg von einer Shopify-Collection-Seite zu einer Tabelle wollen — und keine tiefen Produktdaten brauchen.
Alle 8 Shopify-Scraper-Chrome-Erweiterungen im Vergleich
Hier kommt der vollständige Direktvergleich. Ich habe versucht, jedes Feld so konkret wie möglich zu formulieren, statt bloß Häkchen zu setzen – denn „unterstützt Paginierung“ bedeutet je nach Tool etwas völlig anderes.
| Tool | Einrichtungsaufwand | Datenfelder | Unterseiten-Anreicherung | Paginierung | Anti-Bot-Handling | Exportformate | Scheduling | Gratis-Tarif / Preise |
|---|---|---|---|---|---|---|---|---|
| Thunderbit | Sehr einfach (KI-geführt, 2 Klicks) | Am stärksten für nicht-technische Nutzer (KI schlägt alle relevanten Felder vor) | Ja — Anreicherung mit einem Klick | Ja (Klick + Endlos-Scroll) | Cloud für öffentliche, Browser für geschützte Stores | Sheets, Airtable, Notion, CSV, JSON, Excel | Ja (Scheduling in normalem Deutsch) | 6 Seiten gratis; kostenpflichtig ab 15 $/Monat |
| Instant Data Scraper | Extrem einfach (keine Konfiguration) | Gut nur für Daten auf Listing-Ebene | Nein | Ja (erkennt „nächste Seite“ automatisch) | Nur Browser, keine Anti-Bot-Story | CSV, XLSX | Nein | Kostenlos |
| Web Scraper | Mittel bis schwer (manuelle Sitemap) | Flexibel, wenn die Sitemap gut gebaut ist | Ja, aber manuell über Link-Selektoren | Ja (mit Sitemap-Konfiguration) | Lokal im Browser; Proxy-Rotation in Cloud-Plänen | Lokal CSV; in der Cloud breiter | Ja in Cloud-Plänen | Erweiterung gratis; Cloud ab 50 $/Monat |
| Data Miner | Mittel (rezepbasiert) | Gut, wenn ein Rezept existiert oder gebaut wird | Ja, aber mehrstufiges Crawl-Setup | Ja (Rezept-Konfiguration) | Meist browserseitig | CSV, Excel, Sheets, TSV | Automatisierte Crawls vorhanden | 500 Seiten/Monat gratis; kostenpflichtig ab 19,99 $/Monat |
| Simplescraper | Einfach bis mittel (selektorbasiert) | Solide für leichte Extraktion | Deep Scraping existiert, aber nicht per Klick | Ja (Endlos-Scroll wird unterstützt) | Proxy-Rotation und loginfreundlich | CSV, JSON, Sheets, Airtable, Webhooks | Ja | 100 Credits gratis; kostenpflichtige Tarife vorhanden |
| Octoparse | Schwieriger (Desktop-App) | Sehr stark, wenn korrekt konfiguriert | Ja, über Workflows oder Vorlagen | Ja (AJAX, Endlos-Scroll) | Am stärksten gegen Bots (IP-Rotation, CAPTCHA) | CSV, Excel, JSON, HTML, XML, DBs, Sheets | Ja ab Standard | Gratis; Basic 39 $/Monat; Cloud ab ca. 83 $/Monat |
| Bardeen | Mittel (Playbook-Builder) | Gut, wenn mit Automatisierung verknüpft | Möglich in der Workflow-Logik, nicht Shopify-first | Möglich | Läuft im Browser, Anti-Bot nicht Kernfunktion | CSV, Sheets, Airtable, Notion | Ja über Automatisierungen | 100 Credits gratis; Basic 10 $/Monat; Premium 50 $/Monat |
| Listly | Sehr einfach (Listen-Erkennung per Klick) | Am besten nur für sichtbare Listenzeilen | Nein | Beschränkt auf die erkannte Listenstruktur | Minimal | Excel, Sheets, CSV/JSON-API im Business-Tarif | Ja im Business-Tarif | 10 URLs/Monat gratis; Light 30 $/Monat; Business 90 $/Monat |
Kurzfazit nach Priorität
Brauchst du die tiefsten Shopify-Produktdaten bei minimalem Setup, ist Thunderbits Kombination aus KI und Unterseiten-Anreicherung am stärksten. Geht es dir um einen komplett kostenlosen, schnellen und unkomplizierten Export, leistet Instant Data Scraper bei einfachen Seiten gute Dienste. Willst du volle Kontrolle und baust gern Rezepte, geben dir Web Scraper oder Octoparse diese Macht. Und ist dein eigentliches Ziel scrapen → automatisieren → ans CRM senden, lohnt sich ein Blick auf Bardeen als Workflow-Plattform.
Die Listing-Seite zu scrapen ist nur die halbe Miete: Der Workflow zur Unterseiten-Anreicherung
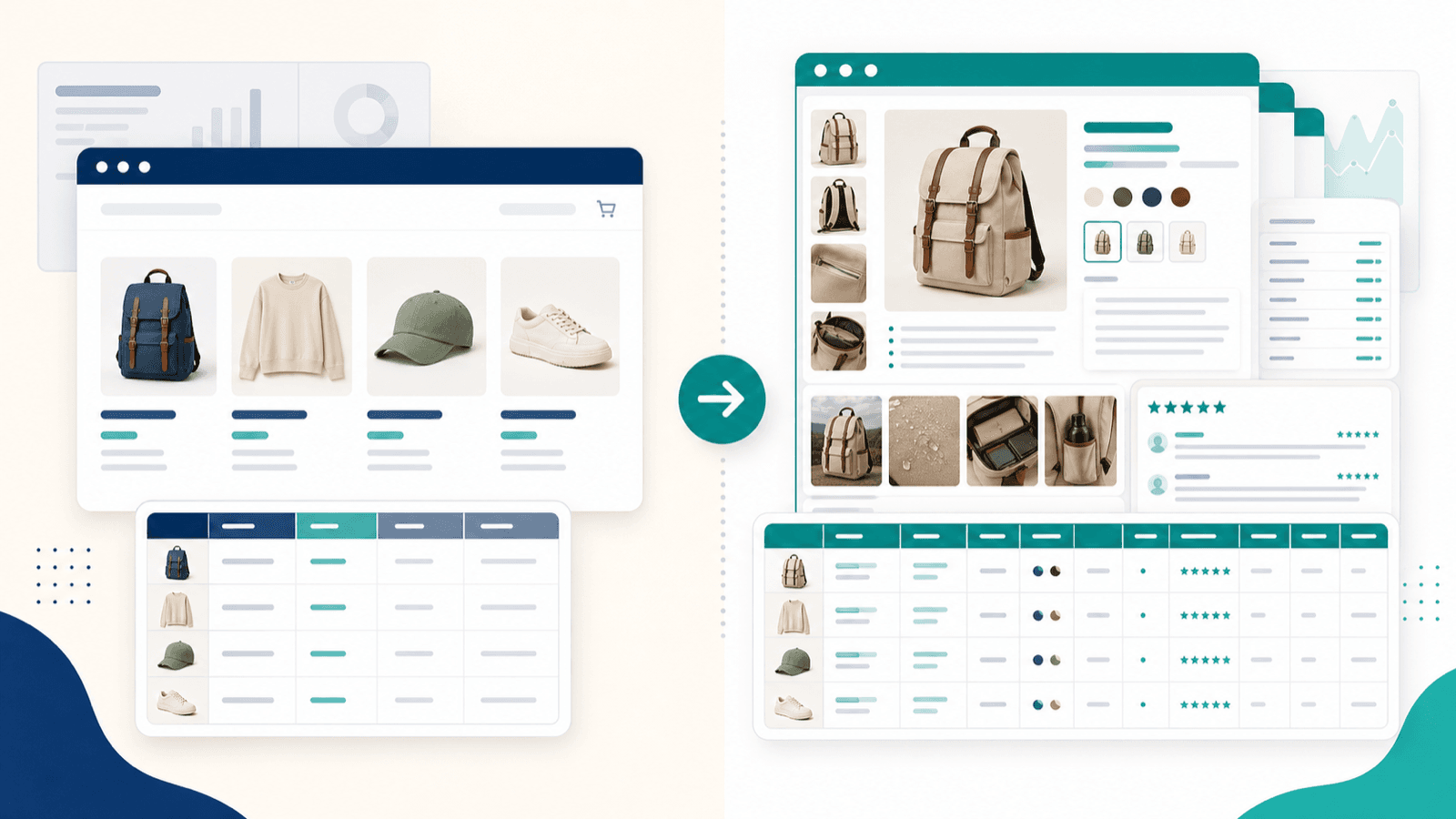
Das ist der Abschnitt, den ich mir in jedem anderen Shopify-Scraper-Artikel wünschen würde – denn genau hier klafft die größte Lücke bei der Konkurrenz, und genau diese Frustration höre ich von E-Commerce-Nutzern am häufigsten.
Scrapst du eine Shopify-Collection-Seite (die Listing-Seite), bekommst du Oberflächendaten: Titel, Preise, Thumbnails, vielleicht eine gekürzte Beschreibung. Doch die Felder, auf die es bei Wettbewerbsanalysen, Katalogimporten oder Dropshipping-Recherche wirklich ankommt, liegen auf den einzelnen Produktdetailseiten.
Was du von der Listing-Seite bekommst vs. nach der Unterseiten-Anreicherung
| Datenfeld | Nur von der Listing-Seite | Nach der Unterseiten-Anreicherung |
|---|---|---|
| Produkttitel | ✅ | ✅ |
| Preis | ✅ | ✅ |
| Vorschaubild | ✅ | ✅ + alle Bilder der Galerie |
| Kurzbeschreibung | ⚠️ Gekürzt | ✅ Vollständige HTML-Beschreibung |
| Varianten (Größe, Farbe) | ❌ | ✅ |
| SKU / Bestand | ❌ | ✅ |
| Bewertungen / Ratings | ❌ | ✅ |
Das ist ein gewaltiger Unterschied.
Ein Export nur von der Listing-Seite ergibt eine flache Tabelle. Ein angereicherter Export mit Unterseiten ergibt einen brauchbaren Datensatz für die Wettbewerbsanalyse.
So funktioniert Unterseiten-Scraping in Thunderbit (Schritt für Schritt)
- Zur Collection-/Listing-Seite des Shopify-Stores navigieren
- Auf „KI-Felder vorschlagen“ klicken — Thunderbit liest die Seite und schlägt Spalten vor (Titel, Preis, Bild, Link usw.)
- Auf „Scrape“ klicken, um die Listing-Daten zu extrahieren
- Auf „Unterseiten scrapen“ klicken — die KI besucht jede Produkt-URL und fügt die Detailseitendaten (vollständige Beschreibung, alle Bilder, Varianten, Bewertungen) zur ursprünglichen Tabelle hinzu
- Die angereicherte Tabelle nach Excel, Google Sheets, Airtable, Notion oder CSV exportieren
Bei einer typischen Collection ist der ganze Vorgang in wenigen Minuten erledigt, und am Ende hältst du einen Datensatz in Händen, für den du manuell Stunden gebraucht hättest.
Thunderbit-Unterseiten-Scraping testen
Welche anderen Tools unterstützen Unterseiten-Anreicherung?
- Web Scraper: Ja, aber nur mit manueller Sitemap-Konfiguration über Link-Selektoren und Child-Sitemaps — rechne mit 15–20 Minuten Einrichtung pro Store
- Octoparse: Ja, über Workflow-Builder oder Vorlagen — leistungsstark, aber aufwendiger
- Data Miner: Ja, über mehrstufige Crawl-Workflows — kein Ein-Klick-Prozess
- Simplescraper: Deep-Scraping-Konzept vorhanden, aber weniger out-of-the-box
- Instant Data Scraper, Listly, Bardeen: Keine dokumentierte Unterseiten-Anreicherung per Klick für Shopify
Der Unterschied zwischen „kann Links technisch mit 20 Minuten manueller Einrichtung folgen“ und „Anreicherung per Klick“ ist der Unterschied zwischen einem Tool für Scraper-Ingenieure und einem Tool für E-Commerce-Operatoren.
Wenn Shopifys products.json versagt — und warum Chrome-Erweiterungen dein Backup sind
Hast du andere Shopify-Scraping-Guides gelesen, ist dir der /products.json-Trick wahrscheinlich vertraut: Häng einfach /products.json an eine Shopify-Store-URL, und du bekommst strukturierte Produktdaten im JSON-Format. Es ist ein echter Endpunkt, und wenn er funktioniert, ist er Gold wert.
So funktioniert products.json
Shopify-Stores stellen unter /products.json einen JSON-API-Endpunkt bereit, der strukturierte Produktdaten zurückgibt. Die Paginierung funktioniert mit ?page=2&limit=250 (maximal 250 Produkte pro Seite).
Typischerweise enthaltene Felder: title, body_html, vendor, product_type, tags, published_at, variants (mit price, compare_at_price, sku, available) und images.
Was products.json nicht liefert
- Keine Bewertungsdaten oder Anzahl der Ratings
- Im Vergleich zu gerenderten Seiten eingeschränkte Beschreibungsformatierung
- Benutzerdefinierte Metafelder oft nicht enthalten
- Bilder auf Variantenebene können uneinheitlich sein
- Kein gerenderter Merchandising-Content, keine Badges oder Social Proof
Wann products.json versagt
Am 27. April 2026 habe ich direkte HTTP-Checks gegen acht echte Shopify-Stores laufen lassen. Die Ergebnisse waren aufschlussreich:
| Store | Ergebnis |
|---|---|
| kith.com | ✅ Funktionierte — sauberes JSON |
| colourpop.com | ✅ Funktionierte |
| allbirds.com | ✅ Funktionierte |
| brooklinen.com | ✅ Funktionierte |
| negativeunderwear.com | ✅ Funktionierte |
| gymshark.com | ❌ Blockiert — 403 HTML statt JSON |
| mvmt.com | ⚠️ Teilweise deaktiviert — 200 HTML-Seite, kein JSON |
| fashionnova.com | ❌ Deaktiviert — 404 |
Fünf von acht lieferten sauberes JSON. Drei nicht.
Foren-Nutzer berichten genau dasselbe: „Aus irgendeinem Grund entscheiden sich manche Shopify-Stores dagegen, products.json bereitzustellen.“ Passwortgeschützte Stores, Stores mit eigenen API-Setups und von Cloudflare geschützte Domains können dieses Muster allesamt durchbrechen.
Der Chrome-Erweiterungs-Plan B
Ist products.json nicht verfügbar, holt ein Chrome-Erweiterungs-Scraper die Daten direkt aus der gerenderten Seite (dem DOM). Genau hier liegt der Kernnutzen browserbasierter Scraper: Sie sehen und extrahieren das, was du in deinem Browser siehst – ganz gleich, ob eine API bereitsteht oder nicht. Damit sind Chrome-Erweiterungen der verlässliche Plan B – und oft sogar Plan A, sobald du gerenderte Seitendaten wie Bewertungen, Merchandising-Content oder vollständige Bildergalerien brauchst.
Anti-Bot-Schutz: Was tatsächlich passiert, wenn du Shopify-Stores scrappst
Die meisten Shopify-Scraper-Artikel tun so, als stünde jeder Store sperrangelweit offen. Tut er nicht. Store Leads berichtet, dass 99,2 % der Shopify-Stores Cloudflare-Infrastruktur einsetzen. Das heißt nicht, dass jeder Store Scraper rigoros blockiert – aber es heißt, dass die Infrastruktur zum Blockieren flächendeckend vorhanden ist.
In der Praxis spannt sich das Spektrum so auf:
Leicht zu scrapen
- Öffentliche Stores ohne aggressiven Cloudflare-Schutz
- Stores mit aktivem products.json
- Stores mit Standard-Shopify-Themes (konsistente DOM-Struktur)
Schwerer zu scrapen
- Von Cloudflare geschützte Stores (CAPTCHA-Herausforderungen, Turnstiles)
- Loginpflichtige oder passwortgeschützte Stores
- Shopify-Plus-Stores mit benutzerdefinierten Sicherheitsschichten
- Stores mit aggressivem Rate Limiting
Wie jedes Tool mit Anti-Bot-Szenarien umgeht
| Szenario | Bester Ansatz | Tools, die es schaffen |
|---|---|---|
| Öffentlicher Store, kein Anti-Bot | Cloud-Scraping (schnell) | Thunderbit (Cloud-Modus), Instant Data Scraper, die meisten anderen |
| Von Cloudflare geschützter Store | Browserbasiertes Scraping (nutzt deine Sitzung) | Thunderbit (Browser-Modus), Web Scraper, Octoparse |
| Loginpflichtiger / privater Store | Browser-Scraping mit deiner eingeloggten Sitzung | Thunderbit (Browser-Modus), Web Scraper, Simplescraper |
| products.json deaktiviert | DOM-basierte Extraktion aus der gerenderten Seite | Alle Chrome-Erweiterungen (das ist ihre Stärke) |
Thunderbits duale Cloud-/Browser-Scraping-Modi spielen hier ihre Stärke aus. Der Cloud-Modus ist schnell für Massen-Scrapes öffentlicher Stores. Der Browser-Modus greift auf deine echte Chrome-Sitzung zurück, sobald der Anti-Bot-Schutz das verlangt. Diese Flexibilität hat mich auf gymshark.com gerettet, wo Cloud-Anfragen blockiert wurden, der Browser-Modus dagegen problemlos durchlief.
Geplantes Shopify-Scraping: Preise und Bestände über Zeit überwachen
Einmaliges Scraping hat seinen Nutzen. Doch E-Commerce-Teams brauchen meist fortlaufende Wettbewerbsinformationen – nicht bloß einen einzelnen Schnappschuss. Preisänderungen, Bestandsschwankungen, neue Produktstarts: Das geschieht ununterbrochen. Ein Nutzer brachte es im Forum direkt auf den Punkt: „Hilfreicher wäre es, den aktuellen Lagerbestand und Schnappschüsse vom sinkenden Bestand zu sehen.“
Trotzdem verliert kaum ein Konkurrenzartikel ein Wort über geplantes oder wiederkehrendes Scraping. Das ist eine klaffende Lücke.
So funktioniert geplantes Shopify-Monitoring
- Einen wiederkehrenden Scrape für die Collection- oder Produktseiten eines Wettbewerbers einrichten
- Die Daten werden bei jedem Lauf nach Google Sheets (oder Airtable) exportiert und bilden eine Zeitreihe von Preis- und Bestandsdaten
- Die Daten nutzen, um zu verfolgen: Preisrückgänge/-anstiege, Out-of-Stock-Situationen, neue Produkte, saisonale Muster
Geplantes Scraping mit Thunderbit einrichten
Thunderbit macht das absurd einfach.
Du beschreibst den Zeitplan in normalem Deutsch (z. B. „jeden Montag um 9 Uhr“), gibst die Shopify-Store-URLs ein und klickst auf „Planen“. Thunderbit führt den Scrape automatisch aus und exportiert an dein gewünschtes Ziel. Keine Cronjobs, kein Code, kein Drittanbieter-Scheduler.
Scheduling-Unterstützung über alle 8 Tools hinweg
| Tool | Scheduling? |
|---|---|
| Thunderbit | Ja — Scheduling in normalem Deutsch |
| Instant Data Scraper | Nein |
| Web Scraper | Ja — in Cloud-Plänen |
| Data Miner | Automatisierte Crawls vorhanden, aber nicht das einfachste Scheduling |
| Simplescraper | Ja |
| Octoparse | Ja — ab Standard |
| Bardeen | Ja — über zeit-/datumsbasierte Automatisierungen |
| Listly | Ja — im Business-Plan |
Gehört laufendes Wettbewerbs-Monitoring zu deinem Workflow, ist das ein wichtiges Unterscheidungsmerkmal. Die meisten kostenlosen Chrome-Erweiterungen bieten es schlicht nicht.
Welche Shopify-Scraper-Chrome-Erweiterung passt zu deinem Anwendungsfall?

Statt eines schwammigen „nimm einfach, was dir gefällt“-Fazits gibt es hier eine Entscheidungsmatrix, die an konkrete Use Cases geknüpft ist:
| Anwendungsfall | Beste Empfehlung | Warum |
|---|---|---|
| Wettbewerbsrecherche zu Preisen | Thunderbit | Listing + Unterseiten-Anreicherung + Scheduling = kompletter Preis-Workflow |
| Schneller Einmal-Export | Instant Data Scraper | Schnellster kostenloser Weg, wenn du nur sichtbare Listendaten brauchst |
| Katalogimport in deinen Shopify-Store | Thunderbit | Vollständige Unterseitendaten + Shopify-Import-freundlicher CSV/Excel-Export |
| Laufende Preis-/Bestandsüberwachung | Thunderbit oder Octoparse | Einfachstes No-Code-Scheduling vs. stärkste Enterprise-artige Planung |
| Lead-Generierung (Kontakte von Store-Betreibern) | Thunderbit | Eingebaute E-Mail-/Telefon-Extraktoren + strukturierter Export |
| Komplexe mehrstufige Automatisierungen | Bardeen | Scrapen, anreichern und in einem Workflow an nachgelagerte Apps senden |
| Technische Nutzer, die volle Kontrolle wollen | Web Scraper oder Octoparse | Beste manuelle Kontrolle über Selektoren, Flow und Extraktionslogik |
Fazit
Beim Shopify-Scraping 2026 geht es längst nicht mehr nur um die Frage, ob du an Produktdaten kommst – sondern darum, wie tief, wie schnell und wie wiederholbar dein Workflow ist. Die meisten Artikel zum Thema bleiben auf der Listing-Seite hängen. Der eigentliche Wert steckt in der Unterseiten-Anreicherung, der geplanten Überwachung und im Umgang mit den Anti-Bot-Überraschungen, die echte Shopify-Stores für dich bereithalten.
Willst du in der Praxis sehen, wie das aussieht – von der Collection-Seite bis zum voll angereicherten Datensatz in wenigen Klicks –, probier Thunderbit aus. Und passt Thunderbit nicht perfekt, ist Instant Data Scraper ein solider kostenloser Startpunkt für einfache Aufgaben, während Web Scraper und Octoparse starke Optionen für technische Nutzer sind, die mehr Kontrolle wollen.
Viel Erfolg beim Scrapen — und mögen deine Produktdaten immer vollständig, strukturiert und variantenreich sein.
Thunderbit für Shopify-Scraping testen Get Started Free
FAQs
1. Ist es legal, Daten aus Shopify-Stores zu scrapen?
Öffentlich verfügbare Produktdaten in Shopify-Stores sind grundsätzlich für alle zugänglich, die die Seite besuchen. Die Rechtmäßigkeit hängt jedoch von deiner Rechtsordnung, den AGB des Stores und davon ab, was du mit den Daten machst. Öffentliche Preise für Wettbewerbsanalysen zu scrapen ist gängige Praxis; Inhalte vollständig zu kopieren und erneut zu veröffentlichen ist riskanter. Das ist keine Rechtsberatung — hol dir für deinen konkreten Fall professionelle Beratung.
2. Kann ich Shopify-Stores scrapen, die ein Login oder Passwort verlangen?
Ja, aber dafür brauchst du einen browserbasierten Scraper, der deine eingeloggte Chrome-Sitzung verwendet. Cloud-Scraper kommen in der Regel nicht an login-geschützte Seiten heran. Thunderbits Browser-Modus, Web Scraper (lokal) und die Login-Workflows von Simplescraper unterstützen dieses Szenario.
3. Wie viele Produkte kann ich auf einmal aus einem Shopify-Store scrapen?
Das hängt vom Tool und vom Plan ab. Shopifys products.json-Endpunkt paginiert mit 250 Produkten pro Seite. Thunderbits Cloud-Modus verarbeitet bis zu 50 Seiten gleichzeitig. Gratis-Tarife der meisten Tools begrenzen Seiten, Zeilen oder Credits — prüfe also deine Planlimits, bevor du einen großen Job startest.
4. Was ist der Unterschied zwischen Cloud-Scraping und Browser-Scraping für Shopify?
Cloud-Scraping läuft auf entfernten Servern — es ist schneller und besser für öffentliche Stores ohne Anti-Bot-Schutz. Browser-Scraping nutzt deine lokale Chrome-Sitzung, wodurch es Cloudflare-geschützte, loginpflichtige oder regionssensitive Stores verarbeiten kann. Thunderbit bietet beide Modi, und die Wahl hängt meist davon ab, ob der Store entfernte Anfragen blockiert.
5. Kann ich gescrapte Shopify-Daten direkt nach Google Sheets oder Airtable exportieren?
Ja, aber nicht alle Tools unterstützen das. Thunderbit exportiert kostenlos nach Google Sheets, Airtable, Notion, Excel, CSV und JSON. Data Miner und Listly unterstützen Google Sheets. Simplescraper unterstützt Sheets und Airtable. Octoparse unterstützt Google Sheets in Premium-Tarifen. Bardeen integriert sich mit Sheets, Airtable und Notion. Instant Data Scraper exportiert nur nach CSV und XLSX ohne direkte Sheets-Integration.
Mehr erfahren




