

Defekte Links. Verwaiste Seiten. Eine „Test“-Seite aus dem Jahr 2019, die Google aus irgendeinem Grund indexiert hat. Wer eine Website betreut, kennt diesen Frust nur zu gut.
Ein guter Crawler erkennt all das – und baut eine Karte Ihrer gesamten Website, damit Sie Probleme gezielt beheben können. Doch die meisten werfen „Web-Crawler“ und „Web-Scraper“ in einen Topf. Dabei sind das zwei verschiedene Dinge.
Ich habe 10 kostenlose Crawler auf echten Websites getestet. Einige sind super für SEO-Audits. Andere eignen sich besser für die Datenerfassung. Hier erfahren Sie, was funktioniert hat – und was nicht.
Was ist ein Website-Crawler? Die Grundlagen erklärt
Zuerst einmal ganz klar: Ein Website-Crawler ist nicht dasselbe wie ein Web-Scraper. Ja, die Begriffe werden oft durcheinandergebracht – aber sie erledigen völlig unterschiedliche Aufgaben. Stellen Sie sich einen Crawler als Kartografen Ihrer Website vor: Er schaut sich jede Ecke an, folgt jedem Link und baut eine vollständige Karte aller Seiten. Seine Aufgabe ist Entdeckung: URLs finden, die Struktur der Website erfassen und Inhalte indexieren. Genau das machen Suchmaschinen wie Google mit ihren Bots – und SEO-Tools nutzen es, um den Zustand Ihrer Website zu prüfen (Thunderbit Blog: What Is a Web Crawler?).
Ein Web-Scraper hingegen ist der Datenjäger. Ihm ist die gesamte Karte egal – er will nur die brauchbaren Infos: Produktpreise, Firmennamen, Bewertungen, E-Mails, was auch immer. Scraper ziehen gezielt einzelne Felder aus den Seiten heraus, die Crawler gefunden haben (Thunderbit Blog: How to Web Crawl a Site?).
Ein einfacher Vergleich:
- Crawler: Die Person, die in jedem Gang eines Supermarkts alles inventarisiert.
- Scraper: Die Person, die direkt zum Kaffeeregal geht und den Preis jeder Bio-Mischung notiert.
Warum ist das wichtig? Wenn Sie einfach nur alle Seiten Ihrer Website finden wollen – etwa für ein SEO-Audit –, brauchen Sie einen Crawler. Wenn Sie alle Produktpreise von der Website eines Mitbewerbers auslesen möchten, brauchen Sie einen Scraper – oder am besten ein Tool, das beides kann.
Warum einen Online-Web-Crawler nutzen? Wichtige Geschäftsvorteile
Warum also überhaupt ein Web-Crawler? Ganz einfach: Das Web wird nicht kleiner. Tatsächlich nutzen über 54 % der Enterprise-Marken spezialisierte Crawling-Plattformen, um ihre Websites zu optimieren, und manche SEO-Tools crawlen täglich 7 Milliarden Seiten.
Das kann ein Crawler für Sie leisten:
- SEO-Audits: Defekte Links, fehlende Titel, doppelte Inhalte, verwaiste Seiten und mehr finden (SEO.ai).
- Linkprüfung & QA: 404-Fehler und Redirect-Schleifen erkennen, bevor es Ihre Nutzer tun (Screaming Frog).
- Sitemap-Erstellung: XML-Sitemaps automatisch für Suchmaschinen und Planung generieren (PowerMapper).
- Content-Inventar: Eine Liste aller Seiten, ihrer Hierarchie und Metadaten erstellen.
- Compliance & Barrierefreiheit: Jede Seite auf WCAG-, SEO- und rechtliche Anforderungen prüfen (SiteOne Crawler).
- Performance & Sicherheit: Langsame Seiten, zu große Bilder oder Sicherheitsprobleme markieren (SiteOne Crawler).
- Daten für KI & Analyse: Gecrawlte Daten in Analyse- oder KI-Tools einspeisen (Thunderbit Blog: Crawl4AI Review).
Hier ist eine kurze Tabelle, die Anwendungsfälle passenden Rollen zuordnet:
| Anwendungsfall | Ideal für | Nutzen / Ergebnis |
|---|---|---|
| SEO- & Website-Audits | Marketing, SEO, kleine Unternehmen | Technische Probleme finden, Struktur optimieren, Rankings verbessern |
| Content-Inventar & QA | Content Manager, Webadmins | Inhalte prüfen oder migrieren, defekte Links/Bilder erkennen |
| Lead-Generierung (Scraping) | Vertrieb, Business Development | Prospektion automatisieren, CRM mit neuen Leads befüllen |
| Wettbewerbsanalyse | E-Commerce, Produktmanager | Preise, neue Produkte und Lagerbestände von Mitbewerbern überwachen |
| Sitemap- & Struktur-Klonen | Entwickler, DevOps, Berater | Website-Struktur für Relaunches oder Backups duplizieren |
| Content-Aggregation | Forscher, Medien, Analysten | Daten aus mehreren Websites für Analysen oder Trendbeobachtung sammeln |
| Marktforschung | Analysten, KI-Training-Teams | Große Datensätze für Analysen oder KI-Training erfassen |
(Thunderbit Blog: How to Web Crawl a Site?)
Wie wir die besten kostenlosen Website-Crawler ausgewählt haben
Ich habe viele späte Nächte damit verbracht – und mehr Kaffee getrunken, als ich zugeben möchte –, Crawler-Tools zu durchforsten, Dokus zu lesen und Test-Crawls zu starten. Darauf habe ich geachtet:
- Technische Leistungsfähigkeit: Kommt das Tool mit modernen Websites klar (JavaScript, Logins, dynamische Inhalte)?
- Benutzerfreundlichkeit: Ist es auch für Nicht-Techniker geeignet, oder braucht man Kommandozeilen-Know-how?
- Limitierungen im Gratis-Tarif: Ist es wirklich kostenlos oder nur eine Lockvogel-Version?
- Online-Zugänglichkeit: Cloud-Tool, Desktop-App oder Code-Bibliothek?
- Besondere Funktionen: Kann es etwas Spezielles – etwa KI-Extraktion, visuelle Sitemaps oder ereignisgesteuertes Crawling?
Ich habe jedes Tool getestet, Nutzerfeedback geprüft und Funktionen direkt verglichen. Wenn mich ein Tool dazu gebracht hätte, den Laptop aus dem Fenster zu werfen, hat es es nicht in die Liste geschafft.
Schneller Vergleich: 10 der besten kostenlosen Website-Crawler auf einen Blick
| Tool & Typ | Kernfunktionen | Bestes Einsatzszenario | Technische Anforderungen | Details zum Gratis-Tarif |
|---|---|---|---|---|
| BrightData (Cloud/API) | Enterprise-Crawling, Proxies, JavaScript-Rendering, CAPTCHA-Lösung | Datenerfassung im großen Stil | Etwas technisches Know-how hilfreich | Gratis-Test: 3 Scraper, je 100 Datensätze (insgesamt ca. 300 Datensätze) |
| Crawlbase (Cloud/API) | API-Crawling, Anti-Bot, Proxies, JavaScript-Rendering | Entwickler, die Backend-Crawling-Infrastruktur brauchen | API-Integration | Kostenlos: ca. 5.000 API-Aufrufe für 7 Tage, danach 1.000/Monat |
| ScraperAPI (Cloud/API) | Proxy-Rotation, JavaScript-Rendering, asynchrones Crawling, vorgefertigte Endpunkte | Entwickler, Preisüberwachung, SEO-Daten | Minimale Einrichtung | Kostenlos: 5.000 API-Aufrufe für 7 Tage, danach 1.000/Monat |
| Diffbot Crawlbot (Cloud) | KI-Crawling + Extraktion, Knowledge Graph, JavaScript-Rendering | Strukturierte Daten im großen Maßstab, KI/ML | API-Integration | Kostenlos: 10.000 Credits/Monat (ca. 10.000 Seiten) |
| Screaming Frog (Desktop) | SEO-Audit, Link-/Meta-Analyse, Sitemap, benutzerdefinierte Extraktion | SEO-Audits, Website-Management | Desktop-App, GUI | Kostenlos: 500 URLs pro Crawl, nur Basisfunktionen |
| SiteOne Crawler (Desktop) | SEO, Performance, Barrierefreiheit, Sicherheit, Offline-Export, Markdown | Entwickler, QA, Migration, Dokumentation | Desktop/CLI, GUI | Kostenlos & Open Source, 1.000 URLs im GUI-Report (konfigurierbar) |
| Crawljax (Java, Open Source) | Ereignisgesteuertes Crawling für JavaScript-lastige Websites, statischer Export | Entwickler, QA für dynamische Web-Apps | Java, CLI/Konfiguration | Kostenlos & Open Source, keine Limits |
| Apache Nutch (Java, Open Source) | Verteilt, plugin-basiert, Hadoop-Integration, eigene Suche | Eigene Suchmaschinen, Crawling im großen Stil | Java, Kommandozeile | Kostenlos & Open Source, nur Infrastrukturkosten |
| YaCy (Java, Open Source) | Peer-to-Peer-Crawling & Suche, Datenschutz, Web-/Intranet-Indexierung | Private Suche, Dezentralisierung | Java, Browser-Oberfläche | Kostenlos & Open Source, keine Limits |
| PowerMapper (Desktop/SaaS) | Visuelle Sitemaps, Barrierefreiheit, QA, Browser-Kompatibilität | Agenturen, QA, visuelles Mapping | GUI, leicht zu bedienen | Gratis-Test: 30 Tage, 100 Seiten (Desktop) oder 10 Seiten (online) pro Scan |
BrightData: Cloud-Website-Crawler für Enterprise-Ansprüche

BrightData ist der „schwere Brocken“ unter den Crawling-Tools. Die Cloud-Plattform bringt ein riesiges Proxy-Netzwerk, JavaScript-Rendering, CAPTCHA-Lösung und eine IDE für individuelle Crawls mit. Wer Daten im großen Stil sammelt – etwa Preisbeobachtung auf hunderten E-Commerce-Seiten –, bekommt mit BrightData eine Infrastruktur, die kaum zu schlagen ist (aimultiple.com).
Stärken:
- Kommt mit schwierigen Websites und Anti-Bot-Schutz zurecht
- Skalierbar für Enterprise-Anforderungen
- Vorgefertigte Vorlagen für häufige Zielseiten
Einschränkungen:
- Kein dauerhaft kostenloser Tarif (nur Testphase: 3 Scraper, je 100 Datensätze)
- Für einfache Audits oft zu groß dimensioniert
- Für nicht-technische Nutzer braucht es etwas Einarbeitung
Wenn Sie das Web im großen Maßstab crawlen müssen, ist BrightData wie ein Formel-1-Wagen zum Ausleihen. Nur bitte nicht erwarten, dass er nach der Probefahrt gratis bleibt (BrightData Pricing).
Crawlbase: API-basierter Free-Web-Crawler für Entwickler

Crawlbase (früher ProxyCrawl) setzt ganz auf programmatisches Crawling. Sie geben die URL per API ein, und das Tool liefert das HTML zurück – inklusive Proxies, Geo-Targeting und CAPTCHA-Handling im Hintergrund (Capterra).
Stärken:
- Sehr hohe Erfolgsraten (99 %+)
- Kommt mit JavaScript-lastigen Seiten klar
- Gut in eigene Apps oder Workflows integrierbar
Einschränkungen:
- Benötigt API- oder SDK-Integration
- Gratis-Tarif: ca. 5.000 API-Aufrufe für 7 Tage, danach 1.000/Monat
Wenn Sie als Entwickler groß skalieren möchten – vielleicht sogar Crawling mit Scraping kombinieren –, ohne Proxies selbst zu verwalten, ist Crawlbase eine solide Wahl (Crawlbase Pricing).
ScraperAPI: Dynamisches Web-Crawling einfacher machen

ScraperAPI ist die „Hol mir einfach die Seite“-API. Sie geben eine URL an, das Tool kümmert sich um Proxies, Headless Browser und Anti-Bot-Schutz und liefert Ihnen das HTML zurück – bei manchen Seiten sogar strukturierte Daten. Besonders stark ist es bei dynamischen Seiten, und der Gratis-Tarif ist großzügig (ScraperAPI Pricing).
Stärken:
- Für Entwickler extrem leicht zu nutzen (nur ein API-Call)
- Kann CAPTCHAs, IP-Sperren und JavaScript bewältigen
- Kostenlos: 5.000 API-Aufrufe für 7 Tage, danach 1.000/Monat
Einschränkungen:
- Keine visuellen Crawl-Berichte
- Wenn Sie Links verfolgen möchten, müssen Sie die Crawl-Logik selbst skripten
Wenn Sie Web-Crawling in wenigen Minuten in Ihre Codebasis einbauen wollen, ist ScraperAPI eine sehr naheliegende Wahl.
Diffbot Crawlbot: Automatische Erkennung von Website-Strukturen

Diffbot Crawlbot wird dort spannend, wo es intelligent werden soll. Es crawlt nicht nur – es nutzt KI, um Seiten zu klassifizieren und strukturierte Daten (Artikel, Produkte, Events usw.) als JSON zu extrahieren. Fast wie ein Roboter-Praktikant, der tatsächlich versteht, was er liest (Diffbot Free Plan).
Stärken:
- KI-gestützte Extraktion, nicht nur Crawling
- Kommt mit JavaScript und dynamischen Inhalten zurecht
- Kostenlos: 10.000 Credits/Monat (ca. 10.000 Seiten)
Einschränkungen:
- Eher für Entwickler gedacht (API-Integration)
- Kein visuelles SEO-Tool – stärker auf Datenprojekte ausgerichtet
Wenn Sie strukturierte Daten in großem Umfang brauchen, besonders für KI oder Analytics, ist Diffbot ein echtes Kraftpaket.
Screaming Frog: Kostenloser Desktop-SEO-Crawler

Screaming Frog ist der Klassiker unter den Desktop-Crawlern für SEO-Audits. In der Gratisversion können Sie bis zu 500 URLs pro Scan crawlen und bekommen alles, was Sie brauchen: defekte Links, Meta-Tags, doppelte Inhalte, Sitemaps und mehr (Screaming Frog User Guide).
Stärken:
- Schnell, gründlich und in der SEO-Welt etabliert
- Kein Coding nötig – einfach URL eingeben und loslegen
- Kostenlos bis 500 URLs pro Crawl
Einschränkungen:
- Nur als Desktop-Version (keine Cloud-Version)
- Erweiterte Funktionen wie JavaScript-Rendering und Planung brauchen eine kostenpflichtige Lizenz
Wer SEO ernst nimmt, kommt an Screaming Frog kaum vorbei – nur sollte man nicht erwarten, damit eine 10.000-Seiten-Website gratis zu crawlen.
SiteOne Crawler: Statischer Export und Dokumentation

SiteOne Crawler ist das Schweizer Taschenmesser für technische Audits. Das Tool ist Open Source, plattformübergreifend und kann Ihre Website crawlen, prüfen und sogar als Markdown exportieren – ideal für Dokumentation oder Offline-Nutzung (SiteOne Crawler).
Stärken:
- Deckt SEO, Performance, Barrierefreiheit und Sicherheit ab
- Exportiert Websites für Archivierung oder Migration
- Kostenlos & Open Source, ohne Nutzungslimits
Einschränkungen:
- Technischer als manche GUI-Tools
- Der Audit-Report in der GUI ist standardmäßig auf 1.000 URLs begrenzt (konfigurierbar)
Wenn Sie Entwickler, QA oder Berater sind und tiefere Einblicke suchen – und Open Source mögen –, ist SiteOne ein echter Geheimtipp.
Crawljax: Open-Source-Java-Web-Crawler für dynamische Seiten
Crawljax ist ein Spezialist: Er ist darauf ausgelegt, moderne, JavaScript-lastige Web-Apps durch Simulation von Nutzerinteraktionen zu crawlen – also Klicks, Formularausfüllungen und mehr. Das Tool arbeitet ereignisgesteuert und kann sogar eine statische Version einer dynamischen Website ausgeben (Wikipedia: Crawljax).
Stärken:
- Ideal für SPAs und AJAX-lastige Websites
- Open Source und erweiterbar
- Keine Nutzungslimits
Einschränkungen:
- Erfordert Java sowie etwas Programmierung/Konfiguration
- Nicht für Nicht-Techniker geeignet
Wenn Sie eine React- oder Angular-App so crawlen möchten, wie ein echter Nutzer sie bedient, ist Crawljax genau richtig.
Apache Nutch: Skalierbarer verteilter Website-Crawler

Apache Nutch ist der Urvater unter den Open-Source-Crawlern. Das Tool wurde für riesige, verteilte Crawls entwickelt – etwa, wenn Sie Ihre eigene Suchmaschine aufbauen oder Millionen von Seiten indexieren möchten (Martechvibe).
Stärken:
- Skaliert mit Hadoop auf Milliarden von Seiten
- Stark konfigurierbar und erweiterbar
- Kostenlos & Open Source
Einschränkungen:
- Steile Lernkurve (Java, Kommandozeile, Konfiguration)
- Nicht für kleine Websites oder Gelegenheitsnutzer
Wenn Sie das Web im großen Stil crawlen wollen und keine Scheu vor der Kommandozeile haben, ist Nutch Ihr Werkzeug.
YaCy: Peer-to-Peer-Web-Crawler und Suchmaschine
YaCy ist ein ungewöhnlicher, dezentraler Crawler und eine Suchmaschine. Jede Instanz crawlt und indexiert Websites, und Sie können sich mit einem Peer-to-Peer-Netzwerk verbinden, um Indizes mit anderen zu teilen (TechRadar: YaCy).
Stärken:
- Datenschutzorientiert, kein zentraler Server
- Gut für private oder interne Suchlösungen
- Kostenlos & Open Source
Einschränkungen:
- Die Ergebnisse hängen von der Abdeckung des Netzwerks ab
- Etwas Einrichtung nötig (Java, Browser-Oberfläche)
Wenn Sie sich für Dezentralisierung interessieren oder Ihre eigene Suchmaschine bauen möchten, ist YaCy eine spannende Option.
PowerMapper: Visueller Sitemap-Generator für UX und QA

PowerMapper konzentriert sich auf die visuelle Darstellung der Website-Struktur. Es crawlt Ihre Website und erzeugt interaktive Sitemaps. Außerdem prüft es Barrierefreiheit, Browser-Kompatibilität und grundlegende SEO-Aspekte (Slickplan Review).
Stärken:
- Visuelle Sitemaps sind ideal für Agenturen und Designer
- Prüft Barrierefreiheit und Compliance
- Einfache GUI, keine technischen Kenntnisse nötig
Einschränkungen:
- Nur Testversion (30 Tage, 100 Seiten Desktop / 10 Seiten online pro Scan)
- Vollversion kostenpflichtig
Wenn Sie Kunden eine Sitemap zeigen oder Compliance prüfen müssen, ist PowerMapper ein praktisches Tool.
Das richtige kostenlose Crawling-Tool für Ihre Anforderungen wählen
Bei so vielen Optionen: Wie entscheidet man sich? Hier meine Kurzempfehlung:
- Für SEO-Audits: Screaming Frog (kleine Websites), PowerMapper (visuell), SiteOne (tiefe Audits)
- Für dynamische Web-Apps: Crawljax
- Für große oder individuelle Suchprojekte: Apache Nutch, YaCy
- Für Entwickler mit API-Zugriff: Crawlbase, ScraperAPI, Diffbot
- Für Dokumentation oder Archivierung: SiteOne Crawler
- Für Enterprise-Anforderungen mit Testphase: BrightData, Diffbot
Wichtige Kriterien:
- Skalierbarkeit: Wie groß ist Ihre Website oder Ihr Crawl-Job?
- Benutzerfreundlichkeit: Können Sie mit Code umgehen, oder bevorzugen Sie Klick-Oberflächen?
- Datenexport: Brauchen Sie CSV, JSON oder Integrationen mit anderen Tools?
- Support: Gibt es eine Community oder Hilfedokumentation, wenn Sie nicht weiterkommen?
Wenn Web-Crawling auf Web-Scraping trifft: Warum Thunderbit die intelligentere Wahl ist
Daten von jeder Website mit KI extrahieren Get Started Free
Die Realität ist: Die meisten Leute crawlen Websites nicht einfach, um hübsche Karten zu erstellen. Das eigentliche Ziel ist meist, strukturierte Daten zu bekommen – seien es Produktlisten, Kontaktdaten oder Content-Inventare. Genau hier kommt Thunderbit ins Spiel.
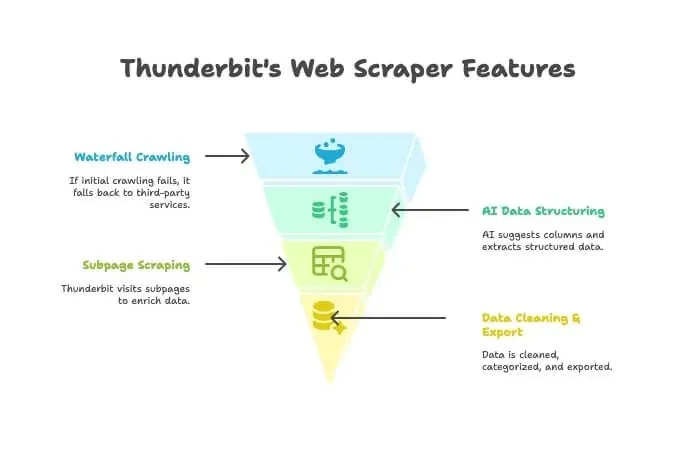
Thunderbit ist nicht nur ein Crawler oder ein Scraper – es ist eine KI-gestützte Chrome-Erweiterung, die beides kombiniert. So funktioniert es:
- KI-Crawler: Thunderbit erkundet die Website wie ein Crawler.
- Waterfall Crawling: Wenn Thunderbits eigene Engine eine Seite nicht erreicht – etwa wegen eines harten Anti-Bot-Schutzes –, wechselt es automatisch auf Drittanbieter-Crawling-Services. Ganz ohne manuelle Einrichtung.
- KI-Datenstrukturierung: Sobald das HTML vorliegt, schlägt Thunderbits KI die passenden Spalten vor und extrahiert strukturierte Daten (Namen, Preise, E-Mails usw.) – ganz ohne Selector-Programmierung.
- Subpage-Scraping: Sie brauchen Details von jeder Produktseite? Thunderbit kann automatisch jede Unterseite besuchen und Ihre Tabelle anreichern.
- Datenbereinigung & Export: Es kann Daten zusammenfassen, kategorisieren, übersetzen und mit einem Klick nach Excel, Google Sheets, Airtable oder Notion exportieren.
- No-Code-Einfachheit: Wenn Sie einen Browser bedienen können, können Sie auch Thunderbit nutzen. Kein Coding, keine Proxies, kein Stress.
Wann sollten Sie Thunderbit statt eines klassischen Crawlers verwenden?
- Wenn Ihr Ziel eine saubere, nutzbare Tabelle ist – nicht nur eine URL-Liste.
- Wenn Sie den gesamten Prozess automatisieren möchten (crawlen, extrahieren, bereinigen, exportieren) – alles an einem Ort.
- Wenn Ihnen Zeit und Nerven wichtig sind.
Sie können Thunderbits Chrome-Erweiterung hier herunterladen und selbst sehen, warum so viele Business-Anwender umsteigen.
Thunderbit kostenlos testen – AI Web Scraper
Fazit: Das Maximum aus kostenlosen Website-Crawlern herausholen
Was ist Data Scraping und wie funktioniert es? Get Started Free
Website-Crawler haben enorme Fortschritte gemacht. Ob Sie Marketingverantwortlicher, Entwickler oder einfach jemand sind, der seine Website gesund halten möchte – es gibt ein kostenloses (oder zumindest kostenlos testbares) Tool für Sie. Von Enterprise-Plattformen wie BrightData und Diffbot über Open-Source-Perlen wie SiteOne und Crawljax bis hin zu visuellen Mapping-Tools wie PowerMapper: Die Auswahl war noch nie so groß.
Wenn Sie aber einen intelligenteren und stärker integrierten Weg suchen, um von „Ich brauche diese Daten“ zu „Hier ist meine Tabelle“ zu kommen, sollten Sie Thunderbit ausprobieren. Es wurde für Business-Nutzer entwickelt, die Ergebnisse wollen – nicht bloß Berichte.
Bereit zum Crawlen? Laden Sie ein Tool herunter, starten Sie einen Scan und finden Sie heraus, was Sie bisher übersehen haben. Und wenn Sie in zwei Klicks von Crawling zu verwertbaren Daten wechseln möchten, sehen Sie sich Thunderbit an.
Weitere fundierte Analysen und praktische Anleitungen finden Sie im Thunderbit Blog.
Website-Daten mit KI in 2 Klicks extrahieren
AI Web Scraper testen Get Started Free
FAQ
Was ist der Unterschied zwischen einem Website-Crawler und einem Web-Scraper?
Ein Crawler entdeckt und kartiert alle Seiten einer Website (also quasi ein Inhaltsverzeichnis). Ein Scraper extrahiert gezielte Datenfelder (wie Preise, E-Mails oder Bewertungen) aus diesen Seiten. Crawler finden, Scraper holen die Daten (Thunderbit Blog: What Is a Web Crawler?).
Welcher kostenlose Web-Crawler eignet sich am besten für Nicht-Techniker?
Für kleine Websites und SEO-Audits ist Screaming Frog sehr benutzerfreundlich. Für visuelle Karten ist PowerMapper während der Testphase gut geeignet. Thunderbit ist am einfachsten, wenn Ihr Ziel strukturierte Daten sind und Sie eine No-Code-Lösung im Browser möchten.
Gibt es Websites, die Web-Crawler blockieren?
Ja – manche Websites nutzen robots.txt oder Anti-Bot-Maßnahmen wie CAPTCHAs oder IP-Sperren, um Crawler zu blockieren. Tools wie ScraperAPI, Crawlbase und Thunderbit (mit Waterfall Crawling) können das oft umgehen. Crawlen Sie aber immer verantwortungsvoll und beachten Sie die Regeln der jeweiligen Website (BrightData Pricing).
Gibt es bei kostenlosen Website-Crawlern Seiten- oder Funktionslimits?
Bei den meisten ja. Die kostenlose Version von Screaming Frog ist zum Beispiel auf 500 URLs pro Crawl begrenzt; die Testversion von PowerMapper auf 100 Seiten. API-basierte Tools haben oft monatliche Kreditlimits. Open-Source-Tools wie SiteOne oder Crawljax haben in der Regel keine harten Grenzen – begrenzt sind Sie dort vor allem durch Ihre Hardware.
Ist die Nutzung eines Web-Crawlers legal und datenschutzkonform?
Das Crawlen öffentlich zugänglicher Webseiten ist grundsätzlich legal, aber prüfen Sie immer die Nutzungsbedingungen und robots.txt der Website. Crawlen Sie niemals private oder passwortgeschützte Daten ohne Erlaubnis, und beachten Sie beim Extrahieren personenbezogener Daten die Datenschutzgesetze (Crawlbase Guide).




