

Webdaten sind heute die Standardgrundlage für Vertrieb, Marketing und Operations. Wenn du noch alles per Copy-and-paste machst, bist du längst ins Hintertreffen geraten.
Das Problem bei „kostenlosen“ Scraping-Tools: Die meisten sind in Wahrheit gar nicht wirklich gratis. Oft sind es nur Testversionen mit harten Grenzen – oder die Funktionen, die du wirklich brauchst, stecken hinter einer Paywall.
Ich habe 12 Tools getestet, um herauszufinden, welche sich mit dem Gratis-Tarif wirklich produktiv einsetzen lassen. Dafür habe ich Google-Maps-Listings, dynamische Seiten hinter Logins und PDFs per data scraper gezogen. Manche haben richtig abgeliefert. Andere haben mir schlicht den ganzen Nachmittag geklaut.
Hier kommt die ehrliche Einordnung – angefangen mit den Tools, die ich wirklich empfehlen würde.
Warum kostenlose Scraper heute wichtiger sind als je zuvor
Seien wir ehrlich: 2026 ist web scraping längst nicht mehr nur etwas für Hacker oder Data Scientists. Für moderne Unternehmen gehört es inzwischen fest dazu – und die Zahlen sprechen für sich. Der Markt für Web-Scraping-Software erreichte 1,01 Milliarden US-Dollar im Jahr 2024 und soll sich bis 2032 mehr als verdoppeln. Warum? Weil heute von Vertriebsteams bis zu Immobilienmaklern alle Webdaten nutzen, um sich einen Vorsprung zu verschaffen.
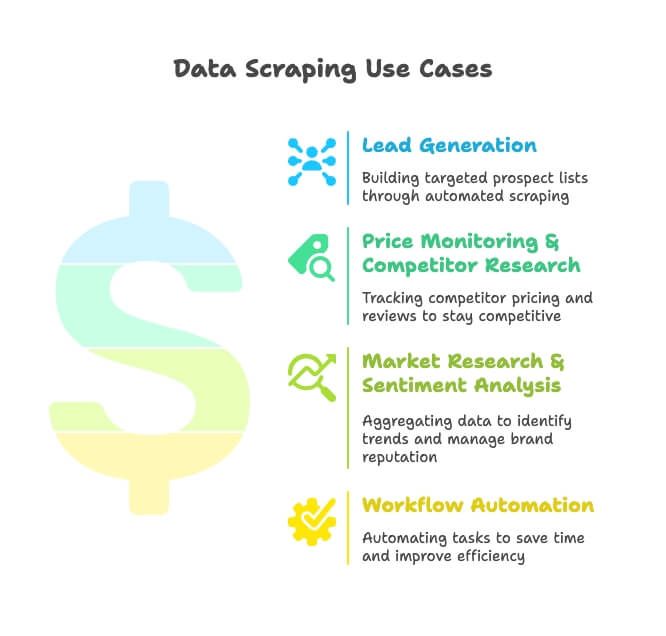
- Lead-Generierung: Vertriebsteams scrapen Verzeichnisse, Google Maps und Social Media, um gezielte Prospect-Listen aufzubauen – Schluss mit manueller Suche.
- Preisüberwachung & Wettbewerbsanalyse: E-Commerce- und Retail-Teams beobachten Produkte, Preise und Bewertungen der Konkurrenz, um wettbewerbsfähig zu bleiben (und ja, 82 % der E-Commerce-Unternehmen scrapen genau aus diesem Grund).
- Marktforschung & Sentiment-Analyse: Marketingteams bündeln Bewertungen, News und Social Buzz, um Trends zu erkennen und den Markenruf im Blick zu behalten.
- Workflow-Automatisierung: Operations-Teams automatisieren alles – von Bestandsprüfungen bis hin zu planmäßigen Reports – und sparen so jede Woche Stunden.
Und noch eine spannende Zahl: Unternehmen, die KI-gestützte Web-Scraper einsetzen, sparen im Vergleich zu manuellen Methoden 30–40 % ihrer Zeit. Das ist nicht nur ein bisschen Zeitgewinn – das ist der Unterschied zwischen Feierabend um 18 Uhr oder erst um 21 Uhr.
So haben wir die besten kostenlosen Data-Scraper ausgewählt
Ich habe schon viele „beste Web-Scraper“-Listen gesehen, die im Grunde nur Marketingtext wiederkäuen. Hier nicht. Für diese Übersicht habe ich auf Folgendes geachtet:
- Echte Nutzbarkeit im Gratis-Tarif: Kann man damit wirklich arbeiten, oder ist es nur ein Lockangebot?
- Bedienbarkeit: Kommt auch jemand ohne Coding schnell zu Ergebnissen, oder braucht man quasi einen PhD in Regex?
- Unterstützte Webseitentypen: Statische Seiten, dynamische Inhalte, Pagination, Login-Bereiche, PDFs, Social Media – deckt das Tool echte Praxisfälle ab?
- Exportmöglichkeiten: Lassen sich Daten ohne großen Aufwand nach Excel, Google Sheets, Notion oder Airtable exportieren?
- Zusatzfunktionen: KI-gestützte Extraktion, Zeitplanung, Vorlagen, Nachbearbeitung, Integrationen.
- Zielgruppe: Ist das Tool für Business-User, Analysten oder Entwickler gedacht?
Ich habe außerdem die Dokumentation der einzelnen Tools geprüft, das Onboarding getestet und die Limits der Gratis-Tarife verglichen – denn „kostenlos“ ist eben nicht immer so kostenlos, wie es klingt.
Auf einen Blick: 12 kostenlose Data-Scraper im Vergleich
Hier ist eine Gegenüberstellung, damit du schneller das passende Tool findest.
| Tool | Plattform | Einschränkungen im Gratis-Tarif | Am besten geeignet für | Exportformate | Besondere Funktionen |
|---|---|---|---|---|---|
| Thunderbit | Chrome-Erweiterung | 6 Seiten/Monat | Nicht-Coder, Business | Excel, CSV | KI-Prompts, PDF-/Bild-Scraping, Unterseiten-Crawl |
| Browse AI | Cloud | 50 Credits/Monat | No-Code-Nutzer | CSV, Sheets | Point-and-Click-Robots, Planung |
| Octoparse | Desktop | 10 Tasks, 50.000 Zeilen/Monat | No-Code, halbtechnisch | CSV, Excel, JSON | Visueller Workflow, Unterstützung dynamischer Seiten |
| ParseHub | Desktop | 5 Projekte, 200 Seiten/Ausführung | No-Code, halbtechnisch | CSV, Excel, JSON | Visuell, Unterstützung dynamischer Seiten |
| Webscraper.io | Chrome-Erweiterung | Unbegrenzte lokale Nutzung | No-Code, einfache Aufgaben | CSV, XLSX | Sitemap-basiert, Community-Vorlagen |
| Apify | Cloud | 5 $ Credits/Monat | Teams, halbtechnisch, Entwickler | CSV, JSON, Sheets | Actor-Marktplatz, Zeitplanung, API |
| Scrapy | Python-Bibliothek | Unbegrenzt (Open Source) | Entwickler | CSV, JSON, DB | Volle Code-Kontrolle, skalierbar |
| Puppeteer | Node.js-Bibliothek | Unbegrenzt (Open Source) | Entwickler | Benutzerdefiniert (Code) | Headless Browser, dynamische JS-Unterstützung |
| Selenium | Mehrsprachig | Unbegrenzt (Open Source) | Entwickler | Benutzerdefiniert (Code) | Browser-Automatisierung, Unterstützung mehrerer Browser |
| Zyte | Cloud | 1 Spider, 1 Std./Job, 7 Tage Aufbewahrung | Entwickler, Ops-Teams | CSV, JSON | Gehostetes Scrapy, Proxy-Management |
| SerpAPI | API | 100 Suchanfragen/Monat | Entwickler, Analysten | JSON | Suchmaschinen-APIs, Anti-Blocking |
| Diffbot | API | 10.000 Credits/Monat | Entwickler, KI-Projekte | JSON | KI-Extraktion, Knowledge Graph |
Thunderbit: Unsere Top-Empfehlung für KI-gestütztes, benutzerfreundliches Scraping
Daten von jeder Website mit KI extrahieren Get Started Free
Lass uns darüber sprechen, warum Thunderbit ganz oben auf meiner Liste steht. Und nein, das sage ich nicht nur, weil ich zum Team gehöre – ich bin wirklich überzeugt, dass Thunderbit dem Gefühl am nächsten kommt, einen KI-Praktikanten zu haben, der wirklich zuhört (und keine Kaffeepausen braucht).
Thunderbit ist kein typisches „erst das Tool lernen, dann scrapen“-Erlebnis. Es fühlt sich eher so an, als würdest du einem smarten Assistenten klare Anweisungen geben: Du sagst, was du brauchst („Hol alle Produktnamen, Preise und Links von dieser Seite“), und die KI von Thunderbit erledigt den Rest. Kein XPath, keine CSS-Selektoren, kein Regex-Frust. Und wenn du Unterseiten scrapen willst – etwa Produktdetailseiten oder Kontaktlinks von Unternehmen –, klickt Thunderbit automatisch weiter und ergänzt deine Tabelle. Auch das wieder nur mit einem Klick.
Was Thunderbit aber wirklich besonders macht, ist das, was nach dem Scraping passiert. Müssen Daten zusammengefasst, übersetzt, kategorisiert oder bereinigt werden? Dafür gibt es die integrierte KI-Nachbearbeitung. Du bekommst also nicht nur Rohdaten, sondern strukturierte, direkt nutzbare Informationen – bereit für dein CRM, dein Spreadsheet oder dein nächstes Projekt.
Gratis-Tarif: Mit der kostenlosen Testversion kannst du bis zu 6 Seiten scrapen (oder 10 mit dem Trial-Boost), einschließlich PDFs, Bildern und sogar Social-Media-Vorlagen. Export nach Excel oder CSV ist kostenlos, ebenso Funktionen wie E-Mail-, Telefon- und Bildextraktion. Für größere Vorhaben schalten kostenpflichtige Pläne mehr Seiten frei, direkten Export nach Google Sheets/Notion/Airtable, geplantes Scraping und Sofortvorlagen für beliebte Seiten wie Amazon, Google Maps und Instagram.
Wenn du Thunderbit in Aktion sehen willst, schau dir die Thunderbit Chrome-Erweiterung an oder stöbere auf unserem YouTube-Kanal nach Schnellstart-Videos.
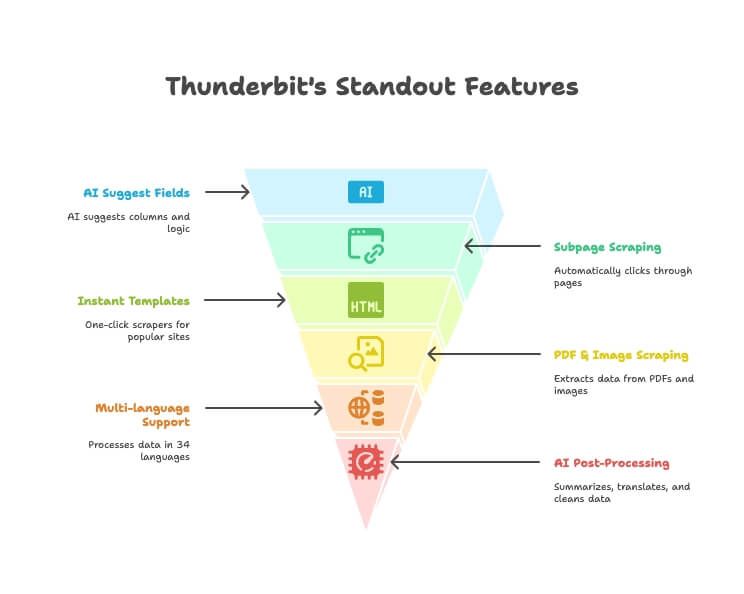
Die herausragenden Funktionen von Thunderbit
- KI-Feldvorschläge: Beschreibe einfach, welche Daten du brauchst, und Thunderbits KI schlägt passende Spalten und Extraktionslogik vor.
- Scraping von Unterseiten: Klickt automatisch durch Detailseiten oder Links und erweitert deine Haupttabelle – ganz ohne manuelles Setup.
- Sofortvorlagen: Ein-Klick-Scraper für Amazon, Google Maps, Instagram und mehr.
- PDF- & Bild-Scraping: Extrahiere Tabellen und Daten aus PDFs und Bildern mit KI – ohne Zusatztools.
- Mehrsprachige Unterstützung: Scrape und verarbeite Daten in 34 Sprachen.
- Direkter Export: Sende deine Daten direkt an Excel, Google Sheets, Notion oder Airtable (kostenpflichtige Pläne).
- KI-Nachbearbeitung: Zusammenfassen, übersetzen, kategorisieren und bereinigen von Daten direkt beim Scraping.
- Kostenlose E-Mail-/Telefon-/Bildextraktion: Kontaktinformationen oder Bilder von jeder Website mit einem Klick erfassen.
Thunderbit schlägt die Brücke zwischen „Daten scrapen“ und „Daten wirklich nutzbar machen“. Es ist das Nächste, was ich bisher an einem echten KI-Datenassistenten für Business-User gesehen habe.
Der Rest der Top 12: Kostenlose Data-Scraper im Überblick
Werfen wir jetzt einen Blick auf den Rest des Feldes – sortiert nach Zielgruppe.
Für No-Code- und Business-Nutzer
Thunderbit
Bereits oben behandelt. Der einfachste Einstieg für Nicht-Coder, mit KI-Funktionen und Sofortvorlagen.
Webscraper.io
- Plattform: Chrome-Erweiterung
- Am besten geeignet für: Einfache, statische Websites; Nicht-Coder, die etwas Trial-and-Error nicht scheuen.
- Wichtige Funktionen: Sitemap-basiertes Scraping, Pagination, Export nach CSV/XLSX.
- Gratis-Tarif: Unbegrenzte lokale Nutzung, aber keine Cloud-Runs oder Zeitplanung. Nur manuelle Ausführung.
- Einschränkungen: Keine integrierte Unterstützung für Logins, PDFs oder komplexe dynamische Inhalte. Nur Community-Support.
ParseHub
- Plattform: Desktop-App (Windows, Mac, Linux)
- Am besten geeignet für: Nicht-Coder und halbtechnische Nutzer, die bereit sind, Zeit ins Lernen zu investieren.
- Wichtige Funktionen: Visueller Workflow-Builder, unterstützt dynamische Seiten, AJAX, Logins und Pagination.
- Gratis-Tarif: 5 öffentliche Projekte, 200 Seiten pro Lauf, nur manuelle Ausführung.
- Einschränkungen: Projekte sind im Gratis-Tarif öffentlich (bei sensiblen Daten vorsichtig sein), keine Planung, langsamere Extraktionsgeschwindigkeit.
Octoparse
- Plattform: Desktop-App (Windows/Mac), Cloud (kostenpflichtig)
- Am besten geeignet für: Nicht-Coder und Analysten, die Leistung und Flexibilität wollen.
- Wichtige Funktionen: Visuelles Point-and-Click, Unterstützung dynamischer Inhalte, Vorlagen für beliebte Websites.
- Gratis-Tarif: 10 Tasks, bis zu 50.000 Zeilen/Monat, nur Desktop (keine Cloud/Planung).
- Einschränkungen: Keine API, keine IP-Rotation und keine Planung im Gratis-Tarif. Bei komplexen Seiten kann die Lernkurve steil sein.
Browse AI
- Plattform: Cloud
- Am besten geeignet für: No-Code-Nutzer, die einfaches Scraping und Monitoring automatisieren möchten.
- Wichtige Funktionen: Point-and-Click-Roboterrekorder, Zeitplanung, Integrationen (Sheets, Zapier).
- Gratis-Tarif: 50 Credits/Monat, 1 Website, bis zu 5 Robots.
- Einschränkungen: Begrenztes Volumen, bei komplexen Seiten anfangs etwas Einarbeitung nötig.
Für Entwickler und technische Nutzer
Scrapy
- Plattform: Python-Bibliothek (Open Source)
- Am besten geeignet für: Entwickler, die volle Kontrolle und Skalierbarkeit wollen.
- Wichtige Funktionen: Hochgradig anpassbar, unterstützt große Crawls, Middleware und Pipelines.
- Gratis-Tarif: Unbegrenzt (Open Source).
- Einschränkungen: Keine GUI, Python-Kenntnisse erforderlich. Nichts für Nicht-Coder.
Puppeteer
- Plattform: Node.js-Bibliothek (Open Source)
- Am besten geeignet für: Entwickler, die dynamische, JavaScript-lastige Seiten scrapen.
- Wichtige Funktionen: Headless-Browser-Automatisierung, volle Kontrolle über Navigation und Extraktion.
- Gratis-Tarif: Unbegrenzt (Open Source).
- Einschränkungen: JavaScript-Kenntnisse erforderlich, keine GUI.
Selenium
- Plattform: Mehrsprachig (Python, Java usw.), Open Source
- Am besten geeignet für: Entwickler, die Browser zum Scraping oder Testen automatisieren.
- Wichtige Funktionen: Unterstützung mehrerer Browser, automatisiert Klicks, Scrollen und Logins.
- Gratis-Tarif: Unbegrenzt (Open Source).
- Einschränkungen: Langsamer als Headless-Libraries, Skripting erforderlich.
Zyte (Scrapy Cloud)
- Plattform: Cloud
- Am besten geeignet für: Entwickler und Ops-Teams, die Scrapy-Spider im großen Stil betreiben.
- Wichtige Funktionen: Gehostetes Scrapy, Proxy-Management, Jobplanung.
- Gratis-Tarif: 1 gleichzeitiger Spider, 1 Stunde/Job, 7 Tage Datenaufbewahrung.
- Einschränkungen: Keine erweiterte Planung im Gratis-Tarif, Scrapy-Kenntnisse erforderlich.
Für Teams und Enterprise-Anwendungen
Apify
- Plattform: Cloud
- Am besten geeignet für: Teams, halbtechnische Nutzer und Entwickler, die fertige oder eigene Scraper nutzen wollen.
- Wichtige Funktionen: Actor-Marktplatz (vorgefertigte Bots), Zeitplanung, API, Integrationen.
- Gratis-Tarif: 5 $ Credits/Monat (für kleine Jobs ausreichend), 7 Tage Datenaufbewahrung.
- Einschränkungen: Etwas Einarbeitung nötig, Nutzung durch Credits begrenzt.
SerpAPI
- Plattform: API
- Am besten geeignet für: Entwickler und Analysten, die Suchmaschinendaten benötigen (Google, Bing, YouTube).
- Wichtige Funktionen: Such-APIs, Anti-Blocking, strukturierte JSON-Ausgabe.
- Gratis-Tarif: 100 Suchanfragen/Monat.
- Einschränkungen: Nicht für beliebige Websites, nur API-Nutzung.
Diffbot
- Plattform: API
- Am besten geeignet für: Entwickler, KI-/ML-Teams und Unternehmen, die strukturierte Webdaten im großen Stil brauchen.
- Wichtige Funktionen: KI-gestützte Extraktion, Knowledge Graph, Artikel-/Produkt-APIs.
- Gratis-Tarif: 10.000 Credits/Monat.
- Einschränkungen: Nur API, technische Kenntnisse erforderlich, Durchsatz durch Rate Limits begrenzt.
Einschränkungen im Gratis-Tarif: Was „kostenlos“ bei jedem Data-Scraper wirklich bedeutet
Seien wir ehrlich: „kostenlos“ kann alles bedeuten – von „für Hobbyanwender unbegrenzt“ bis „gerade genug, um dich anzulocken“. Hier ist die echte Einordnung:
| Tool | Seiten/Zeilen pro Monat | Exportformate | Zeitplanung | API-Zugriff | Wichtige Gratis-Einschränkungen |
|---|---|---|---|---|---|
| Thunderbit | 6 Seiten | Excel, CSV | Nein | Nein | KI-Feldvorschläge eingeschränkt, kein direkter Sheets-/Notion-Export im Gratis-Tarif |
| Browse AI | 50 Credits | CSV, Sheets | Ja | Ja | 1 Website, 5 Robots, 15 Tage Aufbewahrung |
| Octoparse | 50.000 Zeilen | CSV, Excel, JSON | Nein | Nein | Nur Desktop, keine Cloud/Planung |
| ParseHub | 200 Seiten/Ausführung | CSV, Excel, JSON | Nein | Nein | 5 öffentliche Projekte, langsame Geschwindigkeit |
| Webscraper.io | Unbegrenzt lokal | CSV, XLSX | Nein | Nein | Manuelle Ausführung, keine Cloud |
| Apify | 5 $ Credits (ca. geringes Volumen) | CSV, JSON, Sheets | Ja | Ja | 7 Tage Aufbewahrung, Credit-Limit |
| Scrapy | Unbegrenzt | CSV, JSON, DB | Nein | N/A | Programmierung erforderlich |
| Puppeteer | Unbegrenzt | Benutzerdefiniert (Code) | Nein | N/A | Programmierung erforderlich |
| Selenium | Unbegrenzt | Benutzerdefiniert (Code) | Nein | N/A | Programmierung erforderlich |
| Zyte | 1 Spider, 1 Std./Job | CSV, JSON | Eingeschränkt | Ja | 7 Tage Aufbewahrung, 1 gleichzeitiger Job |
| SerpAPI | 100 Suchanfragen | JSON | Nein | Ja | Nur Suchmaschinen-APIs |
| Diffbot | 10.000 Credits | JSON | Nein | Ja | Nur API, Rate Limits |
Unterm Strich: Für echte Projekte bieten Thunderbit, Browse AI und Apify die am besten nutzbaren Gratis-Tarife für Business-User. Für dauerhaftes oder großvolumiges Scraping stößt du schnell an Grenzen und musst upgraden oder auf Open-Source- bzw. Code-Lösungen wechseln.
Welcher Data-Scraper passt zu dir? (Leitfaden nach Nutzerprofil)
Hier ist eine kleine Entscheidungshilfe, je nach Rolle und technischer Erfahrung:
| Nutzerprofil | Beste Tools (kostenlos) | Warum |
|---|---|---|
| Nicht-Coder (Sales/Marketing) | Thunderbit, Browse AI, Webscraper.io | Schnell zu lernen, Point-and-Click, KI-Unterstützung |
| Halbtechnisch (Ops/Analyst) | Octoparse, ParseHub, Apify, Zyte | Mehr Leistung, kann komplexe Seiten verarbeiten, etwas Skripting möglich |
| Entwickler/Engineer | Scrapy, Puppeteer, Selenium, Diffbot, SerpAPI | Volle Kontrolle, unbegrenzt, API-first |
| Team/Enterprise | Apify, Zyte | Zusammenarbeit, Planung, Integrationen |
Web-Scraping in der Praxis: Wie flexibel sind die Tools in typischen Szenarien?
So schneiden die Tools in fünf häufigen Scraping-Szenarien ab:
| Szenario | Thunderbit | Browse AI | Octoparse | ParseHub | Webscraper.io | Apify | Scrapy | Puppeteer | Selenium | Zyte | SerpAPI | Diffbot |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Pagination-Listen | Einfach | Einfach | Mittel | Mittel | Mittel | Einfach | Einfach | Einfach | Einfach | Einfach | N/A | Mittel |
| Google-Maps-Listings | Einfach* | Schwer | Mittel | Mittel | Schwer | Einfach | Schwer | Schwer | Schwer | Schwer | Einfach | N/A |
| Seiten mit Login | Einfach | Mittel | Mittel | Mittel | Manuell | Mittel | Einfach | Einfach | Einfach | Einfach | N/A | N/A |
| PDF-Datenextraktion | Einfach | Nein | Nein | Nein | Nein | Mittel | Schwer | Schwer | Schwer | Schwer | Nein | Eingeschränkt |
| Social-Media-Inhalte | Einfach* | Teilweise | Schwer | Schwer | Schwer | Einfach | Schwer | Schwer | Schwer | Schwer | YouTube | Eingeschränkt |
- Thunderbit und Apify bieten vorgefertigte Vorlagen/Actors für Google Maps und Social-Media-Scraping, wodurch diese Szenarien für nicht-technische Nutzer deutlich einfacher werden.
Plugin vs. Desktop vs. Cloud: Welche Scraper-Erfahrung ist die beste?
- Chrome-Erweiterungen (Thunderbit, Webscraper.io):
- Vorteile: Schnell startklar, läuft direkt im Browser, kaum Setup.
- Nachteile: Viel manuelle Arbeit, anfällig für Website-Änderungen, nur begrenzte Automatisierung.
- Vorteil von Thunderbit: Die KI verarbeitet Strukturänderungen, Unterseiten-Navigation und sogar PDF-/Bild-Scraping – deutlich robuster als klassische Erweiterungen.
- Desktop-Apps (Octoparse, ParseHub):
- Vorteile: Leistungsstark, visuelle Workflows, unterstützt dynamische Seiten und Logins.
- Nachteile: Steilere Lernkurve, auf Gratis-Tarifen keine Cloud-Automatisierung, abhängig vom Betriebssystem.
- Cloud-Plattformen (Browse AI, Apify, Zyte):
- Vorteile: Zeitplanung, Teamarbeit, Skalierbarkeit, Integrationen.
- Nachteile: Gratis-Tarife oft kreditbasiert begrenzt, teils zusätzlicher Setup-Aufwand, manchmal API-Kenntnisse nötig.
- Open-Source-Bibliotheken (Scrapy, Puppeteer, Selenium):
- Vorteile: Unbegrenzt, anpassbar, ideal für Entwickler.
- Nachteile: Coding erforderlich, nicht für Business-User.
Web-Scraping-Trends 2026: Was moderne Tools auszeichnet
Web scraping 2026 dreht sich um KI, Automatisierung und Integration. Das ist neu:
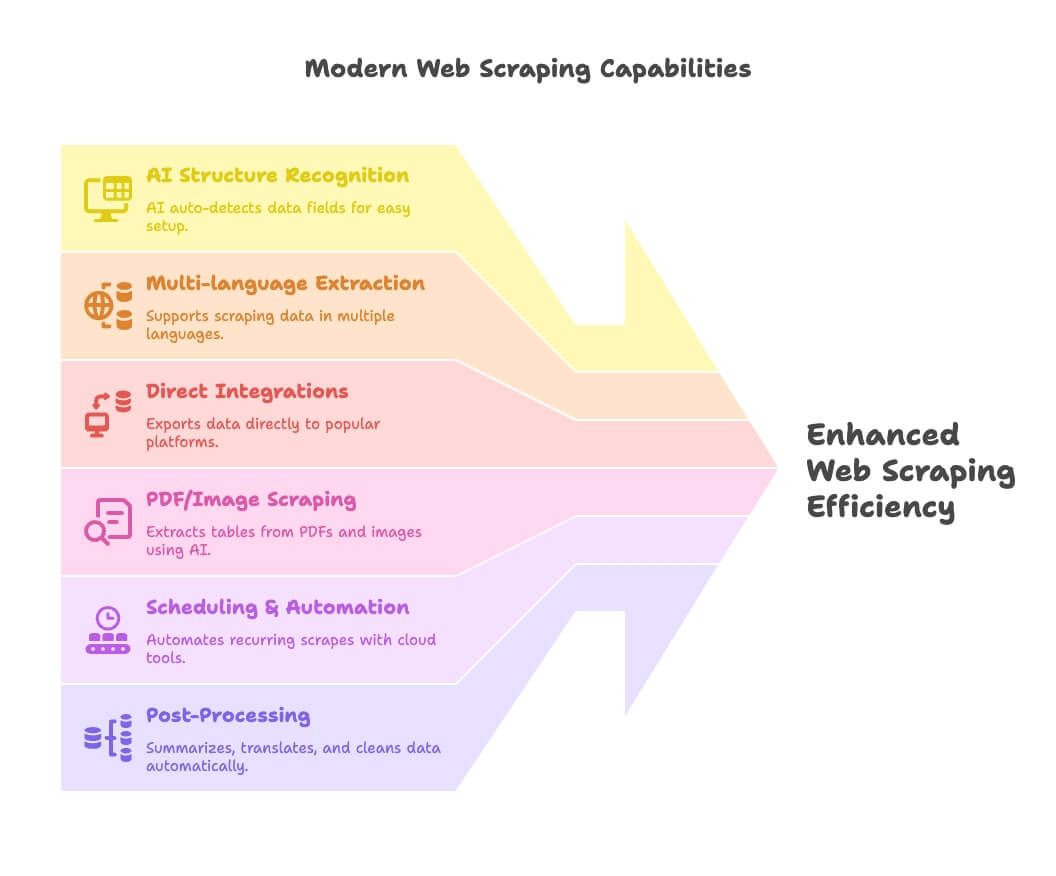
- KI-Erkennung von Strukturen: Tools wie Thunderbit erkennen Datenfelder automatisch – das macht das Setup für Nicht-Coder zum Kinderspiel.
- Mehrsprachige Extraktion: Thunderbit und andere Tools unterstützen das Scrapen und Verarbeiten von Daten in Dutzenden Sprachen.
- Direkte Integrationen: Exportiere Daten direkt nach Google Sheets, Notion oder Airtable – kein CSV-Chaos mehr.
- PDF-/Bild-Scraping: Thunderbit geht hier voran und ermöglicht die Extraktion von Tabellen aus PDFs und Bildern per KI.
- Zeitplanung & Automatisierung: Cloud-Tools (Apify, Browse AI) lassen sich einmal einrichten und dann einfach laufen.
- Nachbearbeitung: Daten direkt beim Scrapen zusammenfassen, übersetzen, kategorisieren und bereinigen – keine chaotischen Tabellen mehr.
Thunderbit, Apify und SerpAPI stehen bei diesen Trends an vorderster Front – Thunderbit sticht aber besonders heraus, weil KI-gestütztes Scraping damit für alle zugänglich wird, nicht nur für Entwickler.
Mehr als Scraping: Datenverarbeitung und Mehrwert-Funktionen
Es geht nicht nur darum, Daten zu sammeln – sondern darum, sie nutzbar zu machen. So schneiden die Top-Tools bei der Nachbearbeitung ab:
| Tool | Bereinigung | Übersetzung | Kategorisierung | Zusammenfassung | Hinweise |
|---|---|---|---|---|---|
| Thunderbit | Ja | Ja | Ja | Ja | Integrierte KI-Nachbearbeitung |
| Apify | Teilweise | Teilweise | Teilweise | Teilweise | Hängt vom verwendeten Actor ab |
| Browse AI | Nein | Nein | Nein | Nein | Nur Rohdaten |
| Octoparse | Teilweise | Nein | Teilweise | Nein | Teilweise Feldverarbeitung |
| ParseHub | Teilweise | Nein | Teilweise | Nein | Teilweise Feldverarbeitung |
| Webscraper.io | Nein | Nein | Nein | Nein | Nur Rohdaten |
| Scrapy | Ja* | Ja* | Ja* | Ja* | Wenn vom Entwickler programmiert |
| Puppeteer | Ja* | Ja* | Ja* | Ja* | Wenn vom Entwickler programmiert |
| Selenium | Ja* | Ja* | Ja* | Ja* | Wenn vom Entwickler programmiert |
| Zyte | Teilweise | Nein | Teilweise | Nein | Einige Auto-Extraktionsfunktionen |
| SerpAPI | Nein | Nein | Nein | Nein | Nur strukturierte Suchdaten |
| Diffbot | Ja | Ja | Ja | Ja | KI-gestützt, aber nur per API |
- Der Entwickler muss die Verarbeitungslogik selbst implementieren.
Thunderbit ist das einzige Tool, mit dem auch nicht-technische Nutzer von rohen Webdaten direkt zu verwertbaren, strukturierten Erkenntnissen kommen – alles in einem einzigen Workflow.
Community, Support und Lernressourcen: So kommst du schnell rein
Dokumentation und Onboarding sind extrem wichtig. So schneiden die Tools ab:
| Tool | Docs & Tutorials | Community | Vorlagen | Lernkurve |
|---|---|---|---|---|
| Thunderbit | Hervorragend | Wachsend | Ja | Sehr niedrig |
| Browse AI | Gut | Gut | Ja | Niedrig |
| Octoparse | Hervorragend | Groß | Ja | Mittel |
| ParseHub | Hervorragend | Groß | Ja | Mittel |
| Webscraper.io | Gut | Forum | Ja | Mittel |
| Apify | Hervorragend | Groß | Ja | Mittel-hoch |
| Scrapy | Hervorragend | Riesig | N/A | Hoch |
| Puppeteer | Gut | Groß | N/A | Hoch |
| Selenium | Gut | Riesig | N/A | Hoch |
| Zyte | Gut | Groß | Ja | Mittel-hoch |
| SerpAPI | Gut | Mittel | N/A | Hoch |
| Diffbot | Gut | Mittel | N/A | Hoch |
Thunderbit und Browse AI sind am einfachsten für Einsteiger. Octoparse und ParseHub bieten sehr gute Ressourcen, verlangen aber mehr Geduld. Apify und Entwickler-Tools haben eine steile Lernkurve, sind dafür aber gut dokumentiert.
Fazit: Der richtige kostenlose Data-Scraper für 2026
Die besten Web-Scraping-Tools in 2026 ansehen Get Started Free
Die Kurzfassung: Nicht alle „kostenlosen“ Data-Scraper sind gleich gut nutzbar, und deine Wahl sollte von deiner Rolle, deinem technischen Komfort und deinem tatsächlichen Bedarf abhängen.
- Wenn du Business-User oder Nicht-Coder bist und schnell an Daten kommen willst – vor allem von kniffligen Websites, PDFs oder Bildern – ist Thunderbit der beste Startpunkt. Der KI-Ansatz, natürliche Sprachprompts und die Nachbearbeitungsfunktionen machen es dem echten KI-Datenassistenten am nächsten. Teste die Thunderbit Chrome-Erweiterung kostenlos und sieh selbst, wie schnell aus „Ich brauche diese Daten“ ein „Hier ist meine Tabelle“ wird.
- Wenn du Entwickler bist oder unbegrenztes, anpassbares Scraping brauchst, sind Open-Source-Tools wie Scrapy, Puppeteer und Selenium die beste Wahl.
- Für Teams und halbtechnische Nutzer bieten Apify und Zyte skalierbare, kollaborative Lösungen mit großzügigen Gratis-Tarifen für kleinere Jobs.
Egal wie dein Workflow aussieht: Fang mit dem Tool an, das zu deinen Fähigkeiten und Anforderungen passt. Und denk daran: 2026 musst du kein Coder sein, um Webdaten zu nutzen – du brauchst nur den richtigen Assistenten (und vielleicht ein bisschen Humor, wenn die Roboter dich überholen).
Du willst tiefer einsteigen? Dann schau dir weitere Leitfäden und Vergleiche im Thunderbit Blog an, darunter:
- Was ist Data Scraping und wie macht man es 2026?
- Wie man Website-Daten mit KI nach Excel scrapt
- Die besten Web-Scraping-Tools & Software in 2026
Mit Thunderbit mit dem Scraping starten
KI-Web-Scraper testen Get Started Free




