

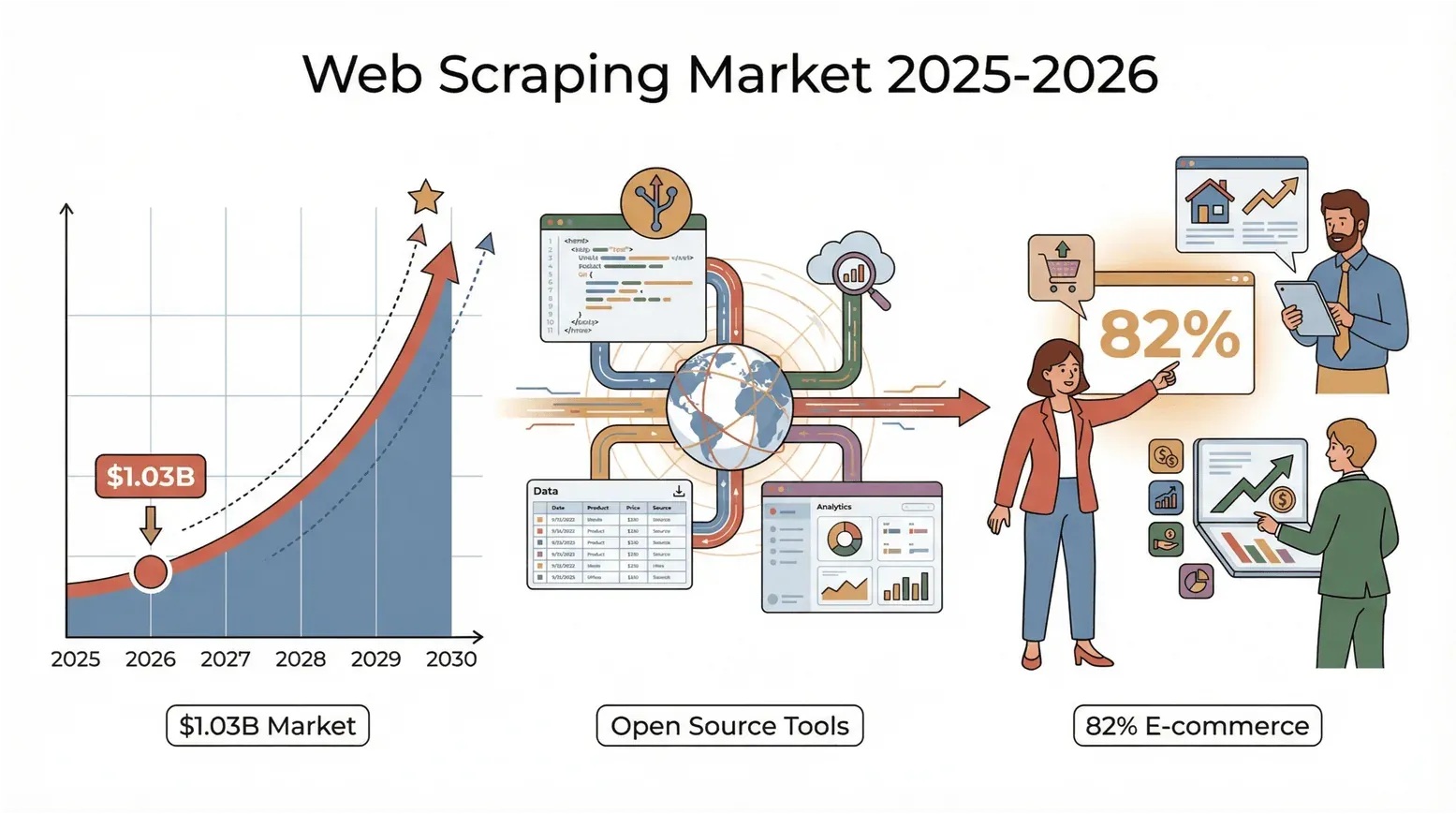
Das Web quillt über vor Daten, und 2026 ist der Wettlauf, dieses Chaos in Erkenntnisse zu übersetzen, härter denn je. Ob du im Vertrieb, im E-Commerce oder in der Immobilienbranche arbeitest oder schlicht ein Datenfanatiker wie ich bist: Die alte Copy-and-paste-Routine reicht längst nicht mehr. Eine erstaunliche Zahl dazu: Der globale Web-Scraping-Markt erreichte laut Mordor Intelligence 1,03 Milliarden US-Dollar im Jahr 2025 (zitiert im 2026 State of Web Scraping Report von PromptCloud) und dürfte sich bis 2030 ungefähr verdoppeln.
Und das trifft nicht nur die Tech-Giganten – 82 % der E-Commerce-Unternehmen und mehr als ein Drittel der Investmentfirmen durchforsten das Web nach Leads, Preisen und Marktforschung (Browsercat). Klartext: Wer kein Web-Scraping-Tool nutzt, lässt vermutlich Geld – und Erkenntnisse – liegen.
Die gute Nachricht: Open-Source-Web-Scraping-Tools sind heute leistungsfähiger, zugänglicher und stärker von der Community getragen als je zuvor. Ob Python-Profi, JavaScript-Fan oder Business-User, der unkompliziert an Daten will – für dich ist das Passende dabei. Ich arbeite seit Jahren in SaaS und Automatisierung und habe diese Entwicklung aus nächster Nähe verfolgt. Es folgen die 5 besten Open-Source-Web-Scraping-Tools, die du 2026 ausprobieren solltest, samt Tipps, wie du das richtige für dich findest.
Warum Open-Source-Web-Scraping-Tools wählen?
Was ist Data Scraping und wie macht man es 2026? Get Started Free
Open-Source-Web-Scraping-Tools sind die Allzweckwerkzeuge der Datenwelt: kosteneffizient (keine Lizenzgebühren), flexibel (du passt alles an) und transparent (du siehst genau, wie sie arbeiten). Das eigentliche Geheimnis? Die Community. Open-Source-Tools tragen Tausende Entwicklerinnen, Entwickler und Nutzende, die Plugins, Anleitungen und Lösungen teilen – du stehst nie allein da (Oreate AI).
Gegenüber kommerziellen Tools behältst du bei Open Source das Steuer in der Hand. Du hängst nicht an der Roadmap oder Preisgestaltung eines Anbieters und ziehst deine Scraper nach, sobald sich Websites verändern. Hinzu kommt: Viele kommerzielle Scraping-Dienste bauen selbst auf genau diesen Open-Source-Engines auf – warum also nicht gleich an der Quelle ansetzen?
Wie wir die besten Open-Source-Web-Scraping-Tools ausgewählt haben
Bei der riesigen Auswahl habe ich mich auf einige zentrale Kriterien konzentriert:
- Benutzerfreundlichkeit: Kommen auch Nicht-Programmierer schnell zum Ziel? Gibt es visuelle oder KI-gestützte Optionen?
- Skalierbarkeit: Stemmt das Tool große Projekte oder nur Einzelaufgaben?
- Sprach- und Plattformunterstützung: Python, JavaScript, browserbasiert, Desktop – für jeden Stack etwas dabei.
- Community und Wartung: Wird das Tool aktiv gepflegt? Gibt es Foren, Dokus und Plugins?
- Besondere Funktionen: KI-Felderkennung, Unterseiten-Scraping, Planung, Cloud-Unterstützung und mehr.
Auch echtes Nutzer-Feedback und typische Business-Anwendungsfälle sind eingeflossen – denn das beste Tool ist das, das dein Problem tatsächlich löst.
Die 5 besten Open-Source-Web-Scraping-Tools zum Ausprobieren
Jetzt zum spannenden Teil. Hier meine handverlesene Liste – von KI-gestützter Einfachheit bis zu echten Entwickler-Kraftpaketen.
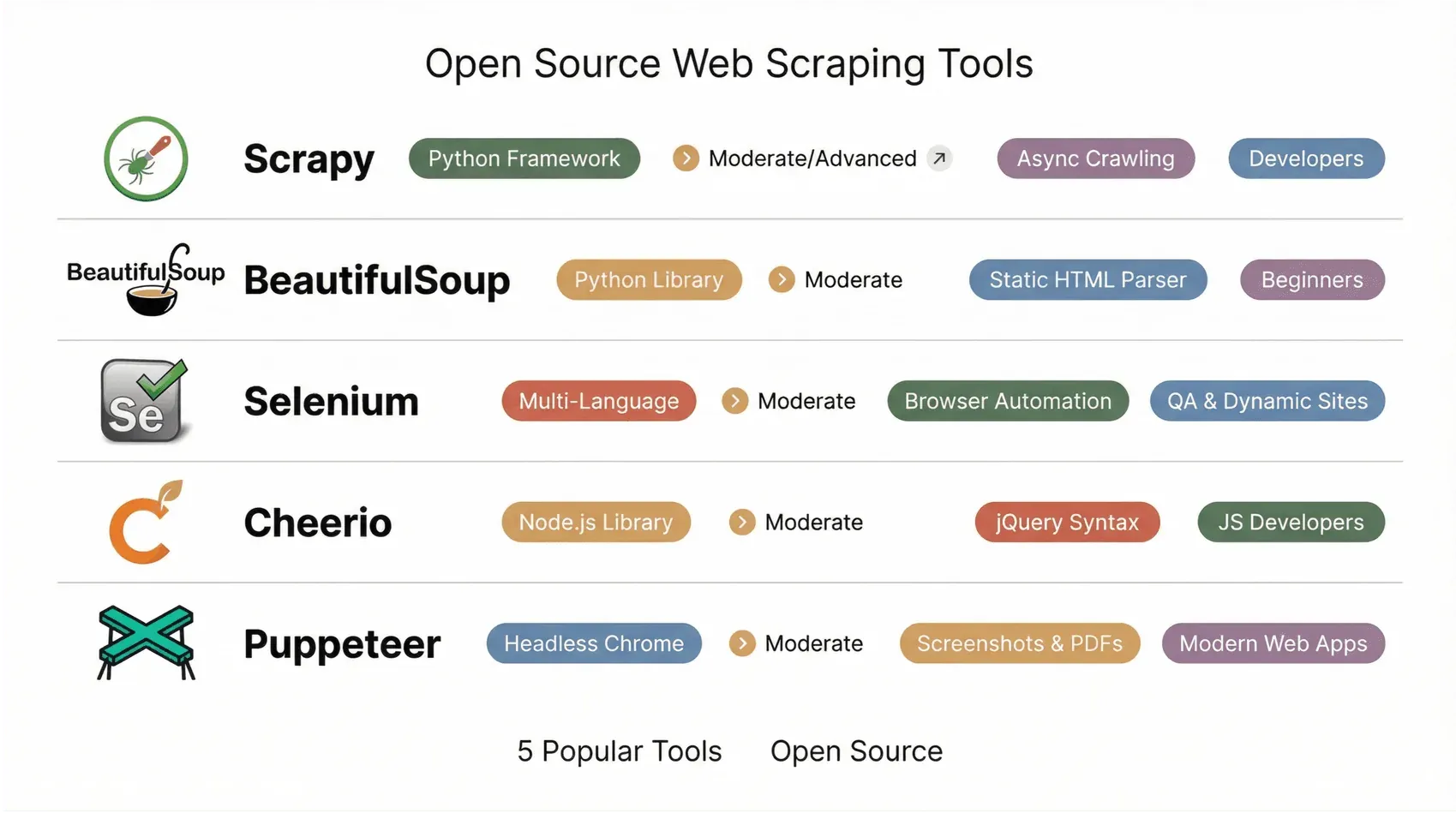
1. Scrapy
Scrapy ist der Traum jedes Python-Entwicklers – ein erprobtes Framework für skalierbare, anpassbare Crawler und Datenpipelines. Du definierst „Spiders“ in Python, Scrapy übernimmt Warteschlangen, Drosselung und den Export nach JSON, CSV oder XML. Mit Release 2.14 (Okt. 2025) und Patch 2.14.1 (Jan. 2026) wurde ein großer Teil der internen Twisted-Deferred-Logik als native asyncio-Komponenten neu geschrieben; hinzu kam ein neuer AsyncCrawlerProcess-Einstiegspunkt, der sich sauber ins moderne Python-Async-Ökosystem einfügt. Der asyncio-Reactor ist nun Standard für neu angelegte Projekte. Beachte: Scrapy 2.14+ setzt Python 3.10 oder neuer voraus.
Das Plugin-Ökosystem ist riesig, mit Middleware für Proxys, Cookies und sogar Headless-Browser-Anbindung für dynamische Websites. Zu Scrapy greifen die meisten Teams, wenn ganze E-Commerce-Kataloge gecrawlt oder Nachrichtenquellen in großem Stil zusammengeführt werden sollen. Für Nicht-Programmierer ist die Lernkurve steil, aber wer Leistung und Flexibilität sucht, wird fündig (Octoparse).
2. Beautiful Soup
Beautiful Soup ist die klassische Python-Bibliothek fürs schnelle, unkomplizierte HTML-Parsing. Anfänger wie Profis schätzen sie wegen der niedrigen Einstiegshürde und des fehlertoleranten Parsers (selbst mit chaotischem HTML kommt sie zurecht). Du holst eine Seite ab (meist mit requests), lädst sie in Beautiful Soup und findest und liest Elemente über einfache Methoden aus.
Ideal für kleine Projekte, Prototypen und den Einsatz zu Lernzwecken. Der Haken? Beautiful Soup führt kein JavaScript aus und arbeitet daher nur mit statischem HTML. Für dynamische Websites kombinierst du sie mit etwas wie Selenium oder requests_html (ProsperaSoft).
3. Selenium
Selenium ist das Urgestein unter den Browser-Automatisierungstools. Ursprünglich für Tests gebaut, ist es heute ein Favorit fürs Scraping dynamischer, JavaScript-lastiger Websites. Selenium startet einen echten Browser (Chrome, Firefox usw.) und ahmt Benutzeraktionen nach – Klicks, Scrollen, Logins. Was ein Mensch sehen kann, kann Selenium scrapen.
Es unterstützt mehrere Sprachen (Python, Java, JS, C#) und glänzt hinter Logins oder bei interaktiven Abläufen. Selenium 4 bindet zudem zunehmend WebDriver BiDi ein, ein bidirektionales Protokoll, über das dein Skript Browser-Ereignisse abonnieren (Netzwerkanfragen, Konsolenlogs, DOM-Änderungen) und Netzwerkaufrufe abfangen kann – Funktionen, wegen denen früher Puppeteer oder Playwright die leichtere Wahl waren. Die Releases 4.40 (Januar 2026) und 4.41 (Februar 2026) bauten die BiDi-Unterstützung für Python-, Java-, .NET- und Ruby-Bindings aus. Die Nachteile bleiben: Selenium ist langsamer und schwerfälliger als reine HTTP-Scraper, und die Driver-Verwaltung ist mühsam. Aber für knifflige Websites – und Teams, die ihre Testautomatisierung ohnehin auf Selenium standardisiert haben – ist es 2026 eine ernstzunehmende Option (ScrapeHero).
4. Cheerio
Cheerio ist das jQuery der Node.js-Welt. Damit parst du HTML serverseitig mit einer vertrauten, jQuery-ähnlichen Syntax. Es ist blitzschnell und wie gemacht für statische Seiten – HTML abrufen (mit Axios oder Fetch), in Cheerio laden und mit Selektoren das Gewünschte herausziehen.
Cheerio führt kein JavaScript aus und passt daher am besten zu statischen Inhalten. Mit anderen Node.js-Tools lässt es sich aber hervorragend kombinieren und ist bei Entwicklerinnen und Entwicklern beliebt, die alles in JavaScript halten wollen (Cheerio Docs).
5. Puppeteer
Puppeteer ist eine Node.js-Bibliothek zur Steuerung von Chrome oder Chromium im Headless-Modus. Sie ist eine beliebte Wahl fürs Scraping moderner Web-Apps und Single-Page-Applications, die echtes Browser-Rendering brauchen: Screenshots, PDF-Erstellung, Abfangen von Netzwerkanfragen – alles über eine saubere async/await-API. Das Chrome-Team bei Google pflegt Puppeteer weiter und hält es mit jeder Chrome-Version und jedem DevTools-Protocol-Update im Gleichschritt.
Ein Punkt, der 2026 zählt: Puppeteers Releases drehen sich inzwischen eher um Chrome-Kompatibilität und Abhängigkeits-Updates als um neue Funktionen, und das ursprüngliche Team hinter den ambitioniertesten Puppeteer-Features hat bei Microsoft Playwright entwickelt. Wer bereits auf Puppeteer setzt und nur Chrome-Automatisierung braucht, bleibt gut bedient. Wer neu startet und plattformübergreifende Browser-Unterstützung, einen integrierten Test-Runner, Auto-Waiting-Locators und einen Trace Viewer will, dem empfehlen die meisten Teams 2026 zuerst Playwright (Firecrawl — Playwright vs Puppeteer, Autonoma — Playwright vs Puppeteer 2026).
Thunderbit KI-Web-Scraper kostenlos ausprobieren
Schnelle Vergleichstabelle: Die besten Open-Source-Web-Scraping-Tools
| Tool | Einfache Bedienung | Plattform/Sprache | Dynamische Inhalte | Am besten geeignet für | Besondere Stärken |
|---|---|---|---|---|---|
| Scrapy | Mittel/Fortgeschritten (Code) | Python-Framework | Teilweise | Entwickler, Data Scientists | Asynchrones Crawling, Plugins, große Community |
| BeautifulSoup | Mittel (einfacher Code) | Python-Bibliothek | Nein | Anfänger, schnelles Parsen | Fehlertoleranter Parser, stark für statisches HTML |
| Selenium | Mittel (Scripting) | Mehrsprachig | Ja | QA, dynamische Websites scrapen | Echte Browser-Automatisierung, funktioniert mit Logins und Nutzerereignissen |
| Cheerio | Mittel (JS-Code) | Node.js-Bibliothek | Nein | JS-Entwickler, statische Seiten | jQuery-Syntax, schnelles HTML-Parsing |
| Puppeteer | Mittel (JS-Code) | Node.js (Headless Chrome) | Ja | Entwickler, moderne Web-Apps | Screenshots, PDFs, SPA-Scraping, async/await-API |
So wählst du das richtige Open-Source-Web-Scraping-Tool für deine Anforderungen
So scrapest du mit KI jede beliebige Website Get Started Free
Hier mein Spickzettel für die richtige Wahl:
- Technische Kenntnisse: Keine Programmiererfahrung? Starte mit Thunderbit, Octoparse, ParseHub oder WebHarvy. Entwickler? Scrapy, Cheerio, Puppeteer oder Apify.
- Projektumfang: Einmalige oder kleine Aufgaben? Beautiful Soup, Cheerio, WebHarvy. Groß angelegt oder dauerhaft? Scrapy, Apify, Thunderbit (mit Zeitplanung).
- Datentyp: Statisches HTML? Nimm Cheerio, Beautiful Soup oder WebHarvy. Dynamisch/JS-lastig? Puppeteer, Selenium, Thunderbit, Octoparse.
- Integration: Soll der Export nach Sheets, Notion oder in Datenbanken gehen? Thunderbit und Octoparse machen das leicht. Brauchst du APIs oder eigene Pipelines? Scrapy und Apify sind deine Freunde.
- Community & Support: Achte auf aktive Foren, frische Updates und reichlich Anleitungen. Scrapy, Cheerio und Selenium haben riesige Communities; Thunderbit und Octoparse wachsen mit ihren Nutzerbasen und vielen Guides.
Teste ein paar Tools an einem kleinen Projekt – und schau, welches zu deinem Workflow und deinem Komfortlevel passt. Und scheu dich nicht, Ansätze zu mischen: Manchmal ist der schnellste Weg ein flotter Scrape mit einem visuellen Tool, gefolgt von einem tieferen Crawl mit einem codebasierten Framework.
Der Wert von Community und laufendem Support beim Open-Source-Scraping
Einer der größten Vorteile von Open Source? Die Community. Aktive Foren, GitHub-Repositories und Stack-Overflow-Tags bedeuten: Du bist nie auf dich allein gestellt. Stößt du auf ein Problem, hat es mit hoher Wahrscheinlichkeit schon jemand gelöst – oder hilft dir dabei. Community-getriebene Tools bekommen häufig Updates und neue Funktionen, und du findest reichlich Tutorials, Plugins und Best Practices (Oreate AI).
Bei visuellen Tools wie Thunderbit und Octoparse sind Nutzerforen und das Teilen von Vorlagen daher eine Fundgrube. Bei Entwickler-Tools spielen GitHub-Issues und Discord-/Slack-Gruppen ihre Stärken aus. Entscheidest du dich für ein Open-Source-Tool, wirst du Teil eines weltweiten Netzwerks von Problemlösern – und das ist unbezahlbar.
Thunderbit:Eine einfachere No-Code-Web-Scraping-Lösung für alle
Sicher, Open Source ist großartig – aber manchmal willst du eben nicht erst einen Scraper bauen, optimieren und dauernd pflegen, nur um an brauchbare Daten zu kommen. Und nicht jedes Scraping-Problem löst sich mit Open-Source-Code. Genau hier setzt Thunderbit an. Wer bis hierhin gelesen und gedacht hat: „Diese Tools sind stark, aber ich will einfach die Daten, ohne Scraper zu bauen oder zu warten“, für den ist Thunderbit der naheliegende nächste Schritt.
Thunderbit ist eine KI-gestützte Chrome-Erweiterung für Business-User, denen Ergebnisse mehr bedeuten als Infrastruktur. Statt Selektoren oder Skripte zu schreiben, klickst du zuerst auf AI Suggest Fields. Die KI versteht die Seitenstruktur, schlägt Spalten vor, und mit einem zweiten Klick scrapest du. Paginierung, Unterseiten und Listen-Detail-Workflows nimmt es dir ab.
Eine der größten Stärken von Thunderbit ist die Brücke zwischen menschlicher Absicht und strukturierten Daten. Du beschreibst in normaler Sprache, was du brauchst (etwa „Produktnamen, Preise und Bewertungen sammeln“), und Thunderbit macht daraus eine saubere Tabelle. Das Unterseiten-Scraping holt reichhaltigere Daten automatisch von den Detailseiten. Exporte nach Excel, Google Sheets, Notion und Airtable sind direkt eingebaut, deine Daten sind also sofort einsatzbereit.
Thunderbit ist besonders beliebt bei Teams aus Vertrieb, Marketing, E-Commerce und Immobilien, die verlässliche Daten brauchen, aber keine Open-Source-Pipelines pflegen wollen. Es unterstützt Dutzende Sprachen, läuft gut auf dynamischen Websites und bringt ein großzügiges Gratispaket für den Einstieg mit. Es ist zwar nicht Open Source, ergänzt diese Tools aber hervorragend – als schnellster Weg, Ideen zu validieren oder wiederkehrende Business-Scrapes ohne technischen Overhead abzuwickeln.
Fazit: Webdaten mit den besten Open-Source-Tools erschließen
Web Scraping ist längst nicht mehr nur etwas für Programmierer oder Großkonzerne. Mit den heutigen Open-Source-Tools verwandelt jeder das Web in strukturierte, handlungsrelevante Daten – ob du eine Lead-Liste aufbaust, Preise beobachtest oder dein nächstes KI-Projekt fütterst. Entscheidend ist, das Tool auf den eigenen Bedarf zuzuschneiden: KI-gestützte und visuelle Tools für Tempo und Einfachheit, Code-Frameworks für Leistung und Skalierung.
Als Nächstes: Such dir ein Tool aus dieser Liste, probier es an einer echten Aufgabe aus und sieh, wie viel Zeit und Aufwand du sparst. Und wenn du einen schnellen Erfolg willst, lade Thunderbit herunter und erlebe, wie leicht Web Scraping sein kann. Die Daten liegen bereit, du musst sie nur noch einsammeln.
Mehr tiefgehende Analysen und Anleitungen findest du im Thunderbit-Blog.
Thunderbit KI-Web-Scraper kostenlos ausprobieren Get Started Free
FAQs
1. Was ist der Hauptvorteil von Open-Source-Web-Scraping-Tools gegenüber kommerziellen Lösungen?
Open-Source-Tools sind kosteneffizient, flexibel und werden von aktiven Communities getragen. Du passt sie an, vermeidest Vendor Lock-in und profitierst von geteiltem Wissen sowie häufigen Updates.
2. Welches Open-Source-Tool ist am besten für nicht-technische Business-User geeignet?
Thunderbit, Octoparse, ParseHub und WebHarvy eignen sich allesamt hervorragend für Nicht-Programmierer. Thunderbit sticht mit seinem KI-gestützten Zwei-Klick-Workflow und direkten Exportmöglichkeiten besonders heraus.
3. Können Open-Source-Tools dynamische, stark JavaScript-lastige Websites verarbeiten?
Ja! Tools wie Thunderbit, Selenium, Puppeteer, Octoparse und ParseHub scrapen dynamische Inhalte, indem sie Seiten in einem echten oder Headless-Browser rendern.
4. Woran erkenne ich, ob ein Tool aktiv gepflegt und unterstützt wird?
Schau auf GitHub nach aktuellen Commits, offenen Issues und Aktivität der Mitwirkenden. Achte auf aktive Foren, frische Blogbeiträge und reichlich von Nutzern beigesteuerte Plugins oder Vorlagen.
5. Was ist der beste Weg, mit Web Scraping zu starten, wenn ich Anfänger bin?
Starte mit einem visuellen oder KI-gestützten Tool wie Thunderbit oder Octoparse. Versuch, ein kleines Datenset zu scrapen, exportier es nach Excel oder Sheets und experimentiere. Mit wachsender Sicherheit kannst du codebasierte Tools für fortgeschrittene Projekte erkunden.
Du willst Thunderbit in Aktion sehen? Lade die Chrome-Erweiterung herunter und schließ dich über 30.000 Nutzenden an, die das Web ohne Code in Daten verwandeln.
Mehr erfahren




