

Das Web ist inzwischen ein riesiges Bilder-Labyrinth – wohin man auch klickt, überall Fotos: Produktgalerien, Immobilienanzeigen, Social-Media-Feeds, die Kataloge der Konkurrenz. Ich erlebe immer wieder, dass Teams aus Vertrieb, E-Commerce und Marketing nicht nur mit Texten und Zahlen hantieren, sondern auch mit der Bilderflut, die Kaufentscheidungen lenkt und das Markenbild prägt. Artikel mit Bildern bekommen 94 % mehr Aufrufe als reine Textbeiträge – und Anleitungen mit Bildern können die Produktivität um 15 % steigern. Visuelle Daten sind also längst kein nettes Extra mehr, sondern eine eigene Währung im Geschäft.

Der Haken: Bilder in großem Stil zu sammeln, ist alles andere als trivial. Jedes Bild einzeln per Rechtsklick zu speichern, führt direkt ins RSI-Syndrom. Und je dynamischer Webseiten werden – endloses Scrollen, Pop-up-Galerien, AJAX-Inhalte –, desto öfter geben klassische Web-Scraper auf. Deshalb habe ich für dich die Top 5 der besten Image Crawler Tools für eine effiziente Bildersuche 2025 zusammengetragen. Ob du ohne Programmierkenntnisse schnelle Ergebnisse willst, als Entwickler gern tüftelst oder im Unternehmen große Datenmengen brauchst – hier ist für jeden etwas dabei.
Was einen wirklich guten Image Crawler ausmacht, wie die Tools im Vergleich abschneiden und welches deinem Workflow am meisten bringt, klären wir jetzt.
Warum die Wahl des richtigen Image Crawlers so wichtig ist
Entdecke die besten Web-Scraping-Tools Get Started Free
Bilder sind überall, aber sie aus dem Web in den eigenen Workflow zu holen, ist oft eine echte Herausforderung. Unternehmen setzen Bilddaten für alles Mögliche ein – von Marktforschung und Wettbewerbsanalyse über KI-Training bis zur Content-Erstellung. Gerade im Handel und in der Immobilienbranche entscheiden Bilder oft über den Verkauf – Kunden wollen sehen, nicht nur lesen. Marketing-Teams werten nutzergenerierte Bilder aus, um Trends zu erkennen, während Forscher Produktfotos analysieren, um Designveränderungen nachzuverfolgen.
Dabei lauern aber einige Stolpersteine:
- Dynamische Inhalte: Viele Seiten laden Bilder erst nach dem Scrollen oder Klicken – einfache Web-Scraper übersehen diese komplett.
- Paginierung und Endlos-Scroll: Produktgalerien erstrecken sich oft über viele Seiten, und die besten Image Crawler müssen „Weiter“-Buttons oder unendliches Scrollen automatisch meistern.
- Relevante Bilder filtern: Nicht jedes Bild ist nützlich – Werbung, Icons und Deko-Grafiken können das Ergebnis verfälschen.
- Integration: Nach dem Scraping müssen die Bilder (oder ihre URLs) möglichst ohne stundenlanges Copy-Paste in Excel, Sheets, Notion oder die eigene Datenbank landen.
Mit dem falschen Tool riskierst du unvollständige Daten, Zeitverlust oder sogar Website-Sperren. Der richtige Image Crawler dagegen spart dir Stunden, liefert präzisere Ergebnisse und hilft dir, bessere und schnellere Entscheidungen zu treffen.
So haben wir die besten Image Crawler Tools ausgewählt
Nicht jeder Image Crawler ist gleich. Bei der Auswahl habe ich auf folgende Punkte geachtet:
- Benutzerfreundlichkeit: Können auch Nicht-Techniker direkt loslegen? Muss man programmieren oder reicht ein Klick?
- Skalierbarkeit: Schafft das Tool hunderte oder tausende Seiten? Gibt es Cloud-Optionen für mehr Tempo?
- Genauigkeit & Flexibilität: Kommt es mit dynamischen, JavaScript-lastigen Seiten klar? Unterstützt es Unterseiten, Filter und eigene Logik?
- Integration & Export: Wie einfach lassen sich die Daten nach Excel, Google Sheets, Notion, Airtable oder in die eigene Datenbank exportieren?
- Preis-Leistung: Gibt es eine kostenlose Version? Ist das Tool für kleine Teams bezahlbar oder eher für große Unternehmen gedacht?
Außerdem habe ich die unterschiedlichen Nutzerbedürfnisse berücksichtigt – manche suchen eine No-Code-Lösung, andere wollen maximale Kontrolle, und Unternehmen brauchen vor allem Zuverlässigkeit und Compliance.
Hier sind meine Favoriten für die Top 5 Image Crawler Tools im Jahr 2025.
1. Thunderbit
Thunderbit ist meine erste Empfehlung für alle, die Bilder schnell, smart und unkompliziert extrahieren wollen. Als Mitgründer bin ich natürlich etwas voreingenommen – aber ich habe Thunderbit genau deshalb entwickelt, weil ich gesehen habe, wie Teams an veralteten Web-Scraper-Lösungen verzweifeln.
Was Thunderbit besonders macht:
- KI-gestützte Einfachheit: Einfach beschreiben, was du brauchst („alle Produktbilder und Preise erfassen“), und Thunderbits KI erledigt den Rest. Keine Selektoren, kein Code, kein Rätselraten.
- 2-Klick-Workflow: Mit „KI-Felder vorschlagen“ erkennt Thunderbit automatisch Bild-URLs, Titel und mehr. Ein Klick auf „Scrapen“ – fertig.
- Unterseiten-Scraping: Du brauchst Bilder von Detailseiten? Thunderbit kann jede Unterseite durchsuchen und alle Bilder extrahieren – ideal für E-Commerce, Immobilien oder Galerien.
- Dynamische Inhalte & Paginierung: Egal ob Endlos-Scroll, „Mehr laden“-Buttons oder JavaScript-Bilder – Thunderbit meistert alles im Browser- oder Cloud-Modus (Dokumentation).
- Sofort-Export: Übertrage Bilddaten (inklusive Bilddateien, nicht nur URLs) direkt nach Excel, Google Sheets, Airtable oder Notion.
- Kostenlose Bildextraktion: Für kleine Aufgaben (6–10 Seiten) sind Bildextraktion und Export kostenlos. Für größere Projekte gibt es ein faires Pay-per-Row-Modell – ohne versteckte Kosten.
Thunderbits wichtigste Funktionen für die Bilder-Extraktion:
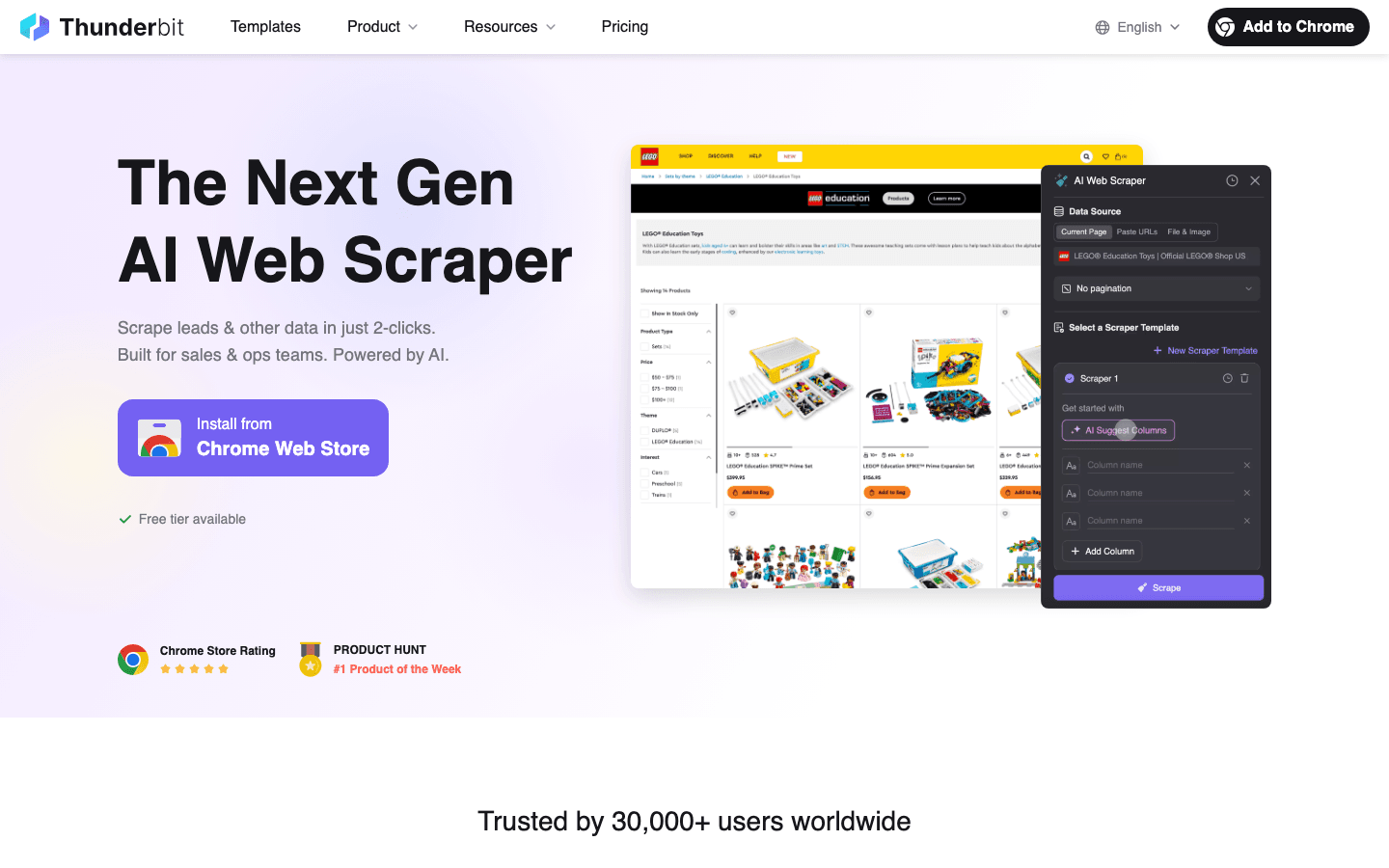
- KI-Felderkennung: Thunderbits KI scannt die Seite und schlägt passende Bildfelder vor – du musst nicht nach dem richtigen HTML-Tag suchen (Dokumentation).
- Automatisierung für Unterseiten & Paginierung: Bilder von Übersichtsseiten und Detailseiten in einem Durchgang extrahieren.
- Cloud- vs. Browser-Scraping: Cloud-Modus für Geschwindigkeit (bis zu 50 Seiten gleichzeitig), Browser-Modus für Logins oder komplexe JavaScript-Seiten.
- Export & Integration: Ein-Klick-Export nach Excel, Sheets, Notion oder Airtable. Bilder werden direkt in Notion/Airtable angezeigt – kein Nachladen nötig (Dokumentation).
- Mehrsprachigkeit: Thunderbit unterstützt 34 Sprachen und ist damit weltweit einsetzbar.
Für wen ist Thunderbit geeignet?
- Vertriebs-, Marketing- und Forschungsteams, die ohne Programmierung Ergebnisse wollen.
- Alle, die schnell Bilder von modernen, dynamischen Webseiten extrahieren möchten.
Preise: Kostenlos für bis zu 6–10 Seiten. Bezahlpläne ab 15 $/Monat für 500 Credits (Zeilen) – ideal für kleine Teams und skalierbar für größere Projekte.
Thunderbit kostenlos für Bilder testen
Du willst sehen, wie einfach Bilder-Crawling sein kann? Lade die Thunderbit Chrome-Erweiterung herunter und probiere es aus.
2. Scrapy
Scrapy ist das Allzweckwerkzeug für Entwickler im Web-Scraping. Open Source, Python-basiert und ideal für alle, die jeden einzelnen Schritt selbst anpassen wollen.
Was Scrapy besonders macht:
- Maximale Flexibilität: Eigene „Spiders“ in Python schreiben, Logins automatisieren, komplexes HTML parsen und gezielt Bilder (oder andere Daten) extrahieren.
- Hohe Performance: Dank asynchroner Architektur crawlt Scrapy tausende Seiten parallel und lädt Bilder gleichzeitig herunter – perfekt für große Projekte.
- Images Pipeline: Die eingebaute Images Pipeline lädt nicht nur Bild-URLs, sondern auch die Dateien selbst, erstellt Thumbnails und filtert nach Größe oder Format.
- Erweiterbar: Viele Plugins für Proxies, Logins und mehr. Große Community.
Scrapys Möglichkeiten für die Bilder-Extraktion:
- Individuelle Logik: Nur Bilder ab einer bestimmten Größe extrahieren? Duplikate überspringen? Alles per Code möglich.
- Integration: Export in eigene Datenbanken, Cloud-Speicher oder beliebige Formate.
- Open Source: Kostenlos nutzbar – vorausgesetzt, du bringst Python-Kenntnisse und Server mit.
Für wen ist Scrapy geeignet?
- Entwickler, Data Engineers und technische Teams, die volle Kontrolle wollen.
- Projekte, bei denen Scraping in größere Datenpipelines integriert werden soll.
Preise: Kostenlos (Open Source), aber Entwicklungs- und Infrastrukturaufwand nötig.
3. Octoparse
Octoparse ist ein visuelles No-Code-Web-Scraping-Tool, das Bilder-Extraktion für alle zugänglich macht – auch ohne Programmierkenntnisse.
Was Octoparse besonders macht:
- Point-and-Click-Oberfläche: Einfach auf die gewünschten Bilder klicken, Octoparse erkennt automatisch den Rest. Kein Code, kein XPath, keine Kopfschmerzen.
- Auto-Detection & Vorlagen: Die Auto-Detect-Funktion scannt Seiten und schlägt Bilder, Listen und mehr vor. Vorlagen für bekannte Seiten ermöglichen den Sofortstart.
- Paginierung & Endlos-Scroll: Mit wenigen Klicks „Nächste Seite“ oder Auto-Scroll hinzufügen.
- Cloud-Scraping & Zeitplanung: In den Bezahlplänen lassen sich Jobs in der Cloud ausführen, regelmäßig planen und große Datenmengen verarbeiten.
Octoparse-Workflow für die Bilder-Extraktion:
- Massen-Extraktion: Tausende Bild-URLs in Minuten extrahieren, mit Chrome-Erweiterung auch als Dateien herunterladen.
- Export-Optionen: Ergebnisse als CSV, Excel oder direkt in die Datenbank/API exportieren.
- Kostenloser Plan: Für kleine Aufgaben limitiert; Bezahlpläne ab ca. 119 $/Monat.
Für wen ist Octoparse geeignet?
- Nicht-technische Teams, Marketer, Forscher und kleine Unternehmen.
- Alle, die ohne Programmierung Bilder extrahieren möchten.
4. ParseHub
ParseHub ist ein weiteres visuelles Scraping-Tool, das besonders bei komplexen, dynamischen Webseiten punktet – etwa bei JavaScript-lastigen Seiten, Single-Page-Apps oder Seiten mit Bedingungen.
Was ParseHub besonders macht:
- Dynamische Inhalte: ParseHub kann mit AJAX-Inhalten, Pop-ups und mehrstufiger Navigation umgehen. Bilder, die erst nach Klick oder Scroll erscheinen, werden zuverlässig erfasst.
- Visuelles Scripting mit Logik: Bedingungen, Schleifen und Variablen lassen sich ohne Code in den Workflow einbauen – ideal für fortgeschrittene Nutzer.
- Multi-Daten-Extraktion: Bilder, Texte, Links und mehr in einem Projekt erfassen.
- Cloud-Ausführung & Zeitplanung: Jobs in der Cloud ausführen, regelmäßig planen und per API integrieren.
ParseHubs Stärken bei Bilddaten:
- Paginierung & Unterseiten: Bilder über mehrere Seiten oder aus Detailseiten extrahieren.
- Export: Download als CSV, Excel oder Anbindung an BI-Tools wie Tableau.
- Kostenloser Tarif: Bis zu 200 Seiten pro Durchlauf; Bezahlpläne ab ca. 189 $/Monat.
Für wen ist ParseHub geeignet?
- Nutzer, die ein No-Code-Tool für komplexe oder moderne Webseiten brauchen.
- Datenanalysten und Forscher, die mehr Kontrolle ohne Programmierung wollen.
5. Content Grabber
Content Grabber (auch bekannt als Sequentum Enterprise) ist die Schwergewichtslösung für Unternehmen, die große, wiederkehrende Scraping-Projekte mit hohen Compliance-Anforderungen stemmen.
Was Content Grabber besonders macht:
- Enterprise-Plattform: On-Premise-Software für Windows, entwickelt für große, geschäftskritische Scraping-Projekte.
- Visueller Editor + Scripting: Workflows visuell bauen, aber bei Bedarf mit C#/VB.NET-Skripten erweitern.
- Multi-Threading: Bilder von tausenden Seiten parallel herunterladen.
- Fehlerbehandlung & Zeitplanung: Integrierter Scheduler, Fehlerbehebung und Monitoring für zuverlässigen, unbeaufsichtigten Betrieb.
- Integration: Export in Datenbanken, APIs, Cloud-Speicher oder jedes gewünschte Format.
- Teamarbeit: Versionskontrolle, Benutzerrechte und zentrale Verwaltung für große Teams.
Content Grabbers Automatisierung für Bilder:
- Komplexe Seiten meistern: AJAX, JavaScript, Pop-ups, CAPTCHAs und mehr.
- Sicherheit & Compliance: Läuft auf eigener Infrastruktur – keine Daten verlassen das Unternehmen.
- Individuelle Preise: Meist eine größere Investition, aber für Unternehmen mit dauerhaftem, großem Bedarf gerechtfertigt.
Für wen ist Content Grabber geeignet?
- Unternehmen, Datenanbieter und alle, die große, wiederkehrende Bild- und Datenextraktionen betreiben.
- Teams mit höchsten Anforderungen an Zuverlässigkeit, Compliance und Integration.
Schnellvergleich: Die besten Image Crawler im Überblick
| Tool | Stärken | Ideal für | Preis (ca.) |
|---|---|---|---|
| Thunderbit | KI-gestützt, 2-Klick-Setup, Unterseiten/Paginierung, Sofort-Export | No-Coder, schnelle Ergebnisse, KMUs | Kostenlos für 6–10 Seiten, dann ab $15/Monat (Pay-per-Row) |
| Scrapy | Python-basiert, flexibel, skalierbar, lädt Bilder direkt herunter | Entwickler, individuelle Projekte, große Datenmengen | Kostenlos (Open Source) |
| Octoparse | No-Code, visuell, Auto-Detect, Vorlagen, Cloud-Scraping | Nicht-technische Teams, Marketing, Forschung | Kostenloser Plan, ab ~$119/Monat |
| ParseHub | Visuell, für dynamische Seiten, Logik/Bedingungen, Cloud-Planung | Komplexe Seiten, Analysten, No-Code-Power-User | Kostenloser Tarif, ab ~$189/Monat |
| Content Grabber | Enterprise, visuell + Scripting, Multi-Threading, On-Prem | Unternehmen, große Datenmengen, Compliance | Individuelle/Enterprise-Preise |
Welcher Image Crawler passt zu deinem Unternehmen?
Wie du jede Website mit KI scrapen kannst Get Started Free
Welches Tool solltest du wählen? Hier meine Einschätzung:
- Du willst schnelle Ergebnisse ohne Setup? Dann ist Thunderbit die einfachste Lösung, besonders für den Export nach Sheets, Notion oder Airtable.
- Du hast Entwicklerressourcen und willst volle Kontrolle? Scrapy ist unschlagbar für individuelle, große Projekte.
- Keine Programmierkenntnisse, aber visuelle Workflows gewünscht? Octoparse ist ideal für kleine bis mittlere Teams, ParseHub für komplexe, dynamische Seiten.
- Du betreibst Scraping im großen Stil? Content Grabber ist für dich gemacht – für Big Data, Compliance und Automatisierung.
Behalte immer die technischen Fähigkeiten deines Teams im Blick, dazu die Komplexität der Zielseiten und wie oft du Scrapes durchführen willst. Die meisten Tools bieten kostenlose Testphasen – probiere sie aus und finde heraus, was am besten zu deinem Workflow passt.
Fazit: Effiziente Bilder-Extraktion mit dem richtigen Image Crawler
Visuelle Daten werden immer wichtiger. Ob du Wettbewerber beobachtest, KI-Modelle trainierst oder Produktkataloge aktuell hältst – mit dem passenden Image Crawler wird aus tagelanger Handarbeit ein automatisierter Prozess in Minuten. Tools wie Thunderbit machen diese Möglichkeiten für alle zugänglich, nicht nur für Entwickler oder Großunternehmen.
Jetzt mit Thunderbit Bilder scrapen
Bereit, deine Bildextraktion auf ein neues Niveau zu bringen? Teste Thunderbit kostenlos oder probiere eines der anderen Top-Tools aus. Noch mehr Tipps und Praxisbeispiele findest du im Thunderbit Blog.
Häufige Fragen (FAQ)
1. Was ist ein Image Crawler und warum brauchen Unternehmen ihn?
Ein Image Crawler ist ein Tool, das automatisch Bilder (oder deren URLs) von Webseiten extrahiert. Unternehmen nutzen Image Crawler, um Produktfotos zu sammeln, Wettbewerber zu beobachten, KI-Modelle zu trainieren und Content-Prozesse zu beschleunigen – das spart Zeit und verbessert die Datenqualität.
2. Was macht Thunderbit bei der Bilder-Extraktion einfacher als andere Tools?
Thunderbit nutzt KI, um Bilder und andere Felder automatisch zu erkennen. So kannst du mit nur zwei Klicks einen Scrape starten – ganz ohne Code oder technische Einrichtung. Außerdem werden Unterseiten durchsucht, dynamische Inhalte verarbeitet und die Daten direkt nach Excel, Sheets, Notion oder Airtable exportiert.
3. Kann ich diese Tools auch ohne Programmierkenntnisse nutzen?
Definitiv. Thunderbit, Octoparse und ParseHub sind speziell für Nicht-Programmierer entwickelt und bieten visuelle Oberflächen sowie KI-gestützte Funktionen. Scrapy richtet sich an Python-Profis, während Content Grabber für IT-Teams in Unternehmen gedacht ist.
4. Worauf sollte ich bei der Auswahl eines Image Crawlers achten?
Überlege dir, wie technisch dein Team ist, wie komplex die Zielseiten sind (dynamische Inhalte, Logins etc.), wie viele Daten du brauchst und wie du die Ergebnisse exportieren oder integrieren willst. Auch der Preis spielt eine Rolle – manche Tools sind kostenlos, andere richten sich an Unternehmen.
5. Ist es legal, Bilder von jeder Website zu scrapen?
Prüfe immer die Nutzungsbedingungen der Website und beachte das Urheberrecht. Extrahiere nur öffentlich zugängliche Daten und vermeide das Sammeln persönlicher oder sensibler Informationen ohne Erlaubnis. Verantwortungsvolles, ethisches Scraping ist wichtig, um rechtliche Probleme zu vermeiden.
Du willst Thunderbit live erleben? Lade die Chrome-Erweiterung herunter und probiere das Scrapen von Bildern auf deiner Lieblingsseite. Für weitere Tipps und Anleitungen schau im Thunderbit Blog vorbei.
Mehr erfahren Die 10 besten kostenlosen Website Crawler 2025 Top 10 automatisierte Web Scraping Tools 2025 Die 12 besten kostenlosen Data Scraper Tools 2025 Top 10 KI-Web-Scraper für mehr Produktivität 2025
Thunderbit KI Image Scraper testen Get Started Free




