Lass mich dich mal kurz mitnehmen zu meinen ersten Schritten im Web-Scraping: Es war 2015, ich saß in einer kleinen Bude in New Jersey, der dritte Kaffee dampfte neben mir, und ich verzweifelte an einem Python-Skript, das jedes Mal abstürzte, sobald sich das Layout der Zielseite änderte. Meine Werkzeuge damals? Beautiful Soup und Selenium. Spulen wir ins Jahr 2025 vor: Die Debatte „Beautiful Soup vs Selenium“ ist immer noch ein Thema – aber durch KI hat sich alles komplett gewandelt. Moderne Tools analysieren nicht mehr nur HTML, sondern verstehen Inhalte, navigieren wie ein Mensch durch Links, holen sich strukturierte Daten per natürlicher Sprache und können diese sogar direkt bereinigen, zusammenfassen oder übersetzen.

Web-Scraping ist heute längst nicht mehr nur ein Nerd-Thema. Es ist ein fester Bestandteil in Vertrieb, Marketing, E-Commerce und Operations, wenn aktuelle, strukturierte Daten gefragt sind – und zwar sofort. Der Markt für Web-Scraping-Software ist mittlerweile über schwer, und neue KI-gestützte Tools wie bringen frischen Wind rein. Die Frage ist heute nicht mehr nur: „Welcher Python Web-Scraper ist der richtige?“ Sondern: „Wie komme ich am schnellsten, einfachsten und ohne Technikfrust an meine Daten?“ Schauen wir uns also das Duell Beautiful Soup vs Selenium an – und wie KI die Spielregeln verändert.
Beautiful Soup vs Selenium: Wo liegen die Unterschiede?
Wer schon mal nach „python web scraper“ gesucht hat, ist garantiert über und gestolpert. Aber was unterscheidet die beiden eigentlich?
Stell dir Beautiful Soup wie eine extrem effiziente Bibliothekarin vor: Es ist eine Python-Bibliothek, die Daten aus statischem HTML oder XML herauszieht. Wenn die Infos schon im Quelltext der Seite stehen, findet Beautiful Soup sie, sortiert sie und liefert sie sauber aufbereitet. Es ist schnell, schlank und braucht keine „Sicht“ auf die Seite – es liest einfach den Roh-HTML-Code.
Selenium dagegen ist wie ein Roboter-Praktikant, der einen echten Browser bedienen kann. Es automatisiert Klicks, das Ausfüllen von Formularen, Logins, Scrollen und wartet auf das Laden von JavaScript. Selenium ist immer dann gefragt, wenn Daten erst nach Interaktionen oder durch dynamisches JavaScript erscheinen.
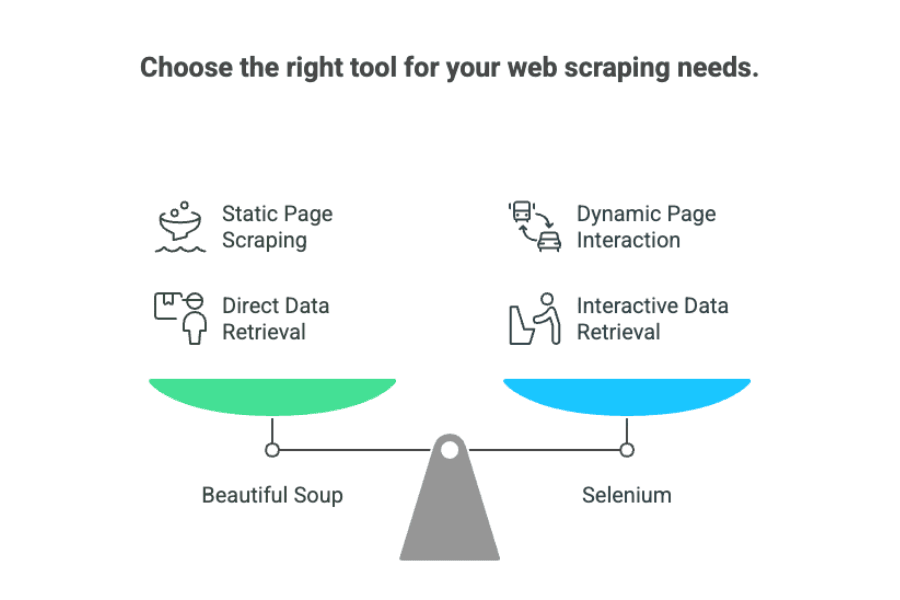
Kurz gesagt:
- Beautiful Soup: Optimal für statische Seiten, bei denen die Daten direkt im HTML stehen.
- Selenium: Die richtige Wahl für dynamische Webseiten, die Interaktionen oder das Nachladen von Inhalten brauchen.
Für Business-Anwender kann man es so sehen:
- Beautiful Soup ist wie das Abschreiben aus einem gedruckten Katalog.
- Selenium ist, als würde man jemanden in den Laden schicken, der im Katalog blättert, ein paar Knöpfe drückt und die aktuellen Preise holt.
Typische Herausforderungen: Grenzen von Beautiful Soup und Selenium
Kommen wir zu den Stolpersteinen. Nach vielen Stunden mit kaputten Scraper-Skripten kann ich sagen: Das sind die größten Probleme bei Beautiful Soup und Selenium:
1. Empfindlichkeit gegenüber Webseiten-Änderungen
Beide Tools sind extrem sensibel, wenn sich der Seitenaufbau ändert. Ändert der Betreiber eine Klassenbezeichnung oder verschiebt ein div, ist der Scraper oft sofort hinüber. Wie : „Die Wartungskosten können das Zehnfache der Entwicklungskosten betragen.“ Autsch.
2. Geschwindigkeit (oder deren Fehlen)
- Beautiful Soup ist beim Parsen flott, aber bei tausenden Seiten summiert sich die Zeit.
- Selenium ist deutlich langsamer: Jede Seite braucht einen Browser-Start, das Laden von Skripten und Interaktionen. Skalierung heißt viele Browser-Instanzen – das frisst Ressourcen.
3. Kaum Wiederverwendbarkeit von Code
Jede Webseite ist anders. Für jede neue Seite braucht es eigene Parsing-Logik, und bei Änderungen fängt man oft von vorne an. Ein universelles Skript gibt’s nicht.
4. Technische Komplexität
Beide Tools setzen Python-Kenntnisse, Wissen über HTML/CSS-Selektoren und (bei Selenium) Browser-Treiber voraus. Für Nicht-Entwickler ist das eine hohe Einstiegshürde.
5. Hoher Wartungsaufwand
Scraper am Laufen zu halten, ist ein Dauerjob. Webseiten ändern sich, Anti-Bot-Maßnahmen werden strenger, und die Skripte müssen ständig überwacht und angepasst werden. Für Unternehmen heißt das: Abhängigkeit von Entwicklern oder Outsourcing.
Jenseits klassischer Python Web-Scraper: Der Aufstieg KI-basierter Lösungen
Jetzt wird’s spannend: In den letzten Jahren sind KI-basierte Web-Scraper entstanden – Tools, die mit großen Sprachmodellen (wie GPT) Webseiten „lesen“ und Daten extrahieren, ganz ohne Programmierung.
Thunderbit: KI-Web-Scraper für Unternehmen
ist eine Chrome-Erweiterung, mit der du jede Webseite in nur zwei Klicks auslesen kannst. Kein Python, kein Code, keine Treiber. Einfach Seite öffnen, klicken – und die KI macht den Rest.
Warum KI-Scraper wie Thunderbit so revolutionär sind
- No-Code, kein Aufwand: Thunderbit ist nicht nur „no code“, sondern „no effort“. Du musst nichts einrichten. Einfach die installieren, Zielseite öffnen und die KI schlägt die zu extrahierenden Felder vor.
- Kommt mit dynamischen Inhalten klar: Da Thunderbit direkt im Browser arbeitet, sieht es alles, was du siehst – auch Daten, die erst durch JavaScript, Klicks oder Logins erscheinen.
- Schnell und präzise: Thunderbit kann mehrere Seiten in einem Rutsch auslesen und liefert besonders für Business-Anwendungen wie Lead-Generierung, E-Commerce oder Immobilien zuverlässige Ergebnisse.
- Keine Wartung: Thunderbit ist wie ein KI-Praktikant, der nie müde wird. Ändert sich die Webseite, passt sich die KI an. Kein ständiges Umschreiben von Code mehr.
- Datenbereinigung und Anreicherung: Thunderbit extrahiert nicht nur Rohdaten, sondern kann sie direkt labeln, formatieren, übersetzen oder zusammenfassen. Es ist, als würdest du 10.000 Webseiten an ChatGPT übergeben und ein sauberes, strukturiertes Spreadsheet zurückbekommen.
Das Ergebnis: Endlich können auch Fachabteilungen ohne IT-Unterstützung oder Python-Kenntnisse an die benötigten Daten kommen.
Thunderbit vs Beautiful Soup vs Selenium: Der Direktvergleich
Hier ein Überblick, wie sich die Tools für Business-Anwender schlagen:
| Kriterium | Beautiful Soup | Selenium | Thunderbit (KI-Web-Scraper) |
|---|---|---|---|
| Einrichtung | Einfache Python-Installation | Komplex (Browser-Treiber) | Chrome-Erweiterung, keine Einrichtung |
| Benutzerfreundlichkeit | Einfach für Entwickler | Anspruchsvoll, Programmierung nötig | No-Code, für Fachanwender |
| Geschwindigkeit | Schnell bei statischen Seiten | Langsam (Browser-Overhead) | Schnell bei kleinen/mittleren Jobs, nicht für Millionen |
| Dynamische Inhalte | Kein JavaScript | Alle dynamischen Inhalte | Alle dynamischen Inhalte |
| Wartung | Hoch (bricht bei Änderungen) | Hoch (bricht, Treiber-Updates) | Gering (KI passt sich an) |
| Skalierbarkeit | Gut für statisch, braucht Infrastruktur | Schwer skalierbar, ressourcenintensiv | Optimal für kleine/mittlere Jobs, nicht für Massen-Scraping |
| Datenbereinigung | Manuell, Nachbearbeitung | Manuell, Nachbearbeitung | Integriert: Label, Format, Übersetzung, Zusammenfassung |
| Integrationen | Individueller Code | Individueller Code | 1-Klick zu Excel, Sheets, Airtable, Notion |
| Technische Kenntnisse | Python erforderlich | Python + Browserwissen | Keine nötig |
Thunderbit im Detail: Wie KI Web-Scraping für Unternehmen neu definiert
Was macht Thunderbit für Business-Anwender so besonders?
1. KI-gestützte Datenerfassung
Thunderbit nutzt KI, um Webseiten zu „lesen“ und die besten Felder zur Extraktion vorzuschlagen. Du klickst einfach auf „KI-Felder vorschlagen“, prüfst die Spalten und startest den Scrape – ganz ohne HTML-Selektoren oder Code.
2. Subseiten-Scraping
Du willst aus einer Produktliste Details von jeder Produktseite erfassen? Thunderbit besucht automatisch jede Unterseite und ergänzt deine Tabelle – ohne Zusatzaufwand.
3. Datenbereinigung, Labeling und Übersetzung
Thunderbit kann:
- Daten labeln: Kategorien oder Tags direkt beim Scraping hinzufügen.
- Daten formatieren: Telefonnummern, Datumsangaben oder Preise vereinheitlichen.
- Übersetzen: Inhalte sofort in deine Wunschsprache übertragen.
- Zusammenfassen: Lange Texte auf Kernaussagen komprimieren.
Kurz: Ein Datenanalyst ist quasi schon eingebaut.
4. Nahtlose Integrationen
Exportiere deine Daten mit einem Klick direkt nach Excel, Google Sheets, Airtable oder Notion. Kein mühsames CSV-Handling mehr.
5. No-Code, keine Wartung
Thunderbit ist für Fachabteilungen gemacht, nicht für Entwickler. Du brauchst kein Python und musst dich nicht um Wartung kümmern – die KI passt sich automatisch an Änderungen an.
Mehr zu den Funktionen von Thunderbit findest du im .
Die richtige Wahl treffen: Empfehlungen für Unternehmen
Wie entscheidet man sich nun zwischen Beautiful Soup, Selenium und Thunderbit? Hier meine Praxistipps aus vielen Jahren Web-Scraping:
1. Wie viel Daten brauchst du?
- Kleine bis mittlere Projekte (einige Hundert bis Tausend Seiten): Thunderbit ist ideal – schnelle Einrichtung, kein Code, integrierte Datenbereinigung.
- Großprojekte (Zehntausende oder Millionen Seiten): Beautiful Soup (mit Frameworks wie Scrapy) oder Enterprise-Lösungen. Thunderbit ist für Massen-Scraping (noch) nicht optimiert.
2. Hast du Entwicklerressourcen?
- Entwickler verfügbar: Beautiful Soup und Selenium bieten volle Kontrolle.
- Keine Entwickler oder schnelle Ergebnisse gewünscht: Thunderbit oder ein anderes KI-Tool.
3. Wie oft ändert sich die Zielseite?
- Häufige Änderungen: Thunderbit passt sich automatisch an und spart Wartungsaufwand.
- Seltene Änderungen: Beautiful Soup oder Selenium funktionieren, aber du musst Skripte ggf. anpassen.
4. Brauchst du Datenbereinigung oder Anreicherung?
- Ja: Thunderbit kann labeln, formatieren, übersetzen und zusammenfassen.
- Nein, nur Rohdaten: Beautiful Soup oder Selenium.
Entscheidungs-Checkliste
| Frage | Bestes Tool |
|---|---|
| Kein Entwickler, Daten werden sofort benötigt | Thunderbit |
| Datenbereinigung/Übersetzung beim Scraping gewünscht | Thunderbit |
| Großes Volumen, individuelle Pipeline | Beautiful Soup/Scrapy |
| Häufige Seitenänderungen, wenig Wartung | Thunderbit |
Fazit: Die Zukunft der Python Web-Scraper
Web-Scraping hat sich seit meinen ersten Python-Skripten enorm weiterentwickelt. Auch 2025 bleibt die Frage „Beautiful Soup vs Selenium“ relevant – aber KI-Tools wie Thunderbit verändern das Spiel für Unternehmen grundlegend.
Beautiful Soup bleibt die erste Wahl für schnelles, unkompliziertes Auslesen statischer HTML-Seiten – schnell, schlank, einfach. Selenium ist weiterhin das Mittel der Wahl für dynamische, interaktive Seiten, bringt aber mehr Aufwand bei Einrichtung und Wartung mit sich.
Wer aber auf Code verzichten, Wartungsprobleme vermeiden und strukturierte, saubere Daten mit minimalem Aufwand erhalten möchte, für den sind KI-Web-Scraper wie Thunderbit die Zukunft. Sie sind nicht nur „no code“, sondern „no effort“. Für Teams in Vertrieb, E-Commerce oder Operations, die sofort Daten brauchen (und nicht erst nach einer Woche Debugging), ist das ein echter Gewinn.
Mein Tipp: Schau dir deine aktuellen Scraping-Prozesse an. Wenn du genug von kaputten Skripten, endloser Wartung oder langen Wartezeiten auf Entwickler hast, probier Thunderbit aus. Die Zukunft des Web-Scrapings ist schlauer, schneller und zugänglicher als je zuvor – und ich bin gespannt, wohin die Reise noch geht.
Du willst Thunderbit in Aktion sehen? oder stöbere in weiteren Anleitungen im . Und falls du gezielt nach Lösungen für bestimmte Seiten suchst (Amazon, Twitter, PDFs und mehr), findest du hier weitere Guides:
Viel Erfolg beim Scrapen – und mögen deine Daten immer aktuell, strukturiert und stressfrei sein.