
Letzten Monat hat die Stripe-Integration eines Freundes an einem Freitag um 23 Uhr plötzlich stillschweigend angefangen, 503-Fehler zurückzugeben. Niemand merkte das bis Samstagmorgen — da lagen im Support-Posteingang bereits über 200 wütende E-Mails von Kund:innen, deren Checkout fehlgeschlagen war.
Diese Geschichte ist nicht ungewöhnlich. Ein beziffert Ausfallzeiten im Schnitt auf 5.600 US-Dollar pro Minute, während . Die genaue Zahl hängt von Traffic, Conversion-Rate, Bestellwert, SLA-Risiko und Wiederherstellungskosten ab — die Richtung ist aber klar: Unüberwachte APIs sind ein Geschäftsrisiko, nicht bloß ein technisches Ärgernis. Und da und , ist Monitoring längst kein optionales Extra mehr. Dieser Leitfaden soll etwas leisten, das ich woanders so nicht gesehen habe: Tools nach deinem Anwendungsfall ordnen, die Qualität von Alerts bewerten, nicht nur ihre Existenz, echte Preise für 2026 zeigen und messen, wie schnell du tatsächlich startklar bist. Nicht schon wieder nur eine flache Logo-Liste.
Noch ein Punkt: Wenn deine API-Arbeit das Sammeln von Webdaten, das Befüllen von LLMs, den Aufbau von RAG-Systemen, das Monitoring von Wettbewerberseiten oder das Extrahieren von Preis- und Produktdaten von Websites umfasst, sollte die Diskussion um "API-Tools" nicht bei Uptime-Monitoring enden. Du brauchst auch einen verlässlichen Weg, unstrukturierte Webseiten in strukturierte Daten zu verwandeln. Genau hier passt in diesen Leitfaden: Es ist kein Uptime-Monitor, aber einer der schnellsten Wege, Websites über eine API in sauberes Markdown oder schema-basiertes JSON zu verwandeln.
Was ist API-Monitoring (und warum sollte sich dein Team darum kümmern)?
API-Monitoring bedeutet, fortlaufend zu prüfen, ob deine API-Endpunkte verfügbar, schnell und korrekt sind. Nicht nur: "Ist der Server online?" — gutes Monitoring validiert HTTP-Statuscodes, Response-Payloads, Latenz, SSL-Zertifikate, mehrstufige Workflows (etwa Login → Suche → Checkout) und sogar die Korrektheit des Schemas.
Das ist etwas anderes als allgemeines Website-Monitoring (das prüft, ob eine Seite lädt) und auch etwas anderes als APM (Application Performance Monitoring), das tief in Code-Traces, Datenbankabfragen und Laufzeit-Interna eintaucht. API-Monitoring sitzt genau an der Schnittstelle: Es testet, was Nutzer:innen, Partner und Integrationen tatsächlich erleben, wenn sie deine Endpunkte aufrufen.
Es gibt außerdem eine verwandte Kategorie, die erwähnenswert ist: Webdaten-APIs. Diese überwachen nicht, ob deine eigene API gesund ist; sie helfen deinem Produkt oder Workflow dabei, externe Webdaten zuverlässig zu erfassen. kann zum Beispiel eine Webseite in sauberes Markdown verdichten, strukturierte Felder als JSON extrahieren und Batch-Jobs über viele URLs hinweg ausführen. Wenn dein "API"-Projekt auf aktuellen Lieferantendaten, Produktseiten, öffentlichen Verzeichnissen, Dokumentationsseiten oder Forschungsquellen basiert, kann eine solche Datenextraktions-API betrieblich genauso wichtig sein wie ein Uptime-Check.
Warum sollten sich Nicht-Techniker:innen dafür interessieren? Weil und . Wenn ein Payment-Gateway, ein Auth-Service oder eine Shipping-API ausfällt, ist das kein abstraktes Infrastrukturproblem — es bedeutet Umsatzverlust, gebrochene Partnerverträge, mehr Support-Anfragen und schwindendes Vertrauen. Produktmanagement, Vertrieb, Operations und Customer Success sind alle betroffen.
Wichtige Kennzahlen, die du beobachten solltest:
- Uptime-Prozentsatz: Anteil der Zeit, in der ein Endpunkt verfügbar ist
- Antwortzeit / Latenz: Wie lange der Endpunkt für eine Antwort braucht (Durchschnitt, p95, p99)
- Fehlerquote: Anteil der Anfragen mit 5xx, Timeouts oder Assertion-Fehlern
- Durchsatz: Anfragen pro Sekunde/Minute
- Korrektheit: Ob die API erwartete Daten zurückgibt, nicht nur ein 200 OK
Wie wir die besten API-Monitoring-Tools für 2026 bewertet haben
Die meisten Artikel zu den "besten API-Monitoring-Tools" stapeln einfach nur Vendor-Namen und Features. Ich wollte bei der Auswahl bewusster vorgehen — zum Teil, weil ich viele Entwicklerforen gelesen habe, und zum Teil, weil mir das Thunderbit-Team geholfen hat, , um einen echten Vergleich zu bauen (dazu später mehr).
Darauf haben wir gewichtet:
| Kriterium | Warum es wichtig ist |
|---|---|
| Einrichtungsaufwand / Zeit bis zum ersten Alert | Kleine Teams brauchen heute Abdeckung, nicht erst nach einem Plattformprojekt |
| Alert-Intelligenz & Lärmreduktion | Wenn Alerts zu laut sind, ignorieren Teams sie und übersehen echte Vorfälle |
| Großzügigkeit des Free-Tiers | Nebenprojekte und frühe Startups starten oft kostenlos |
| Preis-Transparenz | Observability-Kosten können durch Hosts, Seats, Logs, Synthetic Runs und Daten-Ingest explodieren |
| Integrationsbreite | Alerts müssen dort landen, wo Teams ohnehin arbeiten (Slack, PagerDuty usw.) |
| Skalierbarkeit & Datentiefe | Reife Teams brauchen Traces, Logs, APM, RBAC, SSO, Aufbewahrung |
| Community- & Support-Qualität | Open-Source-Teams brauchen Release-Frequenz; Enterprise-Teams brauchen SLAs |
| Fähigkeit zur Webdaten-Extraktion | KI-Apps, RAG-Workflows und Marktanalyse-Tools brauchen oft saubere externe Daten, nicht nur Endpunkt-Uptime |
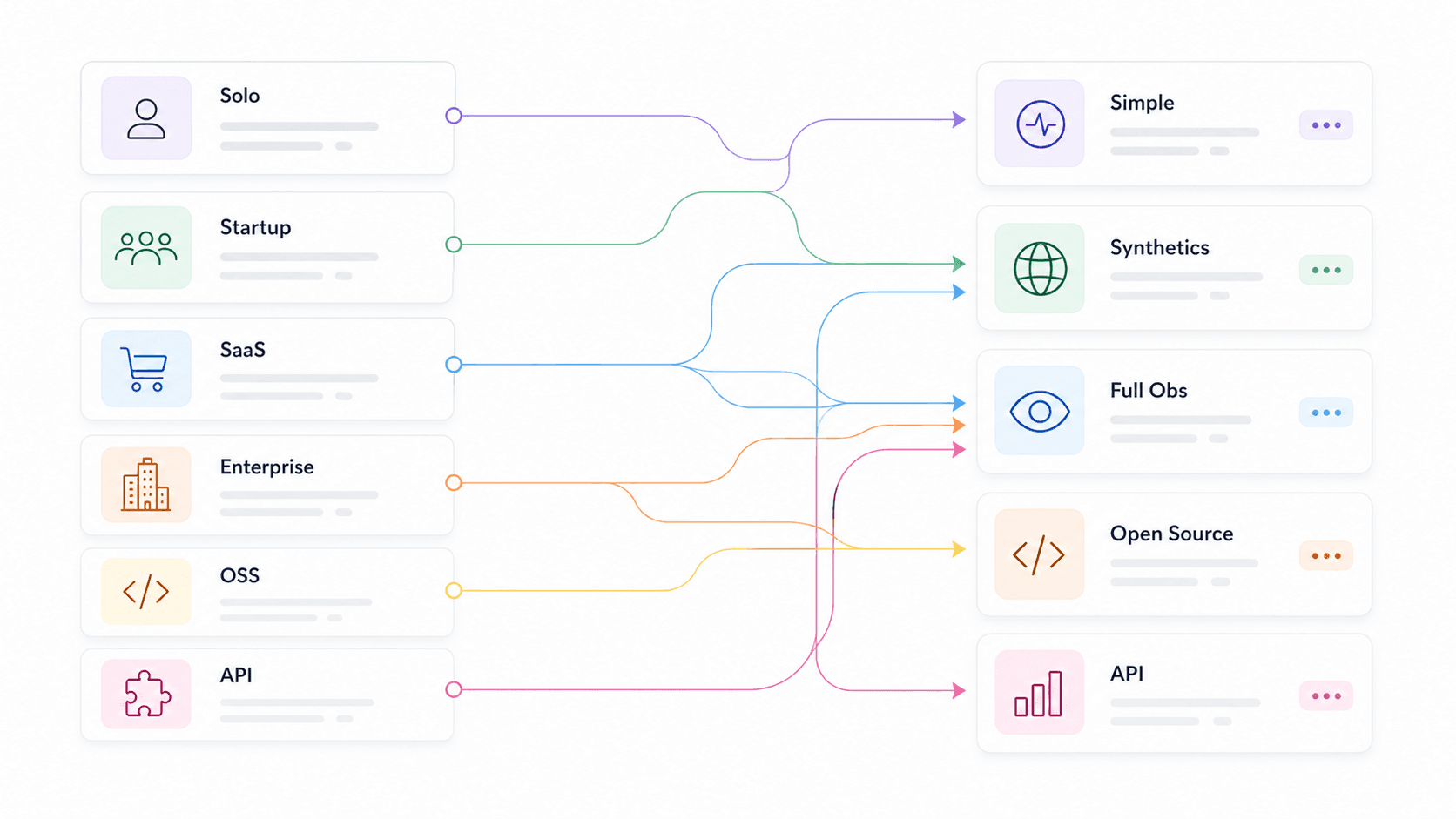
Wir haben die Empfehlungen außerdem nach Anwendungsfall segmentiert — Solo-Entwicklung, Startup, E-Commerce/SaaS, Enterprise, Open-Source-Purist:innen, API-Produktteams sowie Webdaten-/KI-App-Teams — damit du direkt zu deinem Kontext springen kannst, statt 14 Tool-Zusammenfassungen zu lesen und zu raten, welche auf dich zutrifft. Eine ergab, dass und als Auswahlkriterium nannten — das bestätigt, dass diese Punkte nicht bloß nette Extras sind.
Beste API-Monitoring-Tools nach Anwendungsfall: die Schnellwahl-Tabelle
Das ist die Abkürzung. Finde deine Zeile und springe dann zu den Tool-Abschnitten weiter unten für die vollständige Analyse.
| Anwendungsfall | Empfohlene Tools | Wichtigster Unterschied |
|---|---|---|
| Webdaten-/KI-App-Teams | Thunderbit Open API, Moesif, Apitally | Websites in sauberes Markdown oder strukturiertes JSON für LLMs, RAG, Preis- und Research-Workflows verwandeln |
| Solo-Dev / Nebenprojekt | UptimeRobot, Uptime Kuma, Gatus | Kostenlos oder self-hosted, minimale Konfiguration, schneller Start |
| Startup (5–15 Personen) | Checkly, Better Stack, Postman | Smarte Alerts, schneller Start, erschwinglich, Statusseiten |
| E-Commerce / SaaS | Datadog, New Relic, Moesif, Checkly | Business-Metriken, APM/Tracing, SDK-Tiefe, mehrstufige Synthetic-Checks |
| Enterprise / Multi-Cloud | Datadog, New Relic, Splunk, Grafana Cloud | Distributed Tracing, Compliance, Hybrid, RBAC/SSO |
| Open-Source-Purist:innen | Prometheus + Grafana, Uptime Kuma, Gatus, Uptrace | Volle Kontrolle, OTel-nativ, kein Vendor Lock-in |
| API-Produktteams | Moesif, Apitally, New Relic | Nutzung pro Kunde, Endpunkt-Trends, Anomalie-Alerts |
Das wichtigste Muster: Die Tools, die sich am schnellsten einrichten lassen, sind meist bei der Analyse leichter, während tiefere Plattformen mehr Konfiguration und Kostenkontrolle verlangen. Das ist kein Fehler — sondern ein Kompromiss, den man kennen sollte. Thunderbit liegt in einer etwas anderen Spur: Es ist am schnellsten, wenn es darum geht, Webseiten in API-fähige Daten zu verwandeln, nicht Ingenieur:innen über Ausfälle zu informieren.
Thunderbit Open API: Am besten, um Websites in strukturierte API-Daten zu verwandeln
ist die API, die ich an erste Stelle setzen würde für Teams, deren "Monitoring"- oder Research-Workflow von externen Webdaten abhängt. Es ist kein klassisches Uptime-Monitoring-Tool wie Checkly oder UptimeRobot. Stattdessen verwandelt Thunderbit jede Webseite in saubere, strukturierte Daten, die deine Apps, Agents, Dashboards und LLM-Pipelines tatsächlich nutzen können.
Die API hat drei Kern-Workflows. Distill wandelt eine Seite in sauberes, LLM-taugliches Markdown um. Extract nimmt ein Schema und gibt strukturierte JSON-Felder zurück, etwa Produktname, Preis, Verfügbarkeit, Unternehmensgröße, Finanzierungsrunde oder Bewertungsnote. Batch erlaubt die asynchrone Verarbeitung von bis zu 100 URLs mit Webhooks — nützlich, wenn du Preis-Seiten, Wettbewerberkataloge, Vendor-Dokumentationen, Nachrichtenquellen oder große Research-Listen beobachtest.
Warum es in einen API-Tools-Leitfaden gehört: Teams unterschätzen oft, wie viel Infrastruktur hinter einem einfachen "scrape diese Seite" steckt. JavaScript-lastige Seiten brauchen Rendering. Manche Seiten benötigen Geo-Routing. HTML muss von Navigation, Werbung, Modals und Boilerplate befreit werden, bevor es für ein LLM nützlich ist. Selektoren brechen, wenn sich Layouts ändern. Proxy-Rotation, Anti-Bot-Handling, Retries, Queues und Ergebnis-Polling können einen kleinen Datenworkflow in ein Wartungsprojekt verwandeln. Thunderbit nimmt einen großen Teil dieser Arbeit hinter einer API weg.
Geeignet für: Entwickler:innen von KI-Apps, RAG-Teams, E-Commerce-Operations, Sales Ops, Growth-Teams, Marktforscher:innen und Entwickler:innen, die Website-Daten über eine API brauchen, ohne einen Scraping-Stack bauen und betreiben zu müssen.
Preis: , einschließlich bis zu 600 Distill-Seiten oder 30 Extract-Seiten, mit 2 gleichzeitigen Anfragen. Starter ist mit 16 $/Monat bei jährlicher Abrechnung gelistet für 60.000 API-Einheiten/Jahr und 30 gleichzeitige Anfragen. Pro ist mit 40 $/Monat bei jährlicher Abrechnung gelistet für 600.000 API-Einheiten/Jahr und 50 gleichzeitige Anfragen.
Einrichtungsgeschwindigkeit: ca. 5–15 Minuten, um einen API-Schlüssel zu erhalten und mit cURL, SDKs oder der die erste Distill- oder Extract-Anfrage auszuführen.
Nachteile: Thunderbit ersetzt Datadog, New Relic, Better Stack oder Checkly nicht für Uptime-Checks, Incident-Eskalation, Traces, Logs oder On-Call-Routing. Betrachte es als die API, mit der du Webdaten sammelst und strukturierst — inklusive Vendor-Preisen, Dokus, Wettbewerberseiten, Produktlisten oder öffentlichen Datensätzen — nicht als das System, das deine On-Call-Ingenieur:innen alarmiert.
Datadog: Am besten für Full-Stack-Transparenz
Datadog ist das Tool, das ich in Enterprise- und Mid-Market-SaaS-Stacks immer wieder sehe — aus gutem Grund. Es ist nicht nur API-Monitoring, sondern eine vollständige Observability-Plattform, die synthetische API-Tests mit Distributed Traces, Logs, Infrastrukturmetriken und Real User Monitoring in einer Ansicht verbindet.
Speziell für API-Monitoring unterstützt Datadog HTTP, SSL, DNS, WebSocket, TCP, UDP, ICMP, gRPC und . Die lernen erwartete Muster und alarmieren bei Abweichungen statt bei statischen Schwellenwerten — ein deutlicher Fortschritt gegenüber "Alarm, wenn die Latenz > 500 ms ist". Außerdem bietet es , die vorhersagen, wann ein Metrikwert einen Schwellenwert reißen wird, sowie Composite-Monitore, die mehrere Bedingungen kombinieren.
Geeignet für: E-Commerce-, SaaS- und Enterprise-Teams, die eine einheitliche Sicht über APIs, Infrastruktur, Logs und Traces brauchen.
Preis: Details zum Free-Tier variieren je nach Produkt. ; synthetische API-Tests kosten 5 $ pro 10.000 Runs. 800+ Integrationen.
Einrichtungsgeschwindigkeit: ca. 15–30 Minuten für Agent-Installation plus einen einfachen Synthetic Test.
Nachteile: Kann im großen Maßstab teuer werden — "Bill Shock" ist ein wiederkehrendes Thema auf Hacker News und Reddit. Die schiere Zahl an SKUs (Hosts, Logs, Custom Metrics, Synthetics, Nutzer:innen) bedeutet, dass jemand die Rechnung im Blick behalten muss, nicht nur die Dashboards. Die Lernkurve für die Gesamtplattform ist real.
Checkly: Am besten für developer-first Synthetic Checks
Checkly ist das Tool, das ich einem Startup-Engineering-Team geben würde, das API-Checks nahe am Code haben will. Die Kernidee lautet "Monitoring as Code": API- und Browser-Checks programmatisch definieren, von globalen Standorten aus ausführen, in CI/CD-Pipelines integrieren und alles über Git verwalten.
Der Aspekt der Alert-Qualität ist hier stark. Checklys wird ausdrücklich als "erste Verteidigungslinie" gegen False Positives beschrieben — du kannst feste, lineare oder exponentielle Retries konfigurieren, Retries am gleichen oder an einem anderen Standort sowie maximale Retry-Dauern, bevor ein Alert ausgelöst wird. Außerdem unterscheidet es zwischen degradierten, fehlgeschlagenen und wiederhergestellten Zuständen, was hilft, lärmende Pages zu reduzieren.
Geeignet für: Startups und Dev-Teams, die programmierbare API-Checks, , CI/CD-Integration und schnellen Start wollen.
Preis: Aktuelle öffentliche Daten zeigen einen Free-Plan mit 10 Uptime-Monitoren, 1.000 Browser-Checks und 10.000 API-Checks. Starter liegt bei etwa 24 $/Monat bei jährlicher Abrechnung — .
Einrichtungsgeschwindigkeit: ca. 10–20 Minuten für einen ersten API-Check und einen Alarmkanal.
Nachteile: Auf Synthetic Checks fokussiert. Kein Ersatz für tiefes APM, Log-Analysen oder Distributed Tracing. Wenn du einen API-Fehler mit einem Datenbank-Engpass korrelieren musst, brauchst du zusätzlich ein anderes Tool.
UptimeRobot: Am besten für simples, günstiges Uptime-Tracking
UptimeRobot ist der Honda Civic unter den API-Monitoring-Tools. Es macht eine Sache gut: Du legst einen HTTP-, Keyword-, Ping-, Port-, SSL- oder Heartbeat-Monitor an, wählst ein Intervall und wirst benachrichtigt, wenn er ausfällt. Das war’s.
Geeignet für: Solo-Dev:innen, kleine Teams, Agenturen oder alle, die grundlegendes Uptime- und Latenz-Tracking ohne Komplexität brauchen.
Preis: . Paid Solo etwa 7 $/Monat bei jährlicher Abrechnung. Für den Free-Plan ist keine Kreditkarte erforderlich. Einrichtungsgeschwindigkeit: ca. 2–5 Minuten — die schnellste in dieser Liste.
Nachteile: Begrenzte Alert-Intelligenz. Einfache Schwellenwert-Alerts, keine Anomalieerkennung, kein Distributed Tracing, keine tiefen Analysen. Wenn du wissen willst, warum ein Endpunkt langsam ist (und nicht nur dass er langsam ist), kommt UptimeRobot nicht weit genug.
Uptime Kuma: Das beste kostenlose self-hosted API-Monitoring-Tool
Uptime Kuma ist der Liebling der Self-Hosting-Community, und die GitHub-Zahlen geben das her: , Stand Release 2.3.2 im Mai 2026. Es ist MIT-lizenziert, unterstützt HTTP(s), Keyword, JSON Query, WebSocket, TCP, Ping, DNS, Push, Docker, mehrere Statusseiten und 90+ Benachrichtigungsdienste.
Geeignet für: Solo-Dev:innen und Teams, die volle Kontrolle, Privatsphäre und keine laufenden SaaS-Kosten wollen — sofern ein Server vorhanden ist.
Preis: Kostenlos. Die echten Kosten sind deine VM/Container, Backups, Updates und die Sicherstellung, dass der Monitor selbst verfügbar bleibt. Einrichtungsgeschwindigkeit: ca. 5–15 Minuten mit Docker für einen Basis-Check; 15–30 Minuten mit Benachrichtigungen und einer sauber gestalteten Statusseite.
Nachteile: Du bist für die Wartung verantwortlich. Und hier ist der kritische Haken: Wenn du Uptime Kuma auf derselben Infrastruktur hostest, die es überwacht, legen ein Cloud- oder DNS-Ausfall sowohl deine App als auch deinen Monitor lahm. Hoste es extern oder kombiniere es mit einem SaaS-Check.
Better Stack: Am besten für schnelle Incident-Response
Better Stack (von Nutzer:innen oft noch Better Uptime genannt) kombiniert Uptime-Monitoring mit Incident-Management, On-Call-Planung, Eskalationsrichtlinien und Statusseiten in einer Plattform. Es ist weniger stark als Analyse-Tool, dafür besonders gut als Incident-Workflow-Tool rund um das Monitoring.
legen fest, wer in welcher Reihenfolge, mit welchen Verzögerungen und bis zur Bestätigung alarmiert wird. Metadatenbasiertes Routing leitet Incidents nach Schweregrad oder Zuständigkeit weiter. Integriert sich mit Slack, Teams, Webhooks und Zapier.
Geeignet für: Startups und mittelgroße Teams, die Monitoring + Incident Response + Statusseiten möchten, ohne drei separate Tools zusammenstecken zu müssen.
Preis: . Team etwa 29 $/Monat bei jährlicher Abrechnung. Einrichtungsgeschwindigkeit: ca. 5–10 Minuten per GUI-Assistent.
Nachteile: Weniger tief in der Analyse von API-Payloads, Distributed Tracing oder Business-KPI-Analysen als Datadog, New Relic oder Moesif.
Prometheus + Grafana: Der beste Open-Source-Stack für API-Monitoring
Das ist das branchenübliche Open-Source-Duo. sammelt und speichert Zeitreihenmetriken. (73.705 GitHub-Sterne, 3.010 Mitwirkende) liefert Dashboards und Alerting. übernimmt Routing, Gruppierung, Deduplizierung, Stummschaltung und Inhibition. Für API-Endpunkt-Checks ergänzen Teams den für HTTP-, HTTPS-, DNS-, TCP-, ICMP- und gRPC-Probing.
Geeignet für: Open-Source-Purist:innen, Kubernetes-/SRE-Teams und Organisationen, die bereits auf Prometheus-Metriken standardisiert sind.
Preis: Kostenlos self-hosted. hat ein Free-Tier (100k API-Testausführungen/Monat) und nutzungsbasierte Paid-Pläne.
Einrichtungsgeschwindigkeit: 1–4 Stunden für ein grundlegendes Setup mit Blackbox + Prometheus + Grafana + Alertmanager. Für produktives HA-Setup und Alert-Tuning eher Tage.
Nachteile: PromQL, YAML, Relabeling, Dashboard-Design, Aufbewahrung, Storage, HA und Alert-Tuning sind echte Betriebsarbeit. Der wiederkehrende Kompromiss lautet: "weniger UI, mehr YAML." Das ist der Stack für Teams, die ohnehin in Metriken denken und eine Steuerzentrale wollen — nicht für Teams, die das Monitoring bis zum Mittagessen online haben möchten.
New Relic: Am besten für SaaS-Application-Performance
New Relic kombiniert APM, Infrastruktur-Monitoring, Logs, Distributed Tracing, Synthetic Monitoring, Alerts, Dashboards und KI-gestützte Incident-Analyse. Das Free-Tier — — ist für kleine Teams wirklich großzügig.
Bei der Diskussion um Alarmmüdigkeit glänzt New Relic mit seiner Alert-Intelligenz. Die umfasst Event-Korrelation, Anomalieerkennung, Predictive Alerts, Root-Cause-Analyse und Flapping-Unterdrückung. New Relic hat ein Beispiel veröffentlicht, in dem — das ist eine konkrete Zahl zur Lärmreduktion.
Geeignet für: SaaS-Teams und E-Commerce-Plattformen, die API-Monitoring eng mit Application-Traces, Fehlern, Durchsatz und Nutzerwirkung verbinden wollen.
Preis: Kostenlos: 100 GB/Monat, 1 Full User. Paid basiert auf Nutzer- und Datennutzung.
Einrichtungsgeschwindigkeit: ca. 15–30 Minuten für Agent-Installation und geführtes Setup.
Nachteile: Preise können im großen Maßstab komplex werden. Die Alert-Konfiguration hat eine Lernkurve — die Plattform ist leistungsstark, aber nicht sofort selbsterklärend.
Moesif: Am besten für API-Analysen und Business-Metriken
Moesif ist kein klassischer Uptime-Monitor. Es ist API-Analytics und Produkt-Intelligence: Nutzung von APIs nach Kunde, Endpunkt, Kohorte, Unternehmen, Geografie, SDK, Plan und Verhalten verstehen. Wenn deine Frage eher lautet "Welcher Kunde ist betroffen?" als "Ist der Endpunkt online?", ist Moesif genau dafür gebaut.
Es unterstützt für API-Metriken wie Traffic-Spitzen/-Einbrüche, Latenz und Verhaltensänderungen. Die dynamischen Alerts brauchen ein paar Tage API-Verhalten, um ein Modell aufzubauen, fangen danach aber Änderungen ab, die statische Regeln verpassen.
Geeignet für: API-Produktteams, SaaS-Unternehmen und E-Commerce-Plattformen, die API-Performance mit Umsatz, Engagement und Retention verbinden müssen.
Preis: ; Paid-Pläne skalieren mit dem Volumen an API-Events. Konkrete Self-Service-Preise waren in meiner Recherche nicht vollständig auslesbar — bitte die aktuelle Seite prüfen.
Einrichtungsgeschwindigkeit: ca. 20–45 Minuten (SDK-/Proxy-/Gateway-Integration ist tiefer als ein externer Ping).
Nachteile: Stärker analyseorientiert als klassisches Uptime-Monitoring. Wahrscheinlich willst du Moesif mit Checkly, UptimeRobot oder Datadog Synthetics für externe Verfügbarkeitschecks kombinieren.
Splunk: Am besten für Enterprise-Loganalyse und Compliance
Splunk ist das Tool, das man nimmt, wenn Log-Aggregation, Suche, Korrelation, prüfungsfeste Nachvollziehbarkeit und Hybrid-/Multi-Cloud-Support nicht verhandelbar sind. deckt Infrastruktur, APM, Synthetics, Real User Monitoring, Logs und Incident Response ab. kann auffällige Ereignisse zu Episoden bündeln und Lärm über Monitoring-Silos hinweg reduzieren.
Splunks eigene ist ernüchternd: , und .
Geeignet für: Enterprise- und Multi-Cloud-Teams mit strengen Anforderungen an Compliance, Sicherheit, Audit und Logsuche.
Preis: Nutzungsbasiert und meist mit Angebot. Kein einfaches Free-Tier für den produktiven Einsatz.
Einrichtungsgeschwindigkeit: Cloud-Onboarding kann schneller sein, aber Enterprise-Deployments dauern oft Tage bis Wochen.
Nachteile: Teuer im großen Maßstab. Komplexe Einrichtung. Für Solo-Dev:innen und kleine Startups überdimensioniert.
Postman: Am besten für Teams, die ohnehin bereits APIs testen
Postman ist in erster Linie eine Plattform für API-Entwicklung und -Tests, aber das erlaubt es Teams, Postman-Collections zu planen und aus Cloud-Standorten auszuführen. Das stärkste Argument ist die Wiederverwendung: Wenn dein QA- oder Dev-Team bereits Postman-Collections mit Assertions hat, ist daraus ein Monitor der logische nächste Schritt.
Geeignet für: Dev- und QA-Teams, die Postman-Collections bereits nutzen und geplante Checks möchten, ohne ein separates Synthetic-Tool zu kaufen.
Preis: Free-Tier vorhanden. ; Zusatzpaket mit 50.000 Aufrufen für 20 $/Monat. Bitte die prüfen — die Paketierung ändert sich bei Postman.
Einrichtungsgeschwindigkeit: ca. 10 Minuten, wenn Collections bereits existieren.
Nachteile: Die Monitoring-Funktionen sind leichtergewichtig als bei dedizierten Tools wie Checkly, Datadog oder New Relic. Die Alarmoptionen sind einfach.
Weitere API-Monitoring-Tools, die sich lohnen
: Leichtgewichtiges, self-hosted, konfigurationsgetriebenes Health-Dashboard. , unterstützt HTTP, ICMP, TCP, DNS, Prometheus-freundliche Metriken und Uptime-Badges. Sehr gut für Solo-Dev:innen, die etwas Einfacheres als Prometheus wollen, aber YAML/Config-as-Code der UI von Uptime Kuma vorziehen.
: Neueres Tool mit Fokus auf API-Traffic-Analysen und Qualitäts-Tracking für Startups. Behauptet mit benutzerdefinierten Alerts über 14 Metriken hinweg. Gut für leichtgewichtige API-Analysen ohne eine vollständige Observability-Plattform einzuführen.
: Full-Stack-Monitoring mit Logs, Synthetics und Infrastruktur-Transparenz. . Eine günstigere Datadog-Alternative für Mid-Market-Teams.
: OpenTelemetry-natives Backend für APM, Tracing, Metriken und Logs. . Kein reiner Uptime-Checker, aber ideal für Teams, die auf OTel standardisieren und ein Open-Source-freundliches Tracing-Backend wollen.
Build vs. Buy: Solltest du dein eigenes API-Monitoring bauen?
"Soll ich einfach ein Script schreiben, das meine Endpunkte anpingt, oder ein dediziertes Tool nutzen?"
Diese Frage taucht in Entwicklerforen ständig auf. Ich habe genug Reddit-Threads gelesen, um das Muster klar zu sehen: Teams starten mit curl + cron, das funktioniert eine Weile gut — und wechseln dann, sobald sie Dashboards, historische Daten, Multi-Region-Checks, zuverlässiges Alert-Routing oder teamübergreifende Transparenz brauchen.
Eine ehrliche Entscheidungs-Matrix:
| Faktor | Eigenes Script | Spezialisiertes Tool |
|---|---|---|
| Einrichtungszeit | 1–4 Stunden (einfach); Tage (robust) | 5–30 Minuten |
| Wartung | Für immer deine Verantwortung | Anbieter kümmert sich um Updates |
| Alert-Qualität | Einfach (Up/Down) | Smart (Latenztrends, Anomalien, Retries) |
| Kosten | Kostenlos (deine Zeit) | 0–500+ $/Monat |
| Dashboard | Von Grund auf bauen | Vorgefertigt, anpassbar |
| Am besten, wenn… | ≤3 Endpunkte, Dev-lastiges Team, Hobbyprojekt | 5+ Endpunkte, Ops-/Produktteam, Umsatz steht auf dem Spiel |
Die wichtigste Erkenntnis aus Foren: Wer sein Monitoring selbst baut, bereut das oft, sobald Dashboards, historische Daten oder teamübergreifende Sichtbarkeit gebraucht werden. Und es gibt das Meta-Problem: "Du brauchst Monitoring für dein Monitoring." Ein self-hosted Monitor, eine Datenbank, Backups, der Netzwerkpfad und der Alert-Anbieter selbst müssen ebenfalls zuverlässig sein.
Baue selbst, wenn du 2 Endpunkte hast und gern tüftelst. Kaufe, wenn du ein Produkt ausliefern willst.
Die gleiche Logik gilt für Webdaten-Extraktion. Du kannst einen Scraper schreiben, Headless-Browser ausführen, Proxys rotieren, Selektoren pflegen, HTML bereinigen und eine Queue bauen. Aber wenn die Aufgabe darin besteht, Webdaten zuverlässig in ein API-Produkt, einen AI-Agenten oder einen Research-Workflow zu füttern, ist der Einsatz von meist schneller, als die eigene Scraping-Infrastruktur hochzuziehen.
Alert-Müdigkeit: Warum Alert-Qualität wichtiger ist als Alert-Menge
Das ist vielleicht das am meisten unterschätzte Kriterium bei der Wahl eines API-Monitoring-Tools. Alert-Müdigkeit entsteht, wenn Teams so viele laute, doppelte oder nicht handlungsrelevante Alerts bekommen, dass sie irgendwann alle ignorieren — und dann echte Vorfälle übersehen.
Die Zahlen sind auffällig. Ein ergab, dass die Median-Organisation und erzeugte. Die mediane Handlungsfähigkeit von Incidents lag nur bei — also waren weniger als einer von fünf alert-basierten Incidents tatsächlich handlungsrelevant. Eine zeigte, dass und .
Das beste Monitoring-Tool ist das, dessen Alerts du wirklich vertraust. Ein Vergleich, wie die Tools mit Alert-Intelligenz umgehen:
| Tool | Alert-Typ | Methode zur Lärmreduktion | Alert-Kanäle |
|---|---|---|---|
| Datadog | ML-Anomalie, Forecast, Composite | Historische Anomaliebänder, dynamische Baselines, Watchdog AI | Slack, PagerDuty, Opsgenie, Teams, 20+ |
| Checkly | Schwellenwert + Degradierung | Retry vor Auslösung, Retries am gleichen/anderen Standort | Slack, PagerDuty, Opsgenie, Teams, incident.io |
| New Relic | KI-Bündelung von Issues, Anomalie, Predictive | Event-Korrelation, Flapping-Unterdrückung, Root-Cause-Kontext | Slack, PagerDuty, Teams, Webhooks |
| Moesif | Verhaltensanomalie | Dynamische Modelle nach mehreren Tagen Verhalten | Slack, PagerDuty, E-Mail, SMS |
| Better Stack | Uptime/Incident/On-Call | Eskalationsrichtlinien, Zuständigkeitsrouting, Verzögerungen | Slack, Teams, Webhooks, Zapier |
| Prometheus + Alertmanager | PromQL-Regel-Alerts | Gruppierung, Deduplizierung, Stummschaltung, Inhibition | E-Mail, PagerDuty, Opsgenie, Webhooks |
| Splunk | Ereignisse, Episoden, Service Health | ITSI Event Analytics, Episoden-Bündelung, Ticketing | Splunk On-Call, ServiceNow, Webhooks |
| Thunderbit Open API | Keine Alerting-Plattform | Mit eigenem Scheduler, Workflow-Tool oder Monitoring-Stack verwenden | Webhooks für Batch-Jobs; Alerts extern behandelt |
Praktischer Rat: Starte mit weniger, aber zuverlässigeren Alerts. Nutze Retry-vor-Auslösung, Bestätigung über mehrere Regionen, SLO-Burn-Rate-Alerts, Deduplizierung und zuständigkeitsbasiertes Routing. Alarme auf Nutzerwirkung und geschäftskritische Flows ausrichten (Checkout-Fehler, Auth-Fehler, Payment-5xx), nicht auf jedes interne Symptom.
Kostenlose Tarife und Preise 2026: Was du tatsächlich zahlst
Preisseiten ändern sich. Free-Tiers verschieben sich. Versteckte Kosten (Hosts, Seats, Logs, Synthetic Runs, Daten-Ingest) können überraschen. Dieser Abschnitt hätte auf jedem "beste Tools"-Artikel stehen sollen. Der Stand für 2026:
| Tool | Free-Tier | Preis ab | Kreditkarte erforderlich? | Bester kostenloser Anwendungsfall |
|---|---|---|---|---|
| Thunderbit Open API | 600 einmalige API-Einheiten | ca. 16 $/Monat bei jährlicher Abrechnung | Nein | Webdaten-Extraktion für LLMs, RAG, Preise und Research |
| Uptime Kuma | Unbegrenzt (self-host) | — | Nein | Vollständiges Monitoring, eigener Server |
| UptimeRobot | 50 Monitore, 5-Minuten-Intervalle | ca. 7 $/Monat | Nein | Einfache Uptime-Checks |
| Better Stack | 10 Monitore, 1 Statusseite | ca. 29 $/Monat | Nein | Startup-Uptime + Statusseite |
| Checkly | 10 Uptime, 10k API-Checks | ca. 24 $/Monat | Ja | Synthetic API-Checks |
| Postman | Kostenloses Konto + Monitoring-Kontingent | ca. 14 $/Nutzer/Monat | Nein | Vorhandene Collections wiederverwenden |
| Prometheus + Grafana | Unbegrenzt (self-host) | — | Nein | Metriken + Visualisierung |
| Grafana Cloud | 100k API-Testausführungen/Monat | 29 $/Monat Plattform + Nutzung | Prüfen | Verwalteter Synthetics-Test |
| New Relic | 100 GB/Monat, 1 Full User | pro Nutzer + Daten | Einige Pläne | APM + grundlegende Observability |
| Datadog | Test/je nach Produkt unterschiedlich | 15 $/Host/Monat (Infra Pro) | Oft ja | Bewertung des Full-Stack-Setups |
| Moesif | Kostenlos/Test verfügbar | volumenbasiert | Prüfen | Bewertung von API-Analysen |
| Splunk | Tests verfügbar | Angebot | Vertriebsprozess | Enterprise Proof of Concept |
| Gatus | Unbegrenzt (self-host) | — | Nein | YAML-gesteuertes Status-Dashboard |
| Apitally | Kostenlos/Test verfügbar | Prüfen | Prüfen | Leichtgewichtige API-Analysen |
| Sematext | Test/Free variiert | ca. 2 $/HTTP-Monitor | Prüfen | Günstigere Synthetics/Logs |
| Uptrace | Kostenlos self-hosted | Cloud-Tiers variieren | Prüfen | OTel-APM-Bewertung |
Hinweis zu versteckten Kosten: Self-hosted Tools (Uptime Kuma, Prometheus, Gatus) sind lizenzrechtlich "kostenlos", aber eine kleine VM, Backups, Wartungszeit und externes Failover können schnell die echten Kosten werden. Bei Webdaten-APIs ist der versteckte Aufwand meist anderer Natur: Headless-Browser pflegen, kaputte Selektoren reparieren, Proxy-Pools betreiben, Anti-Bot-Umgehungen und HTML-Bereinigung.
Schätzung für kleine Teams: Für 10 API-Endpunkte und 3 Teammitglieder ist der günstigste SaaS-Weg meist UptimeRobot Free oder ein günstiger Paid-Plan, Better Stack Free/Team oder Checkly, wenn das Ausführungsvolumen passt. Datadog und New Relic können für Evaluierungen erschwinglich sein, aber die echte Rechnung hängt von Hosts, Nutzer:innen, Logs, Traces und Synthetic-Run-Volumen ab. Wenn dein Projekt Website-Daten als API braucht, reichen die kostenlosen API-Einheiten von Thunderbit aus, um den Workflow vor einem Paid-Plan zu testen.
Scorecard zur Einrichtungs-Komplexität: Wie schnell bis zum ersten Alert?
Kein Konkurrenzartikel, den ich gefunden habe, bewertet die Time-to-Value — also wie lange es von der Anmeldung bis zum ersten sinnvollen Alert dauert. Für kleinere Teams ist das oft wichtiger als tiefe Features.
| Tool | Zeit bis zum ersten Alert | Erforderliches technisches Niveau | Konfigurationsansatz |
|---|---|---|---|
| Thunderbit Open API | ca. 5–15 Minuten | Niedrig–Mittel | API-Schlüssel, cURL/SDK/CLI |
| UptimeRobot | ca. 2–5 Minuten | Niedrig | GUI, Klick-zu-hinzufügen |
| Better Stack | ca. 5–10 Minuten | Niedrig | GUI-Assistent |
| Checkly | ca. 10–20 Minuten | Niedrig–Mittel | Code oder GUI |
| Postman | ca. 10 Minuten (mit Collections) | Niedrig–Mittel | Collection-Scheduler |
| Uptime Kuma | ca. 5–30 Minuten | Mittel | Docker + GUI |
| Gatus | ca. 15–45 Minuten | Mittel | YAML + Docker |
| Datadog | ca. 15–30 Minuten | Mittel | Agent-Installation + GUI |
| New Relic | ca. 15–30 Minuten | Mittel | Agent + geführtes Setup |
| Moesif | ca. 20–45 Minuten | Mittel | SDK-/Proxy-Integration |
| Grafana Cloud Synthetics | ca. 15–45 Minuten | Mittel | GUI, Terraform optional |
| Prometheus + Grafana | 1–4 Stunden | Mittel–Hoch | YAML, PromQL |
| Uptrace | 30–90 Minuten | Mittel–Hoch | OTel-SDK-Integration |
| Splunk | Stunden bis Wochen | Hoch | Enterprise-Onboarding |
Wenn Monitoring bis Tagesende live sein muss, starte in der oberen Hälfte dieser Tabelle. Wenn das Ziel eine langlebige Plattform-Observability ist, plane dafür ein separates Projekt in der unteren Hälfte. Und wenn dein erstes Meilensteinziel lautet: "Hole saubere Daten von diesen 100 Webseiten in eine App", dann starte mit Thunderbit, bevor du eigene Scraping-Infrastruktur baust.
Die besten API-Monitoring-Tools im direkten Vergleich
Eine Tabelle zum schnellen Scannen, bevor du dich entscheidest:
| Tool | Bester Anwendungsfall | Free-Tier | Alert-Intelligenz | Einrichtungszeit | Hosting | Herausragendes Feature |
|---|---|---|---|---|---|---|
| Thunderbit Open API | Webdaten-Extraktion/API-Datenpipelines | 600 API-Einheiten | Kein Alerting-Tool | 5–15 Min | Cloud | Seiten in Markdown verdichten oder schema-basiertes JSON extrahieren |
| Datadog | Full-Stack Enterprise/SaaS | Test/variiert | Anomalie, Forecast, KI | 15–30 Min | Cloud | Verknüpft Synthetics mit Logs/Traces/Infra |
| Checkly | Developer-first Synthetics | Großzügig, auf Checks basierend | Retries, Degradierung | 10–20 Min | Cloud | Monitoring as Code + Playwright |
| UptimeRobot | Einfaches Uptime-Monitoring | 50 Monitore | Einfache Schwellenwerte | 2–5 Min | Cloud | Schnellster günstiger Basis-Monitor |
| Uptime Kuma | Kostenlos self-hosted | Unbegrenzt | Einfache Status-/Schwellenwerte | 5–30 Min | Self-hosted | Saubere UI, keine SaaS-Gebühr |
| Better Stack | Incident Response/Statusseiten | 10 Monitore | Eskalationen, Routing | 5–10 Min | Cloud | Monitoring + On-Call + Statusseite |
| Prometheus + Grafana | Open-Source-Metrik-Stack | Unbegrenzt (self-host) | Alertmanager-Gruppierung | 1–4 Std | Self-hosted/Cloud | Tiefe im PromQL-Ökosystem |
| New Relic | SaaS APM + API-Checks | 100 GB/Monat, 1 Nutzer | KI-Gruppierung, Flapping-Unterdrückung | 15–30 Min | Cloud | Starkes APM + Synthetics zusammen |
| Moesif | API-Analysen/Business-Metriken | Kostenlos/Test | Verhaltensanomalien | 20–45 Min | Cloud | API-Verhaltensanalysen pro Kunde |
| Splunk | Enterprise-Logs/Compliance | Test | ITSI-Episoden, AIOps | Tage+ | Cloud/self-managed | Enterprise-Logsuche und Governance |
| Postman | Teams, die APIs schon testen | Kostenloses Konto | Einfache Monitor-Alerts | 10 Min | Cloud | Wiederverwendung von API-Test-Collections |
Wie Thunderbit deine Evaluierung von API-Tools beschleunigen kann
Vollständige Offenlegung: ist kein API-Monitoring-Tool — es ist ein KI-Web-Scraper und , um Webseiten in sauberes Markdown oder strukturiertes JSON zu verwandeln. Genau deshalb ist es an einer anderen Stelle im Entscheidungsprozess nützlich: beim Sammeln von Vendor-Preisen, Plan-Limits, Feature-Versprechen, Doku-Details und Integrationslisten, bevor du dich für eine Plattform entscheidest.
Anstatt 10+ Preisseiten von Anbietern manuell zu öffnen und Plan-Namen, Monitor-Limits, Prüfintervalle, Integrationen und Kreditkartenanforderungen in eine Tabelle zu kopieren, haben wir die verwendet, um strukturierte Daten aus den Preis- und Feature-Seiten jedes Tools zu extrahieren. Thunderbits KI liest jede Seite und schlägt Felder vor — Planname, Details zum Free-Tier, Preis, unterstützte Integrationen — und strukturiert die Ausgabe dann in eine exportierbare Tabelle.
Für Entwickler-Workflows gibt dir die dasselbe Prinzip programmatisch. Nutze Distill, wenn du sauberes Markdown für LLMs oder RAG brauchst. Nutze Extract, wenn du bestimmte Felder als JSON zurückhaben willst. Nutze Batch, wenn du eine Liste von Preis-Seiten, Dokumentations-URLs, Produktseiten oder Wettbewerberseiten verarbeiten und die Ergebnisse asynchron erhalten möchtest.
Der Workflow:
- Öffne die Preisseite eines Anbieters (Datadog, Checkly, UptimeRobot usw.)
- Klicke auf "AI Suggest Fields" — Thunderbit schlägt auf Basis des Seiteninhalts Spalten vor
- Klicke auf "Scrape" — die Daten werden in eine strukturierte Tabelle gefüllt
- Nutze das Subpage-Scraping, um Preis-, Feature- und Doku-Seiten jedes Anbieters abzurufen
- Exportiere nach Google Sheets, Excel, Airtable, Notion oder CSV
Für API-First-Teams ist der API-Workflow genauso direkt:
- Hol dir einen kostenlosen API-Schlüssel bei Thunderbit
- Rufe den Distill-Endpunkt auf, um sauberes Markdown von jeder öffentlichen Seite zu erhalten
- Rufe den Extract-Endpunkt mit Schema-Beschreibungen für strukturiertes JSON auf
- Nutze Batch-Endpunkte und Webhooks für größere URL-Listen
- Spiele die Ausgabe in deine App, Tabelle, dein Data Warehouse, die Vektordatenbank oder den Monitoring-Workflow ein
Bei einem Vergleich über 10+ Anbieter kann manuelles Copy-Paste leicht 2–3 Stunden dauern, wenn Preis-Unterseiten, Dokus und Integrationsseiten dazukommen. Thunderbit hat unseren Erst-Durchlauf der Extraktion auf ungefähr 15–30 Minuten verkürzt; die restliche Zeit floss in Prüfung und Abwägungen. Wenn dein Ops-, Procurement-, Research- oder AI-Produktteam unter Zeitdruck Tools evaluiert, ist das ein praktischer Shortcut. Mehr dazu findest du in unserem Leitfaden zum , auf unserer Seite zu den oder auf unserem mit Walkthroughs.
So wählst du das beste API-Monitoring-Tool für dein Team aus
Das "beste" API-Monitoring-Tool hängt von Teamgröße, technischer Tiefe, Budget und davon ab, wie ein Fehler in deinem Produkt aussieht.
Ein Solo-Dev braucht kein Splunk. Ein reguliertes Unternehmen sollte sich nicht auf einen Cronjob verlassen. Ein API-Produktteam braucht vielleicht eher Moesif-artige Kundenanalysen als reine Uptime-Pings. Ein E-Commerce-Team sollte kritische Pfad-Checks für Login, Suche, Warenkorb, Checkout und Payment-Autorisierung priorisieren. Ein KI- oder Datenproduktteam braucht möglicherweise erst Thunderbit-artige Webdaten-Extraktion, bevor es vollständige Observability benötigt.
Drei Prinzipien, die sich in meiner gesamten Recherche bestätigt haben:
- Pass das Tool an deinen Anwendungsfall an. Die Schnellwahl-Tabelle gibt es nicht ohne Grund — fang dort an.
- Priorisiere Alert-Qualität vor Alert-Menge. Wenn dein Team Alerts ignoriert, hast du kein Monitoring. Du hast Lärm.
- Unterschätze die Einrichtungszeit nicht. Ein Monitor, der heute live geht und vertrauenswürdige Alerts sendet, ist besser als ein perfekter Plattformplan, der den Checkout noch einen Monat unüberwacht lässt.
Wenn du mehrere Tools gleichzeitig vergleichst und die Recherche beschleunigen willst, probiere aus, um Vendor-Daten gesammelt in eine einzige Tabelle zu extrahieren. Wenn du ein API-Produkt, eine RAG-Pipeline, einen AI-Agenten oder einen Market-Intelligence-Workflow baust, der saubere Webdaten braucht, beginne mit . Es wählt das Monitoring-Tool nicht für dich aus — aber es bringt dich schneller zur Entscheidung und kann deinem eigenen Produkt eine zuverlässige Webdaten-Schicht geben.
FAQs zu den besten API-Monitoring-Tools
Was ist 2026 das beste kostenlose API-Monitoring-Tool?
Für SaaS-Einfachheit bietet UptimeRobot 50 kostenlose Monitore mit 5-Minuten-Intervallen, ohne dass eine Kreditkarte nötig ist. Für self-hosted Kontrolle ist Uptime Kuma Open Source, unbegrenzt und hat eine saubere UI mit 90+ Benachrichtigungsdiensten. Für Teams, die metrische Tiefe wollen und bereits technisches Know-how haben, ist Prometheus + Grafana + Alertmanager der beste Open-Source-Stack — allerdings dauert die Einrichtung Stunden, nicht Minuten.
Wenn dein Ziel nicht Uptime-Monitoring, sondern Webdaten-Extraktion über eine API ist, hat Thunderbit Open API ein Free-Tier mit 600 einmaligen API-Einheiten. Das reicht, um die Verdichtung von Seiten in Markdown oder die schema-basierte JSON-Extraktion vor dem Skalieren zu testen.
Was ist der Unterschied zwischen API-Monitoring und APM?
API-Monitoring prüft von außen Verfügbarkeit, Antwortzeit, Fehler und Korrektheit eines Endpunkts — es simuliert, was Nutzer:innen oder Integrationen erleben. APM (Application Performance Monitoring) geht tiefer ins Innere der Anwendung: Code-Traces, Datenbankabfragen, Laufzeitfehler, Queue-Latenzen und Service-Abhängigkeiten. Tools wie Datadog und New Relic bieten beides; UptimeRobot und Uptime Kuma konzentrieren sich auf externe Uptime-Checks.
Thunderbit Open API ist anders als beides: Es ist eine Webdaten-Extraktions-API. Sie hilft dir, externe Websites in Markdown oder strukturiertes JSON zu verwandeln — nützlich für LLM-Apps, Research-Workflows, Preis-Intelligence und Datenpipelines.
Wie oft sollte ich meine APIs überwachen?
Produktive, umsatzkritische APIs (Checkout, Auth, Payments) sollten typischerweise jede Minute geprüft werden. Interne oder wenig frequentierte APIs können oft alle 5 Minuten geprüft werden. Aber Frequenz allein ist nicht alles — nutze Retries, mehrere Regionen und aussagekräftige Assertions, damit jeder Check schnell und vertrauenswürdig ist. Ein 1-Minuten-Check mit Fehlalarmen ist schlechter als ein vertrauenswürdiger 5-Minuten-Check.
Bei Webdaten-Extraktions-Workflows hängt die Frequenz davon ab, wie oft sich die Quelle ändert. Preis-Seiten brauchen vielleicht tägliche oder wöchentliche Extraktion. Schnelllebige Bestands-, Reise- oder Marktplatzdaten brauchen eventuell stündliche oder noch häufigere Aktualisierungen. Thunderbits Batch-API und Webhooks sind nützlich, wenn du viele URLs nach Zeitplan verarbeiten musst.
Kann ich APIs überwachen, ohne Code zu schreiben?
Ja. UptimeRobot, Better Stack und Uptime Kuma lassen sich komplett über GUIs nutzen. Checkly unterstützt sowohl GUI- als auch Code-basierte Einrichtung. Postman arbeitet mit einer Collection-basierten Oberfläche. Prometheus/Grafana erfordern normalerweise YAML und PromQL. Datadog und New Relic können über geführtes Setup starten, werden aber mit tieferer Instrumentierung deutlich leistungsfähiger.
Wenn du Website-Daten ohne Code extrahieren möchtest, ist die Chrome-Erweiterung von Thunderbit der No-Code-Weg. Wenn du denselben Workflow aus einer Anwendung heraus automatisieren willst, bietet dir die Distill-, Extract- und Batch-Endpunkte.
Wie reduziere ich Alert-Müdigkeit beim API-Monitoring?
Wähle Tools mit smarter Alarmierung: Anomalieerkennung (Datadog, New Relic), Retry-vor-Auslösung (Checkly), Verhaltensanomalien (Moesif) oder Gruppierung/Stummschaltung (Prometheus Alertmanager). Starte mit weniger, aber zuverlässigeren Alerts mit Fokus auf sichtbare Nutzerwirkung. Nutze SLO-Burn-Rate-Alerts statt statischer Schwellenwerte, dedupliziere über Services hinweg, route nach Zuständigkeit und messe die Handlungsfähigkeit — wenn weniger als 20 % deiner Alerts zu echtem Handeln führen, reduziere zuerst den Lärm.
Mehr erfahren