Zwischen 2 und 3 Millionen Nachrichtenartikel werden jeden einzelnen Tag online veröffentlicht. Diese Daten strukturiert zu erfassen — Überschriften, Daten, Quellen, vollständiger Artikeltext — ist ungefähr so angenehm wie Möbel ohne Aufbauanleitung zusammenzubauen.
Ich habe bei jahrelang Automatisierungstools entwickelt und getestet, und die News-Scraping-Landschaft im Jahr 2026 ist eine merkwürdige Mischung aus großem Potenzial und echtem Frust. Google hat seine offizielle News API schon 2011 eingestellt, Nachrichtenseiten setzen immer aggressivere Anti-Bot-Maßnahmen ein (Cloudflare, CAPTCHAs, JavaScript-Rendering-Sperren), und Layouts ändern sich so oft, dass ein Scraper, der am Montag noch funktioniert, bis Mittwoch schon kaputt sein kann. Gleichzeitig brauchen Teams aus PR, Vertrieb, Forschung und KI-Engineering strukturierte Nachrichtendaten dringender denn je.
Also habe ich 15 News-Scraping-Tools in den Kategorien APIs, No-Code-Plattformen und Open-Source-Bibliotheken getestet. Das Ziel: ein normalisierter Vergleich zu Preis, Wartungsaufwand, sauberer Textextraktion und echter Praxistauglichkeit, den kein anderer Leitfaden bietet.
Was hebt die besten News-Scraper im Jahr 2026 ab?
Die meisten Artikel über die „besten News-Scraper“ lassen die Bewertungskriterien komplett weg — deshalb hier, woran ich tatsächlich getestet habe. Viele dieser Beiträge listen einfach Funktionen auf und machen dann weiter. Aber nach Jahren beim Aufbau von Scraping-Infrastruktur habe ich gelernt, dass die Kriterien, die für Geschäftsanwender zählen, sehr konkret — und oft übersehen — sind.
Das ist der Bewertungsrahmen, den ich verwendet habe:
| Kriterium | Worauf ich geachtet habe |
|---|---|
| Ansatz | API, Browser-Tool ohne Code oder Open-Source-Bibliothek |
| Anti-Bot-Handling | Proxy-Rotation, CAPTCHA-Lösung, Unterstützung für Headless-Browser |
| Saubere Textextraktion | Kann das Tool Anzeigen, Seitenleisten und Navigationsleisten entfernen und nur den Artikeltext zurückgeben? |
| Metadaten-Ausgabe | Autor, Datum, Bilder, Quell-URL, Kategorie |
| Exportformate | CSV, JSON, Google Sheets, Airtable, Notion usw. |
| Paginierung / Bulk-Support | Kann es mehrseitige Ergebnisse und Batch-URLs verarbeiten? |
| Wartungsaufwand | Bricht es, wenn sich Layouts ändern? KI-adaptiv vs. selektorbasiert |
| Normalisierte Kosten pro 1.000 Ergebnisse | Preise auf vergleichbarer Basis (inklusive Free Tier) |
| Bestes Einsatzszenario | PR-Monitoring, Lead-Generierung, Forschung, LLM-Pipeline usw. |
Zwei Kriterien brauchen etwas mehr Kontext. Normalisierte Kosten pro 1.000 Ergebnisse sind wichtig, weil jeder Anbieter Preise anders angibt — pro Credit, pro Anfrage, pro Suche, pro Zeile. Ohne Normierung vergleichst du Äpfel mit U-Booten. Und Wartungsaufwand ist der größte Schmerzpunkt, von dem ich von Nutzern höre. Forum um Forum ist die Beschwerde dieselbe: „Newsseiten lieben es, meine Crawler jeden Dienstag kaputt zu machen.“ Ich habe jedes Tool auf einer dreistufigen Skala bewertet:
- 🟢 Geringer Wartungsaufwand: KI-adaptiv oder vollständig verwaltete API — Layoutänderungen brechen deinen Workflow nicht
- 🟡 Mittlerer Wartungsaufwand: Anti-Bot wird abgefangen, aber deine Extraktionslogik kann trotzdem brechen
- 🔴 Hoher Wartungsaufwand: Selektorbasiert — wenn sich die Seite ändert, musst du manuell nachbessern
Welcher News-Scraper passt zu deiner Rolle? Eine Entscheidungs-Matrix
Scraper-Empfehlungen behandeln fast immer alle Leser gleich, und genau das ist das Kernproblem. Eine PR-Managerin, die Markenerwähnungen verfolgt, hat völlig andere Anforderungen als ein Python-Entwickler, der eine RAG-Pipeline baut. Deshalb hier vor der vollständigen Liste ein schneller Rahmen:
| Anwendungsfall | Bester Ansatz | Empfohlene Tools |
|---|---|---|
| Tägliches News-Briefing (nicht-technisch) | No-Code-Browser-Tool oder RSS | Thunderbit, Octoparse, ParseHub |
| PR / Medienbeobachtung in großem Umfang | News API mit Benachrichtigungen | Newscatcher, Webz.io, Newsdata.io |
| Lead-Extraktion aus News | KI-Scraper mit Unterseiten-Anreicherung | Thunderbit (Unterseiten-Scraping + E-Mail-/Telefon-Extraktion), Apify |
| Akademische Forschung / Korpusaufbau | Open-Source-Bibliothek | Newspaper4k |
| LLM-Pipeline / RAG-Ingestion | Distill-to-Markdown-API | Thunderbit API, ScraperAPI |
| Wettbewerbsanalyse / Preisbeobachtung | Geplantes Scraping | Thunderbit (Geplanter Scraper), Bright Data |
Weißt du schon, in welche Kategorie du fällst? Dann spring vor. Sonst hilft dir die vollständige Übersicht unten weiter.
Die 15 besten News-Scraper auf einen Blick
Hier ist der Gesamtvergleich — die Preise sind auf Kosten pro 1.000 Ergebnisse im günstigsten bezahlten Tarif normalisiert, der Wartungsaufwand ist auf der Dreistufen-Skala bewertet.
| Tool | Typ | Free Tier | Kosten pro 1.000 Ergebnisse (geschätzt) | Anti-Bot | Sauberer Text | Wartung | Bestes Einsatzszenario |
|---|---|---|---|---|---|---|---|
| Thunderbit | No-Code-KI (Chrome-Erweiterung + Cloud) | 6 Seiten/Monat gratis | ca. $3–$15 | Stark (Browser- + Cloud-Modus) | Ja (KI + Unterseiten) | 🟢 Niedrig | Geschäftsteams, Lead-Generierung, tägliches Monitoring |
| SerpApi | API | 250 Suchen/Monat | ca. $15 | Stark (SERP-spezifisch) | Nein (nur Snippets) | 🟢 Niedrig | Google-News-SERP-Dashboards |
| ScraperAPI | API | 1.000 Credits/Monat | ca. $1–$5 | Stark (Proxy + JS-Rendering) | Nein (rohes HTML) | 🟡 Mittel | Entwickler, die Anti-Bot-Infrastruktur wollen |
| Newsdata.io | News API | 200 Anfragen/Tag | ca. $5–$15 | N/A (verwaltete API) | Teilweise (Premium) | 🟢 Niedrig | Strukturierte News-Metadaten |
| Apify | Cloud-Plattform | 5 $ Gratis-Guthaben | ca. $1–$6 | Stark | Je nach Actor unterschiedlich | 🟡 Mittel | Individuelle Cloud-Workflows |
| Oxylabs | Enterprise-API | 2.000 Ergebnisse Testzugang | ca. $0,50–$2 | Sehr stark | Teilweise | 🟢 Niedrig | SERP- und Web-Daten im Enterprise-Scale |
| ScrapingBee | API | Testguthaben | ca. $2–$5 | Stark (Headless Chrome) | Teilweise (grundlegend) | 🟡 Mittel | Newsseiten mit viel JavaScript |
| Scrapingdog | SERP API | 1.000 Credits | ca. $0,10–$0,50 | Stark | Nein (SERP-Daten) | 🟢 Niedrig | Budget-SERP-Monitoring |
| Bright Data | Enterprise-Plattform | 1.000 Anfragen Testzugang | ca. $0,30–$0,50 | Sehr stark | Ja (News Scraper) | 🟢 Niedrig | Newsdaten im Enterprise-Scale |
| Octoparse | No-Code Desktop + Cloud | Eingeschränkter Gratisplan | ca. $5–$10 (amortisiert) | Stark | Ja (mit Vorlagen) | 🟡 Mittel | Visuelles No-Code-Scraping |
| ParseHub | No-Code Desktop | 5 Projekte, 200 Seiten/Lauf | ca. $5–$12 (amortisiert) | Mittel | Ja (mit Konfiguration) | 🔴 Hoch | Anfänger, kleine Projekte |
| Newscatcher | News API | Kein öffentliches Free Tier | Individuell (Enterprise) | N/A (verwaltete API) | Ja (NLP-angereichert) | 🟢 Niedrig | PR-/Medienbeobachtung |
| Webz.io | News-Datenplattform | Kein Self-Service-Free-Tier | Individuell (Enterprise) | N/A (verwalteter Feed) | Ja (Volltext + Metadaten) | 🟢 Niedrig | Historische Archive, LLM-Training |
| Newspaper4k | Open-Source Python | Gratis | $0 (+ Serverkosten) | Keine | Ja (spezialisiert) | 🔴 Hoch | Entwickler, Korpusaufbau |
| HasData | SERP API | Kostenlose Credits | ca. $0,25–$0,60 | Stark | Nein (SERP-Daten) | 🟢 Niedrig | Günstiger News-SERP-Endpunkt |
Die wichtigsten Erkenntnisse: Scrapingdog und HasData sind die günstigsten API-Optionen pro Anfrage. Thunderbit und Newspaper4k führen bei sauberem Artikeltext — allerdings auf sehr unterschiedliche Weise. Bright Data und Oxylabs dominieren das Enterprise-Segment. Wartungsstress? Bleib bei den 🟢-Tools.
1. Thunderbit — Bester No-Code-KI-News-Scraper für Geschäftsteams
 ist das Tool, das mein Team und ich speziell gebaut haben, um das Problem zu lösen: „Ich brauche Daten von dieser Website, und ich will keinen Code schreiben oder Selektoren pflegen.“ Beim News-Scraping ist der Ablauf so einfach wie nur möglich: Eine News-Seite öffnen, auf AI Suggest Fields klicken, die von Thunderbit vorgeschlagenen Spalten prüfen (Überschrift, Datum, Quelle, URL, Zusammenfassung — es liest die Seitenstruktur und erkennt, was vorhanden ist) und dann auf Scrape klicken.
ist das Tool, das mein Team und ich speziell gebaut haben, um das Problem zu lösen: „Ich brauche Daten von dieser Website, und ich will keinen Code schreiben oder Selektoren pflegen.“ Beim News-Scraping ist der Ablauf so einfach wie nur möglich: Eine News-Seite öffnen, auf AI Suggest Fields klicken, die von Thunderbit vorgeschlagenen Spalten prüfen (Überschrift, Datum, Quelle, URL, Zusammenfassung — es liest die Seitenstruktur und erkennt, was vorhanden ist) und dann auf Scrape klicken.
Ein paar Funktionen zusammen machen Thunderbit besonders stark für News:
- KI-adaptive Extraktion: Keine CSS-Selektoren, die man schreiben oder pflegen muss. Die KI liest jedes Mal das aktuelle Seitenlayout neu — wenn eine News-Seite also ein Redesign bekommt (und das tun sie alle), bricht dein Scraper nicht.
- Unterseiten-Scraping: Nachdem du eine Liste von Artikellinks gescrapt hast, kannst du auf Scrape Subpages klicken, um jeden Artikel aufzurufen und den vollständigen Fließtext, Autor, Veröffentlichungsdatum und Bilder zu extrahieren. So bekommst du sauberen Artikelinhalt, nicht nur Überschriften.
- Field AI Prompt: Du kannst die KI spaltenweise anweisen — zum Beispiel: „Extrahiere nur den Haupttext des Artikels, schließe Navigation und Anzeigen aus“ oder „Klassifiziere die Stimmung dieses Artikels als positiv, neutral oder negativ.“ Das ist unter No-Code-Tools einzigartig und für die News-Analyse enorm nützlich.
- Browser Scraping vs. Cloud Scraping: Im Browser-Modus wird deine eigene Sitzung genutzt (hilfreich für Seiten, die Cloud-IPs blockieren), während der Cloud-Modus bis zu 50 Seiten gleichzeitig für mehr Geschwindigkeit verarbeiten kann.
- Geplanter Scraper: Tägliche oder wöchentliche Scraping-Läufe mit natürlichsprachlichen Zeitintervallen einrichten — ideal für fortlaufende News-Beobachtung.
- Export überallhin: Excel, CSV, Google Sheets, Airtable, Notion — alles unterstützt.
Preisgestaltung und Einschränkungen
Thunderbit bietet ein Free Tier (6 Seiten/Monat) und einen 10-Seiten-Test an. Bezahlte Tarife starten bei rund für 500 Credits (1 Credit = 1 Zeile). Für den Browser-Modus ist die Chrome-Erweiterung erforderlich. KI-Funktionen verbrauchen Credits, daher braucht intensive Nutzung über Tausende Artikel hinweg einen bezahlten Plan — für die meisten Geschäftsteams, die täglich überwachen oder wöchentlich recherchieren, sind die Kosten aber überschaubar.
Wartung: 🟢 Niedrig. Die KI liest die Seite jedes Mal frisch ein.
Am besten für: Nicht-technische Vertriebs-, PR- und Ops-Teams, die tägliche News-Daten wollen, ohne Scraper bauen oder pflegen zu müssen.
Wenn du tiefer verstehen möchtest, wie Thunderbit umsetzt, schau dir unseren Leitfaden an.
2. SerpApi — Am besten für strukturierte Google-News-SERP-Daten
 ist eine auf SERPs spezialisierte API, die strukturierte JSON-Daten aus Google-News-Ergebnissen zurückgibt. Wenn dein Anwendungsfall lautet: „Gib mir die Top-Google-News-Ergebnisse zu einem Keyword, strukturiert und dashboard-tauglich“, dann passt SerpApi sehr gut. Es liefert Überschrift, Quelle, Datum, Snippet und Thumbnail — aber keinen vollständigen Artikeltext. Dafür brauchst du einen separaten Schritt (oder ein anderes Tool), um den eigentlichen Artikeltext zu holen.
ist eine auf SERPs spezialisierte API, die strukturierte JSON-Daten aus Google-News-Ergebnissen zurückgibt. Wenn dein Anwendungsfall lautet: „Gib mir die Top-Google-News-Ergebnisse zu einem Keyword, strukturiert und dashboard-tauglich“, dann passt SerpApi sehr gut. Es liefert Überschrift, Quelle, Datum, Snippet und Thumbnail — aber keinen vollständigen Artikeltext. Dafür brauchst du einen separaten Schritt (oder ein anderes Tool), um den eigentlichen Artikeltext zu holen.
Wichtige Funktionen:
- Strukturierte JSON-Ausgabe aus Google-News-SERPs
- Anti-Detection wird auf ihrer Seite abgefangen (SERP-spezifisch)
- Unterstützt mehrere Google-News-Lokalisierungen und Sprachen
Preisgestaltung: Free Tier mit 250 Suchen/Monat. Bezahlte Tarife starten bei 75 $/Monat für 5.000 Suchen — also rund 15 $ pro 1.000 Ergebnisse.
Einschränkung: Liefert nur Snippets. Wenn du vollständigen Artikeltext brauchst, ist SerpApi Schritt eins, nicht die komplette Pipeline.
Wartung: 🟢 Niedrig (verwaltete API, Google-Änderungen werden von ihnen behandelt).
Am besten für: Entwickler, die News-Monitoring-Dashboards bauen oder SERP-Daten in Analysetools einspeisen.
3. ScraperAPI — Beste günstige Scraping-API mit Proxy-Rotation
 ist eine allgemeine Scraping-API, nicht auf News spezialisiert, aber effektiv für das Abrufen von News-Seiten. Ihr Kernvorteil ist Proxy-Rotation, JavaScript-Rendering und CAPTCHA-Handling — also die Anti-Bot-Infrastruktur, die du sonst selbst bauen müsstest.
ist eine allgemeine Scraping-API, nicht auf News spezialisiert, aber effektiv für das Abrufen von News-Seiten. Ihr Kernvorteil ist Proxy-Rotation, JavaScript-Rendering und CAPTCHA-Handling — also die Anti-Bot-Infrastruktur, die du sonst selbst bauen müsstest.
Wichtige Funktionen:
- Proxy-Rotation mit Residential- und Datacenter-IPs
- JavaScript-Rendering für dynamische News-Seiten
- CAPTCHA-Handling
- Liefert rohes HTML — den Artikelinhalt musst du selbst parsen
Preisgestaltung: Free Tier mit 1.000 Credits/Monat (plus Testguthaben). JavaScript-Rendering kostet pro Anfrage mehr Credits. Bezahlte Tarife starten bei 49 $/Monat. Die normalisierten Kosten liegen je nach JS-Nutzung ungefähr bei 1–5 $ pro 1.000 Anfragen.
Einschränkung: Keine integrierte Artikelanalyse. Du bekommst HTML, keinen sauberen Text. Kombiniere es für die Artikelauslese mit Newspaper4k oder einem eigenen Parser.
Wartung: 🟡 Mittel (Anti-Bot wird übernommen, aber die Extraktionslogik musst du selbst pflegen).
Am besten für: Entwickler, die Anti-Bot-Infrastruktur wollen, ohne ihr eigenes Proxy-Netzwerk aufzubauen.
4. Newsdata.io — Beste dedizierte News API für strukturierte Metadaten
 ist eine speziell entwickelte News-API mit . Sie liefert strukturierte Daten — Titel, Beschreibung, Quelle, Datum, Kategorien, Stimmung — und auf Premium-Tarifen auch vollständigen Artikelinhalt.
ist eine speziell entwickelte News-API mit . Sie liefert strukturierte Daten — Titel, Beschreibung, Quelle, Datum, Kategorien, Stimmung — und auf Premium-Tarifen auch vollständigen Artikelinhalt.
Wichtige Funktionen:
- Abfrage nach Keyword, Kategorie, Sprache, Land
- Integrierte Stimmungsanalyse
- Historisches News-Archiv (bezahlte Tarife)
- Keine Scraping-Infrastruktur, die du verwalten musst
Preisgestaltung: Free Tier mit 200 Anfragen/Tag und eingeschränkten Feldern. Bezahlte Tarife schalten Volltext und historische Daten frei. Die Kosten pro 1.000 Ergebnisse liegen je nach Tarif in etwa bei 5–15 $.
Einschränkung: Deckt nur die eigenen indexierten Quellen ab — du kannst nicht einfach eine beliebige URL angeben und sagen: „Scrape das.“ Wenn eine Nischenpublikation nicht im Index ist, findest du sie dort nicht.
Wartung: 🟢 Niedrig (voll verwaltete News-API).
Am besten für: Teams, die strukturierte News-Metadaten brauchen und keine Scraping-Infrastruktur betreiben wollen.
5. Apify — Beste Cloud-Plattform für individuelle News-Scraping-Workflows
 ist eine actor-basierte Cloud-Plattform mit vorgefertigten Scraper für Google News, einzelne Publikationen und allgemeine Artikelextraktion. Sie liegt genau zwischen No-Code und kompletter Eigenentwicklung.
ist eine actor-basierte Cloud-Plattform mit vorgefertigten Scraper für Google News, einzelne Publikationen und allgemeine Artikelextraktion. Sie liegt genau zwischen No-Code und kompletter Eigenentwicklung.
Wichtige Funktionen:
- Vorgefertigte Actors für Google News, Artikelauslese und mehr
- Unterstützt JavaScript-Rendering und Headless-Browser-Ausführung
- Cloud-Ausführung mit Zeitplanung
- Export zu JSON, CSV, Excel, XML und mehr
Preisgestaltung: Gratisplan mit . Bezahlte Tarife bei 49 $, 499 $ und 999 $/Monat. Die Kosten pro 1.000 Ergebnisse hängen vom Actor ab — bei News-Scraping-Actors ungefähr 1–6 $.
Einschränkung: Vorgefertigte Actors werden von der Community gepflegt und können brechen, wenn sich News-Seiten ändern. Mehr Einrichtung als reine No-Code-Tools.
Wartung: 🟡 Mittel (Actors brauchen bei Seitenänderungen eventuell Updates).
Am besten für: Teams, die Cloud-Ausführung wollen und mit Marketplace-Actors zurechtkommen.
6. Oxylabs — Beste Scraping-Infrastruktur auf Enterprise-Niveau
 ist ein Enterprise-Scraping-Dienst mit einem Proxy-Pool von über 100 Millionen IPs, CAPTCHA-Lösung und Browser-Rendering. Ihre SERP Scraper API verarbeitet Google-News-Ergebnisse mit Geo-Targeting, und ihre Web Scraper API funktioniert für beliebige News-Seiten.
ist ein Enterprise-Scraping-Dienst mit einem Proxy-Pool von über 100 Millionen IPs, CAPTCHA-Lösung und Browser-Rendering. Ihre SERP Scraper API verarbeitet Google-News-Ergebnisse mit Geo-Targeting, und ihre Web Scraper API funktioniert für beliebige News-Seiten.
Wichtige Funktionen:
- Massive Proxy-Infrastruktur mit Geo-Targeting
- SERP Scraper API für Google News
- Web Scraper API für beliebige URLs
- JSON-/CSV-Ausgabe, große parallele Anfragevolumen
Preisgestaltung: Startet bei 49 $/Monat für SERP-Daten. Individuelle Enterprise-Preise für hohe Volumina. Kostenloser Test bis zu 2.000 Ergebnissen.
Einschränkung: Für kleine Teams teuer. Primär für großskalige Operationen gedacht.
Wartung: 🟢 Niedrig (voll verwaltete Enterprise-API).
Am besten für: Unternehmen, die hochvolumige, geo-targetierte News-Daten mit Enterprise-Zuverlässigkeit brauchen.
7. ScrapingBee — Am besten für News-Seiten mit viel JavaScript
 ist eine Scraping-API mit Fokus auf JavaScript-Rendering über echte Browserausführung. Wenn die News-Seite, die du brauchst, Inhalte per clientseitigem JavaScript lädt (und viele moderne Seiten tun das), kommt ScrapingBee damit gut klar.
ist eine Scraping-API mit Fokus auf JavaScript-Rendering über echte Browserausführung. Wenn die News-Seite, die du brauchst, Inhalte per clientseitigem JavaScript lädt (und viele moderne Seiten tun das), kommt ScrapingBee damit gut klar.
Wichtige Funktionen:
- Headless Chrome mit Proxy-Rotation
- CAPTCHA-Handling
- Einfache Funktion zur „Article Extraction“ für einige Seiten
- Gibt rohes HTML, JSON oder Markdown-ähnliche Ausgabe zurück
Preisgestaltung: Tarife ab . Credit-basiert, JavaScript-Rendering kostet mehr. Testguthaben verfügbar.
Einschränkung: Die Article-Extraction-Funktion ist im Vergleich zu KI-gestützten Alternativen eher grundlegend. In den meisten Workflows erhältst du vor allem HTML — Parsing bleibt also trotzdem nötig.
Wartung: 🟡 Mittel (Anti-Bot wird übernommen, aber die Extraktion muss vom Nutzer konfiguriert werden).
Am besten für: Entwickler, die JS-lastige News-Seiten scrapen und gerendertes HTML wollen, ohne Headless-Browser selbst zu verwalten.
8. Scrapingdog — Beste budgetfreundliche SERP API für News
 ist eine günstige SERP-API mit einem dedizierten Google-News-Endpunkt. Die Antwortzeiten sind schnell (im Test rund 2 Sekunden pro Anfrage), und die Preise gehören bei API-Optionen zu den wettbewerbsfähigsten in dieser Liste.
ist eine günstige SERP-API mit einem dedizierten Google-News-Endpunkt. Die Antwortzeiten sind schnell (im Test rund 2 Sekunden pro Anfrage), und die Preise gehören bei API-Optionen zu den wettbewerbsfähigsten in dieser Liste.
Wichtige Funktionen:
- Dedizierter Google-News-Endpunkt
- Strukturierte JSON-Ausgabe (Überschriften, Quelle, Datum, Snippets)
- Schnelle Antwortzeiten
Preisgestaltung: Startet bei 40 $/Monat für 400.000 Anfragen — das sind ungefähr 0,10 $ pro 1.000 Ergebnisse, also bemerkenswert günstig. Free Tier mit 1.000 Credits.
Einschränkung: Liefert nur SERP-Daten (Überschriften, Snippets), keinen vollständigen Artikelinhalt. Derselbe Kompromiss wie bei SerpApi, aber zu einem Bruchteil des Preises.
Wartung: 🟢 Niedrig (verwaltete SERP-API).
Am besten für: Preisbewusste Entwickler, die Google-News-SERP-Daten in großem Umfang brauchen.
9. Bright Data — Beste Wahl für Newsdaten im Enterprise-Scale
 ist das Schwergewicht für Unternehmen. Die Plattform umfasst ein dediziertes News-Scraper-Produkt, eine riesige Proxy-Infrastruktur, CAPTCHA-Lösung, Browser-Rendering und die Auslieferung der Daten an S3, Snowflake und mehr.
ist das Schwergewicht für Unternehmen. Die Plattform umfasst ein dediziertes News-Scraper-Produkt, eine riesige Proxy-Infrastruktur, CAPTCHA-Lösung, Browser-Rendering und die Auslieferung der Daten an S3, Snowflake und mehr.
Wichtige Funktionen:
- Dediziertes News-Scraper-Produkt
- Vorgefertigte Datensätze und Echtzeiterfassung
- Automatisierte Proxy-Verwaltung und CAPTCHA-Lösung
- Geplante Erfassung und Benachrichtigungen
- Export zu JSON, CSV, NDJSON, S3, Snowflake, GCS, Azure, SFTP
Preisgestaltung: Ab etwa im Pay-as-you-go-Modell. Enterprise-Tarife auf Anfrage verfügbar. 1.000-Anfragen-Testzugang.
Einschränkung: Komplexe Preisstruktur mit Mindestabnahmen. Vor allem für Enterprise-Budgets gedacht.
Wartung: 🟢 Niedrig (Enterprise-verwaltet, hohe Zuverlässigkeit).
Am besten für: Große Organisationen, die zuverlässige News-Datenpipelines mit hohem Volumen brauchen.
10. Octoparse — Bester visueller No-Code-Scraper für News-Seiten
 Octoparse ist eine Desktop-Anwendung mit einem visuellen Point-and-Click-Workflow-Builder. Sie hat vorgefertigte Vorlagen für gängige News-Seiten, verarbeitet Paginierung und unendliches Scrollen und bietet Cloud-Ausführung für geplante Läufe.
Octoparse ist eine Desktop-Anwendung mit einem visuellen Point-and-Click-Workflow-Builder. Sie hat vorgefertigte Vorlagen für gängige News-Seiten, verarbeitet Paginierung und unendliches Scrollen und bietet Cloud-Ausführung für geplante Läufe.
Wichtige Funktionen:
- Visueller Point-and-Click-Workflow-Builder
- Vorgefertigte Vorlagen für News-Seiten
- Cloud-Ausführung mit Zeitplanung
- IP-Rotation und automatische CAPTCHA-Lösung
- Export zu Excel, CSV, JSON, Datenbanken, Google Sheets
Preisgestaltung: Gratisplan mit 10 Aufgaben und 50.000 Exporten/Monat. Bezahlte Tarife ab etwa 89 $/Monat.
Einschränkung: Selektorbasierte Extraktion bedeutet, dass Scraper brechen, wenn News-Seiten ihre Layouts aktualisieren. Manuelle Korrekturen sind nötig — und News-Seiten aktualisieren Layouts ständig.
Wartung: 🟡 Mittel (Vorlagen helfen, aber Selektoren können trotzdem brechen).
Am besten für: Nutzer, die einen visuellen No-Code-Builder wollen und gelegentliche Vorlagenpflege nicht scheuen.
11. ParseHub — Beste kostenlose No-Code-Option für Einsteiger
 ParseHub ist ein visueller Point-and-Click-Scraper mit einem großzügigen Gratisplan. Er verarbeitet JavaScript-gerenderte Inhalte und eignet sich gut für einmalige Rechercheprojekte oder kleinere News-Extraktionen.
ParseHub ist ein visueller Point-and-Click-Scraper mit einem großzügigen Gratisplan. Er verarbeitet JavaScript-gerenderte Inhalte und eignet sich gut für einmalige Rechercheprojekte oder kleinere News-Extraktionen.
Wichtige Funktionen:
- Visuelle Elementauswahl (kein Coding)
- Unterstützt JavaScript-gerenderte Seiten
- Export zu CSV/JSON
- Free Tier: 5 Projekte, 200 Seiten pro Lauf
Preisgestaltung: Gratisplan mit 5 Projekten und 200 Seiten/Lauf. Bezahlte Tarife ab 189 $/Monat.
Einschränkung: CSS-Selektor-basiert, daher brechen Scraper häufig, wenn sich Layouts ändern. Begrenzte Skalierbarkeit und langsamer als API-Tools. Nutzer auf Reddit und in Foren weisen immer wieder auf die Lernkurve und Fragilität hin.
Wartung: 🔴 Hoch (Selektoren brechen oft, keine KI-Anpassung).
Am besten für: Einsteiger mit kleinen, einmaligen News-Rechercheprojekten, die einen kostenlosen Startpunkt wollen.
12. Newscatcher — Beste News API für PR und Medienbeobachtung
 ist eine dedizierte News-Aggregation-API mit . Sie ist speziell für Medienbeobachtung, PR-Tracking und Trendanalyse gebaut und bietet NLP-angereicherte Felder wie Stimmung, Zusammenfassung und Entitätsextraktion.
ist eine dedizierte News-Aggregation-API mit . Sie ist speziell für Medienbeobachtung, PR-Tracking und Trendanalyse gebaut und bietet NLP-angereicherte Felder wie Stimmung, Zusammenfassung und Entitätsextraktion.
Wichtige Funktionen:
- Abdeckung von über 70.000 Quellen
- NLP-Anreicherungen: Stimmung, Zusammenfassung, Entitätsextraktion, Deduplizierung, Clustering
- Abfrage nach Keyword, Thema, Quelle, Sprache, Land
- Zugriff auf historische Archive
Preisgestaltung: Enterprise-Preise (individuelle Angebote). Kein öffentliches Free Tier zum Testen, obwohl auf Anfrage Testzugänge möglich sein können.
Einschränkung: Die auf Unternehmen ausgerichtete Preisgestaltung kann für kleine Teams außerhalb der Reichweite liegen. Kein Self-Service-Free-Tier.
Wartung: 🟢 Niedrig (voll verwaltete API).
Am besten für: PR- und Medienbeobachtungsteams in mittelgroßen bis großen Unternehmen.
13. Webz.io — Best für historische News-Archive und LLM-Trainingsdaten
 ist eine News-Datenplattform mit einem riesigen historischen Archiv — Milliarden von Artikeln über viele Jahre hinweg. Sie bietet sowohl Echtzeit-Feeds als auch Zugriff auf historische Daten und liefert strukturiertes JSON mit vollständigem Artikeltext, Metadaten und Anreicherungen.
ist eine News-Datenplattform mit einem riesigen historischen Archiv — Milliarden von Artikeln über viele Jahre hinweg. Sie bietet sowohl Echtzeit-Feeds als auch Zugriff auf historische Daten und liefert strukturiertes JSON mit vollständigem Artikeltext, Metadaten und Anreicherungen.
Wichtige Funktionen:
- Milliarden von Artikeln im historischen Archiv
- Echtzeit-Feeds und Zugriff auf historische Daten
- Vollständiger Artikeltext mit strukturierten Metadaten
- Beliebt bei KI-/ML-Teams für Trainingsdatensätze und RAG-Pipelines
Preisgestaltung: Enterprise-/individuelle Preise (nach Datenvolumen). Kein Self-Service-Free-Tier für News.
Einschränkung: Nicht für Gelegenheitsnutzer gedacht. Nur Enterprise-Preise.
Wartung: 🟢 Niedrig (voll verwalteter Datenfeed).
Am besten für: KI-/ML-Teams, die Trainingsdatensätze bauen, und Enterprise-Teams mit Bedarf an tiefen historischen News-Archiven.
14. Newspaper4k — Beste Open-Source-Bibliothek für die Artikelauslese
 ist eine Python-Bibliothek (Nachfolger von Newspaper3k), die speziell für die Extraktion sauberer Artikelinhalte entwickelt wurde. Sie entfernt Anzeigen, Seitenleisten und Navigation und gibt nur den Artikel zurück: Titel, Fließtext, Autoren, Veröffentlichungsdatum, Bilder, Keywords und Zusammenfassung.
ist eine Python-Bibliothek (Nachfolger von Newspaper3k), die speziell für die Extraktion sauberer Artikelinhalte entwickelt wurde. Sie entfernt Anzeigen, Seitenleisten und Navigation und gibt nur den Artikel zurück: Titel, Fließtext, Autoren, Veröffentlichungsdatum, Bilder, Keywords und Zusammenfassung.
Wichtige Funktionen:
- Extrahiert sauberen Artikel-Fließtext und entfernt Störquellen
- Gibt Titel, Autoren, Veröffentlichungsdatum, Bilder, Keywords, Zusammenfassung zurück
- Komplett gratis und Open Source
- Leichtgewichtig und schnell für statische HTML-Seiten
Preisgestaltung: Kostenlos. Du brauchst aber deinen eigenen Server, deine eigene Proxy-Infrastruktur und Entwicklerzeit.
Einschränkung: Kein integriertes Anti-Bot-Handling. Bricht bei stark dynamischen oder JavaScript-gerenderten News-Seiten. Erfordert Python-Kenntnisse und eine eigene Pipeline für alles über die Grundextraktion hinaus. Wenn sich die HTML-Struktur einer Seite ändert, musst du es reparieren.
Wartung: 🔴 Hoch (bricht bei HTML-Änderungen der Seite, manuelle Fixes nötig).
Am besten für: Python-Entwickler, die individuelle News-Extraktionspipelines bauen und maximale Kontrolle über das Parsing wollen.
15. HasData — Beste günstige SERP API mit News-Endpunkt
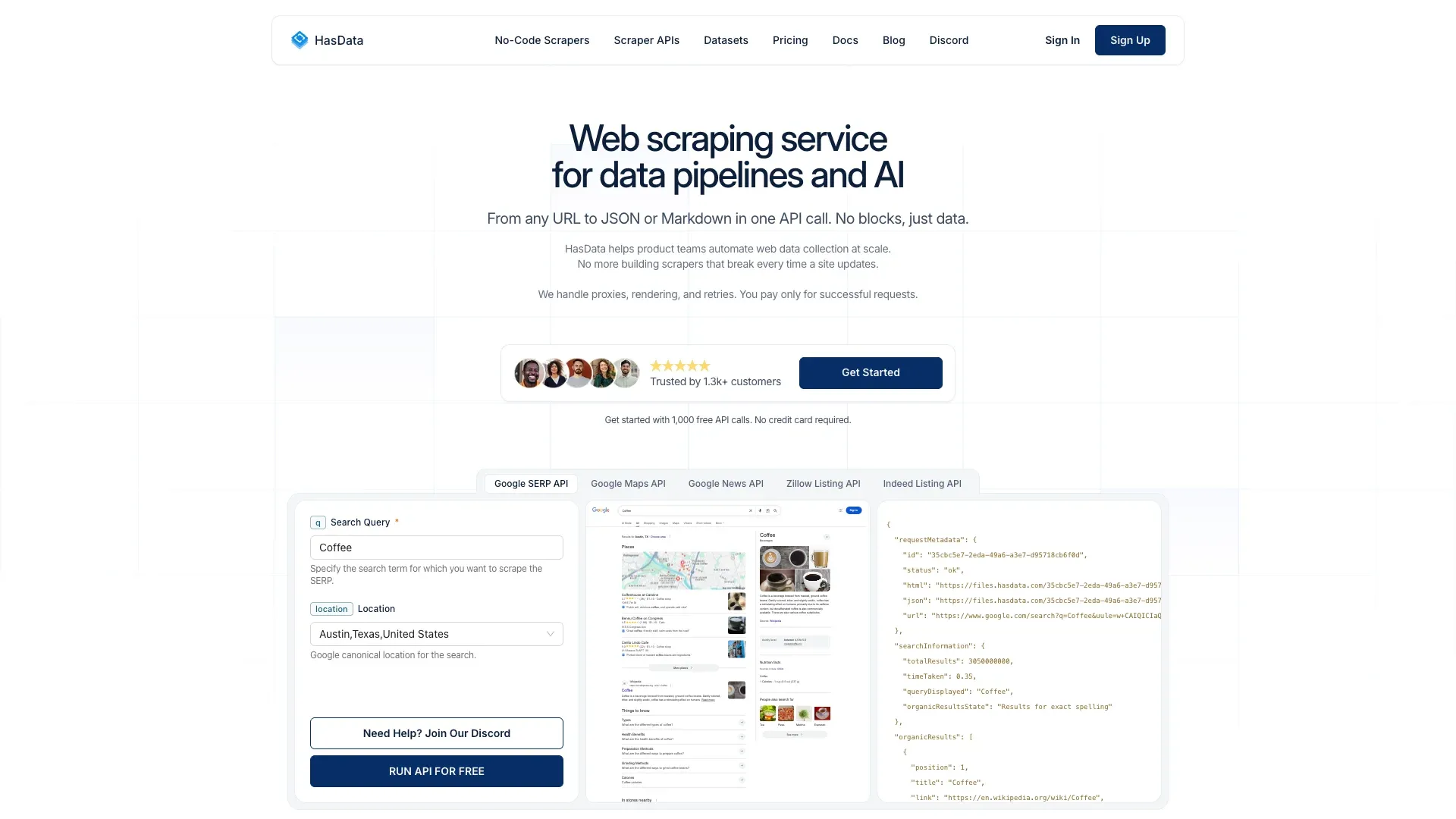 ist eine SERP-API mit einem dedizierten Google-News-Endpunkt. Sie liefert strukturiertes JSON mit News-Ergebnissen zu wettbewerbsfähigen Preisen.
ist eine SERP-API mit einem dedizierten Google-News-Endpunkt. Sie liefert strukturiertes JSON mit News-Ergebnissen zu wettbewerbsfähigen Preisen.
Wichtige Funktionen:
- Dedizierter Google-News-Endpunkt
- Strukturierte JSON-Ausgabe
- Antwortzeit von etwa 3–4 Sekunden pro Anfrage
- Kostenlose Credits zum Testen
Preisgestaltung: Startet bei (5 Credits pro News-Anfrage = 40.000 Anfragen). Das sind ungefähr 0,25–0,60 $ pro 1.000 Ergebnisse.
Einschränkung: Liefert SERP-Daten (Überschriften, Snippets), keinen vollständigen Artikeltext.
Wartung: 🟢 Niedrig (verwaltete SERP-API).
Am besten für: Preisbewusste Teams, die Google-News-SERP-Daten brauchen, ohne den Preis von SerpApi zu zahlen.
Auffällige Muster
Nachdem ich alle 15 Tools durchgearbeitet habe, fallen einige Muster deutlich auf.
SERP-APIs (SerpApi, Scrapingdog, HasData) sind großartig für strukturierte Überschriften-Daten, lassen dich aber hängen, wenn du vollständigen Artikeltext brauchst. Dedizierte News-APIs (Newsdata.io, Newscatcher, Webz.io) lösen das Metadaten-Problem hervorragend, können aber keine beliebigen URLs scrapen. No-Code-Tools (Thunderbit, Octoparse, ParseHub) geben dir Flexibilität, um jede Seite zu scrapen — ihr Wartungsprofil unterscheidet sich allerdings enorm. Und Newspaper4k liefert die sauberste Artikelauslese, wenn du bereit bist, die Pipeline selbst zu bauen und zu pflegen.
API vs. No-Code vs. Open Source: Die echten Kosten pro 1.000 Artikel
Niemand sonst normalisiert diesen Vergleich über alle Kategorien hinweg. Hier ist die Rechnung:
| Methode | Einrichtungszeit | Kosten pro 1.000 Artikel | Wartung | Am besten für |
|---|---|---|---|---|
| Open Source (Newspaper4k) | Stunden bis Tage | $0 (aber Server- + Entwicklerkosten) | 🔴 Hoch | Entwickler mit individuellen Anforderungen |
| News API (Newsdata.io, Newscatcher, Webz.io) | Minuten | $5–$50+ | 🟢 Niedrig | Strukturierte Daten, historische Archive |
| Scraping-API (ScraperAPI, ScrapingBee, Oxylabs) | 30 Min. | $1–$5 | 🟡 Mittel | Entwickler, die Anti-Bot-Handling wollen |
| No-Code-KI (Thunderbit, Octoparse, ParseHub) | 2 Minuten | $3–$15 | 🟢–🟡 | Geschäftsnutzer, nicht-technische Teams |
Die versteckten Kosten von „kostenlosen“ Open-Source-Tools sind Entwicklerzeit. Ein Senior-Entwickler, der jeden Monat 4 Stunden damit verbringt, eine kaputte Newspaper4k-Pipeline zu reparieren? Das ist nicht kostenlos — das ist teuer.
Am anderen Ende haben Enterprise-APIs wie Webz.io und Newscatcher zwar wenig Wartungsaufwand, tragen aber Preisschilder, die sich nur im großen Maßstab lohnen.
Für die meisten Geschäftsteams, mit denen ich spreche, liegt der Sweet Spot entweder bei einem No-Code-KI-Tool wie Thunderbit für flexibles Ad-hoc-Scraping oder bei einer dedizierten News-API für strukturierte, laufende Überwachung.
Das Wartungsproblem: Warum die meisten News-Scraper kaputtgehen (und welche nicht)
Das verdient einen eigenen Abschnitt.
Das ist die häufigste Beschwerde, die ich in Foren, Support-Tickets und Gesprächen mit Nutzern sehe. News-Seiten ändern ihre Layouts ständig — manchmal wöchentlich. Ein Scraper, der auf CSS-Selektoren oder XPath basiert, kann heute perfekt funktionieren und morgen nur noch Müll zurückgeben.
So schneiden die 15 Tools auf dem Wartungsspektrum ab:
| Wartungsniveau | Tools | Was passiert, wenn sich eine Seite ändert? |
|---|---|---|
| 🟢 Niedrig (KI-adaptiv oder verwaltete API) | Thunderbit, SerpApi, Newsdata.io, Newscatcher, Webz.io, Scrapingdog, HasData, Oxylabs, Bright Data | Die KI liest die Seite neu ein oder der API-Anbieter übernimmt es. Du musst nichts anfassen. |
| 🟡 Mittel (Vorlage + Proxy) | ScraperAPI, ScrapingBee, Apify, Octoparse | Anti-Bot wird abgefangen, aber deine Extraktionslogik oder dein Actor/deine Vorlage braucht eventuell ein Update. |
| 🔴 Hoch (selektorbasiert) | ParseHub, Newspaper4k | Wenn sich die Seite ändert, bricht dein Scraper. Du musst Selektoren oder Parsing-Regeln manuell anpassen. |
Thunderbits Ansatz ist hier besonders erwähnenswert: Weil die KI bei jedem Scrape-Lauf die aktuelle Seitenstruktur neu liest, gibt es keine fest codierten Selektoren, die gepflegt werden müssen. Ich habe gesehen, wie unsere Nutzer über Monate dieselben News-Quellen scrapen konnten, ohne ihre Konfiguration anzupassen — selbst nachdem die Seiten Layoutänderungen ausgerollt hatten. Genau diese Zuverlässigkeit zählt, wenn du ein tägliches News-Briefing oder einen wöchentlichen Wettbewerbsbericht fährst.
Sauberer Artikeltext: Welche News-Scraper entfernen den Lärm wirklich?
„Ich habe die Daten bekommen, aber sie sind voller Anzeigen, Navigationsmenüs und Sidebar-Müll.“ Das ist ungefähr drei von fünf Supportfragen, die ich zum News-Scraping sehe.
Hier ist die ehrliche Einordnung:
| Fähigkeit zu sauberem Text | Tools |
|---|---|
| Gibt sauberen Artikeltext direkt aus | Newspaper4k, Thunderbit (mit Unterseiten-Scraping + Field AI Prompt), Newsdata.io (Premium), Webz.io, Bright Data (News Scraper), Newscatcher |
| Gibt nur Überschriften/Snippets zurück (kein Volltext) | SerpApi, Scrapingdog, HasData, Oxylabs (SERP-Modus) |
| Gibt rohes HTML zurück (Nutzer muss parsen) | ScraperAPI, ScrapingBee |
| Hängt von der Konfiguration ab | Apify, Octoparse, ParseHub |
Newspaper4k ist der Goldstandard, wenn es darum geht, Störfaktoren aus normalen News-Seiten zu entfernen — dafür wurde es buchstäblich gebaut. Aber es braucht Python und bricht auf stark JS-lastigen Seiten.
Thunderbits Field AI Prompt ist das No-Code-Pendant: Du kannst die KI spaltenweise anweisen, „nur den Haupttext des Artikels extrahieren, Navigation und Anzeigen ausschließen“, und sie kann beim Extrahieren auch labeln, kategorisieren oder zusammenfassen. Für Teams, die sauberen Artikeltext ohne Programmierung brauchen, ist das die praktischste Lösung, die ich gefunden habe.
Wenn dich interessiert, wie sich KI-gestützte Extraktion mit traditionellen Methoden vergleicht, geht unser Beitrag zu tiefer darauf ein.
News verantwortungsvoll scrapen: Rechtliche und ethische Grundlagen
Keine der konkurrierenden Artikel, die ich gefunden habe, behandelt das — eine Lücke, die man schließen sollte, besonders für Unternehmensleser.
robots.txt: Immer prüfen. Viele große News-Seiten verbieten das Scraping bestimmter Pfade ausdrücklich. Verantwortungsvolle Tools (einschließlich Thunderbit) ermöglichen Browser-basiertes Scraping unter Berücksichtigung des Sitzungskontexts, trotzdem solltest du vor großen Jobs die robots.txt der Seite prüfen.
Nutzungsbedingungen: Es ist ein großer Unterschied, Metadaten (Titel, Daten, URLs) für interne Forschung zu extrahieren oder vollständige urheberrechtlich geschützte Artikel neu zu veröffentlichen. Ersteres ist in der Regel mit geringerem Risiko verbunden; Letzteres kann echte rechtliche Folgen haben. Aktuelle Fälle wie und zeigen, dass sich die Rechtslage weiter entwickelt.
Best Practices: Nutze offizielle APIs, wenn verfügbar (Google News RSS, Newsdata.io, Newscatcher). Caching verantwortungsvoll einsetzen. Anfragen drosseln. Paywalls niemals umgehen. Mehrere Tools auf dieser Liste — darunter Thunderbit, ScraperAPI und Bright Data — bieten integrierte Rate-Limits oder ethische Scraping-Funktionen, die dir helfen, auf der sicheren Seite zu bleiben.
Dieser Artikel dient nur zu Informationszwecken und ist keine Rechtsberatung. Wenn du in Enterprise-Größe scrapest, sprich mit deinem Legal-Team.
Wie Thunderbit in deinen News-Scraping-Workflow passt
Da mein Team Thunderbit gebaut hat, kenne ich seine Stärken und Grenzen beim News-Scraping besser als die meisten. So sieht der Workflow tatsächlich aus.
Der typische Ablauf für Geschäftsnutzer sieht so aus:
- Eine News-Seite öffnen (Google-News-Ergebnisse, die Startseite einer Publikation, eine Themen-Suchseite) in Chrome.
- Auf die Thunderbit-Erweiterung klicken und AI Suggest Fields auswählen. Thunderbit liest die Seite und schlägt Spalten vor — Überschrift, Datum, Quelle, URL, Snippet, Bild usw.
- Spalten bei Bedarf anpassen. Willst du eine Stimmungsbewertung? Füge eine Spalte mit einem Field AI Prompt hinzu wie „klassifiziere die Stimmung als positiv, neutral oder negativ“. Willst du nur Artikel aus einer bestimmten Kategorie? Füge einen Filter-Prompt hinzu.
- Auf Scrape klicken. Wähle Browser-Modus (nutzt deine Sitzung, gut für Seiten, die Cloud-IPs blockieren) oder Cloud-Modus (schneller, verarbeitet bis zu 50 Seiten gleichzeitig).
- Scrape Subpages verwenden, um jede Artikel-URL aufzurufen und vollständigen Fließtext, Autor, Veröffentlichungsdatum und Bilder zu extrahieren.
- Exportieren nach Excel, CSV, , Airtable oder Notion.
Für laufendes Monitoring erlaubt dir der Geplante Scraper, tägliche oder wöchentliche Läufe mit natürlichsprachlichen Intervallen einzurichten (z. B. „jeden Werktag um 8 Uhr“). Und weil Thunderbit unterstützt, ist internationales News-Monitoring unkompliziert.
Wo Thunderbit weniger ideal ist: Millionen von Artikeln pro Monat zu den niedrigstmöglichen Stückkosten zu scrapen — dort ist eine Enterprise-API wie Bright Data oder Webz.io kosteneffizienter. Und wenn du tiefe NLP-Anreicherung (Entitätsextraktion, Clustering, Deduplizierung) direkt in der API-Antwort brauchst, ist Newscatcher dafür spezialisiert.
Du kannst Thunderbit kostenlos über die ausprobieren — keine Kreditkarte erforderlich.
Wie du den richtigen News-Scraper auswählst
Mein Spickzettel, verdichtet aus dem Test von allen 15 Tools:
- Nicht-technischer Geschäftsnutzer, der täglich News-Daten will? Starte mit Thunderbit. Zwei Klicks, kein Code, die KI handhabt Layoutänderungen.
- Entwickler, der eine Monitoring-Pipeline baut? SerpApi oder Scrapingdog für SERP-Daten. ScraperAPI oder ScrapingBee für rohes HTML mit Anti-Bot.
- Enterprise-Team mit Bedarf an Scale und Zuverlässigkeit? Bright Data oder Oxylabs.
- PR-Team, das Markenerwähnungen über Tausende Quellen hinweg verfolgt? Newscatcher oder Newsdata.io.
- Forscher, der einen Textkorpus aufbaut? Newspaper4k (wenn du dich mit Python wohlfühlst) oder Thunderbits Unterseiten-Scraping (wenn nicht).
- KI-Engineer, der eine RAG-Pipeline speist? Thunderbit API oder Webz.io für sauberen, strukturierten Artikeltext.
- Mit knappem Budget? Scrapingdog für APIs, Thunderbits Free Tier für No-Code, Newspaper4k für Open Source.
Das richtige Tool hängt von deiner Bereitschaft zum Wartungsaufwand, deinem Budget und deinem technischen Niveau ab. Nicht sicher? Starte mit einem Free Tier — die meisten dieser Tools bieten eines an — und schau, welcher Workflow zu deiner Realität passt.
Für mehr Optionen und Vergleiche deckt unser Überblick über die die breitere Landschaft ab. Und wenn du vor der Tool-Entscheidung erst verstehen willst, , ist dieser Leitfaden ein guter Startpunkt.
Fazit
News-Scraping im Jahr 2026 ist ein gelöstes Problem — wähle das richtige Tool für deinen Anwendungsfall, und die Daten fließen. Empfehlungen nach dem Einheitsmodell sind vorbei. SERP-APIs sind großartig für Überschriften, liefern aber keinen Artikeltext. Dedizierte News-APIs sind fantastisch für strukturierte Metadaten, können aber keine beliebigen URLs scrapen. No-Code-KI-Tools wie Thunderbit geben dir Flexibilität und geringen Wartungsaufwand, während Open-Source-Bibliotheken dir Kontrolle geben — auf Kosten deiner Wochenenden.
Meine ehrliche Empfehlung: Entscheide zuerst, ob du Überschriften, vollständigen Artikeltext oder angereicherte Metadaten brauchst — und ordne das dann dem Wartungsniveau und Budget zu, das du tragen kannst. Und wenn du sehen willst, wie modernes, KI-adaptives News-Scraping aussieht, ohne eine einzige Zeile Code zu schreiben, . Ich glaube, du wirst überrascht sein, wie viel du mit wenigen Klicks erledigen kannst.
Viel Spaß beim Scrapen — und mögen dein Artikeltext immer sauber, deine Selektoren nie kaputt und dein Export im richtigen Tabellenblatt landen.
FAQs
1. Welcher News-Scraper ist am besten für nicht-technische Nutzer?
Thunderbit ist die stärkste Option für nicht-technische Nutzer. Sein KI-gestützter 2-Klick-Workflow erfordert weder Programmierung noch CSS-Selektoren. Die KI liest die Seitenstruktur automatisch, schlägt Extraktionsfelder vor und passt sich an Layoutänderungen an — du musst also nichts pflegen. Außerdem exportiert es direkt nach Google Sheets, Airtable und Notion.
2. Kann ich mit News-Scrapern den vollständigen Artikeltext bekommen oder nur Überschriften?
Das hängt vom Tool ab. SERP-APIs wie SerpApi, Scrapingdog und HasData liefern nur Überschriften und Snippets. Dedizierte News-APIs wie Newsdata.io und Webz.io geben auf Premium-Tarifen den Volltext zurück. No-Code-Tools wie Thunderbit können vollständigen Artikeltext per Unterseiten-Scraping extrahieren, und Newspaper4k ist in Python speziell für saubere Artikelauslese gebaut. Prüfe immer, ob ein Tool rohes HTML, Snippets oder sauberen Artikeltext zurückgibt, bevor du dich festlegst.
3. Gehen News-Scraper kaputt, wenn Websites ihr Layout ändern?
Selektorbasierte Tools (ParseHub, Octoparse, Newspaper4k, benutzerdefinierte Scrapy-Pipelines) brechen häufig, wenn News-Seiten ihre Layouts aktualisieren — und das tun sie oft. KI-adaptive Tools wie Thunderbit lesen die Seitenstruktur bei jedem Lauf neu, sodass Layoutänderungen den Workflow nicht brechen. Verwaltete APIs (SerpApi, Newsdata.io, Newscatcher) kümmern sich selbst darum. Wenn Wartung wichtig ist, priorisiere Tools mit 🟢 Niedrig in der Vergleichstabelle.
4. Was ist die günstigste Möglichkeit, News in großem Umfang zu scrapen?
Für API-basiertes Scraping bietet Scrapingdog die niedrigsten Kosten pro Anfrage (ab etwa 0,10 $ pro 1.000 Ergebnisse). Für No-Code-Scraping deckt Thunderbits Free Tier kleine Projekte ab, und bezahlte Pläne beginnen bei etwa 9 $/Monat. Für Open Source ist Newspaper4k kostenlos — aber rechne Entwicklerzeit und Serverkosten mit ein, die schnell erheblich werden können.
5. Ist es legal, News-Websites zu scrapen?
Das Scrapen öffentlich zugänglicher Daten für interne Forschung ist in der Regel mit geringerem Risiko verbunden, aber das erneute Veröffentlichen vollständiger urheberrechtlich geschützter Artikel kann rechtliche Risiken mit sich bringen. Prüfe vor dem Scraping immer die robots.txt und die Nutzungsbedingungen einer Seite. Nutze offizielle APIs, wenn sie verfügbar sind, respektiere Rate-Limits und umgehe niemals Paywalls. Aktuelle Fälle wie hiQ gegen LinkedIn und Meta gegen Bright Data zeigen, dass sich die Rechtslage weiter entwickelt. Für Scraping im Enterprise-Scale solltest du dein Legal-Team einbeziehen.
Mehr erfahren