Das Internet ist eine echte Goldmine an Infos – aber aus diesem riesigen Datenmeer wirklich nützliche Erkenntnisse für dein Business zu ziehen, ist die eigentliche Kunst und gleichzeitig eine riesige Chance. In meinen Jahren als Entwickler für SaaS- und Automatisierungslösungen habe ich hautnah miterlebt, wie Unternehmen sich von Bauchgefühl hin zu datengetriebenen Prozessen entwickelt haben. Heute sind es längst nicht mehr nur die großen Tech-Player, die Daten aus Webseiten ziehen – auch kleine Teams nutzen das, um Vertrieb, Marketing, Preise und Produktentwicklung auf ein neues Level zu bringen. Aber je komplexer und dynamischer das Web wird, desto kniffliger ist es, saubere, rechtssichere und wirklich brauchbare Daten zu bekommen.
Lass uns konkret werden: Ich zeige dir, warum Webdaten-Extraktion für moderne Unternehmen so wichtig ist, welche Stolperfallen es gibt und wie du – mit Best Practices und Erfahrungen aus dem Thunderbit-Team – rechtssicher, effizient und skalierbar vorgehst. Egal, ob du mit unstrukturierten Inhalten kämpfst, dir Sorgen um Datenschutz machst oder einfach das Copy-Paste in Tabellen leid bist: Dieser Guide ist genau für dich.
Warum Webdaten-Extraktion für Unternehmen ein Muss ist
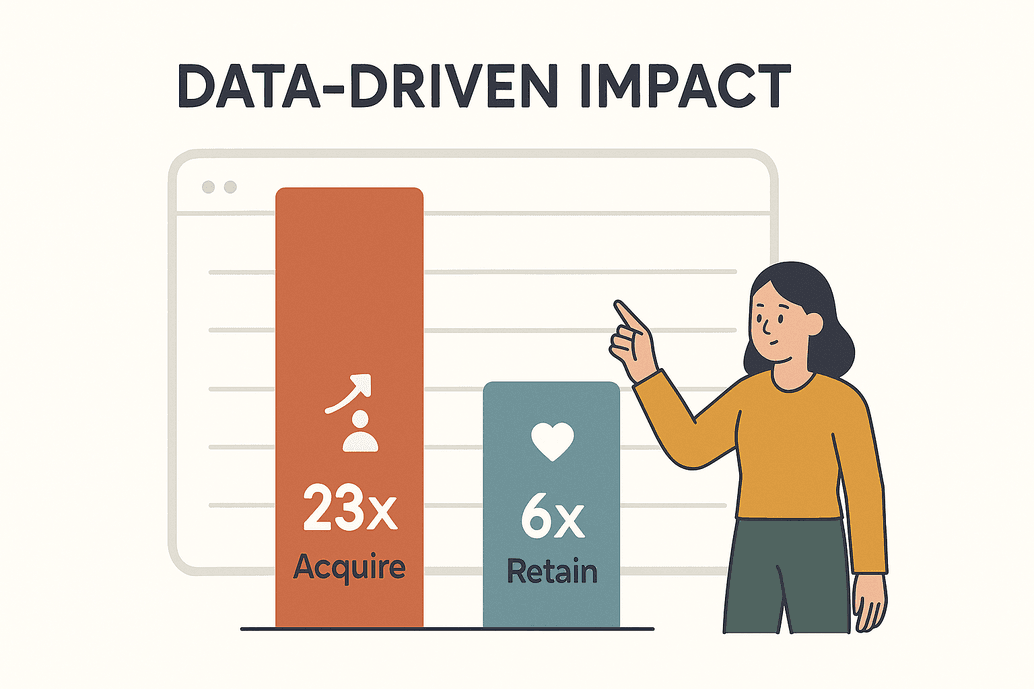 Daten sind heute viel mehr als nur ein Buzzword – sie sind das Rückgrat jedes erfolgreichen Unternehmens. Laut einer haben datengetriebene Unternehmen 23-mal höhere Chancen, neue Kunden zu gewinnen, und sind 6-mal besser darin, sie zu halten. Das ist nicht nur beeindruckend, sondern überlebenswichtig. Bis 2025 werden Unternehmen täglich Milliarden von Webseiten auslesen, um Analysen, KI-Modelle und schnelle Entscheidungen zu ermöglichen ().
Daten sind heute viel mehr als nur ein Buzzword – sie sind das Rückgrat jedes erfolgreichen Unternehmens. Laut einer haben datengetriebene Unternehmen 23-mal höhere Chancen, neue Kunden zu gewinnen, und sind 6-mal besser darin, sie zu halten. Das ist nicht nur beeindruckend, sondern überlebenswichtig. Bis 2025 werden Unternehmen täglich Milliarden von Webseiten auslesen, um Analysen, KI-Modelle und schnelle Entscheidungen zu ermöglichen ().
Wie sieht das im Alltag aus? Hier ein paar typische Use Cases, die ich immer wieder sehe:
| Business Application | Description & Benefits | Example/Stat |
|---|---|---|
| Preisüberwachung | Konkurrenzpreise, Lagerbestände und Aktionen in Echtzeit verfolgen; eigene Strategie flexibel anpassen. | Über 80 % der führenden Online-Händler beobachten täglich die Preise der Konkurrenz (kanhasoft.com). |
| Lead-Generierung | Verzeichnisse, soziale Netzwerke oder Bewertungsportale nach neuen Kontakten durchsuchen. | Automatisierte Datenerfassung füllt CRMs schneller als jede manuelle Recherche. |
| Markt- und Trendanalyse | Bewertungen, Foren und News aggregieren, um Trends und Stimmungswechsel frühzeitig zu erkennen. | 26 % der Scraping-Aktivitäten zielen auf Social Media für Trendanalysen (blog.apify.com). |
| Content-Aggregation | Nachrichten, Produktlisten oder Events von verschiedenen Seiten bündeln. | Redaktionsteams kuratieren Feeds für ihre Zielgruppen. |
| Produkt- & Forschungsdaten | Produktdetails, Bewertungen oder Forschungsdaten für Analysen und Entwicklung sammeln. | 67 % der Investmentberater nutzen alternative Webdaten (scrap.io). |
| KI-Trainingsdaten | Große Mengen an Texten, Bildern oder Datensätzen für KI-Modelle extrahieren. | Rund 70 % großer KI-Modelle basieren auf gescrapten Webdaten (kanhasoft.com). |
Wer heute keine Webdaten extrahiert, ist praktisch unsichtbar im Markt. Ich habe E-Commerce-Teams gesehen, die ihren ROI in nur sechs Monaten verdreifacht haben, weil sie Preisüberwachung automatisiert haben (). Fazit: Webdaten sind ein strategischer Vorteil – und professionelle Extraktion ist heute Pflicht.
Die größten Hürden bei der Webdaten-Extraktion
Natürlich ist das Ganze nicht so easy wie ein simpler CSV-Export. Das Web ist chaotisch, und beim Datenziehen gibt’s echte Herausforderungen:
- Unstrukturierte Daten: Rund 80 % der Online-Daten sind unstrukturiert – versteckt in wildem HTML, verteilt auf zig Seiten oder hinter interaktiven Elementen. Eine saubere Tabelle daraus zu machen, ist echte Handwerkskunst ().
- Ständig wechselnde Webseiten: Layouts ändern sich ständig. Ich habe erlebt, dass ein Scraper in einem Monat 15-mal angepasst werden musste, weil die Zielseite ihr Design geändert hat ().
- Menge und Skalierung: Unternehmen müssen oft hunderte oder tausende Seiten regelmäßig auslesen. Copy-Paste per Hand? Keine Chance.
- Anti-Scraping-Maßnahmen: CAPTCHAs, Zugriffsbeschränkungen, Login-Pflichten – Webseiten werden immer besser darin, Bots zu blocken. Über ein Drittel des Web-Traffics kommt inzwischen von Bots (), und die Abwehrmechanismen werden ständig weiterentwickelt.
- Fehleranfälligkeit bei Handarbeit: Manuelles Kopieren ist langsam und fehleranfällig. Ein falscher Selektor – und du ziehst die falschen Daten oder gar nichts.
Klassische Methoden stoßen hier schnell an ihre Grenzen. Deshalb setzen immer mehr Teams auf smarte, automatisierte Lösungen – und ich bin überzeugt: KI-basierte Tools sind die Zukunft.
Recht, Compliance & Sicherheit beim Webdaten-Extrahieren
Klartext: Nur weil du Daten aus einer Webseite extrahieren kannst, heißt das nicht, dass du es auch darfst – zumindest nicht ohne die rechtlichen und ethischen Spielregeln zu beachten. Was Unternehmen wissen sollten:
- Öffentliche vs. private Daten: Das Auslesen öffentlich zugänglicher Infos ist in vielen Ländern erlaubt. Alles, was hinter einem Login liegt, ist tabu. Authentifizierungen zu umgehen, ist ein absolutes No-Go ().
- Nutzungsbedingungen: Schau dir immer die ToS einer Seite an. Ist Scraping verboten, drohen rechtliche Konsequenzen oder Sperrungen. Im Zweifel: Erlaubnis holen oder offizielle APIs nutzen.
- Datenschutzgesetze (DSGVO, CCPA): Wer personenbezogene Daten sammelt, braucht eine rechtliche Grundlage (z. B. berechtigtes Interesse), muss die Datenerhebung minimieren und auf Anfrage löschen. Verstöße können richtig teuer werden ().
- robots.txt beachten: Nicht rechtlich bindend, aber guter Stil. Halte dich an Crawl-Delays und überlaste keine Server.
- Datensicherheit: Behandle extrahierte Daten vertraulich. Sicher speichern, Zugriffe beschränken und vor Nutzung bereinigen.
Compliance-Checkliste:
| Consideration | Best Practice |
|---|---|
| Rechtmäßiger Zugriff | Nur öffentliche Daten extrahieren; niemals Logins umgehen (xbyte.io). |
| Nutzungsbedingungen | ToS prüfen und respektieren; bei Verbot offizielle APIs nutzen. |
| Personenbezogene Daten | Nach Möglichkeit vermeiden; falls nötig, minimieren und DSGVO/CCPA einhalten. |
| robots.txt & Crawl-Delays | Seitenregeln beachten; Anfragen drosseln. |
| Datensicherheit | Verschlüsseln, Zugriffe beschränken, bei Bedarf löschen. |
Effizienz-Booster: Wie KI die Webdaten-Extraktion verändert
Jetzt wird’s spannend: Künstliche Intelligenz hat das Extrahieren von Webdaten komplett auf den Kopf gestellt. Statt mühsam Selektoren zu basteln oder fehleranfällige Skripte zu schreiben, kannst du heute KI-gestützte Tools nutzen, die Webseiten „verstehen“ und relevante Daten mit wenigen Klicks rausziehen.
Was heißt das konkret?
- Kaum Einrichtung nötig: KI-Web-Scraper wie erkennen Felder automatisch. Ein Klick auf „KI-Felder vorschlagen“ – und die passenden Spalten werden angezeigt. Kein Programmieren, kein Rätselraten.
- Anpassungsfähigkeit: KI erkennt Muster statt starrer Layouts. Ändert sich die Seite, passt sich die KI oft selbst an. Weniger Wartung, weniger Stress.
- Hohe Genauigkeit: KI filtert Störfaktoren, entfernt Duplikate und bereinigt Daten schon beim Extrahieren. Manche Teams berichten von Genauigkeitsraten bis zu 99,5 % mit KI-Tools ().
- Dynamische Inhalte: KI-Scraper kommen mit JavaScript-lastigen Seiten, Endlos-Scrolls und sogar Texterkennung aus Bildern oder PDFs klar.
- Direkte Verarbeitung: Du brauchst Übersetzungen, Kategorisierungen oder Zusammenfassungen direkt beim Scrapen? KI macht das alles in einem Rutsch.
 Ich habe Teams gesehen, die mit KI-Tools 30–40 % Zeitersparnis bei der Datenerfassung schaffen (). Das ist nicht nur effizienter, sondern bringt dir einen echten Vorsprung.
Ich habe Teams gesehen, die mit KI-Tools 30–40 % Zeitersparnis bei der Datenerfassung schaffen (). Das ist nicht nur effizienter, sondern bringt dir einen echten Vorsprung.
Thunderbit macht das Extrahieren einfach, präzise und für alle zugänglich – auch für Leute ohne Programmierkenntnisse. (Und ja, sogar meine Mutter kommt damit klar. Netflix übt sie noch.)
Thunderbit KI-Web-Scraper: Die wichtigsten Features für Unternehmen
Ein bisschen Eigenlob muss sein: Thunderbit wurde speziell für Business-User entwickelt – Vertrieb, Operations, Marketing, Immobilien – die Ergebnisse wollen, keine Kopfschmerzen. Das macht Thunderbit besonders:
- KI-Felder vorschlagen: Ein Klick, und Thunderbits KI scannt die Seite, schlägt Spalten vor und richtet den Scraper ein. Kein Selektoren-Gefummel mehr.
- 2-Klick-Scraping: Felder festlegen, auf „Scrapen“ klicken – und schon hast du eine saubere Tabelle. Ohne Programmierung, ohne Aufwand.
- Unterseiten-Scraping: Mehr Details nötig? Thunderbit besucht automatisch jede Unterseite (z. B. Produkt- oder Profilseiten) und ergänzt deine Tabelle mit weiteren Infos.
- Vorlagen für beliebte Seiten: Für Plattformen wie Amazon, Zillow, Instagram, Shopify & Co. einfach Vorlage auswählen und loslegen – keine Einrichtung nötig.
- Export überallhin: Kostenloser Export nach Excel, Google Sheets, Airtable, Notion oder als CSV. Keine versteckten Kosten.
- Geplanter Scraper: Wiederkehrende Extraktionen automatisieren – einfach das Intervall beschreiben („jeden Montag um 8 Uhr“), Thunderbit macht den Rest.
- Cloud- oder Browser-Scraping: Nutze Thunderbits Cloud-Server für Speed oder deinen eigenen Browser für Seiten mit Login.
- Mehrsprachigkeit: Extrahiere Daten in 34 Sprachen, darunter Deutsch, Englisch, Spanisch, Chinesisch und viele mehr.
Automatisieren & skalieren: Mit Zeitplänen und Integrationen Webdaten extrahieren
Manuelles Scraping ist längst Geschichte. Der echte Mehrwert entsteht, wenn du die Datenerfassung automatisierst und direkt in deine Workflows einbaust:
- Geplanter Scraper: Lass Thunderbit täglich, wöchentlich oder nach deinem Wunschintervall laufen. Perfekt für Preisüberwachung, Lead-Generierung oder News-Aggregation.
- Direkte Integration: Exportiere Daten direkt nach Google Sheets, Excel, Airtable oder Notion. Kein Download und erneutes Hochladen mehr.
- CRM- & Analyse-Integration: Übertrage Daten direkt ins CRM oder BI-Tool – für Echtzeit-Dashboards, Benachrichtigungen oder automatisierte Aktionen.
Beispiel: Automatisierte Preisüberwachung
- Thunderbit auf der Produktseite eines Mitbewerbers einrichten.
- Mit „KI-Felder vorschlagen“ Produktname, Preis und URL erfassen.
- Scraping täglich um 7 Uhr morgens planen.
- Ergebnisse nach Google Sheets exportieren und mit dem Dashboard verknüpfen.
- Der Preismanager prüft Änderungen und passt die Strategie an – bevor die Konkurrenz reagiert.
Mit Automatisierung bist du nicht nur schneller, sondern immer up to date.
Best Practices für unstrukturierte Webdaten
Die Realität: Die meisten Webdaten sind unstrukturiert, inkonsistent und manchmal einfach chaotisch. So bringst du Ordnung rein:
- Struktur vorab festlegen: Nutze KI-Feldvorschläge oder Vorlagen, um von Anfang an eine klare Struktur zu schaffen – Spalten und Datentypen vor dem Scraping definieren.
- Feld-AI-Prompts: In Thunderbit kannst du für jedes Feld eigene Anweisungen hinterlegen. Produkte kategorisieren, Telefonnummern formatieren oder Beschreibungen übersetzen? Sag der KI einfach, was du willst.
- NLP nutzen: Für Bewertungen, Kommentare oder Artikel helfen eingebaute NLP-Funktionen beim Zusammenfassen, Sentiment-Scoring oder Extrahieren von Schlagwörtern.
- Daten normalisieren: Formate (z. B. Datum, Preis, Telefonnummer) schon beim Scraping vereinheitlichen. Konsistenz ist entscheidend.
- Duplikate entfernen & validieren: Doppelte Einträge löschen und Ergebnisse stichprobenartig prüfen. Bei Auffälligkeiten Prompts oder Einstellungen anpassen.
Feld-AI-Prompts: Extraktion individuell steuern
Eines meiner Lieblingsfeatures: Mit Feld-Prompts kannst du zum Beispiel:
- Labeln & Kategorisieren: „Ordne dieses Produkt als Elektronik, Möbel oder Kleidung ein – je nach Beschreibung.“
- Formate erzwingen: „Gib das Datum im Format JJJJ-MM-TT aus.“ „Extrahiere nur den numerischen Preis.“
- Direkt übersetzen: „Übersetze die Produktbeschreibung ins Deutsche.“
- Störfaktoren entfernen: „Ziehe die Nutzer-Bio, ignoriere ‚Mehr lesen‘-Links oder Werbung.“
- Felder kombinieren: „Fasse Adresszeilen zu einem Feld zusammen.“
Das ist, als hättest du einen fleißigen Junior-Analysten direkt im Scraper – und der braucht nie eine Kaffeepause.
Datenqualität und Konsistenz bei der Webdaten-Extraktion sichern
Gute Datenerfassung endet nicht beim Export. So bleiben deine Daten sauber und verlässlich:
- Validierung: Bereichsprüfungen, Pflichtfelder und eindeutige Schlüssel helfen, Fehler zu erkennen.
- Stichprobenkontrolle: Prüfe regelmäßig eine Auswahl der extrahierten Daten direkt an der Quelle – besonders nach der Einrichtung oder bei Webseiten-Änderungen.
- Fehlerbehandlung: Fehlgeschlagene Scrapes protokollieren und bei Auffälligkeiten (z. B. plötzlicher Rückgang der Zeilenzahl) Benachrichtigungen einrichten.
- Laufende Bereinigung: Mit Tabellen-Tools oder Skripten Leerzeichen entfernen, Codierungen korrigieren und Texte normalisieren.
- Schema-Konsistenz: Feldnamen und Formate über die Zeit stabil halten. Änderungen dokumentieren, damit das Team immer den Überblick behält.
Vertrauen in deine Daten ist alles. Sorgfalt am Anfang erspart später viel Ärger.
Web-Scraping-Tools im Vergleich: Worauf du achten solltest
Nicht jedes Web-Scraping-Tool ist gleich. Das solltest du beachten:
| Tool | Strengths | Considerations |
|---|---|---|
| Thunderbit | Besonders einfach für Nicht-Techniker; KI-Felderkennung; Unterseiten-Scraping; Vorlagen; kostenloser Export; günstige Tarife (Thunderbit Blog). | Nicht für extrem große Entwicklerprojekte; nutzt ein Creditsystem. |
| Browse AI | No-Code, gut für Änderungsüberwachung; Google Sheets-Integration; Massendatenextraktion. | Höhere Einstiegspreise; Einrichtung kann aufwendig sein. |
| Octoparse | Leistungsstark, auch für dynamische Seiten; viele Profi-Features. | Hohe Lernkurve; teurer. |
| Web Scraper (webscraper.io) | Kostenlos für kleine Projekte; visuelle Einrichtung; große Community. | Manuelle Einrichtung kann verwirrend sein; wenig KI-Unterstützung. |
| Diffbot | KI-basiert, analysiert unstrukturierte Seiten via API; ideal für Entwickler. | Teuer, API-basiert, nicht für Nicht-Techniker. |
Mein Tipp: Wenn du als Business-User schnelle, präzise Ergebnisse willst, bist du mit super beraten. Für Power-User oder Entwickler können Octoparse oder Diffbot die richtige Wahl sein. Teste immer erst die kostenlose Version, bevor du dich festlegst.
Fazit: Webdaten-Extraktion in der Praxis
Webdaten zu extrahieren ist heute kein „Nice-to-have“ mehr, sondern Pflicht für jedes Unternehmen, das wettbewerbsfähig bleiben will. Das solltest du mitnehmen:
- Mehrwert: Webdaten ermöglichen bessere, schnellere Entscheidungen. Nutze dieses Potenzial.
- Herausforderungen meistern: Mit KI-Tools bewältigst du unstrukturierte Daten, große Mengen und Webseiten-Änderungen.
- Rechtssicherheit: Datenschutz, Seitenregeln und Datensicherheit beachten.
- Automatisieren: Integriere die Extraktion in deine täglichen Abläufe.
- Qualität zählt: Daten validieren, bereinigen und laufend überwachen.
Neugierig, wie einfach das geht? und probiere es bei deinem nächsten Datenprojekt aus. Noch mehr Tipps, Anleitungen und Praxisbeispiele findest du im .
Viel Erfolg beim Scrapen – und mögen deine Daten immer strukturiert, rechtssicher und einsatzbereit sein.
Häufige Fragen (FAQ)
1. Ist es legal, Daten von jeder Website zu extrahieren?
In vielen Ländern ist das Auslesen öffentlich zugänglicher Daten erlaubt, solange keine Logins oder Sicherheitsmechanismen umgangen werden. Prüfe immer die Nutzungsbedingungen und halte Datenschutzgesetze wie DSGVO und CCPA ein ().
2. Wie verbessert KI die Webdaten-Extraktion?
KI-Tools wie erkennen Felder automatisch, passen sich an Layout-Änderungen an, bereinigen und formatieren Daten und kommen auch mit dynamischen Inhalten oder Übersetzungen klar – alles mit minimalem Aufwand und hoher Genauigkeit ().
3. Was sind Best Practices für unstrukturierte Daten?
Lege die Datenstruktur vorab fest, nutze Feld-Prompts zur Steuerung der Extraktion, normalisiere Formate schon beim Scraping und validiere die Ergebnisse. Mit Thunderbit kannst du Daten direkt kategorisieren, formatieren und beschriften.
4. Wie kann ich Webdaten-Extraktion automatisieren und skalieren?
Nutze Zeitpläne für regelmäßige Extraktionen und integriere die Ergebnisse direkt in Tools wie Google Sheets, Airtable oder dein CRM. So bleiben deine Daten immer aktuell und der manuelle Aufwand sinkt.
5. Wie stelle ich die Qualität und Konsistenz der extrahierten Daten sicher?
Führe Validierungen durch, prüfe regelmäßig Stichproben, behandle Fehler systematisch und halte dein Datenschema konsistent. Kontinuierliche Kontrolle und Optimierung sind entscheidend für verlässliche Daten.
Du willst diese Best Practices live erleben? und erlebe, wie einfach, rechtssicher und skalierbar Webdaten-Extraktion sein kann.
Mehr erfahren