

Fast die Hälfte des gesamten Internetverkehrs läuft inzwischen über Bots – und die meisten davon durchforsten Links, Daten und URLs in gigantischem Umfang. Wer das noch von Hand erledigt, gerät schnell ins Hintertreffen.
Ich habe 12 Link-Extraktor-Tools auf den Prüfstand gestellt – von KI-gestützten Chrome-Erweiterungen bis zu Python-Bibliotheken –, um herauszufinden, welche Lösungen wirklich liefern, wenn tausende URLs in kürzester Zeit raus müssen.
Das ist mein Fazit.
Warum Link-Extraktoren wichtig sind
Ganz ehrlich: Das Web quillt über vor Daten, und Unternehmen versuchen, aus diesem Chaos verwertbare Erkenntnisse zu ziehen. Link-Extraktoren und URL-Extraktoren sind heute unverzichtbar für Teams, die Folgendes erreichen wollen:
- Leads generieren: Vertriebsteams ziehen in wenigen Minuten Unternehmensprofile aus Verzeichnissen oder LinkedIn und speisen diese URLs anschließend in Tools zur Kontaktdatenerfassung ein. Schluss mit endlosem Klicken.
- Inhalte bündeln und SEO stärken: Marketingteams sammeln alle Artikel-URLs aus einem Blog, behalten die Backlinks der Wettbewerber im Blick oder prüfen die Website-Struktur auf defekte Links.
- Wettbewerber beobachten und Marktforschung betreiben: Operations-Teams erfassen automatisch Links zu neuen Produkten, Preisseiten oder Pressemitteilungen – und behalten so die Konkurrenz im Auge, ohne viel Aufwand zu treiben.
- Workflows automatisieren und Zeit sparen: Moderne Link-Scraper verarbeiten große URL-Mengen, crawlen Unterseiten und exportieren Daten in strukturierte Formate (CSV, Excel, Google Sheets, Notion und mehr). Das heißt: keine Copy-and-paste-Marathons und kein mühsames Aufräumen chaotischer Textdateien mehr.
Da täglich zig Milliarden Webseiten gecrawlt werden, ist das manuelle Vorgehen schlicht keine Option. Der richtige Link-Extraktor ist wie ein unermüdlicher Assistent mit Turbogang: Er macht nie schlapp, übersieht keinen Link und verlangt nie nach einer Kaffeepause.
Wie wir die besten Link-Extraktoren ausgewählt haben
Bei der Fülle an Tools kann die Wahl des richtigen Link-Extraktors schnell wie Speed-Dating auf einer Tech-Konferenz wirken – alle versprechen, „die eine“ Lösung zu sein, aber nur wenige halten Wort. So habe ich die Top 12 eingegrenzt:
- Einfache Bedienung: Kommen auch Nicht-Programmierer damit klar, ohne einen Doktortitel in Regex? No-Code- und Low-Code-Lösungen bekamen Pluspunkte.
- Massenverarbeitung & mehrstufiges Scraping: Verarbeitet das Tool Hunderte URLs auf einen Schlag? Crawlt es Unterseiten und folgt Links automatisch?
- Export & Integration: Exportiert es nach CSV, Excel, Google Sheets, Notion, Airtable oder per API? Je weniger Handarbeit, desto besser.
- Zielgruppe & Flexibilität: Ist es für Business-Anwender, Analysten oder Entwickler gedacht? Manche Tools sind für alle gemacht, andere eher für spezielle Anwendungsfälle.
- Erweiterte Funktionen: KI-gestützte Erkennung, Planung, Cloud-Skalierung, Datenbereinigung und Vorlagen für gängige Websites.
- Preis & Skalierbarkeit: Gratis-Tarife, nutzungsbasierte Abrechnung oder Enterprise? Ich habe bewertet, was Sie fürs Geld bekommen.
Aufgenommen habe ich alles – von Browser-Erweiterungen bis zu Enterprise-Plattformen. Egal ob Solo-Founder oder großes Data-Team eines Fortune-500-Konzerns: Hier ist für jeden etwas dabei.
Thunderbit: Der intelligenteste Link-Extraktor für Business-Anwender
Beginnen wir mit dem Spitzenreiter. Thunderbit ist meine erste Empfehlung für die Link-Extraktion – und das nicht nur, weil ich an der Entwicklung mitgewirkt habe. Thunderbit ist eine KI-gestützte Web-Scraper-Chrome-Erweiterung, die für Business-Anwender entwickelt wurde, die schnell Ergebnisse wollen.
Was Thunderbit besonders macht? Es ist, als hätten Sie einen KI-Praktikanten, der wirklich zuhört. Beschreiben Sie in Alltagssprache, was Sie brauchen („Hole alle Produktlinks und Preise von dieser Seite“), und Thunderbits KI übernimmt den Rest. Kein Herumprobieren mit Selektoren, kein Skript-Geschreibe.
Damit ist es aber noch nicht getan:
- Unterstützung für große URL-Mengen: Fügen Sie eine einzelne URL ein oder gleich Hunderte – Thunderbit verarbeitet alles in einem Durchgang.
- Navigation über Unterseiten: Sie möchten Links aus einer Übersichtsseite ziehen und dann jede Detailseite besuchen, um weitere URLs zu sammeln? Genau das ermöglicht Thunderbits mehrstufige Scraping-Logik.
- Strukturierter Export: Nach der Extraktion benennen Sie Felder um, ordnen Kategorien zu und exportieren die Daten direkt nach Google Sheets, Notion, Airtable, Excel oder CSV. Kein Nachbearbeiten, kein Ärger.
Links von jeder Website mit KI extrahieren Get Started Free
Thunderbit ist weltweit bei über 30.000 Nutzern im Einsatz – von Vertriebsteams über Immobilienmakler bis zu kleinen E-Commerce-Shops. Und ja, es gibt einen kostenlosen Tarif (bis zu 6 Seiten, mit Trial-Boost 10), sodass Sie das Tool risikofrei ausprobieren können.
Thunderbit Link-Extraktor kostenlos testen
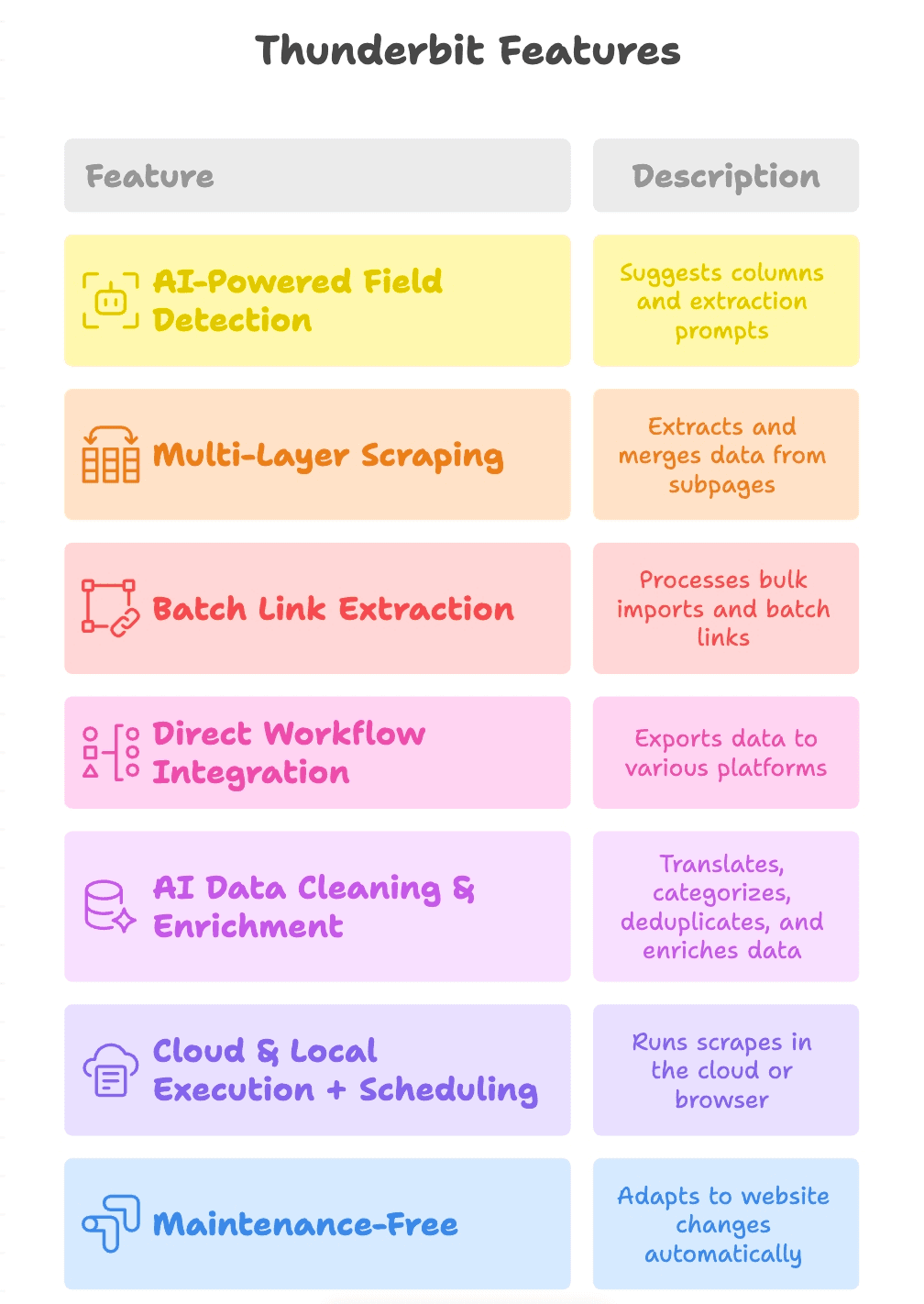
Die herausragenden Funktionen von Thunderbit
Schauen wir uns an, was Thunderbit wirklich abhebt:
- KI-gestützte Felderkennung: Ein Klick auf „AI Suggest Fields“ genügt – Thunderbit liest die Seite, schlägt Spalten vor (zum Beispiel „Produktlink“, „PDF-URL“, „Kontakt-E-Mail“) und erstellt sogar passende Extraktions-Prompts für jedes Feld.
- Mehrstufiges Scraping: Thunderbit navigiert von der Hauptseite zu Unterseiten wie Produktdetailseiten oder PDF-Downloads, extrahiert weitere Links und führt alles in einer einzigen Tabelle zusammen.
- Batch-Link-Extraktion: Ob eine Seite oder tausend – Thunderbit bewältigt große Importe und Batch-Extraktionen mühelos.
- Direkte Workflow-Integration: Exportieren Sie Ergebnisse nach Google Sheets, Notion oder Airtable oder laden Sie sie als CSV/Excel herunter. Ihre Daten landen genau dort, wo Ihr Team sie braucht.
- KI-gestützte Datenbereinigung & Anreicherung: Thunderbit kann beim Scraping übersetzen, kategorisieren, Duplikate entfernen und Ihre Daten anreichern – damit die Ausgabe sofort einsatzbereit ist und nicht nur ein roher Datenexport.
- Cloud- & Browser-Ausführung plus Zeitplanung: Führen Sie Scrapes in der Cloud für maximales Tempo aus oder im Browser, wenn Login-Zugänge nötig sind. Planen Sie wiederkehrende Jobs, damit Ihre Daten aktuell bleiben.
- Wartungsarm: Thunderbits KI passt sich an Website-Änderungen an, sodass Sie weniger Zeit mit kaputten Scrapern und mehr mit echten Ergebnissen verbringen.
Octoparse: No-Code Link-Scraper für alle
Octoparse ist ein Klassiker im No-Code-Scraping. Die Desktop-App für Windows und Mac bietet eine visuelle Oberfläche zum Anklicken statt Programmieren. Sie laden eine Webseite, klicken die gewünschten Links an, und Octoparse erledigt den Rest.
- Ideal für Einsteiger: Kein Code erforderlich. Einfach klicken, extrahieren, fertig.
- Pagination & dynamische Inhalte: Octoparse klickt auf „Weiter“-Buttons, scrollt und loggt sich sogar auf Websites ein.
- Cloud-Scraping & Zeitplanung: Mit bezahlten Tarifen führen Sie Jobs in der Cloud aus und planen wiederkehrende Aufgaben.
- Export-Optionen: Daten als CSV, Excel oder JSON herunterladen oder in Datenbanken übertragen.
Der kostenlose Tarif ist für kleinere Aufgaben recht großzügig (bis zu 10 Aufgaben und 50.000 Zeilen pro Monat), für intensivere Nutzung braucht es jedoch einen kostenpflichtigen Plan (ab etwa 75 US-Dollar pro Monat, ca. 69 €/Monat).
Apify: Flexibler URL-Extraktor für individuelle Workflows
Apify ist das Allzweckwerkzeug unter den Web-Scraping-Tools. Es bietet einen Marktplatz mit vorgefertigten „Actors“ (Scraping-Tools) und lässt Sie außerdem eigene Skripte in JavaScript oder Python schreiben.
- Vorgefertigt & anpassbar: Nutzen Sie Community-Actors für typische Aufgaben oder bauen Sie eigene Workflows.
- Massen- & geplantes Scraping: URLs in eine Warteschlange stellen, Jobs parallel ausführen und wiederkehrende Scrapes terminieren.
- API-first: Export nach JSON, CSV, Excel oder Google Sheets und Integration in Ihre Datenpipeline.
- Pay-as-you-go: Monatlich kostenlose Credits, danach nutzungsbasierte Abrechnung.
Apify eignet sich ideal für semi-technische Teams und Entwickler, die Flexibilität und Skalierbarkeit brauchen.
Bright Data URL Scraper: Link-Scraping auf Enterprise-Niveau
Bright Data ist für Unternehmen gebaut, die in großem Maßstab scrapen müssen. Der Data Collector liefert einen vorkonfigurierten URL-Scraper für hohe Volumina.
- Bewältigt riesige Mengen: Tausende oder Millionen von Seiten scrapen – gestützt auf eine robuste Proxy-Infrastruktur, um Blockaden zu umgehen.
- Vordefinierte Vorlagen: Fertige Scraper für E-Commerce, Social Media, Immobilien und mehr.
- Enterprise-Funktionen: Compliance-Tools, Experten-Support und fortschrittliche Anti-Blocking-Mechanismen.
- Preisgestaltung: Ab etwa 350 US-Dollar (ca. 322 €) für 100.000 Seitenaufrufe – klar auf große Unternehmen ausgerichtet.
Für Startups ist das womöglich überdimensioniert. Für geschäftskritisches Scraping mit hohem Volumen ist Bright Data jedoch eine echte Power-Lösung.
WebHarvy: Visueller Link-Extraktor mit Point-and-Click-Bedienung
WebHarvy ist eine Desktop-App für Windows, mit der Sie Links einfach anklicken und direkt im integrierten Browser extrahieren.
- Extrem einfach: Link anklicken, und WebHarvy markiert automatisch ähnliche Elemente zur Extraktion.
- Unterstützung für reguläre Ausdrücke: Eingebaute Muster für gängige Aufgaben, ganz ohne Programmierung.
- Export nach Excel, CSV, JSON, XML, SQL: Ideal für Business-Anwender, die ihre Daten in vertrauten Formaten brauchen.
- Einmalige Lizenz: Einmal zahlen, dauerhaft nutzen.
Perfekt für kleine Unternehmen, Forschende oder alle, die schnell und unkompliziert Links ohne Code erfassen wollen.
Web Scraper (Chrome-Erweiterung): Schnelles Link-Scraping direkt im Browser
Die Web Scraper Chrome Extension ist ein kostenloses Open-Source-Tool, das Ihren Browser in einen Scraper verwandelt.
- Sitemaps definieren: Sie geben vor, wie navigiert wird und was extrahiert werden soll.
- Pagination & mehrstufiges Crawling: Kategorien, Unterkategorien und Detailseiten lassen sich crawlen.
- Export nach CSV/XLSX: Daten direkt aus dem Browser herunterladen.
- Community-Vorlagen: Viele geteilte Sitemaps für bekannte Websites.
Ideal für schnelle Einmalaufgaben oder für Studierende und kleine Teams mit begrenztem Budget.
ScraperAPI: Skalierbarer Link-Scraper für Entwickler
ScraperAPI richtet sich an Entwickler, die Webseiten in großem Umfang abrufen wollen, ohne sich um Proxies, Blockaden oder CAPTCHAs kümmern zu müssen.
- API-gesteuert: URL senden, HTML oder extrahierte Daten zurückerhalten.
- Skalierung & Anti-Bot-Schutz: Proxy-Rotation, JavaScript-Rendering und CAPTCHA-Lösung sind integriert.
- In den eigenen Code integrierbar: Nutzbar mit Python, Node.js oder jeder anderen Sprache.
- Preisgestaltung: Kostenloser Tarif mit etwa 1000 API-Aufrufen, danach Bezahlung pro Anfrage.
Ideal für eigene Crawler oder wenn Sie bei hohem Volumen auf Zuverlässigkeit und Tempo angewiesen sind.
ParseHub: Visueller Link-Scraper mit erweiterten Auswahlfunktionen
ParseHub ist eine Desktop-App für Windows, Mac und Linux, mit der Sie Scraping-Projekte visuell aufbauen.
- Erweiterte Auswahl & Navigation: Anklicken, Schleifen erstellen und Links bedingt extrahieren – auch aus dynamischen oder versteckten Elementen.
- Verschachtelte Seiten: Kategorien crawlen, dann Detailseiten, dann weitere Links extrahieren.
- Export nach CSV, Excel, JSON: Cloud-Ausführungen und API-Zugang in den bezahlten Tarifen.
- Kostenloser Plan: 5 Projekte, bis zu 200 Seiten pro Lauf.
ParseHub ist besonders beliebt bei Marketing- und Research-Teams, die Leistung ohne Code wollen.
Scrapy: Python-Link-Extraktor für Entwickler
Scrapy ist der Goldstandard für Python-Entwickler, die volle Kontrolle wollen.
- Code-first: Eigene Spiders bauen, um Links in jeder Größenordnung zu crawlen und zu extrahieren.
- Verteiltes Crawling: Effizient, asynchron und hochgradig anpassbar.
- Export nach CSV, JSON, XML oder Datenbank: Sie bestimmen die Ausgabe.
- Open Source & kostenlos: Allerdings müssen Sie Ihre eigene Umgebung verwalten.
Wenn Sie sich mit Python wohlfühlen, ist Scrapy kaum zu schlagen.
Diffbot: KI-gestützter Link-Scraper für strukturierte Daten
Diffbot ist das „KI-Gehirn“ unter den Web-Scraping-Tools. Das Tool analysiert Seiten und liefert strukturierte Daten – inklusive Links – ganz ohne manuelles Setup.
- Automatische Inhaltserkennung: URL eingeben, strukturierte Daten zurückerhalten (Artikel, Produkte, Links usw.).
- Crawlbot & Knowledge Graph: Ganze Websites crawlen oder den riesigen Web-Index abfragen.
- API-gesteuert: Integration in BI-Tools oder Ihre Datenpipeline.
- Enterprise-Preisgestaltung: Ab etwa 299 US-Dollar pro Monat (ca. 275 €/Monat) – dafür bekommt man aber auch entsprechend viel.
Am besten geeignet für Unternehmen, die saubere, strukturierte Daten wollen, ohne Scraper selbst verwalten zu müssen.
Cheerio: Leichter Link-Scraper für Node.js
Cheerio ist ein schnelles, jQuery-ähnliches HTML-Parsing-Tool für Node.js.
- Sehr schnell: Analysiert HTML in Millisekunden.
- Vertraute Syntax: Wer jQuery kennt, findet sich in Cheerio sofort zurecht.
- Ideal für statische Seiten: Rendert kein JavaScript, ist aber perfekt für serverseitig gerenderte Inhalte.
- Open Source & kostenlos: In Kombination mit axios oder fetch für Anfragen nutzbar.
Ideal für Entwickler, die eigene Skripte bauen und dabei auf Tempo und Einfachheit setzen.
Puppeteer: Browser-Automatisierung für fortgeschrittenes Link-Scraping
Puppeteer ist eine Node.js-Bibliothek zur Steuerung von Chrome im Headless-Modus.
- Vollständige Browser-Automatisierung: Seiten laden, klicken, scrollen und wie ein echter Nutzer interagieren.
- Geeignet für dynamische Inhalte & Logins: Perfekt für JavaScript-lastige Websites oder komplexe Workflows.
- Feingranulare Kontrolle: Auf Elemente warten, Screenshots erstellen, Netzwerkanfragen abfangen.
- Open Source & kostenlos: Allerdings ressourcenintensiv und langsamer als schlankere Tools.
Greifen Sie zu Puppeteer, wenn Sie Links von Websites extrahieren müssen, die bei einfachen Scrapern nicht mitspielen.
Vergleich auf einen Blick: Welcher Link-Extraktor passt zu Ihnen?
Hier ist ein schneller Vergleich aller 12 Tools:
| Tool | Am besten geeignet für | Bulk- & Unterseiten-Support | Export-Optionen | Preisgestaltung |
|---|---|---|---|---|
| Thunderbit | Nicht-Programmierer, Business | Ja (KI, mehrstufig) | Excel, CSV, Sheets, Notion, Airtable | Kostenloser Test, ab ca. 9 $/Monat |
| Octoparse | No-Code-Nutzer, Analysten | Ja | CSV, Excel, JSON, Cloud-Speicher | Kostenloser Tarif, ca. 75 $/Monat |
| Apify | Semi-technische Nutzer, Entwickler | Ja | CSV, JSON, Sheets per API | Gratis-Credits, nutzungsbasiert |
| Bright Data | Enterprise | Ja (hohes Volumen) | CSV, JSON, NDJSON per API | ca. 350 $/100k Seiten |
| WebHarvy | Nicht-Programmierer, Desktop | Ja | Excel, CSV, JSON, XML, SQL | Kostenpflichtige Lizenz |
| Web Scraper Extension | Alle, schnell & kostenlos | Ja | CSV, XLSX | Kostenlos, Open Source |
| ScraperAPI | Entwickler, API-Nutzer | Ja | JSON (HTML per API) | Kostenlos 1k Anfragen, kostenpflichtige Tarife |
| ParseHub | Nicht-Programmierer, Fortgeschrittene | Ja | CSV, Excel, JSON, API | Kostenlos 5 Projekte, danach kostenpflichtig |
| Scrapy | Entwickler, Python | Ja | CSV, JSON, XML, DB | Kostenlos, Open Source |
| Diffbot | Enterprise, KI | Ja (KI-Crawl) | JSON (strukturierte Daten per API) | ab ca. 299 $/Monat+ |
| Cheerio | Entwickler, Node.js | Ja (Custom Code) | Individuell (JSON usw.) | Kostenlos, Open Source |
| Puppeteer | Entwickler, komplexe Websites | Ja (vollständige Automatisierung) | Individuell (Skript-Ausgabe) | Kostenlos, Open Source |
Wie Sie den richtigen Link-Scraper für Ihr Unternehmen auswählen
Wie treffen Sie also die richtige Wahl? Hier ist meine Kurzfassung:
- Keine Programmierkenntnisse? Starten Sie mit Thunderbit, Octoparse, ParseHub, WebHarvy oder der Web Scraper-Erweiterung.
- Sie brauchen individuelle Workflows? Apify, ScraperAPI oder Cheerio sind für Entwickler sehr stark.
- Enterprise-Maßstab? Bright Data oder Diffbot sind dafür gemacht.
- Python- oder Node.js-Entwickler? Scrapy (Python) oder Cheerio/Puppeteer (Node.js) geben Ihnen volle Kontrolle.
- Direkter Export nach Sheets/Notion gewünscht? Hier ist Thunderbit die beste Wahl.
Wählen Sie das Tool passend zu Ihrem technischen Komfort, Ihrem Datenvolumen und Ihren Integrationsanforderungen. Die meisten Tools bieten kostenlose Testphasen – probieren Sie also ruhig mehrere aus.
Weitere Web-Scraping-Ratgeber entdecken Get Started Free
Thunderbits einzigartiger Mehrwert für Link-Extraktion im Jahr 2026
Kehren wir noch einmal zu dem zurück, was Thunderbit wirklich unterscheidet:
- KI-gestützte Einfachheit: Beschreiben Sie Ihr Ziel in Alltagssprache – Thunderbits KI erledigt den Rest.
- Mehrstufiges Scraping: Extrahieren Sie Links von Hauptseiten, folgen Sie Unterseiten und erfassen Sie weitere URLs – alles in einem einzigen Ablauf.
- Massenimport & Batch-Verarbeitung: Fügen Sie Hunderte URLs ein, extrahieren Sie Links in großen Mengen und exportieren Sie strukturierte Daten sofort.
- Workflow-Integration: Direkt nach Google Sheets, Notion oder Airtable exportieren oder als CSV/Excel herunterladen.
- Null Wartungsaufwand: Thunderbits KI passt sich Website-Änderungen an, sodass Sie nicht ständig kaputte Scraper reparieren müssen.
Thunderbit schließt die Lücke zwischen „einfach Daten scrapen“ und „Daten erhalten, die Sie wirklich nutzen können“. Es ist das Tool, das ich mir vor Jahren gewünscht hätte, als ich in manuellen Datenaufgaben unterzugehen drohte.
Kostenlos mit Link-Extraktion mit Thunderbit starten
Fazit: Links intelligenter extrahieren und Ihren Workflow beschleunigen
Webdaten sind der Treibstoff für Unternehmenswachstum – und der richtige Link-Extraktor ist Ihr Motor. Ob Sie Lead-Listen aufbauen, Wettbewerber beobachten oder Recherchen automatisieren: Hier finden Sie ein Tool, das zu Ihren Anforderungen und Ihrem Skillset passt.
Wenn Sie sehen möchten, wie moderne Link-Extraktion aussieht, testen Sie Thunderbit kostenlos. Ich glaube, Sie werden überrascht sein, wie viel sich mit nur wenigen Klicks erledigen lässt. Und falls Thunderbit nicht perfekt passt, probieren Sie einfach einige andere Tools aus dieser Liste aus – es gab nie einen besseren Zeitpunkt, langweilige Aufgaben zu automatisieren und sich aufs Wesentliche zu konzentrieren.
Viel Erfolg beim Scrapen – und mögen Ihre Links stets sauber, strukturiert und einsatzbereit sein. Wenn Sie tiefer ins Thema Web-Scraping einsteigen möchten, finden Sie im Thunderbit Blog weitere Leitfäden und Tipps.
Thunderbit Link-Extraktor kostenlos testen Get Started Free
FAQs
1. Warum sind Link-Extraktoren so wichtig?
Da fast die Hälfte des Internetverkehrs von Bots stammt und Unternehmen aggressiv Daten scrapen, sind Link-Extraktoren entscheidend, um aus dem Web-Chaos verwertbare Erkenntnisse zu ziehen. Sie automatisieren Aufgaben wie Lead-Generierung, Content-Aggregation, SEO-Audits und Wettbewerbsbeobachtung – und sparen dabei enorm viel Zeit und Aufwand.
2. Was hebt Thunderbit von anderen Link-Extraktoren ab?
Thunderbit nutzt KI, um das Scraping zu vereinfachen: Beschreiben Sie Ihr Ziel in normaler Sprache, und das Tool erledigt den Rest. Es unterstützt die Eingabe vieler URLs, mehrstufiges Scraping, intelligente Felderkennung und den nahtlosen Export zu Plattformen wie Google Sheets und Notion. Ideal für Nicht-Programmierer und Business-Anwender, die starke Ergebnisse ohne technischen Aufwand wollen.
3. Gibt es Link-Extraktor-Tools für Entwickler und individuelle Workflows?
Ja. Tools wie Apify, ScraperAPI, Cheerio, Puppeteer und Scrapy richten sich an Entwickler. Sie bieten Scripting, API-Integration und die nötige Flexibilität für komplexe Scraping-Aufgaben, große Datenmengen und fortgeschrittene Automatisierung.
4. Welche Tools eignen sich am besten für Nutzer ohne Programmiererfahrung?
Thunderbit, Octoparse, ParseHub, WebHarvy und die Web Scraper Chrome-Erweiterung sind die besten Optionen für technisch weniger versierte Nutzer. Diese Tools bieten visuelle Oberflächen, vorgefertigte Vorlagen und KI-gestützte Funktionen, die die Link-Extraktion für alle zugänglich machen.
5. Wie wähle ich den passenden Link-Extraktor für meine Anforderungen aus?
Berücksichtigen Sie Ihre technischen Fähigkeiten, Ihr Datenvolumen und Ihre Exportanforderungen. Nicht-Programmierer greifen am besten zu Tools wie Thunderbit oder Octoparse, während Entwickler eher Scrapy oder Puppeteer bevorzugen. Unternehmen im großen Maßstab sollten sich Bright Data oder Diffbot ansehen. Starten Sie immer mit einer kostenlosen Testphase, um herauszufinden, was am besten passt.




