
Google verarbeitet täglich weit über – Schätzungen liegen sogar näher bei – und diese Zahl steigt weiter. All diese Suchdaten sind eine Goldgrube für SEO-Teams, Sales Ops, E-Commerce-Analysten und zunehmend auch für KI-Agenten, die aktuelle Web-Belege brauchen. Das Problem? 2026 die richtige SERP-API auszuwählen fühlt sich weniger an wie die Wahl eines Tools und mehr wie das Entschlüsseln eines Labyrinths aus Preisseiten, Credit-Systemen und vagen Versprechen über „strukturierte JSON-Daten“.
In den letzten Wochen habe ich mich durch acht SERP-API-Anbieter gearbeitet – Antwortzeiten getestet, Preise über verwirrende Abrechnungsmodelle hinweg normalisiert und geprüft, welche SERP-Features tatsächlich in strukturierte Felder zerlegt werden. Das Ziel: ein ehrlicher, vergleichbarer Vergleich, wie es ihn sonst nirgends gibt. Es geht um Geschwindigkeit, echte Kosten im großen Maßstab, Parsing-Abdeckung, KI-Agenten-Tauglichkeit und Produktionsstabilität. Wenn dich schon einmal das Gefühl genervt hat, dass man „Preislisten vergleicht und nicht die tatsächlichen Kosten“ – ein echtes Zitat aus einem , den ich gefunden habe –, dann ist dieser Artikel für dich.
Warum du 2026 eine SERP-API brauchst (und warum die Auswahl so schwer ist)
Eine SERP-API ist ein gehosteter Dienst, der eine Suchanfrage an eine Suchmaschine sendet und die Ergebnisseite als maschinenlesbare Ausgabe zurückgibt – in der Regel JSON. Statt selbst Proxy-Rotation, CAPTCHA-Behandlung, Browser-Rendering und Parser aufzubauen, rufst du einen Endpunkt auf und erhältst strukturierte Daten zurück. Ein einfaches Konzept, ein komplizierter Markt.
Die Einsatzszenarien gehen längst weit über Rank-Tracking hinaus:
- SEO-Teams brauchen Rankings, Snippet-Besitz, People-Also-Ask-Fragen und Sichtbarkeit der Wettbewerber.
- Sales- und GTM-Teams nutzen SERPs, um Unternehmen, Bewertungsseiten, Verzeichnisse und Kaufsignale zu entdecken.
- E-Commerce-Teams überwachen Google Shopping, bezahlte Anzeigen und Preise der Konkurrenz.
- KI-Entwickler speisen SERP-Daten in LLM-Agenten, RAG-Pipelines und Workflow-Tools wie n8n und LangChain ein.
Der soll bis 2031 erreichen und mit rund 13,78 % CAGR wachsen. SERP-APIs sind ein großer Teil dieses Kuchens.
Die Kernfrustration ist diese: Jeder Anbieter behauptet, „strukturierte JSON“ zu liefern, aber die tatsächlich geparsten SERP-Elemente – PAA, Knowledge Panels, Local Packs, Shopping-Anzeigen, Featured Snippets – unterscheiden sich stark. Auch die Preisgestaltung ist chaotisch. Manche rechnen pro Suche ab, manche pro Credit, manche pro Ergebnis, und manche verlangen unterschiedliche Preise je nach Geschwindigkeitsstufe oder Geolokation. Ein Reddit-Nutzer brachte es gut auf den Punkt: „SerpApi rechnet pro erfolgreicher Suche ab, ScraperAPI verpackt alles in Credits, und Serperdev wirkt billig, bis man Credits auf die echte Arbeitslast umrechnet.“
Dieser Artikel schließt die Lücken, die ich sonst nirgends gefunden habe: eine Parsing-Matrix mit dem, was jede API tatsächlich zurückgibt, normalisierte Preise bei 1K/10K/100K Anfragen, Eignung für KI-Agenten und Daten zur Produktionsreife.
Wie wir getestet haben: Kriterien für die beste SERP-API
Ich habe jeden Anbieter anhand von acht Dimensionen bewertet, die direkt widerspiegeln, worauf es Nutzern im produktiven Einsatz wirklich ankommt. Die meisten Vergleichsartikel behandeln zwei oder drei davon nur oberflächlich. Ich wollte alle acht – inklusive Belege.
Geschwindigkeit und Antwortzeit. Ich habe mich auf Benchmarks von Drittanbietern gestützt – insbesondere auf den – sowie auf die Dokumentation der Anbieter. Geschwindigkeit ist wichtig, wenn du Echtzeit-Dashboards baust oder KI-Agenten mit Tool-Calling einsetzt, die nicht 30 Sekunden auf eine Antwort warten können.
Preisgestaltung im großen Maßstab (1K, 10K, 100K Anfragen). Ich habe die Preise jedes Anbieters auf Kosten pro 1.000 erfolgreiche Anfragen normalisiert. Nur so lassen sich Credit-basierte, Abo-Bucket- und Pay-as-you-go-Modelle fair vergleichen.
Geparste SERP-Features (über organische Ergebnisse hinaus). Ich habe Dokumentation und Beispielantworten geprüft, um zu verifizieren, welche SERP-Elemente jede API als strukturierte Felder zurückgibt – nicht nur rohes HTML.
Free Tier und Pay-as-you-go-Verfügbarkeit. Ein niedriger Einstieg ist wichtig. Wenn du einen Anbieter nicht mit deiner echten Arbeitslast testen kannst, bevor du Hunderte von Dollar bindest, ist das ein Warnsignal.
KI- und Automatisierungsintegration. 2026 brauchen mehr Teams SERP-APIs für KI-Agenten als für Dashboards. Schema-Stabilität, saubere Ausgabe und Markdown-Konvertierung sind für den nachgelagerten LLM-Einsatz entscheidend.
Unterstützung mehrerer Suchmaschinen. Die meisten Artikel konzentrieren sich ausschließlich auf Google. Ich habe geprüft, welche Anbieter Bing, Yandex, DuckDuckGo, Baidu und weitere unterstützen.
Rate Limits und Produktionsreife. Kein anderer Vergleichsartikel stellt Rate Limits, Retry-Strategien oder SLAs systematisch gegenüber. Dabei brauchen Teams, die auf Tausende Anfragen pro Tag skalieren, genau diese Informationen.
Entwicklerfreundlichkeit. Qualität der Doku, Verfügbarkeit von SDKs und Time-to-First-Result.
1. Thunderbit
verfolgt einen grundsätzlich anderen Ansatz als klassische SERP-APIs. Statt feste Endpunkte anzubieten, die vorab definierte SERP-Elemente parsen, lässt dich Thunderbits Extract API dein eigenes JSON-Schema festlegen – und die KI extrahiert genau die Felder, die du angibst, aus jeder Suchergebnisseite. Die Distill API wandelt jede URL in sauberes, LLM-taugliches Markdown um.
Das bedeutet: Thunderbit funktioniert auf Google, Bing, Yandex, DuckDuckGo oder jeder anderen Suchmaschine – die KI liest die Seite jedes Mal frisch, statt auf hart kodierte Selektoren zu setzen. SERP-Layouts ändern sich ständig. Du musst nicht darauf warten, dass ein Anbieter einen Parser aktualisiert.
Hauptfunktionen
- Extract API: Definiere ein eigenes JSON-Schema (organische Ergebnisse, PAA-Fragen, Local-Pack-Unternehmen, Shopping-Produkte – was immer du brauchst) und erhalte genau diese Felder als strukturierte Daten zurück.
- Distill API: Wandelt jede SERP-Seite in sauberes Markdown um – ideal für RAG-Pipelines und LLM-Zusammenfassungen.
- Multi-Engine by Design: Funktioniert mit jeder zugänglichen Suchseite, nicht nur mit Google.
- Batch-Verarbeitung: Mehrere URLs parallel verarbeiten.
- Integrierter Anti-Bot-Schutz: CAPTCHA-Lösung, JS-Rendering und Proxy-Rotation sind enthalten.
- Rate Limits nach Tarif: Free (10 Anfragen/Min, 2 parallel), Pro (100 Anfragen/Min, 10 parallel), Enterprise (1.000 Anfragen/Min, 50 parallel).
Preise
Credit-basiertes Modell. Distill kostet 1 Credit pro Seite; Extract kostet 20 Credits pro Seite. Für Tests stehen kostenlose Credits zur Verfügung. Auf Basis eines Jahresplans kann die Grenzkosten von Distill bei nur etwa 0,80 US-Dollar pro 1K Seiten liegen, während Extract bei voller Auslastung bei rund 16 US-Dollar pro 1K Seiten liegt. Der Mehrwert von Extract: Du erhältst exakt das Schema, das dein Downstream-System braucht – ohne Nachbearbeitung.
Aktuelle Pakete findest du unter .
Am besten geeignet für
Workflows mit KI-Agenten, RAG-Pipelines, Multi-Engine-Scraping, Teams, die ein flexibles Schema statt fixer Ausgabe brauchen, und alle, die es satt haben zu warten, bis ein Anbieter ein neues SERP-Feature unterstützt.
2. SerpApi
ist der Veteran in diesem Bereich – seit 2016 aktiv und mit der breitesten Auswahl an Google-spezifischen Endpunkten. Abgedeckt sind Google Search, Maps, Shopping, Scholar, News, Jobs, Trends, Images, Videos und mehr.
Hauptfunktionen
- Dedizierte Endpunkte für verschiedene Google-Produkte mit ausgereiftem Geo-Targeting bis auf Stadtebene.
- Parst PAA, Knowledge Panels, Local Pack, Anzeigen, Shopping-Ergebnisse, Featured Snippets, Answer Boxes und verwandte Suchen als strukturierte Felder.
- Gut gepflegte Dokumentation und Client-Bibliotheken in mehreren Sprachen.
Preise
. Starter-Tarif: 25 US-Dollar/Monat für 1.000 Suchen (effektiv 25 US-Dollar pro 1K). Beliebter Tarif: 130 US-Dollar/Monat für 15.000 Suchen (ca. 8,67 US-Dollar pro 1K). Big Data: 2.750 US-Dollar/Monat für 500.000 Suchen (ca. 5,50 US-Dollar pro 1K). Keine einfache Pay-as-you-go-Option – es sind Abo-Buckets.
Geschwindigkeit und Zuverlässigkeit
Der Benchmark von HasData weist eine durchschnittliche Antwortzeit von rund 5,49 Sekunden aus – nicht die schnellste, aber stabil. SerpApi bewirbt auf kostenpflichtigen Plänen ein SLA mit 99,95 % Verfügbarkeit, und die Limits für parallele Anfragen variieren je nach Tarif.
Am besten geeignet für
Teams, die die breiteste Google-Produktabdeckung brauchen (Maps, Scholar, Shopping, Jobs) und dabei hohe Genauigkeit sowie stabile Schemata wollen. Enterprise-Projekte mit Budget für Premium-Preise.
3. Serper
ist die Lösung für Tempo und Kosten. Als neuerer Anbieter konzentriert sich Serper auf schnelles Google-SERP-Scraping zu extrem wettbewerbsfähigen Preisen und ist in der n8n- und LangChain-Community wegen seiner KI-Agenten-Integration beliebt geworden.
Hauptfunktionen
- Saubere JSON-Ausgabe für Google Search, News, Scholar, Images, Shopping, Videos, Places, Patents und Autocomplete.
- Minimaler Setup-Aufwand – du kannst in unter einer Minute Ergebnisse abrufen.
- So einfach, dass KI-Agenten-Frameworks es nativ integrieren.
Preise
2.500 kostenlose Anfragen bei der Anmeldung. Einstiegspreise ab etwa 0,001 US-Dollar pro Suche, bei hohem Volumen sinkend auf rund 0,00075 US-Dollar. Pay-as-you-go-freundlich. Ein Hinweis: Mehr als 10 Ergebnisse pro Anfrage können 2 Credits kosten (aktuelles Verhalten im Dashboard prüfen).
Geschwindigkeit und Zuverlässigkeit
Unter den schnellsten im Benchmark – HasData nennt rund 2,87 Sekunden im Durchschnitt. Support nur per E-Mail, und das Team hält sich öffentlich relativ zurück, was manche Nutzer vorsichtig macht. Bei sehr hoher Parallelität melden einige Reviewer Zuverlässigkeitsprobleme. Für die meisten Workloads ist es jedoch solide.
Am besten geeignet für
Preisbewusste Projekte, Startups, KI-Agenten-Integrationen, die schnelle und günstige Google-SERP-Daten brauchen. High-Volume-Rank-Tracking, bei dem Kosten pro Anfrage die Hauptrolle spielen.
4. Scrapingdog
ist seit über 5 Jahren am Markt und taucht in Drittanbieter-Benchmarks regelmäßig als der schnellste Anbieter auf. HasData misst bei einer Erfolgsrate von 100 %.
Hauptfunktionen
- Die Google-SERP-API liefert organische Ergebnisse, PAA, Featured Snippets, Anzeigen und lokale Ergebnisse als strukturiertes JSON.
- Sowohl rohes HTML als auch geparstes JSON verfügbar.
- Dokumentation in mehreren Sprachen mit Code-Snippets für die meisten Programmiersprachen – der Einstieg dauert Minuten, nicht Stunden.
- 24/7-Support.
Preise
. Bezahlpläne starten bei etwa 40 US-Dollar/Monat. Die Preisgestaltung pro Aufruf beginnt bei rund 0,001 US-Dollar und fällt bei hohem Volumen deutlich – einige Vergleiche nennen sogar Tarife von nur 0,000058 US-Dollar in den oberen Stufen.
Geschwindigkeit und Zuverlässigkeit
Die Geschwindigkeitswerte sind wirklich beeindruckend. Wenn dein Workflow latenzkritisch ist und du eine große Menge an Google-SERP-Daten mit festem Schema extrahierst, ist Scrapingdog bei der reinen Antwortzeit schwer zu schlagen.
Am besten geeignet für
SEO-Tools und Rank-Tracker mit hohem Volumen, die geringe Latenz und niedrige Kosten brauchen. Teams, die Produktionssysteme bauen, bei denen jede Millisekunde API-Antwortzeit zählt.
5. DataForSEO
ist nicht nur eine SERP-API – es ist eine komplette API-Suite für Unternehmen, die SEO-Produkte entwickeln. Abgedeckt sind SERP, Keywords, Backlinks, Geschäftsdaten, Google Ads, Trends und mehr.
Hauptfunktionen
- Extrem umfassendes Parsing von SERP-Features – organisch, bezahlt, Local Pack, Knowledge Graph, PAA, Featured Snippets, Shopping, Images, Videos, Top Stories und mehr.
- Zwei Modi: Live (synchron) für Echtzeit-Dashboards und Standard (asynchron) für Batch-Workflows, bei denen Tasks in eine Warteschlange gestellt und später abgerufen werden.
- Multi-Engine: Google, Bing, Yahoo, Baidu, Naver, Seznam und weitere.
Preise
Pay-as-you-go-Modell, aber die Kosten variieren je nach Endpunkt, Suchmaschine, Gerät, Priorität und Modus. Die SERP-Preise liegen typischerweise bei etwa 0,0006 bis 0,002 US-Dollar pro Task für Google Organic, abhängig von Standard vs. Live und den Prioritätseinstellungen. Die Dokumentation ist dicht – plane Zeit mit dem Preisrechner ein. .
Geschwindigkeit und Zuverlässigkeit
Der Standard-Async-Modus kann langsamer sein (ca. 10 Sekunden), weil Tasks in einer Warteschlange landen. Live-/High-Speed-Modi kosten mehr, sind aber für Echtzeit-Dashboards geeignet. Lange Marktpräsenz, bewährte Stabilität und Enterprise-Support verfügbar.
Am besten geeignet für
SaaS-Unternehmen, die SEO-Plattformen, Rank-Tracking-Dashboards und Keyword-Recherche-Tools bauen. Teams, die mit komplexer Dokumentation und Enterprise-Infrastruktur umgehen können.
6. Bright Data
ist das Enterprise-Schwergewicht. Die SERP-API ist nur eines von vielen Produkten – dazu kommen Proxies, Datasets, Web Unlocker und Scraping-Tools. Der Mehrwert liegt in Skalierung, Zuverlässigkeit und Infrastruktur.
Hauptfunktionen
- Dedizierte Endpunkte für Google Maps, Shopping und allgemeine Suche – plus Multi-Engine-Support über Proxy-Infrastruktur für Bing, Yahoo, Yandex und DuckDuckGo.
- Anspruch auf 100 % Erfolgsrate dank integrierter Unblocking-Technologie.
- Besonders stark ist Bright Data bei Geo-Targeting, Parallelität und Unblocking im Enterprise-Maßstab.
Preise
Auf Enterprise ausgerichtet. Öffentliche Preise zeigen Pay-as-you-go- und Abo-Optionen; viele Vergleiche nennen Einstiegsvorgaben um 499 US-Dollar/Monat. Die Kosten pro Aufruf beginnen bei etwa 0,005 US-Dollar und sinken mit dem Volumen. . Test-Credits verfügbar (Wert von 5 US-Dollar).
Geschwindigkeit und Zuverlässigkeit
Benchmarks zeigen oft 2 bis 5,58 Sekunden. Der Grund, Bright Data zu kaufen, ist nicht die reine Median-Latenz – sondern Enterprise-SLA, dedizierter Support und Infrastruktur, die Millionen paralleler Anfragen ohne Leistungseinbußen verarbeitet. Die empfiehlt, schrittweise hochzufahren.
Am besten geeignet für
Enterprise-Teams, die Millionen von SERPs pro Monat erfassen. Organisationen, die Google-Maps-/Local-Business-Daten in großem Maßstab brauchen. Teams, die bereits Bright-Data-Proxy-Produkte einsetzen.
7. ScraperAPI
ist eine allgemeine Web-Scraping-API, die auch strukturierte Google-SERP-Endpunkte anbietet. Es ist die „ein Tool für alles“-Option – leicht zu integrieren und mit einem Proxy-Pool von über 40 Millionen IPs.
Hauptfunktionen
- Strukturierte Daten-Endpunkte für Google Search, Shopping, News und Jobs.
- Maschinenlern-basierter Anti-Blocking- und CAPTCHA-Schutz, inklusive JavaScript-Rendering ohne Aufpreis.
- Geo-Targeting für lokalisierte Ergebnisse.
Preise
7-tägige kostenlose Testphase mit 5.000 Credits. Bezahlpläne starten bei etwa 49 US-Dollar/Monat. Der Haken: SERP-Aufrufe können andere Credits verbrauchen als einfache Scraping-Anfragen, daher immer nach den tatsächlich gelieferten erfolgreichen SERP-Queries normalisieren. .
Geschwindigkeit und Zuverlässigkeit
Hier die ehrliche Einordnung: HasDatas Benchmark weist für SERP-Anfragen eine durchschnittliche Antwortzeit von rund 33,66 Sekunden aus. Das ist deutlich langsamer als bei spezialisierten SERP-APIs. Hohe Erfolgsrate (99,9 %), aber die Latenz macht das für Echtzeitanwendungen weniger geeignet. Besser für Batch-Verarbeitung.
Am besten geeignet für
Teams, die eine allgemeine Web-Scraping-Lösung brauchen, bei der SERP nur eine Zusatzfunktion ist. Projekte, bei denen Geschwindigkeit weniger wichtig ist als Zuverlässigkeit und einfacher Setup. Entwickler, die ScraperAPI bereits für andere Scraping-Aufgaben nutzen und Anbieter konsolidieren wollen.
8. Apify
ist keine reine SERP-API. Es ist eine Scraping- und Automatisierungsplattform, die auf „Actors“ basiert – wiederverwendbaren Skripten für Aufgaben wie Google-Search-Scraping, Maps-Extraktion und Workflow-Automatisierung. Denk daran als an einen Marktplatz, auf dem du den Scraper auswählst (oder baust), der genau zu deinem Bedarf passt.
Hauptfunktionen
- Marktplatz mit vorgefertigten mit unterschiedlicher Feature-Abdeckung.
- Hochgradig anpassbar – baue eigene Scraping-Workflows, verknüpfe Actors und plane Läufe.
- Ausgabe als JSON; flexibel genug, um bestimmte SERP-Features über die Actor-Konfiguration zu parsen.
- Stark, wenn SERP-Extraktion mit anderen Scraping-/Automatisierungsaufgaben kombiniert werden soll.
Preise
Free Tier mit monatlichen Plattform-Credits (Wert von etwa 5 US-Dollar, ungefähr 1.400 Ergebnisse). Bezahlpläne starten bei etwa 49 US-Dollar/Monat. Die Kosten auf Actor-Ebene variieren – manche rechnen pro Ergebnis ab, andere pro Compute Unit. Drittanbieter-Vergleiche setzen Apify oft bei etwa 0,003 US-Dollar pro Suche im kleinen Maßstab an. .
Geschwindigkeit und Zuverlässigkeit
HasData nennt rund 8,2 Sekunden im Durchschnitt. Die actor-basierte Architektur bringt im Vergleich zu dedizierten SERP-Endpunkten zusätzlichen Overhead mit sich. Besser für geplante Batch-Workflows als für Echtzeit-Abfragen.
Am besten geeignet für
Teams, die neben SERP-Daten auch maßgeschneiderte Scraping- und Automatisierungs-Workflows brauchen. Projekte, die SERP-Extraktion mit anderen Web-Scraping-Aufgaben kombinieren. Entwickler, die maximale Flexibilität statt vorgefertigter Endpunkte wollen.
SERP-Feature-Parsing-Matrix: Was jede API tatsächlich zurückgibt
Das ist der Vergleich, den ich nirgendwo sonst finden konnte. Jeder Anbieter sagt „strukturierte JSON-Daten“, aber die tatsächlich als First-Class-Felder geparsten SERP-Elemente unterscheiden sich massiv. Ich habe dafür die Dokumentation und Beispielantworten jedes Anbieters geprüft.
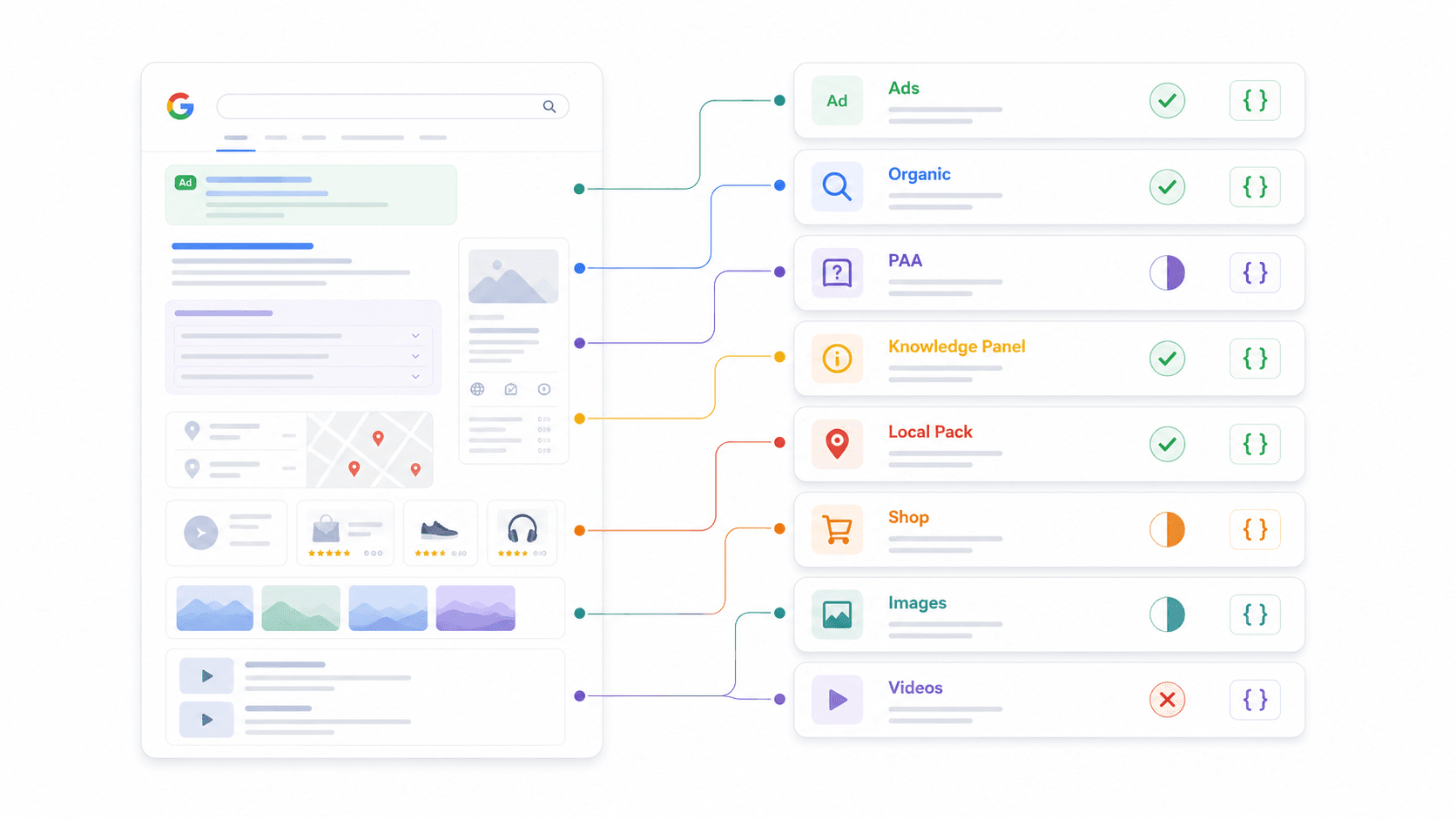
| SERP-Feature | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| Organische Ergebnisse | Custom Schema | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | Actor-abhängig |
| People Also Ask | Custom Schema | ✅ | ✅ | ✅ | ✅ | Teilweise | Teilweise | Actor-abhängig |
| Knowledge Panel | Custom Schema | ✅ | Teilweise | Teilweise | ✅ | Teilweise | Teilweise | Actor-abhängig |
| Local Pack / Maps | Custom Schema | ✅ | ✅ | Teilweise | ✅ | ✅ | Teilweise | Actor-abhängig |
| Shopping-Ergebnisse | Custom Schema | ✅ | ✅ | Teilweise | ✅ | ✅ | ✅ | Actor-abhängig |
| Featured Snippets | Custom Schema | ✅ | Teilweise | ✅ | ✅ | Teilweise | Teilweise | Actor-abhängig |
| Anzeigen (oben/unten) | Custom Schema | ✅ | Teilweise | ✅ | ✅ | Teilweise | Teilweise | Actor-abhängig |
| Image Pack | Custom Schema | ✅ | ✅ | ✅ | ✅ | Teilweise | Teilweise | Actor-abhängig |
| Video-Ergebnisse | Custom Schema | ✅ | ✅ | Teilweise | ✅ | Teilweise | Teilweise | Actor-abhängig |
Was „Custom Schema“ bei Thunderbit bedeutet: Statt vorab festzulegen, welche SERP-Features geparst werden, definierst du dein eigenes JSON-Schema, um genau die Felder zu extrahieren, die du brauchst. Willst du PAA-Fragen plus Antwortzusammenfassungen plus Signale zur kommerziellen Suchintention? Definiere dieses Schema, und die KI liefert es. Diese Flexibilität ist der Grund, warum Thunderbit mit jeder Suchmaschine funktioniert – nicht nur mit Google.
Warum das für deinen Workflow wichtig ist: Wenn du PAA-Daten für deine Content-Strategie brauchst, prüfe, ob dein Anbieter sie tatsächlich parst. Wenn du Shopping-Anzeigen für E-Commerce trackst, vergewissere dich, dass strukturierte Shopping-Felder vorhanden sind. Verlass dich nicht darauf, dass „strukturierte JSON“ gleichbedeutend mit vollständiger Abdeckung ist.
Echte Kosten im großen Maßstab: Preis-pro-Abfrage-Vergleich
Die auf Websites genannten Listenpreise erzählen nicht die ganze Geschichte. Ich habe alles auf Kosten pro 1.000 erfolgreiche Anfragen bei drei Volumenstufen normalisiert.
| Anbieter | Kosten für 1K Anfragen | Kosten für 10K Anfragen | Kosten für 100K Anfragen | Pay-as-you-go? | Free Tier |
|---|---|---|---|---|---|
| Thunderbit (Distill) | ca. 0,80–3,20 US-Dollar | ca. 8–32 US-Dollar | ca. 80–320 US-Dollar | Credit-Paket | Kostenlose Credits |
| Thunderbit (Extract) | ca. 16–64 US-Dollar | ca. 160–640 US-Dollar | ca. 1.600–6.400 US-Dollar | Credit-Paket | Kostenlose Credits |
| SerpApi | 25 US-Dollar (Starter) | ca. 87 US-Dollar (Popular) | ca. 550 US-Dollar (Big Data) | Nein (Abo) | 250/Monat |
| Serper | ca. 1 US-Dollar | ca. 10 US-Dollar | ca. 75–100 US-Dollar | Ja | 2.500 Anfragen |
| Scrapingdog | ca. 1 US-Dollar | ca. 10 US-Dollar oder weniger | Kann deutlich unter 10 US-Dollar fallen | Abo/Credit | 1.000 Credits |
| DataForSEO | ca. 0,60–2 US-Dollar | ca. 6–20 US-Dollar | ca. 60–200 US-Dollar | Ja | Test-Credits |
| Bright Data | ca. 0,50–5+ US-Dollar | Angebotsabhängig | Am besten im Enterprise-Volumen | Ja/Abo | Test-Credits (5 US-Dollar) |
| ScraperAPI | Credit-abhängig | Credit-abhängig | Credit-abhängig | Abo/Credit | 5.000 Test-Credits |
| Apify | ca. 3 US-Dollar (kleiner Maßstab) | Actor-abhängig | Actor-abhängig | Plattform-Credits | Monatliche Gratis-Credits |
Versteckte Kosten, auf die du achten solltest:
- Serpers mögliche 2-Credit-Gebühr für mehr als 10 Ergebnisse pro Anfrage.
- DataForSEOs Preisunterschiede zwischen Standard- und Live-/High-Priority-Modi.
- ScraperAPIs Credit-Multiplikatoren für SERP im Vergleich zu einfachem Scraping.
- Bright Datas Enterprise-Mindestverpflichtungen.
Wert je Stufe:
- Nebenprojekte (50 US-Dollar/Monat): Serper oder Scrapingdog für fixes Google-SERP-JSON.
- Wachsende Teams (10K–50K Anfragen/Monat): Serper, Scrapingdog oder DataForSEO – je nach Parsing-Tiefe.
- Enterprise (100K+ Anfragen/Monat): DataForSEO, Bright Data oder SerpApi Big Data.
- KI-first-Extraktion: Thunderbit, weil das Schema ohne Nachbearbeitung zu den Erwartungen deines Downstream-Agenten passt.
Beste SERP-API für KI-Agenten und LLM-Workflows in 2026
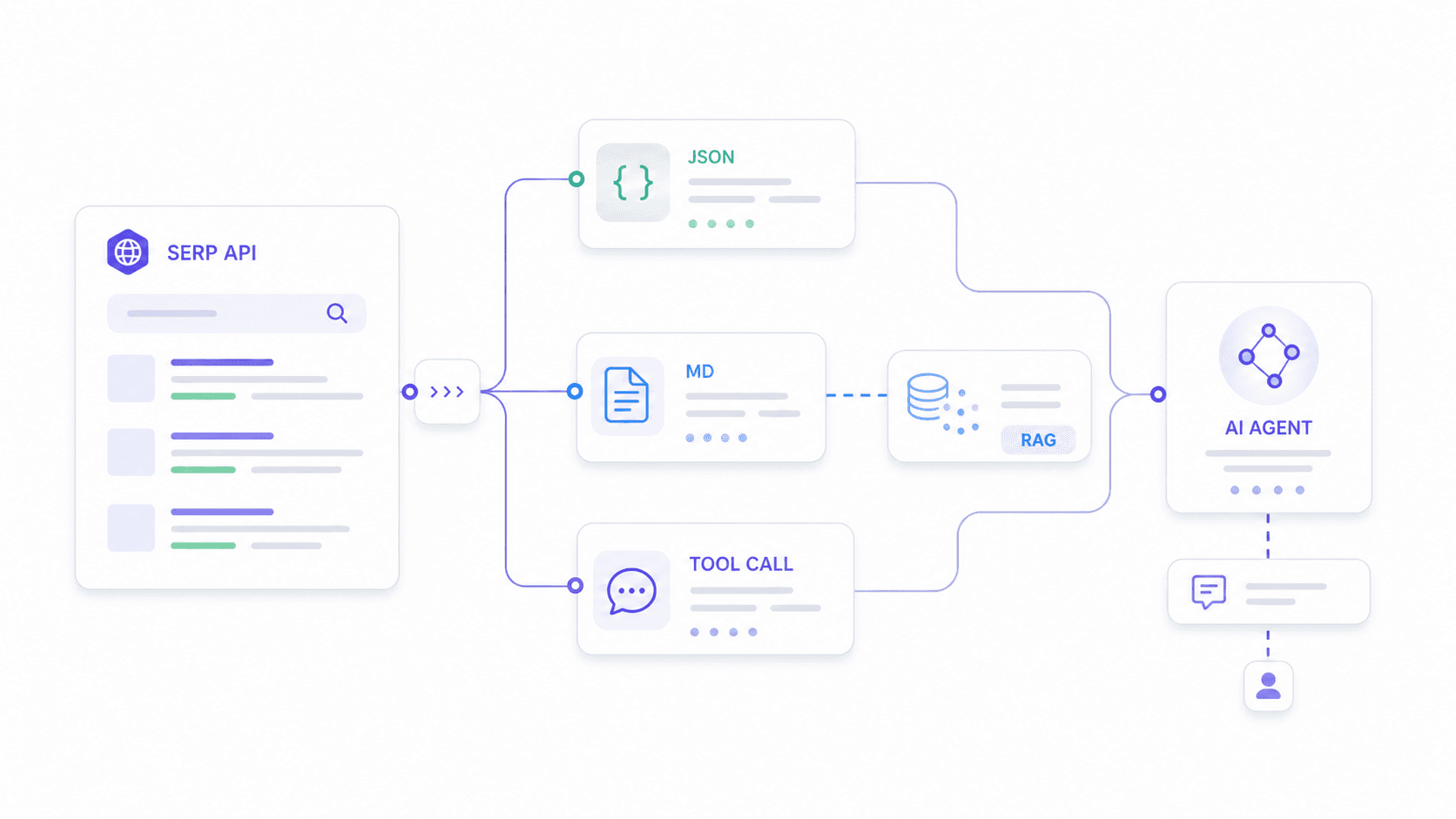
Das ist der Use Case, den sonst niemand gut abdeckt. Ich habe mindestens drei gefunden, in denen Nutzer beschreiben, wie sie SERP-APIs in n8n-Workflows und KI-Agenten integrieren wollen, wobei einer ausdrücklich schreibt, dass er „nicht herausgefunden hat, wie das mit einem KI-Agenten richtig funktioniert“.
KI-Agenten brauchen andere Dinge als Rank-Tracking-Dashboards. Sie brauchen:
- Schema-stabiles JSON, das ihre Parsing-Logik nicht bricht, wenn ein Anbieter sein Ausgabeformat ändert.
- Eigene Ausgabefelder, die genau zum erwarteten Input des Downstream-Modells passen – kein generischer Dump von allem.
- Sauberes Markdown oder Text für RAG-Embedding-Pipelines.
- Geringe Latenz für Tool-Calling in Echtzeit.
Wie sich jeder Anbieter in einen KI-Agenten-Stack einfügt
| Anbieter | Eignung für KI-Agenten | Warum |
|---|---|---|
| Thunderbit | Hervorragend | Custom JSON Schema (Extract API) + Markdown für RAG (Distill API). Am flexibelsten für agentenspezifische Extraktion. |
| Serper | Sehr gut | Schnelles, sauberes JSON, in n8n-/LangChain-Communities beliebt. Einfach und günstig für grundlegende Search-Tool-Aufrufe. |
| SerpApi | Gut | Stabiles Schema, exzellente Doku. Funktioniert gut, wenn Agenten Google-Vertikalen (Maps, Scholar, Shopping) brauchen. |
| DataForSEO | Gut | Am besten, wenn der Agent Teil einer größeren SEO-Datenpipeline ist. |
| Scrapingdog | Gut | Schnell und günstig; das Schema ist für Google SERP stabil. |
| Bright Data | Gut | Datenerfassung im Enterprise-Maßstab über Suchmaschinen und Regionen hinweg. |
| ScraperAPI | Mittelmäßig | Besser, wenn der Agent zusätzlich allgemeines Web-Crawling braucht. |
| Apify | Mittel bis gut | Flexibel, aber langsamer; besser für geplante Batch-Workflows. |
Praktisches Beispiel mit Thunderbit: Stell dir vor, dein KI-Agent soll die Suchintention für „best CRM for real estate“ analysieren. Du definierst ein Schema, das organische Ergebnisse anfordert (Titel, URL, Snippet, Position), People-Also-Ask-Fragen mit Antwortzusammenfassungen und eine Klassifizierung der kommerziellen Suchintention. Thunderbits Extract API gibt genau diese Struktur zurück – nicht mehr und nicht weniger. Dein Agent verschwendet keine Tokens damit, irrelevante Felder zu parsen oder HTML-Reste zu bereinigen.
Für RAG-Pipelines wandelt Thunderbits Distill API die SERP-Seite in sauberes Markdown um, das direkt für Embeddings bereit ist. Die meisten spezialisierten SERP-APIs liefern feste JSON-Schemata; Thunderbits Ansatz erlaubt Entwicklern, die Ausgabe an genau das anzupassen, was das Downstream-Modell erwartet.
Entscheidungs-Matrix nach Use Case: Wenn du X brauchst, nimm Y
In Foren fragen Nutzer immer wieder nach konkreten Empfehlungen, die zu ihren echten Workflows passen – nicht nach allgemeinem „es kommt darauf an“. Also habe ich genau das gebaut.
| Dein Use Case | Beste Wahl | Zweitbeste Wahl | Warum |
|---|---|---|---|
| SEO-Rank-Tracking (hohes Volumen) | DataForSEO | Scrapingdog | SEO-native Endpunkte, Mengenpreise, umfassendes Parsing |
| Google Maps / lokale Geschäftsdaten | SerpApi | Bright Data | Ausgereifter Maps-Endpunkt; Bright Data eignet sich für lokales Scraping im Enterprise-Maßstab |
| KI-Agent / n8n-Automatisierung | Thunderbit | Serper | Custom Schema + Markdown für RAG; Serper ist schnell und günstig für einfache Aufrufe |
| Budget-MVP / Side Project (<50 US-Dollar/Monat) | Serper | Scrapingdog | Großzügige Free-Tiers, Pay-as-you-go, minimaler Setup-Aufwand |
| Multi-Engine (Bing, Yandex, DuckDuckGo) | Thunderbit | DataForSEO | Thunderbit funktioniert per KI-Extraktion mit jeder Suchmaschine; DataForSEO hat Multi-Engine-Endpunkte |
| Google Reviews Aggregation | SerpApi | DataForSEO | Dedizierte Review-Parsing-Endpunkte |
| E-Commerce / Shopping-Monitoring | SerpApi | DataForSEO | Starke Google-Shopping-Abdeckung und strukturierte Felder |
| Eigene Scraping-Workflows | Apify | ScraperAPI | Actor-Flexibilität; ScraperAPI ist einfach für allgemeines Scraping plus SERP |
Kurzer Persona-Guide:
- SEO-Team: Starte mit DataForSEO, wenn du Dashboards baust; nimm SerpApi, wenn Google-Vertikalabdeckung und Doku wichtiger sind als der Preis.
- Sales-Team: Nutze Thunderbit, wenn der Workflow SERPs, Verzeichnisse und Enrichment umfasst; nutze Serper für einfache Lead-Discovery-Abfragen.
- KI-Tool-Entwickler: Thunderbit für Custom Schemas/RAG, Serper für günstige schnelle Suche, SerpApi für robuste Google-Vertikalen.
- Solo-Unternehmer: Starte mit den Free-Tiers von Serper, Scrapingdog, SerpApi und Thunderbit. Führe dieselben 20 produktionsnahen Abfragen aus, bevor du dich festlegst.
Rate Limits, Zuverlässigkeit und Produktionsreife im Vergleich
Ich wünschte, es hätte diesen Abschnitt schon gegeben, als ich Anbieter erstmals für produktive Workflows bewertet habe. Teams, die auf Tausende Anfragen pro Tag skalieren, brauchen vorhersehbare Rate Limits, automatische Retries und Verfügbarkeitsgarantien – und kein anderer Vergleichsartikel behandelt das systematisch.
| Anbieter | Rate Limit | Parallele Anfragen | Retry bei Fehlern | SLA / Verfügbarkeit |
|---|---|---|---|---|
| Thunderbit Free | 10 Anfragen/Min | 2 | Integriert (Anti-Bot, CAPTCHA) | — |
| Thunderbit Pro | 100 Anfragen/Min | 10 | Integriert | — |
| Thunderbit Enterprise | 1.000 Anfragen/Min | 50 | Integriert | Individuelle Bedingungen |
| SerpApi | tarifbasiert (Suchen/Stunde) | tarifbasiert | Anbieter übernimmt Proxies/CAPTCHA | 99,95 % SLA |
| Serper | konto-/tarifbasiert | nicht breit veröffentlicht | Manueller Client-Retry empfohlen | Kein öffentliches SLA |
| Scrapingdog | tarifbasiert | Tarifbedingungen prüfen | Anti-Blocking integriert | Nicht immer öffentlich |
| DataForSEO | pro Endpunkt/Modus dokumentiert | variiert je Modus | Async unterstützt Polling/Retry | Enterprise-Support |
| Bright Data | Dokumentiert, schrittweise hochfahren | Enterprise-Maßstab | Integriertes Unblocking | Enterprise-SLA |
| ScraperAPI | tarifbasierte Parallelität | Credit-abhängig | Übernimmt Retries/Proxies | Kostenpflichtige Support-Optionen |
| Apify | abhängig von Actor/Speicher/Compute | Plattform-Limits | Actor-Level-Konfiguration | Plattform-Zuverlässigkeit |
Produktions-Checkliste vor dem Commit:
- Frage nach, ob der Anbieter für fehlgeschlagene oder geblockte Requests Gebühren erhebt.
- Bestätige die genaue Parallelität, Requests pro Minute und das Burst-Verhalten.
- Prüfe, ob Geo-Targeting, Mobile vs. Desktop und JS-Rendering den Credit-Verbrauch verändern.
- Speichere Beispiel-JSON-Antworten für 20–50 echte Abfragen und vergleiche die Feldnamen über mehrere Tage hinweg, um die Schema-Stabilität zu prüfen.
- Füge clientseitige Retries und Timeout-Budgets hinzu, wenn SERP-Daten geschäftskritisch sind.
Kurzüberblick: Alle 8 SERP-APIs im Vergleich
| Anbieter | Durchschnittliche Geschwindigkeit | Kosten pro 1K | Free Tier | Parsing-Abdeckung | KI-Eignung | Multi-Engine | Fazit |
|---|---|---|---|---|---|---|---|
| Thunderbit | Mittel (KI-Extraktion) | Niedrig (Distill) bis Premium (Extract) | Ja | Custom (jede Funktion) | Hervorragend | Hervorragend | Am besten für KI-native, maßgeschneiderte SERP-Extraktion und RAG |
| SerpApi | ca. 5,5 s | Premium | 250/Monat | Hervorragend (fix) | Gut | Breite Google-Vertikalen | Beste ausgereifte Google-Abdeckung |
| Serper | ca. 2–3 s | Sehr niedrig | 2.500 Anfragen | Gut | Sehr gut | Vor allem Google | Beste günstige schnelle API für KI/MVPs |
| Scrapingdog | ca. 1,25 s | Sehr niedrig bei Scale | 1.000 Credits | Gut | Gut | Engines prüfen | Beste Kombination aus Geschwindigkeit und Kosten |
| DataForSEO | Mittel bis langsam (Standard) | Niedrig bis moderat | Test-Credits | Hervorragend | Gut | Hervorragend | Beste Infrastruktur für SEO-Plattformen |
| Bright Data | ca. 2–5,5 s | Enterprise | Test (5 US-Dollar) | Gut (produktabhängig) | Gut | Hervorragend | Beste Datenerfassung im Enterprise-Maßstab |
| ScraperAPI | ca. 33 s | Credit-abhängig | 5.000 Test-Credits | Moderat | Moderat | Google-Endpunkte | Am besten, wenn SERP nur ein Teil des größeren Scraping-Setups ist |
| Apify | ca. 8 s | Actor-abhängig | Monatliche Credits | Actor-abhängig | Moderat bis gut | Actor-abhängig | Am besten für maßgeschneiderte Automatisierungs-Workflows |
Wie Thunderbit in deinen SERP-Workflow passt
Ein bisschen mehr Kontext dazu, warum unser Team Thunderbits API genau so gebaut hat. Das traditionelle SERP-API-Modell – feste Endpunkte, vorgegebene Ausgabefelder, nur Google – funktioniert gut für simples Rank-Tracking. Aber sobald du etwas leicht anderes brauchst (PAA-Antworten mit Sentiment, Local-Pack-Ergebnisse mit Bewertungszahlen oder Shopping-Daten, die für ein bestimmtes Datenbankschema formatiert sind), landest du schnell bei Nachbearbeitung oder Anbieterwechsel.
Thunderbits Extract API dreht dieses Modell um. Du sagst über ein JSON-Schema, was du willst, und die KI findet heraus, wie sie es von der jeweiligen Suchseite bekommt. Heute Google, morgen Bing, nächste Woche eine Nischen-Suchmaschine für eine bestimmte Branche – dieselbe API, derselbe Ansatz.
Die Distill API löst ein anderes Problem: unübersichtliche SERP-Seiten in sauberes Markdown zu verwandeln, das LLMs tatsächlich verarbeiten können, ohne an HTML-Resten, Navigationselementen und Tracking-Skripten zu scheitern. Wenn du eine RAG-Pipeline baust, die frische Suchbelege braucht, ist das der schnellste Weg von „live SERP“ zu „eingebetteter Inhalt“.
Beide Endpunkte enthalten Anti-Bot-Schutz, CAPTCHA-Lösung und JS-Rendering standardmäßig. Du zahlst dafür nicht extra – sie sind in den Credit-Kosten enthalten.
Probiere es selbst aus: für browserbasierte Extraktion oder nutze direkt die API für programmatische Workflows. Unser bietet Anleitungen, wenn du es vor dem Coden in Aktion sehen möchtest.
Ein Hinweis zur Rechtslage
Das kommt in jeder FAQ vor, deshalb hier die Kurzfassung: Die Rechtmäßigkeit von SERP-Scraping ist einzelfall- und jurisdiktionsabhängig. Der stellte fest, dass das Scrapen öffentlich zugänglicher Daten nicht zwangsläufig ein Computerstrafdelikt ist, gibt aber keine pauschale Erlaubnis. Google wegen SERP-Scraping, was zeigt, dass es rund um den Zugang aktiven kommerziellen Druck gibt.
Praktischer Rat: Nutze Vendor-APIs gemäß ihren Nutzungsbedingungen, vermeide das Sammeln personenbezogener Daten, wenn es nicht notwendig ist, und frage Anbieter, wie sie Compliance handhaben. Geh nicht davon aus, dass SERP-Scraping risikofrei ist.
Fazit
Kein einzelner Anbieter gewinnt in allen Dimensionen – die richtige Wahl hängt von deinem Anwendungsfall, Budget und Tech-Stack ab. Nach der Normalisierung der Preise, dem Testen der Geschwindigkeit, dem Mapping der Parsing-Abdeckung und der Bewertung der KI-Agenten-Reife ist hier mein Entscheidungsrahmen:
- Du brauchst Flexibilität + KI-Agenten-Tauglichkeit? → Thunderbit
- Du brauchst breite Google-Produktabdeckung? → SerpApi
- Du brauchst Tempo + niedrigste Kosten? → Serper oder Scrapingdog
- Du baust eine SEO-Plattform? → DataForSEO
- Enterprise-Maßstab mit SLA? → Bright Data oder DataForSEO
- Allgemeines Scraping + gelegentliche SERPs? → ScraperAPI oder Apify
Starte mit den Free-Tiers. Führe 20–50 echte Abfragen aus, die deiner produktiven Arbeitslast entsprechen. Vergleiche die JSON-Antworten. Prüfe die tatsächlichen Kosten nach Credits und Multiplikatoren. Dann entscheide dich.
Die Preise ändern sich in diesem Markt häufig – dieser Vergleich wurde im Mai 2026 auf Basis aktueller öffentlicher Seiten normalisiert. Wenn du das Monate später liest, prüfe die Preise vor dem Kauf erneut.
Mehr zu -Ansätzen und dem Vergleich mit klassischen Methoden haben wir ausführlich behandelt. Und wenn du evaluierst, übernimmt Thunderbits Chrome-Erweiterung auch diesen Teil.
FAQs
1. Was ist eine SERP-API und wer braucht sie?
Eine SERP-API ist ein Dienst, der Suchanfragen an Suchmaschinen wie Google, Bing oder Yandex sendet und die Ergebnisse als strukturierte Daten zurückgibt (meist JSON). SEO-Profis nutzen sie für Rank-Tracking, Sales-Teams zur Lead-Entdeckung, E-Commerce-Teams zur Preisüberwachung und KI-Entwickler, um Live-Suchdaten in Agenten und RAG-Pipelines einzuspeisen.
2. Wie viel kostet es, 1.000 Google-Suchergebnisse per API zu scrapen?
Die Spanne ist groß – von etwa 0,60 US-Dollar pro 1K (DataForSEO im Standard-Tarif) bis zu etwa 25 US-Dollar pro 1K (SerpApi Starter-Tarif). Rabatte bei hohem Volumen unterscheiden sich stark zwischen den Anbietern. Vergleiche immer die Kosten pro 1.000 erfolgreiche Anfragen statt nur die hervorgehobenen Listenpreise.
3. Kann ich eine SERP-API mit KI-Agenten wie LangChain oder n8n verwenden?
Ja. Serper ist in der n8n-Community für einfache Search-Aufrufe beliebt. Thunderbit ist besonders stark, wenn dein Agent Custom JSON-Schemata oder Markdown für RAG braucht. SerpApi eignet sich gut für Agenten, die stabile Google-Vertikaldaten (Maps, Scholar, Shopping) benötigen.
4. Welche SERP-API hat das beste Free Tier zum Testen?
Serper bietet bei der Anmeldung 2.500 kostenlose Anfragen – am großzügigsten in Bezug auf reines Volumen. SerpApi gibt 250/Monat, Scrapingdog 1.000 Credits, ScraperAPI 5.000 Test-Credits (7 Tage), und Thunderbit enthält kostenlose Credits für Prototyping. Apify hat monatliche Plattform-Credits im Wert von etwa 5 US-Dollar.
5. Welche SERP-Features sollte ich vor dem Kauf daraufhin prüfen, ob sie geparst werden?
Geh nicht davon aus, dass „strukturierte JSON-Daten“ vollständige Abdeckung bedeutet. Prüfe, ob die API strukturierte Felder für Folgendes zurückgibt: People Also Ask, Knowledge Panel, Local Pack/Maps, Shopping-Ergebnisse, Featured Snippets, Anzeigen (oben und unten), Image Pack und Video-Ergebnisse. Nutze die Parsing-Matrix in diesem Artikel als Start-Checkliste und teste mit echten Abfragen, bevor du dich für einen Plan entscheidest.
Mehr erfahren