Das Web ist längst keine saubere, statische Sammlung von Seiten mehr – eher ein wilder, ständig wechselnder Daten-Dschungel als eine digitale Bibliothek. Wenn Sie 2025 Daten von modernen Websites scrapen wollen, stehen Sie nicht nur vor einer Wand aus JavaScript, sondern vor einer Festung. Ich habe aus erster Hand erlebt, wie klassische Scraping-Tools an dynamischen Inhalten, endlosem Scrollen und Anti-Bot-Schutz scheitern. Genau deshalb ist der Aufstieg des Python Headless Browsers nicht bloß ein Trend, sondern eine echte Revolution für alle, die zuverlässige und skalierbare Web-Datenextraktion brauchen.
Und nicht nur Technik-Teams interessieren sich dafür. Bis 2025 setzen , und über . Ob Vertrieb, E-Commerce oder Operations: Der richtige Python Headless Browser macht den Unterschied zwischen „Daten auf Knopfdruck“ und „Daten außer Reichweite“. Blenden wir also den ganzen Lärm aus – ich habe diese Tools getestet, verglichen und im Alltag eingesetzt. Hier zeige ich die 10 besten Python Headless Browser für modernes Scraping – mit besonderem Fokus darauf, wie KI für Nicht-Programmierer das Spiel verändert.
Warum ist ein Python Headless Browser für modernes Scraping unverzichtbar?
Zuerst kurz zur Einordnung: Ein Python Headless Browser ist einfach ein Webbrowser, den Sie per Python-Code steuern – nur eben ohne das sperrige Fenster auf dem Bildschirm. Er lädt Seiten, führt JavaScript aus, klickt Buttons, füllt Formulare aus – alles unsichtbar im Hintergrund. Stellen Sie ihn sich als Geisterbrowser vor, der unermüdlich arbeitet, während Sie Ihren Kaffee trinken.
Warum ist das wichtig? Weil moderne Websites für Menschen gebaut sind, nicht für Bots. Sie verstecken Daten hinter JavaScript, verlangen Logins und erwarten, dass Sie sich wie ein echter Nutzer verhalten. Klassische Scraper, die nur HTML abrufen, starren dann auf leere Hüllen. Headless Browser dagegen simulieren echtes Nutzerverhalten – sie warten auf AJAX-Aufrufe, scrollen durch endlose Feeds und holen die Inhalte genau so, wie Sie sie in Chrome oder Firefox sehen ().
Aber da kommt noch mehr dazu:
- Geschwindigkeit & Effizienz: Headless Browser verzichten auf die visuelle Darstellung, sind dadurch schneller und brauchen weniger Speicher – ideal für Scraping im großen Maßstab ().
- Unterstützung für dynamische Inhalte: Sie führen JavaScript aus, sodass Sie echte, gerenderte Daten bekommen – nicht nur rohes HTML.
- Automatisierungs-Superkräfte: Müssen Sie sich einloggen, durch Seiten blättern oder Pop-ups behandeln? Python Headless Browser können das alles automatisieren.
- Skalierbarkeit: Hunderte Instanzen in der Cloud ausführen, Tausende Seiten parallel scrapen und dabei ganz entspannt bleiben.
Für Business-Anwender heißt das: Sie können endlich Leads sammeln, Wettbewerber beobachten oder Preise tracken – selbst wenn die Website wie Fort Knox gebaut ist. Und mit den neuesten KI-gestützten Tools brauchen Sie dafür nicht einmal Entwickler zu sein.
Wie wir die besten Python Headless Browser ausgewählt haben
Ich habe nicht einfach nur blind auf eine Liste von Browsernamen gezeigt. Darauf habe ich geachtet:
- Leistung & Geschwindigkeit: Kommt das Tool mit modernen, stark JavaScript-lastigen Websites schnell und zuverlässig zurecht?
- Browser-Unterstützung: Funktioniert es mit Chrome, Firefox, WebKit oder sogar älteren Engines wie IE?
- Benutzerfreundlichkeit: Ist es für Nicht-Programmierer geeignet, oder braucht man dafür einen Python-PhD?
- KI- & No-Code-Funktionen: Können Business-Anwender KI nutzen, um Scraping ohne Skripte zu automatisieren?
- Community & Support: Gibt es eine aktive Community, gute Doku und laufende Weiterentwicklung?
- Besondere Funktionen: Bietet das Tool etwas Spezielles – etwa sofort einsatzbereite Vorlagen, Cloud-Scraping oder Navigation über Unterseiten?
Ich habe Teams gesehen, die sich wochenlang mit dem Setup quälen und dann an die Wand laufen, sobald sich das Seitenlayout ändert. Die besten Tools funktionieren nicht nur – sie passen sich an, skalieren und machen das Leben leichter.
Die 10 besten Python Headless Browser für modernes Scraping
Hier ist meine endgültige Liste – mit einem Blick darauf, was jedes Tool auszeichnet (oder ausbremst).
1. Thunderbit
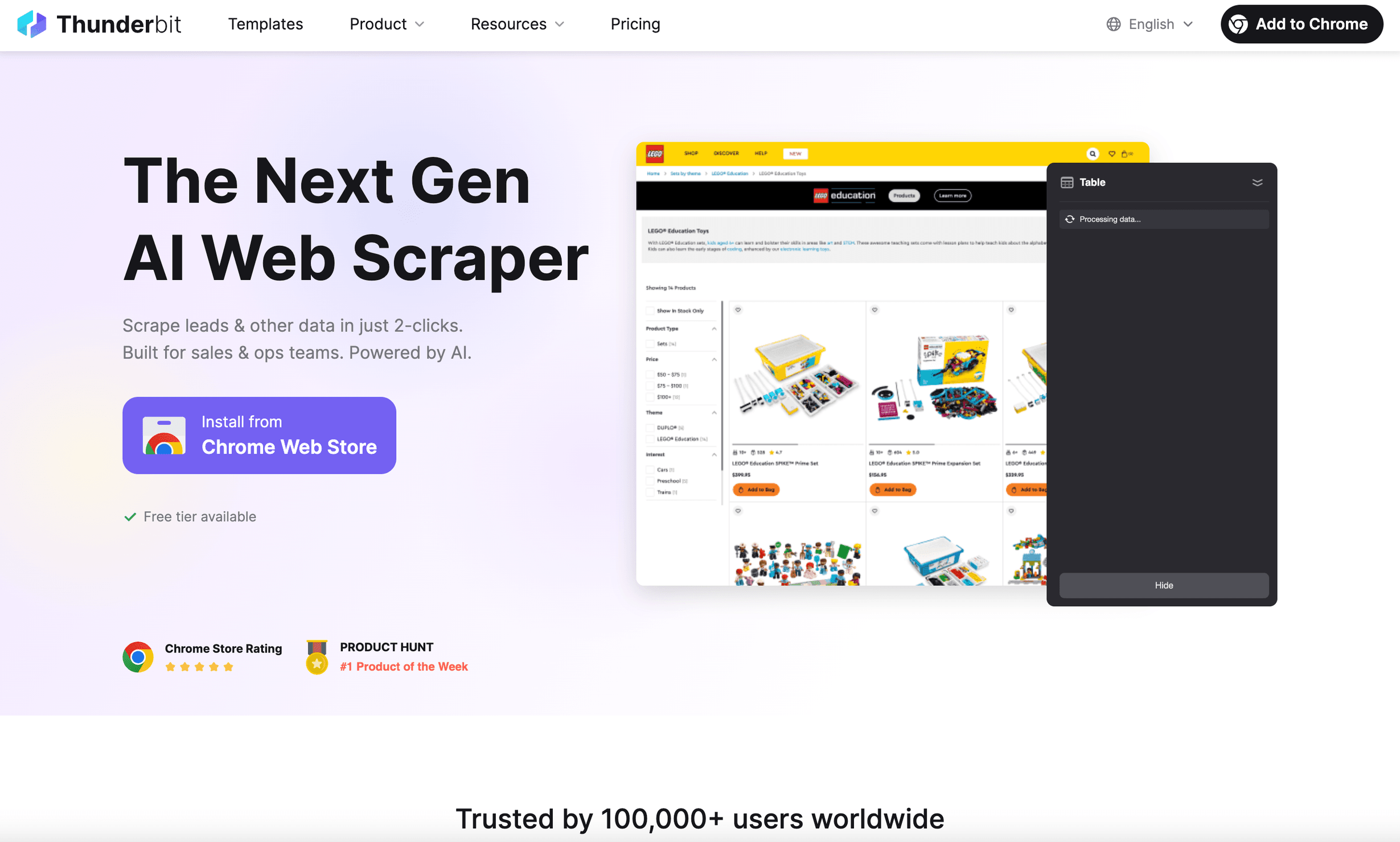 ist der Python Headless Browser, den ich mir vor Jahren gewünscht hätte. Es ist nicht einfach ein Browser-Automatisierungstool, sondern eine KI-gestützte Web-Scraper-Chrome-Erweiterung, gebaut für Business-Anwender, die Ergebnisse wollen – nicht Kopfschmerzen.
ist der Python Headless Browser, den ich mir vor Jahren gewünscht hätte. Es ist nicht einfach ein Browser-Automatisierungstool, sondern eine KI-gestützte Web-Scraper-Chrome-Erweiterung, gebaut für Business-Anwender, die Ergebnisse wollen – nicht Kopfschmerzen.
Warum Thunderbit heraussticht:
- KI-Felder vorschlagen: Einfach auf „KI-Felder vorschlagen“ klicken, und die KI von Thunderbit liest die Seite, empfiehlt die zu extrahierenden Daten und richtet den Scraper für Sie ein ().
- Sofortige Datenvorlagen: Für beliebte Websites (Amazon, Zillow, LinkedIn usw.) gibt es Vorlagen mit einem Klick – ganz ohne Setup.
- Scraping von Unterseiten & Paginierung: Thunderbit kann Unterseiten anklicken, endloses Scrollen handhaben und alle Daten in einer einzigen Tabelle zusammenführen.
- Prompts in natürlicher Sprache: Beschreiben Sie einfach auf Deutsch oder Englisch, was Sie möchten; der Rest läuft über die KI von Thunderbit.
- Scraping in der Cloud oder im Browser: Führen Sie Scrapes lokal oder in der Cloud aus – für mehr Tempo sogar mit bis zu 50 Seiten gleichzeitig.
- Kein Coding erforderlich: Wirklich – wenn Sie einen Browser bedienen können, können Sie Thunderbit nutzen.
- Kostenloser Datenexport: Exportieren Sie mit einem Klick nach Excel, Google Sheets, Notion oder Airtable.
Ich habe gesehen, wie Thunderbit Vertriebs- und Ops-Teams Stunden spart – beim Scrapen von Leads, beim Preis-Monitoring oder beim Aggregieren von Produktdaten, ganz ohne Code. Es wird weltweit von vertraut, und das Feedback ist durchweg: „Ich kann kaum glauben, wie einfach das ist.“
Am besten für: Nicht-technische Nutzer, Business-Teams, alle, die KI die schwere Arbeit machen lassen wollen.
2. Selenium
 ist der OG der Browser-Automatisierung. Wenn Sie jemals nach „Python Headless Browser“ gesucht haben, sind Sie wahrscheinlich schon über Selenium WebDriver gestolpert.
ist der OG der Browser-Automatisierung. Wenn Sie jemals nach „Python Headless Browser“ gesucht haben, sind Sie wahrscheinlich schon über Selenium WebDriver gestolpert.
Vorteile:
- Unterstützt alle wichtigen Browser: Chrome, Firefox, Safari, Edge, sogar Internet Explorer (für Mutige).
- Riesige Community: Unzählige Tutorials, Plugins und Stack-Overflow-Antworten.
- Sehr flexibel: Automatisiert alles, was ein Nutzer tun kann – Klicks, Formulare, Navigation.
Nachteile:
- Das Setup kann mühsam sein: Browser-Driver müssen verwaltet und Versionen synchron gehalten werden.
- Langsamer als moderne Tools: Das WebDriver-Protokoll bringt Overhead mit sich, und Hunderte Browser zu skalieren ist umständlich.
- Umständliche API: Sie schreiben mehr Code als mit Playwright oder Puppeteer.
Am besten für: Teams mit bestehender Selenium-Expertise, Cross-Browser-Tests oder ältere Automatisierungs-Workflows.
3. Puppeteer
 ist Googles High-Level-Automatisierungsbibliothek für Chrome/Chromium. Zwar ist sie nativ für Node.js, aber Python-Nutzer können über Pyppeteer trotzdem damit arbeiten.
ist Googles High-Level-Automatisierungsbibliothek für Chrome/Chromium. Zwar ist sie nativ für Node.js, aber Python-Nutzer können über Pyppeteer trotzdem damit arbeiten.
Vorteile:
- Auf Chrome optimiert: Schnell, effizient und eng mit Chrome DevTools integriert.
- Asynchrone API: Sehr gut für moderne, JavaScript-lastige Websites.
- Reich an Funktionen: Screenshots, PDF-Export, Netzwerk-Interception.
Nachteile:
- Nur Chromium: Keine Unterstützung für Firefox oder Safari.
- Nativ für Node.js: Python-Nutzer müssen Pyppeteer verwenden (das inzwischen nicht mehr gepflegt wird – siehe unten).
Am besten für: Entwickler, die schnelle und zuverlässige Chrome-Automatisierung wollen und keine Unterstützung für mehrere Browser brauchen.
4. Playwright
 ist der Newcomer im Feld, entwickelt von Microsoft – und ist für mich schnell zum Favoriten für fortgeschrittenes Scraping geworden.
ist der Newcomer im Feld, entwickelt von Microsoft – und ist für mich schnell zum Favoriten für fortgeschrittenes Scraping geworden.
Vorteile:
- Multi-Browser-Support: Automatisiert Chromium, Firefox und WebKit mit einer API.
- Auto-Waiting: Kein Rätselraten mehr, wann eine Seite bereit ist – Playwright wartet für Sie.
- Parallelität: Mehrere Browser-Contexts gleichzeitig ausführen für enorme Geschwindigkeit.
- Python-first: Native Python-Bindings, sowohl asynchron als auch synchron.
Nachteile:
- Größere Installation: Mehrere Browser werden mitgeliefert, das Setup ist also etwas schwerer.
- Trotzdem Coding nötig: Für nicht-technische Nutzer nicht so einsteigerfreundlich wie Thunderbit.
Am besten für: Entwickler, die robuste, moderne Automatisierung brauchen – besonders für komplexe, dynamische Web-Apps.
5. Headless Chrome
 ist die Engine hinter vielen der oben genannten Tools. Sie können ihn direkt über das Chrome DevTools Protocol (CDP) steuern, um maximale Flexibilität zu erhalten.
ist die Engine hinter vielen der oben genannten Tools. Sie können ihn direkt über das Chrome DevTools Protocol (CDP) steuern, um maximale Flexibilität zu erhalten.
Vorteile:
- Modernste Web-Unterstützung: Wenn es in Chrome funktioniert, funktioniert es auch in Headless Chrome.
- Feingranulare Kontrolle: Zugriff auf jede Ecke und jedes Detail des Browsers.
Nachteile:
- Steile Lernkurve: Sie müssen CDP beherrschen oder eine Wrapper-Bibliothek verwenden.
- Nur Chrome: Keine Unterstützung für mehrere Browser.
Am besten für: Experten, die eigene Automatisierungspipelines bauen oder Chrome auf niedriger Ebene integrieren.
6. Pyppeteer
 ist die inoffizielle Python-Portierung von Puppeteer. Sie brachte asynchrone Chrome-Automatisierung nach Python, aber … es gibt einen Haken.
ist die inoffizielle Python-Portierung von Puppeteer. Sie brachte asynchrone Chrome-Automatisierung nach Python, aber … es gibt einen Haken.
Vorteile:
- Puppeteer-ähnliche API: Wenn Sie Puppeteer kennen, fühlen Sie sich sofort zu Hause.
- Schnelle Chrome-Automatisierung: Sehr gut für dynamische Websites.
Nachteile:
- Nicht mehr gepflegt: Das ursprüngliche Projekt wird nicht mehr aktualisiert (die Entwickler empfehlen den Umstieg auf Playwright).
- Nur Chromium: Keine Unterstützung für Firefox oder Safari.
Am besten für: Legacy-Projekte, die bereits Pyppeteer verwenden. Für neue Projekte sollten Sie Playwright nehmen.
7. Splash
 ist ein leichter, skriptfähiger Headless Browser mit HTTP-API, entwickelt vom Scrapinghub- (heute Zyte-) Team.
ist ein leichter, skriptfähiger Headless Browser mit HTTP-API, entwickelt vom Scrapinghub- (heute Zyte-) Team.
Vorteile:
- Leichtgewichtig: Nutzt QtWebKit und ist dadurch ressourcenschonender als Chrome.
- HTTP-API: Von jeder Sprache aus steuerbar, nicht nur mit Python.
- Sehr gut für Scrapy: Lässt sich nahtlos in Scrapy-Spider für JS-Rendering integrieren.
Nachteile:
- Ältere WebKit-Engine: Kann bei modernem JavaScript an Grenzen stoßen.
- Lua-Skripting erforderlich: Für fortgeschrittene Interaktionen müssen Sie etwas Lua lernen.
Am besten für: Scrapy-Nutzer, die gelegentlich JavaScript-Rendering brauchen, oder leichte serverseitige Rendering-Aufgaben.
8. PhantomJS
 ist der ursprüngliche skriptfähige Headless Browser, aufgebaut auf WebKit. Er war ein Pionier – ist heute aber weitgehend veraltet.
ist der ursprüngliche skriptfähige Headless Browser, aufgebaut auf WebKit. Er war ein Pionier – ist heute aber weitgehend veraltet.
Vorteile:
- Einfache Skripterstellung: Mit JavaScript leicht zu automatisieren.
- Legacy-Support: Funktioniert noch für ältere, statische Websites.
Nachteile:
- Nicht mehr gepflegt: Seit 2016 keine Updates mehr.
- Veraltete Engine: Kommt mit modernen, stark JS-lastigen Websites nicht zurecht.
- Sicherheitsrisiken: Keine aktuellen Patches.
Am besten für: Pflege alter Skripte. Für neue Projekte sollten Sie auf Playwright oder Puppeteer migrieren.
9. HtmlUnit
 ist ein Java-basierter Headless Browser, der Browserverhalten simuliert. Er ist schnell und leichtgewichtig, aber keine echte Browser-Engine.
ist ein Java-basierter Headless Browser, der Browserverhalten simuliert. Er ist schnell und leichtgewichtig, aber keine echte Browser-Engine.
Vorteile:
- Reines Java: Ideal für Java-lastige Umgebungen.
- Schnell bei statischen Seiten: Kein vollständiger Browserstart nötig.
Nachteile:
- Begrenzter JS-Support: Hat Probleme mit modernen, dynamischen Websites.
- Nicht nativ für Python: Erfordert Integrationsschichten, z. B. Seleniums HtmlUnitDriver.
Am besten für: Java-basierte Workflows, Tests älterer Anwendungen oder Scraping einfacher, servergerenderter Seiten.
10. TrifleJS
 ist ein Headless Browser für Internet Explorer (IE), gedacht für die Automatisierung alter Web-Apps unter Windows.
ist ein Headless Browser für Internet Explorer (IE), gedacht für die Automatisierung alter Web-Apps unter Windows.
Vorteile:
- IE-Automatisierung: Beherrscht alte Intranet-Apps oder Systeme, die nur in IE funktionieren.
- API ähnlich wie PhantomJS: Für PhantomJS-Skripte sind nur minimale Änderungen nötig.
Nachteile:
- Nur unter Windows: Keine plattformübergreifende Unterstützung.
- Veraltet: IE ist abgekündigt; TrifleJS ist eine Nische und wird selten gepflegt.
Am besten für: Spezialisierte Legacy-Workflows, bei denen IE-Automatisierung noch nötig ist.
Vergleichstabelle der Funktionen: Python Headless Browser auf einen Blick
| Tool | Browser-Unterstützung | Leistung & Skalierung | Benutzerfreundlichkeit | KI/No-Code-Funktionen | Community & Support | Am besten für |
|---|---|---|---|---|---|---|
| Thunderbit | Chrome (Erweiterung/Cloud) | Hoch (Cloud-Parallelität) | Am einfachsten – kein Code | Ja (KI, Vorlagen) | Wachsend, aktiv | Nicht-Programmierer, Sales/Ops, schnelle Datenextraktion |
| Selenium | Alle wichtigen Browser | Mittel | Mittel (Setup) | Nein | Riesig, ausgereift | Cross-Browser, Legacy, Testautomatisierung |
| Puppeteer | Chromium/Chrome | Sehr hoch | Hoch (für Entwickler) | Nein | Groß (Node.js) | Nur Chrome, Entwickler, schnelle Automatisierung |
| Playwright | Chromium, Firefox, WebKit | Sehr hoch (Multi-Context) | Hoch (für Entwickler) | Nein | Schnell wachsend | Fortgeschritten, Multi-Browser, modernes Scraping |
| Headless Chrome | Chrome/Edge | Sehr hoch | Niedrig (manuelles CDP) | Nein | N/A (Grundlage) | Benutzerdefiniert, Experten, Low-Level-Kontrolle |
| Pyppeteer | Chromium/Chrome | Hoch | Mittel (async) | Nein | Klein, nicht gepflegt | Alte Pyppeteer-Skripte |
| Splash | QtWebKit | Mittel | Mittel (API/Lua) | Nein | Nische (Scrapy/Zyte) | Scrapy-Nutzer, leichtgewichtiges JS-Rendering |
| PhantomJS | WebKit (alt) | Niedrig (heute veraltet) | Mittel (JS) | Nein | Eingestellt | Nur für Legacy-Fälle |
| HtmlUnit | Simuliert (Java) | Mittel/Hoch (statisch) | Niedrig (Java) | Nein | Klein, Java-zentriert | Java-Workflows, einfache/statische Seiten |
| TrifleJS | Internet Explorer (Trident) | Niedrig/Mittel | Mittel (JS, Win) | Nein | Winzig, Legacy | Legacy-Automatisierung nur für IE |
Wie Sie den richtigen Python Headless Browser für Ihr Unternehmen auswählen
Hier ist mein Spickzettel für die Auswahl des richtigen Tools:
- Sie brauchen schnelles No-Code-Scraping mit KI-Unterstützung? Dann nehmen Sie . Für Nicht-Programmierer ist es der einfachste Weg zu verlässlichen Daten – besonders für Sales-, E-Commerce- oder Research-Teams.
- Sie wollen maximale Kontrolle und Unterstützung für mehrere Browser? Dann ist die beste Wahl. Es ist robust, modern und für Skalierung gebaut.
- Sie haben bereits in Selenium investiert? Bleiben Sie bei – es ist weiterhin der Platzhirsch für Legacy- und Multi-Browser-Workflows.
- Sie bauen als Entwickler Chrome-only-Automatisierung? (oder Playwright) ist schnell und leistungsstark.
- Sie scrapen einfache, statische Seiten in einer Java-Umgebung? ist leichtgewichtig und einfach zu integrieren.
- Sie pflegen Legacy-Skripte oder IE-only-Apps? und sind Ihre Freunde – wenn auch nur als letzte Option.
Und denken Sie daran: Das beste Tool ist das, das zu Ihrem Workflow, den Fähigkeiten Ihres Teams und Ihren Geschäftsanforderungen passt. Manchmal heißt das auch, mehrere Tools zu kombinieren – Thunderbit für schnelle Aufgaben, Playwright für Schweres und Selenium für alte Systeme.
FAQs
1. Was ist ein Python Headless Browser, und warum brauche ich einen fürs Scraping?
Ein Python Headless Browser ist ein Webbrowser, den Sie mit Python-Code steuern, der aber unsichtbar läuft (ohne GUI). Er ist unverzichtbar für das Scraping moderner, stark JavaScript-lastiger Websites, weil er Skripte ausführen, Nutzerinteraktionen behandeln und vollständig gerenderte Inhalte extrahieren kann – etwas, das klassische HTML-Scraper nicht leisten.
2. Welcher Python Headless Browser ist am besten für nicht-technische Nutzer?
ist die beste Wahl für Nicht-Programmierer. Es nutzt KI, um das Setup zu automatisieren, bietet sofort einsatzbereite Vorlagen und ermöglicht Datenextraktion in nur wenigen Klicks – ganz ohne Programmierung.
3. Worin unterscheiden sich Playwright und Puppeteer für Python-Nutzer?
Playwright unterstützt mehrere Browser (Chromium, Firefox, WebKit) und hat robuste Python-Bindings, was es ideal für fortgeschrittene Automatisierung macht. Puppeteer ist nur für Chrome und nativ für Node.js, aber Python-Nutzer können Pyppeteer verwenden (auch wenn es inzwischen nicht mehr gepflegt wird). Für neue Python-Projekte ist Playwright die bessere Wahl.
4. Ist Selenium für modernes Web-Scraping noch relevant?
Ja – Selenium wird weiterhin häufig genutzt, vor allem für Cross-Browser-Tests und Legacy-Automatisierung. Es ist jedoch langsamer und komplexer einzurichten als neuere Tools wie Playwright oder Thunderbit und bei Scraping im großen Maßstab weniger effizient.
5. Wann sollte ich Legacy-Tools wie PhantomJS, HtmlUnit oder TrifleJS verwenden?
Nur zur Wartung oder Migration alter Workflows. PhantomJS und TrifleJS sind veraltet, und HtmlUnit eignet sich am besten für Java-basierte Umgebungen mit einfachen Seiten. Für neue Projekte sollten Sie moderne, aktiv gepflegte Tools verwenden.
Wenn Sie sehen wollen, wie modernes, KI-gestütztes Scraping aussieht, . Und für mehr tiefgehende Einblicke in Web-Automatisierung schauen Sie im vorbei. Viel Spaß beim Scraping – möge Ihre Datenbasis immer frisch und Ihr Browser für immer headless sein.
Mehr erfahren