
Das Web ist längst nicht mehr nur ein digitaler Spielplatz – es ist das größte Datenlager der Welt, und alle, von Vertriebsteams bis zu Marktanalysten, wollen darauf zugreifen. Aber ehrlich: Webdaten per Hand zu sammeln macht ungefähr so viel Spaß wie IKEA-Möbel ohne Anleitung zusammenzubauen – nur mit doppelt so vielen übrig gebliebenen Schrauben.
Da Unternehmen immer stärker auf Marktinformationen in Echtzeit, wettbewerbsfähige Preise und Lead-Generierung angewiesen sind, war der Bedarf an effizienten und zuverlässigen Data-Crawling-Tools noch nie größer. Tatsächlich verlassen sich inzwischen fast , um Entscheidungen voranzutreiben, und der globale Web-Scraping-Markt wird voraussichtlich bis 2030 .
Wenn Sie genug vom Copy-and-Paste haben, keine frischen Leads verpassen wollen oder einfach sehen möchten, was möglich ist, wenn Automatisierung die schwere Arbeit übernimmt, sind Sie hier richtig. Ich habe jahrelang Web-Extraktions-Tools gebaut und getestet (und ja, das Team bei geleitet), also weiß ich aus erster Hand, wie das richtige Tool stundenlange Kleinarbeit in einen Zwei-Klick-Flow verwandeln kann. Egal, ob Sie als Nicht-Techniker sofortige Ergebnisse wollen oder als Entwickler volle Kontrolle brauchen: Diese Liste der 10 besten Data-Crawling-Tools hilft Ihnen, die passende Lösung zu finden.
Warum die Wahl des richtigen Data-Crawling-Tools wichtig ist
Seien wir ehrlich: Der Unterschied zwischen einem guten und einem mittelmäßigen Data-Crawling-Tool ist nicht nur eine Frage des Komforts – er wirkt sich direkt auf das Unternehmenswachstum aus. Wenn Sie Web-Extraktion automatisieren, sparen Sie nicht nur Zeit (ein G2-Bewerter berichtete sogar, dass er eingespart hat), sondern reduzieren auch Fehler, erschließen neue Chancen und stellen sicher, dass Ihr Team immer mit den aktuellsten und genauesten Daten arbeitet. Manuelle Recherche ist langsam, fehleranfällig und oft schon veraltet, wenn Sie fertig sind. Mit dem richtigen Tool können Sie Wettbewerber beobachten, Preise verfolgen oder Lead-Listen in Minuten statt in Tagen erstellen.
Ein Beispiel: Ein Beauty-Händler nutzte Web Scraping, um Lagerbestand und Preise von Wettbewerbern zu überwachen, und . Genau so etwas lässt sich mit Tabellenkalkulationen und Muskelkraft eben nicht erreichen.
Wie wir die besten Data-Crawling-Tools bewertet haben
Bei so vielen Optionen fühlt sich die Auswahl des richtigen Data-Crawling-Tools schnell an wie Speed-Dating auf einer Tech-Konferenz. Hier sind die Kriterien, mit denen ich die Besten vom Rest getrennt habe:
- Einfache Bedienung: Kann man ohne PhD in Python loslegen? Gibt es eine visuelle Oberfläche oder KI-Unterstützung für Nicht-Programmierer?
- Automatisierungsfunktionen: Unterstützt das Tool Paginierung, Unterseiten, dynamische Inhalte und Zeitplanung? Kann es für große Jobs in der Cloud laufen?
- Preise und Skalierbarkeit: Gibt es einen kostenlosen Tarif oder einen günstigen Einstiegstarif? Wie entwickeln sich die Kosten, wenn der Datenbedarf wächst?
- Funktionsumfang und Integration: Lässt sich nach Excel, Google Sheets oder per API exportieren? Gibt es Vorlagen, Zeitplanung oder integrierte Funktionen zur Datenbereinigung?
- Am besten geeignet für: Für wen ist das Tool wirklich gedacht – Business-Nutzer, Entwickler oder Enterprise-Teams?
Am Ende habe ich eine schnelle Vergleichstabelle eingefügt, damit Sie sehen können, wie sich die einzelnen Tools im direkten Vergleich schlagen.
Jetzt tauchen wir ein in die 10 besten Data-Crawling-Tools für effiziente Web-Extraktion im Jahr 2026.
1. Thunderbit
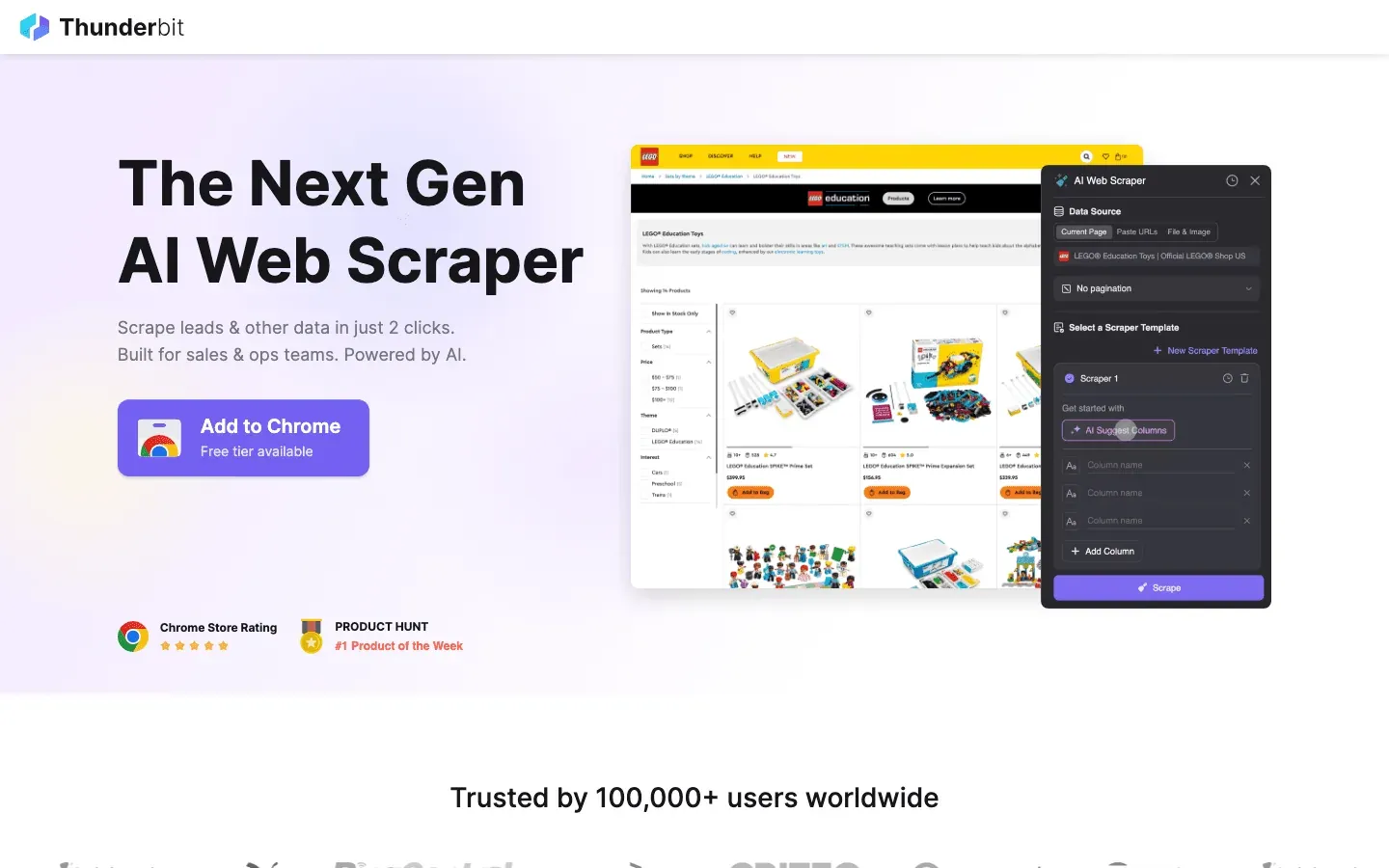 ist meine klare Empfehlung für alle, die Daten-Crawling so einfach haben wollen wie Essen bestellen. Thunderbit ist als KI-gestützte Chrome-Erweiterung gebaut und setzt ganz auf 2-Klick-Scraping: Einfach auf „KI-Felder vorschlagen“ klicken, die KI analysiert die Seite, dann auf „Scrapen“ klicken und die Daten holen. Kein Programmieren, kein Herumhantieren mit Selektoren – nur sofortige Ergebnisse.
ist meine klare Empfehlung für alle, die Daten-Crawling so einfach haben wollen wie Essen bestellen. Thunderbit ist als KI-gestützte Chrome-Erweiterung gebaut und setzt ganz auf 2-Klick-Scraping: Einfach auf „KI-Felder vorschlagen“ klicken, die KI analysiert die Seite, dann auf „Scrapen“ klicken und die Daten holen. Kein Programmieren, kein Herumhantieren mit Selektoren – nur sofortige Ergebnisse.
Warum ist Thunderbit bei Vertriebs-, Marketing- und E-Commerce-Teams so beliebt? Weil es für echte Business-Workflows gemacht ist:
- KI-Felder vorschlagen: Die KI liest die Seite und empfiehlt die besten Spalten für die Extraktion – Namen, Preise, E-Mails, was auch immer Sie brauchen.
- Unterseiten-Scraping: Brauchen Sie mehr Details? Thunderbit kann automatisch jede Unterseite besuchen (etwa Produktdetails oder LinkedIn-Profile) und Ihre Tabelle anreichern.
- Sofortiger Export: Schieben Sie Ihre Daten direkt nach Excel, Google Sheets, Airtable oder Notion. Alle Exporte sind kostenlos.
- Vorlagen mit einem Klick: Für beliebte Websites (Amazon, Zillow, Instagram) können Sie Sofortvorlagen für noch schnellere Ergebnisse nutzen.
- Kostenloser Datenexport: Es gibt keine Paywall, wenn Sie Ihre Daten herausbekommen wollen.
- Geplantes Scraping: Richten Sie wiederkehrende Jobs in natürlicher Sprache ein („jeden Montag um 9 Uhr“) – perfekt für Preisüberwachung oder wöchentliche Lead-Updates.
Thunderbit verwendet ein Credit-System (1 Credit = 1 Zeile) und bietet einen für bis zu 6 Seiten (oder 10 mit einem Test-Boost). Bezahlte Pläne starten bei 15 $/Monat für 500 Credits und sind damit für Teams jeder Größe erschwinglich.
Wenn Sie Thunderbit in Aktion sehen möchten, schauen Sie auf unserem oder im vorbei. Es ist das Tool, das ich mir gewünscht hätte, als ich noch in manueller Dateneingabe versank.
2. Octoparse
 ist ein Schwergewicht in der Welt des Data-Crawlings, besonders für Enterprise-Nutzer, die echte Leistung brauchen. Es bietet eine visuelle Desktop-Oberfläche (Windows und Mac), mit der Sie per Klick und Auswahl Extraktions-Workflows bauen können – ganz ohne Programmierung. Aber lassen Sie sich von der freundlichen Oberfläche nicht täuschen: Im Hintergrund verarbeitet Octoparse Logins, unendliches Scrollen, rotierende Proxies und sogar CAPTCHA-Lösungen.
ist ein Schwergewicht in der Welt des Data-Crawlings, besonders für Enterprise-Nutzer, die echte Leistung brauchen. Es bietet eine visuelle Desktop-Oberfläche (Windows und Mac), mit der Sie per Klick und Auswahl Extraktions-Workflows bauen können – ganz ohne Programmierung. Aber lassen Sie sich von der freundlichen Oberfläche nicht täuschen: Im Hintergrund verarbeitet Octoparse Logins, unendliches Scrollen, rotierende Proxies und sogar CAPTCHA-Lösungen.
- 500+ vorgefertigte Vorlagen: Starten Sie schnell mit Vorlagen für Amazon, Twitter, LinkedIn und mehr.
- Cloud-basiertes Scraping: Führen Sie Jobs auf den Servern von Octoparse aus, planen Sie Aufgaben und skalieren Sie für große Projekte.
- API-Zugriff: Integrieren Sie extrahierte Daten direkt in Ihre Business-Apps oder Datenbanken.
- Erweiterte Automatisierung: Verarbeitet dynamische Inhalte, Paginierung und mehrstufige Workflows.
Der kostenlose Tarif umfasst 10 Aufgaben plus ein großzügiges monatliches Exportlimit von 50.000 Zeilen – also ein echter Arbeits-Tarif, kein bloßer Appetithappen. Bezahlte Pläne starten bei 69 $/Monat für Standard (jährliche Abrechnung; ca. 82 $/Monat bei monatlicher Zahlung) und bei 249 $/Monat für Professional. Die Lernkurve ist steiler als bei Thunderbit, aber wenn Sie Tausende Seiten zuverlässig scrapen und Cloud-Ausführung wollen, bleibt Octoparse eine der etabliertesten Optionen, die einen genaueren Blick wert ist. Preise am 13.05.2026 anhand von geprüft.
3. Scrapy
 ist der Goldstandard für Entwickler, die volle Kontrolle über ihre Data-Crawling-Projekte wollen. Es ist ein Open-Source-Python-Framework, mit dem Sie eigene Spiders (Crawler) für jede beliebige Website programmieren können. Wenn Sie es sich vorstellen können, können Sie es mit Scrapy bauen.
ist der Goldstandard für Entwickler, die volle Kontrolle über ihre Data-Crawling-Projekte wollen. Es ist ein Open-Source-Python-Framework, mit dem Sie eigene Spiders (Crawler) für jede beliebige Website programmieren können. Wenn Sie es sich vorstellen können, können Sie es mit Scrapy bauen.
- Volle Programmierbarkeit: Schreiben Sie Python-Code, um genau festzulegen, wie eine Website gecrawlt und geparst wird.
- Asynchron und schnell: Verarbeitet Tausende Seiten parallel für große Projekte.
- Erweiterbar: Fügen Sie Middleware für Proxies, Headless-Browser oder eigene Logik hinzu.
- Starke Community: Unzählige Tutorials, Plugins und Hilfe für knifflige Scraping-Szenarien.
Scrapy ist kostenlos und Open Source, erfordert aber Programmierkenntnisse. Wenn Sie ein technisches Team haben oder eine eigene Pipeline aufbauen möchten, ist Scrapy kaum zu schlagen. Für Nicht-Programmierer ist es allerdings ein ziemlich steiler Aufstieg.
4. ParseHub
 ist ein visuelles No-Code-Web-Scraping-Tool, das perfekt für Nicht-Techniker ist, die es mit komplexen Websites zu tun haben. Mit der Klick-und-Auswahl-Oberfläche können Sie Elemente markieren, Aktionen definieren und Scraping-Workflows bauen – sogar für Seiten mit dynamischen Inhalten oder schwieriger Navigation.
ist ein visuelles No-Code-Web-Scraping-Tool, das perfekt für Nicht-Techniker ist, die es mit komplexen Websites zu tun haben. Mit der Klick-und-Auswahl-Oberfläche können Sie Elemente markieren, Aktionen definieren und Scraping-Workflows bauen – sogar für Seiten mit dynamischen Inhalten oder schwieriger Navigation.
- Visueller Workflow-Builder: Mit Klicks Daten auswählen, Paginierung einrichten und Pop-ups oder Dropdowns behandeln.
- Verarbeitet dynamische Inhalte: Funktioniert mit JavaScript-lastigen Websites und interaktiven Seiten.
- Cloud-Läufe und Zeitplanung: Scrapes in der Cloud ausführen und wiederkehrende Jobs planen.
- Export nach CSV, Excel oder per API: Einfache Integration in Ihre Lieblingstools.
ParseHub bietet einen kostenlosen Plan (5 Projekte), bezahlte Pläne starten bei . Es ist etwas teurer als manche Wettbewerber, aber der visuelle Ansatz macht es zugänglich für Analysten, Marketer und Forscher, die mehr als nur eine einfache Chrome-Erweiterung brauchen.
5. Apify
 ist sowohl eine Plattform als auch ein Marktplatz für Web-Crawling. Es bietet eine riesige Bibliothek vorgefertigter „Actors“ (fertige Scraper) für beliebte Websites sowie die Möglichkeit, eigene Crawler in der Cloud zu bauen und auszuführen.
ist sowohl eine Plattform als auch ein Marktplatz für Web-Crawling. Es bietet eine riesige Bibliothek vorgefertigter „Actors“ (fertige Scraper) für beliebte Websites sowie die Möglichkeit, eigene Crawler in der Cloud zu bauen und auszuführen.
- 5.000+ fertige Actors: Scrapen Sie sofort Google Maps, Amazon, Twitter und mehr.
- Individuelles Scripting: Entwickler können JavaScript oder Python nutzen, um fortgeschrittene Crawler zu bauen.
- Cloud-Skalierung: Führen Sie Jobs parallel aus, planen Sie Aufgaben und verwalten Sie Daten in der Cloud.
- API und Integration: Binden Sie Ergebnisse in Ihre Apps, Workflows oder Datenpipelines ein.
Apify gibt Ihnen zunächst 5 $ kostenlose Plattformguthaben, danach folgen Starter für 29 $/Monat, Scale für 199 $/Monat und Business für 999 $/Monat – jede Stufe basiert auf „Plattformguthaben + Pay-as-you-go für Compute Units“, also treiben die tatsächliche Nutzung die Rechnung. Die Lernkurve ist etwas vorhanden, aber wenn Sie sowohl Plug-and-Play-Actors als auch die Möglichkeit wollen, eigene Crawler in JS oder Python zu schreiben, gehört Apify zu den stärksten Optionen auf dieser Liste. Preise am 13.05.2026 anhand von geprüft.
6. Data Miner
 ist eine Chrome-Erweiterung für schnelles, vorlagenbasiertes Data-Crawling. Sie ist perfekt für Business-Nutzer, die Daten aus Tabellen oder Listen ohne Einrichtung erfassen wollen.
ist eine Chrome-Erweiterung für schnelles, vorlagenbasiertes Data-Crawling. Sie ist perfekt für Business-Nutzer, die Daten aus Tabellen oder Listen ohne Einrichtung erfassen wollen.
- Große Vorlagenbibliothek: Über tausend Rezepte für gängige Websites (LinkedIn, Yelp usw.).
- Klick-und-Auswahl-Extraktion: Vorlage auswählen, Daten ansehen und sofort exportieren.
- Browserbasiert: Arbeitet mit Ihrer aktuellen Sitzung – ideal für Scraping hinter Logins.
- Export nach CSV oder Excel: Bringen Sie Ihre Daten in Sekunden in eine Tabellenkalkulation.
Der umfasst 500 Seiten/Monat, bezahlte Pläne starten bei 20 $/Monat. Am besten eignet sich das Tool für kleine, einmalige Aufgaben oder wenn Sie Daten sofort brauchen – erwarten Sie nur nicht, dass es riesige Jobs oder komplexe Automatisierung bewältigt.
7. Import.io
 ist eine Enterprise-Plattform für Organisationen, die eine kontinuierliche und zuverlässige Integration von Webdaten benötigen. Es ist mehr als nur ein Crawler – es ist ein verwalteter Service, der saubere, strukturierte Daten direkt in Ihre Geschäftssysteme liefert.
ist eine Enterprise-Plattform für Organisationen, die eine kontinuierliche und zuverlässige Integration von Webdaten benötigen. Es ist mehr als nur ein Crawler – es ist ein verwalteter Service, der saubere, strukturierte Daten direkt in Ihre Geschäftssysteme liefert.
- No-Code-Extraktion: Visuelle Einrichtung, um festzulegen, welche Daten gezogen werden sollen.
- Daten-Feeds in Echtzeit: Streamen Sie Daten in Dashboards, Analyse-Tools oder Datenbanken.
- Compliance und Zuverlässigkeit: Handhabt IP-Rotation, Anti-Bot-Maßnahmen und rechtliche Anforderungen.
- Managed Services: Das Team von Import.io kann Ihre Scraper einrichten und warten.
Die Preise sind , mit einer 14-tägigen kostenlosen Testphase für die SaaS-Plattform. Wenn Ihr Unternehmen auf ständig aktuelle Webdaten angewiesen ist (etwa im Handel, Finanzwesen oder in der Marktforschung), lohnt sich ein Blick auf Import.io.
8. WebHarvy
 ist ein Desktop-Scraper für Windows-Nutzer, die eine Klick-und-Auswahl-Lösung ohne Abonnement möchten. Besonders beliebt ist er bei kleinen Unternehmen und Einzelpersonen, die lieber einmal kaufen statt monatlich zahlen.
ist ein Desktop-Scraper für Windows-Nutzer, die eine Klick-und-Auswahl-Lösung ohne Abonnement möchten. Besonders beliebt ist er bei kleinen Unternehmen und Einzelpersonen, die lieber einmal kaufen statt monatlich zahlen.
- Visuelle Mustererkennung: Klicken Sie auf Datenelemente, und WebHarvy erkennt wiederkehrende Muster automatisch.
- Verarbeitet Text, Bilder und mehr: Extrahiert alle gängigen Datentypen, einschließlich E-Mails und URLs.
- Paginierung und Zeitplanung: Navigieren Sie durch mehrseitige Websites und richten Sie geplante Scrapes ein.
- Export nach Excel, CSV, XML, JSON oder SQL: Flexible Ausgabe für jeden Workflow.
Eine Einzelbenutzerlizenz kostet und ist damit eine kosteneffiziente Wahl für regelmäßige Nutzung – beachten Sie nur, dass das Tool ausschließlich für Windows verfügbar ist.
9. Mozenda
 ist eine cloudbasierte Data-Crawling-Plattform für Geschäftsprozesse und fortlaufenden Datenbedarf. Sie kombiniert einen Desktop-Designer (Windows) mit leistungsstarker Cloud-Ausführung und Automatisierung.
ist eine cloudbasierte Data-Crawling-Plattform für Geschäftsprozesse und fortlaufenden Datenbedarf. Sie kombiniert einen Desktop-Designer (Windows) mit leistungsstarker Cloud-Ausführung und Automatisierung.
- Visueller Agent Builder: Entwerfen Sie Extraktionsroutinen mit einer Klick-und-Auswahl-Oberfläche.
- Cloud-Skalierung: Führen Sie mehrere Agents parallel aus, planen Sie Jobs und verwalten Sie Daten zentral.
- Datenverwaltungs-Konsole: Kombinieren, filtern und bereinigen Sie Datensätze nach der Extraktion.
- Enterprise-Support: Feste Ansprechpartner und Managed Services für große Teams.
Der Self-Service-Pilot-Tarif von Mozenda kostet 500 $/Monat (5.000 Processing Credits, 10 Agents, 10 GB Speicher); Enterprise gibt es nur auf Anfrage. Außerdem gibt es eine 14-tägige kostenlose Teststufe mit 500 Credits, wenn Sie das Tool vor einer Entscheidung ausprobieren möchten. Mozenda eignet sich am besten für Unternehmen, die verlässliche, wiederholbare Webdaten fest in ihre täglichen Abläufe integrieren wollen – die Preise sind real, und die Plattform erwartet, dass Sie sie ernst nehmen. Preise am 13.05.2026 anhand von geprüft.
10. BeautifulSoup
 ist die klassische Python-Bibliothek zum Parsen von HTML und XML. Sie ist kein vollständiger Crawler, wird aber von Entwicklern für kleine, maßgeschneiderte Scraping-Projekte sehr geschätzt.
ist die klassische Python-Bibliothek zum Parsen von HTML und XML. Sie ist kein vollständiger Crawler, wird aber von Entwicklern für kleine, maßgeschneiderte Scraping-Projekte sehr geschätzt.
- Einfaches HTML-Parsen: Extrahieren Sie Daten aus statischen Webseiten mühelos.
- Funktioniert mit Python Requests: Kombinieren Sie es mit anderen Bibliotheken zum Abrufen und Crawlen.
- Flexibel und leichtgewichtig: Perfekt für schnelle Skripte oder Lernprojekte.
- Große Community: Unzählige Tutorials und Stack-Overflow-Antworten.
BeautifulSoup ist , aber Sie müssen den Code und die Crawling-Logik selbst schreiben. Am besten ist es für Entwickler oder Lernende geeignet, die die Grundlagen und Zusammenhänge des Web Scraping verstehen möchten.
Vergleichstabelle: Data-Crawling-Tools auf einen Blick
| Tool | Einfache Bedienung | Automatisierungsgrad | Preis | Exportoptionen | Am besten geeignet für |
|---|---|---|---|---|---|
| Thunderbit | Sehr einfach, No-Code | Hoch (KI, Unterseiten) | Testversion, ab 15 $/Monat | Excel, Sheets, Airtable, Notion, CSV | Vertrieb, Marketing, E-Commerce, Nicht-Techniker |
| Octoparse | Mittel, visuelle UI | Sehr hoch, Cloud | Kostenlos, 83–299 $/Monat | CSV, Excel, JSON, API | Unternehmen, Datenteams, dynamische Websites |
| Scrapy | Niedrig (Python nötig) | Hoch (anpassbar) | Kostenlos, Open Source | Beliebig (per Code) | Entwickler, große individuelle Projekte |
| ParseHub | Hoch, visuell | Hoch (dynamische Seiten) | Kostenlos, ab 189 $/Monat | CSV, Excel, JSON, API | Nicht-Techniker, komplexe Webstrukturen |
| Apify | Mittel, flexibel | Sehr hoch, Cloud | Kostenlos, 29–999 $/Monat | CSV, JSON, API, Cloud-Speicher | Entwickler, Unternehmen, fertige oder eigene Actors |
| Data Miner | Sehr einfach, Browser | Niedrig (manuell) | Kostenlos, 20–99 $/Monat | CSV, Excel | Schnelle einmalige Extraktionen, kleine Datensätze |
| Import.io | Mittel, verwaltet | Sehr hoch, Enterprise | Individuell, volumenbasiert | CSV, JSON, API, direkte Integration | Unternehmen, kontinuierliche Datenintegration |
| WebHarvy | Hoch, Desktop | Mittel (Zeitplanung) | 129 $ einmalig | Excel, CSV, XML, JSON, SQL | KMU, Windows-Nutzer, regelmäßiges Scraping |
| Mozenda | Mittel, visuell | Sehr hoch, Cloud | 250–450+ $/Monat | CSV, Excel, JSON, Cloud, DB | Laufende, groß angelegte Geschäftsprozesse |
| BeautifulSoup | Niedrig (Python nötig) | Niedrig (manuelle Programmierung) | Kostenlos, Open Source | Beliebig (per Code) | Entwickler, Lernende, kleine individuelle Skripte |
So wählen Sie das richtige Data-Crawling-Tool für Ihr Team aus
Das beste Data-Crawling-Tool zu wählen, bedeutet nicht, das „leistungsstärkste“ zu finden – sondern das, was zu den Fähigkeiten, Anforderungen und dem Budget Ihres Teams passt. Hier meine schnelle Empfehlung:
- Nicht-Techniker oder Business-Nutzer: Starten Sie mit Thunderbit, ParseHub oder Data Miner für schnelle Ergebnisse und einfache Einrichtung.
- Enterprise- oder Großprojekte: Schauen Sie sich Octoparse, Mozenda oder Import.io an, wenn Sie Automatisierung, Zeitplanung und Support brauchen.
- Entwickler oder individuelle Projekte: Scrapy, Apify oder BeautifulSoup bieten volle Kontrolle und Flexibilität.
- Preisbewusst oder für einmalige Jobs: WebHarvy (Windows) oder Data Miner (Browser) sind kosteneffizient und unkompliziert.
Testen Sie Ihre Favoriten immer mit einer kostenlosen Testversion an Ihren echten Zielseiten – was auf einer Website funktioniert, muss auf einer anderen noch lange nicht klappen. Und vergessen Sie die Integration nicht: Wenn Ihre Daten in Sheets, Notion oder einer Datenbank landen sollen, achten Sie darauf, dass Ihr Tool das direkt unterstützt.
Fazit: Geschäftlichen Mehrwert mit den besten Data-Crawling-Tools erschließen
Webdaten sind das neue Öl – aber nur, wenn Sie die richtige Maschine haben, um sie zu fördern und zu veredeln. Mit modernen Data-Crawling-Tools verwandeln Sie stundenlange manuelle Recherche in Minuten automatisierter Erkenntnisse – und schaffen damit die Grundlage für klügeren Vertrieb, präziseres Marketing und agilere Abläufe. Ob Sie Lead-Listen aufbauen, Wettbewerber beobachten oder einfach nur keine Lust mehr auf Copy-and-Paste haben: Auf dieser Liste gibt es ein Tool, das Ihnen das Leben deutlich leichter macht.
Sehen Sie sich also die Anforderungen Ihres Teams an, probieren Sie ein paar dieser Tools aus und erleben Sie, wie viel mehr Sie schaffen können, wenn Automatisierung die schwere Arbeit übernimmt. Und wenn Sie sehen möchten, wie KI-gestütztes 2-Klick-Scraping aussieht, . Viel Erfolg beim Crawlen – und mögen Ihre Daten immer frisch, strukturiert und einsatzbereit sein.
FAQs
1. Was ist ein Data-Crawling-Tool, und warum brauche ich eines?
Ein Data-Crawling-Tool automatisiert das Extrahieren von Informationen aus Websites. Es spart Zeit, reduziert Fehler und hilft Teams dabei, aktuelle Daten für Vertrieb, Marketing, Recherche und Betrieb zu sammeln – viel effizienter als manuelles Copy-and-Paste.
2. Welches Data-Crawling-Tool ist für nicht-technische Nutzer am besten geeignet?
Thunderbit, ParseHub und Data Miner sind Top-Empfehlungen für Nicht-Programmierer. Thunderbit überzeugt mit seinem 2-Klick-KI-Workflow, während ParseHub eine visuelle Lösung für komplexere Websites bietet.
3. Wie unterscheiden sich die Preismodelle bei Data-Crawling-Tools?
Die Preisgestaltung ist sehr unterschiedlich: Manche Tools (wie Thunderbit und Data Miner) bieten kostenlose Tarife und günstige Monatspläne, während Enterprise-Plattformen (wie Import.io und Mozenda) mit individuellen oder volumenbasierten Preisen arbeiten. Prüfen Sie immer, ob die Kosten zum Datenbedarf passen.
4. Kann ich diese Tools für laufende, geplante Datenextraktion nutzen?
Ja – Tools wie Thunderbit, Octoparse, Apify, Mozenda und Import.io unterstützen geplante oder wiederkehrende Crawls und eignen sich daher ideal für laufende Preisüberwachung, Lead-Generierung oder Marktforschung.
5. Was sollte ich vor der Wahl eines Data-Crawling-Tools beachten?
Berücksichtigen Sie die technischen Fähigkeiten Ihres Teams, die Komplexität der Websites, die Sie crawlen möchten, das Datenvolumen, Integrationsanforderungen und Ihr Budget. Testen Sie einige Tools mit Ihren echten Aufgaben, bevor Sie sich für einen kostenpflichtigen Plan entscheiden.
Für weitere Deep Dives und praktische Anleitungen schauen Sie im vorbei.
Mehr erfahren